Do Adversarially Robust ImageNet Models Transfer Better? 리뷰
안녕하세요, 오늘은 2020년 NeurIPS 학회에서 발표된 “Do Adversarially Robust ImageNet Models Transfer Better?” 논문을 리뷰할 예정입니다. Transfer Learning을 다룬 논문이며 Transfer Learning은 딥러닝에서 굉장히 자주 사용되는 학습 방법이며 최근에는 거의 default로 사용이 된다고 해도 과언이 아닙니다. 딥러닝을 공부해보신 분들이라면 필수적으로 ImageNet Pretrained Model을 가져와서 새로운 데이터셋에 학습을 시켜 보셨을 것입니다. 일반적으로 정확도가 높았던 pretrained model에서 transfer를 하면 target model에서도 높은 정확도를 얻는다고 알려져 있습니다.
실제로 이러한 경향을 실험적으로 밝힌 논문 “Do Better ImageNet Models Transfer Better?“ 이 CVPR 2019에서 발표 되었으며, ImageNet Top-1 Accuracy가 높았던 모델일수록 Transfer Accuracy도 상대적으로 높아진다는 결과를 제시하였습니다.
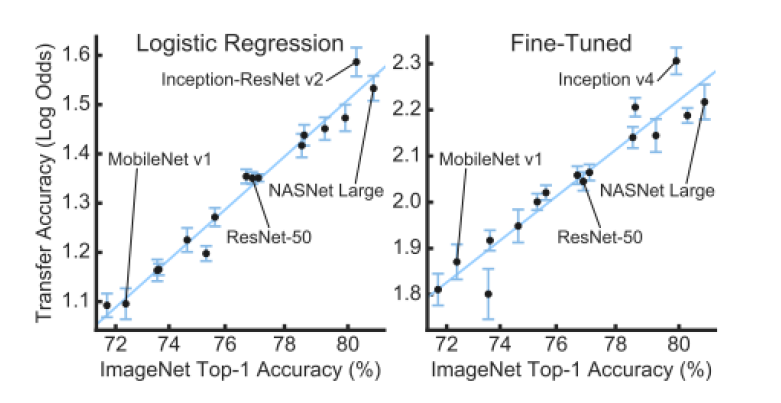
다만 Source 데이터셋(ImageNet)에서 높은 정확도를 달성하는 것이 Transfer Accuracy를 높이는 유일한 방법은 아닐 텐데, 아직까지 Transfer Accuracy에 관여하는 요소에 대한 자세한 분석이 잘 다뤄지지 않았습니다. 오늘 소개드릴 논문은 Transfer Accuracy를 높이기 위해 Adversarial robustness를 고려해야 함을 제시하고 있는데요, 이제 논문 설명으로 넘어가겠습니다. 이 논문을 다룬 발표 자료와 유튜브 발표 영상도 있으니 같이 참고해주시면 감사드리겠습니다.
Related Works
우선 오늘 소개드릴 논문과 관련이 있는 선행 연구들을 짚고 넘어가겠습니다. 여기서 언급하는 선행연구들은 본 논문에서 인용한 논문들입니다.
Transfer Learning in various domain
- “Comparison of deep transfer learning strategies for digital pathology”, 2018 CVPRW
- “Senteval: An evaluation toolkit for universal sentence representations”, 2018 arXiv
- “Faster r cnn : Towards real time object detection with region proposal networks”, 2015 NIPS
- “R fcn : Object detection via region based fully convolutional networks”, 2016 NIPS
- “Speed/accuracy trade offs for modern convolutional object detectors”, 2017 CVPR
- Deeplab : Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs ”, 2017 TPAMI
우선 다양한 domain에 Transfer Learning을 적용하려는 시도를 다룬 논문은 굉장히 많습니다. 그 중에서 Medical Imaging, Language Modeling, Object Detection, Segmentation 등에 Transfer Learning을 접목시킨 대표적인 논문이 위에 있습니다.
Transfer Learning with fine-tuning or frozen feature-based methods
- “Analyzing the performance of multilayer neural networks for object recognition”, 2014 ECCV
- “Return of the devil in the details: Delving deep into convolutional nets”, 2014 arXiv
- “Rich feature hierarchies for accurate object detection and semantic seg-mentation”,2014 CVPR
- “How transferable are features in deep neural networks?”,2014 NIPS
- “Factors of transferability for a generic convnet representation”, 2015 TPAMI
- “Bilinear cnn models for fine-grained visual recognition”,2015 ICCV
- “What makes ImageNet good for transfer learning?”, 2016 arXiv
- “Best practices for fine-tuning visual classifiers to new domains”,2016 ECCV
다음으론 Transfer Learning을 할 때 feature extractor를 freeze할 지, 아니면 전체를 fine-tuning할 지를 분석한 연구들이 위에 정리되어 있습니다. 요즘에는 후자인 fine-tuning이 대세이며 실제로 여러 연구에서도 fine-tuning이 더 좋은 성능을 보임을 제시하고 있습니다.
Adversarial robustness
- “Towards deep learning models resistant to adversarial attacks”, 2018 ICLR
- “Virtual adversarial training: a regularization method for supervised and semi-supervised learning”,2018
- “Provably robust deep learning via adversarially trained smoothed classifier”,2019NeurIPS

다음은 워낙 유명한 분야죠. Adversarial robustness입니다. 위의 그림은 딥러닝을 공부해보신 분들이라면 반드시 한 번쯤은 보셨을 그림입니다. Adversarial Attack을 다룬 논문, Defense를 다룬 논문 등 다양한 논문들이 단기간에 쏟아져 나왔고, 최근에는 Adversarially robust하게 network를 학습시켰을 때 얻어지는 feature들이 어떤 특징을 가지고 있는지를 분석하려는 시도들이 제안이 되고 있습니다. 일반적으로 adversarial robustness를 증가시키면, 일반 test set에서의 accuracy가 감소한다고 알려져 있으며, 이 둘 간의 tradeoff를 이론적, 실험적으로 밝히려는 연구들도 진행이 되고 있습니다.
Adversarial robustness & Transfer Learning
- “Adversarially robust transfer learning”, 2019 arXiv
- “Adversarially-Trained Deep Nets Transfer Better”, 2020 arXiv
마지막으로 오늘 소개 드리는 논문과 거의 비슷한 관점에서 진행된 논문은 두 편이 있습니다. 우선 첫번째 논문은 오늘 논문과는 반대로, Transfer Learning을 하면 From scratch로 학습을 시킬 때 보다 downstream task에서 adversarial robustness가 증가한다는 관찰을 담은 논문입니다. 두 번째 논문은 오늘 소개 드리는 논문과 같은 이야기를 하고 있습니다. Adversarial robustness를 증가시키는 방향으로 network를 학습시키면 Transfer Learning이 잘 된다는 것을 관찰은 했지만 실험과 분석이 다소 부족한 측면이 있어서 이를 발전시킨 논문이 오늘 다룰 “Do Adversarially Robust ImageNet Models Transfer Better?” 이라 할 수 있습니다.
Motivation: Feature Representation & Transfer Learning
자 이제 본론으로 들어가겠습니다.
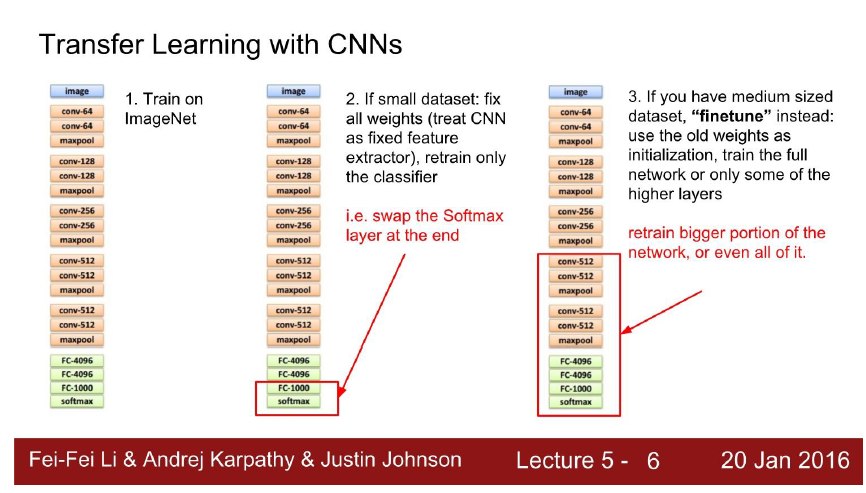
위의 그림은 제가 딥러닝을 입문할 때 많은 참고를 했던 스탠포드의 cs231n의 lecture note에서 발췌한 그림입니다. 예전에는 위의 그림의 가운데와 같이 feature extractor는 freeze 시키고, 마지막에 Fully-connected layer만 붙여서 Transfer Learning을 하는 방식을 많이 사용했습니다. 그렇게 되면 pretraining을 하여 얻은 feature extractor의 품질에 따라 Transfer Learning의 성능이 좌우되겠죠?
여기서 궁금증이 생깁니다. 과연 pretraining에 사용한 source dataset (e.g. ImageNet)에 대해서 높은 정확도를 얻었다고 반드시 feature extractor가 좋다고 할 수 있을까? (= Transfer Learning 성능이 높게 나올 수 있을까?)
위에 질문에는 사실 대답하기 어렵습니다. Network가 높은 정확도를 보유한다면, 그만큼 양질의 feature를 추출한다고 생각할 수 있긴 하지만, 그렇다고 해서 무조건 Transfer Learning도 잘 될 것이라는 보장은 하기 어렵습니다. Transfer Learning 관점에서 생각해보면 단순 source dataset에 대한 accuracy 보다는 feature extractor의 품질이 더 Transfer Learning에 좋은 영향을 미칠 것이라는 상상을 해볼 수 있습니다. 여기서 feature extractor의 품질을 높이기 위해서는 network architecture를 건드리는 방법도 있고, loss function을 바꾸는 방법도 있고 각종 augmentation, regularization 기법을 적용하는 방법도 있습니다. 즉, Transfer Learning을 잘 하기 위해선, 단순히 source dataset에 대한 accuracy만 보지 말고, feature extractor를 좋게 만드는 것에 초점을 둬야 한다 가 요지입니다.
서두가 길었는데, 정리하자면 Transfer Learning을 잘 하기 위해선 양질의 feature extractor를 얻어야 하고, 양질의 feature extractor를 얻기 위해선 각종 기법들을 적용할 수 있는데 그 중 한가지 기법이 adversarial robustness를 증가시키는 방법입니다. 하지만 여기서 약간의 모순이 생깁니다. Adversarially robust하게 network를 학습시키면 trade-off로 인해 standard test set에 대한 accuracy가 떨어지게 됩니다. 여기서 2가지 주장이 생겨납니다.
- Adversarially robust하게 학습을 시키면 standard accuracy가 떨어지니 Transfer Learning 성능도 떨어질 것이다. (예전 연구들의 의견)
- Adversarially robust하게 학습을 시키면 feature representation의 품질이 좋아지니 Transfer Learning 성능이 좋아질 것이다. (저자들의 주장)

실제로 network를 Adversarially robust하게 학습을 시킨 뒤 feature 들을 추출해보면 일반 모델들 보다 더 시각적인 정보를 많이 담고 있고, representation의 invertibility가 높아지고, 더욱 specialized feature를 배운 다는 연구들이 많이 발표가 되었습니다. 저자들은 위의 상충되는 두 가지 가설 중에 무엇이 정답인지 확인하기 위해 실험을 설계하고 진행하였습니다. 실험은 Fixed-Feature Transfer Learning 실험과 Full-Network Fine Tuning 모두 진행하였으며, 두 실험의 결과는 굉장히 높은 correlation을 가집니다.
실험 결과
자 이제 실험 셋팅을 설명 드리겠습니다. 우선 network는 ResNet 기반의 4개의 architecture (ResNet-18, ResNet-50, WideResNet-50-x2, WideResNet-50-x4)를 사용하였으며, ResNet-50에서 channel 개수를 2배, 4배씩 키워준 이유는 뒤에서 network의 width와 Transfer Learning의 성능을 비교하는 실험에 사용되기 때문입니다.
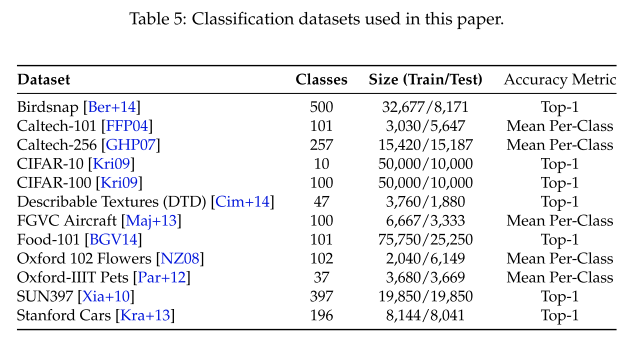
다음으로 실험에 사용한 데이터 셋은 일반적인 Transfer Learning 연구에서 주로 사용되는 12가지의 벤치마크 데이터셋을 사용하였습니다.

실험 결과 저자들의 주장대로 Robust Model을 사용하였을 때 transfer accuracy가 대체로 더 높은 것을 확인할 수 있었습니다. 물론 모든 데이터셋에서 다 그런 건 아니지만 대체로 그런 경향을 보입니다.
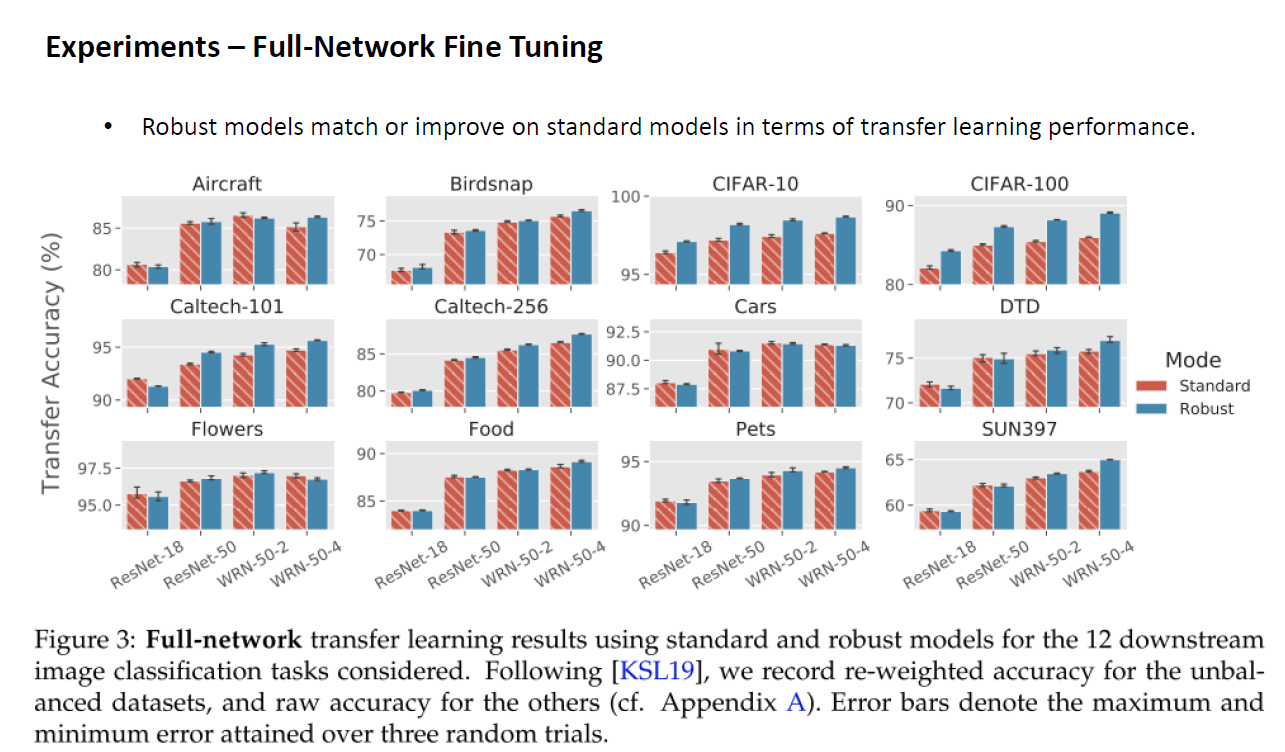
똑같은 실험을 Full-Network Fine tuning 기반의 Transfer Learning에서도 수행을 하였습니다. 많은 선행 연구들에서 Fixed-Feature transfer learning과 Full-Network Fine Tuning의 Transfer 성능이 매우 높은 correlation을 가지고 있음을 보였었는데, Robust Model을 사용하였을 때에도 같은 경향을 보이는 것을 확인할 수 있었고, 마찬가지로 Robust Model을 사용하였을 때 더 좋은 Transfer Accuracy를 보였습니다. 즉, 저자들의 주장이 맞았습니다.

또한 Classification 뿐만 아니라 다른 Computer vision task인 object detection, instance segmentation에도 Transfer Learning 실험을 수행하였고 마찬가지로 Robust Model을 사용할 때 더 좋은 정확도를 달성할 수 있음을 보여주고 있습니다.
Analysis & Discussion
다음은 추가적인 실험을 통해 Adversarially Robust Network의 행동을 분석한 내용들을 간략하게 설명드리겠습니다.
4.1 ImageNet accuracy and Transfer performance
우선 robust network와 일반 standard network에 transfer learning을 적용하였을 때의 공통점과 차이점을 살펴보았습니다.
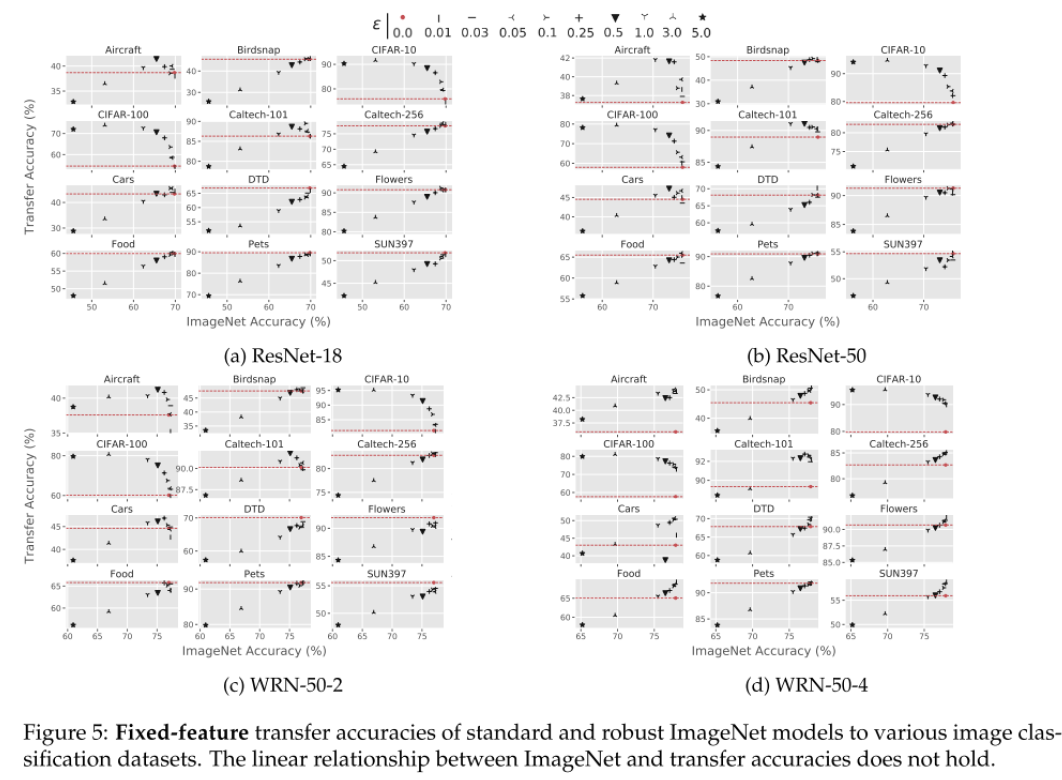
위의 실험 결과는 다양한 adversarial robust revel에 따른 standard accuracy (x축)와 transfer accuracy (y축)을 나타낸 그래프이고, 빨간색 점선이 standard network의 transfer accuracy를 의미합니다. 결과를 살펴보면 대체로 x축이 커질수록 y축도 커지는 경향을 보이지만 그렇지 않은 경우 (ex, CIFAR-10, CIFAR-100, Caltech-101)도 존재하는 것을 알 수 있고, Robust Model을 사용할 때가 그렇지 않을 때(빨간 점선)보다 항상 위에 존재할 수 있음을 보여주고 있습니다.
이러한 실험을 통해 standard accuracy (source 데이터 셋에서의 accuracy)와 transfer accuracy는 어느 정도 양의 상관관계를 가지지만, adversarial robustness를 고려하면 그렇지 않은 경우가 발생하며, 이를 통해 robustness와 standard accuracy는 분리해서 생각해야 함을 시사하고 있습니다. 즉, 고정된 robustness 값에서는 높은 standard accuracy일 때 더 좋은 transfer accuracy를 가지고, 고정된 standard accuracy 에서는 높은 robustness일 때 더 좋은 transfer accuracy를 가지는 것을 의미합니다.
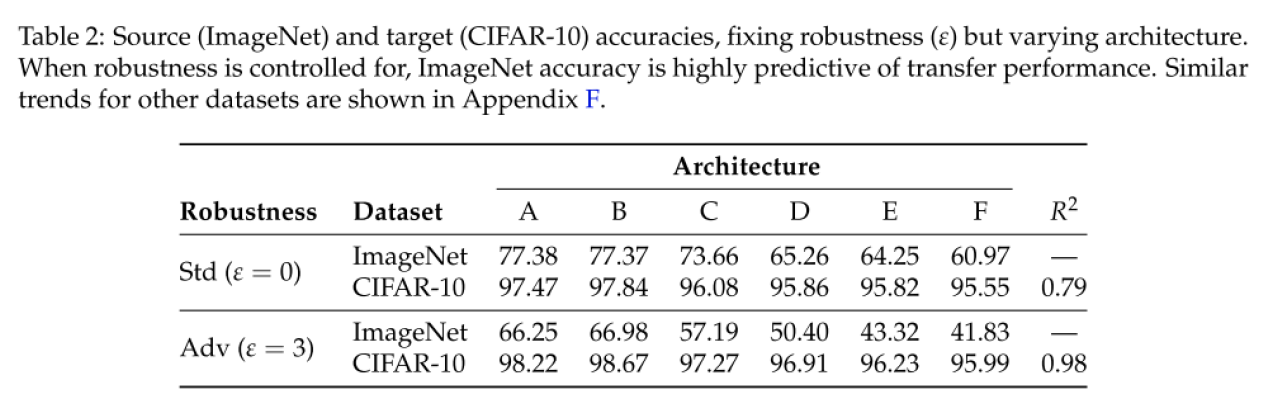
이를 더 자세히 확인하기 위해 robustness level을 0과 3으로 고정해두고, 다양한 architecture에 대해서 실험을 수행한 결과가 위의 표에 정리가 되어있습니다. Standard Model을 사용하였을 때에 source dataset의 accuracy(ImageNet)과 transfer accuracy(CIFAR-10)의 correlation은 0.79인 반면, Robust Model을 사용하면 둘 간의 correlation이 0.98로 매우 커지는 것도 발견할 수 있습니다.
4.2 Robust Models improve with width
다음으론 기존 연구들에서는 network의 depth (layer 개수)를 키워주는 것은 transfer accuracy에 좋은 영향을 준 반면, network의 width (channel 개수)를 키워주는 것은 오히려 transfer accuracy에 안 좋은 영향을 줬다고 합니다. 이러한 경향이 Robust Model에서도 관찰되는지 확인하기 위해 실험을 수행하였습니다.

실험 결과 Standard Model (빨간 점선)의 경우 width를 키워줄수록 Transfer accuracy가 떨어지거나 비슷한 값을 가지는 경향이 관찰되는 반면, Robust Model의 경우 width를 키워주면 Transfer accuracy도 같이 증가하는 경향을 보이는 것을 확인할 수 있습니다.
4.3 Optimal robustness levels for downstream tasks
다음으론 각 데이터 셋 마다 가장 Transfer 성능이 좋았던 robustness parameter에 대한 고찰입니다. CIFAR-10, CIFAR-100에서는 각각 1, 3일 때가 최적인 반면, 나머지 10개의 데이터 셋에서는 굉장히 작은 값의 입실론을 사용할 때 성능이 좋았다고 합니다. CIFAR와 나머지 데이터셋의 가장 큰 차이는 input resolution입니다. CIFAR는 32x32로 굉장히 작은 해상도의 이미지로 구성이 되어있는데, input image resolution을 dataset의 granularity라고 가정을 한 뒤, dataset의 granularity와 최적의 robustness parameter 입실론이 관계가 있을 것이라는 가설을 세웁니다.
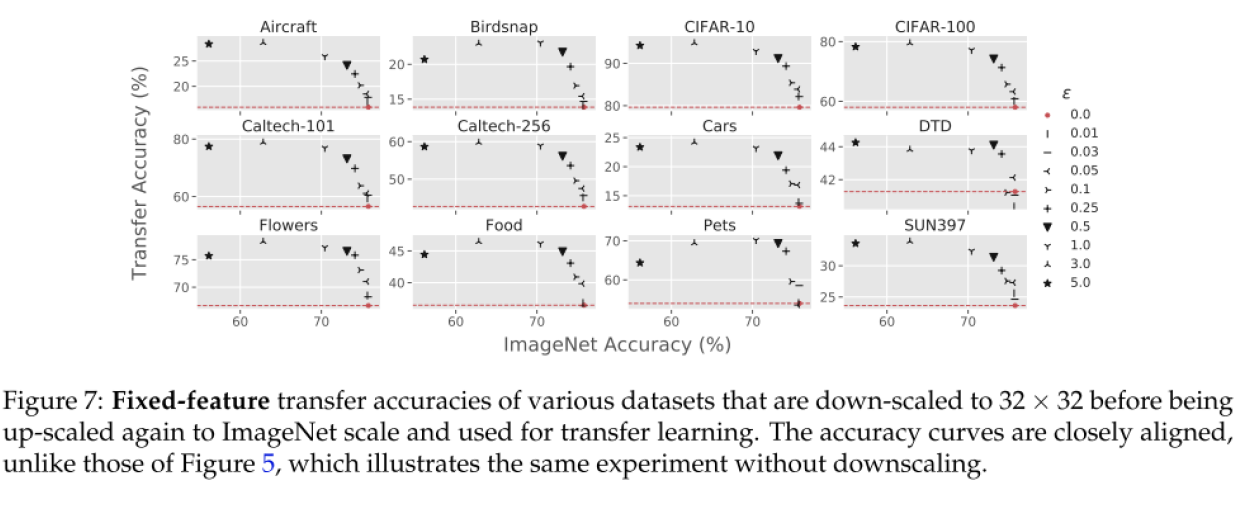
이를 검증하기 위해 나머지 10개의 데이터셋도 CIFAR처럼 32x32로 줄인 뒤 Transfer Learning 실험을 수행하여 최적의 입실론 값을 찾아보는 실험을 수행하였고, 그 결과가 위의 그림에 나와있습니다. 저자들의 예상대로 input resolution을 맞춰주니 비슷한 경향이 관찰되는 것을 확인할 수 있었습니다. 이를 통해 Dataset의 granularity가 높을수록 (= image resolution이 클수록) 더 작은 입실론 값을 사용하는 것이 유리하다는 실험적인 결론을 내릴 수 있습니다.
4.4 Comparing adversarial robustness to texture robustness

마지막으로 “ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness”, 2019 ICLR 논문에서 만든 Stylized ImageNet 데이터셋으로 학습시킨 texture-invariant model과 성능을 비교하였습니다.

실험 결과, Adversarially robust model이 texture-invariant model보다 더 좋은 성능을 달성할 수 있었음을 보여주고 있습니다.
결론
오늘은 NeurIPS 2020에 발표된 “Do Adversarially Robust ImageNet Models Transfer Better?” 논문을 리뷰해봤습니다. Robustness 쪽으로 활발하게 연구 중인 MIT Madry Lab에서 나온 논문이라 기대하면서 읽었는데 전달하고자 하는 메시지 “Adversarial Robust Model을 쓰면 Transfer Learning 성능이 좋아진다” 는 확실하게 와 닿았지만, 왜 좋아지는데? 에 대해서는 아직 명확하게 밝혀지지 않아서 그 점이 좀 아쉬웠고, 저자들도 “Still, future work is needed to confirm or refute such hypotheses, and more broadly, to understand what properties of pre-trained models are important for transfer learning.” 라고 언급하며 이 점을 future work로 남겨두고 있습니다. 다음 연구가 기대가 되는 논문이었습니다. 긴 글 읽어 주셔서 감사합니다!
comments powered by Disqus