YOLOv4:Optimal Speed and Accuracy of Object Detection Review
안녕하세요, 오늘은 지난 4월 23일 arXiv에 공개된 “YOLOv4:Optimal Speed and Accuracy of Object Detection” 논문을 자세히 리뷰할 예정입니다.
YOLO는 Object Detection을 공부하시는 분들이라면 다들 들어 보셨을 것이라 생각합니다. Object Detection은 크게 2-Stage 와 1-Stage Detector로 분류가 되며, 정확도를 약간 포기하는 대신 속도를 챙긴 1-Stage Detector의 대표적인 모델이며 v1, v2, v3에 이어 이번에 4번째 버전이 공개가 되었습니다. (이번엔 YOLO의 아버지인 Joseph Redmon이 빠졌습니다..! ㅠ)
- You Only Look Once: Unified, Real-Time Object Detection
- YOLO9000: Better, Faster, Stronger
- YOLOv3: An Incremental Improvement
Object Detection에 대한 기본적인 내용을 공부하고 싶으신 분들은 제 블로그에 총 9편의 Object Detection Tutorial 이 존재하니 같이 참고하셔도 좋을 것 같습니다!
Introduction
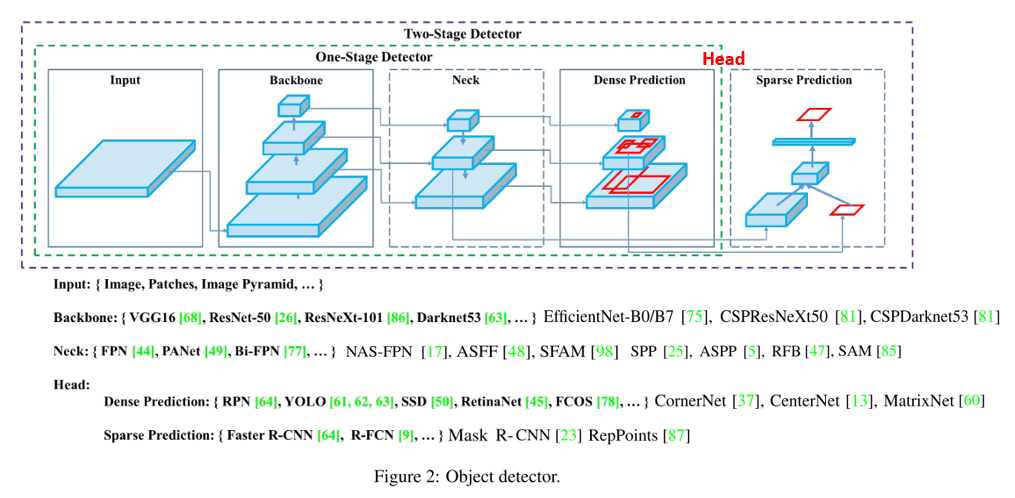
Object Detection에 대한 연구는 R-CNN을 시작으로 굉장히 다양한 연구가 단기간에 진행되었고, 이 글을 작성하고 있는 시점인 2020년 중순에도 많은 논문이 나오고 있습니다.
제가 Object Detection에 딥러닝을 적용한 논문들을 시간 순서에 따라 정리를 하고 있는 repository에 2020 CVPR까지 정리를 하였는데, 최근에는 새로운 모델을 제안하는 논문은 예전만큼 많지는 않고, Object Detection의 임계 성능을 높이기 위해 AutoML, Semi-Supervised Learning 등을 적용하는 시도가 주를 이루고 있습니다. 저는 이제 단일 모델에 대한 연구는 어느 정도 포화가 되었다고 생각을 했었는데, 잠시 잊고 있었던 YOLO의 4번째 버전이 공개되어서 반가웠습니다.
저 또한 회사에서 Object Detection 알고리즘을 구현하여 현업에 적용을 하고 있지만 아직까지 실생활에서 실시간 동작이 가능할 만큼 성능이 완벽하지 않은 것이 현실입니다. 저자들도 Object Detection은 대부분 수 초에 걸쳐 detection이 처리되는 주차장에서 빈 자리 찾기, 공항 X-ray image에서 위험 물질 검출과 같은 상황에서 대부분 사용이 될 뿐, 실시간 동작이 필수적인 자율 주행 자동차 등에서는 아직 완벽하게 사용이 되기 어렵다고 강조하고 있습니다.
이러한 한계를 극복하기 위해 저자들은 원래의 전략처럼 매우 빠르고 꽤 정확한 모델을 설계하는 데 집중하였습니다. YOLO의 새로운 버전이 출시되는 사이에 학계에서도 굉장히 다양한 기법들이 제안이 되어왔는데요, 본 논문에서는 학계에서 좋은 성능을 보이는 여러가지 기법들을 YOLO에 적용하여 성능 향상을 이뤘습니다. 논문에서는 이러한 기법들을 Bag or Freebies, Bag of Specials라 부르고 있으며, 각 기법들의 효과를 분석하였고, 기존 방법을 개선하는 결과도 보였습니다. 본 논문의 Main Contribution은 다음과 같습니다.
- Develop an efficient and powerful object detection models. It makes everyone can use just single GPU ( 1080 Ti or 2080 Ti)
- Verify the influence of SOTA Bag of Freebies and Bag of Specials methods
- Modify SOTA methods and make them more efficient and suitable for single GPU training
본문으로 들어가기에 앞서 YOLO의 v1~v3까지를 하나의 그림으로 요약하면 다음과 같습니다.
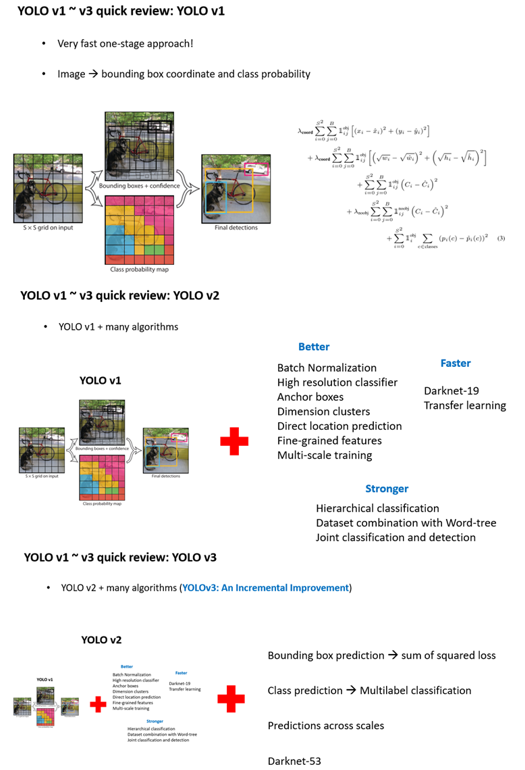
제가 현재 참여 중인 PR-12 논문 읽기 모임에서 YOLOv1 ~ v3을 한국어로 잘 설명해주신 발표 영상이 있으니 같이 참고하셔서 공부하시면 좋을 것 같습니다. 참고로 오늘 소개드릴 YOLOv4는 제가 PR-12 논문 읽기 모임에서 최근 발표했고, 발표 영상은 하단 링크에서 확인하실 수 있습니다.
- PR-016: You only look once: Unified, real-time object detection
- PR-023: YOLO9000: Better, Faster, Stronger
- PR-207: YOLOv3: An Incremental Improvement
- PR-249: YOLOv4: Optimal Speed and Accuracy of Object Detection
Bag of Freebies
본 논문에서는 YOLO에 적용한 기법들을 2가지 유형으로 나눠서 설명하고 있습니다. 우선 Bag of Freebies는 Data augmentation, Loss function, Regularization 등 학습에 관여하는 요소로, training cost를 증가시켜서 정확도를 높이는 방법들을 의미합니다.

Data Augmentation으로는 image의 일부 영역에 box를 생성하고 해당 영역을 0~255의 random한 값으로 채우는 Random erase, 0으로 채우는 CutOut, 두 image와 label을 alpha blending하는 MixUp, CutOut과 MixUp을 응용한 CutMix, Style-transfer GAN 등의 기법을 사용하였습니다.
Regularization 기법으로는 DropOut, DropPath, Spatial DropOut, DropBlock 등을 이용하였고, Bounding Box Regression에 사용되는 Loss function으로는 MSE, IoU, Generalized IoU, Complete IoU, Distance IoU 등 다양한 기법을 사용하였습니다.
이번 포스팅에서는 이 다양한 기법들을 하나 하나 설명드리진 않을 예정이며, 관심있으신 분들은 각 방법론들의 논문을 참고하시기 바랍니다.
Bag of Specials
Bag of Specials는 architecture 관점에서의 기법들이 주를 이루고, post processing도 포함이 되어 있으며, 오로지 inference cost만 증가시켜서 정확도를 높이는 기법들을 의미합니다. 앞의 Bag of Freebies는 학습과 관련된 요소였다면, Bag of Specials는 학습에서는 Forward pass만 영향을 주고, 학습된 모델에 대해 Inference를 하는 부분에 관여를 한다는 점이 차이입니다. (사실 왜 구분을 하였는지 잘 모르겠습니다 ㅎㅎ)
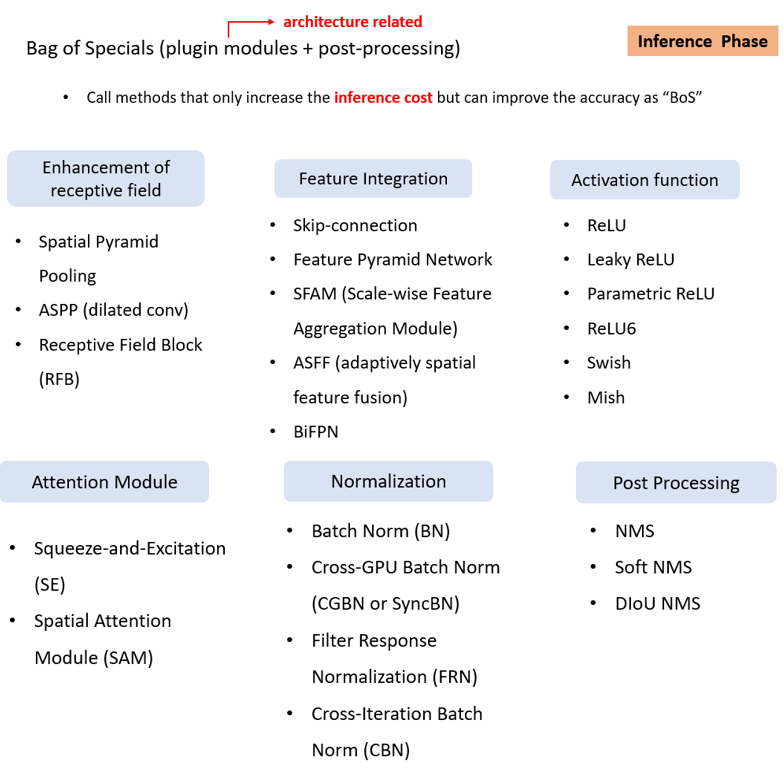
Receptive Field를 키워서 검출 성능을 높이기 위해 제안된 Spatial Pyramid Pooling (SPP), atrous convolution(dilated convolution)을 적용한 ASPP, Receptive Field Block (RFB) 등을 사용하였고, Feature를 중간에서 합쳐주는 Skip-connection, Feature Pyramid Network (FPN), Scale wise Feature Aggregation Module (SFAM), adaptively spatial feature fusion (ASFF), BiFPN 등을 사용하였습니다.
Activation Function으로는 자주 이용되는 ReLU 계열의 activation function과 AutoML로 찾은 Swish, Swish를 개선시킨 Mish 등을 사용하였습니다.
Attention module에는 Squeeze-and-Excitation Module (SE), Spatial Attention Module (SAM)을 사용하였고, Normalization은 가장 많이 사용되는 Batch Normalization 외에 Filter Response Normalization (FRN), Cross-Iterative Batch Normalization (CBN)을 사용하였고, 본 논문에서는 1개의 GPU로 YOLOv4를 사용하는 것을 목표로 하였기 때문에 Cross-GPU Batch Normalization은 사용하지 않았습니다.
마지막으로 Post Processing에는 예측된 Bounding box들 중 중복된 Bounding box들을 하나로 합쳐주는 Non Maximum Suppression (NMS), Soft NMS, DIoU NMS 등을 사용하였습니다.
YOLOv4
이제 YOLOv4의 architecture에 대해 설명을 드리겠습니다. 우선 YOLO의 고질적인 문제로 작은 object에 취약한 점이 있는데, 다양한 작은 object들을 잘 검출하기 위해 input resolution을 크게 사용하였습니다. 기존에는 224, 256 등의 resolution을 이용하여 학습을 시켰다면, YOLOv4에서는 512을 사용하였습니다.
또한 receptive field를 물리적으로 키워 주기 위해 layer 수를 늘렸으며, 하나의 image에서 다양한 종류, 다양한 크기의 object들을 동시에 검출하려면 높은 표현력이 필요하기 때문에 parameter 수를 키워주었습니다.
다만 이렇게 정확도 관점에서 좋은 방향의 변화를 주면 당연히 속도 관점에서 손해를 보게 되겠죠? 그래서 본 논문에서는 2020년 CVPR Workshop에 발표될 예정인 CSPNet 기반의 backbone을 설계하여 사용하였습니다.
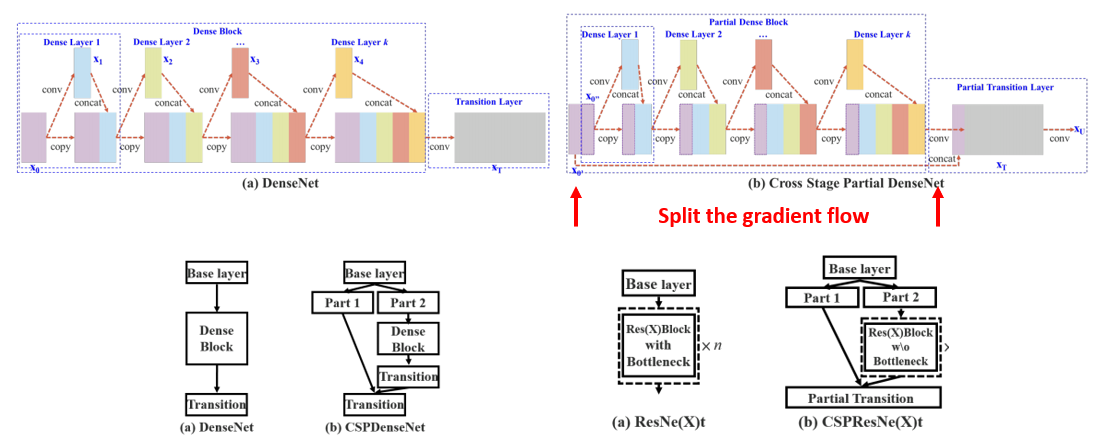
CSPNet은 굉장히 heavy한 inference cost를 완화시키며 정확도 손실을 최소로 할 수 있는 Cross Stage Partial Network 구조를 제안하였으며, 위의 그림과 같이 input feature map을 2개의 part로 나눈 뒤, 하나의 part는 연산에 참여시키지 않고 뒤에서 합쳐주는 방식을 기반으로 inference cost, memory cost 등을 줄일 수 있었습니다. 또한, 학습 관점에서는 gradient flow를 나눠줘서 학습에 좋은 영향을 줘서 정확도 손실이 적다고 주장하고 있습니다.
YOLOv4에서는 CSPNet 기반의 CSPDarkNet53을 제안하였으며, CSPResNext50, EfficientNet-B3에 비해 parameter수와 FLOPS는 많았지만 실제 Inference Time (Throughput)은 가장 좋은 결과를 보이고 있습니다.
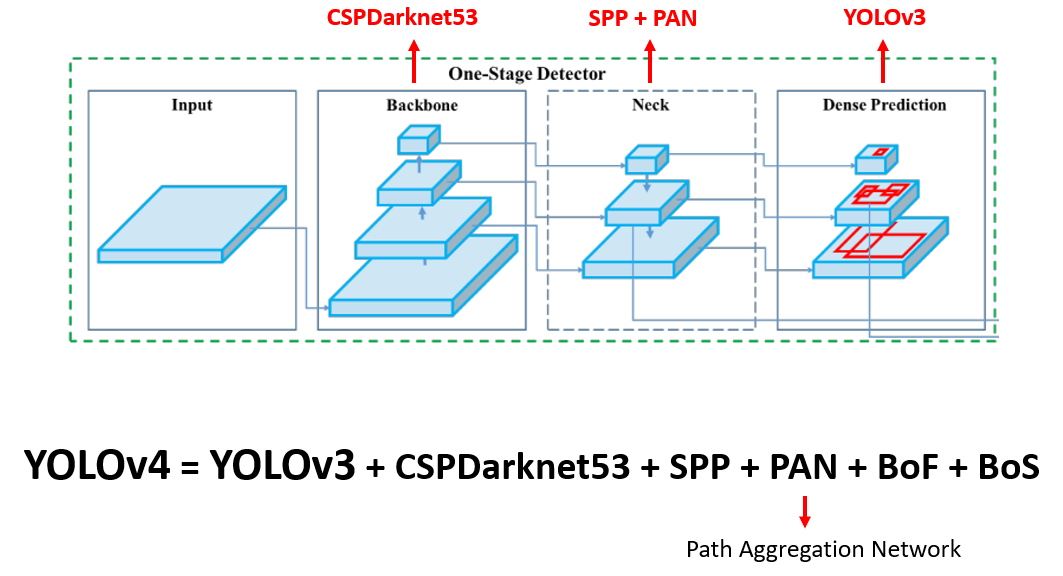
처음 보여드렸던 그림 상에서 YOLOv4를 대입해보면 위와 같이 나타낼 수 있습니다. 대부분의 아이디어는 YOLOv3를 기반으로 하였고, 여기에 backbone을 CSPDarkNet53으로 바꾸고 Neck에는 SPP와 Path Aggregation Network(PAN)을 적용하였고, 위에서 설명 드렸던 Bag of Freebies, Bag of Specials를 적용하였다고 정리할 수 있습니다.
Additional Improvements
마지막으로, 위에서 설명한 Bag of Freebies, Bag of Specials 외에도 저자들이 자체적으로 제안한 기법들에 대해서도 설명하고 있습니다.
Mosaic Augmentation

Mosaic Augmentation은 논문의 마지막 부분에 Acknowledgments를 참고하면 Glenn Jocher라는 분의 도움을 받아서 추가한 아이디어이며 4개의 image를 하나로 합치는 방식을 의미합니다. 위의 그림과 같이 각기 다른 4개의 image와 bounding box를 하나의 512x512 image로 합쳐주며, 당연히 image의 모양의 변화에 따라 bounding box GT의 모양도 바뀌게 됩니다. 이를 통해 하나의 input으로 4개의 image를 배우는 효과를 얻을 수 있어서 저자의 주장에 따르면 Batch Normalization의 statistics 계산에 좋은 영향을 줄 수 있다고 합니다. 기존 Batch Normalization에서는 작은 batch size를 사용하면 학습 안정성이 떨어져서 이를 개선하기 위해 Group Normalization, Switchable Normalization 등이 제안되었는데, Mosaic Augmentation을 이용하면 batch size가 4배 커지는 것과 비슷한 효과를 볼 수 있어서 작은 batch size를 사용해도 학습이 잘된다는 설명을 하고 있습니다. 여기에 제 사견을 덧붙이자면, 4개의 image를 하나로 합치는 과정에서 자연스럽게 small object들이 많아지다 보니 small object를 학습에서 많이 배우게 돼서 small object에 대한 성능도 좋아지지 않을까 생각해봅니다.
Self-Adversarial Training
다음은 Self-Adversarial Training이라는 방법을 제안하였다고 합니다. 다만 논문에 이 방법에 대한 설명도 부실하고 무엇보다 실험 결과가 존재하지 않아서 왜 이러한 내용을 넣어 놨는지 잘 이해가 되지 않네요.

위의 그림은 yolo의 official code repository의 코드와 issue들을 샅샅이 뒤져서 찾아낸 그림입니다. 그림을 바탕으로 이해한 바를 설명드리자면, 우선 input image에 저희가 잘 아는 FGSM과 같은 adversarial attack을 가해서 model이 예측하지 못하게 만듭니다. 그 뒤, perturbed image와 원래의 bounding box GT를 가지고 학습을 시키는 것을 Self-Adversarial Training이라 부르고 있습니다. 이는 보통 정해진 adversarial attack에 robustness를 높이기 위해 진행하는 defense 방식인데, 이러한 기법을 통해 model이 detail한 부분에 더 집중하는 효과를 보고 있다고 설명하고 있는데, 실험 결과가 없어서 저는 잘 이해가 되지 않았습니다.
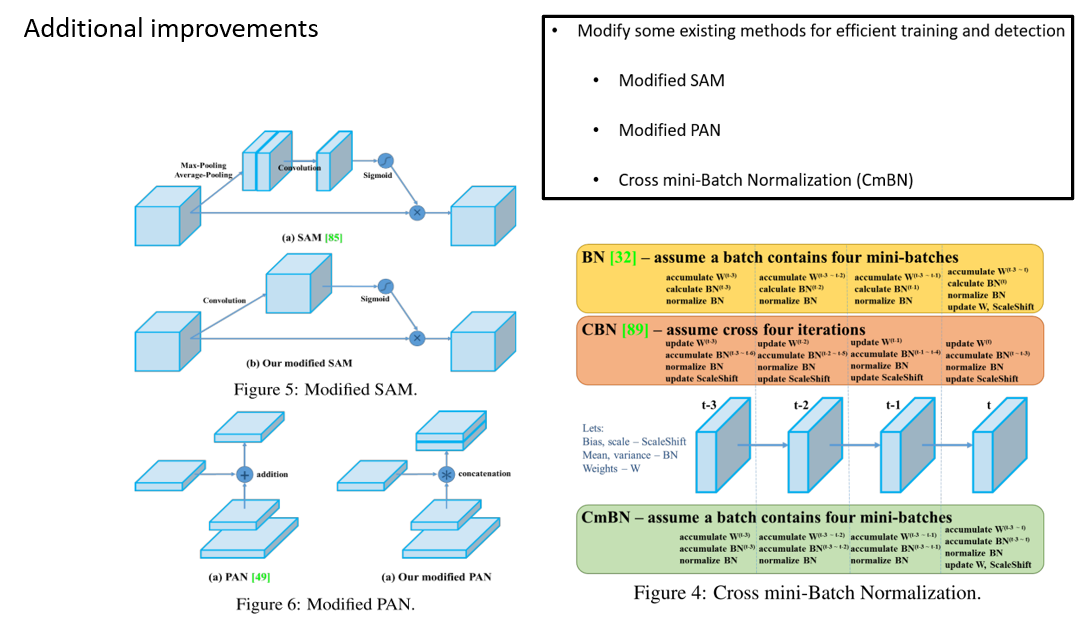
Modified SAM, PAN, CmBN
마지막으로 기존의 Spatial Attention Module(SAM), Path Aggregation Network(PAN), Cross iteration-Batch Normalization(CBN)을 본인들이 약간의 수정을 해서 사용을 하였다고 합니다. 다만 왜 수정을 하였는지는 잘 설명이 되어있지 않습니다.
Experiments and Results
이제 실험 진행 방식과 실험 결과에 대해 알아보겠습니다. 앞서 굉장히 많은 Bag of Freebies, Bag of Specials 들을 다뤘었는데요, 모든 기법들을 다 실험하진 않고, 일부는 제외하였다고 합니다.
Experimental Setup

우선 학습이 어려워서 PReLU, SELU를 제외하였고, ReLU6도 quantized network에 특화된 함수여서 제외하였다고 합니다. Regularization 방법으로는 DropBlock 하나만 사용하였고, 그 이유로는 DropBlock의 저자들이 YOLO에 대해서 본인들의 방법이 다른 방법보다 우수함을 보여서 DropBlock만 사용하였다고 합니다. 이 외에도, YOLOv4의 철학이 Single GPU만으로 사용이 가능해야 한다! 이므로 Multi-GPU 학습 환경에서 사용되는 SyncBN도 제외하였습니다.

이 외에 ImageNet 데이터셋을 이용한 classification 실험, MS COCO 데이터셋을 이용한 object detection 실험에 대한 구체적인 실험 셋팅은 위와 같습니다.
Experimental Result
우선 실험에서 사용한 CSPResNeXt, CSPDarknet-53의 ImageNet Classification 실험 결과는 다음과 같습니다.

CutMix, Mosaic Augmentation과 Label Smoothing을 적용하여 성능이 약간 향상이 되었고, Activation Function으로는 ReLU대비 Swish는 오히려 안 좋은 결과를 보였고 Mish를 사용할 때 큰 폭의 성능 향상이 있었습니다.
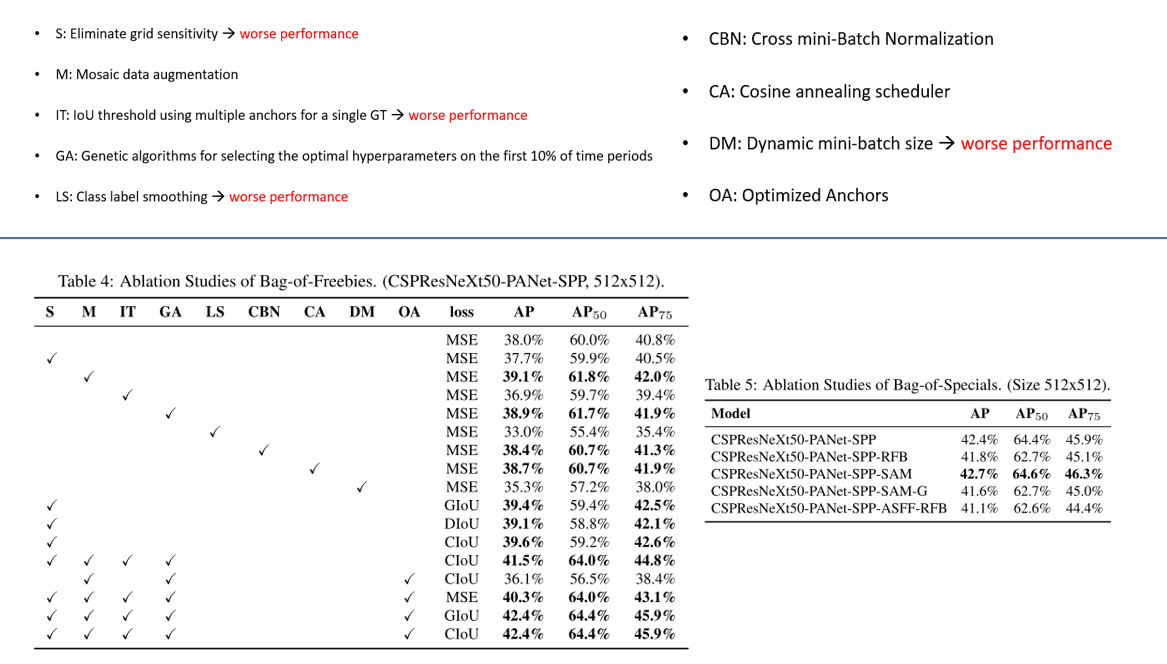
Object Detection 실험에도 다양한 테크닉들을 적용하였는데, 9가지의 기법들에 대한 설명과 각각을 적용하였을 때의 성능 표는 위에 그림에서 확인하실 수 있습니다. 적용하여서 성능이 떨어진 기법들에 대해선 따로 설명을 하지 않을 예정이니, 혹시 궁금하신 분들은 논문을 참고하시기 바랍니다.
우선 M은 앞서 설명드린 Mosaic Augmentation을 의미하고, GA는 Mosaic를 제안한 Glenn Jocher의 도움을 받아서 진행한 방식이며 유전 알고리즘을 이용한 hyper parameter search를 의미합니다. CBN은 Cross mini-Batch Normalization, CA는 Cosine Annealing Learning Rate scheduling을 의미하고, 마지막으로 OA는 YOLOv2에서 제안된 k-means 기반의 사전에 정해 놓은 anchor 크기를 사용하는 것을 의미하며, 512x512 input resolution에 최적화된 anchor들을 사용하였다고 합니다. 이 외에도 loss도 MSE, GIoU, DIoU, CIoU 등을 사용하였고, 각각을 적용하였을 때의 Ablation study 결과도 제시되어 있습니다.
여담이지만 제 블로그에 리뷰가 되어있는 2019 ICCV에 발표된 Gaussian YOLO 기법을 YOLOv4에 적용하였을 때 오히려 정확도가 떨어지는 결과도 논문에 제시되어 있습니다. 하하.. 아쉽네요..
이 외에도 추가적인 실험 결과들이 더 제시되어 있는데, 별로 중요한 것 같지 않아서 설명은 생략하도록 하겠습니다. Batch size를 4로 줄였을 때, 본인들이 제안한 방법을 쓰면 batch size가 8일 때랑 성능이 거의 비슷하다는 결과 정도만 짚고 넘어가면 될 것 같습니다.
결론
이번 포스팅에서는 YOLO의 4번째 버전에 대해 자세히 알아보았습니다. YOLOv3 대비 정확도(AP)를 거의 10% 포인트나 끌어 올린 점이 인상깊으며, 실시간으로 동작해야 하는 조건에서는 고려해 봄직한 모델을 만든 것 같습니다. 물론 연구적인 관점에서 봤을 때는 다소 주먹구구식으로 이 방법 저 방법을 가져다 쓴 느낌이 들긴 하지만, 실용적인 관점에서 봤을 때는 Single GPU로 학습과 테스트, 모델 배포가 가능하다는 점이 가장 큰 장점이라고 생각합니다. 또한 Object Detection 관련 다양한 기법들을 제시하고 있어서, Object Detection을 공부하시는 분들, Kaggle 등 Challenge를 준비하시는 분들이라면 아이디어를 얻어 가시기 좋을 것 같습니다. 공부하시는데 도움이 되셨으면 좋겠습니다! 감사합니다!