DenseNet Tutorial [1] Paper Review & Implementation details
안녕하세요, 오늘은 오랜만에 Image Classification 분야의 논문을 리뷰하고,코드로 구현하는 과정을 설명드릴 예정입니다. 오늘 리뷰할 논문은 DenseNet으로 잘 알려져 있는 CNN architecture를 다룬 “Densely Connected Convolutional Networks” 이라는 논문입니다. 2017년 CVPR Best Paper Award를 받았으며 아이디어가 참신하고 구현이 용이하다는 장점이 있어서 리뷰 대상으로 선택하였습니다.
DenseNet 핵심 내용 정리
이번 파트에서는 DenseNet을 이해하기 위해 필요한 핵심 내용들을 정리할 예정입니다. 논문 자체가 간결하게 쓰여져있어서 논문의 핵심 내용을 키워드로 나눠서 정리해보았습니다.
Dense Connectivity
DenseNet은 논문의 제목에서 알 수 있듯이 Densely Connected 된 CNN 구조를 제안하였고, 이 아이디어는 아래의 그림으로 쉽게 설명이 가능합니다.
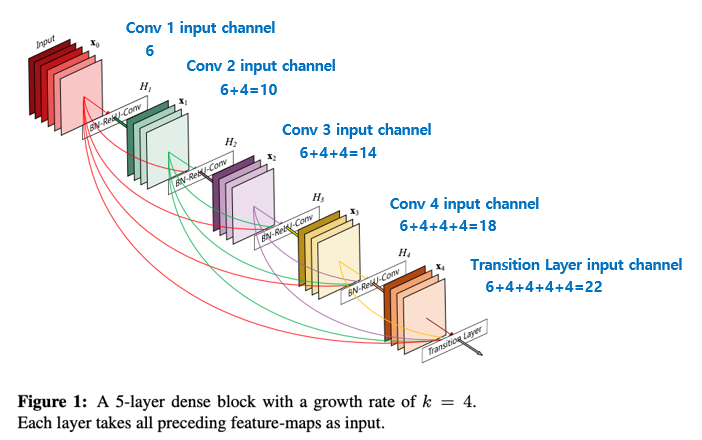
이전 layer들의 feature map을 계속해서 다음 layer의 입력과 연결하는 방식이며 이러한 방식은 ResNet에서도 사용이 되었습니다. 다만 ResNet은 feature map 끼리 더하기 를 해주는 방식이었다면 DenseNet은 feature map끼리 Concatenation 을 시키는 것이 가장 큰 차이점입니다.
이러한 구조를 통해 얻을 수 있는 이점은 다음과 같습니다.
- Vanishing Gradient 개선
- Feature Propagation 강화
- Feature Reuse
- Parameter 수 절약
Growth Rate
각 feature map끼리 densely 연결이 되는 구조이다 보니 자칫 feature map의 channel 개수가 많은 경우 계속해서 channel-wise로 concat이 되면서 channel이 많아 질 수 있습니다. 그래서 DenseNet에서는 각 layer의 feature map의 channel 개수를 굉장히 작은 값을 사용하며, 이 때 각 layer의 feature map의 channel 개수를 growth rate(k) 이라 부릅니다.
위의 그림 1은 k(growth rate) = 4 인 경우를 의미하며 그림 1의 경우로 설명하면 6 channel feature map 입력이 dense block의 4번의 convolution block을 통해 (6 + 4 + 4 + 4 + 4 = 22) 개의 channel을 갖는 feature map output으로 계산이 되는 과정을 보여주고 있습니다. 위의 그림의 경우를 이해하실 수 있으면 실제 논문에서 구현한 DenseNet의 각 DenseBlock의 각 layer마다 feature map의 channel 개수 또한 간단한 등차수열로 나타낼 수 있습니다.
Bottleneck Layer
ResNet과 Inception 등에서 사용되는 bottleneck layer의 아이디어는 DenseNet에서도 찾아볼 수 있습니다.
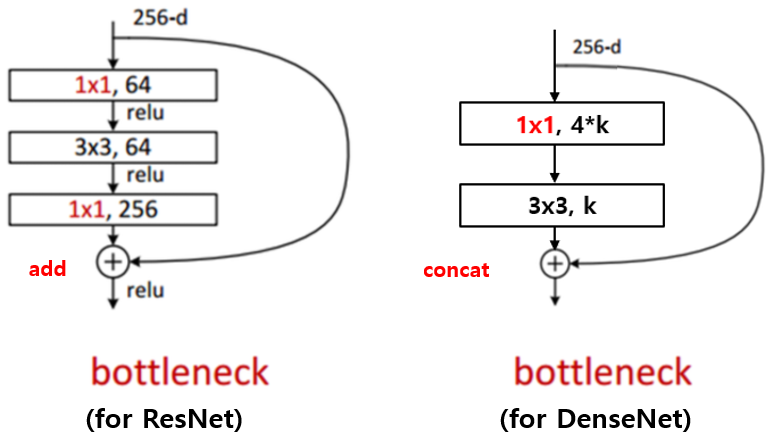
3x3 convolution 전에 1x1 convolution을 거쳐서 입력 feature map의 channel 개수를 줄이는 것 까지는 같은데, 그 뒤로 다시 입력 feature map의 channel 개수 만큼을 생성하는 대신 growth rate 만큼의 feature map을 생성하는 것이 차이 점이며 이를 통해 computational cost를 줄일 수 있다고 합니다.
또한 구현할 때 약간 특이한 점이 존재합니다. DenseNet의 Bottleneck Layer는 1x1 convolution 연산을 통해 4*growth rate 개의 feature map을 만들고 그 뒤에 3x3 convolution을 통해 growth rate 개의 feature map으로 줄여주는 점이 특이합니다. Bottleneck layer를 사용하면, 사용하지 않을 때 보다 비슷한 parameter 개수로 더 좋은 성능을 보임을 논문에서 제시하고 있습니다.
다만 4 * growth rate의 4배 라는 수치는 hyper-parameter이고 이에 대한 자세한 설명은 하고 있지 않습니다.
Transition Layer
다음으로 설명드릴 부분은 Transition layer이며 feature map의 가로, 세로 사이즈를 줄여주고 feature map의 개수를 줄여주는 역할을 담당하고 있습니다. 마지막 Dense Block을 제외한 나머지 Dense Block 뒤에 연결이 되며 Batch Normalization, ReLU, 1x1 convolution, 2x2 average pooling 으로 구성이 되어있습니다.
1x1 convolution을 통해 feature map의 개수를 줄여주며 이 때 줄여주는 정도를 나타내는 theta 를 논문에서는 0.5를 사용하였으며 마찬가지로 이 값도 hyper-parameter입니다. 이 과정을 Compression이라 논문에서 표현하고 있습니다. 즉 논문에서 제시하고 있는 transition layer를 통과하면 feature map의 개수(channel)이 절반으로 줄어들고, 2x2 average pooling layer를 통해 feature map의 가로 세로 크기 또한 절반으로 줄어듭니다. 물론 theta를 1로 사용하면 feature map의 개수를 그대로 가져가는 것을 의미합니다.
Composite function
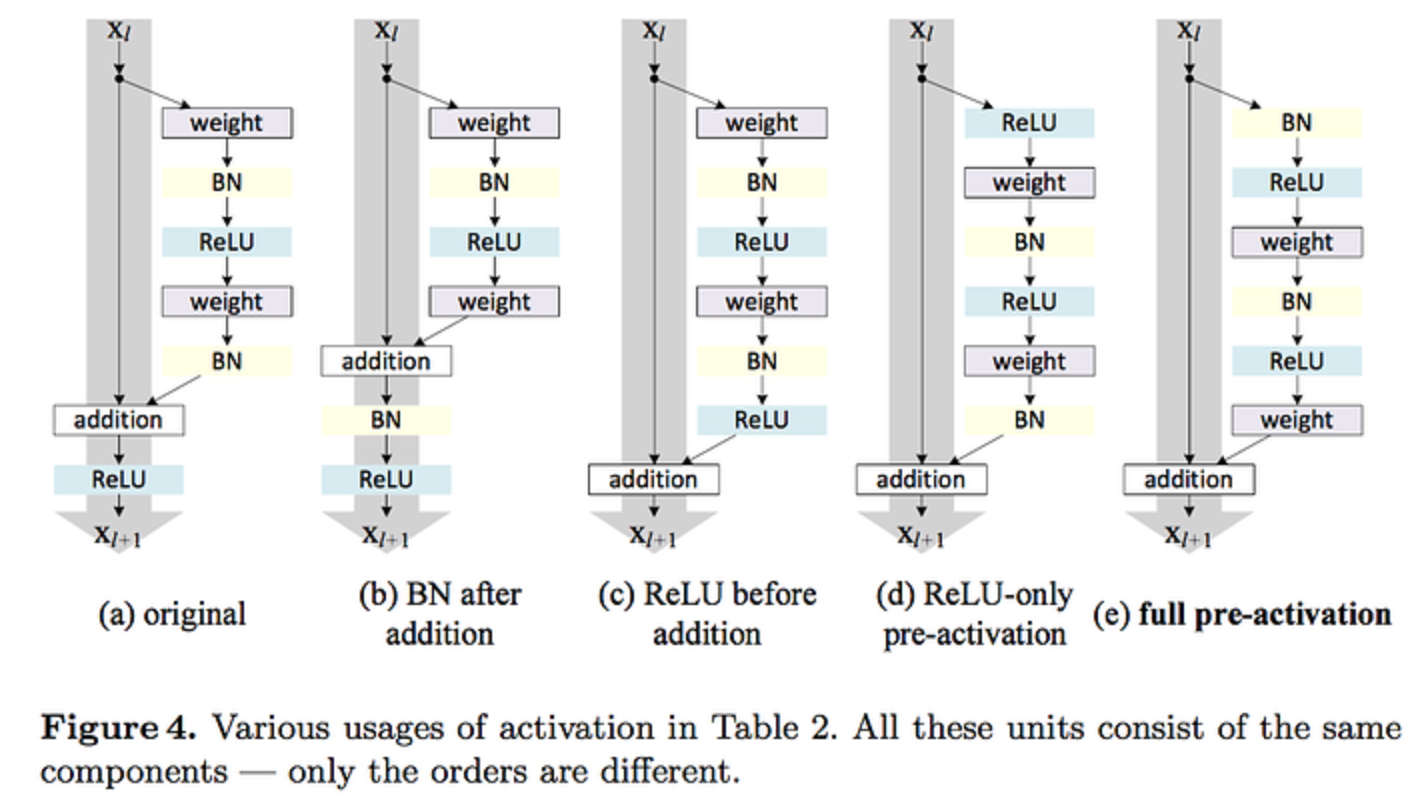
DenseNet은 ResNet의 구조에 대해 분석한 “Identity mappings in deep residual networks, 2016 ECCV” 논문에서 실험을 통해 제안한 BatchNorm-ReLU-Conv 순서의 pre-activation 구조를 사용하였습니다.
DenseNet implementation details
앞선 핵심 아이디어들을 이해하시면 DenseNet의 구현에 대해 쉽게 이해가 가능하실 것입니다. 본 논문에서는 ImageNet, CIFAR-10, SVHN 3가지 데이터셋에 대해 실험을 하였으며, ImageNet은 다른 두가지 데이터셋에 비해 이미지 사이즈가 크기 때문에 ImageNet과 나머지 두 데이터셋이 다른 architecture를 가지는 것이 특징입니다.
논문에서는 ImageNet에 대한 architecture는 표로 제시를 하고 있으나 CIFAR-10, SVHN에 대한 architecture는 표가 존재하지 않아서 표를 그려보았습니다. 각 Dense Block 마다 같은 개수의 convolution 연산을 사용하는 점을 이해하면 쉽게 작성이 가능합니다.
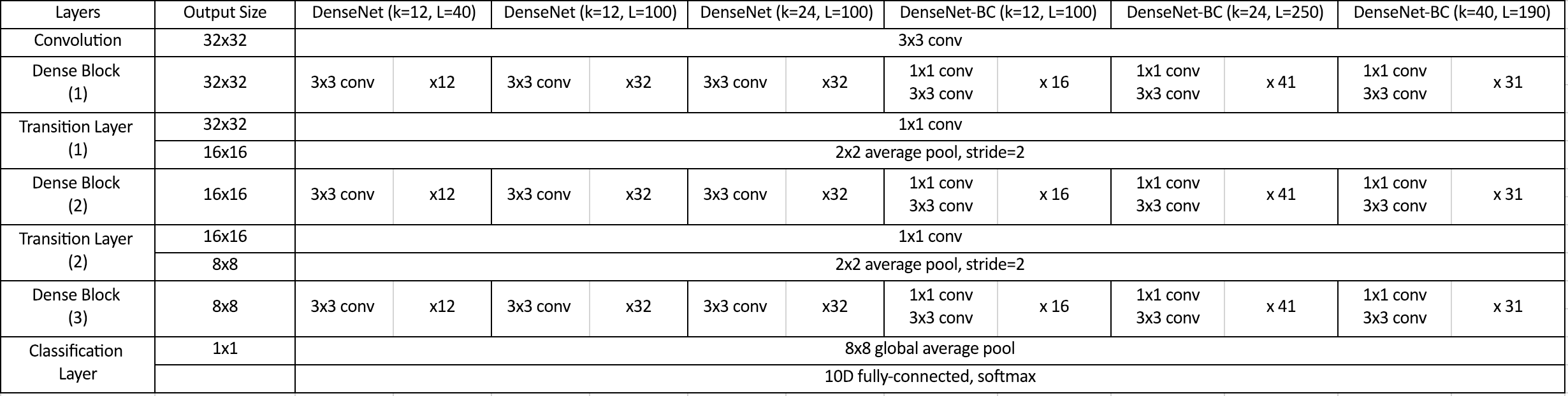
ImageNet의 DenseNet architecture와 비교하면 차이점은 다음과 같습니다.
- DenseBlock 이전 Convolution 연산의 차이
- DenseBlock, Transition Layer 개수 차이
- 각 Dense Block의 layer 개수 차이
- Fully-connected layer의 output 개수(class 개수) 차이
architecture에서 차이는 존재하지만 핵심 내용은 같으므로 CIFAR-10에 대한 architecture를 구성할 수 있으면 ImageNet에 대해서도 쉽게 구성할 수 있을 것입니다. 논문에서는 CIFAR-10에 대해 총 6가지 version으로 실험을 진행하였으며 각 version은 bottleneck layer의 유무, growth rate, 전체 Layer 개수가 달라지는 것을 의미합니다. 또한 dropout을 각 convolution layer 뒤에 적용하였으며 Dropout rate는 0.2를 사용하였습니다.
이번 포스팅에서는 CIFAR-10에 대해 실험을 진행할 예정이며 학습 관련 셋팅은 다음과 같습니다.
- batch size: 64
- total epochs: 300
- initial learning rate: 0.1
- learning rate decay: x0.1 at 150 epoch, 225 epoch
- weight decay: 10e-4
- Nesterov momentum: 0.9 without dampening
- weight initialization: He initialization
결론
이번 포스팅에서는 DenseNet에 대한 핵심 내용들과 코드 구현을 위한 detail들을 분석해보았습니다. 개인적으로는 DenseNet 논문을 읽고 아이디어는 참신하지만 일부 아이디어들(bottleneck layer의 4*growth rate, transition layer의 0.5배 압축 등)이 다소 설명이 부족한 점이 아쉬웠습니다. 이러한 점들은 저만 느낀 것이 아니었는지 추후에 다른 논문에서 이 점들에 대한 문제 제기를 하게 됩니다. 그 논문도 추후에 포스팅으로 다룰 예정입니다. (스포를 하자면.. Pelee 라는 논문이며 해당 링크에 제가 작성한 ppt 를 통해 미리 보실 수 있습니다.)
다음 포스팅에서는 DenseNet을 PyTorch로 구현하고 각 부분에 대해 설명을 드릴 예정입니다. 읽어주셔서 감사합니다!
참고 문헌
- “Densely Connected Convolutional Networks”
- “Identity mappings in deep residual networks, 2016 ECCV”
- pelee:a real time object detection system on mobile devices paper review