SNUAI 스터디 7기 발표 내용 소개 및 후기
안녕하세요, 이번 포스팅에서는 제가 운영진으로 활동하고 있는 SNUAI 스터디의 7번째 활동을 마치며 각 발표들에 대해 짧게 리뷰를 드리고, 가볍게 후기 등을 정리해보았습니다.
SNUAI 스터디 소개
우선 SNUAI 스터디에 대해 먼저 소개를 드리고 시작하겠습니다. 스터디 소개 자료를 PPT로 만들었는데, 아래 링크에서도 확인하실 수 있습니다.
SNUAI 스터디는 2016년 7월 서울대학교에서 시작된 스터디 모임이며, 최초에는 SNU TF 라는 이름으로 시작된 모임이며, 이진원님, 이우진님, 최건호님, 곽동현님, 이지민님, 조재민님, 임성빈님들이 운영진 및 구성원으로 꾸준히 운영해 주셨습니다. 그 뒤, 2018년 1월 SNU TF에서 SNUAI로 이름이 바뀌었고 그 뒤로 올해 7기까지 꾸준히 진행이 되어왔습니다. 7기수 동안 약 200번의 발표가 있었고, 현재는 구 운영진 분들은 OB(Alumni)로 전환하시고 새로운 5명의 운영진이 운영 중인 역사가 깊은 스터디입니다.
SNUAI 스터디 7기 발표 요약
이번 SNUAI 7기는 20명의 인원으로 시작하였고 대학원생, 회사원 등 다양한 분야에서 활동하고 계신 구성원 분들이 알찬 발표들을 준비해 주셨습니다. 하나의 스터디에서 Computer Vision, Natural Language Processing, Learning Theory, Quantization, Recommendation System, Audio(Speech) Processing, Forecasting, Graph Neural Network, Medical Image Analysis, Deep Learning Model Compression 등 다양한 주제의 발표가 진행된다는 점이 저희 스터디의 특징이자 자랑거리라 생각합니다!
이제 지난 12주간 다뤄졌던 22번의 발표를 짧게 정리해서 소개 드리겠습니다. 제 블로그 글 외에도 운영진 김경선님이 직접 손수 제작하신 카드 뉴스도 같이 참고하시면 좋을 것 같습니다!
1주차: 이호성(Cognex Deep Learning Lab KR)
우선 첫 주에는 스터디 진행 방식에 대한 오리엔테이션과 제 발표가 진행이 되었습니다.
저는 Semi-Supervised Learning(이하 SSL) 연구에 대한 소개와 대표적인 방법들을 소개 드리고, 가장 최신 논문인 “FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence” 논문을 리뷰하였습니다.
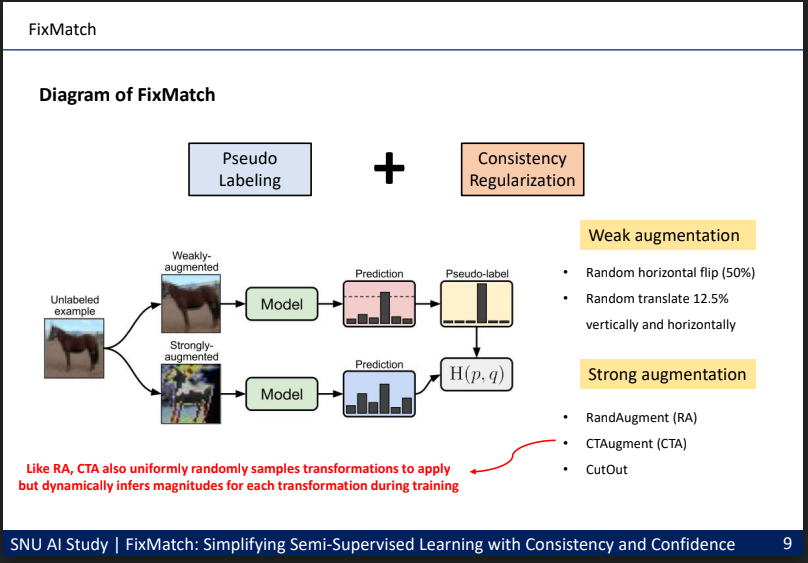
SSL에서 주로 다뤄지던 Pseudo Labeling(Self-Training) 방식과 Consistency Regularization 방식을 결합하여 기존 논문들에 비해 tuning할 부분은 줄어 들어 단순하면서도 효과적인 SSL 방식을 제안한 논문이며, 논문에서 다뤄진 실험들에 대한 요약과 제 개인적인 의견도 자료에 정리하여 발표를 진행하였습니다.
이 논문에 대한 리뷰는 SNUAI 스터디 뿐 만 아니라 TensorFlow KR 그룹에서 운영 중인 PR-12 논문 읽기 모임에서도 발표를 하였고, 발표 영상은 PR-237 YouTube Link 에서 확인하실 수 있습니다.
2주차: 김경선(LG전자), 유인완(Lunit)
2주차에도 운영진으로 활동하고 계신 김경선님과 유인완님이 발표해 주셨습니다.
우선 김경선님은 AAAI 2020 학회에 발표된 Action Recognition 관련 3가지 논문, 대표적인 Action Recognition 데이터셋인 UCF-101을 소개해 주셨습니다.

첫 번째 논문은 NLP에서 주로 사용되는 Co-Attention의 아이디어와 GAN의 아이디어를 Action Recognition에 적용하여 Cross-Domain Action Recognition을 잘하기 위한 방법을 다루고 있습니다. 두 번째 논문은 Volterra filter를 이용해 CNN의 complexity를 낮춰서 input data간의 interaction을 파악할 수 있게 됩니다. 이러한 방식을 이용하여 action recognition의 성능을 높이는 방법을 제안하고 있습니다. 마지막 논문은 하나의 video input에 global한 feature와 local한 feature를 동시에 추출하여 활용하는 방식을 제안하고 있습니다.
두 번째 발표를 맡으신 유인완님은 Multiple Instance Learning에 대한 소개와, 딥러닝을 이용한 2가지 논문을 소개해 주셨습니다.
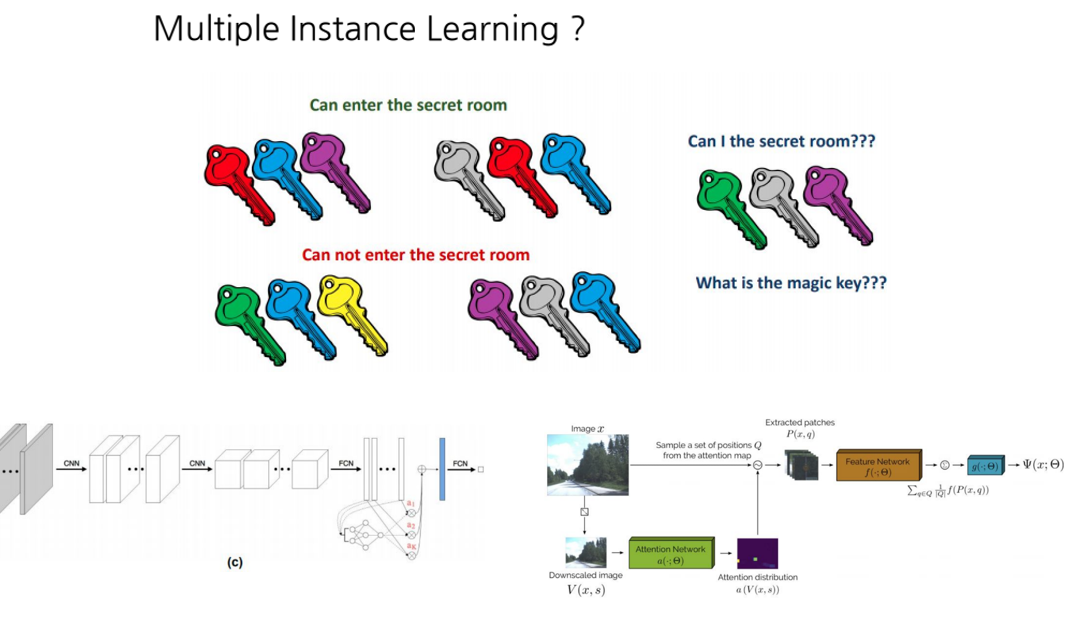
Multiple Instance Learning(이하 MIL)이란 말 그대로 여러 개의 Instance(bag)를 Input으로 하여 Output을 예측하는 문제를 의미하며, 위의 그림과 같이 3개의 열쇠 꾸러미를 주고 문을 열 수 있는지 아닌지를 예측하는 것이 대표적인 예시입니다. 저희에게 친숙한 MNIST에도 MIL 문제로 접근할 수 있습니다. 여러 개의 image가 포함된 하나의 bag에 0이 포함 되어있는지 아닌지를 분류하는 binary classification 문제로 접근할 수 있습니다. 발표에서 다룬 첫 번째 논문은 Attention을 기반으로 한 MIL 방법론을 제안하였고, 두 번째 논문도 Attention과 sampling 기법을 통해 해상도가 큰 image에 대해서 MIL을 적용하는 방법을 다루고 있습니다.
3주차: 한송이(삼성전자)
3주차에도 운영진으로 활동하고 계신 한송이님이 발표해 주셨습니다.
한송이님은 ICCV 2019에 발표된 “Data-Free Quantization Through Weight Equalization and Bias Correction” 논문을 리뷰해 주셨습니다.
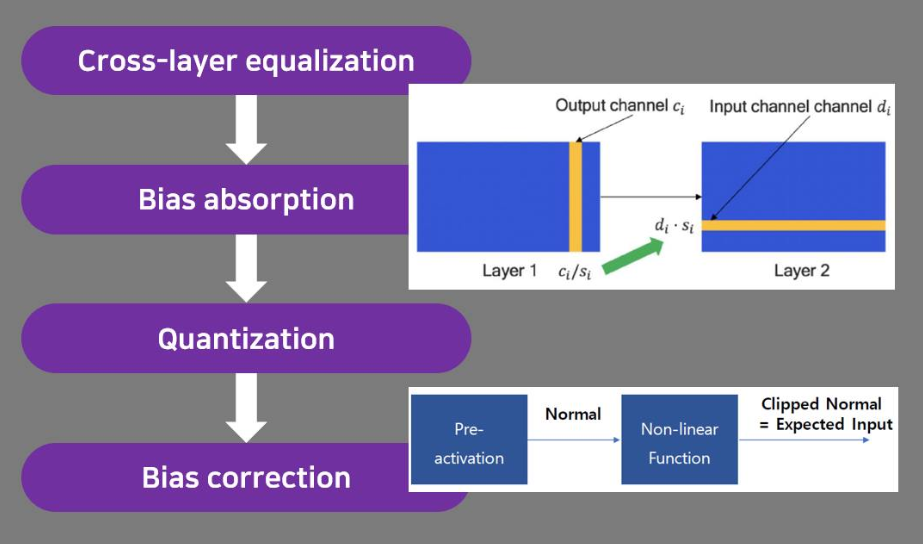
Edge device에서 DNN의 수요가 증가함에 따라, 저전력으로 DNN을 이용하기 위해선 기존의 floating point를 그대로 사용할 수 없어서 fixed point로 숫자를 표현하게 되고, 숫자를 표현하기 위해 사용되는 bit precision도 32bit에서 훨씬 적은 bit로 표현하게 됩니다. 이 때 사용되는 기법이 Quantization이며, 기존에는 추가적인 데이터를 통해 최적의 bit를 찾고, 추가적인 fine tuning, retraining 등을 이용한 Quantization 기법이 주를 이뤘는데, 본 논문에서는 Data와 Training 없이 Quantization하는 방법을 제안하였고, 주로 Quantization에서 애를 먹던 MobileNet에서도 Integer 8bit로 Quantization하였을 때 좋은 성능을 달성할 수 있었습니다.
4주차: 서동우(네이버 오디오플랫폼), 안상준(연세대)
4주차에는 서동우님과 안상준님이 발표해 주셨으며, 전세계적인 코로나 바이러스 창궐로 인해 4주차부터는 온라인으로 스터디가 진행이 되었답니다. ㅠㅠ
우선 서동우님은 Causality에 대한 소개와 이를 다룬 ICLR 2020에 발표된 “A meta-transfer objective for learning to disentangle causal mechanisms” 논문을 리뷰해 주셨습니다.

우선 Causality는 인과 관계라는 의미를 갖고 있으며, 두 확률적 변수의 event에 서로 원인과 결과 관계가 존재하는지를 찾는 것을 목표로 하며, 상관 관계와는 비슷하지만 다른 의미를 가지고 있습니다. 소개주신 논문에서는 causal graph의 relation을 찾기 위해 meta learning을 도입하여 문제를 푸는 방법을 제안하고 있습니다.
두 번째 발표를 맡으신 안상준님은 학습 데이터에 잘못된 label이 존재하는 Noisy Labels 상황에서 robust하게 학습을 하는 방법을 다룬 ICLR 2020에 발표된 “SELF: Learning to Filter Noisy Labels with Self-Ensembling” 논문을 소개해 주셨습니다.
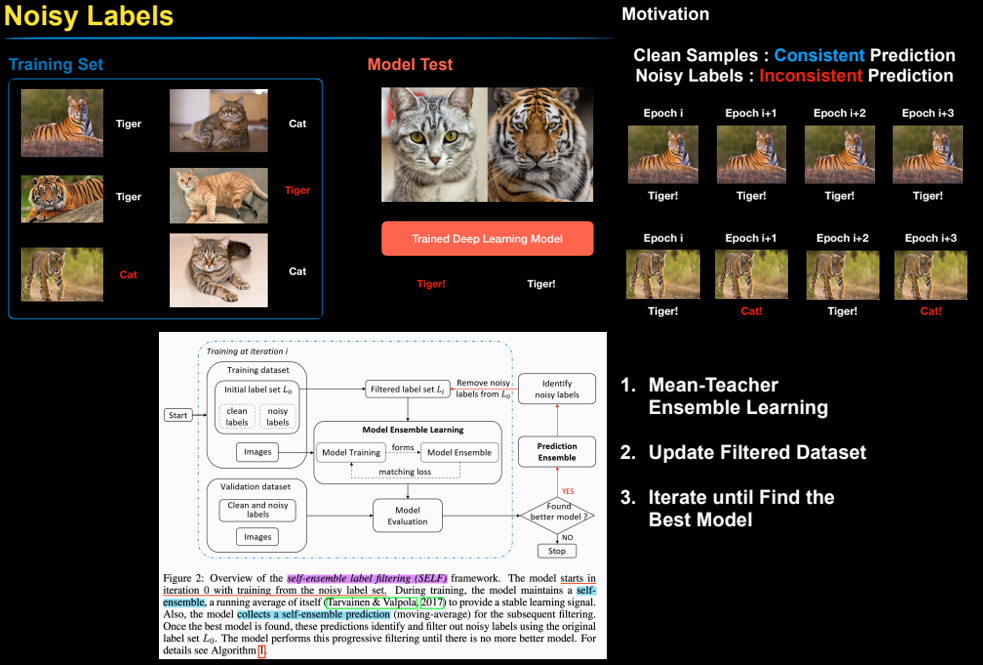
학습 데이터 셋에 Noisy한 Label이 존재한다고 가정했을 때 학습을 시키면 Clean한 sample은 시간(epoch)이 흘러도 일관된 예측을 하지만 Noisy한 sample은 시간이 흐름에 따라 들쭉날쭉한 예측을 한다는 사실에서 출발해서 Model의 self-ensemble(앙상블) 방식을 통해 noisy sample을 filtering하고 이를 이용해 전반적인 알고리즘의 성능을 높이는 SELF 라는 방법을 제안하였습니다.
5주차: 김종진(SKT), 임재수(카카오)
5주차에는 김종진님과 임재수님이 발표해 주셨으며 마찬가지로 온라인으로 진행이 되었습니다.
우선 김종진님은 음색변환 기술을 다룬 “Non-Parallel Sequence-to-Sequence Voice Conversion with Disentangled Linguistic and Speaker Representations” 논문을 소개해 주셨습니다.
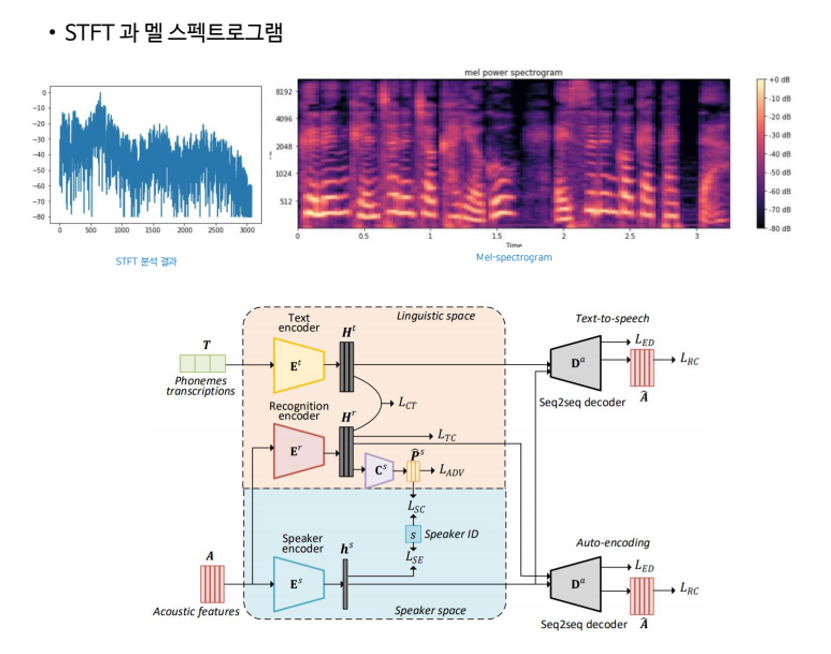
음색변환이란 A 사람의 목소리를 B 사람의 목소리로 바꿔주는 기술을 의미합니다. 즉, 제가 녹음한 파일을 목소리가 좋은 이선균, 한석규 배우의 목소리로 변환을 하는 것을 의미합니다. 하지만 음성 신호에는 언어 성분, 운율 성분, 신호 성분 등 다양한 요소들이 결합이 되어있기 때문에 여기에서 음색만 따로 분리해내는 과정이 필요합니다. 본 논문에서는 음색을 분리하기 위한 Seq2Seq 기반 구조를 제안하고 있습니다.
두 번째 발표를 맡으신 임재수님은 광고, 추천시스템 관련 주제로 발표해 주셨습니다.
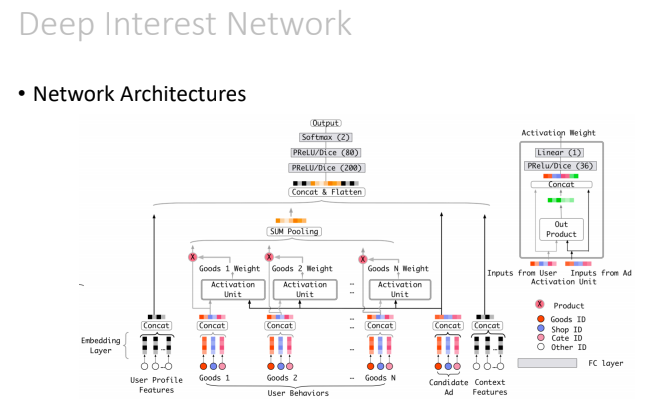
우선 전통적으로 많이 사용되는 Collaborative Filtering 기법부터 Factorized Machine, Deep Learning based Recommender System, CTR in Ad Eco System, 마지막으로 SIGKDD 2018에 발표된 “Deep Interest Network for Click-Through Rate Prediction” 논문까지 소개해 주셨습니다. LSTM, Attention 등을 사용하지 않고 Sum Pooling을 사용한 점이 특징이며, Data Adaptive Activation Function을 사용한 점도 특징입니다.
6주차: 류동민(토모큐브), 류성원(카카오 엔터프라이즈)
6주차에는 류동민님과 류성원님이 발표해 주셨습니다.
류동민님은 토모큐브에서 다루고 있는 문제인 Unsupervised Denoise Method 연구에 대해 소개해 주셨습니다.
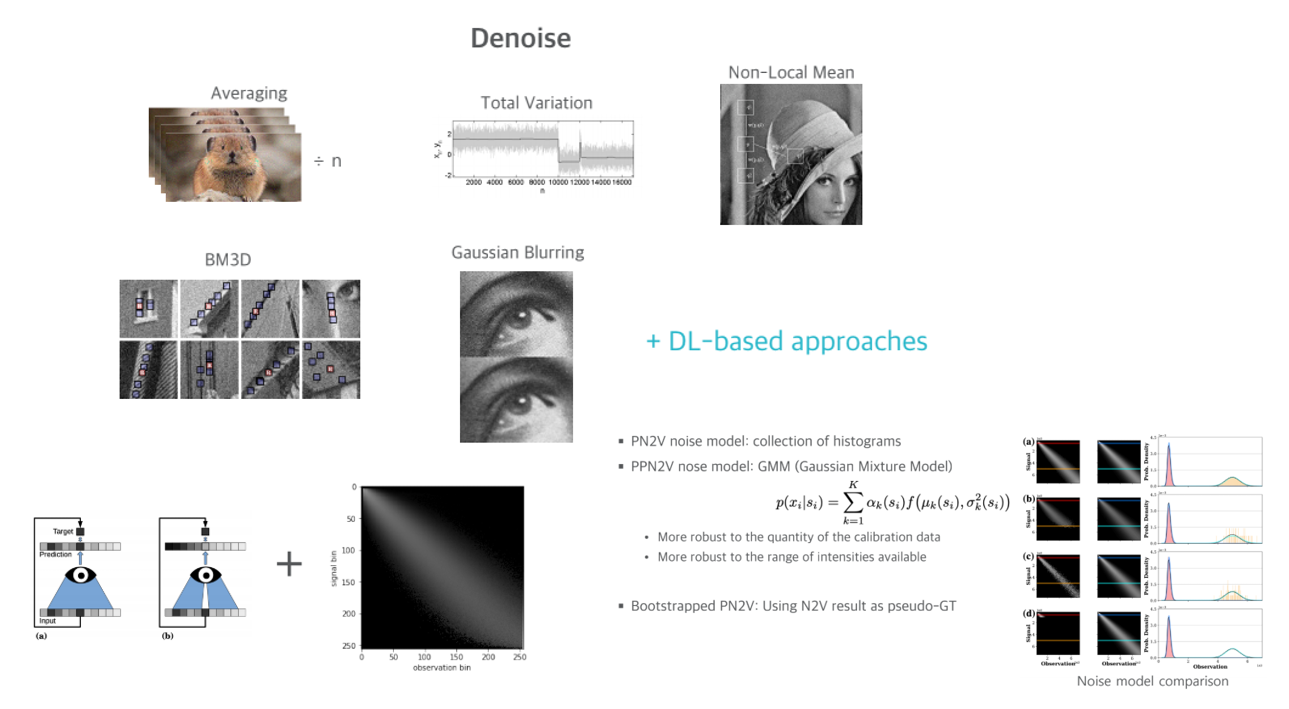
우선 denoise란 image에 존재하는 noise를 제거하는 것을 의미합니다. 전통적인 방식들이 주로 사용이 되다가, 최근 딥러닝 기반 방식들이 제안이 되었습니다. 실제 사용 시나리오를 생각해보면, 같은 물체에 대해 noise가 존재하는 image와 noise가 없는 동일한 image를 동시에 얻는 것은 불가능하기 때문에, 이번 발표에서는 Ground Truth가 없는 환경에서의 Unsupervised Denoise 연구의 대표적인 방법인 Noise2Void(N2V)와 후속 연구인 Probabilistic N2V(PN2V), Parametric PN2V 방법들을 소개해 주셨습니다.
두 번째 발표를 맡으신 류성원님은 Continual(Lifelong) Learning 분야에 대해 소개해 주시고 이를 다룬 2편의 논문 Memory Aware Synapses: Learning what (not) to forget(ECCV 2018), Selfless Sequential Learning(2019 ICLR)을 소개해 주셨습니다.
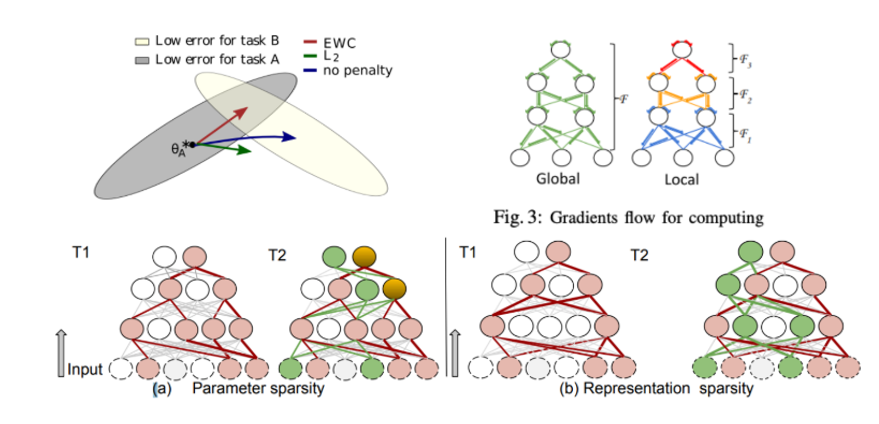
Continual Learning이란 기존에 학습한 지식들을 그대로 유지한 채, 새로운 지식을 학습하는 방법론을 의미하며 Lifelong Learning이라고도 불립니다. 예를 들면 한 classifier가 10가지 종류의 새를 분류하도록 학습을 한 뒤에, 갑자기 10가지 종류의 꽃도 분류를 해야 한다고 가정했을 때 feature extractor 뒷부분에 추가적인 FC layer를 붙여서 fine-tuning을 시켜서 꽃을 학습시키면 기존에 새를 분류하던 성능이 망가지는 문제가 있는데, 떨어지는 성능폭을 줄이기 위한 기법들을 다룬 논문을 소개해 주셨습니다.
7주차: 조진형(현대자동차), 최현영(forcs)
7주차에는 조진형님과 최현영님이 발표해 주셨습니다.
조진형님은 원유 가격을 예측하기 위한 연구에 대해 소개해 주셨습니다.
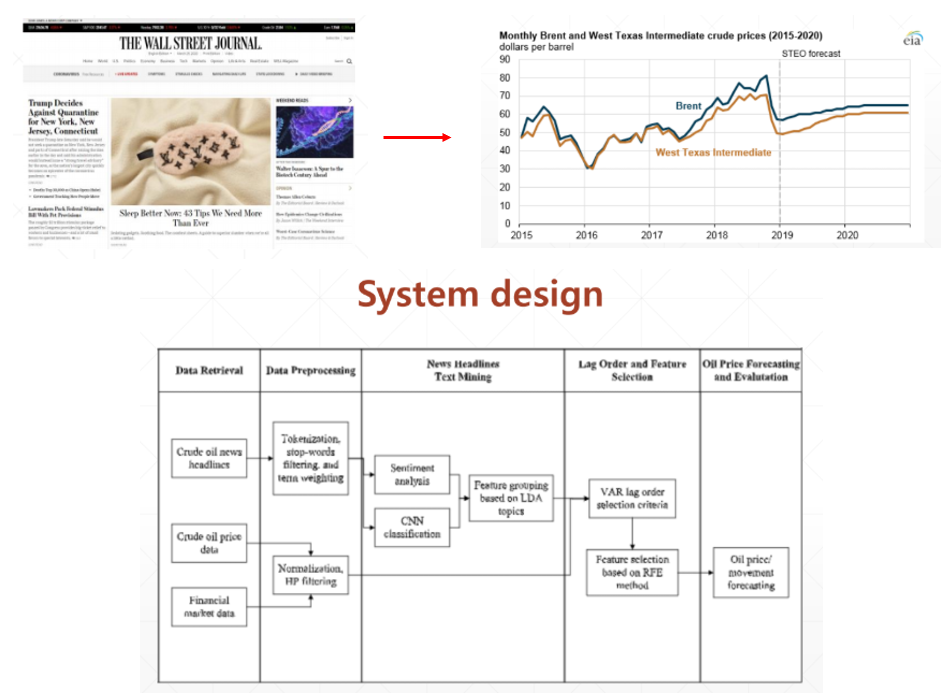
전통적으로 원유 가격 예측은 경제학의 시계열 모형에 기반을 두고 발전해왔고, Neural Network를 이용하여 성능이 많이 발전해왔습니다. 이번 발표에서는 뉴스의 헤드라인의 text mining을 거쳐서 원유 가격을 예측하는 “Text-based crude oil price forecasting: A deep learning approach” 논문을 소개해 주셨습니다.
두 번째 발표를 맡은 최현영님은 Graph Neural Network(GNN)에 대한 소개와, GNN에 Attention mechanism을 적용한 연구들을 소개해 주셨습니다.
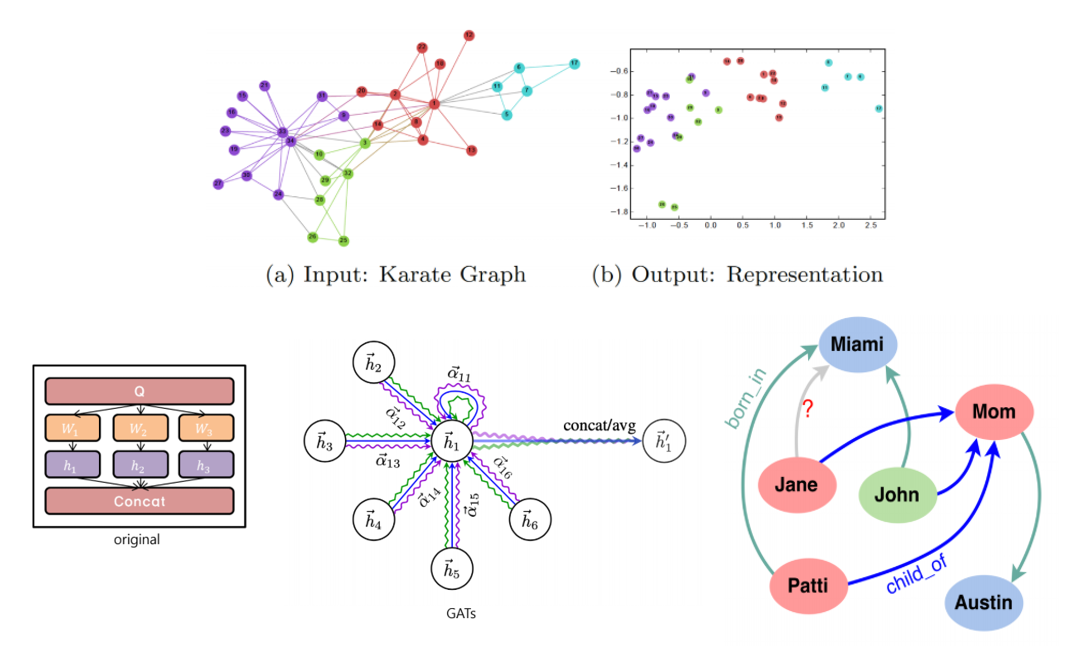
우선 GNN에 Multi head Attention을 붙인 Graph Attention Networks(GATs)에 대해 설명해 주신 뒤, 해당 모델을 Knowledge Graph Completion 분야에 활용하여 State-of-the-art 성능을 달성한 “Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs” 논문에 대해서도 소개해 주셨습니다.
8주차: 홍석일(서울대), 박상수(한양대)
8주차에는 홍석일님과 박상수님이 발표해 주셨습니다.
홍석일님은 CNN 기반으로 Video에서 Human Action Recognition을 하는 대표적인 2가지 논문을 소개해 주셨습니다.
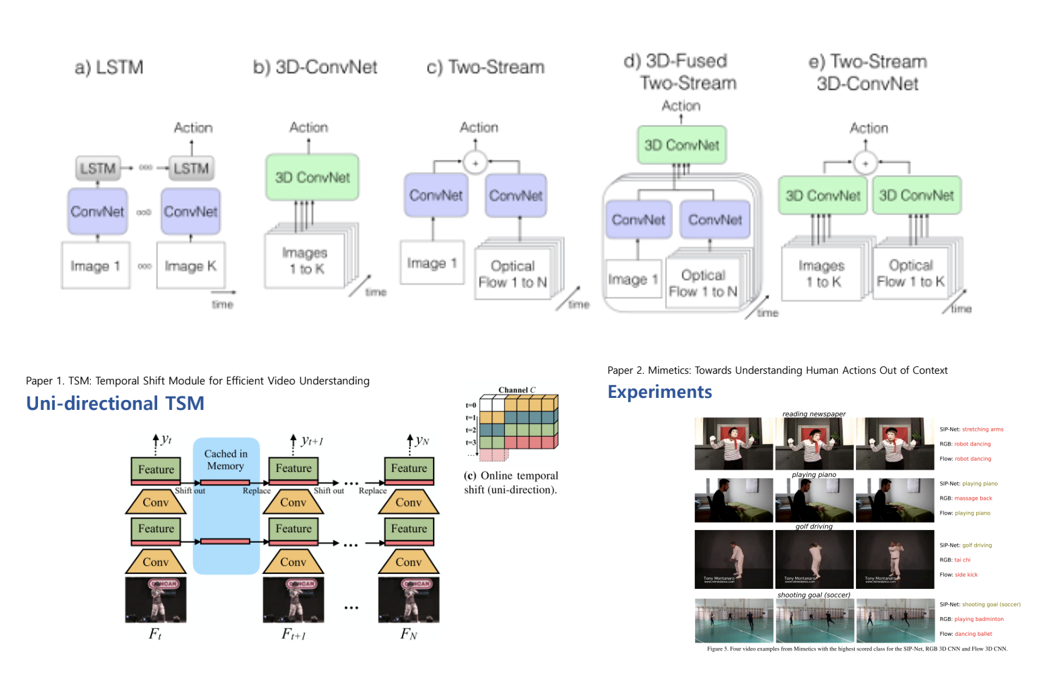
우선 Human Action Recognition이란 사람의 행동이 담긴 비디오를 통해 어떠한 action을 취하고 있는지 classification하는 문제를 뜻하며, LST, 3D-ConvNet을 기반으로 다양한 방법이 제안되어 왔습니다. 첫번째로 계산 효율과 정확도를 동시에 잡기 위해 제안된 “TSM: Temporal Shift Module for Efficient Video Understanding” 논문을 소개해 주셨습니다. 그 뒤, 대부분의 Action Recognition 방법론들이 실제 사람의 action보다는 scene, object 등 다른 context에 집중해서 판단을 하는 문제에 집중해서, 사람의 action에만 집중할 수 있도록 헷갈리는 context들을 곳곳에 배치하여 Mimetics라는 데이터셋을 제작한 뒤 이에 대한 분석을 다룬 “Mimetics: Towards Understanding Human Actions Out of Context” 논문을 소개해 주셨습니다.
두 번째 발표를 맡은 박상수님은 AutoML을 이용한 Neural Architecture Search(NAS) 연구 중에 hardware와 software를 동시에 고려하여 architecture를 찾는 연구에 대해 소개해 주셨습니다.
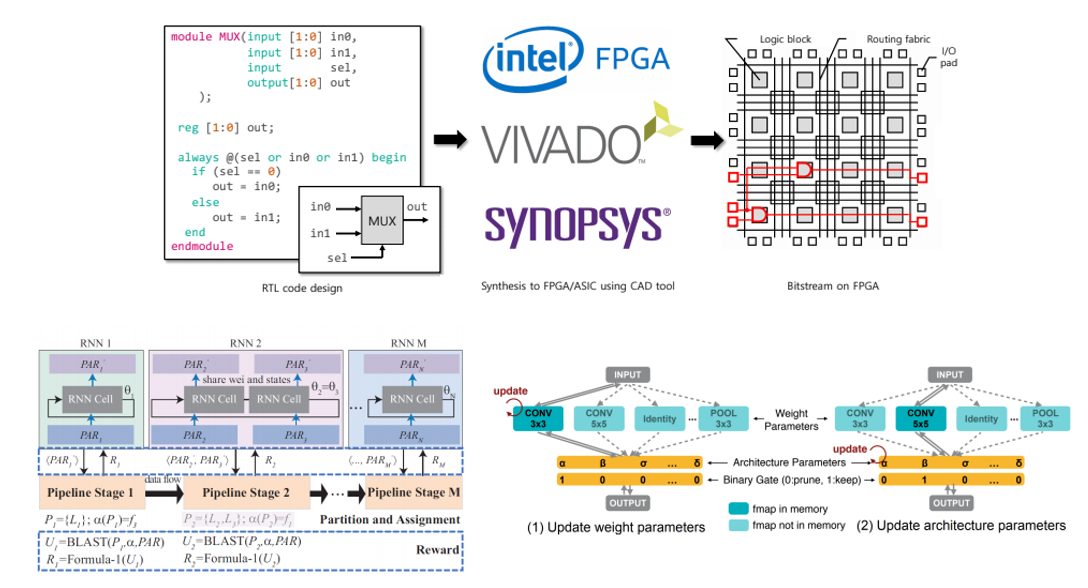
대부분의 NAS 연구들은 대부분 정확도에 초점을 맞춰서 architecture를 search합니다. 이번 발표에서 다룬 “Hardware/Software Co-Exploration of Neural Architectures” 논문은 고정된 hardware(FPGA) platform 하에서 정확도와 높은 throughput을 동시에 달성할 수 있도록 HW와 SW을 동시에 고려하는 NAS 방법론을 제안하고 있습니다. 비슷한 연구로는 Mobile Device에서 latency와 accuracy를 동시에 고려하는 MnasNet 논문과 타겟 task와 hardware에 맞게 NAS를 수행하는 ProxylessNAS 논문 등이 있습니다.
9주차: 이지민(서울대), 이형민(연세대)
9주차에는 SNUAI의 창립 멤버이자 운영진으로 활동하셨던 이지민님의 연사 초청 강연과, 차기 운영진(?!) 이형민님의 발표가 온라인/오프라인 병행으로 진행되었습니다.
우선 이지민님은 방사선의학 분야에 대한 소개와 딥러닝이 접목된 연구들을 소개해 주셨습니다.
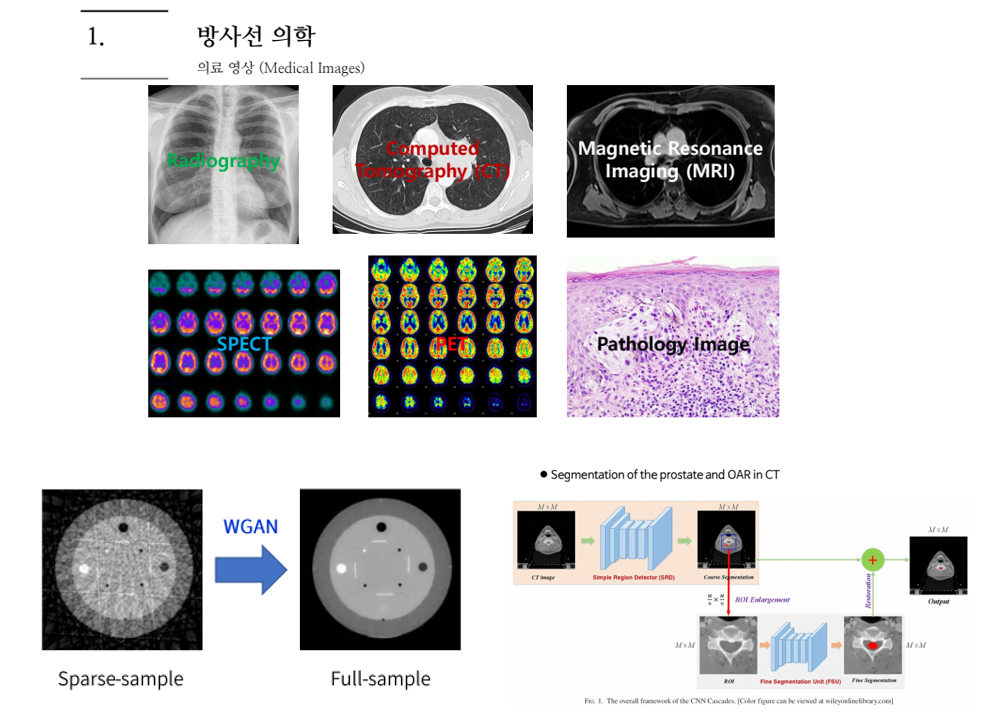
의료 영상은 X-ray, CT, MRI, SPECT, PET 등 다양한 종류의 데이터를 다루며, 데이터 수집과 레이블링이 다른 도메인에 비해 어려운 편에 속합니다. 본 발표에서는 인공지능 기반 의료영상을 처리하는 다양한 연구들을 소개해 주셨고, 몇 개를 간단히 소개 드리자면 우선 제한된 angle과 view에서 촬영한 sparse한 CT sample들을 가지고 WGAN 등 Generative model을 사용하여 Full sample로 변환해주는 연구를 소개해 주셨습니다. 이 외에도 MR로부터 Pseudo CT를 생성하는 연구, X-ray 기반 비파괴 검사 연구, X-ray 기반 수화물 검색 연구 등도 소개해 주셨습니다.
다음 발표를 맡은 이형민님은 Video Frame Interpolation(이하 VFI) 주제로 발표해 주셨습니다.
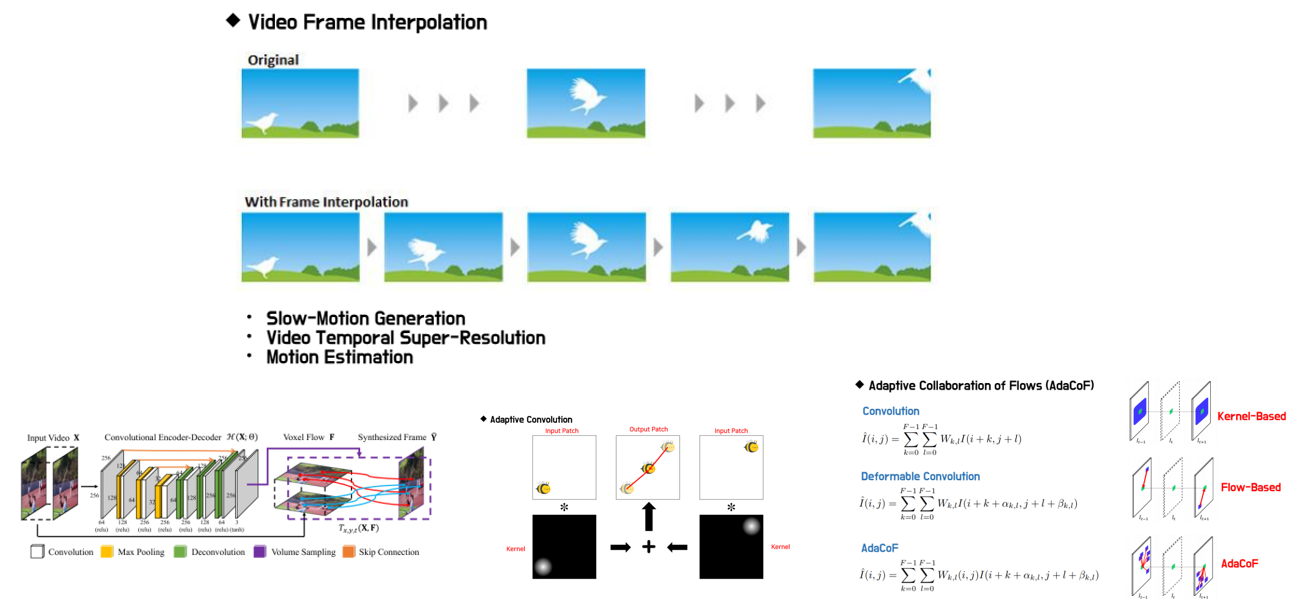
VFI란 video에서 연속하는 frame에서 각 frame의 사이에 존재할 법한 frame을 추정하는 문제를 의미하며, 주로 찾고자 하는 frame의 앞 frame와 뒤 frame을 동시에 고려하여 추정합니다. Motion을 기반으로 주로 연구가 진행되며, Voxel flow를 기반으로 frame을 추정하는 Flow-based VFI 방식과 Kernel을 기반으로 frame을 추정하는 Kernel-based VFI 방식이 있습니다. 발표자 이형민님은 이 두 방식의 장점만을 합쳐서 Adaptive하게 Flow를 합쳐주는 AdaCoF라는 방식을 제안하였고, 이번 CVPR 2020에서 연구 결과를 발표하실 예정입니다. 이 외에도 Optical Flow 기반의 VFI 방식과, 2개 이상의 frame을 보고 VFI를 하는 Quadratic VFI 방식에 대해서도 소개해 주셨습니다.
10주차: 안재만(SavviHub.com), 이홍석(Vuno)
10주차에는 안재만님과 이홍석님이 온/오프라인을 통해 발표를 진행해 주셨습니다.
안재만님은 2015 NIPS에 발표된 “Hidden Technical Debt in Machine Learning Systems” 라는 잘 알려진 논문을 소개해 주셨습니다.
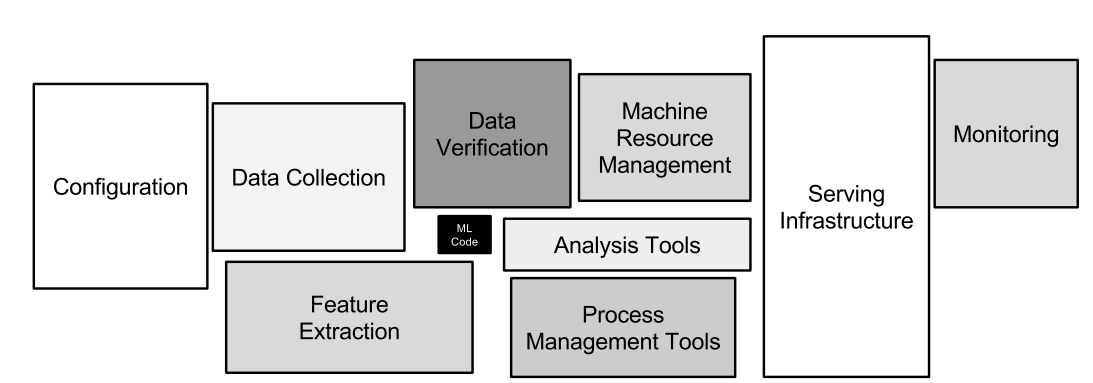
위의 그림은 이 논문의 핵심을 보여주는 그림입니다. 실제론 Machine Learning code는 전체 system에서 차지하는 비중이 적고, 오히려 더 고려해야 할 요소들이 많음을 강조하고 있습니다. Technical Dept란 기술 부채라는 뜻이며 Machine Learning System의 원활한 유지보수를 위해 이들을 잘 관리해야 합니다. code의 리팩토링, code의 history 관리, Data Dependency 제거, Configuration의 체계적인 관리 등 다양한 기술 부채에 대한 solution들을 다루고 있습니다. Machine Learning System의 생태계(?!)를 잘 요약해 주셔서 도움이 많이 된 발표였습니다!
두 번째 발표를 맡은 이홍석님은 의료 영상에 대한 전반적인 소개와, 조직 병리 image에서 Instance Segmentation을 하기 위해 제안된 “Hover-Net: Simultaneous Segmentation and Classification of Nuclei in Multi-Tissue Histology Images” 논문을 소개해 주셨습니다.
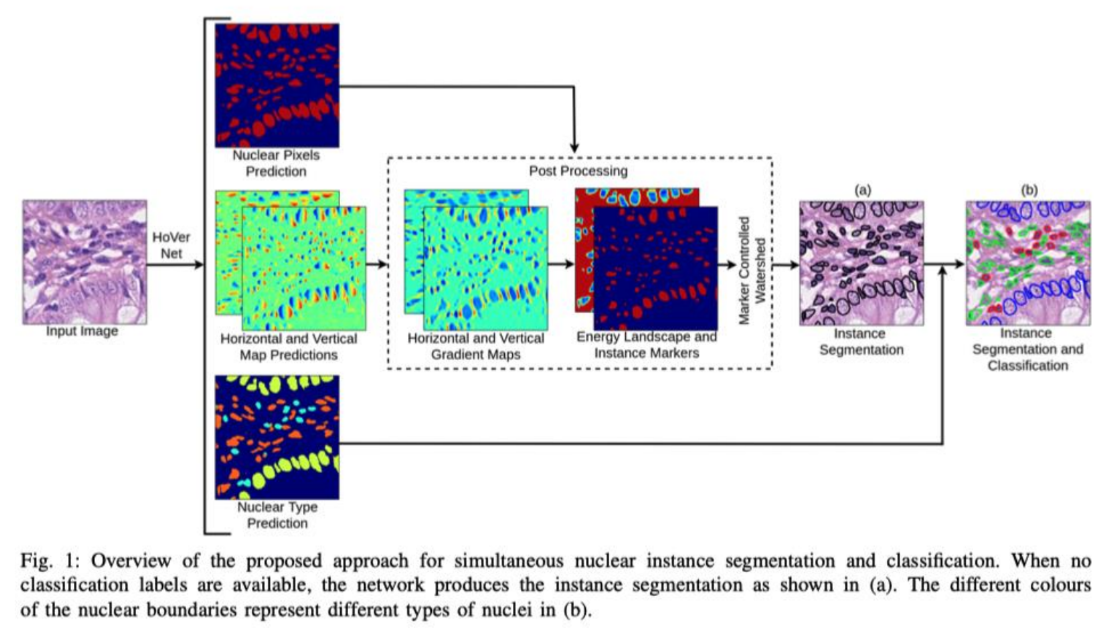
조직 병리학이란 조직, 세포 변화 등을 육안, 현미경, 조직 화학 변화 관찰 등을 이용하여 신체 조직을 연구하는 병리학이며(위키백과 출처) 다양한 조직의 형태가 존재하고, 같은 class에 속하는 조직도 다양한 모양을 가지고 있고 occlusion도 존재할 수 있어서 난이도가 어려운 image에 속합니다. 이러한 문제를 해결하기 위해 본 논문에서는 단순히 Instance Segmentation만 하는 방식을 Nuclear pixel을 예측하는 branch와 Nuclear type을 예측하는 branch, 마지막으로 occlusion 등에 강인한 예측을 하기 위해 Horizontal, Vertical Map을 예측하는 branch 총 3개의 branch로 multi-task로 학습을 시키는 방식을 통해 좋은 성능을 달성할 수 있음을 보여주고 있습니다.
11주차: 정욱재(스캐터랩), 공서택(Vuno)
11주차에는 정욱재님과 공서택님이 마찬가지로 온/오프라인을 통해 발표를 진행해 주셨습니다.
정욱재님은 NLP에서 굉장히 많은 관심을 받고 있는 BERT를 한 번의 학습으로 Adaptive하게 Width와 Depth를 조절할 수 있는 방법을 제안한 “DynaBERT: Dynamic BERT with Adaptive Width and Depth” 논문을 소개해 주셨습니다.
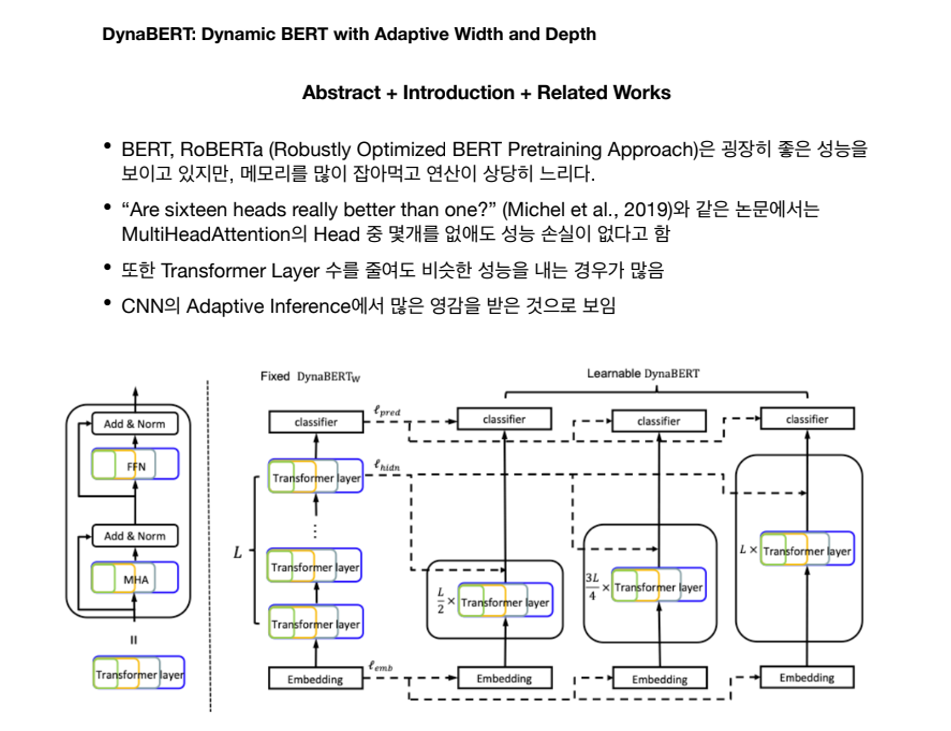
BERT는 Transformer 기반으로 Masked LM을 이용한 Pre-training을 통해 기존 방법들 대비 압도적인 성능을 달성하며 유명해진 방법론입니다. 다만 BERT에는 Multi head attention의 head 몇 개를 없애도 성능 손실이 없는 등 많은 부분에서 redundancy가 존재합니다. 이러한 점에서 착안해서, CNN의 Slimmable Neural Network 방식에서 아이디어를 얻어서 하나의 network 내에서 adaptive하게 model의 size를 조절하는 방법인 DynaBERT를 제안하였습니다. 이를 통해 한번의 학습으로 model size를 조절하며 연산량과 정확도의 trade-off를 조절할 수 있게 되었고, redundancy를 제거하여 성능이 약간 향상되는 결과도 보여주고 있습니다.
두 번째 발표를 맡은 공서택님은 Online Learning (Optimization) / Game Theory 주제로 발표해 주셨습니다.

알파고는 강화학습을 기반으로 바둑을 두는 모델입니다. 1:1 포커 게임에서도 AI를 접목시킬 수 있으며, 프로선수 급 실력을 갖춘 Libratus, DeepStack 모델의 핵심이 되는 Game Theory의 전반적인 내용을 소개해 주셨습니다. 포커와 같은 Imperfect information game을 다루기 위해 Regret Minimization 알고리즘이 2007년 제안이 되었고, 나아가서 online으로 optimization을 하기 위해 제안된 Optimistic Regret Minimization for Extensive-Form Games via Dilated Distance-Generating Functions(NeurIPS 2019) 논문도 소개해 주셨습니다. 공부해본 적 없던 Online learning, Game Theory 관련 내용을 핵심만 잘 요약해주셔서 다 이해하진 못했지만 감은 잡을 수 있었던 발표였습니다.. 하하…
12주차: 김태오(연세대), 이진원(삼성전자)
마지막 주차에는 현 운영진인 김태오님의 발표와 구 운영진인 이진원님의 초청 강연이 진행되었습니다.
김태오님은 얼굴 인식 분야에 대한 전반적인 내용을 Tutorial 형태로 소개해 주셨습니다.
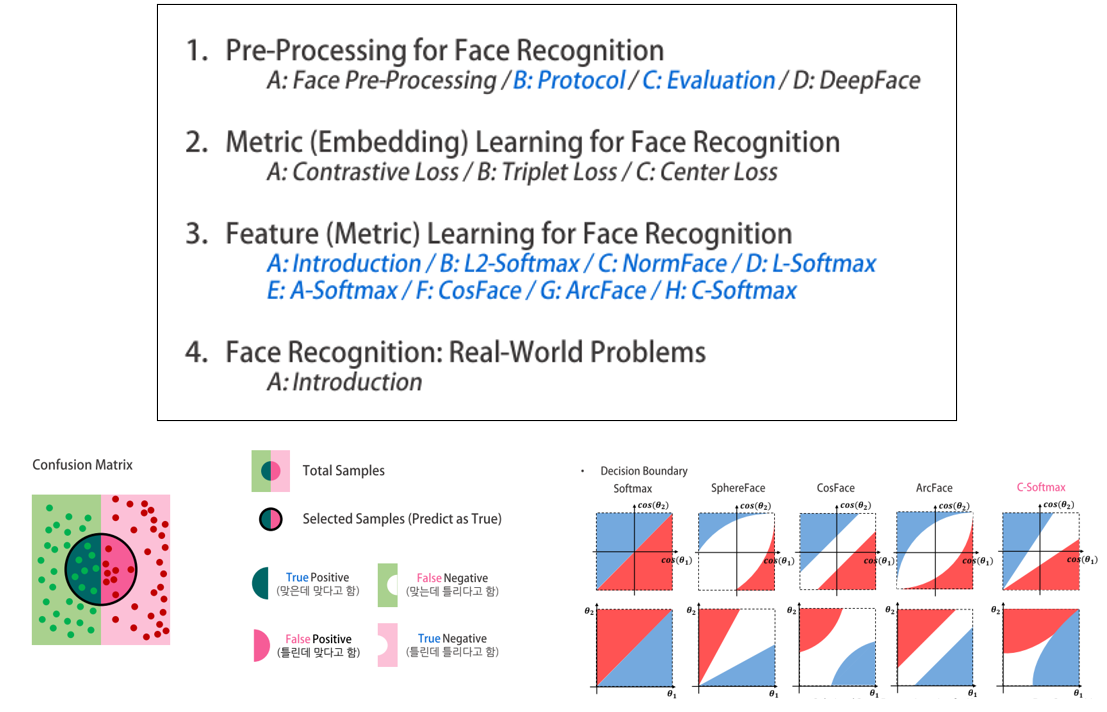
얼굴 인식은 보통 Face Detection을 거쳐 얼굴 영역을 찾은 뒤 Face Alignment, Anti-Spoofing 등의 전처리를 통해 input data로 만들어지는 과정을 거칩니다. 얼굴 인식은 두 얼굴 image를 주고 같은 사람인지 아닌지를 binary classification하는 Verification 문제와, 지정된(등록된) 여러 사람들의 얼굴을 Gallery로 만든 뒤, input이 Gallery의 몇 번째 ID인지를 맞히는 Identification 문제로 나뉘며, Train Class와 Test Class가 다를 수 있는 Open Set Problem입니다. 그래서 보통 Classification에서 사용되는 Softmax 대신 Similarity 기반으로 학습을 시키는 Metric Learning, Feature Learning 방식이 주로 사용됩니다. 각 접근 방식들의 대표적인 방법론들을 요약해 주셨고, 얼굴 인식의 Evaluation Protocol에 대해서도 자세히 다루어 주셨습니다.
이번 SNUAI 7기의 마지막 발표를 맡은 이진원님은 On-Device AI를 위한 Deep Learning Model의 Compression을 주제로 발표해 주셨습니다.
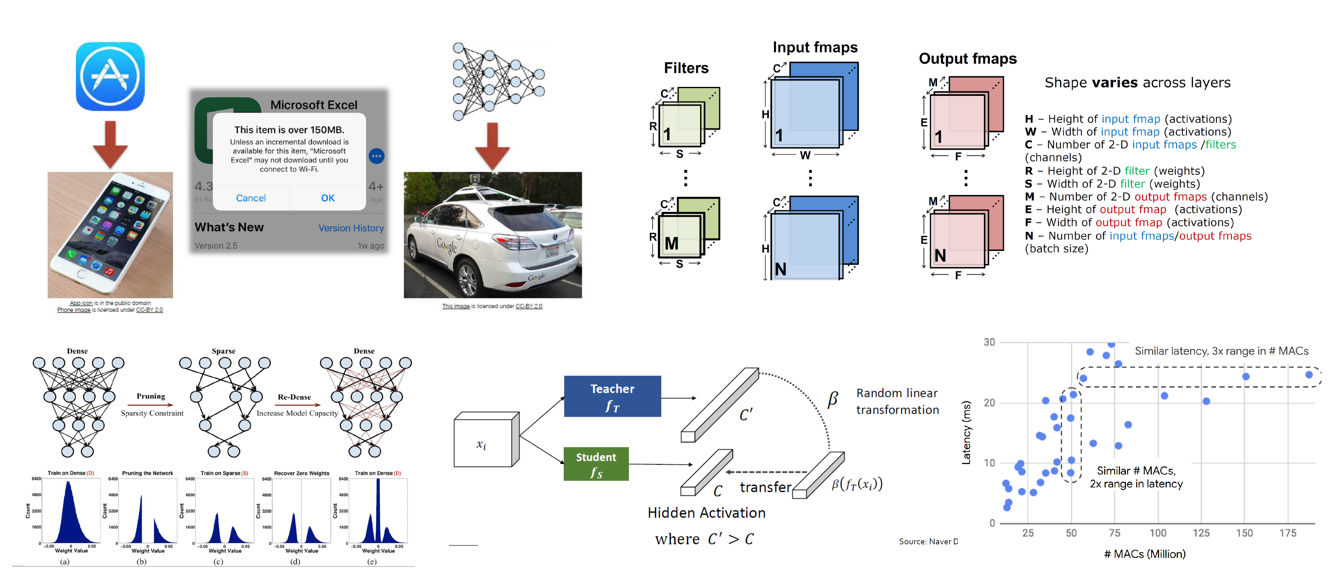
Deep Learning Model 연구의 흐름은 일단은 정확도를 높이는 데 초점을 두고 연구가 주로 진행이 되어왔습니다. 사람의 수준을 뛰어넘기 시작하고 점점 더 정확해졌지만, 그에 따라서 굉장히 많은 연산량을 필요로 하게 되었고, 학습을 시키기 위해 굉장히 많은 시간과 전력이 소모가 되어왔습니다. 그래서 점차 model의 크기를 줄이는 방법에 대한 연구도 진행이 되기 시작하였고, 실생활에서 Device 내에서 Deep Learning을 사용하기 위한 연구들도 진행이 되어왔습니다. 대표적인 방법으로는 Reduced Precision (Quantization), Sparsity(Pruning), Knowledge Distillation, Efficient Network Architecture 등이 있으며, 각 방법마다 대표적인 논문들을 소개해 주셨습니다. (자료의 양이 어마어마합니다! 양질의 자료!) 또한 단순히 연산 량(FLOPS)만 고려하면 안되고, 실제 throughput에 영향을 미치는 요소에는 어떤 것들이 있는지도 자세히 설명해 주셨습니다. Deep Learning 경량화에 관심이 있으신 분들은 꼭 이 자료를 참고하시는 것을 강력 추천 드립니다!
SNUAI 7기를 마무리하며
지난 3달간의 대장정이 이번주에 마무리되었는데요, 이번 기수도 다양한 분야의 주제를 접할 수 있어서 개인적으로도 많은 성장을 할 수 있었다고 생각합니다. 각 연구 분야의 최신 연구 동향을 한 자리에서 들을 수 있다는 점이 가장 큰 장점이라고 생각이 됩니다. 비록, 예기치 못한 코로나 바이러스로 인해 대부분의 스터디가 온라인으로 진행이 되어서 구성원 분들과 많은 이야기를 나누지 못한 점이 아쉽긴 하지만, 무사히 마칠 수 있게 친절히 협조해 주셔서 감사드린다는 말씀 전하고 싶습니다. SNUAI 스터디는 재충전의 시간을 보낸 뒤 8기로 다시 찾아 뵐 예정입니다! 다음 기수도 많은 관심 부탁드립니다!
comments powered by Disqus