Deep Learning Image Classification Guidebook [1] LeNet, AlexNet, ZFNet, VGG, GoogLeNet, ResNet
안녕하세요, 2020년 hoya research blog의 장기 프로젝트 중 하나였던 Deep Learning Image Classification Guidebook의 첫 삽을 드디어 푸게 되었습니다. 이름에서 알 수 있듯이 딥러닝을 이용한 대표적인 Image Classification 연구들, 즉 주요 Convolutional Neural Network(CNN) Architecture 들을 소개 드리는 글을 작성할 예정입니다.
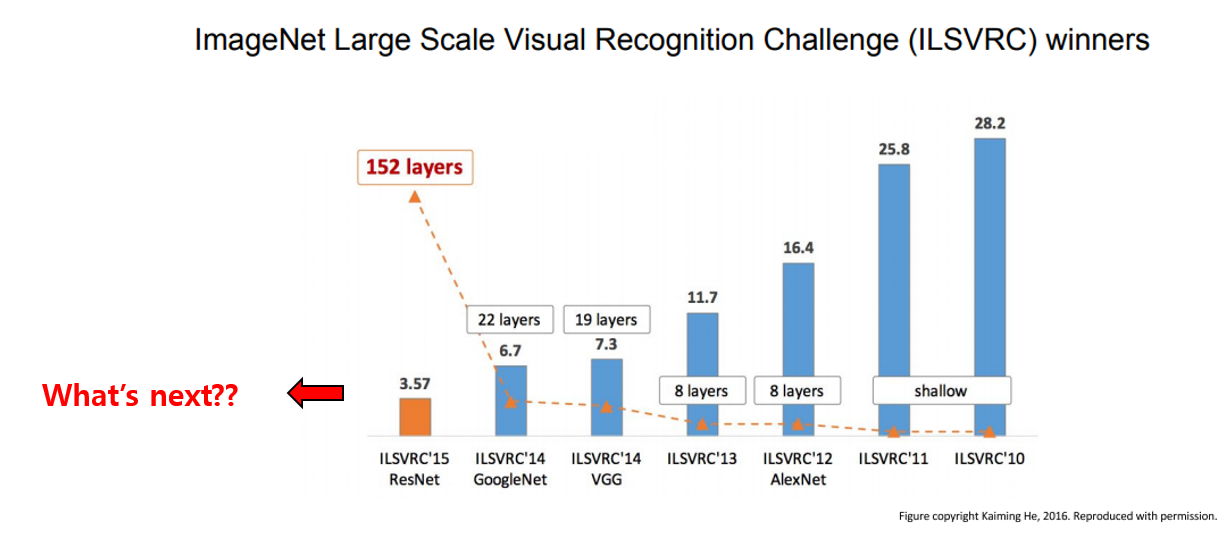
위의 그림은 제가 좋아하는 강의 자료인 Stanford의 cs231n 의 강의 자료의 한 페이지를 가져온 것입니. 대부분의 강의 자료와 잘 정리된 블로그 글 등을 보면 2012년 제안된 AlexNet을 시작으로 VGG, GoogLeNet, ResNet 정도 까지는 굉장히 잘 설명이 되어있습니다.
하지만, 딥러닝 연구의 붐이 불기 시작한 2016년 무렵 이후에 발표된 수많은 연구들에 대해선 한 곳에 잘 모아 놓은 자료가 거의 없어서 논문을 하나 하나 찾아보면서 공부를 하면서, “시간 순으로 잘 모아둔 자료가 있으면 좋겠다!” 고 느꼈고, 그러다 보니 공부도 할 겸 자연스럽게 글을 작성하게 되었습니다.
Image Classification 성능을 높이기 위한 다양한 시도들이 있는데, 저는 이번 연재에서는 Convolutional Neural Network(CNN) Architecture 에 집중할 예정입니다. 각 architecture들의 구조와 특징, ImageNet 데이터셋에 대한 성능 정도의 지표들을 약 PPT 1페이지 분량으로 요약하여 설명드릴 예정입니다.
나중에 기회가 된다면 augmentation 관점, optimizer 관점 등 학습 방법을 다룬 연구들도 총 정리를 할 예정입니다.
1990년대 ~ 2015년까지의 연구들
LeNet-5, 1998
처음 소개드릴 논문은 Image Classification에 거의 보편적으로 사용되는 Convolutional Neural Network(CNN)을 최초로 제안한 논문인 Yann LeCun의 LeNet-5 입니다.
그 당시 classifier로 주로 사용되던 fully-connected multi-layer network, 즉 MLP가 가지는 한계점인 input의 pixel수가 많아지면 parameter가 기하급수적으로 증가하는 문제, local한 distortion(ex, image를 1pixel shift)에 취약한 문제 등을 지적하며, 이러한 문제를 해결할 수 있는 Convolutional Neural Network 구조를 처음 제안하였습니다. Input을 1차원적으로 바라보던 관점에서 2차원으로 확장 하였고, parameter sharing을 통해 input의 pixel수가 증가해도 parameter 수가 변하지 않는다 는 특징을 가지고 있습니다.
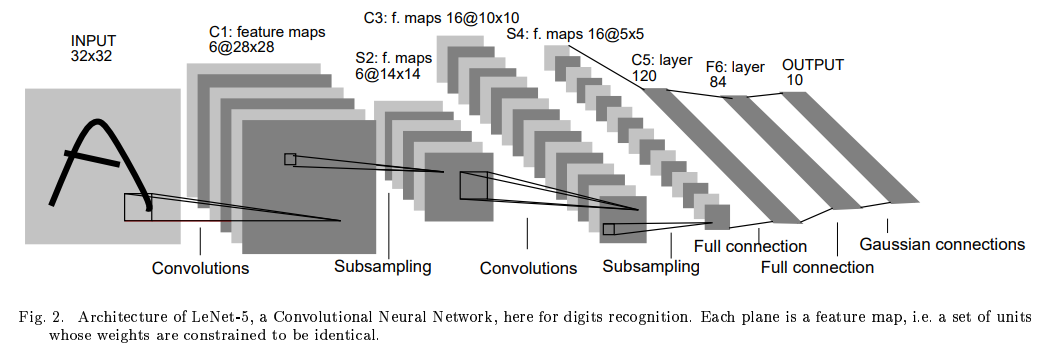
손 글씨 인식을 위해 제안이 된 architecture이고, 1990년대 당시에는 지금 수준의 컴퓨팅 파워에 비하면 현저히 연산 자원이 부족했기 때문에 32x32라는 작은 size의 image를 input으로 사용하고 있습니다. Layer의 개수도 Conv layer 2개, FC layer 3개로 굉장히 적은 개수의 layer를 사용하고 있습니다.
여담으로 architecture의 이름은 LeCun의 이름과 Network를 합쳐서 LeNet이란 이름으로 부르게 되었다고 합니다. 또한 LeNet은 LeNet-1, LeNet-4를 거쳐 LeNet-5라는 이름을 가지게 되었는데, 왜 하필 LeNet-5인지, 왜 LeNet-2, LeNet-3은 없는지 궁금했지만 답을 찾지는 못했습니다. ResNet-18, ResNet-34와 같이 Layer의 개수로 부르는 건 아닌 것 같고.. 혹시 아시는 분 계신가요? ㅎㅎ
AlexNet, 2012
다음으로 소개드릴 논문은 AlexNet 입니다. ImageNet 데이터셋을 이용하여 Classification 성능을 겨루는 대회인 ILSVRC 대회가 2010년부터 매년 열렸는데, SuperVision 이라는 이름의 팀이 2012년 압도적인 성능으로 우승을 하게 됩니다. 이 SuperVision팀이 사용한 architecture가 바로 AlexNet입니다. 2012년 NIPS에 발표된 논문이며, LeNet과 마찬가지로 저자의 이름 Alex와 Network를 합쳐서 AlexNet이라는 이름을 가지고 있습니다.
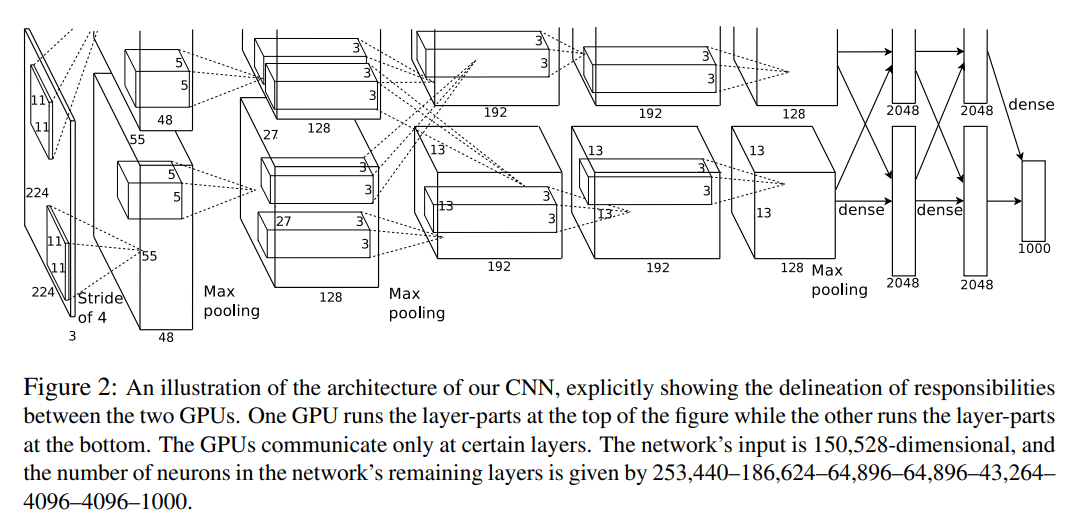
224x224 크기의 RGB 3 channel image를 input으로 사용하며 자세한 architecture 구조는 위의 그림에서 확인하실 수 있습니다. 그림을 보면 특이한 점이 2갈래로 나뉘어져서 연산을 수행하며, 중간 중간 결과를 공유하는 것을 알 수 있습니다. 이러한 구조를 가지게 된 이유는 그 당시에 사용한 GPU인 GTX 580이 3GB의 VRAM을 가지고 있는데, 하나의 GPU로 실험을 하기엔 memory가 부족하여 위와 같은 구조를 가지게 되었다고 합니다.
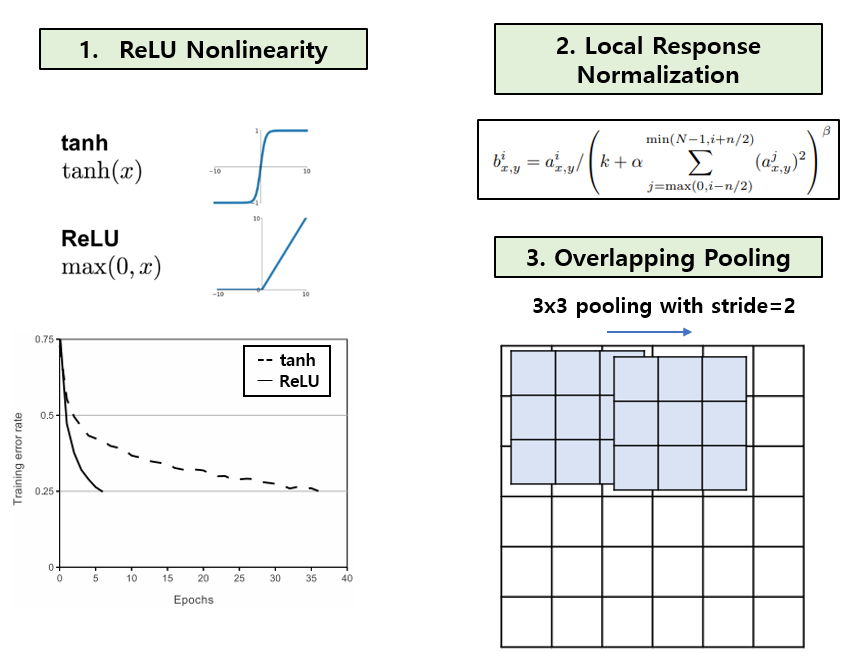
Multi GPU Training 외에도 3가지 특징이 있습니다. 첫째론 activation function으로 Rectified Linear Units(ReLUs) 를 사용하였으며, ReLU 자체를 처음 제안한 논문은 아닙니다. 기존에 사용되던 tanh 보다 빠르게 수렴하는 효과를 얻을 수 있었다고 합니다. 둘째론 최근엔 거의 사용하지 않는 normalization 테크닉인 Local Response Normalization(LRN) 을 사용하였고, 마지막으론 Pooling의 kernel size를 stride보다 크게 하는 Overlapping Pooling 을 사용하였습니다. 이 외에도 Dropout, PCA를 이용한 data augmentation 등의 기법들도 사용하였습니다.
ZFNet, 2013
다음 소개드릴 논문은 ILSVRC 2013 대회에서 우승한 Clarifai 팀의 Zeiler와 Fergus의 이름을 따서 지은 ZFNet 입니다.
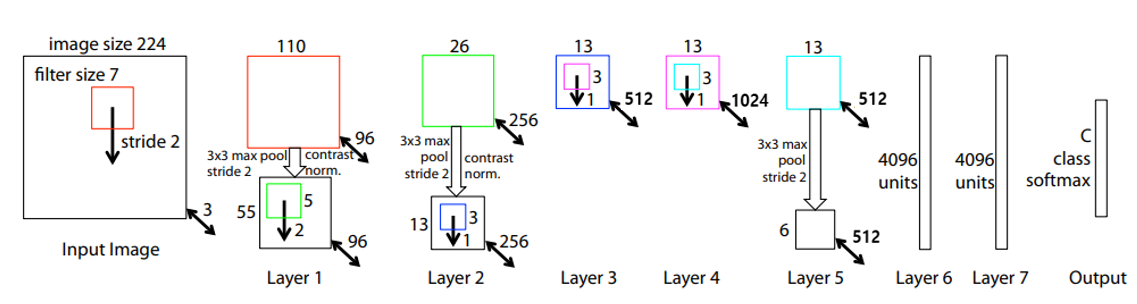
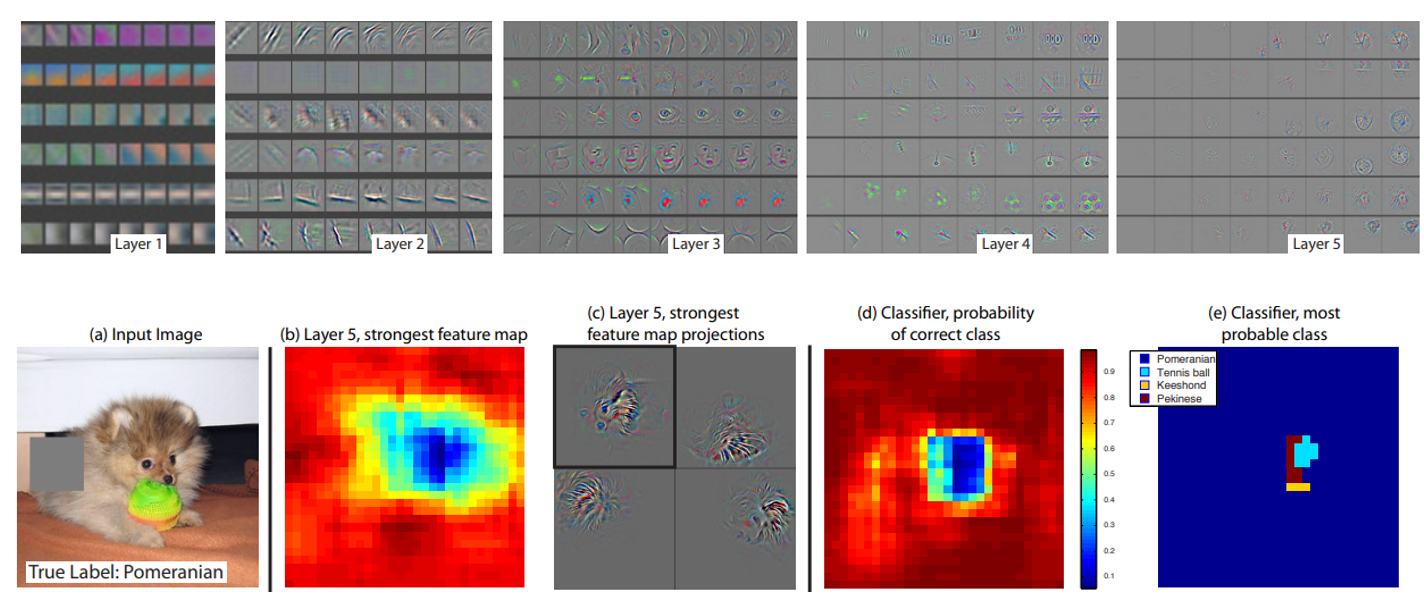
AlexNet을 기반으로 첫 Conv layer의 filter size를 11에서 7로, stride를 4에서 2로 바꾸고, 그 뒤의 Conv layer들의 filter 개수를 키워주는 등(Conv3,4,5: 384, 384, 256 –> 512, 1024, 512) 약간의 튜닝을 거쳤으며 이 논문은 architecture에 집중하기 보다는, 학습이 진행됨에 따라 feature map을 시각화하는 방법과, 모델이 어느 영역을 보고 예측을 하는지 관찰하기 위한 Occlusion 기반의 attribution 기법 등 시각화 측면에 집중한 논문이라고 할 수 있습니다.
VGG, 2014
다음 소개드릴 논문은 옥스포드 연구진에서 2014년 발표한 VGG 입니다. ILSVRC 2014 대회에서 2위의 성적을 거두었으며, 이번엔 저자의 이름이 아닌, 저자들의 소속인 Visual Geometry Group에서 이름을 따왔습니다.
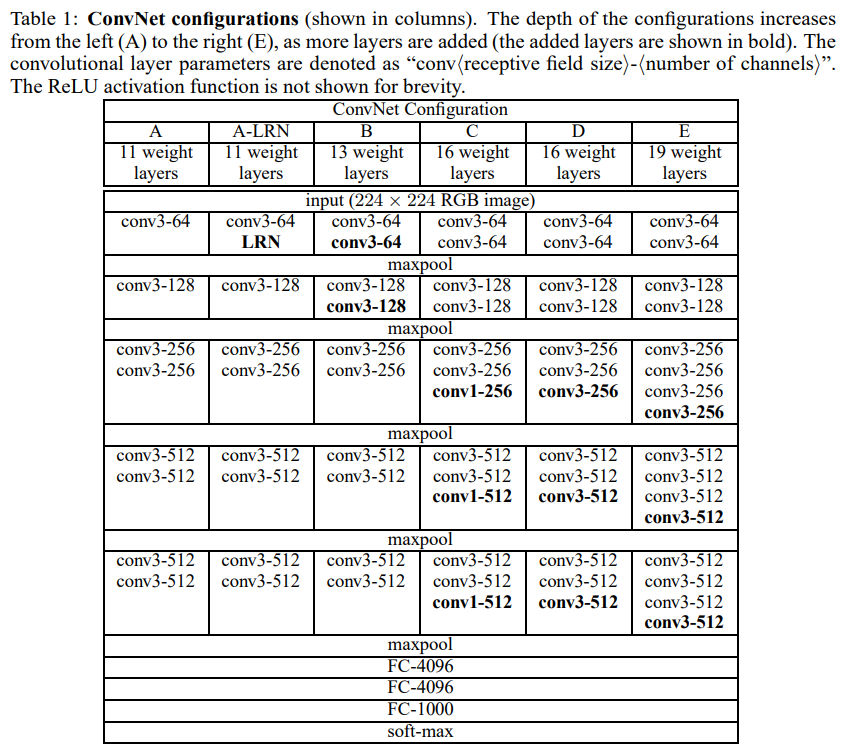
이전 방식들과는 다르게 비교적 작은 크기인 3x3 convolution filter를 깊게 쌓는다는 것이 VGG의 핵심이며, AlexNet, ZFNet은 8개의 layer를 사용하였다면 VGG는 11개, 13개, 16개, 19개 등 더 많은 수의 layer를 사용하고 있습니다. 이렇게 3x3 filter를 중첩하여 쌓는 이유는, 3개의 3x3 conv layer를 중첩하면 1개의 7x7 conv layer와 receptive field가 같아지지만, activation function을 더 많이 사용할 수 있어서 더 많은 비선형성을 얻을 수 있으며, parameter 수도 줄어드는 효과를 얻을 수 있습니다. (3x3x3 = 27 < 7x7 = 49)

VGG의 주요 특징은 cs231n의 강의 자료에 잘 정리가 되어있어서 그대로 인용을 하였습니다.
GoogLeNet(Inception), 2014
다음은 VGG와 같은 해에 제안이 되었고, ILSVRC 2014 대회에서 1위를 한 GoogLeNet 이며, Inception architecture라는 예명도 가지고 있습니다. 이전 network들은 대학 연구팀에서 주로 제안이 되었다면, GoogLeNet을 기점으로 거대 기업들이 뛰어들었다는 점이 주목할 만한 부분입니다. 이름은 Google과 LeNet을 합쳐서 지었다고 합니다.
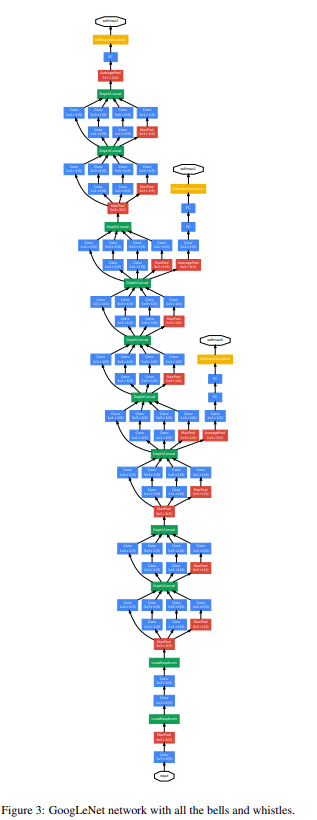
총 22개의 layer로 구성이 되어있으며 architecture 그림을 보면 아시겠지만 굉장히 길고 복잡한 구조로 구성이 되어있습니다. GoogLeNet의 주요 특징들은 Network In Network(NIN), 2014 논문의 영향을 많이 받아서 제안이 되었습니다.
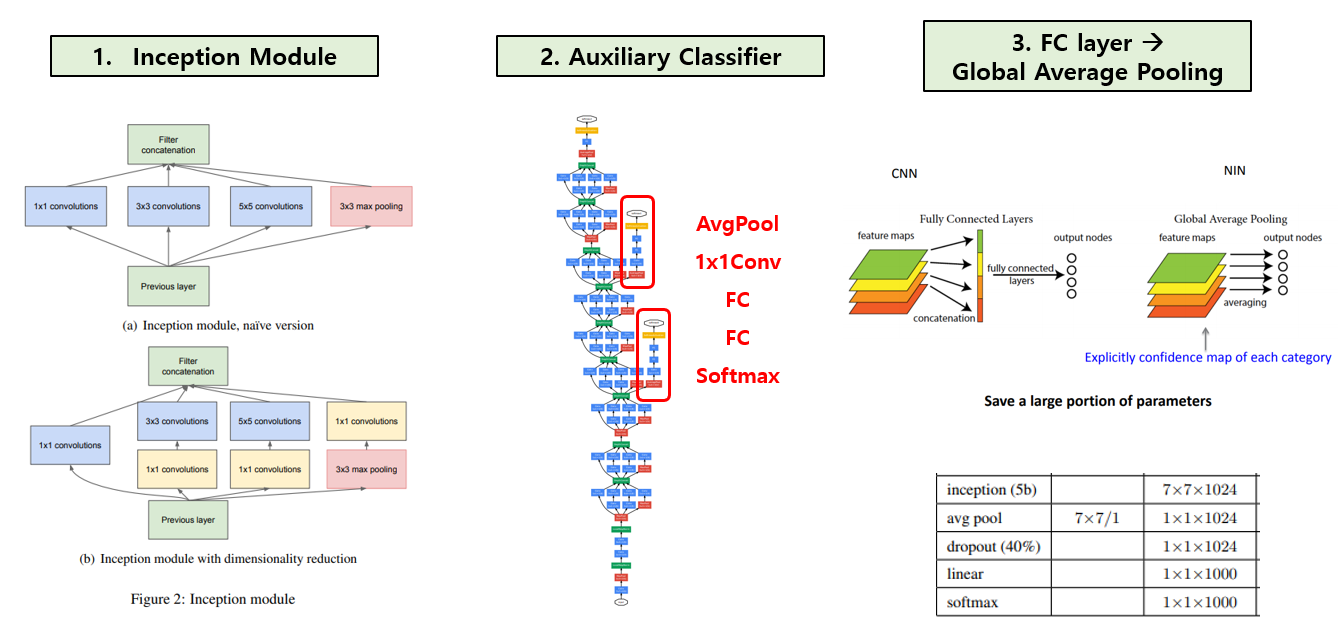
우선 Inception module 이라 불리는 block 구조를 제안하였습니다. 기존에는 각 layer 간에 하나의 convolution 연산, 하나의 pooling 연산으로 연결을 하였다면, inception module은 총 4가지 서로 다른 연산을 거친 뒤 feature map을 channel 방향으로 합치는 concatenation을 이용하고 있다는 점이 가장 큰 특징이며, 다양한 receptive field를 표현하기 위해 1x1, 3x3, 5x5 convolution 연산을 섞어서 사용을 하였습니다. 이 방식을 Naïve Inception module 이라 부릅니다. 여기에 추가로, 3x3 conv, 5x5 conv 연산이 많은 연산량을 차지하기 때문에 두 conv 연산 앞에 1x1 conv 연산을 추가하여서 feature map 개수를 줄인 다음, 다시 3x3 conv 연산과 5x5 conv 연산을 수행하여 feature map 개수를 키워주는 bottleneck 구조를 추가한 Inception module with dimension reduction 방식을 제안하였습니다. 이 덕에 Inception module의 연산량을 절반이상 줄일 수 있습니다.
GoogLeNet은 Inception module을 총 9번 쌓아서 구성이 되며, 3번째와 6번째 Inception module 뒤에 classifier를 추가로 붙여서 총 3개의 classifier를 사용하였고, 이를 Auxiliary Classifier 라 부릅니다. 가장 뒷 부분에 Classifier 하나가 존재하면 input과 가까운 쪽(앞 쪽)에는 gradient가 잘 전파되지 않을 수 있는데, Network의 중간 부분, 앞 부분에 추가로 softmax Classifier를 붙여주어 vanishing gradient를 완화시킬 수 있다고 주장하고 있습니다. 다만 Auxiliary Classifier로 구한 loss는 보조적인 역할을 맡고 있으므로, 기존 가장 뒷 부분에 존재하던 Classifier보단 전체적으로 적은 영향을 주기 위해 0.3을 곱하여 total loss에 더하는 식으로 사용을 하였다고 합니다. 학습 단계에만 사용이 되고 inference 단계에선 사용이 되지 않으며, 이유론 inference 시에 사용하면 성능 향상이 미미하기 때문입니다.
마지막으로 대부분의 CNN의 대부분의 parameter를 차지하고 있는 Fully-Connected Layer를 NIN 논문에서 제안된 방식인 Global Average Pooling(GAP) 으로 대체하여 parameter 수를 크게 줄이는 효과를 얻었습니다. GAP란 각 feature map의 모든 element의 평균을 구하여 하나의 node로 바꿔주는 연산을 뜻하며, feature map의 개수만큼의 node를 output으로 출력하게 됩니다. GoogLeNet에서는 GAP를 거쳐 총 1024개의 node를 만든 뒤 class 개수(ImageNet=1000)의 output을 출력하도록 하나의 Fully-Connected layer만 사용하여 classifier를 구성하였습니다. 그 덕에 AlexNet, ZFNet, VGG 등에 비해 훨씬 적은 수의 parameter를 갖게 되었습니다.
ResNet, 2015
오늘 마지막으로 소개드릴 architecture는 굉장히 유명하고, 지금도 널리 사용되는 ResNet 입니다. Microsoft Research에서 제안한 구조이며 ILSVRC 2015 대회에서 1위를 하였습니다. 확실히 2014년부터 기업이 힘을 쓰기 시작하면서 2015년에도 거대 기업에서 우승을 한 점이 인상깊네요. Architecture의 이름은 본 논문에서 제안한 핵심 아이디어인 Residual Block에서 유래하였으며, 실제로도 이 Residual Block 하나만 알면 architecture를 이해할 수 있을 정도로 단순하면서 효과적인 구조를 제안하였습니다.
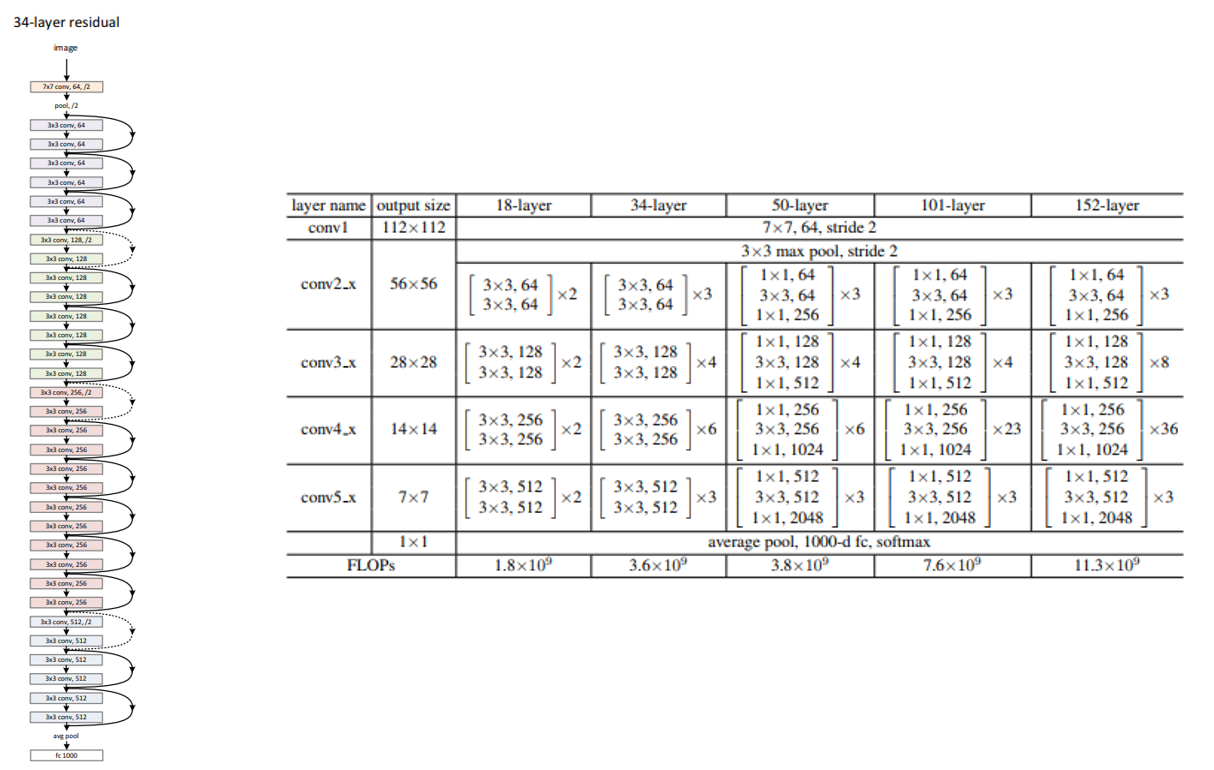
위의 그림의 왼쪽 architecture는 ResNet-34의 구조를 나타내고 있습니다. ResNet은 3x3 conv가 반복된다는 점에서 VGG와 유사한 구조를 가지고 있습니다. Layer의 개수에 따라 ResNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-152 등 5가지 버전으로 나타낼 수 있으며, ILSVRC 2015 대회에선 ResNet-152로 1위를 차지하였습니다. Layer 개수를 많이 사용할수록 연산량과 parameter 개수는 커지지만 정확도도 좋아지는 효과를 얻을 수 있습니다.
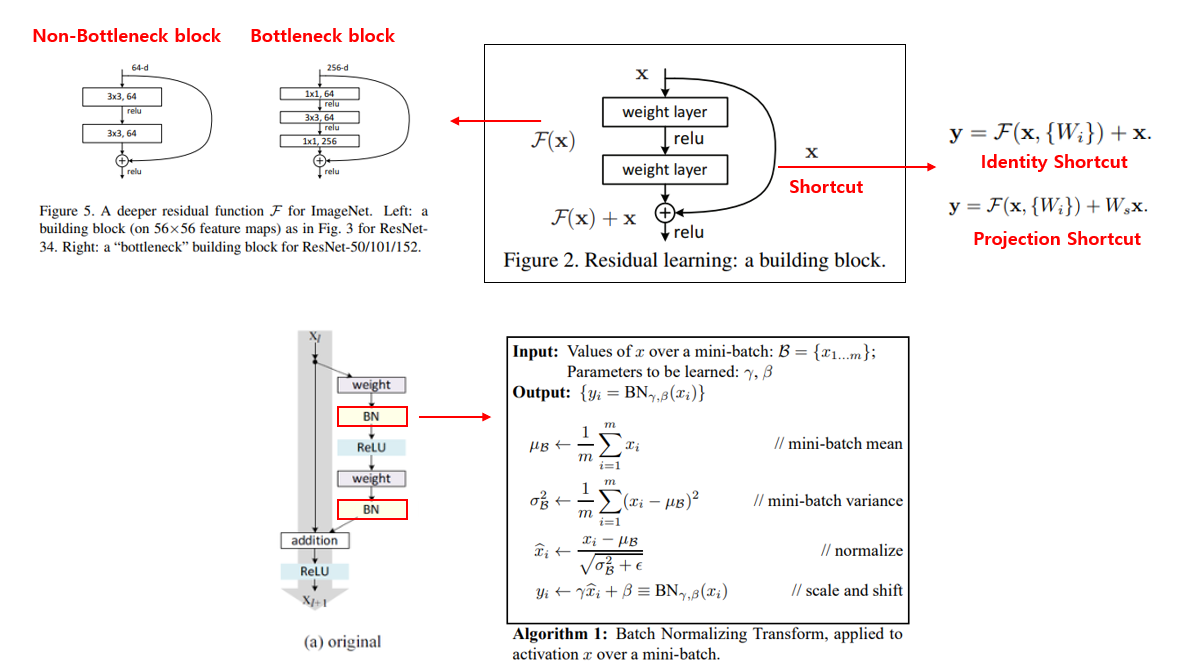
다시 ResNet-34의 그림으로 돌아가면, 2개의 conv layer마다 옆으로 화살표가 빠져나간 뒤 합쳐지는 식으로 그려져 있습니다. 이러한 구조를 Shortcut 이라 부릅니다. 일반적으로 Shortcut으로는 identity shortcut, 즉 input feature map x를 그대로 output에 더해주는 방식을 사용합니다.
하지만, 그림을 자세히 보시면 conv 연산을 나타내는 네모 박스의 색이 output feature map의 개수가 변함에 따라 달라지는 것을 알 수 있으며, 이 때는 Shortcut이 실선이 아니라 점선을 이용하는 것을 알 수 있습니다. Output feature map의 개수가 2배로 커질 때 마다 feature map의 가로, 세로 size는 절반으로 줄여주는 방식을 이용하고 있으며, 이 때는 pooling 대신 stride=2를 갖는 convolution 연산을 이용하는 점이 특징입니다. 이 경우, Shortcut에서도 feature map size를 줄여주어야 하며, 이 때는 identity shortcut 대신 projection shortcut 을 이용합니다. 이러한 shortcut 구조를 통해 vanishing gradient에 강인한 학습을 수행할 수 있게됩니다.
또한 ResNet-50 이상의 모델에서는 feature map의 개수가 많다 보니 연산량도 많아지게 되는데, Inception module에서 보았던 bottleneck 구조를 차용하여 bottleneck residual block 을 중첩하여 사용하는 점이 특징입니다.
마지막으론 같은 2015년에 제안이 되었고, 지금도 굉장히 자주 사용되는 방식인 Batch Normalization(BN) 을 Residual block에 사용을 하였으며, Conv-BN-ReLU 순으로 배치를 하였습니다. 3가지 연산을 어떤 순서로 배치하는지에 따라 성능이 조금 달라질 수 있는데 이와 관련된 논문은 다음 포스팅에서 다룰 예정입니다.
결론
이번 포스팅에서는 딥러닝을 이용한 Image Classification 연구의 시초가 된 1998년 LeNet부터 2015년 ResNet까지 총 6개의 CNN architecture들을 간단히 정리해보았습니다.
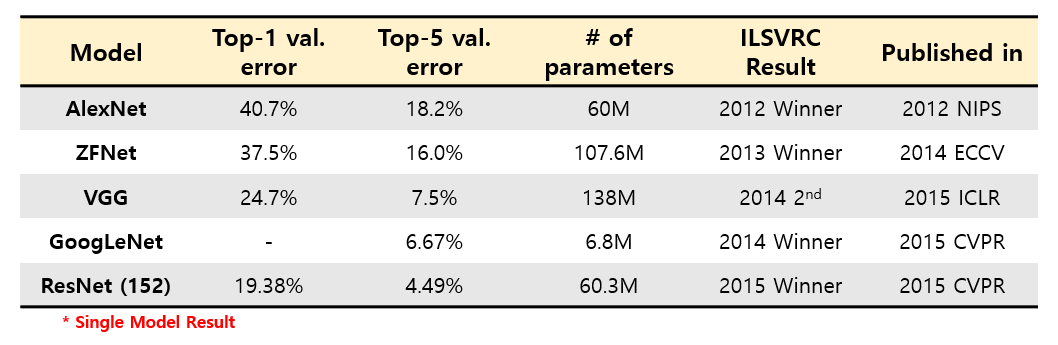
각각 architecture들의 ImageNet validation set에 대한 성능 지표와, parameter 개수 등을 한눈에 보기 좋게 정리를 하였습니다. ZFNet과 ResNet-152의 경우 parameter 개수를 제가 직접 계산을 해서 약간의 차이가 있을 수 있습니다…!
다음 포스팅에서는 오늘 소개 드린 architecture에 이어서 2016년에 제안된 여러 CNN architecture들을 소개드릴 예정입니다. 다음 편을 기대해주세요!
2편으로 이동
위의 버튼을 클릭하세요!
Reference
- Stanford cs231n
- Network In Network, 2014 ICLR Slides
- Identity Mappings in Deep Residual Networks, 2016 ECCV
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 2015 ICML