Anomaly Detection 개요: [2] Out-of-distribution(OOD) Detection 문제 소개 및 핵심 논문 리뷰
안녕하세요, 이번 포스팅에서는 지난 포스팅에 이어 Anomaly Detection(이상 탐지)에 대한 내용을 다룰 예정이며 Anomaly Detection 연구 분야 중 Out-of-distribution(OOD) Detection 문제에 대해 여러 논문을 토대로 깊이 있게 소개를 드릴 예정입니다.
Out-of-distribution(OOD) Detection 이란?
이전 포스팅인 ” Anomaly Detection 개요: (1) 이상치 탐지 분야에 대한 소개 및 주요 문제와 핵심 용어, 산업 현장 적용 사례 정리” 에서 잠시 언급했던 Out-of-distribution(OOD) Detection은 현재 보유하고 있는 In-distribution 데이터 셋을 이용하여 multi-class classification network를 학습시킨 뒤, test 단계에서 In-distribution test set은 정확하게 예측하고 Out-of-distribution 데이터 셋은 걸러내는 것을 목표로 하고 있다고 말씀드렸습니다.
하지만 기존 classification network는 분류를 위해 feature extractor 마지막 부분에 softmax를 붙여서 사용하는데, softmax 계산 식이 exponential 함수를 이용하기 때문에 예측 확률이 거의 1에 근접하는 high-confidence 예측이 자주 관찰됩니다. In-distribution 데이터 셋을 정확하게 high-confidence로 예측하는 것은 큰 문제가 되지 않습니다. 다만 Out-of-distribution 데이터 셋을 test 단계에 넣어주는 경우, 이상적인 결과는 어떠한 class로도 예측되지 않도록 각 class를 (1/class 개수) 확률로 uniform 하게 예측하는 것입니다. 하지만 대부분의 경우 Out-of-distribution 데이터 셋을 test 단계에 넣어주면 high-confidence 예측이 관찰되기 때문에 단순한 방법으로는 걸러 내기 힘든 문제가 있습니다.
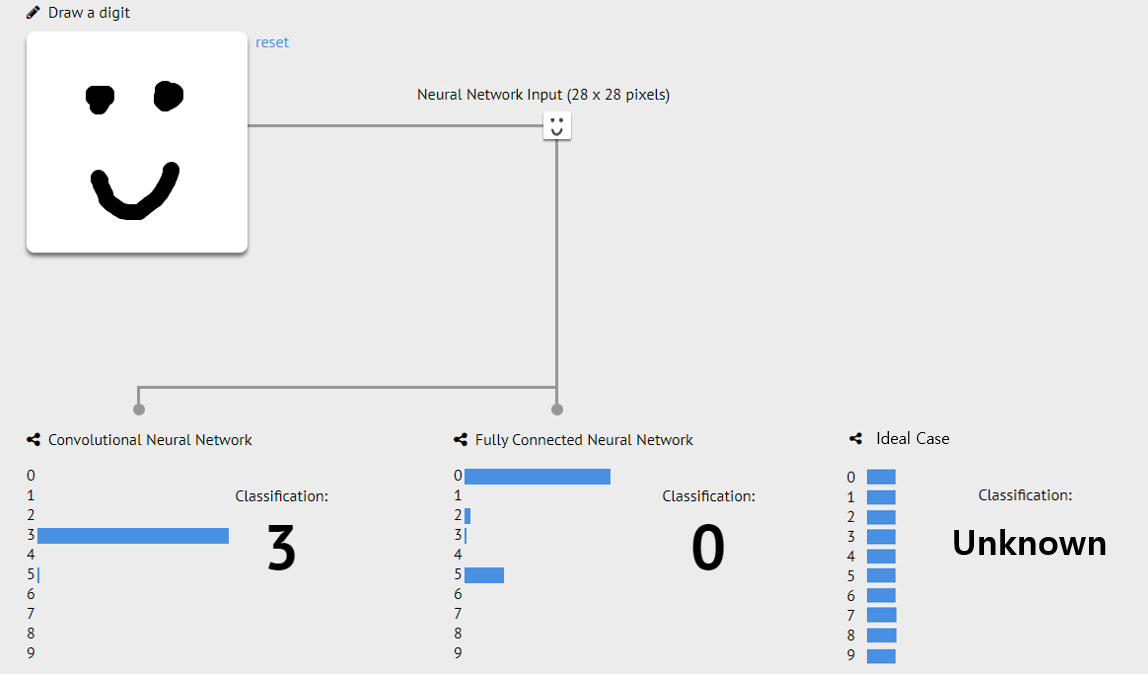
위의 그림은 유저가 직접 마우스로 input을 주면 CNN(Convolutional Neural Network)와 MLP(Multi-Layer Perceptron)를 통해 0부터 9까지 숫자를 예측하는 과정을 데모로 구현한 MNIST Web Demo 페이지에서, 숫자 대신 전혀 다른 sample인 미소 짓는 얼굴을 Out-of-distribution sample로 가정하고 입력한 예시입니다. 0 ~ 9 중 어느 class에도 속하지 않기 때문에 이상적인 경우에는 어떠한 class로도 예측되지 않아야 하지만 CNN의 경우는 매우 높은 확률로 3이라는 class로, MLP의 경우 0이라는 class에 가장 높은 확률, 5라는 class에 2번째로 높은 확률 값으로 예측하는 것을 확인할 수 있습니다.
Classifier를 학습시킬 때 0~9에 속하지 않는 sample들을 모아서 Unknown 이라는 11번째 class로 가정하여 11-way classification으로 문제를 바꿔서 학습시키는 것을 가장 먼저 생각해볼 수 있습니다. 다만 이러한 경우 이미 학습된 망을 다시 학습하여야 하는 문제와, Unknown sample을 다양하게 취득하여야 하는 한계가 존재합니다.
이러한 문제점에 집중해서 Unknown class를 추가하는 단순한 방법 대신 보다 더 효율적이면서 효과적인 방법을 제시한 논문들을 시간 순으로 소개를 드리겠습니다.
Out-of-distribution Detection을 다룬 논문들 소개
이번 장에서는 Out-of-distribution Detection을 다룬 여러 논문들을 핵심 아이디어 위주로 설명을 드릴 예정이며 가장 최초의 논문부터 글을 작성하고 있는 시점의 최신 논문까지 소개를 드릴 예정입니다.
- “A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks”, 2017 ICLR
Out-of-distribution Detection을 다룬 최초의 논문이며, Out-of-distribution Detection에 대한 문제 정의와 평가 방법 등을 제시하였고, 간단한 abnormality module 구조를 제안하였고 약간의 성능 향상을 달성한 내용을 논문에서 언급하고 있습니다.
본 논문에서는 Computer Vision과 Natural Language Processing, Automatic Speech Recognition에 대해 실험을 하였지만 이번 포스팅에서는 Computer Vision에 대해서만 다룰 예정입니다. 실험에는 In-distribution 데이터 셋으로는 MNIST, CIFAR-10, CIFAR-100을 이용하였고 Out-of-distribution 데이터 셋으로는 Scene Understanding(SUN) 데이터 셋, Omniglot 데이터 셋, Synthetic 데이터인 Gaussian Random Noise 데이터 셋, Uniform Random Noise 데이터 셋 등을 이용하였습니다.
In-distribution 데이터 셋으로 network를 학습을 시킨 뒤, test 단계에서 in-distribution 데이터 셋과 out-of-distribution 데이터 셋을 test set으로 사용을 하게 됩니다. 당연한 이야기지만 학습에는 in-distribution 데이터 셋만 사용을 하게 됩니다. 학습이 끝난 뒤 network에 test set을 넣어주면 class 개수만큼 softmax 값이 계산이 되는데, 이 중 가장 큰 값(Maximum Softmax Probability)을 사용하여 Out-of-distribution detection에 활용할 수 있습니다. 모종의 threshold 값을 정해두고, Maximum Softmax Probability 값이 threshold보다 크면 in-distribution, 작으면 out-of-distribution sample이라고 분류할 수 있습니다.
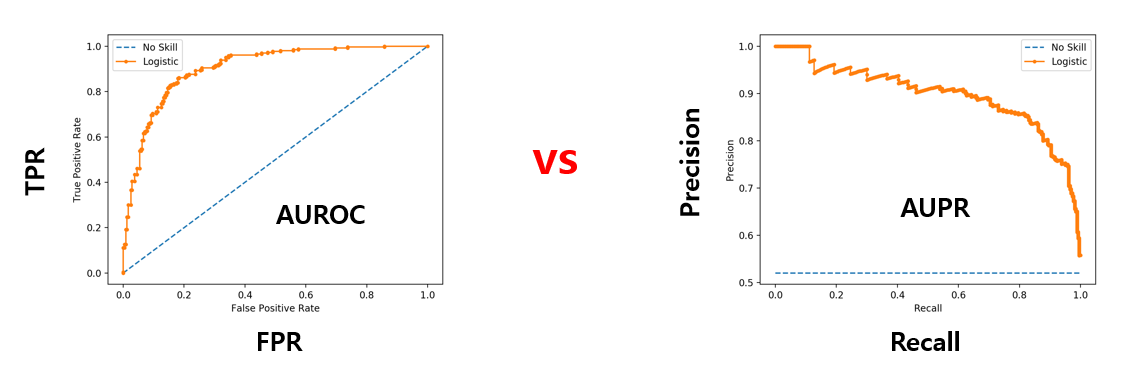
성능 평가를 위한 metric으로는 threshold 값에 무관한 지표인 AUROC와 AUPR을 사용하였습니다. AUROC는 ROC 커브의 면적을 통해 계산할 수 있으며 ROC 커브는 positive class와 negative class의 sample 개수가 다른 경우에 이를 반영하지 못하기 때문에 추가로 Precision-Recall 커브의 면적인 AUPR 도 사용하였습니다. AUPR을 계산할 때에는 In-distribution 데이터 셋을 Positive로 간주하였을 때의 값인 AUPR In 과 Out-of-distribution 데이터 셋을 Positive로 간주하였을 때의 값인 AUPR Out 2가지 값을 각각 계산합니다.
마지막으로 out-of-distribution 데이터 셋으로 test를 하였을 때의 각 sample 별 예측한 class의 확률 값들을 평균 낸 지표인 Pred. Prob(mean) 지표도 제안하였습니다. 이 지표가 높다는 것은 모델이 out-of-distribution 데이터 셋을 high-confidence로 잘못 예측하고 있음을 시사합니다. 다만 이 지표는 후속 논문 들에서는 사용되지 않습니다.
본 논문에서는 Out-of-distribution Detection 문제에 대한 Baseline을 잘 정립해주었고, 실험 프로토콜과 3가지 평가 지표를 제안하였다는 점에서 큰 의미를 가지고 있다고 생각합니다.
- “Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks”, 2018 ICLR
2018년 ICLR에 발표된 논문이며 ODIN(Out-of-DIstribution detector for Neural networks)이라는 기억하기 쉬운 방법론 이름을 제안하여 유명세를 얻은 논문입니다. 이미 학습이 끝난 neural network에 어떠한 추가 학습 없이 간단하면서 효과적으로 out-of-distribution sample들을 찾아낼 수 있다는 점이 가장 큰 장점이며 실제로도 간단히 구현할 수 있습니다.
핵심 아이디어는 temperature scaling과 input preprocessing 2가지이며, 각각은 새로 고안해낸 것이 아니라 기존 유명한 논문 들에서 제안된 방법을 적절히 가져와서 사용했다는 점이 인상 깊으며 각각에 대해 자세히 설명을 드리겠습니다.

우선 Temperature Scaling은 Hinton 교수의 Knowledge Distillation 에서 제안된 방법이며 classification task에서 prediction confidence를 calibration 하는데 사용이 되기도 합니다. 학습 중에는 temperature scaling parameter T 를 1로 두고 학습을 진행한 뒤, test 단계에서 주어진 input의 예측 확률을 구하기 위해 softmax score를 구하게 되는데 이때 각 logit들을 T 로 나눠주는 방식으로 구현이 가능합니다. 이를 Out-of-distribution Detection 문제에 적용하면 in-distribution sample과 out-of-distribution sample의 softmax score를 서로 더 멀어지게 하여 out-of-distribution sample을 구별하기 쉽게 도와주는 역할을 합니다. 여기서 temperature scaling parameter T 가 hyper-parameter이며 적절한 값을 선택하는 것이 중요합니다.
Input Preprocessing은 adversarial attack의 시초가 된 논문에서 제안한 Fast Gradient Sign Method(FGSM) 방식에서 아이디어를 얻었으며, Back Propagation을 통해 loss를 최소화하도록 학습하는 것을 반대로 이용하여, loss를 증가시키는 방향의 gradient를 계산하여 얻은 극소량의 perturbation을 input에 더해 줌으로써 true label에 대한 softmax score를 낮춰주는 역할을 하는 것이 증명이 된 바 있습니다. 본 논문에서는 이를 역으로 이용하여 극소량의 perturbation을 input에서 빼 줌으로써 주어진 input에 대한 softmax score를 높여주는 것을 목표로 하고, 이를 통해 in-distribution sample에 대한 예측을 강화하여 out-of-distribution sample과 더 잘 분리될 수 있도록 도와주는 역할을 합니다. 여기서 perturbation magnitude parameter epsilon 이 hyper-parameter이며 적절한 값을 선택하는 것이 중요합니다.
위의 2가지 과정을 거쳐서 얻어진 maximum softmax score를 기반으로 단순히 thresholding을 거쳐 in-distribution sample 인지 out-of-distribution sample 인지를 판단하게 되며, 이때 사용하는 threshold 값 또한 hyper-parameter입니다. 즉 총 3개의 hyper-parameter가 전반적인 성능에 관여하게 됩니다.
본 논문에선 in-distribution sample의 TPR(True Positive Rate)가 95%가 되는 시점에서의 hyper-parameter를 선택하였고, 실험을 통해 최적 값으로 발견해낸 T =1000, epsilon =0.0012 값으로 고정하여 성능을 측정하였습니다. 각 hyper-parameter의 변화에 따른 성능 변화 양상은 논문에서 자세히 확인하실 수 있습니다.
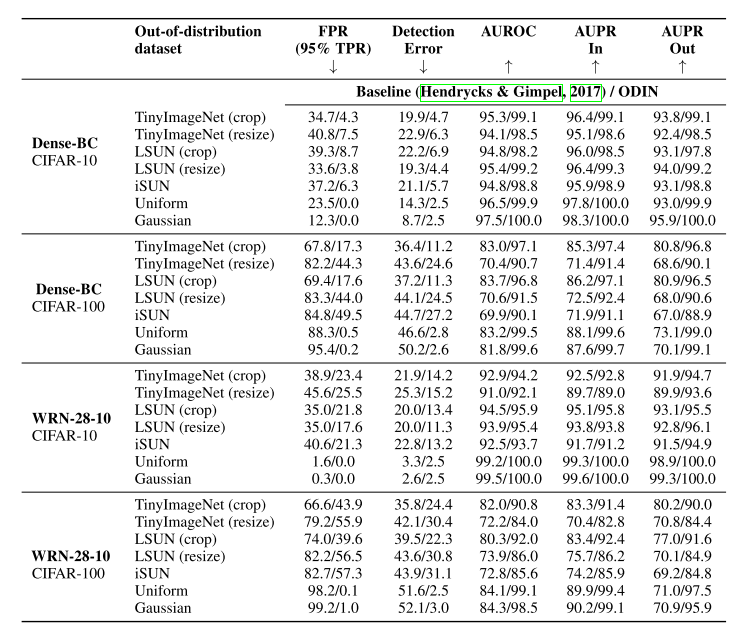
위의 표는 ODIN 논문에서 Baseline 논문과 성능을 비교한 결과이며, 성능 평가 지표로는 baseline과 동일하게 AUROC, AUPR을 사용하였고, 추가로 FPR at 95% TPR 지표와 Detection Error 지표를 사용하였습니다.
FPR at 95% TPR은 말 그대로 TPR이 95%가 되는 시점에서의 FPR이며 FPR은 1-TNR로 계산이 가능하기 때문에 후속 논문들 에서는 TNR at 95% TPR 지표로 사용이 되기도 합니다.
Detection Error는 test set에 positive sample과 negative sample 이 같은 비율로 존재한다는 가정하에 0.5(1-TPR) + 0.5FPR로 계산이 됩니다. 다만 이 지표는 개인적으로는 유의미한 정보를 담고 있지 않다고 생각이 되며 최신 논문들에서는 사용이 되지 않는 지표입니다.
Baseline을 큰 격차로 따돌리며 Out-of-distribution 연구의 성장 가능성을 보여준 논문이며 추후에도 계속 언급이 될 논문입니다.
- “Training Confidence-calibrated Classifiers for Detecting Out-of-Distribution Samples”, 2018 ICLR
ODIN 논문이 나온 지 얼마 지나지 않아 공개된 논문이며 ODIN 논문과 마찬가지로 2018년 ICLR에 발표가 된 논문입니다.
기존 방법들은 학습이 끝난 뒤 inference 단계에만 집중하고 있다면, 본 논문에서는 Out-of-distribution Detection을 잘하기 위한 training 방법을 제안하고 있는 점이 가장 큰 특징입니다.
총 2가지 방법을 제안하였는데, 첫 번째는 학습 시에 out-of-distribution sample이 덜 confident 하도록 기존 cross-entropy loss에 confidence loss 라는 loss term을 추가하는 방법을 제안하였습니다. Out-of-distribution sample의 예측 distribution이 uniform distribution과 같아지도록 하기 위해 둘 간의 KL-divergence를 구한 뒤, 이를 최소화하도록 loss function에 녹여냈다고 이해할 수 있습니다.
다음은 confidence loss를 사용할 때, in-distribution sample 근처의 out-of-distribution sample들을 이용하면 더 decision boundary를 잘 얻을 수 있음을 보여주기 위한 toy-example 실험을 수행한 뒤, 이를 바탕으로 새로운 loss term을 추가하는 방법을 제안하고 있습니다.
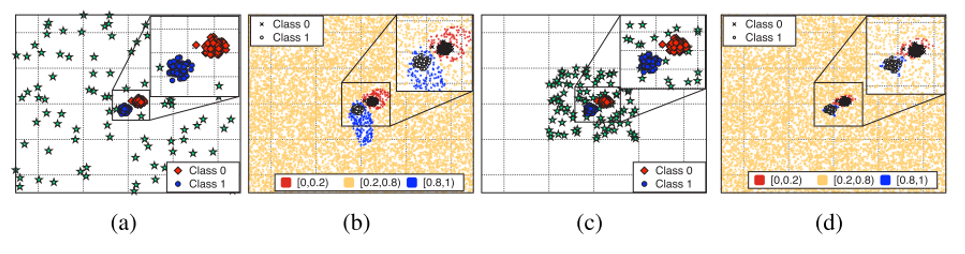
위의 그림에서 빨간 네모와 파란 동그라미는 in-distribution sample이고, 초록색 별은 가상으로 생성해낸 out-of-distribution sample을 의미합니다. 그 뒤 confidence loss를 추가하여 classifier를 학습시켰을 때의 decision boundary가 (b)와 (d)에 해당합니다. 아무 데나 흩뿌려 놓은 (a)보다 비교적 in-distribution sample 근처에 생성한 (c)를 이용하여 학습을 시킬 때 더 decision boundary를 잘 얻을 수 있음을 보여주고 있습니다. 다만 in-distribution 근처의 out-of-distribution sample을 취득하는 것이 어렵기 때문에 본 논문에서는 Generative Adversarial Network(GAN)을 이용한 GAN loss를 추가하는 방향으로 접근하였습니다. 즉, in-distribution sample과 유사한 out-of-distribution sample을 다른 데이터 셋으로부터 가져오는 대신, GAN을 통해 in-distribution sample과 유사한 out-of-distribution sample을 생성하는 방법을 제안하고 있습니다.

결과적으로 기존 cross-entropy loss term에 confidence loss와 GAN loss가 추가가 되며, 전체 loss function은 위의 그림과 같이 설계가 될 수 있습니다.
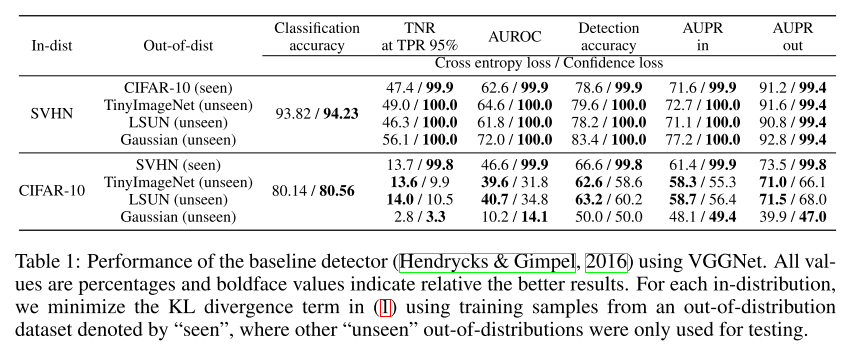
본 논문도 baseline 논문과 성능을 비교하였으며, 위의 실험 결과는 confidence loss만 사용하였을 때의 성능을 보여주고 있습니다. Out-of-distribution 데이터 셋 중 confidence loss 학습을 위해 사용된 데이터셋을 (seen) 이라 표현을 하고 있습니다. confidence loss를 최소화하기 위해 사용된 out-of-distribution 데이터 셋에 대해서는 이미 봤던 데이터 셋이고, 이를 Uniform Distribution으로 예측하도록 학습시켰기 때문에, 당연한 결과지만 월등한 검출 성능을 보입니다. 다만, 학습에 관여하지 않은 out-of-distribution 데이터 셋(unseen)에 대해서는 성능이 좋아지기도 하고 나빠지기도 하는 결과를 보여주고 있습니다. 이는 confidence loss를 최소화하기 위해 사용된 out-of-distribution을 적절히 잘 골라야 성능 향상을 기대할 수 있음을 의미합니다.
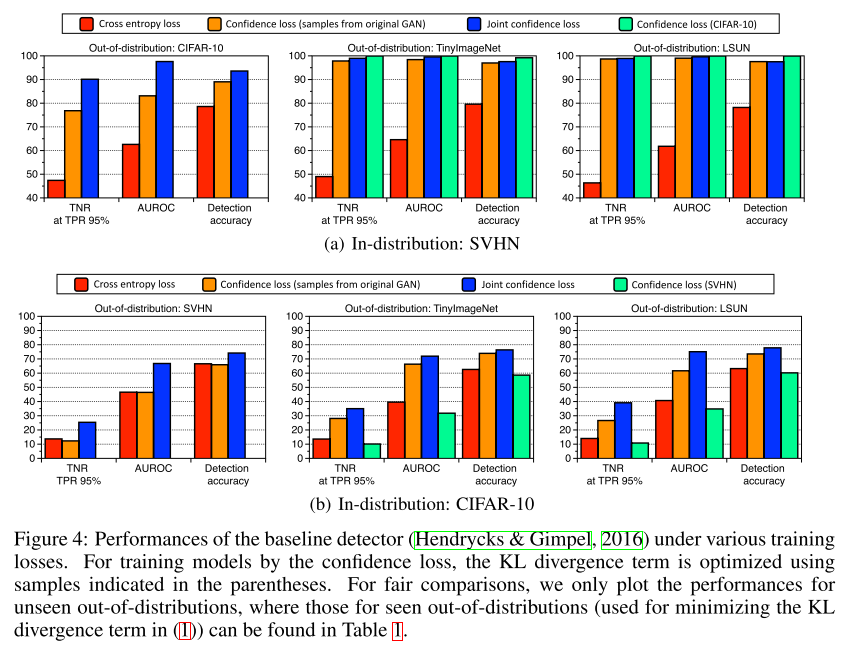
즉 confidence loss만 사용하면 불안 요소가 많지만 GAN loss까지 같이 적용하면 전반적으로 성능이 올라가는 것을 실험을 통해 보여주고 있습니다. 위의 그림에서 청록색은 confidence loss만 사용하였을 때의 결과이고, 파란색은 전체 loss function을 사용하였을 때의 결과를 보여주고 있습니다.
이 논문은 기존에는 inference 단계만 고려하고 있었는데, Out-of-distribution 문제를 풀기 위해 training 단계까지 고려하면 더 좋다는 결과를 보여준 논문이며 후속 연구에도 좋은 방향을 제시해준 논문이라 할 수 있습니다.
- “A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks”, 2018 NIPS
이 논문은 방금 소개 드린 “Training Confidence-calibrated Classifiers for Detecting Out-of-Distribution Samples” 논문의 저자들이 진행한 후속 논문이며, loss function을 재설계하는 방향에서 벗어나 다시 inference 단계에 집중을 하였으며, 이미 학습이 끝난 network의 feature들은 class-conditional Gaussian distribution을 따른다는 가정하에 가장 가까운 class conditional distribution에 대한 Mahalanobis distance 를 구하여 confidence score로 사용하겠다는 것이 논문의 핵심 내용입니다.

논문에서 알고리즘을 설명하기 위해 만든 그림이며 핵심 내용들이 다 그림에 들어있습니다. 우선 가장 가까운 class를 찾은 뒤, ODIN에서 사용했던 것처럼 input에 perturbation을 가하는 방법을 사용합니다. 다만 ODIN에서는 softmax score를 증가시키는 방향으로 perturbation을 주었다면, 본 논문에서는 Mahalanobis distance를 증가시키는 방향으로 perturbation을 주는 것이 다른 점입니다.
이렇게 해서 구해진 Mahalanobis distance를 confidence score로 사용하며, 가장 마지막 feature만 사용하던 기존 논문들과는 다르게 모든 low-level feature까지 사용하는 feature ensemble 방식도 적용을 하였습니다.
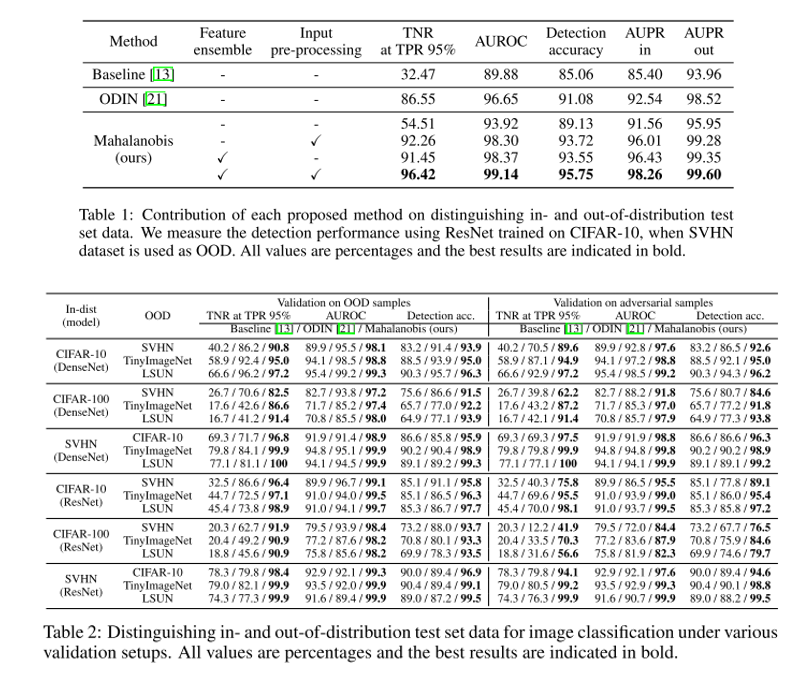
Input pre-processing과 Feature ensemble을 동시에 적용하면 모든 지표에서 ODIN보다 높은 성능을 달성할 수 있으며, 본 논문에서는 Out-of-distribution detection에서 끝나는 것이 아니라, Class-incremental learning에도 적용 가능성을 보여주고 있고, 나아가 adversarial attack에도 어느 정도 robust 해질 수 있음을 보이고 있습니다. Class incremental learning은 주어진 class에 대해 학습이 끝난 classifier에 새로운 class의 sample이 발생할 때, 이를 반영하여 새로운 class도 추가하여 학습을 하는 방법론을 의미합니다. 이 때 Mahalanobis distance 기반의 score를 활용하여 Class incremental learning을 하는 방법을 논문에서 제안하고 있습니다. Adversarial attack은 FGSM, BIM, DeepFool, CW 등의 방법을 통해 생성해낸 adversarial image들을 Out-of-distribution sample로 간주하여 얼마나 잘 걸러낼 수 있는지를 실험하였습니다. 하나의 방법으로 총 3가지 적용 사례를 제안했다는 점이 인상 깊은 논문입니다. Class incremental learning과 Adversarial attack에 대한 내용과 실험 결과가 궁금하신 분들은 논문을 참고하시면 좋을 것 같습니다.
- “Deep Anomaly Detection with Outlier Exposure”, 2019 ICLR
이 논문은 첫번째 소개 드린 Baseline 논문의 저자가 진행한 후속 연구이며, Auxiliary(보조) 데이터 셋을 활용하여 Out-of-distribution Detection의 성능을 높이는 실용적인 방법을 제안하고 있습니다.
보조 데이터 셋을 활용하려는 시도는 “Training Confidence-calibrated Classifiers for Detecting Out-of-Distribution Samples” 논문에서 사용된 confidence loss 아이디어에서 이미 등장한 바 있습니다. 다만, out-of-distribution test set의 검출 성능을 높이기 위해 기존 방법 들에서는 loss 간의 weight를 조절하거나, input pre-processing, output confidence calibration 등에 다양한 parameter들을 tuning 하는 과정이 필요했는데, 본 논문에서는 hyper-parameter에 민감하지 않다는 것을 장점으로 언급하고 있습니다. 그 외에 label이 없는 상황에서 density estimation을 하는 Generative model 기반 방법에도 Outlier Exposure 방법이 적용이 가능하며 이 때는 margin ranking loss를 사용했다는 점 등 약간의 차이점들이 존재합니다.
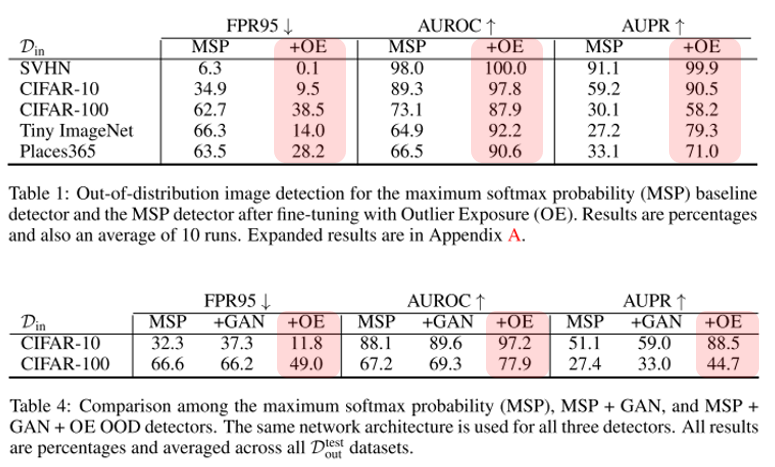
Outlier Exposure는 기존 방법들에 독립적으로 추가가 가능한 아이디어여서, 기존 detector 들에 Outlier Exposure를 추가하였을 때 얼마나 성능이 향상되는지를 논문에서 결과로 제시하고 있습니다. 다만 Outlier Exposure로 어떤 데이터 셋을 사용하는지에 따라 성능이 크게 달라질 수 있다는 점이 풀어야 할 문제이며, Gaussian noise나 GAN으로 생성한 sample 등을 활용하는 것은 크게 효과적이지 않음을 한계라 설명하고 있습니다. 이에 대해선 Outlier Exposure로 사용하는 데이터 셋을 최대한 realistic 하면서 size도 크고, 다양하게 구축하는 것이 좋은 성능을 달성하는 데 도움을 준다고 가이드를 제시해주고 있습니다.
본 논문은 기존에 존재하던 Out-of-distribution Detection 알고리즘들에 추가로 적용이 가능하면서도 손쉽게 구현이 가능한 방법론을 제안하였고, 실제로 쏠쏠한 성능 향상을 이뤄냈다는 점이 의미가 있습니다.
- Generative model 기반 접근법을 다룬 논문들
오늘 소개 드린 5편의 Out-of-distribution 논문들은 모두 classifier 기반의 접근법을 이용하였는데, 학계에서는 2018년 무렵 Generative model을 기반으로 한 연구들도 제안되기 시작했습니다. 주로 label이 없는 상황에서 training sample의 분포를 예측해내는 것을 density estimation이라 부르고, Autoregressive and invertible model인 PixelCNN++ 방식과 Glow 방식이 제안이 되었습니다. 이러한 Density estimator에 out-of-distribution sample을 넣어주면 낮은 likelihood 값으로 예측하기를 기대합니다. 다만, 기대와는 다르게 Generative model로부터 구해진 likelihood 값은 in-distribution 데이터 셋과 out-of-distribution 데이터 셋을 잘 구분하지 못한다는 문제가 “WAIC, but why? Generative ensembles for robust anomaly detection” 2018 arXiv 논문에서 처음 제기가 되었으며 아래의 그림이 이 문제를 잘 보여주고 있습니다.
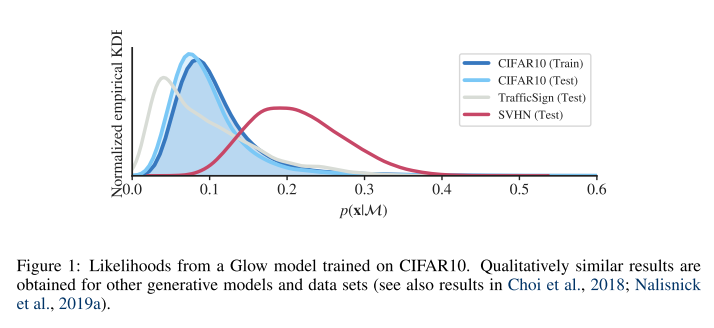
CIFAR-10으로 training을 시킨 뒤, CIFAR-10, TrafficSign, SVHN 등으로 test를 하는 경우에, generative model이 in-distribution 데이터 셋인 CIFAR-10보다 out-of-distribution 데이터 셋인 SVHN에서 더 높은 likelihood 값을 가지기도 하고, TrafficSign은 낮은 likelihood를 가지는 등 일관적이지 못한 현상이 관찰이 됩니다.
이에 대해 분석한 논문 “Input Complexity and Out-of-distribution Detection with Likelihood-based Generative Models” 2020 ICLR 에 accept이 되었습니다. 본 논문에서는 input image의 복잡도가 클수록 likelihood가 낮게 관측된다는 것을 발견하였고, 이를 통해 input의 복잡도를 추정한 뒤, 이를 활용하여 Out-of-distribution score로 활용하는 방법을 제안하였습니다.
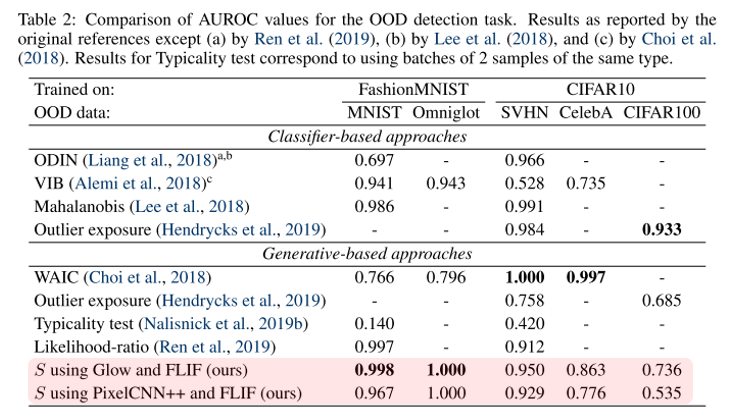
실험은 간단하게 FashionMNIST와 CIFAR-10을 in-distribution 데이터 셋으로 이용하고, 각각 다른 out-of-distribution 데이터 셋으로 test를 하여 기존 방법들과 검출 성능을 비교하였습니다. Classifier 기반의 방법론들과 견줄 만한 성능을 달성하였지만 데이터 셋에 따라 성능의 편차가 크다는 점에서 아직 더 연구해 볼 만한 여지가 있다고 생각이 됩니다.
결론
이번 포스팅에서는 Anomaly Detection 연구 분야 중 Out-of-distribution(OOD) Detection 문제를 다룬 여러 논문들을 바탕으로 소개를 드렸습니다. 초기 논문들은 Classifier를 기반으로 연구가 진행이 되어왔고 가장 초기에 나온 baseline 논문에서는 Maximum Softmax Probability를 이용하는 실험 프로토콜을 제안하였습니다.
후속 논문에선 input pre-processing, softmax score에 calibration을 적용하는 방법과 confidence score를 Mahalanobis distance를 이용하여 계산하는 방법 등 test 단계에 집중하는 시도들과, GAN을 이용하는 방법, auxiliary 데이터 셋을 Outlier Exposure로 이용하여 network를 fine-tuning 하는 방법 등 training 단계에 집중하는 시도들이 제안이 되었고, 각 논문의 핵심 내용을 정리하여 소개 드렸습니다. 또한 Classifier 기반이 아닌 Generative model을 기반으로 한 연구들도 최근 제안이 되고 있음을 살펴보았습니다.
Out-of-distribution Detection 문제는 Computer Vision 분야 외에도 자연어 처리, 음성 인식 등 다양한 분야에서 활용이 될 수 있습니다. 오늘 소개 드린 내용이 독자분들이 공부하시는 데 도움이 되었으면 좋겠습니다. 긴 글 읽어 주셔서 감사합니다!
Reference
- AUROC, AUPR 그림 인용 블로그 글
- MNIST Web Demo
- “A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks”, 2017 ICLR
- “Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks”, 2018 ICLR
- “Distilling the Knowledge in a Neural Network”, 2014 NIPS Workshop
- “On Calibration of Modern Neural Networks”, 2017 ICML
- “Explaining and Harnessing Adversarial Examples”, 2015 ICLR
- “Training Confidence-calibrated Classifiers for Detecting Out-of-Distribution Samples”, 2018 ICLR
- “A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks”, 2018 NIPS
- “Deep Anomaly Detection with Outlier Exposure”, 2019 ICLR
- “PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications”, 2017 ICLR
- “Glow: Generative Flow with Invertible 1x1 Convolutions”, 2018 NeurIPS
- “WAIC, but why? Generative ensembles for robust anomaly detection”, 2018 arXiv
- “Input Complexity and Out-of-distribution Detection with Likelihood-based Generative Models”, 2020 ICLR