AutoML-Zero:Evolving Machine Learning Algorithms From Scratch Review
안녕하세요, 오랜만에 AutoML 관련 논문을 리뷰드리네요. 이번 포스팅에서는 일주일 전 공개된 “AutoML-Zero: Evolving Machine Learning Algorithms From Scratch” 논문을 간단히 설명드릴 예정입니다. 논문의 결과가 흥미롭고 생각할 여지가 많아서 빠르게 리뷰하였습니다. 참고로 이 논문은 Google Brain과 Google Research에서 연구를 수행하고 작성하였습니다.
Introduction
AutoML은 Machine Learning을 Automatic하게 수행하는 과정을 의미하며 지난 NASNet 논문 리뷰 포스팅 에서 간단히 소개 드린 바 있습니다. AutoML을 다룬 연구는 짧은 시간 동안 굉장히 많은 발전을 이뤘습니다. 대표적인 Neural Architecture Search(NAS)는 처음 제안된 방법은 수백개의 GPU로 몇 달을 돌려야 CIFAR-10에 대한 architecture 하나를 구할 수 있었는데, 이제는 하나의 GPU로 몇 시간만에 사람이 설계한 architecture의 성능을 뛰어넘고, 나아가 hardware에 최적화된, 즉 연산량, throughput까지 고려한 architecture를 자동으로 찾아내주기도 합니다.
다만 대부분의 AutoML 연구는 architecture를 찾는데 집중을 했었습니다. 오늘 소개드릴 AutoML-Zero 논문은 한 줄로 본인들의 목표를 설명하고 있습니다.
Our goal is to show that AutoML can go further
즉, AutoML이라고 부르긴 했지만 실제론 어느 정도 사람이 개입하여야 했고, 대표적인 사례가 바로 search space 입니다. Architecture search를 예로 들면 각 layer에 1x1 conv, 3x3 conv, 3x3 max pooling 등 여러 옵션을 먼저 사람이 정해 놓은 뒤 search algorithm을 통해 architecture를 설계하는 방식이죠. 이렇게 AutoML은 아직까지 사람이 디자인해야 하는 요소가 남아있었는데 본 논문은 좀더 혁신적인 AutoML로 가기 위해선 전체 ML 알고리즘을 설계하는 과정에서 사람의 개입을 최소화 해야 한다고 역설하고 있습니다.
AutoML-Zero는 model, optimization, initialization 등 ML과 관련 있는 요소들을 오로지 수학적인 연산 정도만 옵션으로 주고 다 설계할 수 있는지를 살펴보는 것을 중점으로 연구를 진행하였습니다. 정확한 설명은 아래에서 자세히 드리도록 하겠습니다.
AutoML-Zero
AutoML-Zero는 굉장히 많은 요소가 있는데, 하나의 큰 그림을 그리고 각 세부 내용들을 설명드리겠습니다.
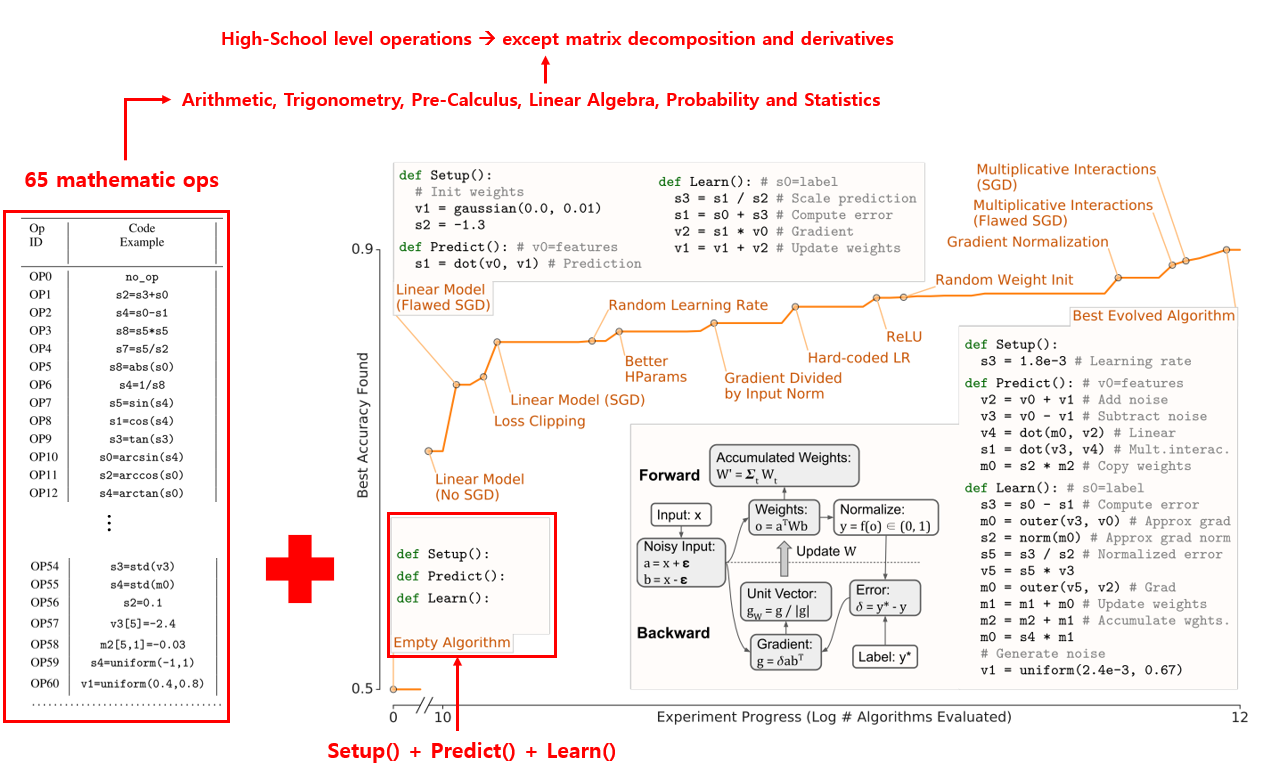
Search Space
우선 앞서 말씀드린 것처럼 ML과 관련 있는 요소들을 오로지 고등학교 수학 수준(사실 우리나라의 고등학교 수학 수준은 훨씬 높죠.. 허허)의 65가지의 연산들만 이용할 예정이며, matrix decomposition, 미분 등 복잡한 연산은 제외하였다고 합니다. 논문의 Supplementary Material S1에 65가지 연산 목록이 나와있습니다. 이런 식으로 수학 기호들을 search space로 하여 AutoML을 적용한 시도를 다룬 연구는 2017년 optimizer를 symbolically 표현하고 이를 AutoML로 찾아서 PowerSign, AddSign 등의 optimizer를 제안한 Neural Optimizer Search with Reinforcement Learning 논문이 있습니다. 다만 이 논문은 optimizer를 제외한 나머지 영역은 사람이 개입을 하였다는 점이 가장 큰 차이입니다. 즉, network는 미리 정해두고, forward pass에는 activation을 계산하고 backward pass에선 weight gradient를 계산하는 등 저희가 일반적으로 사용하는 방식을 그대로 따라하고 있죠. 하지만 AutoML-Zero는 이러한 prior를 사용하지 않고 바닥부터 시작하는 점이 핵심입니다.
아무튼 65가지의 연산들을 정했고, 앞으로 이러한 연산들을 Instruction이라 부를 예정입니다. 이제 어떠한 방식을 써서라도 ML 알고리즘을 만들고, 학습을 시켜서, Test Set에대한 정확도를 측정하여야 하기 때문에, 딱 3가지의 component function인 Setup(), Predict(), Learn() 를 정의하고 search를 시작합니다.
이름에서 유추할 수 있듯이 Setup은 weight를 초기화하는 것을 의미하고, Predict는 forward propagation을 구성하는 모든 요소로 이해하시면 될 것 같습니다. 즉 training, validation 2개의 for-loops가 있는데 Predict는 2개의 loop에 모두 수행이 됩니다. Learn은 training에 관여하는 모든 요소를 포함하고 있으며 training loop에서만 수행이 됩니다. 전체적인 Overview 그림을 보시면 처음에는 3개의 component function이 다 비어 있었는데, 시간이 지날수록 점점 채워지고, 정확도가 가장 높았던 뒷 부분의 예시를 보면 꽤 그럴싸한 구조를 가지고 있는 것을 알 수 있습니다.

이렇게 3가지 component function을 만들면 위의 그림과 같은 pseudo code와 같이 사용이 됩니다. 3가지 component function과 training set, validation set이 필요하며, classification task의 경우 -무한 ~ 무한의 범위를 갖는 prediction 값을 0과 1사이로 normalize 시키기 위해 sigmoid(binary classification) 혹은 softmax(multi-class)를 넣어주며, 이 때 약간의 사람의 개입이 들어갑니다. 이러한 evaluation 과정은 여러 task를 동시에 수행하며 search method에 의해 정해진 알고리즘의 quality를 평가할 때는 모든 task들의 정확도의 중앙값을 사용하였다고 합니다.
Search Method
이제 위에서 정한 Search Space를 기반으로 어떻게 Search를 수행하는지 설명을 드리겠습니다. 우선 AutoML-Zero에서는 놀랍게도(논문에서 이렇게 표현하고 있습니다) evolutionary algorithm(진화 알고리즘)을 채택하였습니다. 정확히는 regularized evolution search method 를 사용하였으며, genetic programming(유전 프로그래밍)과 비슷하지만 tree 구조가 아닌 programmer가 코드를 작성하는 것처럼 instruction의 sequence 형태로 프로그램을 표현하였습니다. 가장 단순하면서 효율적인 방법이라고 판단돼서 regularized evolution search method를 사용하였고, 본인들도 search method에 대해선 큰 집중을 하지 못했다고 인정하며, 더 복잡한 evolutionary algorithm, 강화 학습, Bayesian optimization 등을 future work로 남겨두었습니다.
무튼, regularized evolution search method에 대한 그림은 다음과 같습니다.
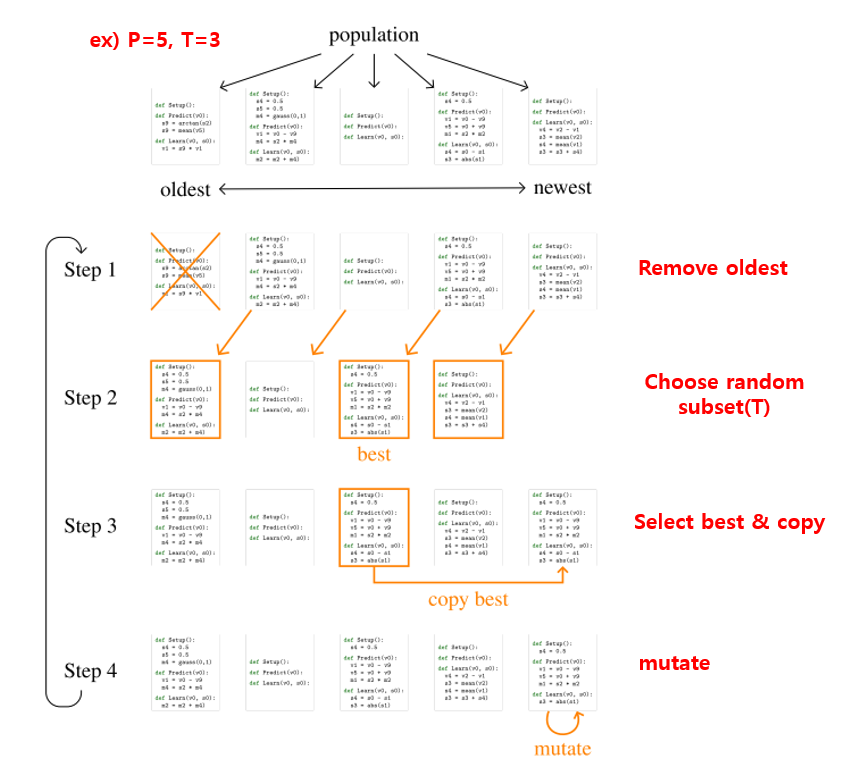
우선 Step 1에서 P개의 population이 있을 때 가장 오래된 것을 제거합니다. 그 뒤, Step 2에선 random하게 T개를 추출합니다. 당연히 T는 P보다 작아야겠죠? Step 3에선 가장 성능이 좋은(예를 들면 test accuracy가 가장 높은) 하나를 복제합니다. 마지막으로 Step 4에선 mutation(돌연변이)를 수행합니다. Mutation은 다음 그림과 같이 3가지 방법을 random하게 선택하여 사용합니다.
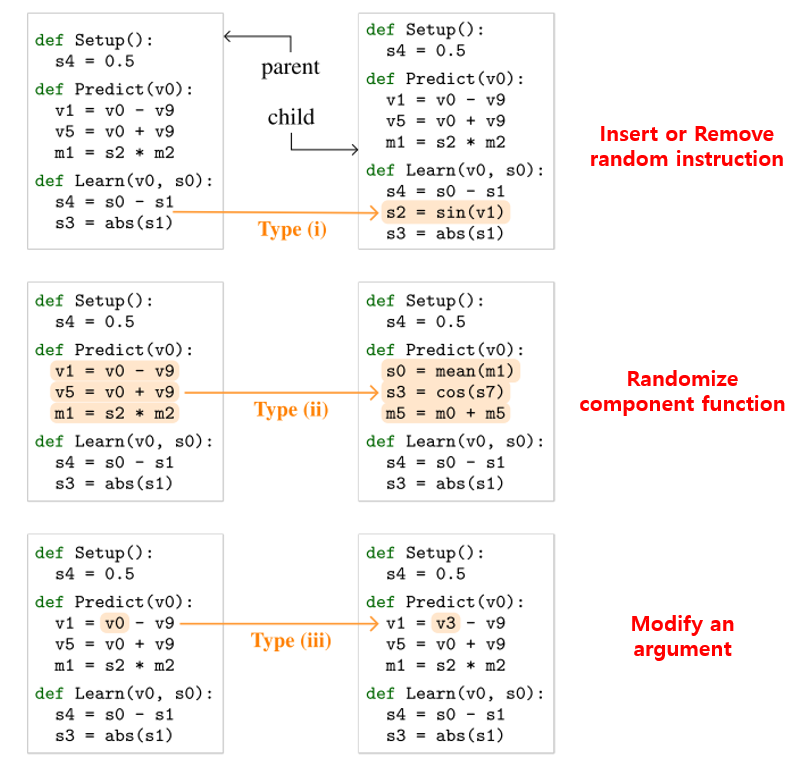
우선 첫번째 mutation 방법으론 임의의 instruction을 넣거나 제거하는 방법이 있습니다. 어떠한 component function의 어떠한 위치에 적용이 가능합니다. 두번째 mutation 방법으론 하나의 component function의 구성을 아예 다 바꿔버리는 방법입니다. 약간 과격한 방식이죠. 세번째 mutation 방법은 소심하게 하나의 instruction의 argument 하나만 바꾸는 방식입니다. 이렇게 소심한 방법, 중간 정도의 방법, 과격한 방법을 적용하였으며, 이 때는 어쩔 수 없이 사람이 개입하긴 합니다.
탐색 속도 가속
추가로 탐색 속도를 2000 ~ 10000/sec/cpu 정도로 빠르게 만들기 위해 총 2가지 방법을 적용하였습니다. 우선 첫번째론 functional equivalence checking(FEC) 라는 방식인데, 쉽게 말해 search method로 찾은 함수들이 supervised ML 알고리즘에서 사용되는 함수와 같은 역할을 하는지 확인하는 것을 의미합니다. (비록 구현은 다를지라도) 이를 확인하기 위해 일부의 데이터를 10개의 training step, 10개의 validation step을 거친 뒤 결과가 같은 지 알아보는 방식을 사용하였으며, 이 FEC 방식을 통해 4배의 speedup을 이룰 수 있었다고 합니다. 두번째론 2019년 ICML에 발표된 The Evolved Transformer 에서 제안한 hurdles 을 추가하여 5배의 throughput 향상이 있었다고 합니다. 다만 어떻게 hurdles을 추가하였는지는 자세한 설명이 되어있지 않습니다. 이 외에도 당연히 분산적으로 실험을 수행하였다고 합니다. 속도 향상에 대한 자세한 설명은 Supplementary Material S8에 되어있습니다.
실험 결과
다음은 실험 결과에 대한 설명입니다. 저자들은 총 3가지 질문에 답하기 위해 실험을 설계하였다고 합니다. 각 질문과 그에 대한 대답을 차례대로 설명 드리겠습니다.
Finding Simple Neural Nets in a Difficult Space
우선 첫번째 질문은 “how difficult is searching the AutoML-Zero space?” 입니다. 탐색 공간의 어려움에 대해 질문을 던지고 이에 대한 답을 하였습니다. 결론을 먼저 말씀드리면 어렵지만, evolutionary search를 통해 흥미로운 알고리즘을 찾을 수 있었다! 입니다.
얼마나 어려운지 비교하기 위해 Random Search(RS)와 비교 실험을 수행합니다. 우선 쉬운 난이도의 문제인 fitting linear regression data 문제를 주고 2가지 방법에게 풀게 시켰습니다. 하지만 RS는 사람이 개입하여 힌트를 주지 않으면 단순한 문제도 풀지 못했다고 합니다.
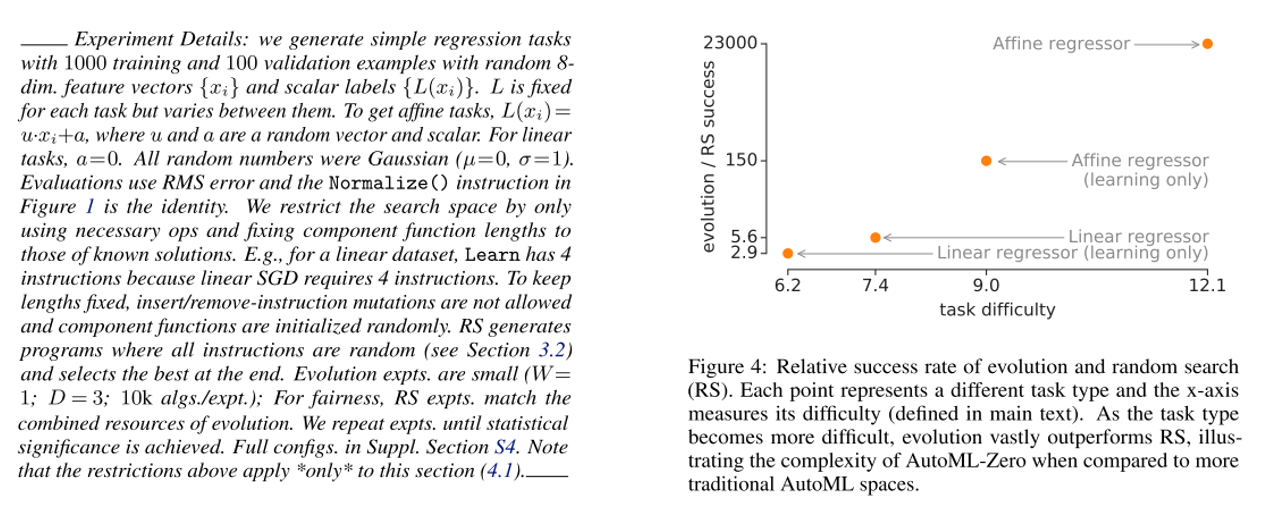
우선 위의 그림의 왼쪽은 실험 설계에 대한 디테일한 내용이며(다 안 읽어봐도 됩니다) 오른쪽 그래프는 x축이 문제의 난이도, y축은 RS 대비 Evolutionary Search의 성공 비율을 뜻하며 문제가 어려워질수록 RS보다 훨씬 많은 비율로 성공을 하는 것으 확인할 수 있습니다.
여기서 나아가서 nonlinear data에 대해서도 실험을 해보니 RS는 아예 성공하지 못하면서 두 search 방식 간의 차이가 더 벌어졌다고 합니다. 실험을 위해 regression task를 생성하였고, 좋은 solution이 존재하는 것을 담보하기 위해 teacher neural network 를 생성하였습니다. 그 뒤, evolutionary search가 teacher의 코드를 재발견하는지 확인하는 실험을 수행하였습니다.

놀랍게도 생성해낸 teacher network를 재현하는데 성공을 하였고, task의 개수를 100개로 늘리면, 각 task가 서로 다른 weight를 발견해야 하는데, 이 과정에서 evolution은 단순히 forward pass를 발견하는 것뿐만 아니라, weight를 학습하기 위한 backward propagation code도 찾아내는(논문에서는 invent 라 표현) 놀라운 결과를 보여줍니다. 오른쪽 그림이 AutoML-Zero가 스스로 밑바닥부터 찾아낸 2-layer neural network with gradient descent 입니다. 정말 놀라운 결과입니다. 이에 대한 자세한 내용은 Supplementary Material S4에서 확인하실 수 있습니다.
Searching with Minimal Human Input
이번엔 “can we use our framework to discover reasonable algorithms with minimal human input?” 라는 질문을 던집니다. 즉 최소한의 사람의 개입을 해도 우리가 납득할만한 알고리즘을 발견할 수 있는지에 대한 대답을 얻기 위해 실험을 진행하였습니다. 실험은 간단하게 CIFAR-10과 MNIST을 이용하여 binary classification 문제를 만들어서 풀게 시킵니다. (저는 이 부분을 이해하는데 한참 걸렸습니다..) 어떻게 binary classification으로 문제를 바꾸냐면, CIFAR-10과 MNIST는 둘 다 class 개수가 10개이므로 10개 중에 2개를 고르는 경우의 수가 45가지입니다. 즉 10가지 class에서 2개를 고른 뒤 둘을 구분하도록 학습을 시키는 것입니다. 예를 들면 숫자 0과 숫자 7을 구분하는 binary classification 모델을 생성하는 것입니다.
총 45가지의 조합 중에 36개는 탐색에 사용되고(Training Set), 나머지 9개는 model selection에 사용이 됩니다(Validation Set). 그 뒤 최종적으로 Test Set으론 CIFAR-10 test set을 이용하였다고 합니다. 실험에 대한 자세한 설명은 본 논문의 7페이지와 Supplementary Material S4에서 확인하실 수 있습니다.
아무튼 CIFAR-10과 MNIST에 대해 20번 작은 실험을 해보니 사람이 디자인한 2-layer MLP + gradient descent 모델보다 20번 중 13번 더 좋은 성능을 달성하였다고 합니다. 또한 전체 CIFAR-10 test set에 대해 성능을 비교해보니 AutoML-Zero로 찾은 모델이 logistic regression, 2-layer MLP보다 더 높은 정확도를 달성하였고, SVHN, downsampled ImageNet, Fashion MNIST에서도 높은 정확도를 달성할 수 있었습니다. 즉 밑바닥부터 찾아낸 코드가 사람이 짠 2-layer MLP + gradient descent 코드보다 성능이 좋았음을 의미합니다.
이 과정에 대한 설명은 맨 처음 보여드렸던 그림에서 확인하실 수 있으며, 놀랍게도 시간이 지날수록 Input noise, Loss Clipping, SGD, Gradient Normalization, Hard-coded LR, ReLU, Random Weight Initialization, averaged perceptron, weight averaging 등을 차례대로 배워가는 모습이 관찰이 되었다고 합니다. 그리고 최종적으론 높은 정확도를 내는 깔끔한 코드로 완성이 됩니다. 정말 신기한 결과입니다!
Discovering Algorithm Adaptations
마지막 질문은 “can we discover different algorithms by varying the type of task we use during the search experiment?” 이며 쉽게 말해 문제 상황이 바뀔 때 유연하게 적응할 수 있을지 확인하는 것을 목표로 실험을 진행하였습니다.
총 3가지 상황을 가정하였는데, 첫번째는 training example이 부족한 경우, 두번째는 빠른 학습을 하여야 하는 경우, 세번째는 class의 개수가 늘어나는 경우입니다. 모든 실험은 위에서 탐색하였던 Rediscovered neural network 알고리즘 그림의 Figure 5의 2-layer neural network를 기반으로 시작을 하였다고 합니다.

각 문제 상황에 대해 굉장히 놀랍게 잘 적응을 하는 것을 확인할 수 있었습니다. 우선 training example이 부족한 경우에 AutoML-Zero는 input data에 noise를 주입하여 augmentation을 하는 것을 스스로 배웠다고 합니다. 이러한 아이디어는 noisy ReLU, Dropout 등 잘 알려진 방법에서 사용하는 방식과 유사합니다. 빠른 학습을 위해선 스스로 learning-rate decay를 배웠으며, 이 또한 저희가 잘 알고 있는 방식입니다. 마지막으로 class의 개수가 늘어난 경우에는 weight matrix의 평균에 절대값을 씌우고 sin 함수에 넣은 뒤 이를 learning rate로 사용하는 다소 이해할 수 없는 방식을 채택하였고, 이로 인해 성능이 향상되었다고 합니다. 즉 사람이 이해할 수 있는 방식을 제안하기도 하지만, 이해할 수 없는 방식도 제안할 수 있음을 보여주고 있는 좋은 예시입니다.
결론
본 논문에서는 기존에 사람이 많이 개입하여 왔던 AutoML 분야에서 사람의 개입을 최소화한 채 밑바닥부터 evolutionary search method를 통해 수학 연산(instruction)들을 조합하여 ML 모델을 생성하는 과정을 제안하였습니다.
사람이 제안하였던 여러 방식들을 잘 따라서 만들어내는 과정도 보았고, 사람이 이해할 수 없지만 효과적인 방법도 제안하였습니다. 저는 개인적으로 이 논문이 AutoML의 무궁무진한 가능성을 잘 보여준 좋은 사례라고 생각이 되고, 앞으로 어떤 놀라운 연구가 진행될지 기대가 되기도 하면서 살짝 두렵기도 하네요.
생각보다 글이 길어져서 디테일한 부분을 생략한 곳이 많은데 양해 부탁드리며.. 자세한 부분이 궁금하시면 논문을 참조하시기 바랍니다! 읽어 주셔서 감사합니다!