Averaging Weights Leads to Wider Optima and Better Generalization 리뷰
안녕하세요, 오늘은 2018년 UAI 학회에서 발표된 “Averaging Weights Leads to Wider Optima and Better Generalization” 논문을 리뷰할 예정입니다. 이 논문에서 제안한 방법인 Stochastic Weight Averaging(이하 SWA)는 딥러닝 모델의 일반화 성능을 높여주는 간단한 기법이며, PyTorch 1.6 버전에서 공식적으로 지원하게 되었습니다. 방법이 단순한데 꽤 효과적이어서 강력 추천드리며, PyTorch를 이용한 Tutorial은 다음 글에서 자세히 다루겠습니다.
Related Works
이 논문을 설명 드리기 앞서, 이 논문이 작성되기 이전에 다뤄졌던 관련 연구들을 먼저 짤막하게 소개드리고 시작하겠습니다. 우선 deep neural network는 기본적으로 여러 layer를 쌓는 구조를 택하는데, 이러한 multilayer network의 loss surface를 분석하려는 연구들이 진행되어왔고, 이를 이용해 학습이 빨리 수렴하는 방법, 학습 안정성을 높이는 방법, test set에 대한 정확도를 높이는 방법 등 다양한 연구들이 진행되어왔습니다.
이 논문에서는 언급하지 않았지만, 대표적으로 2018 NeurIPS에서 발표된 “How does batch normalization help optimization” 논문이 loss surface 분석을 통해 Batch Normalization이 어떻게 학습에 도움을 주는지를 이론적, 실험적으로 접근하였습니다. 이 논문을 리뷰한 발표 자료 도 같이 보시면 좋을 것 같습니다.
또한 마찬가지로 2018 NeurIPS에서 발표된 “Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs” 논문에서는 Stochastic Gradient Descent(이하, SGD)에 의해 발견된 local optima가 간단한 상수의 loss의 curve로 연결된다는 것을 밝혔습니다.

이러한 관찰에서 Insight를 얻어서 해당 논문에서 Fast Geometric Ensembling(이하, FGE) 방법을 제안하였습니다. 이 방법은 하나의 DNN을 학습시킬 때 weight space에 위치한 여러 인접한 point들을 sampling하여 ensemble하는 기법을 제안하였으며, 비슷한 방법으로는 선행 연구인 “Snapshot ensembles: Train 1, get m for free”, 2017 ICLR 이 있습니다.
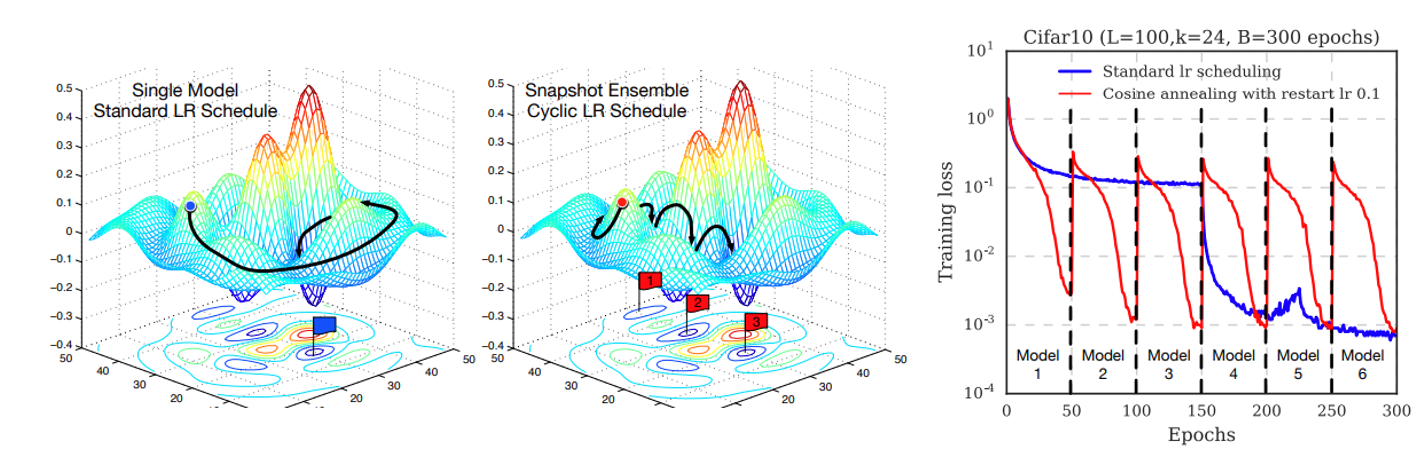
위의 그림은 Snapshot ensemble을 한장으로 설명하는 그림입니다. 이제는 대세로 자리잡은 Cosine Annealing Learning Rate Scheduling에 restart를 주는 Cyclic Cosine Annealing을 통해 일정 주기마다 Learning Rate를 다시 크게 키워주면서, 해당 지점의 모델을 저장합니다. 작은 Learning Rate로 미세하게 수렴을 하다가 갑자기 Learning Rate가 커지면 loss surface에서 크게 벗어난 지점으로 껑충 뛰게 되겠죠? 이러한 방식을 통해 시간 축으로 각기 다른 특징을 갖는 모델을 한 번의 학습으로 얻을 수 있게 됩니다.
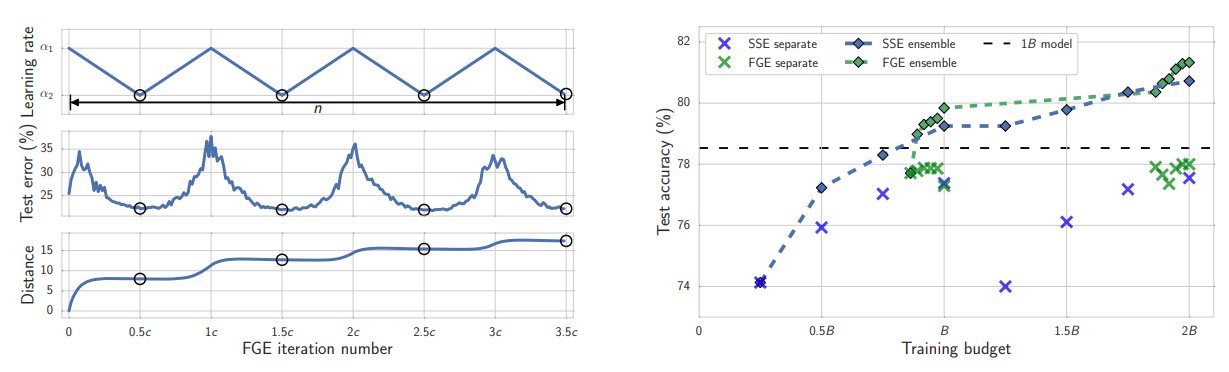
FGE는 Snapshot Ensemble과 아이디어는 비슷하지만 다른 특징을 가지고 있습니다. 우선, Cyclic Cosine Annealing 대신 piecewise linear cyclical learning rate 기법(위의 그림의 왼쪽)을 사용하였고, cycle의 주기도 Snapshot Ensemble(SSE)보다 훨씬 짧게 가져갑니다. 그래도 좋은 성능을 보일 수 있었고, 실제로도 Snapshot Ensemble보다 더 빨리 좋은 모델을 찾고, 더 높은 test accuracy를 달성하게 됩니다.
Stochastic Weight Averaging (SWA)
자 이제 본격적으로 오늘의 논문에서 제안한 기법인 Stochastic Weight Averaging (SWA)를 설명 드리겠습니다. 시간 축으로 모델을 Ensemble하는 아이디어는 그대로 가져오는데, 선행 연구인 FGE와의 가장 큰 차이점은 모델의 weight를 시간 축으로 여러 개 저장하는 대신 모델의 weight를 시간 축으로 누적(running average)시킨다는 점이며, 이를 통해 여러 이점을 누릴 수 있습니다. 우선, 성능도 좋아지는데 가장 큰 차이는, FGE는 모델의 weight를 k개 저장한 뒤, k번 inference를 하여 prediction 값들을 ensemble해야하는 반면, SWA는 하나의 모델 weight만 저장하였기 때문에 computational overhead가 거의 없습니다.
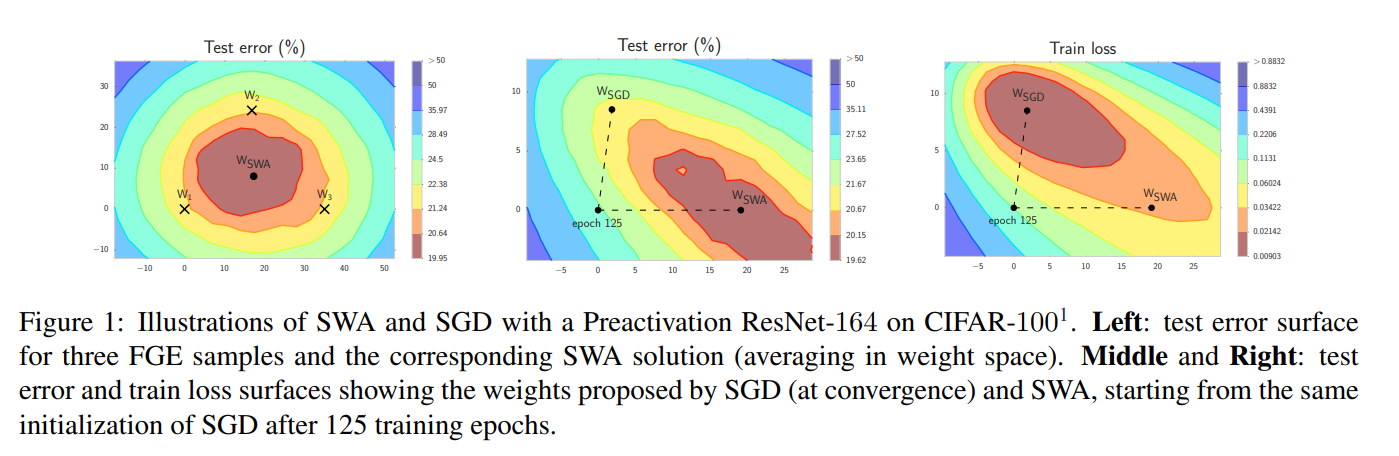
이 그림이 loss surface 상에서 FGE와 SWA의 차이를 잘 보여주고 있는데요, 왼쪽 그림은 3개의 FGE sample weight의 test error와 1개의 SWA weight의 test error를 나타낸 것입니다. FGE를 통해 학습된 weight들은 주로 optimal solution의 가장 자리 쪽에 위치하는 경향을 보이는데, 이렇게 weight space 상에서 3개의 weight를 합쳐버리면 test error 가 더 낮은 surface에 위치할 수 있겠죠? 실제로 저 3개의 weight 들을 평균내면 SWA의 weight와 거의 비슷한 지점에 위치하게 됩니다. 또한 SGD와 비교를 했을 때, SGD가 train loss는 더 낮았지만, 실제로 중요한 test error는 SWA가 더 낮은 것을 확인할 수 있습니다. 또한 SGD는 여러 연구 결과를 통해 optimal point 근처의 넓고 평평한 region의 경계에 수렴하는 특징을 가지고 있는데, SWA를 통해 weight들을 averaging 시키면, SGD로는 갈 수 없었던 optimal point에 진입할 수 있게 해주는 효과를 볼 수 있다고 합니다.

SWA의 알고리즘은 위와 같은 pseudo code로 나타낼 수 있으며 굉장히 단순합니다. 기존 학습 과정과 비교했을 때, SWA의 시간과 메모리 overhead는 거의 무시할 만한 수준입니다. 추가되는 메모리 소모량은 DNN weights의 running average를 저장할 때 발생하는 데, 전체 학습 과정에서 대부분의 메모리 사용량은 weight 보다는 activation을 저장할 때 발생합니다. 즉, DNN weight의 running average를 저장하는 과정은 웃으면서 넘길 수 있는 수준이고 많아야 10% 정도 메모리를 더 사용한다고 합니다.

또한 기존 방식과 비교했을 때, 매 iteration 마다 aggregated weight average를 계산하는 연산 1개만 더 추가되고, 기존 DNN의 weight와 새로 계산한 DNN의 weight를 weight sum 해주면 되기 때문에 학습 시간도 거의 무시할 만한 수준으로 증가합니다.
이 외에도 local optimum의 width가 SGD보다 SWA를 사용할 때 더 커진다는 분석 (3.4), SWA과 Ensemble의 관계에 대한 분석 (3.5), SWA와 Convex Minimization의 관계에 대한 분석 (3.6) 도 논문에 자세히 서술되어 있으니 관심 있으신 분들은 읽어 보시는 것을 추천 드립니다. 내용이 쉽진 않습니다..
실험 결과 및 Discussion
이제 실험 결과에 대해 설명 드리겠습니다. 우선 CIFAR-10, CIFAR-100, ImageNet 데이터셋을 사용하였고, SGD와 FGE과 성능을 비교하였습니다.
Conventional SGD training은 일반적인 learning rate decaying scheduling을 사용하였으며, 구체적으로는 전체 학습이 B epoch인 경우에 0 ~ 0.5B epoch 구간은 고정된 learning rate 값을 사용하고, 0.5B ~ 0.9B 구간에서는 0.01 * learning rate만큼 linear 하게 감소시키고, 마지막으로 0.9B ~ 1B epoch 구간에서는 0.01 * learning rate 값을 고정시켜서 학습을 시켰다고 합니다.
FGE와 SWA는 SGD에서 사용한 전체 epoch 값인 B를 Budget 이라고 정의한 뒤, 1 Budget으로 학습을 시켜서 얻은 모델의 test accuracy를 측정하였습니다. 또한 SWA에서는 Budget을 1.25, 1.5로 올려서 실험을 하였으며, Budget을 키워주면 성능이 좋아지는 경향을 보입니다.
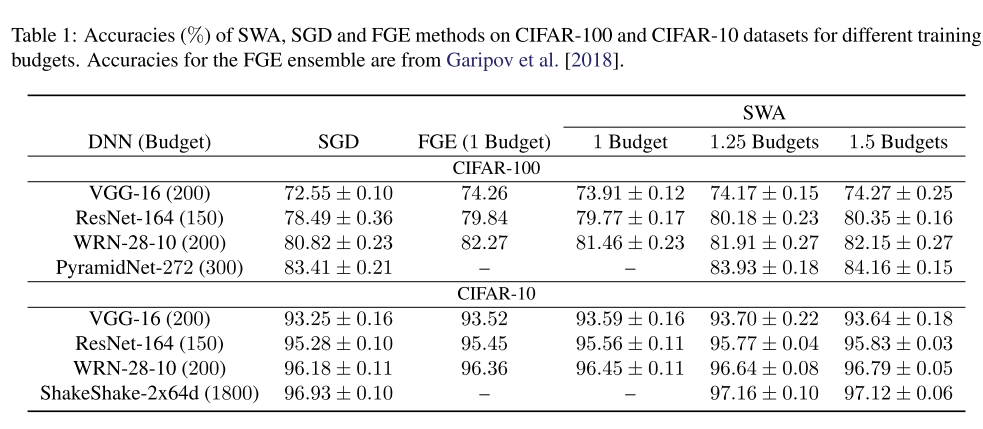
위의 표는 CIFAR-10, CIFAR-100의 실험 결과이며, 모든 CNN 모델에 대해 3번 반복 실험을 하여 평균, 표준편차를 계산하여 나타냈습니다. 실험 결과 SWA가 모든 경우에서 SGD보다 좋은 성능을 보였고, 1 Budget에서는 CIFAR-100에서는 FGE가 더 좋은 성능을 보였지만, Budget을 키워주면 비슷한 성능을 얻을 수 있었고, CIFAR-10에서는 1 Budget에서도 SWA가 더 좋은 성능을 달성할 수 있었습니다. FGE는 모델을 여러 개 저장하여 Ensemble하는 반면, SWA는 하나의 모델만 저장하여 Prediction을 하는 방식이니, 더 적은 계산량으로 더 높은 정확도를 달성할 수 있어서 큰 의미가 있는 것 같습니다.
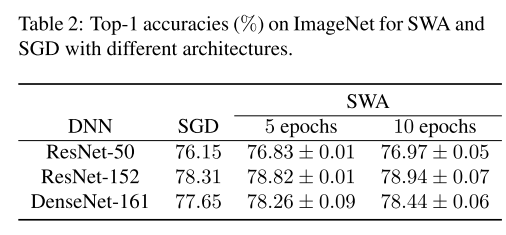
ImageNet 데이터셋에서도 SWA가 SGD보다 우수한 성능을 보이는 것을 확인할 수 있습니다.
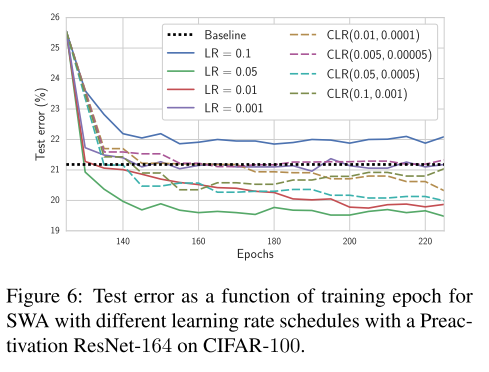
이번에는 learning rate scheduling에 따른 SWA의 성능 변화를 측정하는 실험을 수행하였습니다. 모델은 Preact-ResNet-164, 데이터셋은 CIFAR-100을 사용하였고, conventional SGD로 125 epoch 학습시킨 모델의 weight로 weight를 initialization 한 뒤 실험을 시작하였다고 합니다. 위의 그림의 점선은 conventional SGD로 150 epoch을 돌려서 얻은 결과입니다.
실험은 Constant Learning Rate Schedule 4가지 값, Cyclical Learning Rate Schedule 4가지 값을 사용하였고 대체로 Constant Learning Rate Schedule을 사용하면 더 빨리 수렴하는 경향을 보였고, Test error도 더 낮은 것을 확인할 수 있습니다. 즉, 굳이 선행 연구들에서 사용했던 Cyclical Learning Rate Schedule 방식을 굳이 사용하지 않아도 좋은 성능을 낼 수 있다는 뜻입니다. 이러면 Cycle length라는 hyper parameter를 하나 줄일 수 있다는 장점이 생깁니다.
저자들은 이러한 발견에서 나아가서, 아예 DNN 모델을 learning rate scheduling 없이 고정된 값으로scratch로부터 학습시킬 수 있을지 실험을 수행하였습니다. 이번엔 Wide ResNet-28-10에 CIFAR100을 이용하여 실험하였고, 0.05 learning rate로 300 epoch을 학습하였습니다.
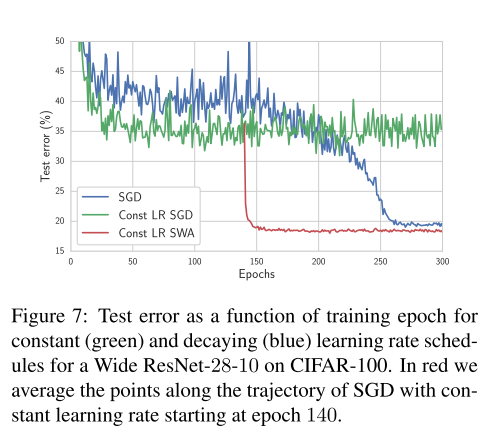
SWA는 SGD의 140 epoch 지점부터 300 epoch 지점까지의 weight를 average하였고, 실험 결과 constant learning rate scheduling을 하였을 때의 SGD(초록 선), decaying learning rate scheduling을 하였을 때의 SGD(파란선)보다 constant learning rate scheduling + SWA를 사용하였을 때 더 빠르게 수렴하고 더 낮은 test error를 보이는 것을 확인할 수 있습니다.
Constant learning rate scheduling을 이용하면 SGD는 oscillate하는 반면 SWA는 원활하게 학습이 되는 것을 관찰할 수 있습니다. 저자들은 말미에 실용적인 관점에서 SWA를 사용할 때, 이 실험과 같이 초반 부분은 conventional한 training을 통해 학습을 시킨 뒤, 중간 지점부터 SWA를 사용하는 것이, 처음부터 SWA를 사용하는 것보다 더 빠르고 더 안정적으로 학습을 시킬 수 있다고 안내하고 있습니다.
결론
오늘은 2018년 UAI 학회에서 발표된 “Averaging Weights Leads to Wider Optima and Better Generalization” 논문을 간단히 리뷰하였는데요, Ensemble 느낌이 나지만 엄밀하게는 Ensemble은 아니고, Single Model을 사용하는 기법이며, 단순하지만 매우 효과적이어서 현업이나 Kaggle 등에서 자주 사용될 수 있을 것으로 생각됩니다. 또한 구현이 그렇게 어렵지 않고, PyTorch에서는 이제 공식적으로 지원하는 만큼 독자 여러분들도 한 번쯤 살펴보시는 것을 권장 드리고, 다음 글에서는 PyTorch의 SWA 기능을 살펴보는 Tutorial 글로 찾아 뵙겠습니다. 긴 글 읽어 주셔서 감사합니다.