ICLR 2019 image recognition paper list guide
안녕하세요, 이번 포스팅에서는 2019년 5월 6일 ~ 9일 미국 뉴올리언스에서 개최될 ICLR 2019 학회의 논문 중에 이미지 인식, 영상 처리와 관련이 있는 논문 28편에 대해 제 주관적으로 리스트를 정리해보았습니다. 오늘 다루지 않을 주제들은 자연어 처리(NLP), 강화학습(RL), 음성 관련 연구 등이며 이러한 주제들은 제가 배경지식이 많이 없어서 정리를 하지 못한 점 양해 부탁드립니다!
아직 학회가 많이 남았지만 미리 읽어 보기 좋도록 리스트를 추리는 것을 목표로 글을 작성하였으며, 전체 accepted paper가 500편이다보니 하나하나 읽어보는 것은 불가능하여서, 제가 제목만 보고 재미있을 것 같은 논문 위주로 정리를 해보았습니다.
당부드리는 말씀은 제가 정리한 논문 리스트에 없다고 재미 없거나 추천하지 않는 논문은 절대 아니고 단지 제 주관에 의해 정리된 것임을 강조드리고 싶습니다.
ICLR 2019 Paper Statistics
지난번 소개드렸던 NeurIPS 처럼 ICLR 도 굉장히 인기있는 학회인데요, 이 학회에는 매년 몇 편의 논문이 accept되는 지 조사를 해보았습니다.

매년 제출되는 논문 편수도 증가하고 있고, 그에 따라서 accept되는 논문들의 편수도 증가를 하고 있습니다. 불과 2년전에 비해 규모가 약 3배가량 커졌으며 약 30% 대의 acceptance rate를 보이고 있는 것을 확인할 수 있습니다.
또한 ICLR는 특이하게 Open-Review 방식으로 review가 진행되어서 각 논문마다 reviewer로부터 몇 점을 받았는지 확인할 수 있습니다. 이를 잘 정리해놓은 자료를 발견하여서 이 자료 를 토대로 ICLR 2019를 분석하였습니다.
우선 10점 만점의 점수 중에 accepted paper는 평균 6.6점 정도의 rating을, rejected paper는 평균 4.7점 정도의 rating을 보이고 있으며, 오늘 소개드릴 논문마다 평균 점수도 같이 기재할 예정입니다. 또한 theory, robustness, graph neural network 등의 키워드를 가진 논문들이 평균적으로 점수가 높았다고 합니다. 이러한 키워드 정보를 참고하면 최근 트렌드를 파악하는데 도움이 될 수 있습니다.
참고로 올해는 총 24편의 oral paper와 476편의 poster 총 500편 논문이 accept되었으며, 저는 오늘 그 중 28편의 논문을 소개드리고자 합니다.
Image Recognition 관련 논문 소개
앞서 말씀드렸듯이 ICLR 2019에 accept된 논문을 모두 다 확인하기엔 시간과 체력이 부족하여서, 간단하게 제목만 보면서 제가 느끼기에 재미가 있을 것 같은 논문들을 추려보았습니다. 총 28편의 논문이며, 6편의 oral paper, 22편의 poster paper로 준비를 해보았습니다. 또한 각 논문마다 abstract를 읽고 논문을 간단히 정리해보았습니다.
1. Large Scale GAN Training for High Fidelity Natural Image Synthesis (Oral)
- Rating: 7 / 10 / 9 , avg. 8.67
- 512x512 크기의 이미지와 같이 high resolution 이미지를 생성하는 generative model BigGAN 제안. ICLR paper중 가장 높은 rating을 받았으며 실제로 결과 이미지들을 보면 해상도가 큰 이미지인데도 그럴싸하게 생성해내는 것을 확인할 수 있음.

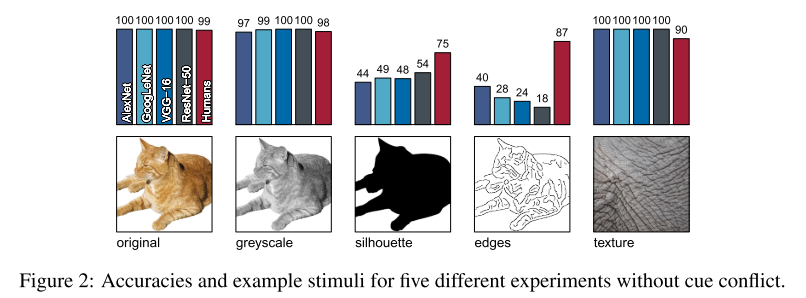
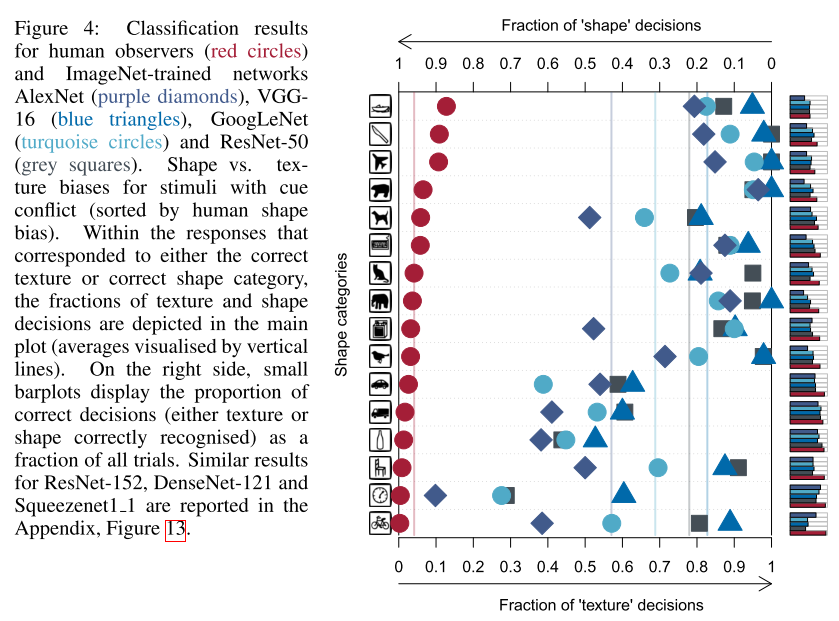
2. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness (Oral)
- Rating: 7 / 8 / 8 , avg. 7.67
- ImageNet으로 pretrain된 CNN은 object의 texture에 bias되어있음을 보이며, global object shape 정보를 이용하면 robust한 CNN을 만들 수 있음을 보임. 또한 실험을 위해 Style Transfer 알고리즘을 이용하여 ImageNet으로부터 Stylized-ImageNet 이라는 데이터셋을 생성한 점이 인상 깊음. 해당 데이터셋은 해당 링크 에서 확인할 수 있음.
3. Learning Unsupervised Learning Rules (Oral)
- Rating: 8 / 8 / 8 , avg. 8.00
- Meta-learning 관련 논문이며 unsupervised representation learning update rule을 다룬 논문. Unsupervised learning에 관심이 있다면 꼭 읽어보면 좋을 논문이며 실제로도 리뷰어들로부터 높은 평점을 받은 논문임.

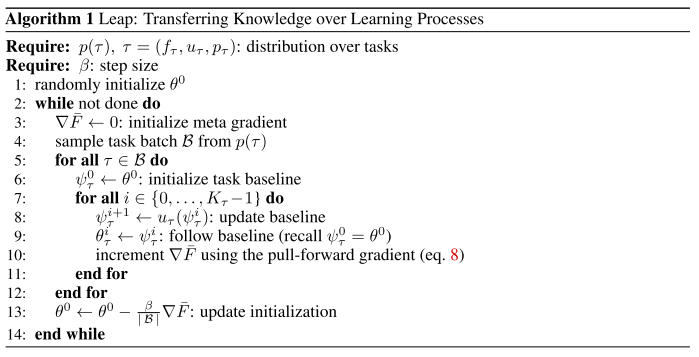
4. Transferring Knowledge across Learning Processes (Oral)
- Rating: 6 / 8 / 8 , avg. 7.33
- Transfer learning에 대한 논문이며 meta learning 관점에서 학습을 통해 knowledge를 잘 transfer하도록 하는 Leap 라는 방법론 제안. Omniglot 데이터셋, Multi-CV benchmark 에 대해 실험을 수행하였고 선행 연구들에 비해 좋은 성능을 달성함.
5. Learning Robust Representations by Projecting Superficial Statistics Out (Oral)
- Rating: 7 / 7 / 9 , avg. 7.67
- 학습에 사용하지 않은 배경이나 texture 등 작은 변화에 취약한 classifier를 개선하기 위해 unguided domain generalization 라는 문제 상황을 설정하고 이를 해결하기 위한 gray-level co-occurrence matrix(GLCM) 방법을 제안함.

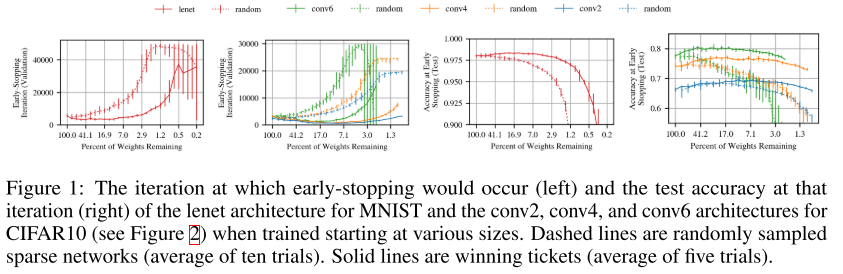
6. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks (Oral)
- Rating: 5 / 9 / 9 , avg. 7.67
- pruning 관련 논문이며 기존의 pruning을 적용한 architecture 기반으로 학습을 수행할 때 학습이 잘 되지 않는 문제를 해결하는 방법을 제안함. 논문의 제목에서도 알 수 있듯이 Trainable한 pruned network를 찾는(winning tickets) 방법을 다룸.
7. Three Mechanisms of Weight Decay Regularization (Poster)
- Rating: 6 / 7 / 7 , avg. 6.67
- Weight decay는 최근 neural network를 구성할 때 흔히 사용하는 방법임. 이 방법들의 효과를 분석한 논문. Weight decay의 regularization 효과를 크게 3가지 mechanism으로 나눌 수 있으며 이에 대한 분석을 세세히 수행함. 3가지 mechanism은 아래 그림과 같음.

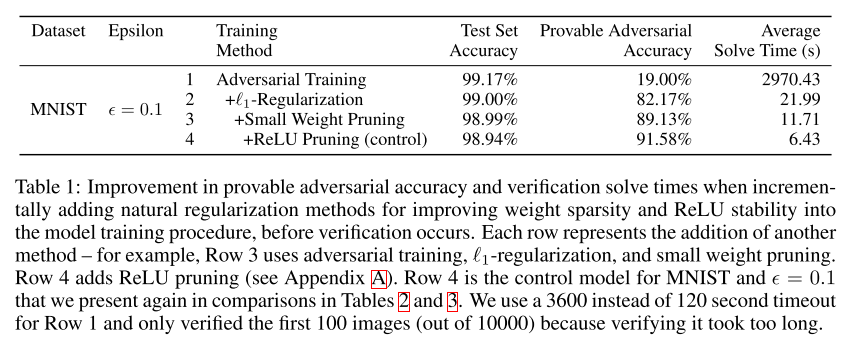
8. Training for Faster Adversarial Robustness Verification via Inducing ReLU Stability (Poster)
- Rating: 8 / 7 / 5 , avg. 6.67
- adversarial attack에 강인하면서도 빠르게 학습시키는 방법을 다룬 논문. Weight sparsity와 ReLU stability 두가지 방향으로 접근하며 빠르며 강인한 network를 학습시킬 수 있음을 보임.
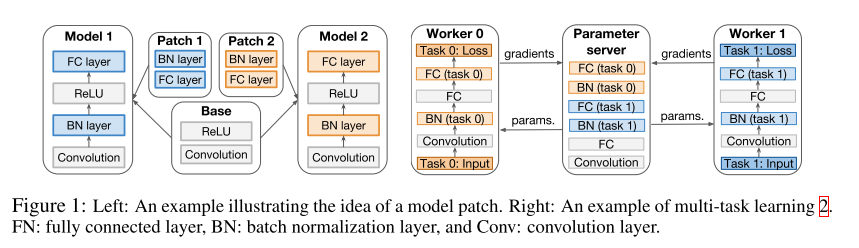
9. K For The Price Of 1: Parameter Efficient Multi-task And Transfer Learning (Poster)
- Rating: 7 / 6 / 8 , avg. 7.00
- Transfer learning과 multi-task learning 관련 논문이며 모델의 parameter의 일부분(model patch)이 각 task에 특화되도록 학습을 시키는 방법을 제안함. 즉 모든 parameter들을 재학습 시키지 않고 일부의 특화된 parameter들만 학습시켜도 비슷한 효과를 볼 수 있는 효율적인 학습 방법을 제안함.
10. Adaptive Gradient Methods with Dynamic Bound of Learning Rate (Poster)
- Rating: 7 / 4 / 6 , avg. 5.67
- Optimizer 관련 논문이며 기존의 AdaGrad, Adam, RMSProp 등보다 안정적인 AdaBound, AMSBound optimizer 를 제안함. Adaptive gradient 방식이면서 dynamic하게 learning rate를 clipping하여 안정성을 높임. 다만 성능 측면에서 크게 좋아지는 점은 없어서 리뷰어들의 평점으로도 큰 점수를 주지는 않은 것으로 보임.

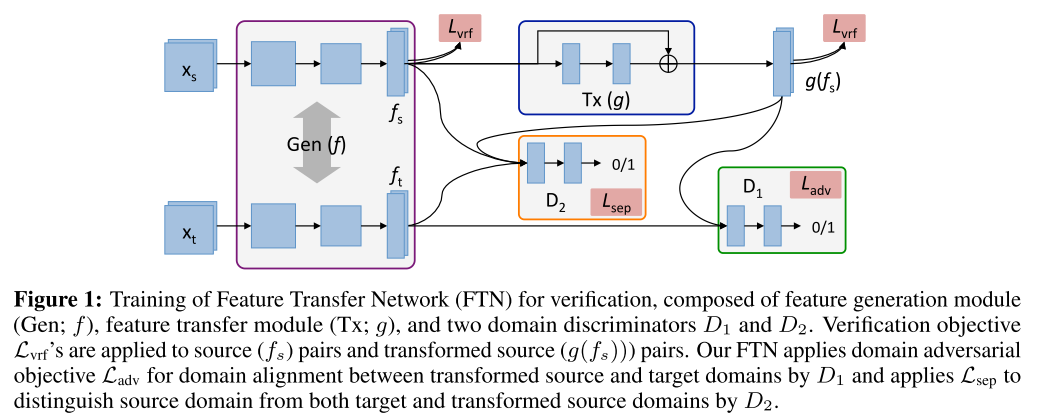
11. Unsupervised Domain Adaptation for Distance Metric Learning (Poster)
- Rating: 8 / 5 / 8 , avg. 7.00
- Unsupervised domain adaptation 관련 논문이며 주로 선행연구에서 풀지 못했던 문제인 source domain과 target domain이 서로 다른 label space를 가지는 경우에 대해 연구를 수행함. Feature Transfer Network(FTN) 이라는 방법을 제안하였으며 기존의 Domain Adversarial Neural Network(DANN) 대비 좋은 성능을 보임. 또한 non-parametric multi-class entropy minimization loss를 제안하고 target domain에서 FTN의 구분 성능을 끌어올림.
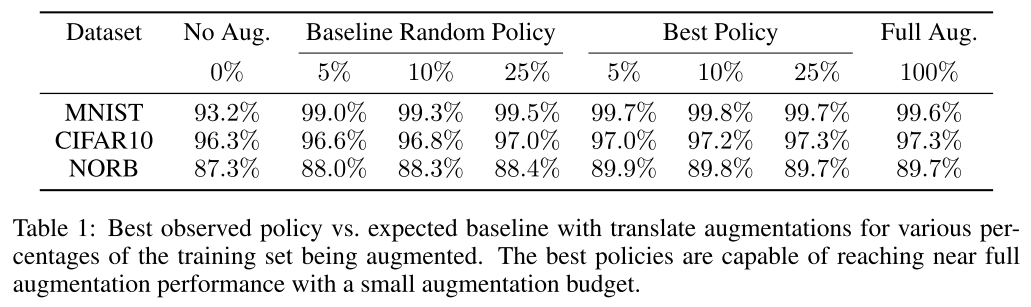
12. Efficient Augmentation via Data Subsampling (Poster)
- Rating: 6 / 7 / 6 , avg. 6.33
- Dataset augmentation에 대한 논문이며 model influence 와 loss를 기반으로 한 data subsampling 방식으로 효율적으로 augmentation을 하는 방법을 제안함. 효율적으로 augmentation을 수행하면 훨씬 적은 augmentation budget으로 full augmentation과 유사한 성능을 달성할 수 있음을 확인함. 또한 model influence와 loss를 계산하는 데에는 original dataset 기준 one-time cost of training이 소요되어 time issue도 존재하지 않음.
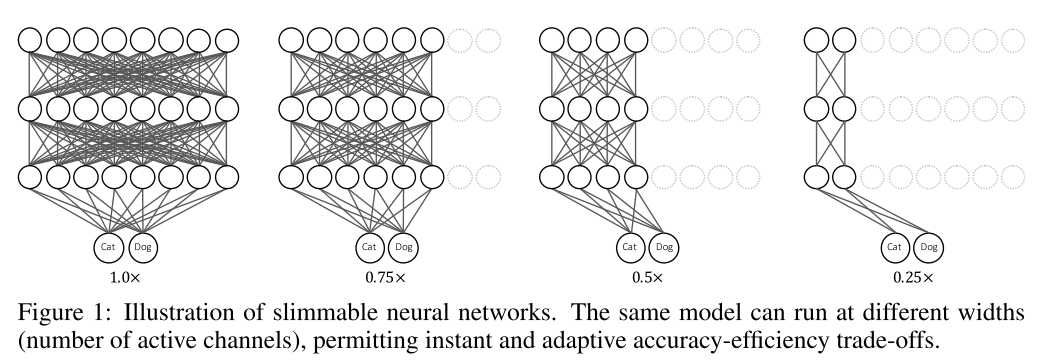
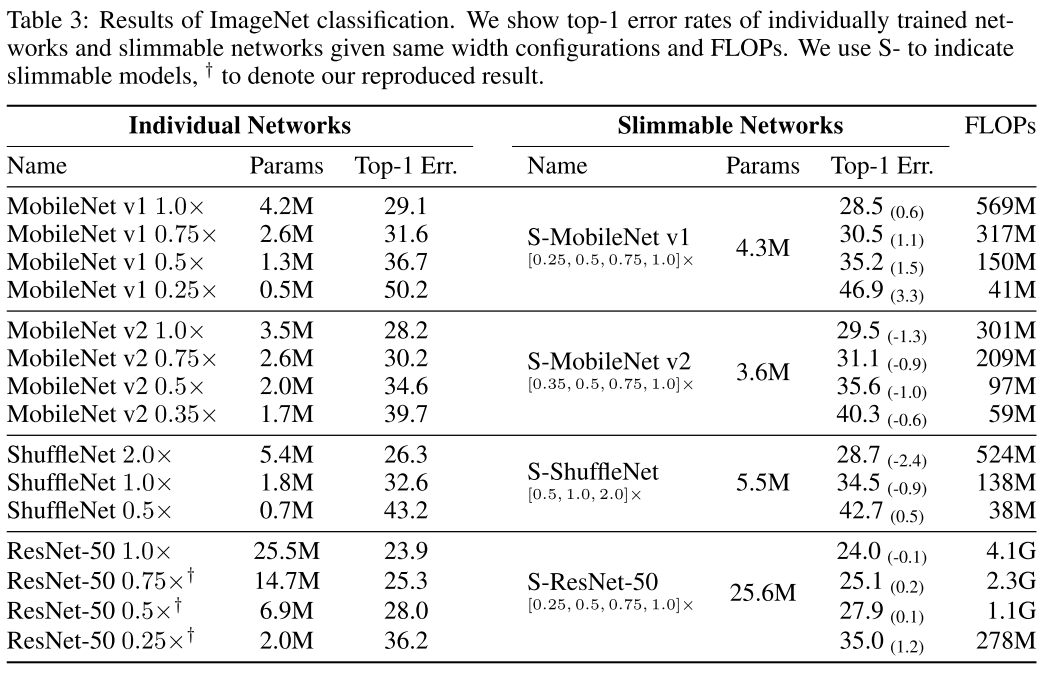
13. Slimmable Neural Networks (Poster)
- Rating: 8 / 9 / 7 , avg. 8.00
- 하나의 모델에서 연산 복잡도를 조절할 수 있도록 switchable batch normalization 이란 방법을 제안한 논문. 즉 각각 연산 복잡도마다 새로운 모델을 학습시킬 필요 없이 하나의 모델을 통해 accuracy-efficiency trade-off를 조절할 수 있다는 장점이 있음. 실용적으로 많이 사용될 수 있을 것으로 보임. 개인적으로 굉장히 인상 깊었으며 왜 Poster paper인지 개인적으로 궁금한 논문.
14. Don’t let your Discriminator be fooled (Poster)
- Rating: 7 / 7 /6 , avg. 6.67
- GAN의 discriminator를 robust 하게 학습시키기 위한 방법을 제안함. 기존의 standard gradient penalty 방식들보다 안정적인 결과를 내는 학습 방법인 Robust Feature Matching(RFM) 을 제안함.

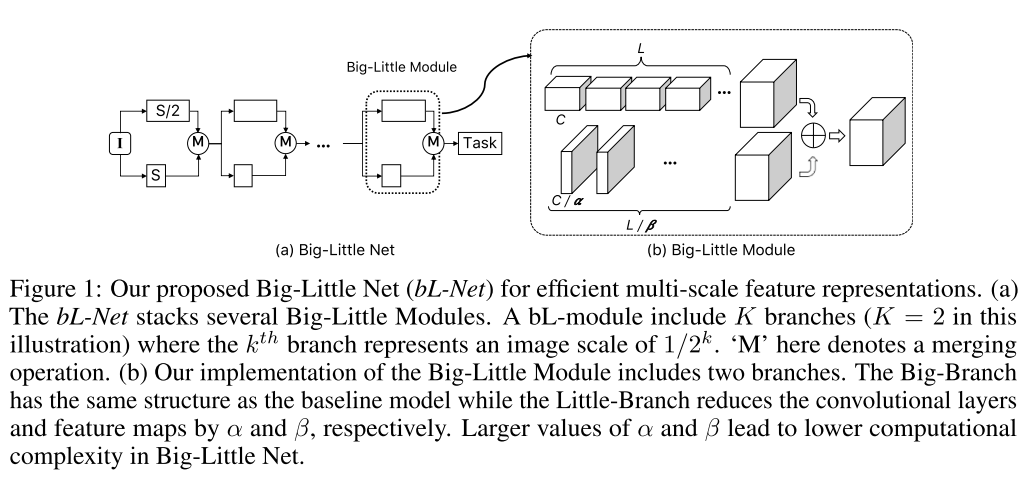
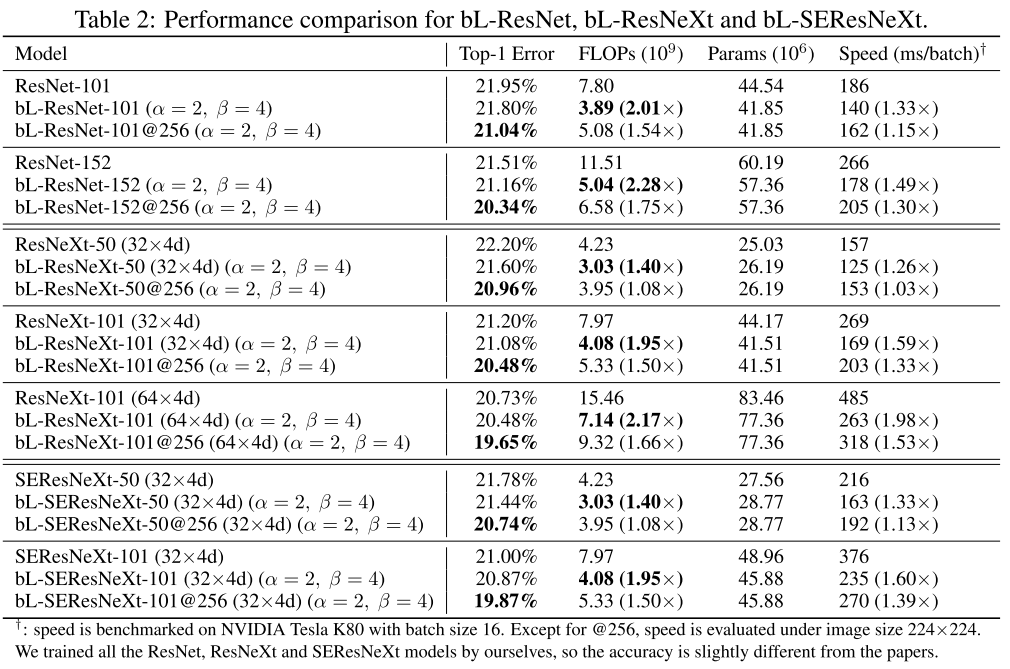
15. Big-Little Net: An Efficient Multi-Scale Feature Representation for Visual and Speech Recognition (Poster)
- Rating: 7 / 6 / 7 , avg. 6.67
- Multi-scale feature representation 학습을 위한 Big-Little Network 구조를 제안함. 제안한 방식을 사용하여 object recognition과 speech recognition 분야에 대해 실험을 하였고, model efficiency와 performance 모두 좋아지는 결과를 얻음.
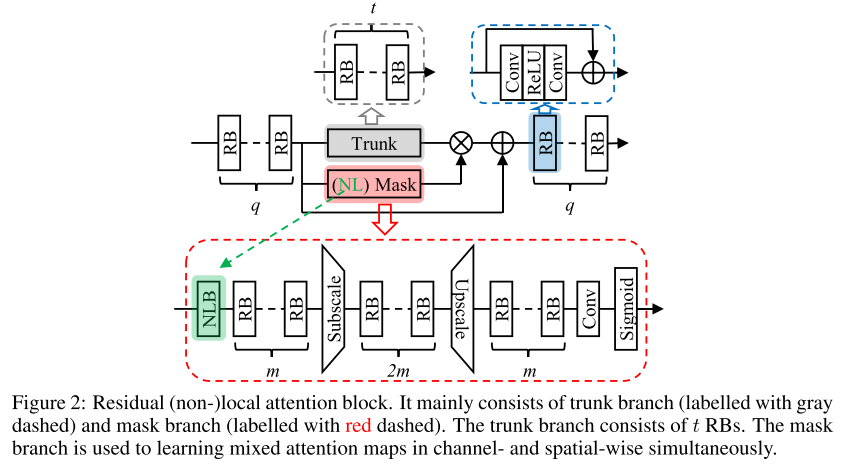
16. Residual Non-local Attention Networks for Image Restoration (Poster)
- Rating: 7 / 7 / 6 , avg. 6.67
- 이미지 복원 관련 residual non-local attention network 구조를 제안함. Denoising, demosaicing, compression artifact reduction, super resolution 등 다양한 image restoration에 대해 실험을 진행하였고 좋은 성능을 보임. Image Restoration 연구에 관심이 있으면 참고하면 좋을 논문.
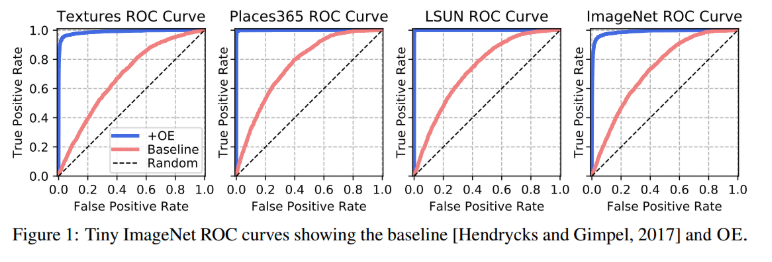
17. Deep Anomaly Detection with Outlier Exposure (Poster)
- Rating: 6 / 6 / 8 , avg. 6.67
- auxiliary dataset을 이용한 Outlier Exposure(OE) 접근법을 통해 anomaly detection(out-of-distribution detection) 문제를 해결하는 방법론을 제안함. 외부 데이터셋을 활용해야 한다는 단점이 있지만 상황만 잘 맞으면 좋은 성능을 낼 수 있음을 보임.
18. Efficient Multi-Objective Neural Architecture Search via Lamarckian Evolution (Poster)
- Rating: 6 / 6 / 6 , avg. 6.00
- Neural Architecture Search 관련 논문이며 진화알고리즘 방식을 사용한 LEMONADE 라는 이름의 방법론을 제안함. 다만 최근 NAS 관련 다양한 논문들이 나오고 있어서 특별한 장점을 보이는 것 같지는 않음.

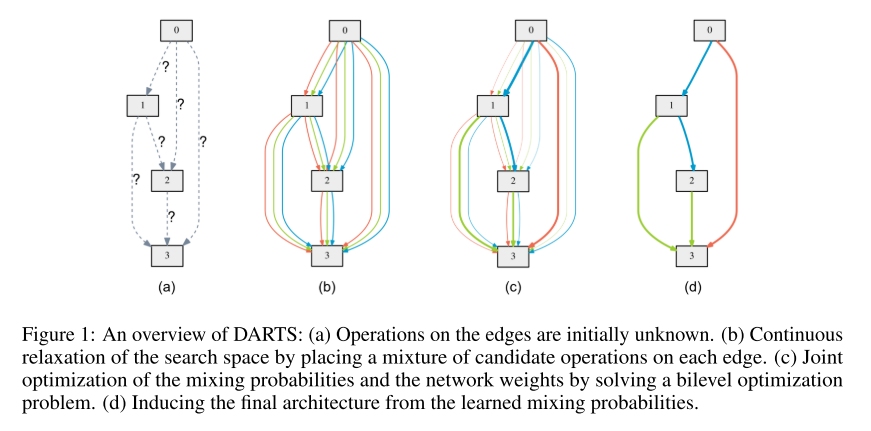
19. DARTS: Differentiable Architecture Search (Poster)
- Rating: 6 / 7 / 8 , avg. 7.00
- 마찬가지로 Neural Architecture Search 관련 논문이며 gradient-based differentiable NAS 방법론을 제안함. 그 덕에 적은 계산 량으로 architecture를 찾을 수 있으며 준수한 성능을 보이는 것을 확인함.
20. SNAS: stochastic neural architecture search (Poster)
- Rating: 6 / 7 / 7 , avg. 6.67
- 마찬가지로 Neural Architecture Search 관련 논문이며, 위의 DARTS와 거의 유사한 gradient-based differentiable NAS 방법론임. 둘의 차이점은 아래 그림과 논문에서 자세히 확인할 수 있음. 다만 성능 측면에서 큰 이점을 보이진 않음.

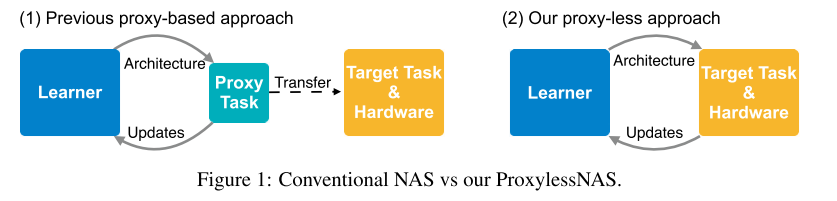
21. ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware (Poster)
- Rating: 6 / 6 / 7 , avg. 6.67
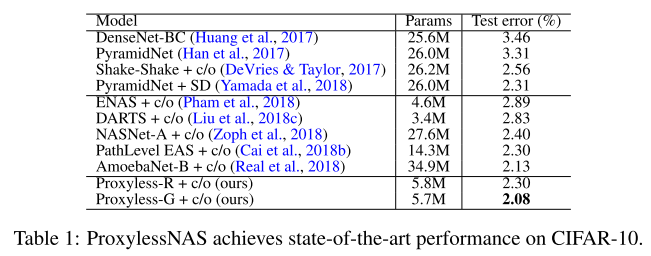
- 마찬가지로 Neural Architecture Search 관련 논문이며 기존 논문들(ex, CIFAR-10에서 찾은 구조를 기반으로 ImageNet에 transfer 시키는 방식) 과는 다르게 타겟 task와 hardware를 고려하여 directly architecture를 찾는 방법이며 gradient-based 방식을 적용함. CIFAR-10 데이터셋에 대해서는 기존 사람이 design한 network, Neural Architecture Search를 통해 design한 network를 통틀어서 가장 높은 정확도(97.92%)를 달성함.
22. CAMOU: Learning Physical Vehicle Camouflages to Adversarially Attack Detectors in the Wild (Poster)
- Rating: 4 / 8 / 7 , avg. 6.33
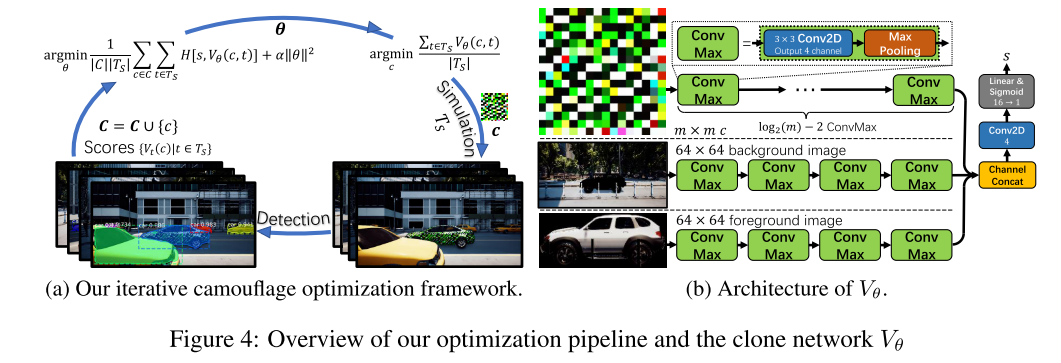
- 물리적인 adversarial attack을 통해 차량 detection을 방해하는 것을 다룬 논문이며 현실에서도 physical adversarial attack이 가능한 것을 확인할 수 있음.
23. Multi-class classification without multi-class labels (Poster)
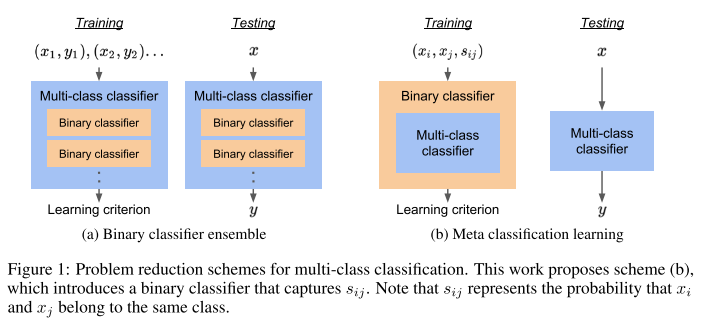
- Rating: 6 / 7 / 5 , avg. 6.00
- class label 정보 없이 probabilistic graphical model을 이용한 binary decision 방식 기반 multi-class classification을 하는 방법을 다룬 논문. Supervised, unsupervised, semi-supervised learning에서 다 적용 가능한 것을 확인함.
24. A Closer Look at Deep Learning Heuristics: Learning rate restarts, Warmup and Distillation (Poster)
- Rating: 4 / 7 / 6 , avg. 5.67
- Learning rate restarts, Warmup and Distillation 등의 heuristic하게 사용되던 방법을 분석한 논문. 실제로 이러한 방법들이 왜 잘 되는지, 언제 잘 되는지 등을 분석함.
25. Rethinking the Value of Network Pruning (Poster)
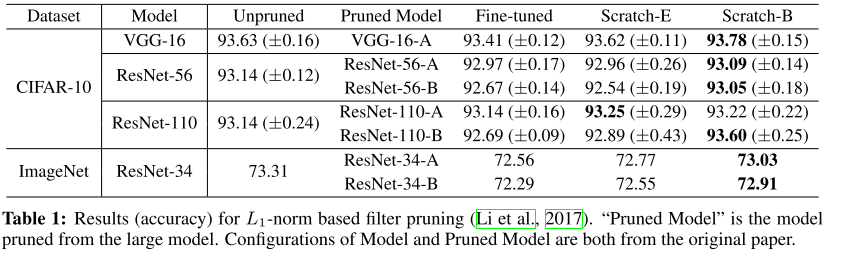
- Rating: 6 / 6 / 7 , avg. 6.33
- Network Pruning에서 일반적으로 여겨지던 사실들에 대해 다시 생각해보는 논문. 6개의 State-of-the-art pruning 알고리즘에 대해 pruned model을 fine-tuning한 결과 scratch부터 학습한 결과와 비교하였을 때 효과적이지 않으며 기존 모델에서의 “important” weight가 pruned model에서도 꼭 중요하지는 않음을 보임.
26. Practical lossless compression with latent variables using bits back coding (Poster)
- Rating: 6 / 6 / 8 , avg. 6.67
- 딥러닝을 이용한 무손실 압축 방식 Bits Back with ANS(BB-ANS) 을 제안함. MNIST dataset에 대해 실험을 진행하였으며 선행 연구 대비 가장 좋은 성능을 달성함.

27. Differentiable Learning-to-Normalize via Switchable Normalization (Poster)
- Rating: 7 / 7 / 7 , avg. 7.00
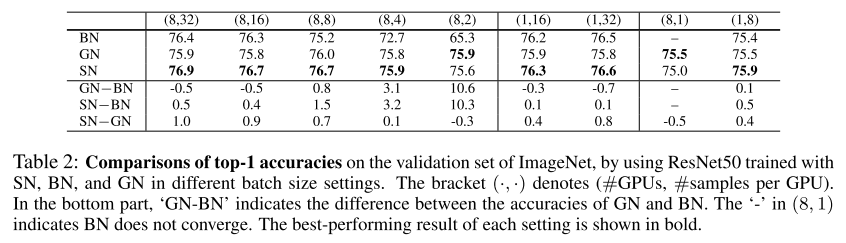
- Learning-to-normalize 방식인 Switchable normalization(SN) 기법을 다룬 논문. SN은 channel, layer, minibatch 총 3개의 scope에서 mean과 variance를 계산하며, 다양한 network에 쉽게 적용이 가능한 장점이 있음. 또한 다양한 batch size(e.g. 2)에 대해서도 robust하게 동작하며 Group Normalization과 다르게 hyper-parameter에 sensitive하지 않은 장점이 있음.

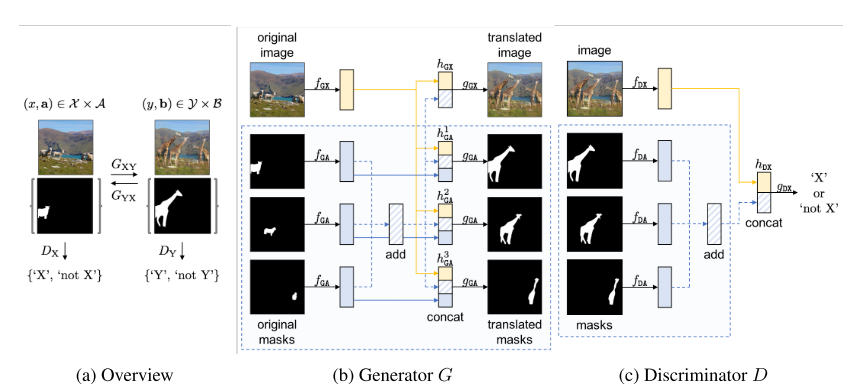
28. InstaGAN: Instance-aware Image Translation (Poster)
- Rating: 7 / 8 / 7 , avg. 7.33
- 기존의 Unsupervised image-to-image translation에서 겪었던 여러 어려움들(다양한 target instance, shape의 변화 등)을 개선한 Instance-aware GAN(InstaGAN) 방법을 제안함.

결론
이번 포스팅에서는 ICLR 2019에 accept된 논문 중에 이미지 인식 분야와 관련있는 28편에 대해 정리를 해보았습니다. 제가 정리한 논문 외에도 양질의 논문들이 많이 있으니 관심있으신 분들은 다른 논문들도 읽어보시고, 추천을 해주시면 감사하겠습니다!
참고 문헌