Tutorials of Object Detection using Deep Learning [7] Object Detection 최신 논문 Review
안녕하세요, Tutorials of Object Detection using Deep Learning 일곱 번째 포스팅입니다. 이번 포스팅에서는 Object Detection의 성능을 개선하는 여러 최신 논문들을 간단하게 리뷰할 예정입니다. 이전 포스팅들과는 다르게 각 논문에 대한 설명은 짧지만 핵심 아이디어를 소개드릴 예정이며 총 7편의 논문을 다룰 예정입니다.
오늘 다룰 논문들은 다음과 같습니다.
- “DSOD: Learning Deeply Supervised Object Detectors from Scratch”, 2017 ICCV
- “Rethinking ImageNet Pre-training”, 2018 arXiv
- “Scale-Transferrable Object Detection”, 2018 CVPR
- “STDnet: A ConvNet for Small Target Detection”, 2018 BMVC
- “Group Normalization”, 2018 arXiv
- “MegDet: A Large Mini-Batch Object Detector”, 2018 CVPR
- “Domain Adaptive Faster R-CNN for Object Detection in the Wild”, 2018 CVPR
1. How to train from scratch well?
일반적으로 Object Detection은 ImageNet 으로 pretraining된 backbone을 사용합니다. 하지만 ImageNet과 같은 자연계 이미지 domain과 성질이 크게 다른 경우(ex, depth image, synthetic image, etc.)에는 오히려 역효과를 불러일으킬 수 있습니다. 또한 기존 사용하던 backbone과 다른 backbone을 사용하는 경우 다시 ImageNet으로 pretraining을 시켜야 하는데, 이 과정에 굉장히 많은 시간과 리소스가 소요됩니다.
이와 같이 pretrained weight를 사용하기 힘든 경우에 random initialized된 weight로부터 학습을 하여야 하는데, 이를 scratch로부터 학습한다 고 표현합니다. 오늘 소개드릴 “DSOD: Learning Deeply Supervised Object Detectors from Scratch” 논문은 제목에서도 알 수 있듯이 scratch로부터 Detector를 잘 학습시키는 방법을 다루고 있습니다. DenseNet의 Dense Block과 Inception의 Stem Block을 활용하는 것이 핵심이며 pretraining을 하지 않았을 때도 ImageNet으로 pretraining을 하였을 때와 비슷한 성능을 보임을 실험을 통해 증명합니다.
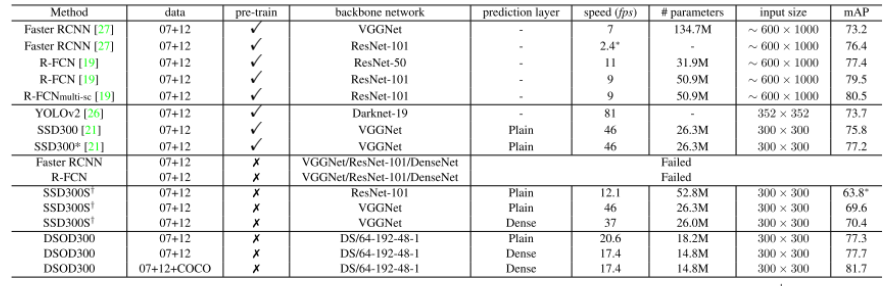
비슷한 주제로 최근에 Object Detection의 거장들이 모여서 낸 Technical report가 있어서 추가로 소개 드립니다. “Rethinking ImageNet Pre-training” 이라는 제목만 봐도 무슨 이야기를 할 지 예측이 가능합니다.
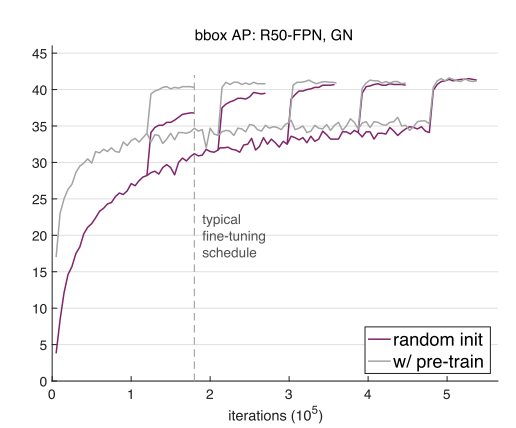
굳이 ImageNet pretrained weight을 사용하지 않아도, 학습만 잘 시키면 비슷한 효과를 볼 수 있음을 실험적으로 보인 technical report이며 관심있으신 분들은 참고하시면 좋을 것 같습니다.
2. 다양한 Scale의 Object에 강인한 Network 구조를 다룬 연구
현실 세계에는 다양한 scale의 object가 존재하며, 실제로 Object Detection의 주요 데이터셋에서 모델의 성능을 저하시키는 대표적인 원인 중 하나가 바로 object의 다양한 scale입니다. 그 중에서도 small object의 경우 검출하기가 어려운데, 이러한 문제를 해결하기 위해 나온 논문들이 있습니다. 두 논문의 방법론은 재미있는 점이 이름이 굉장히 비슷합니다. 헷갈리지 않게 잘 기억해두시면 좋을 것 같습니다.
첫번째로 소개드릴 논문은 “Scale-Transferrable Object Detection”이며 STDN 이라는 이름을 가진 방법론을 제안합니다.
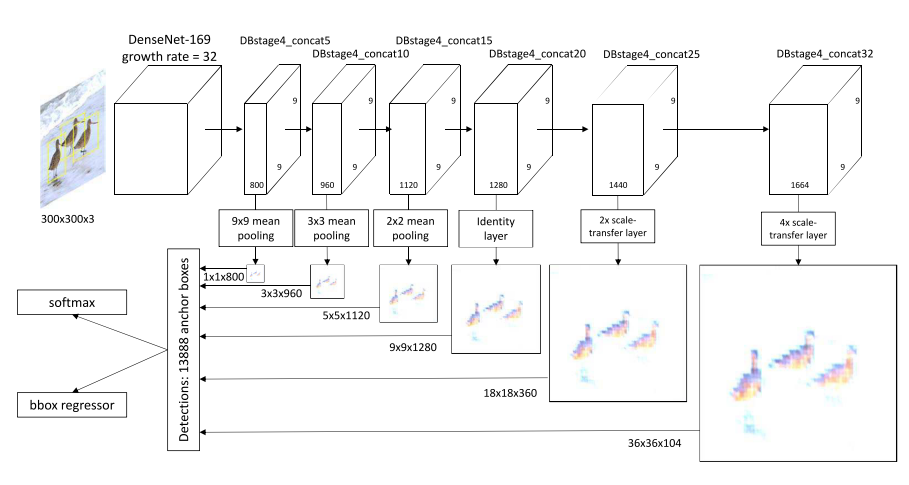
큰 object 검출을 위해 큰 receptive field를 가져가기 위해 pooling을 사용하며 작은 object 검출을 위해 Image Super-Resolution에서 사용되는 Pixel Shuffler(Depth to Space) 방식을 통해 고해상도의 feature map을 생성하는 방법을 제안합니다. 영상 처리에서 사용되는 방식을 Object Detection에 접목시킨 점이 인상깊은 논문입니다.
다음 소개드릴 “STDnet: A ConvNet for Small Target Detection” 논문도 제목에서 알 수 있듯이 작은 object의 검출 성능을 올리기 위한 방법을 제안합니다. Region Context Network(RCN) 라는 visual attention 모듈을 제안하고, 이를 통해 고해상도의 feature map에서 작은 object를 잘 검출할 수 있게 됩니다.
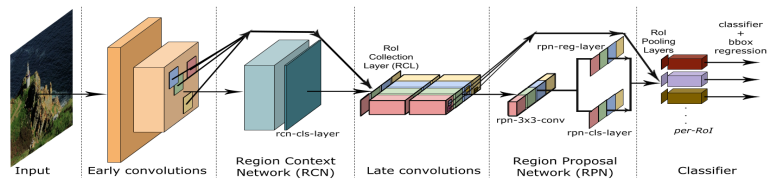
3. 작은 Batch size로 인해 생기는 BatchNorm의 성능 저하를 막기 위한 연구
최근에는 거의 보편적으로 사용되는 Batch Normalization은 16, 64 등 적당히 큰 batch size에서는 잘 동작하지만 batch size가 작은 경우 성능 저하가 크다고 알려져 있습니다. 하지만 대부분의 Object Detection 모델은 학습 시 작은 batch size를 사용하기 때문에 Batch Normalization에서 성능 저하가 발생할 수 있습니다. 이를 해결하기 위해 나온 Normalization 기법이 Group Normalization 이며 실험 결과 작은 batch size에서도 Batch Normalization과 비슷한 효과를 보이는 것을 확인할 수 있습니다. 실험 결과와 방법론은 그림 5에서 확인하실 수 있습니다.
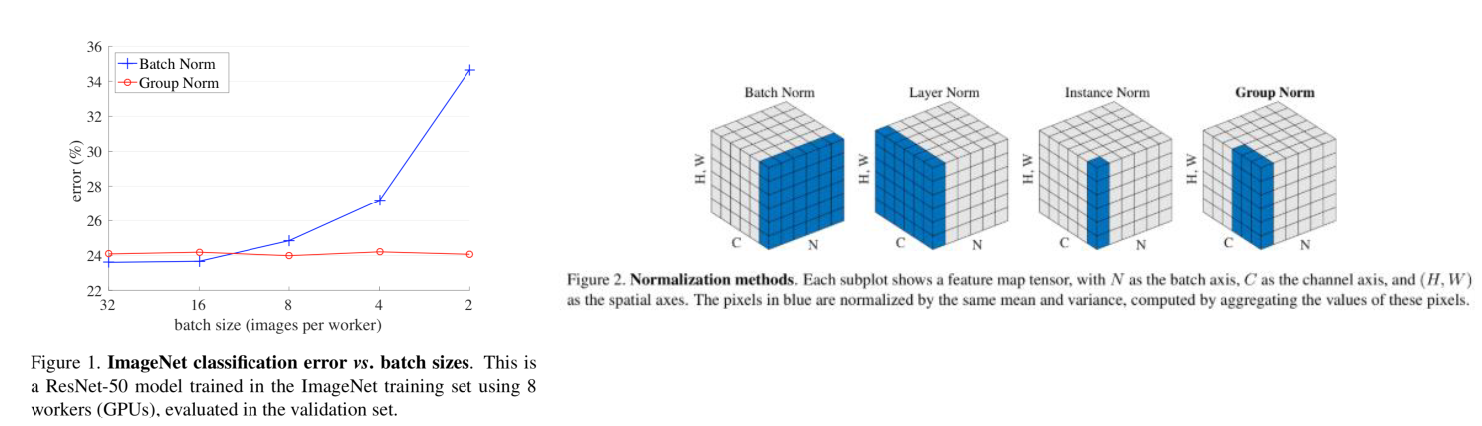
4. GPU 리소스가 많을 때 빠르게 학습시키기 위한 연구
이번에 소개드릴 논문은 GPU 리소스가 많아서 Batch Size를 크게 가져갈 수 있을 때 효율적으로 학습을 시키는 방법을 다룬 “MegDet: A Large Mini-Batch Object Detector” 논문입니다. 위에서 말씀드린 것처럼 대부분의 Detection 모델은 작은 batch size를 가져가는데, 큰 batch size에서도 잘 학습을 시킬 수 있는 방법을 제안하였으며, “Cross-GPU Batch Normalization” 기법과 “Linear Gradual Warmup Learning rate scheduling” 기법을 이용하였습니다. 방법론과 실험 결과는 그림 6에서 확인하실 수 있습니다. 참고로 “Linear Gradual Warmup Learning rate scheduling” 기법은 “Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour” 논문에서 제안된 방법이니 관심있으신 분들은 해당 논문도 참고하시면 좋을 것 같습니다.
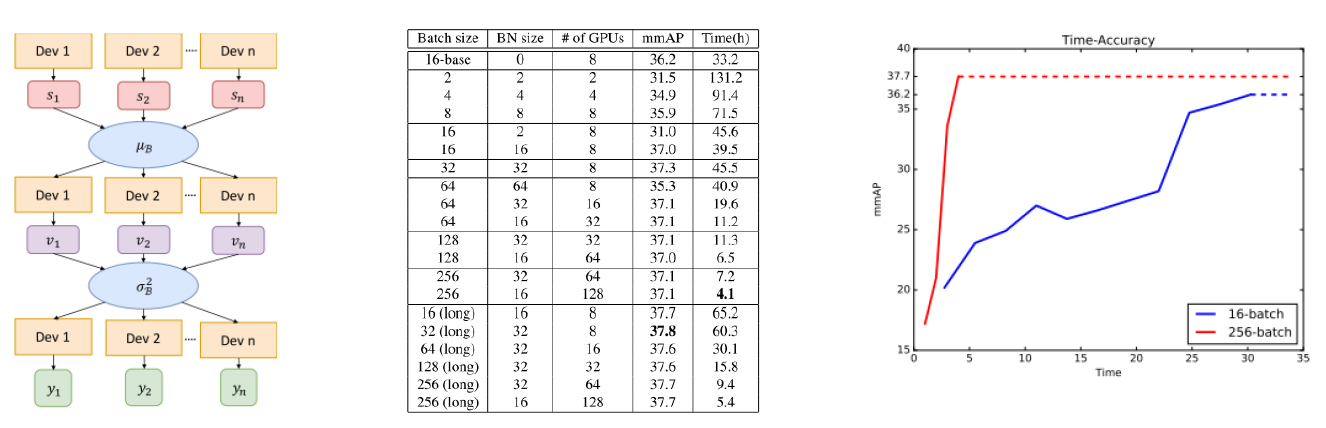
5. Domain Adaptation 기법을 Object Detection에 적용한 연구
마지막으로 소개드릴 논문은 “Domain Adaptive Faster R-CNN for Object Detection in the Wild” 이며 실제 현업에서 적용할 때의 상황을 다루고 있다는 점이 흥미롭습니다. 현업에서 직접 데이터셋을 구축해야 할 때 기존 보유하고 있던 비슷한 데이터셋의 정보를 활용하여 Domain Adaptation을 하는 방법을 다루고 있으며 두 데이터셋 간의 분포의 차이를 H-divergence로 정의하고 이를 최소화하는 방향으로 학습하는 방법을 제안합니다. 3가지 시나리오에서 실험을 하였으며, Baseline 대비 좋은 성능을 보임을 확인할 수 있습니다.
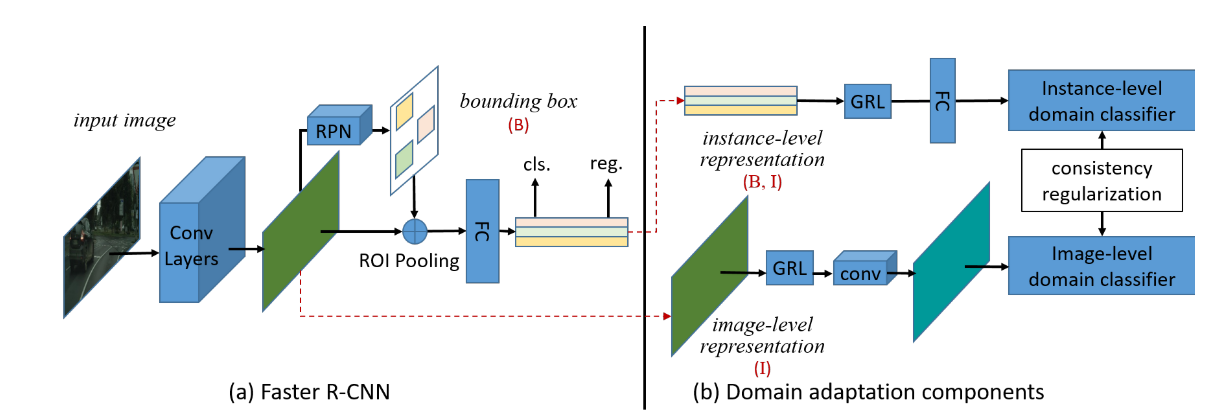
결론
이번 포스팅에서는 Object Detection의 성능을 올리기 위한 최신 연구들을 간단하게 리뷰해보았습니다. 최신 연구들은 몇 년 전과는 다르게 굉장히 다양한 방향으로 연구가 진행이 되고 있는 것을 확인할 수 있었습니다. 오늘 다룬 논문들 외에도 2018년 중순부터 2019년 초까지 또 다양한 논문들이 발표가 되었으니, 최신 논문들에 관심있으신 분들은 제 github repository 를 참고하시면 좋을 것 같습니다. 혹시 글을 읽으시다가 잘 이해가 되지 않는 부분은 편하게 댓글에 질문을 주시면 답변 드리겠습니다. 읽어 주셔서 감사합니다!
참고 문헌
- “DSOD: Learning Deeply Supervised Object Detectors from Scratch”, 2017 ICCV
- “Rethinking ImageNet Pre-training”, 2018 arXiv
- “Scale-Transferrable Object Detection”, 2018 CVPR
- “STDnet: A ConvNet for Small Target Detection”, 2018 BMVC
- “Group Normalization”, 2018 arXiv
- “MegDet: A Large Mini-Batch Object Detector”, 2018 CVPR
- Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour, 2017, arXiv
- “Domain Adaptive Faster R-CNN for Object Detection in the Wild”, 2018 CVPR