Tutorials of Object Detection using Deep Learning [2] First Object Detection using Deep Learning
안녕하세요, Tutorials of Object Detection using Deep Learning 두번째 포스팅입니다. 이번 포스팅에서는 소제목에도 나와있듯이 Deep Learning을 이용한 최초의 Object detection 방법론에 대해 설명을 드리고, 대표적인 연구 방향에 대해 다룰 예정입니다. 이전 포스팅들은 다음과 같습니다.
Tutorials of Object Detection using Deep Learning: [1] What is object detection
First Object Detection using Deep Learning
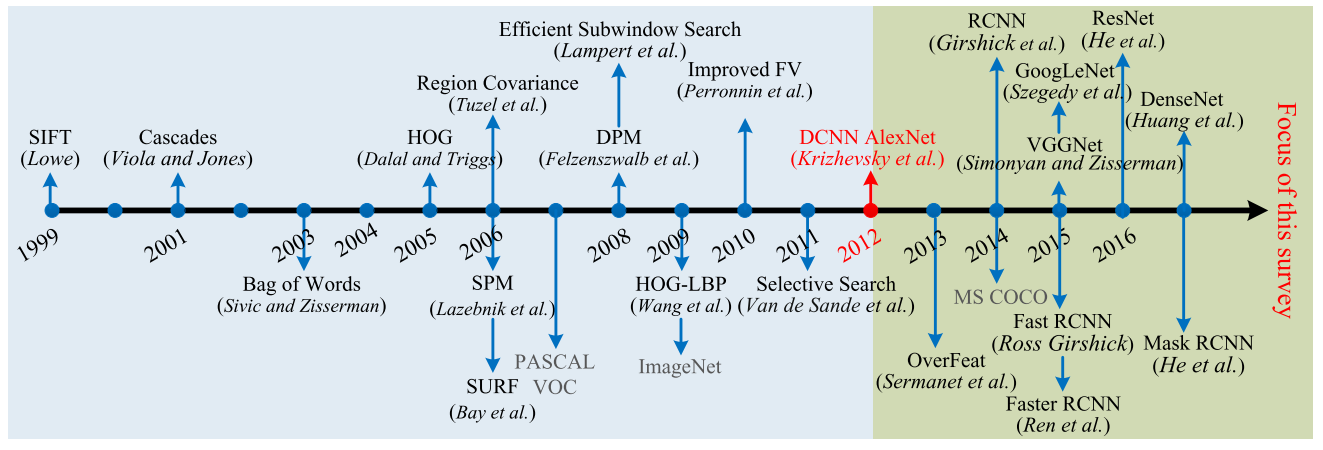
앞선 포스팅에서도 인용했던 그림을 보면 2012년 AlexNet 이후 Object detection에서도 Deep Learning을 이용하기 시작한 것을 확인할 수 있습니다. 이 그림에서는 OverFeat이라는 방법론을 최초의 방법론이라 설명하고 있지만, 다른 자료들에서는 R-CNN을 최초의 방법론이라 설명하고 있습니다. 공부를 하는 입장에서 굉장히 혼란스러울 수 있는데, 한 번 정리해보겠습니다.
우선 OverFeat에 대해 간단하게 설명을 드리겠습니다. OverFeat은 2013년 열린 ImageNet 대회인 ILSVRC2013에서 Object Localization 부문에서 1위를 차지하였고, Object Detection 부문에서는 3위를 차지한 방법론입니다. Object Localization은 Object Detection에 비해 쉬운 task이며 이미지 당 하나의 object에 대해 bounding box를 얻는 문제를 의미합니다.
OverFeat은 Object Localization 문제를 풀기 위해 제안된 방법이며, 같은 아이디어를 Object Detection에도 적용하였고, 꽤 높은 성능을 보여서 주목을 얻게 되었습니다. 또한 ILSVRC2013이 끝난 뒤에 추가로 연구를 하여, ILSVRC2013 대회의 우승자보다 높은 Object Detection 성능을 얻는데 성공을 하게 됩니다. 그래서 많은 주목을 받게 됩니다.
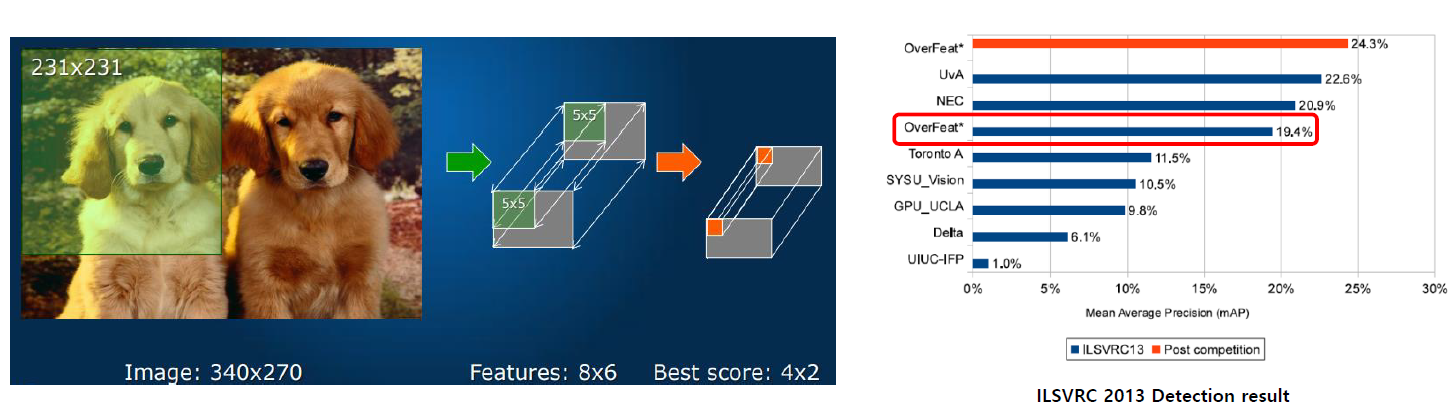
OverFeat은 arXiv 기준 2013년 12월 21일에 처음 업로드 되었으며, ImageNet 대회에서 Classification이 아닌 다른 분야에 처음으로 CNN을 적용한 방법론입니다. 이러한 이유로 Deep Learning, 그 중에서도 CNN을 이용한 최초의 Object Detection 논문이라고 알려져 있습니다.
하지만 arXiv 기준으로 보면 OverFeat보다 한달 일찍 R-CNN 논문이 업로드가 된 것을 확인할 수 있습니다. (2013년 12월 21일 vs 2013년 11월 11일)
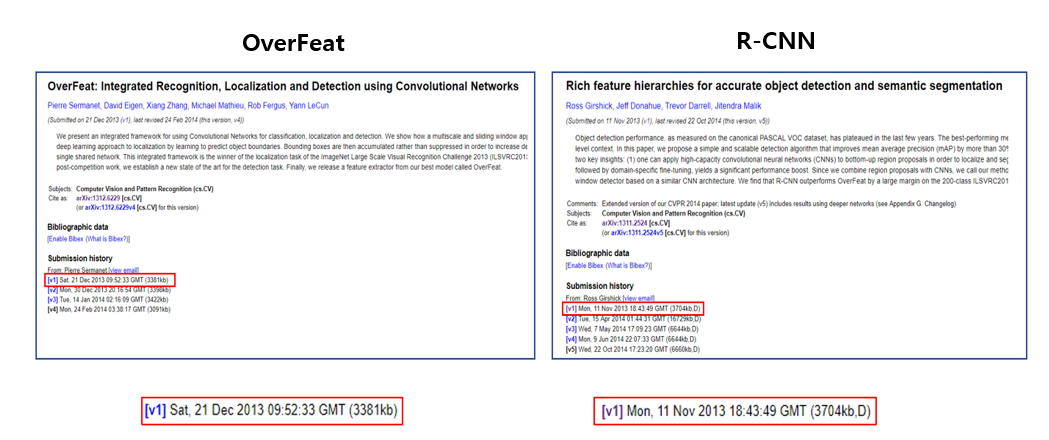
이러한 점들로 비추어 봤을 때, R-CNN이 한 달 먼저 나온 방법론이고, ImageNet 대회에 참석하지 않아서 주목을 먼저 받지 못한 것으로 판단이 됩니다. 또한 재미있는 점은, OverFeat과 마찬가지로 ILSVRC2013이 끝난 뒤에 R-CNN도 성능을 측정하였는데, 이 Object Detection 성능이 OverFeat의 성능을 압도하게 되며 큰 주목을 얻게 됩니다.
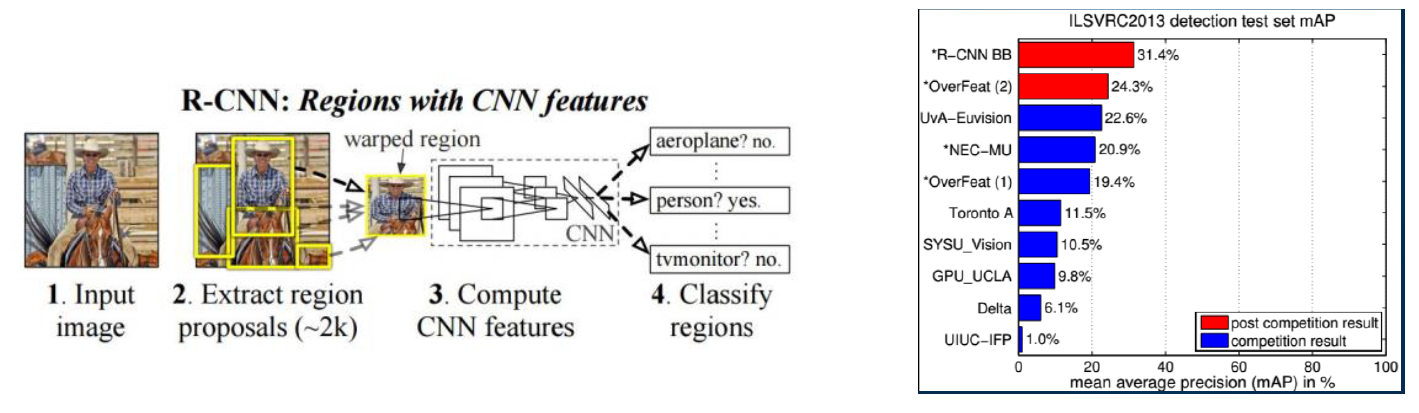
R-CNN에 대해 간단하게 설명 드리면 Object Detection에 CNN을 적용한 첫 논문이며, 이전 포스팅에서 설명한 Selective Search와 CNN을 결합한 방법론입니다.
우선 input image가 있으면 Selective Search를 통해 Region Proposal을 수행합니다. 그 뒤, Proposal된 영역들을 CNN의 고정 사이즈를 가지는 입력으로 변환시키고, 각 영역마다 Classification을 수행하는 방식으로 되어있습니다. 예를 들어 1000개의 Region이 Proposal된 경우에는 CNN에서 1000번의 Classification이 수행되는 것입니다. 또한 Proposal된 Region에서 실제 object의 위치와 가까워지도록 보정해주는 Regression도 수행이 됩니다.
이 방법론이 Deep Learning을 이용한 Object Detection의 시초가 되는 방법이라 해도 과언이 아닐 정도로, 굉장히 큰 영향력을 가지고 있습니다. Object Detection을 공부하시는 분들이라면 필수로 읽어야 할 논문으로 이 논문을 추천 드리고 싶습니다. 물론 다른 논문들도 시간이 되면 다 읽어 보시는 걸 추천 드립니다.
R-CNN, who’s next?
앞서 제가 게시한 포스팅에서도 나와있듯이 Image Classification 분야는 최근에는 AutoML로 얻은 architecture가 사람이 고안한 architecture의 정확도를 넘어서기도 하였으며, 굉장히 많은 연구가 진행이 되어있는 분야입니다.
OverFeat과 R-CNN이 제안된 이후로 굉장히 많은 연구들이 쏟아져 나오기 시작합니다. 초기에는 detection의 성능을 향상시키는 데 초점을 두는 연구들이 주로 진행이 되었으며, 최근 들어서는 연산을 가속하는 연구들과 효율적으로 학습을 시키는 방법 등 다양한 방향으로 연구가 진행이 되고 있습니다.
Deep Learning을 이용한 Object detection은 크게 2가지 방향으로 나눌 수 있습니다.
- 1-Stage Object Detector
- 2-Stage Object Detector
R-CNN과 같이 탐색 영역을 찾는 Region Proposal 과 해당 영역을 분류하는 Detection 두 가지 과정이 순차적으로 수행되는 방법론을 2-stage object detector 라 부르며, 두 가지 과정을 한번에 처리하는 방법론을 1-stage object detector 라 부릅니다.
우선 2-stage object detector는 다음 그림과 같이 나타낼 수 있습니다.
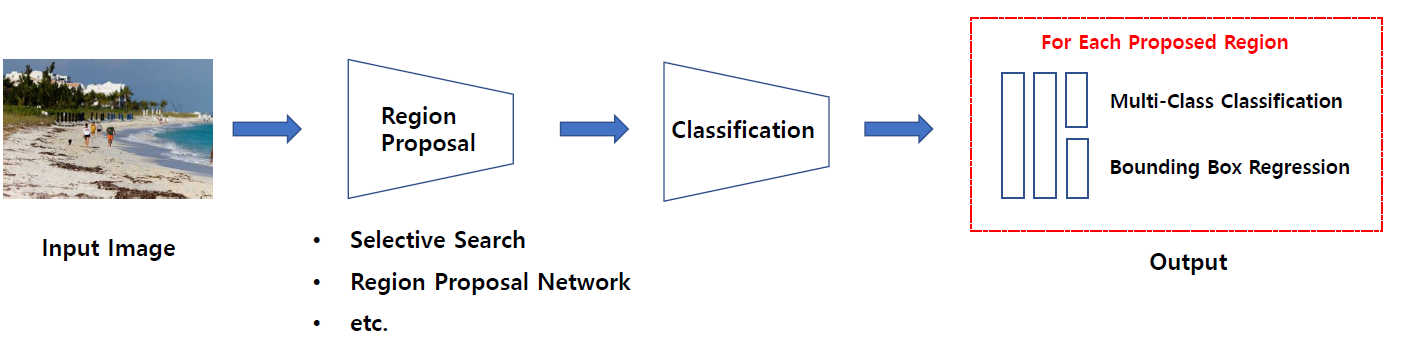
R-CNN과 그 이후 진행된 R-CNN 계열의 연구들(Fast R-CNN, Faster R-CNN)등이 대표적인 2-stage object detector이며 이름 그대로 2단계의 과정을 거치면서 object detection을 수행합니다. 1-stage object detector에 비해 비교적 느리지만 정확하다 는 특징을 가지고 있습니다.
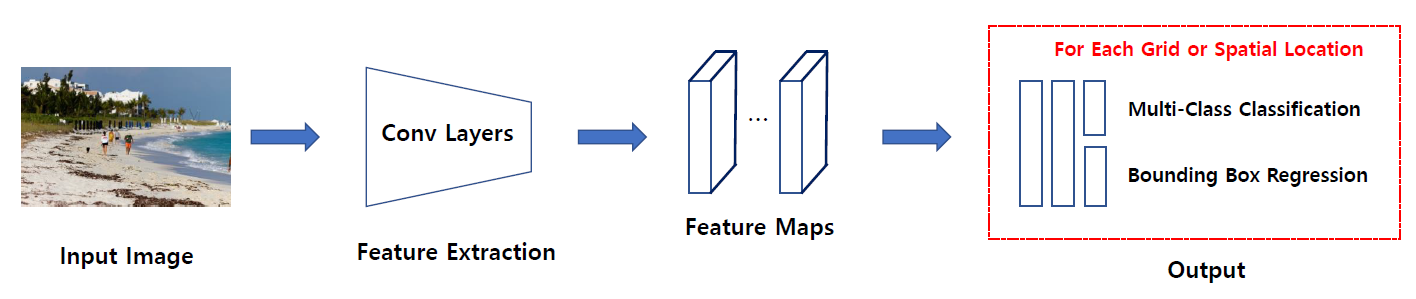
SSD, YOLO가 대표적인 1-stage object detector이며 Region Proposal과 detection이 한 번에 수행이 되며, 2-stage object detector에 비해 빠르지만 부정확하다 는 특징을 가지고 있습니다. YOLO는 version 1부터 version 3까지 성능이 좋아지고 있으며 SSD는 DSSD, DSOD, RetinaNet 등 다양한 후속 연구들이 제안되고 있습니다.
학계에서도 1-stage, 2-stage 두 가지 접근 방법으로 연구가 주로 진행이 되고 있으며 속도를 요구하는 task에서는 1-stage object detector를, 정확성을 요구하는 task에서는 2-stage object detector를 사용하는 추세입니다. 여러분들이 실무에 object detection을 활용하시는 경우에는 이러한 특징을 잘 생각하셔서 model을 선정하시기 바랍니다.
결론
이번 포스팅에서는 Deep Learning을 이용한 Object Detection의 변천사에 대해 설명을 드렸습니다. Deep learning을 적용한 최초의 Object Detection 방법론과 성장 과정들에 대해 간단하게 다루고 대표적인 2가지 연구 방향에 대해 설명을 드렸습니다. 다음 포스팅에서는 이러한 Object Detection들이 현실에서 어떤 방식으로 적용이 될 수 있는지 정리를 할 예정입니다.
혹시 글을 읽으시다가 잘 이해가 되지 않는 부분은 편하게 댓글에 질문을 주시면 답변 드리겠습니다.
참고 문헌