Learning Transferable Architectures for Scalable Image Recognition 리뷰
안녕하세요, 오늘은 최근 주목받고 있는 AutoML 관련 논문을 리뷰하려고 합니다. 논문 제목은 “Learning Transferable Architectures for Scalable Image Recognition” 이며 올해, 2018년 CVPR에 발표된 논문입니다. 이 논문을 소개하기에 앞서 AutoML에 대해 간략하게 설명을 드리고 그 중 오늘 소개드릴 논문을 집중적으로 설명 드리고, 그 후속 연구들에 대해 간단하게 설명 드리겠습니다.
이전 포스팅과는 다르게 구현체는 따로 올리지 않았습니다. 구현체를 올리지 않은 가장 큰 이유는 NASNet 학습을 시키려면 고성능의 GPU 500장으로 4일 동안 돌려야 CIFAR-10에 대해 architecture search가 가능하기 때문입니다. 이 글을 보시는 대부분의 분들은 GPU 500장을 보유하고 계시지 않을 가능성이 높기 때문에 전체 코드 구현체는 따로 구현하지 않았습니다. (만약 계시다면 심심한 사과의 말씀을 드립니다…) 또한 이 논문에서 CIFAR-10에 대해 찾은 architecture 구조는 쉽게 구현이 가능하며 코드 또한 많이 공개가 되어있어서 따로 구현체를 올리지 않았습니다. NASNet architecture 구현체가 필요하신 분들은 해당 링크 에서 확인이 가능합니다.
AutoML 이란?
AutoML 이란 간단하게 설명을 드리면 Machine Learning 으로 설계하는 Machine Learning을 의미하며, 크게 3가지 방향으로 연구가 진행이 되고 있습니다.
- Automated Feature Learning
- Architecture Search
- Hyperparameter Optimization
Machine Learning에서 중요한 부분을 차지하는 Feature Extraction, 혹은 Feature Engineering 은 학습 모델에 입력을 그대로 사용하지 않고, 유의미한 feature(특징점)를 추출해서 입력으로 사용하는 방법을 의미합니다. 기존에는 사람이 직접 feature 추출 방법을 정해서 하는 방식이라 각 모델마다 최적의 feature 추출 방식을 찾는 과정에 많은 시간이 소요되었습니다. Automated Feature Learning은 사람이 직접 실험적으로 feature 추출 방법을 정하는 대신 최적의 feature 추출 방법을 학습을 통해서 찾는 방법을 의미합니다. Deep Learning에서는 feature 추출이 뒤에 소개드릴 2가지 요소에 비해 중요성이 비교적 낮은 편이어서 본 포스팅에서는 자세히 다루지는 않을 예정입니다.
Architecture Search란 저희가 익히 알고 있는 AlexNet, VGG Net, ResNet, DenseNet 등 CNN과 LSTM, GRU 등 RNN을 구성하는 network 구조, 즉 architecture를 사람이 직접 하나하나 설계하는 대신 학습을 통해 최적의 architecture를 설계하는 방법을 의미합니다. 주로 강화학습(Reinforcement Learning)이나 유전 알고리즘 등을 이용한 연구들이 최근에 많이 발표되고 있으며, 올해에는 gradient 기반으로 한 DARTS 등 활발하게 연구가 진행되고 있습니다. 본 포스팅에서는 Architecture Search를 주로 다룰 예정이며, 강화학습 기반 방법론을 리뷰할 예정입니다.
Hyperparameter Optimization이란 학습을 시키기 위해 필요한 hyperparameter들을 학습을 통해 추정하는 것을 의미합니다. 예를 들어 학습률(learning rate), 배치 크기(mini-batch size) 등 학습에 큰 영향을 주는 hyperparameter들을 기존에는 사람이 하나하나 값을 바꿔서 모델을 학습시켜서 가장 성능이 좋았던 hyperparameter를 사용하는 방식이 주로 사용이 되었다면, AutoML에서는 학습을 통해 최적의 hyperparameter를 추정하는 방법을 제안합니다. 이 부분도 Deep Learning에서 중요한 부분을 차지하고 있지만, 본 포스팅에서는 Architecture Search에 대해서만 다룰 예정입니다.
강화학습 기반 Architecture Search 방법론
기존 방법론(NAS)
강화학습 기반으로 최적의 architecture를 찾는 연구는 Barret Zoph, Quoc V. Le의 “Neural Architecture Search with reinforcement learning”(2017) 논문 이 가장 잘 알려져 있습니다. 줄여서 NAS라고 불리며, network의 architecture를 결정하는 요소들, 예를 들면 각 convolutional layer의 filter size, stride 등의 값을 예측하는 RNN Controller와, 이 RNN Controller가 출력한 값들로 구성한 모델을 학습시켜 얻은 validation accuracy를 reward로 하여 RNN controller를 학습시키는 강화학습 모델로 구성이 되어있습니다.
RNN controller가 출력한 값을 토대로 생성한 architecture를 타겟 데이터셋으로 처음부터 끝까지 학습을 시킨 뒤 성능을 측정하는 이 모든 과정이, 강화학습 모델에게는 학습을 진행하기 위한 하나의 episode에 해당합니다. 일반적으로 전체 데이터셋을 이용하여 학습을 시킨 뒤, 성능을 측정하는 과정엔 경우에 따라 다르겠지만 적지 않은 시간이 소모됩니다. 이러한 긴 과정이 강화학습 입장에서는 단 하나의 episode에 해당하니 강화학습을 통해 성능을 높이기 위해선 굉장히 많은 학습을 반복해야 함을 의미합니다.
실제로 익히 알려진 데이터셋인 CIFAR-10에 대해 최적의 모델을 찾기까지 800대의 최상급 GPU 를 사용하여 거의 한달 이 걸렸다고 합니다. 이렇게 해서 찾은 모델은 ResNet보다는 좋은 성능을 보이고, DenseNet과는 거의 유사한 성능을 보이는 것을 확인할 수 있었습니다. 하지만 CIFAR-10 데이터셋은 앞선 포스팅에서도 다뤘듯이, 이미지의 크기가 32x32로 작은 편이며 전체 학습 이미지의 개수도 5만장밖에 되지 않습니다. 만약 ImageNet과 같이 이미지의 크기도 크고, 학습 이미지의 개수도 훨씬 많은 경우에는 최적의 모델을 찾기까지 굉장히 많은 시간이 소모될 것입니다. 이러한 치명적인 한계가 존재하지만, 강화학습을 기반으로 사람이 design한 모델에 버금가는 모델을 찾을 수 있음을 보인 것 자체로 큰 의미를 가질 수 있다고 생각합니다.
NASNet
이제 본격적으로 설명드릴 내용은 위의 연구에서 발전된 연구이며, 위의 단락의 말미에서 언급 드린 한계를 해결하는 방법을 제안하였습니다. 논문에 제목에서도 알 수 있듯이 Transferable한 Architecture Search 방법론을 제안하게 됩니다. 선행 연구인 NAS와 다르게 image classification 을 위한 CNN 구조 탐색으로 범위를 한정 지어서 논문을 작성하였습니다. 결론을 먼저 말씀드리면 본 논문은 CIFAR-10에서 찾은 최적의 모델의 정보를 활용하여 ImageNet 데이터에 대해 적용하였을 때 사람이 design한 기존 State-of-the art 모델에 버금가는 성능을 보일 수 있음을 보여주고 있습니다. 또한 선행 연구인 NAS보다 학습에 소요되는 시간이 단축되었습니다. 물론 단축된 시간도 굉장히 긴 편입니다.
- NAS
- 800 GPU, 28 days (NVIDIA K40 GPU)
- NASNet
- 500 GPU, 4days (NVIDIA P100s GPU)
우선 두 방식의 가장 큰 차이점은 Search space의 변화입니다. Search space, 즉 탐색 공간의 차이로 인해 많은 것을 얻을 수 있었습니다. 여기서 말하는 탐색 공간이란 Network 구조를 구성하는 요소를 어떻게 정의하여 탐색하는지를 의미합니다.
기존 방법론(NAS)의 경우 network를 구성하는 각 layer 하나 하나를 RNN controller를 통해 탐색합니다. 이 경우 좀 더 network를 구체적으로 정의할 수 있지만 그만큼 탐색 공간이 커지는 장단점이 있습니다. 실제로 CIFAR-10에 대해 NAS를 적용하여 얻은 network를 보면 규칙성을 찾기 힘들 정도로 거의 매 layer마다 다른 모양의 convolution filter를 사용하는 것을 알 수 있습니다. 반면 소개드릴 방법론은 Search space를 좁혀서 network 구조를 탐색하는 방법을 제안합니다.
논문에서는 Convolution Cell이라는 단위를 사용하였는데, 전체 network 대신 이 Cell들 탐색한 뒤, 이 Cell들을 조합하여 전체 network를 설계합니다. 여러분의 이해를 돕기 위해 쉬운 예시를 들어보겠습니다. 여러분이 듣기 좋은 음악을 작곡한다고 가정해봅시다. 실제론 그렇지 않겠지만 비유를 위해 가정을 하나 더 하자면, 만든 음악이 가령 기계(oracle)에 의해 좋은 정도에 따라 0 ~ 100점 척도로 점수가 매겨진다고 가정해봅시다. 이러한 상황에서 기존 NAS의 접근 방법은 매번 새로운 음악을 만든 뒤 점수 평가를 받은 뒤, 그 음악은 버리고 그 느낌을 기억한 채로 다시 새로운 음악을 만드는 과정을 반복하는 것이라고 표현할 수 있습니다.
본 논문의 방법은 일정 길이를 갖는 멜로디, 예를 들면 후렴구와 같은 멜로디를 여러 개 만든 뒤에 정해진 순서에 맞게 배치하여 곡을 만들고 점수 평가를 받는 과정으로 비유할 수 있습니다. 이렇게 되면 점수 평가를 받기까지 걸리는 시간이 처음부터 하나의 노래 전체를 작곡하는 것 보다 짧게 되는 장점이 있고 무엇보다 더 긴 노래를 만들어야 하는 상황이 생겼을 때 만든 후렴구들을 이어 붙이기만 하면 긴 노래를 쉽게 만들 수 있다는 장점이 있습니다. 물론 같은 구간이 반복되어 작곡의 자유도가 떨어지는 단점이 있습니다. 하지만 긴 노래를 만들어야 하는 상황에서는 처음부터 끝까지 다 작곡하는 방법(NAS)보다는 훨씬 빠르게 작곡이 가능할 것입니다. 또한 이 논문의 결론에 의하면 이렇게 여러 멜로디를 이어 붙여도 꽤 그럴싸한 노래를 만들 수 있음을 보여주고 있습니다. 작곡을 architecture search로 치환하면 NAS와 NASNet의 관계가 되는데, 이 비유는 이번 단락을 다 이해하시면 쉽게 와 닿으실 수 있을 것이라 생각합니다.
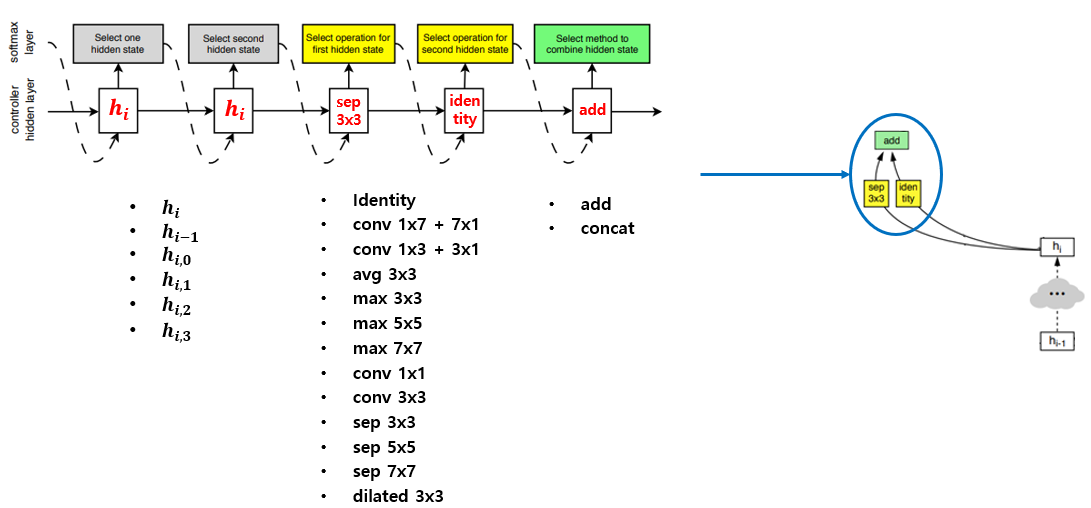
우선 가장 작은 단위인 Block 에 대해 설명을 드리겠습니다. Block은 2개의 연산을 수행하여 하나의 feature map을 출력하는 역할을 하며, 위의 그림과 같이 RNN controller 5개 값이 하나의 block을 결정합니다. 순서대로 2개의 hidden state input과 2개의 operation과 1개의 combine operation을 결정하게 됩니다.
Hidden state input은 해당 block이 포함되어 있는 convolution cell의 input인 hi 혹은 이전 convolution cell의 input인 hi-1, 또는 해당 block의 다른 hidden state의 output 중 하나를 선택하도록 제약이 있습니다. 이렇게 제약을 둔 이유도 아마 search space를 효율적으로 가져가기 위해 둔 것으로 판단이 됩니다.
Operation은 총 13가지가 있으며, 이 논문이 쓰여진 시점에서 잘 알려져 있고, 성능이 좋다고 알려져 있는 operation 위주로 추려진 것으로 판단됩니다. Operation의 종류는 위의 그림에 나와있으며 identity, pooling, conv와 conv의 변형 등 다양하게 구성이 되어있습니다.
마지막으로 Combine operation은 2개의 operation으로부터 나온 값을 그대로 element-wise로 더해서 사용할 지 아니면 channel-wise로 concatenate하여 사용할지 선택하도록 되어있습니다. 이렇게 5개의 값이 RNN controller를 통해 출력되면 하나의 block이 얻어집니다. 이렇게 순차적으로 B개의 block을 만들어내면 하나의 Convolution Cell을 구성하게 됩니다.
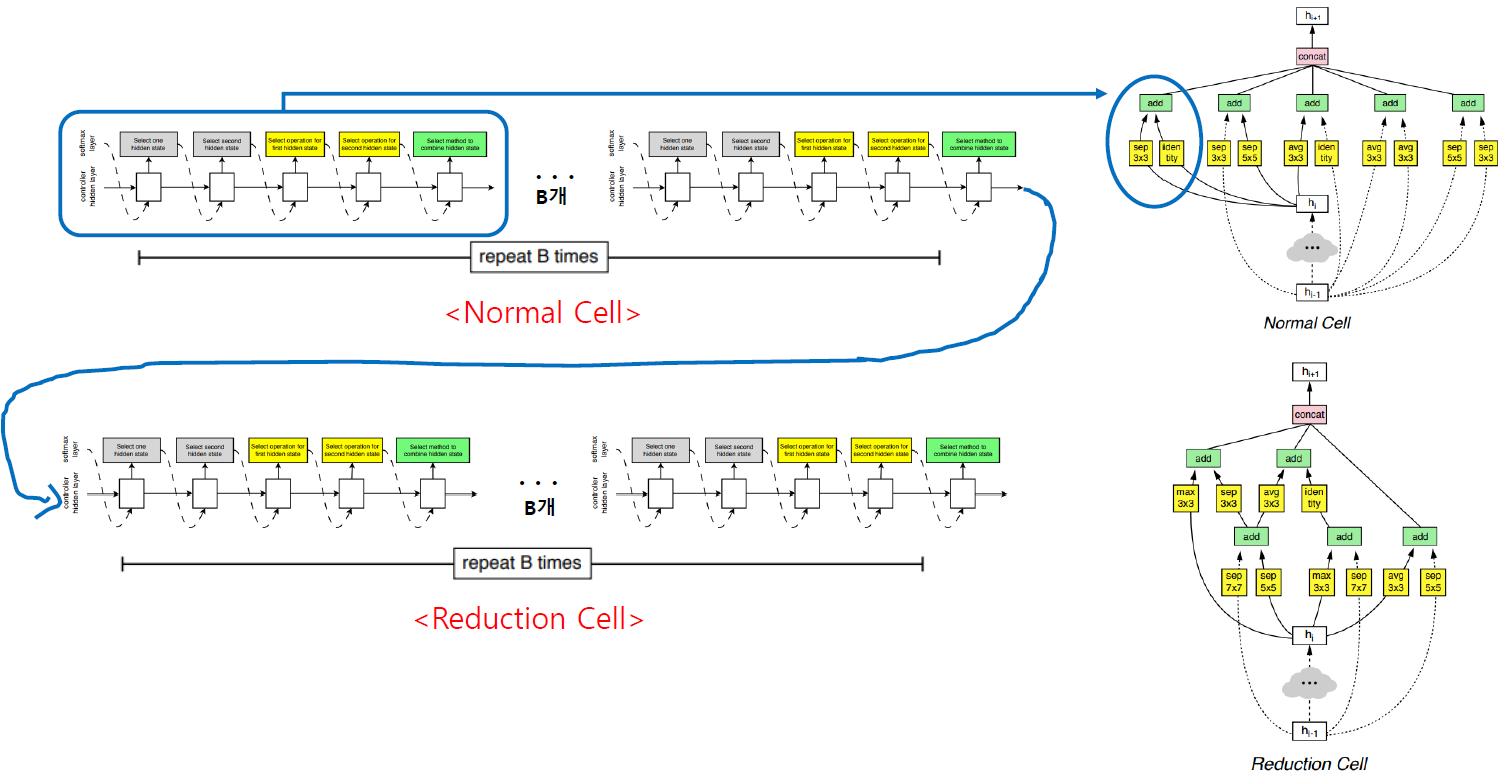
다음 단위인 Convolution Cell에 대해 설명을 드리겠습니다. Convolution Cell은 Normal Cell, Reduction Cell 총 두 가지의 Cell이 존재합니다. Normal Cell은 입력과 출력의 feature map의 가로, 세로 크기가 같은 Cell을 의미하며, Reduction Cell은 출력 feature map의 가로, 세로 크기가 입력 feature map의 가로, 세로 크기의 절반이 되는 Cell을 의미합니다.
Reduction Cell과 Normal Cell은 모두 block으로부터 생성이 되며 유일한 차이는 block의 연산들의 stride입니다. Normal Cell을 구성할 때에는 연산들의 stride가 1로 고정이 되며, Reduction Cell을 구성할 때에는 stride 값을 1 또는 2를 사용하게 됩니다. 즉, 같은 RNN controller로부터 Normal Cell을 위한 B개의 block과 Reduction Cell을 위한 B개의 block을 추출하지만, Reduction Cell을 구성하는 block은 stride가 1 또는 2가 될 수 있음을 의미합니다.
Reduction Cell의 stride가 1인 경우는 해당 block의 input으로 같은 Cell의 다른 block의 output을 사용하는 경우를 의미합니다. 이미 그 block에서 stride 2를 거쳐서 feature map의 가로, 세로 크기가 절반이 되었기 때문에 stride를 1을 이용하게 됩니다. 이제 이렇게 block을 만들고, 만든 block으로 convolution cell을 만들어서 어떻게 전체 architecture를 구성하는지 설명 드리겠습니다.
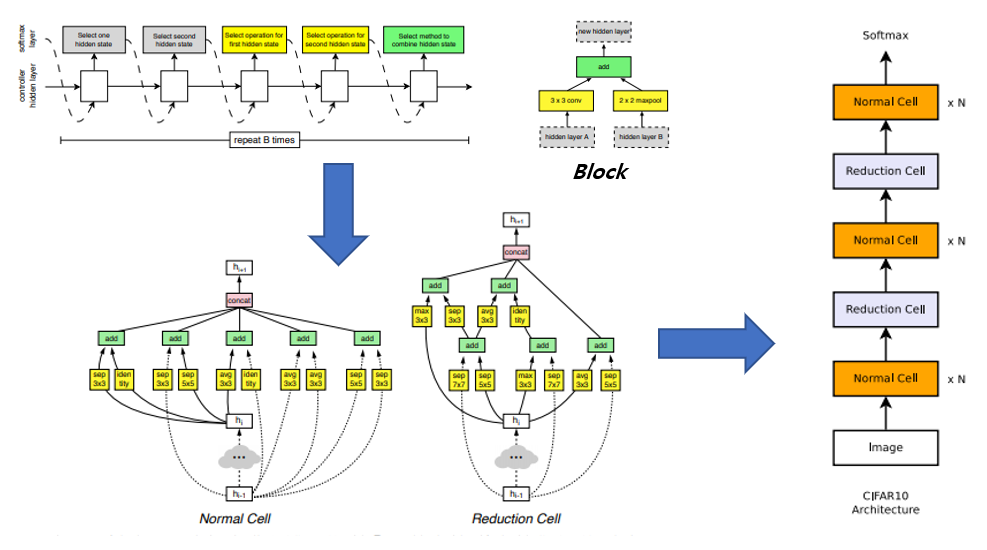
위의 그림은 Block에서 Convolution Cell을 거쳐 전체 architecture를 구성하는 과정을 보여주고 있습니다. 과정을 순차적으로 정리하면 다음과 같습니다.
- RNN controller로부터 Normal Cell을 위한 block B개, Reduction Cell을 위한 block B개를 생성한다.
- 생성된 2xB개의 block을 이용하여 Normal Cell과 Reduction Cell 두 가지의 Cell을 구성한다. (그림 3의 좌측 하단 부분)
- 두 가지의 Convolution Cell을 정해진 순서에 맞게 배치하여 network를 구성한다.
- 구성된 network를 토대로 training data로 학습을 시킨 뒤 validation accuracy를 측정하여 reward로 사용하여 강화학습을 수행한다.
- RNN controller를 update한 뒤, 다시 1번으로 돌아간다.
마지막으로 학습 과정의 detail에 대해 설명하겠습니다. RNN controller는 one layer LSTM 구조를 사용하였으며, 각 layer마다 100개의 hidden unit을 가지고 있습니다. RNN controller를 학습시키기 위한 강화학습 알고리즘으로는 선행 연구인 NAS에서는 REINFORCE rule을 사용하였는데, 본 논문에서는 2017년 OpenAI에서 발표한 Proximal Policy Optimization(PPO)를 사용하였습니다. 이 외의 전체적인 강화학습 방법은 NAS와 거의 유사합니다. 즉, State는 controller의 hidden state이고, Action은 controller로부터 생성된 prediction이고, Reward는 생성된 network로부터 측정한 validation accuracy를 의미합니다. 더 자세한 내용은 Appendix에서 확인이 가능합니다.
NAS vs NASNet Architecture 비교
이번 장에서는 강화학습을 통해 찾은 architecture에 대해 분석을 할 예정입니다. 우선 선행 연구 NAS에서 찾은 architecture와, NASNet 방법으로 찾은 architecture가 어떻게 다른 지 분석을 하겠습니다.
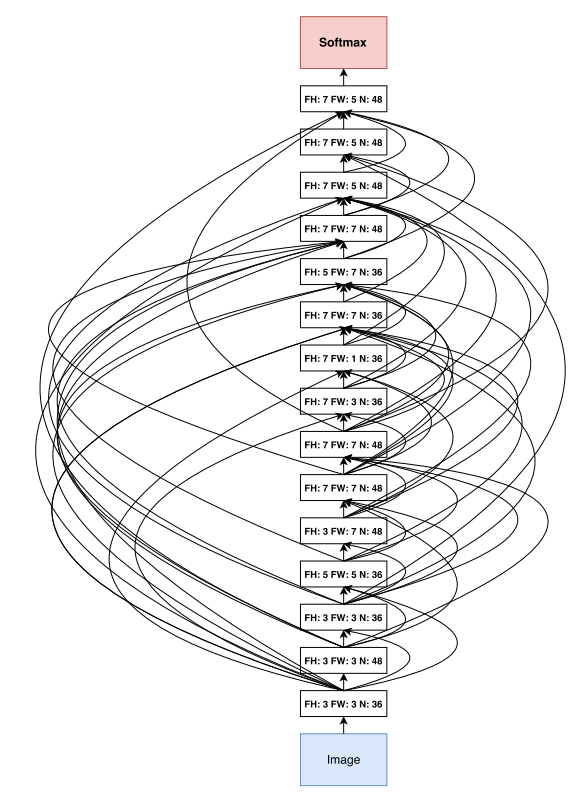
위의 그림은 NAS 방법으로 찾은 architecture입니다. NAS에서는 각 layer마다 filter의 모양, stride, filter 개수, skip connection 등을 RNN controller로 결정하기 때문에 직렬 적인 구조를 가지게 됩니다. Architecture를 자세히 들여다보면 저희가 주로 사용하는 3x3 convolution filter는 3번밖에 쓰이지 않았고 5x5, 7x5, 5x7, 7x7 등 다양한 모양의 convolution filter를 사용하는 것을 확인할 수 있습니다. 또한 skip connection이 굉장히 많으며 사람이 design하기에는 다소 무리가 있을 정도로 불규칙성이 심한 것을 확인할 수 있습니다.
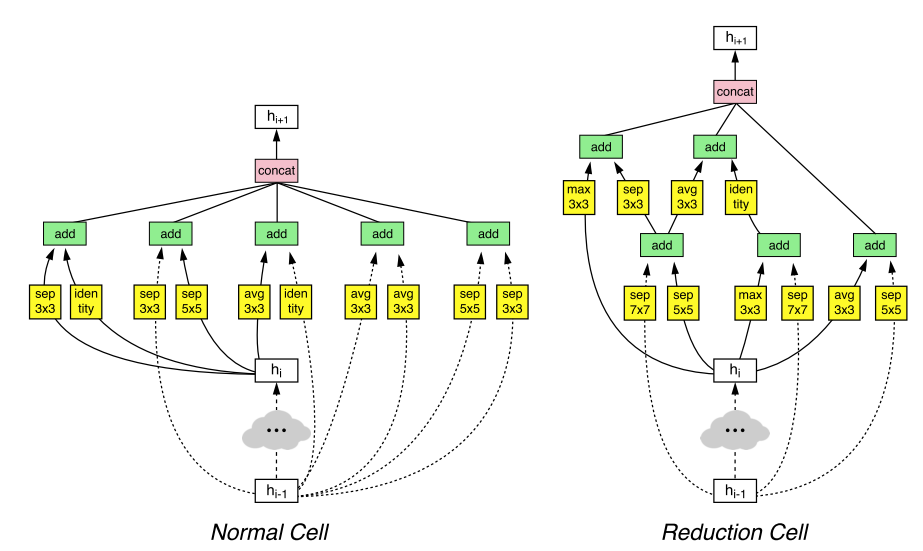
위의 그림은 이 논문에서 제안한 방법으로 찾은 2개의 Convolution Cell을 보여주고 있습니다. 이 Cell들을 적절히 조합하여 architecture를 설계하면 되기 때문에 전체 architecture를 한번에 설계하는 NAS와 그림이 다소 모양이 다릅니다.
우선 본 논문에서 제안한 3가지 version(NASNet-A, B, C) 중 가장 성능이 좋은 NASNet-A의 Normal cell과 Reduction cell의 구조를 관찰해보면, 신기하게도 초록색 박스로 되어있는 부분인 combine operation이 전부 add operation이 선택된 것을 확인할 수 있습니다. 또한 노란색 박스에는 13가지 operation이 선택될 수 있는데, 그림 1에 나와있듯이 operation 중 convolution 연산은 총 8가지인데 막상 찾은 Convolution Cell은 depthwise-separable convolution(sep) 연산만 선택된 것이 흥미로운 점입니다. 이는 NASNet-B, C에서도 비슷한 경향을 보이며 대부분 sep 연산이 선택되었습니다. 또한 pooling 연산의 경우 대부분 3x3 pooling이 선택된 것도 흥미로운 점입니다.
이 논문이 생성한 architecture를 보면서, 바둑에서 사람을 압도한 알파고의 기보를 보며 사람이 바둑을 배우는 것처럼, 딥러닝을 통해 찾은 architecture로부터 사람이 무언가를 배울 수 있지 않을까 생각해봅니다.
실험 결과
이번 단락에서는 NASNet의 실험 결과를 설명 드릴 예정입니다. 우선 목표로 삼았던 CIFAR-10 데이터셋에 대한 실험 결과를 설명 드리고, NASNet의 가장 큰 장점인 transferable한 특징을 잘 보여주는 여러 실험 결과를 설명 드리겠습니다.
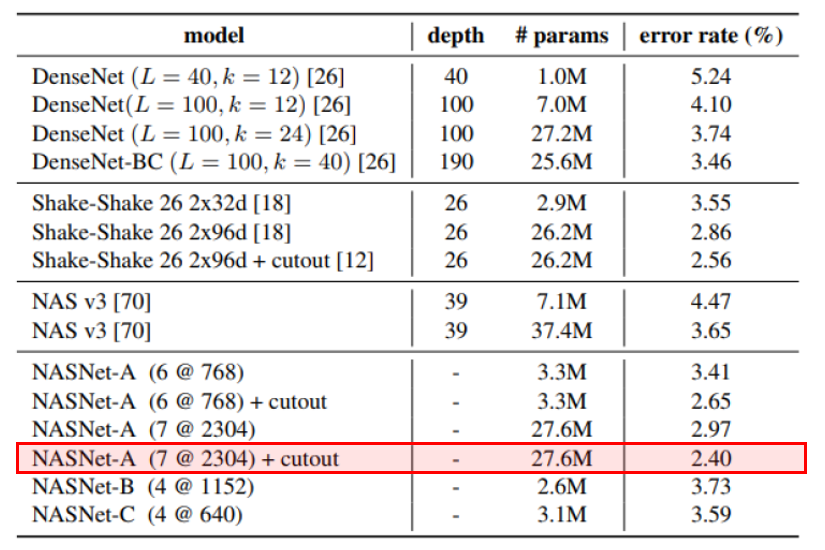
우선 CIFAR-10에 대한 실험 결과는 위의 표에 잘 나와있습니다. 우선 SOTA로 알려진 방법론들과, 선행 연구인 NAS의 결과가 제시되어 있고, 그 아래에는 NASNet parameter 수를 조절하고 구조에 변형을 주었을 때의 실험 결과가 제시되어 있습니다. 표의 결과는 정확도를 5번 측정하여서 평균을 낸 결과입니다.
앞서 리뷰했던 논문인 shake-shake regularization 에 cutout을 적용하였을 때의 2.56% error rate이 현존하는 방법론 중에 가장 낮은 error rate였는데 NASNet을 사용하면 거의 비슷한 수의 parameter로 더 낮은 2.40%의 error rate를 달성할 수 있는 것을 확인할 수 있습니다. 또한 가장 성능이 좋았던 경우는 2.19%의 error rate를 달성하였다고 합니다. 물론 cutout을 적용하지 않은 경우에는 shake shake의 결과가 더 좋긴 하지만, 강화학습으로 찾은 network가 사람이 공을 들여서 design한 network에 버금가는 성능을 보이는 것 만으로도 큰 의미를 가질 수 있다고 생각합니다.
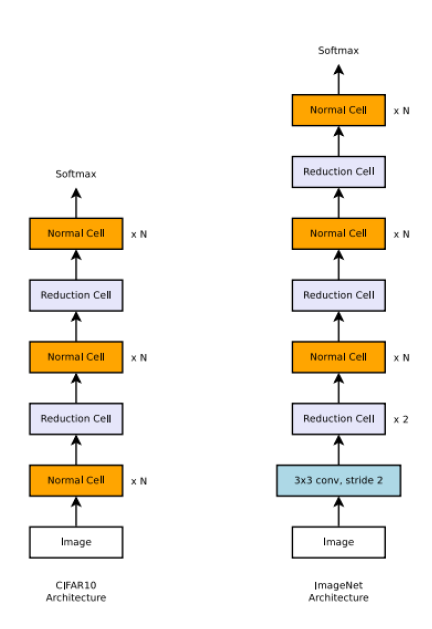
다음 설명드릴 내용은 이 논문의 정체성인 Transferability를 잘 보여주는 실험 결과입니다. 비교적 이미지 사이즈와 개수가 적은 CIFAR-10에서 찾은 Convolution Cell을 이용하여 ImageNet 데이터셋에서 학습을 수행하였을 때의 실험 결과를 보여주고 있습니다. 위의 그림을 보면 가장 첫 부분에 3x3 conv with stride=2 와 2개의 Reduction Cell을 넣어준 뒤에는 CIFAR-10의 구조를 그대로 사용하였으며 마지막 softmax에서 나오는 값이 10개에서 1000개로 바뀐 것이 차이입니다. 이렇게 CIFAR-10에서 찾은 Convolution Cell을 토대로 ImageNet을 위한 architecture를 구성해서 학습을 시켰을 때 성능이 어느 정도가 나올지 궁금할 수 있는데, 그 결과가 다음 단락에 제시되어 있습니다.
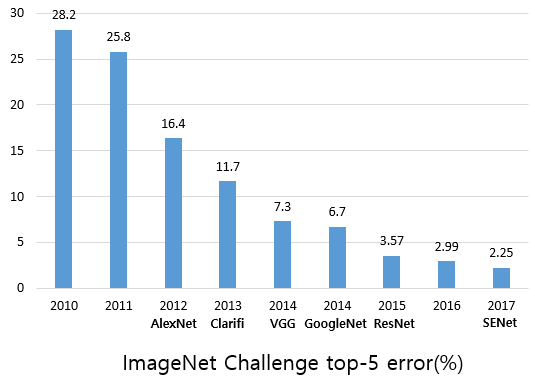
우선 ImageNet challenge에서 작년 우승을 거둔 SENet이 사람이 design한 network 중 ImageNet Challenge에서 가장 좋은 성능을 보인 State-Of-The-Art(SOTA)로 알려져 있었습니다. 이러한 network를 설계하는데 얼마나 많은 시간이 소요되었을 지 상상조차 하기 어려울 정도로 많은 노력과 시간이 투입되었을 것입니다. 이러한 ImageNet 데이터셋에 AutoML을 적용하려는 시도는 있었으나 결과를 제시한 경우는 없었습니다. CIFAR-10과 같이 작은 이미지에 대해서도 수백개의 GPU로 몇 달이 소요되는데, 훨씬 이미지도 크고 장수도 많은 ImageNet에서는 몇 달을 넘어서 몇 년 단위가 필요하기 때문입니다. 이 어려운 일을 NASNet에서 해냈습니다. 물론 결과도 가히 충격적이라 할 수 있습니다.
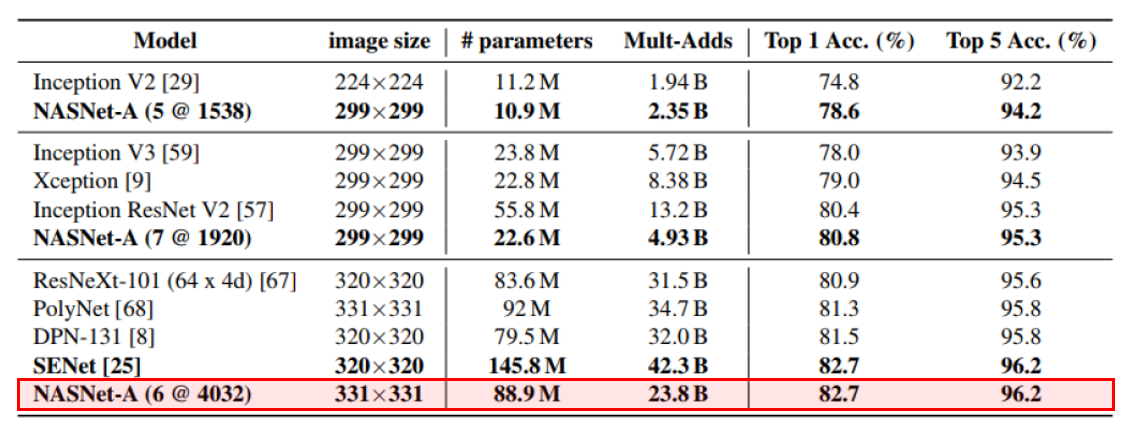
NASNet의 결과는 앞서 여러 번 말씀드렸듯이, ImageNet 데이터셋으로 최적의 network를 찾은 것도 아니고 단지 CIFAR-10에서 잘 되던 구조를 참고하여 network를 설계하여 ImageNet 데이터셋에 대해 성능을 측정한 것입니다. 하지만 작년 ImageNet competition에서 1위를 차지하고, 현존하는 network 중 가장 높은 성능을 보이는 SENet에 비해 훨씬 적은 수의 parameter를 사용하여 거의 같은 accuracy를 달성하였습니다.
또한 parameter 수를 조절하여도 기존에 주로 사용되던 Inception, Xception 등에 비해 더 적은 수의 parameter로 비슷하거나 더 높은 성능을 보이는 것을 확인할 수 있습니다. 저는 이 실험 결과를 보고 이제 image classification 분야에서는 사람이 network를 design할 필요가 없을 수도 있겠다고 느꼈습니다.
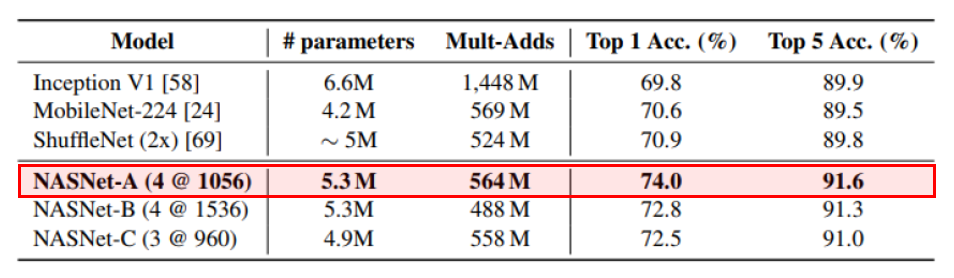
또한 mobile device를 target으로 한 여러 모델들과 비슷한 parameter 수를 사용하였을 때 ImageNet에 대해서 훨씬 높은 정확도를 보이는 것을 확인할 수 있습니다. 이 논문에서 주장하고 있는 Transferability를 잘 보여주고 있다고 생각합니다.
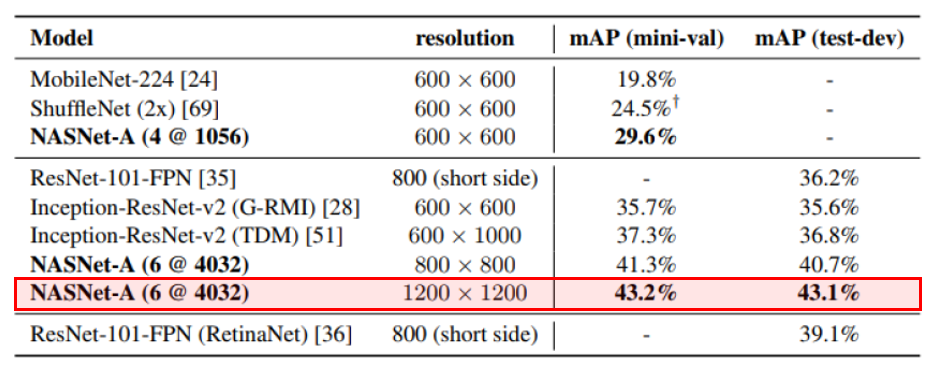
마지막으론 이 방법론을 Object detection에 적용하는 사례를 보여주고 있습니다. 앞서 ImageNet으로 학습시킨 NASNet-A의 backbone architecture를 Faster-RCNN 구조에 적용하였을 때의 실험 결과가 위의 표에 나와있습니다. 이 실험은 feature extractor 부분(backbone architecture)만 NASNet-A로 대체하고 뒤의 detection을 수행하는 부분은 그대로 사용한 환경에서 진행된 실험입니다.
실험 결과, mobile device를 target으로 한 모델들 보다 좋은 성능을 보였고, 성능이 좋다고 알려져 있는 RetinaNet 보다도 test-dev에서 측정한 mAP 값이 높은 것을 확인할 수 있습니다. 물론 이 결과에서는 parameter 수를 비슷하게 통제하지는 않은 것으로 보이지만, classification이 아닌 다른 task에 적용하여도 좋은 성능을 보일 수 있음을 증명하였습니다. 아직 object detection, segmentation 등 다른 task를 위한 architecture search는 진행되지 않았지만 조만간 적용하는 방법들이 나올 것으로 기대하고 있습니다.
후속 연구
NASNet이 공개된 뒤 여러 의미 있는 후속 연구들이 진행되었습니다. Architecture Search 분야에서는 본 논문의 저자가 포함되어 있는 연구진에서 많은 분들이 들어 보셨을 ENAS 라는 연구 결과를 제시하였으며, architecture search에 걸리는 시간을 획기적으로 줄였습니다. 1대의 GPU로 거의 하루만에 architecture를 찾을 수 있었으며 성능도 비교적 높게 측정되는 것을 확인할 수 있습니다.
Architecture Search 뿐만 아니라 비슷한 아이디어를 다양한 곳에 접목시킨 연구들도 나오고 있습니다. 최적의 Optimizer, Activation function 등을 AutoML을 이용하여 찾는 연구도 진행이 되었습니다. Optimizer를 다룬 논문 과 Activation function을 다룬 논문 도 전반적인 흐름은 기존 NAS 계열 연구와 유사하며 타겟만 architecture에서 optimizer, activation function 으로 바꾼 것으로, 쉽게 이해가 가능하실 것으로 생각됩니다. Activation function은 한 줄로 설명을 드리면 기존에 자주 사용하던 ReLU와 그 변형된 function 대신 Swish라는 이름을 가진 f(x)=x⋅sigmoid(βx) 함수를 AutoML을 통해 발견하였고, 이 함수를 사용하면 더 성능이 좋다고 설명을 하고 있습니다.
이 외에도 최근에는 augmentation에도 AutoML을 적용한 AutoAugment 논문 , Mobile device를 타겟으로 NAS를 적용한 MNASNet 논문 등 굉장히 다양한 연구들이 쏟아지고 있습니다. 이 논문들도 흥미로우니 관심이 있으신 분들은 확인하시면 좋을 것 같습니다.
결론
이번 포스팅에서는 AutoML에 대한 간략한 소개와 AutoML을 통해서 Architecture Search를 하는 연구에 대해서 소개를 드렸습니다. 또한 말미에는 최근 AutoML을 이용하여 진행되고 있는 여러 연구들에 대해 소개를 드렸습니다.
본 포스팅에서 다룬 NASNet은 다른 데이터셋에 transferable하다는 장점을 가지고 있으며, CIFAR-10에 대해 architecture search를 하는 과정엔 많은 GPU와 많은 시간이 소요되지만, 탐색하여 얻은 Convolution Cell을 조합하여 모델을 구축한다면 새로운 데이터셋에 대해서 재탐색을 하지 않아도 된다는 장점을 가지고 있습니다. 또한 이렇게 transfer를 하였을 때에도 높은 성능이 보장이 된다는 장점이 있어서 본 포스팅을 보신 분들은 각자의 데이터셋에 NASNet 구조를 이용해보시는 것을 추천 드립니다. 혹시 이 글을 보시다가 궁금한 점이 생기시거나 이해가 잘 되지 않는 부분이 있으면 댓글 남겨 주시면 감사하겠습니다! 정독해주셔서 감사합니다.
참고 문헌
- Keras-NASNet
- Neural Architecture Search with Reinforcement Learning 논문
- Learning Transferable Architectures for Scalable Image Recognition 논문
- Efficient Neural Architecture Search via Parameter Sharing 논문
- Neural Optimizer Search with Reinforcement Learning 논문
- Searching for Activation Functions 논문
- AutoAugment: Learning Augmentation Policies from Data 논문
- MnasNet: Platform-Aware Neural Architecture Search for Mobile 논문