NeurIPS 2018 image recognition paper list guide
안녕하세요, 이번 포스팅에서는 올해 12월 3일 ~ 8일 캐나다 몬트리올에서 개최된 저희에게는 NIPS로 잘 알려져있는 NeurIPS 2018 학회의 논문 중에 이미지 인식과 관련이 있는 논문 24편에 대해 제 주관적으로 리스트를 정리해보았습니다.
우선 전체 accepted paper가 1011 편이다보니 하나하나 읽어보는 것은 불가능하여서, 제가 제목만 보고 재미있을 것 같은 논문 위주로 정리를 해보았습니다. 당부드리는 말씀은 제가 정리한 논문 리스트에 없다고 재미 없거나 추천하지 않는 논문은 절대 아니고 단지 제 주관에 의해 정리된 것임을 강조드리고 싶습니다.
NeurIPS 2018 Paper Statistics
올해 NeurIPS 학회는 등록이 시작된지 1시간이 되지 않아서 마감이 될 만큼 굉장히 인기있는 학회였는데요, 그래서 제 주변에서도 가고 싶었는데 가지 못하는 경우를 봤습니다. 그만큼 인기가 높아진 학회인데요, 이 학회에는 매년 몇 편의 논문이 accept되는 지 조사를 해보았습니다.
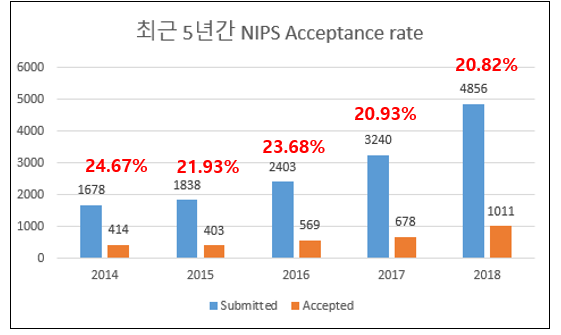
매년 제출되는 논문 편수도 증가하고 있고, 그에 따라서 accept되는 논문들의 편수도 증가를 하고 있습니다. 올해의 전체 제출된 논문은 5년전의 약 3배, 2년전의 약 2배로 굉장히 규모가 커진 것을 확인할 수 있습니다. 또한 약 20% 초반의 acceptance rate를 보이고 있는 것을 확인할 수 있습니다.
참고로 올해는 총 30편의 oral paper와 168편의 spotlight paper, 그리고 813편의 poster 총 1011편의 논문이 accept되었으며, 저는 오늘 그 중 24편의 논문을 소개드리고자 합니다.
Image Recognition 관련 논문 소개
앞서 말씀드렸듯이 1011편을 다 확인하기엔 시간과 체력이 부족하여서, 간단하게 제목만 보면서 제가 느끼기에 재미가 있을 것 같은 논문들을 추려보았습니다. 총 24편의 논문이며, 1편의 oral paper, 6편의 spotlight paper, 17편의 poster paper로 준비를 해보았습니다. 또한 각 논문마다 abstract를 읽고 논문을 간단히 정리해보았습니다.
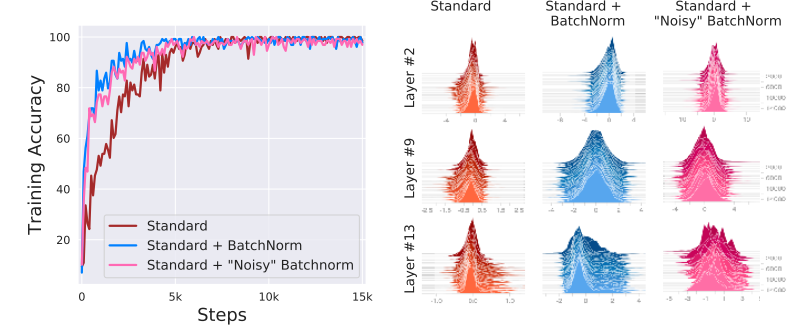
1. How Does Batch Normalization Help Optimization? (Oral)
- Batch normalization이 optimization을 잘 되게 해주는 이유를 분석한 논문. 일반적으로 알려져 있는 “internal covariate shift” 효과는 실제로는 미미하며, optimization landscape를 smooth하게 해주는 효과가 optimization에 큰 도움을 주고 있음을 증명함.
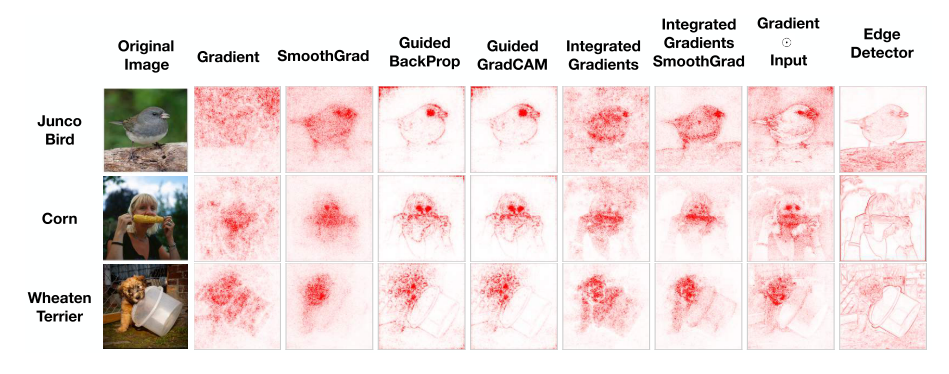
2. Sanity Checks for Saliency Maps (Spotlight)
- Saliency method들은 학습 결과와 관련이 있는 입력의 feature를 강조하는데 사용이 됨. 이러한 방식들이 좋은 지 나쁜 지 판단할 기준이 애매한데, 실험을 통해 saliency map의 온전성 검사를 하는 방식을 제안함.
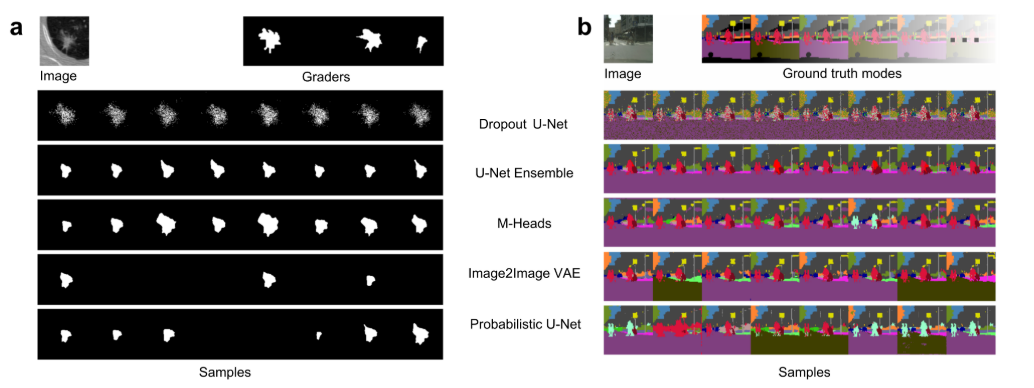
3. A Probabilistic U-Net for Segmentation of Ambiguous Images (Spotlight)
- 의료 영상 segmentation을 예로 들면, 사람마다 CT 영상을 보면서 암 조직을 labeling할 때(Ground Truth를 제작할 때) 의견이 다를 수 있음. 이러한 애매한 이미지에 대해 학습과 예측이 가능한 Probabilistic U-Net 구조를 제안함.
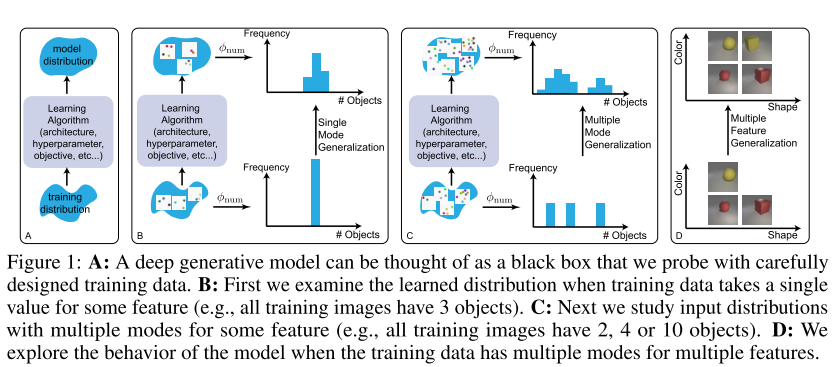
4. Bias and Generalization in Deep Generative Models: An Empirical Study (Spotlight)
- 이미지와 관련된 Deep generative model의 bias와 generalization을 추론하는 방법을 제안함. 인지 심리학적인 실험 방법들을 통해 잘 design된 학습 데이터를 이용하면 각 feature마다 구별되는 generalization pattern들을 찾을 수 있다고 설명함.
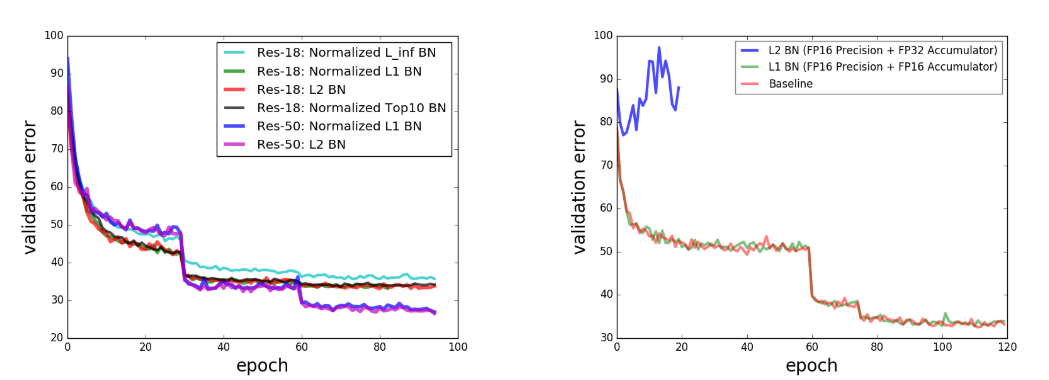
5. Norm matters: efficient and accurate normalization schemes in deep network (Spotlight)
- Deep network에서 흔히 사용되는 normalization의 목적과 기능에 대해 분석을 진행하였음. 이를 통해 normalization, weight decay, learning rate adjustment간의 연결을 강조함. 또한 새로운 batch normalization 기법을 제안하며 기존 batch normalization의 절반의 floating point precision으로 동등한 성능을 낼 수 있음을 보임. 또한 bounded weight normalization이라는 방법도 제안함.
6. GILBO: One Metric to Measure Them All (Spotlight)
- GAN, VAE와 같은 latent variable generative model들의 joint generative density에 포함된 mutual information의 lower bound(Generative Information Lower BOund, GILBO)를 제안함. 이는 data-independent measure를 제공하며, generative model을 평가하기 위한 새로운 metric으로 사용할 수 있음. 본 논문에서는 3200개의 generative model에 대해 실험을 진행함.

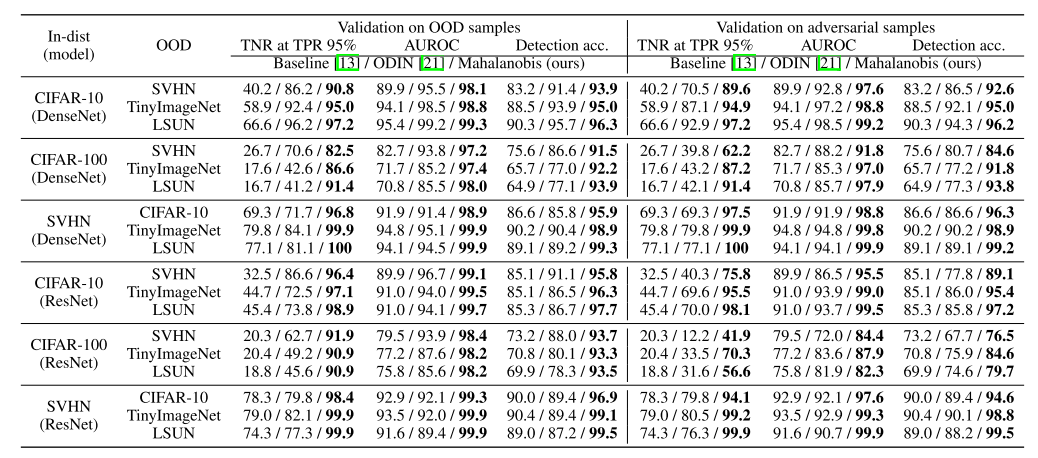
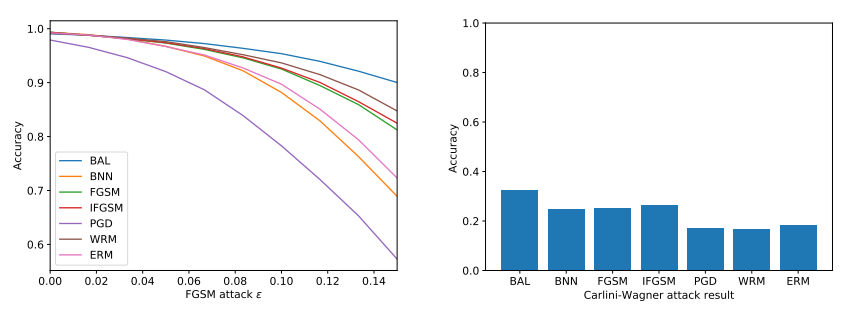
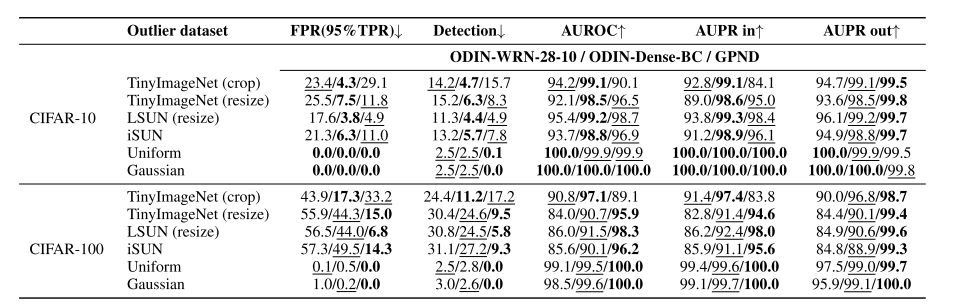
7. A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks (Spotlight)
- 학습 데이터의 분포와 동떨어진 test sample을 찾는 과정을 Out-of-Distribution detection 이라 부름. 하지만 deep neural network의 softmax를 사용하는 classifier는 out-of-distribution sample에 대해서도 highly confident한 예측을 하는 문제가 있음. 이를 해결하기 위한 간단하면서 효과적인 방법을 제안하며, 기존 pre-trained softmax classifier에 적용이 가능한 장점이 있음. 또한 adversarial attack을 detect하는데도 적용이 가능하고, class incremental learning에도 적용이 가능함.
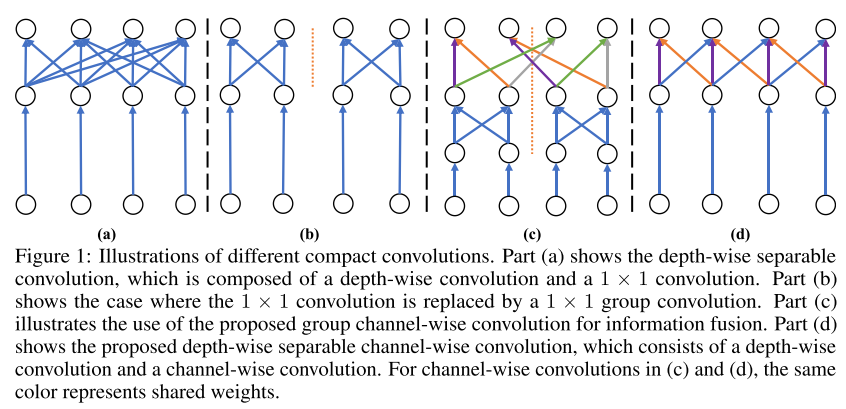
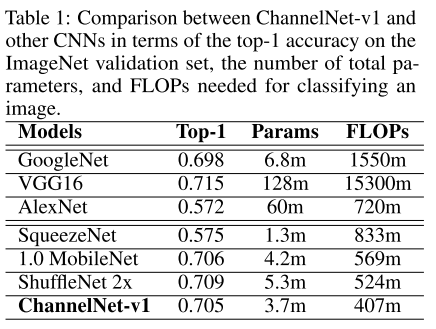
8. ChannelNets: Compact and Efficient Convolutional Neural Networks via Channel-Wise Convolutions
- Architecture 경량화를 위한 Channel-wise convolution을 제안함. Mobile Device를 타겟으로 한 선행 연구들과 비교하였을 때 가장 빠른 처리 속도로 동등한 성능을 달성함.
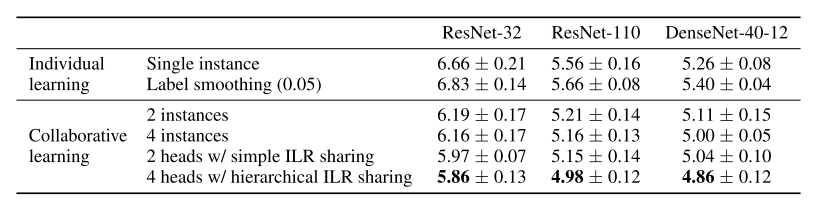
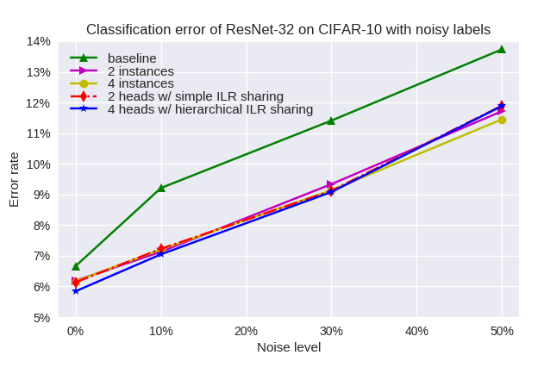
9. Collaborative Learning for Deep Neural Networks
- 같은 네트워크 여러 개를 이용하여 같은 학습 데이터에 대해 학습을 시켜서 일반화 성능을 높이고 label noise에 강인한 Collaborative Learning 방법을 제안함.
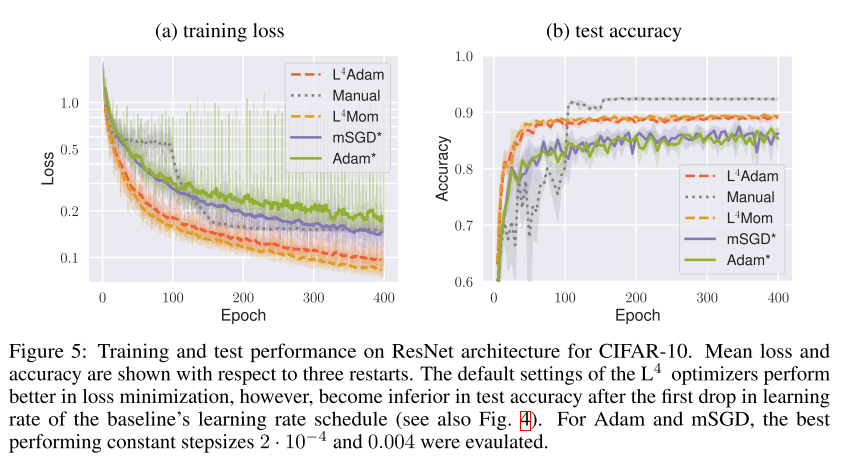
10. L4: Practical loss-based stepsize adaptation for deep learning
- Practical loss 기반 SGD의 step size adaptation 방식을 제안함. 이름의 L4는 Linearized Loss-based optimaL Learning-rate를 의미.
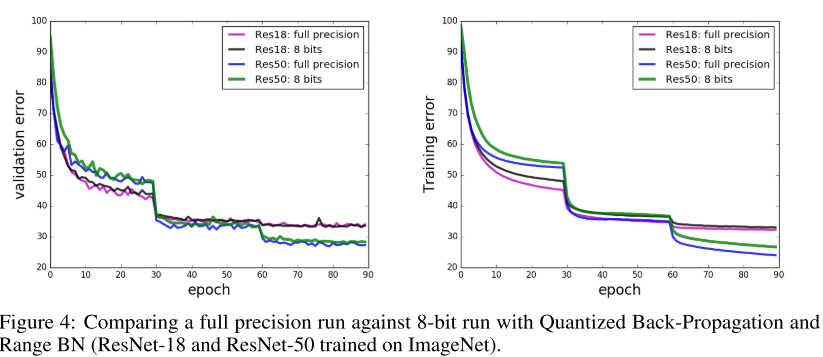
11. Scalable Methods for 8-bit Training of Neural Networks
- Quantized Neural Network를 타겟으로, 8-bit precision으로 Neural Network를 학습하는 방법을 제안함. 또한 batch-normalization은 높은 bit precision에서 학습해야 하는 문제를 Range Batch-Normalization을 고안하여 개선시킴.
12. Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
- Computer Vision task에서 이미지에 약간의 perturbation을 줘서 model이 잘못된 판단을 하도록 하는 adversarial attack에 대한 논문이며, 과연 사람(Time-Limited)도 adversarial attack에 취약한지에 대해 실험을 한 논문임.

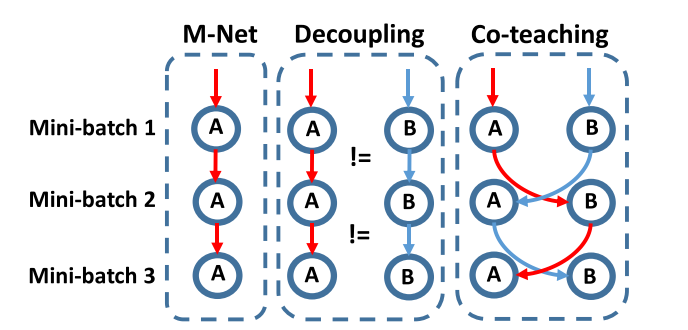
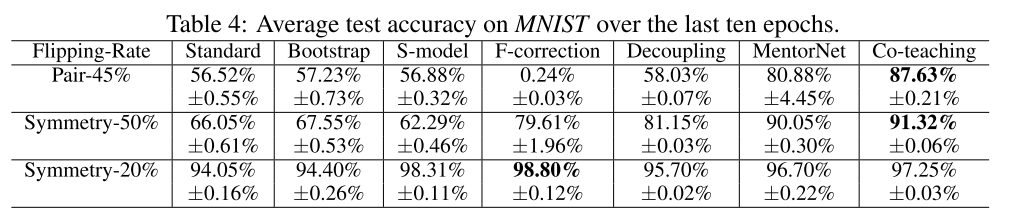
13. Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels
- Extremely noisy label이 존재하는 상황에서 강인한 classifier를 학습시키는 Co-teaching이란 방법론 제안. 두개의 신경망을 동시에 학습시키며 서로가 서로의 선생 역할을 수행하여 Co-teaching이라고 부름.
14. Deep Anomaly Detection Using Geometric Transformations
- 오로지 Normal Class만 이용하여 model을 학습한 뒤, anomaly 이미지를 검출하는 방법을 제안함. Normal 이미지에 geometric transformation을 주어 학습을 시킴.

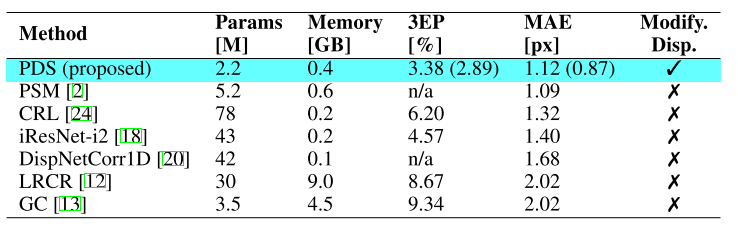
15. Practical Deep Stereo (PDS): Toward applications-friendly deep stereo matching.
- 현존하는 end-to-end deep learning stereo matching 알고리즘은 실생활에 적용하기에 어려움이 있음(메모리가 많이 필요하고, 주어진 disparity range에 대해서 학습이 되어야 함). 이를 해결하기 위한 실용적인 stereo matching 알고리즘을 제안함.

16. Bayesian Adversarial Learning
- Adversarial attack에 강인한 Bayesian robust learning 방법을 제안함.
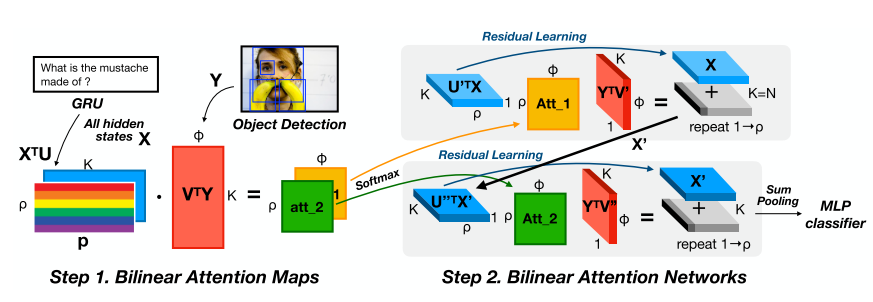
17. Bilinear Attention Networks
- Multimodal learning에서 attention network가 좋은 성능을 보여주지만 각 multimodal input pair에 대해 attention distribution을 학습하는 데 많은 연산량을 필요로 하는 문제를 해결하기 위해 bilinear attention network를 제안함. VQA 데이터셋과 sentence-based image description 데이터셋에 대해 좋은 성능을 달성함.
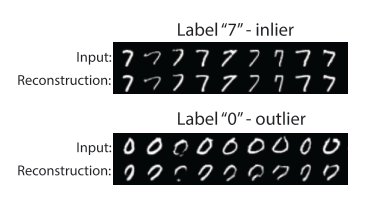
18. Generative Probabilistic Novelty Detection with Adversarial Autoencoders
- Novelty detection을 위한 Generative Probabilistic Adversarial Autoencoder를 제안함.
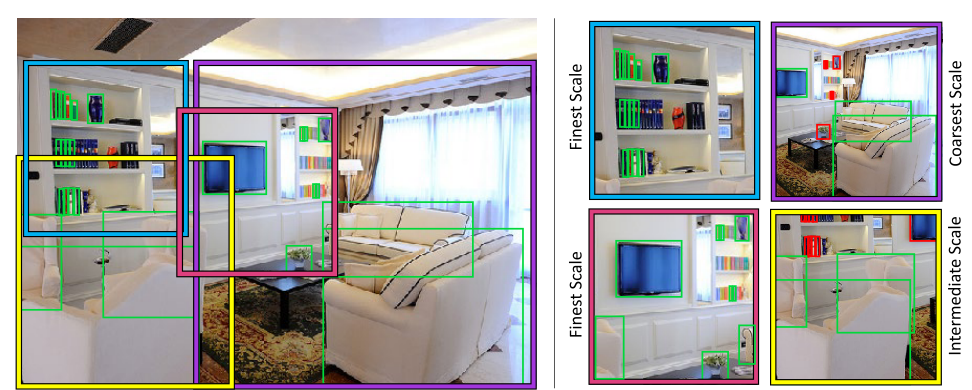
19. SNIPER: Efficient Multi-Scale Training
- Instance level visual recognition task(ex, Object Detection)에서 효율적인 multi-scale training에 대한 알고리즘을 제안함. Context-region 기반으로 scene의 복잡도에 따라 차등적으로 학습을 수행하고, 고해상도 이미지에 대해 효율적으로 학습하는 방법을 제안함.
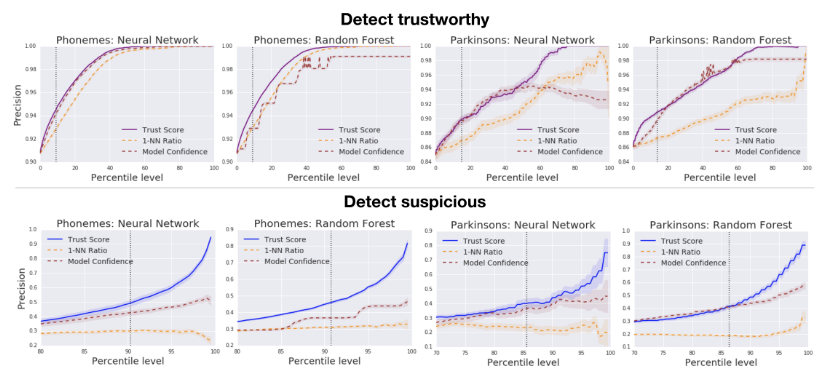
20. To Trust Or Not To Trust A Classifier
- Classifier의 prediction이 믿을 만한지를 아는 것은 굉장히 중요한 문제임. 이를 위해 “trust score”라는 새로운 scoring 방식을 제안함. 기존의 classifier의 confidence score보다 더 정확한 정보를 얻을 수 있음.
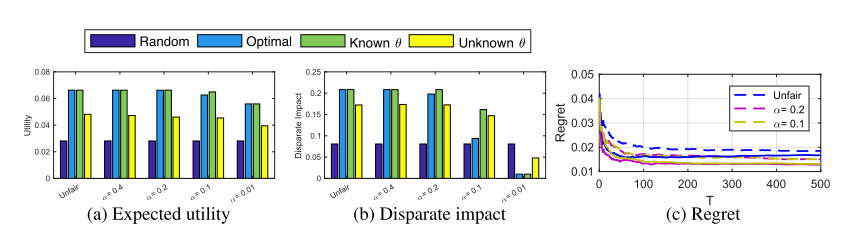
21. Enhancing the Accuracy and Fairness of Human Decision Making
- 우리가 살아가는 사회에서는 종종 일련의 전문가들에 의해 의사 결정을 내리는 순간이 있음. (ex, 재판, 논문 accept or reject 등) 하지만 이러한 결정에는 제한된 경험, 암묵적인 편향, 잘못된 추론 등으로 인해 불완전한 결정이 내려질 수 있음. 이러한 의사 결정의 정확성과 공정성을 높이기 위한 방법을 제안함.
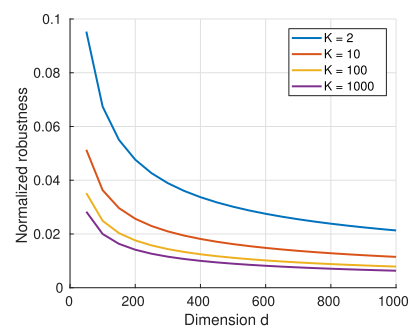
22. Adversarial vulnerability for any classifier
- SOTA classifier들은 adversarial attack에 취약한 약점을 가지고 있고 극복하는 것이 굉장히 까다롭다고 알려져 있음. 본 논문에서는 모든 classifier에 대해 adversarial perturbation의 robustness의 upper bound를 도출하고, 다른 classifier에 잘 transfer되는 adversarial perturbation의 존재를 증명함.
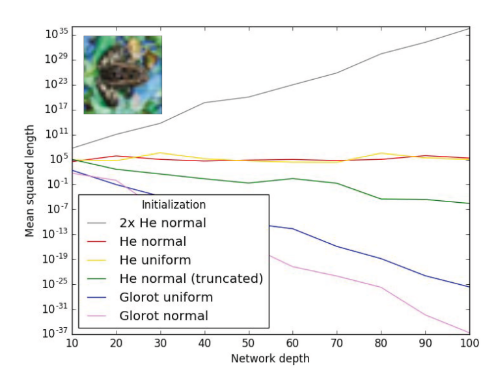
23. How to Start Training: The Effect of Initialization and Architecture
- Deep ReLU net을 학습시킬 때 발생하는 흔한 두가지 실패 유형 (exploding or vanishing mean activation length, exponentially large variance of activation length)에 대해 분석을 진행함. 또한 이를 해결하기 위한 올바른 initialization과 architecture 선정을 실험적으로 증명함.
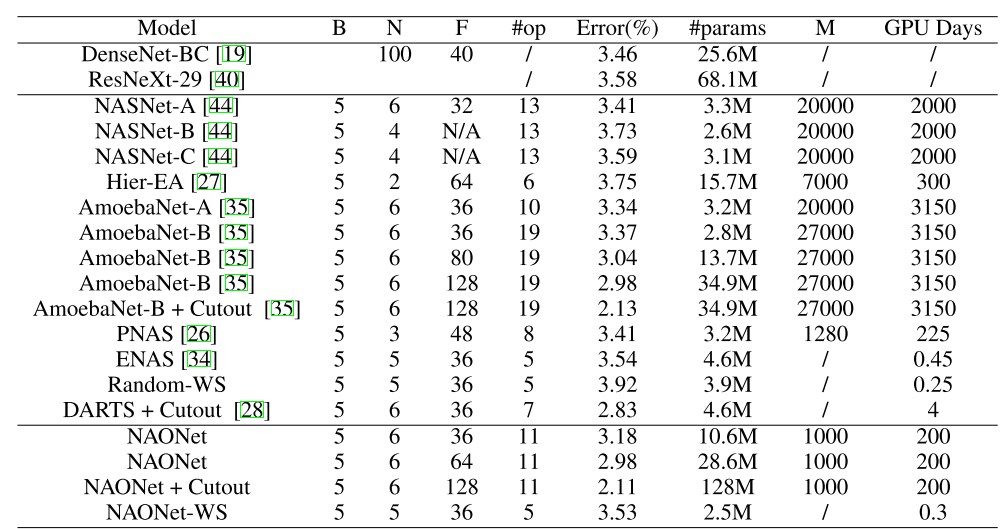
24. Neural Architecture Optimization
- 기존의 architecture search 방식은 discrete space에서 search를 하여서 비효율적이었음. 이를 개선하기 위해 간단하면서 효율적인 continuous optimization에 기반한 architecture search NAO(Neural Architecture Optimization) 방식을 제안함. 학습에 적은 시간이 소요되면서도 정확한 architecture를 찾는 것을 증명함.
결론
이번 포스팅에서는 올해 NeurIPS 2018에 accept된 논문 중에 이미지 인식 분야와 관련있는 24편에 대해 정리를 해보았습니다. 제가 정리한 논문 외에도 양질의 논문들이 많이 있으니 관심있으신 분들은 다른 논문들도 읽어보시고, 추천을 해주시면 감사하겠습니다!
앞으로도 관심있는 학회에 대해서 이렇게 논문 리스트를 정리할 예정이며 피드백을 주시면 반영을 하도록 하겠습니다. 또한 다녀온 학회에 대한 리뷰도 시간이 되는대로 작성을 하도록 하겠습니다. 감사합니다.
참고 문헌