DenseNet Tutorial [2] PyTorch Code Implementation
안녕하세요, 오늘은 이전 포스팅에 이어서 DenseNet을 PyTorch 로 구현할 예정입니다. Deep Neural Network의 Architecture를 다루는 논문들은 논문을 읽어보는 것도 중요하지만, 개인적으로는 직접 구현을 해보면서 더 깊은 이해를 할 수 있어서 직접 구현을 해보게 되었습니다.
빠른 실습을 위해 오늘 포스팅은 ipynb 구현체를 통해 진행할 예정이며 google colab 을 이용할 예정입니다. ipynb 코드는 해당 링크 에서 확인하실 수 있습니다.
google colab은 ipynb 코드를 다운로드 받으신 후, 해당 링크 에 접속하셔서 본인의 구글 드라이브에 업로드하셔서 사용하실 수 있습니다.
Requirements
우선 google colab을 이용하여 실습을 진행할 예정이며, 최근 PyTorch도 official하게 지원이 되기 시작하면서 별도의 설치 과정 필요 없이 바로 PyTorch 이용이 가능합니다. 다만 GPU를 사용하지 않으면 학습이 굉장히 오래 걸리기 때문에 “런타임-런타임 유형 변경” 에서 하드웨어 가속기를 “GPU” 로 선택해주시면 됩니다.
Code Implementation
Preparation Step
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision.utils import save_image
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import os
import glob
import PIL
from PIL import Image
from torch.utils import data as D
from torch.utils.data.sampler import SubsetRandomSampler
import random
import torchsummary
print(torch.__version__)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
batch_size = 64
validation_ratio = 0.1
random_seed = 10
initial_lr = 0.1
num_epoch = 300
우선 torch와 관련된 여러 package들과 이미지와 관련된 library들을 import 해주고 학습과 관련된 hyper-parameter 들을 설정합니다. Batch size와 initial learning rate는 논문에서 제시한 값을 사용하였고, validation set의 비율은 학습 데이터의 10%를 사용하였습니다.
transform_train = transforms.Compose([
#transforms.Resize(32),
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
transform_validation = transforms.Compose([
#transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
transform_test = transforms.Compose([
#transforms.Resize(32),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
trainset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_train)
validset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_validation)
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform_test)
num_train = len(trainset)
indices = list(range(num_train))
split = int(np.floor(validation_ratio * num_train))
np.random.seed(random_seed)
np.random.shuffle(indices)
train_idx, valid_idx = indices[split:], indices[:split]
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
train_loader = torch.utils.data.DataLoader(
trainset, batch_size=batch_size, sampler=train_sampler, num_workers=0
)
valid_loader = torch.utils.data.DataLoader(
validset, batch_size=batch_size, sampler=valid_sampler, num_workers=0
)
test_loader = torch.utils.data.DataLoader(
testset, batch_size=batch_size, shuffle=False, num_workers=0
)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
이 부분은 training, validation, test set으로 split하여 각각의 data loader를 생성해주는 부분을 의미하고, 학습 시에는 random crop, random horizontal flip augmentation을 사용하였습니다. 또한 입력 이미지를 CIFAR-10 데이터셋의 평균, 분산으로 normalize를 해주는 전처리 또한 포함이 되어있습니다. [4]번 셀까지 실행을 하면 CIFAR-10 데이터셋을 불러와서 torch data loader class를 생성하게 됩니다.
Module Class 생성
DenseNet을 구성하는 Module들을 나타내는 class를 각각 생성하고 이를 조립하여 전체 architecture를 구성할 예정입니다. 우선 가장 기본이 되는 bn_relu_conv class는 다음과 같습니다.
class bn_relu_conv(nn.Module):
def __init__(self, nin, nout, kernel_size, stride, padding, bias=False):
super(bn_relu_conv, self).__init__()
self.batch_norm = nn.BatchNorm2d(nin)
self.relu = nn.ReLU(True)
self.conv = nn.Conv2d(nin, nout, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias)
def forward(self, x):
out = self.batch_norm(x)
out = self.relu(out)
out = self.conv(out)
return out
말 그대로 Batch Normalization – ReLU – Convolution 연산을 차례대로 수행하는 역할을 하며, DenseNet에 이러한 composite function이 자주 사용되어서 편의상 별도의 class로 생성을 하였습니다.
class bottleneck_layer(nn.Sequential):
def __init__(self, nin, growth_rate, drop_rate=0.2):
super(bottleneck_layer, self).__init__()
self.add_module('conv_1x1', bn_relu_conv(nin=nin, nout=growth_rate*4, kernel_size=1, stride=1, padding=0, bias=False))
self.add_module('conv_3x3', bn_relu_conv(nin=growth_rate*4, nout=growth_rate, kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
bottleneck_output = super(bottleneck_layer, self).forward(x)
if self.drop_rate > 0:
bottleneck_output = F.dropout(bottleneck_output, p=self.drop_rate, training=self.training)
bottleneck_output = torch.cat((x, bottleneck_output), 1)
return bottleneck_output
다음으로 설명드릴 bottleneck layer는 DenseNet-BC에서 사용되며 앞선 포스팅에서 설명 드린 것처럼 1x1 convolution 과 3x3 convolution 연산이 차례대로 수행이 됩니다. 또한 각 연산의 output feature map의 크기가 변하는 것도 코드에서 확인이 가능하시고 drop out도 구현이 되어있습니다.
여기서 가장 주목할 부분은 바로 torch.cat 함수입니다. DenseNet의 핵심인 부분이며 매 bottleneck layer를 거칠 때 마다 feature map이 channel-wise로 누적이 되는 것을 간단히 한 줄로 구현할 수 있습니다. Cat 함수의 2번째 parameter의 argument로 넣어준 1 값은 concatenation을 해주는 dimension을 의미하며 1번째 차원은 channel을 의미합니다.
class Transition_layer(nn.Sequential):
def __init__(self, nin, theta=0.5):
super(Transition_layer, self).__init__()
self.add_module('conv_1x1', bn_relu_conv(nin=nin, nout=int(nin*theta), kernel_size=1, stride=1, padding=0, bias=False))
self.add_module('avg_pool_2x2', nn.AvgPool2d(kernel_size=2, stride=2, padding=0))
다음 설명드릴 Transition Layer는 간단하게 구현이 가능합니다. 1x1 convolution 이후 2x2 average pooling을 사용하며, Compression hyper parameter인 theta에 따라 1x1 convolution의 output feature map의 개수를 조절할 수 있습니다.
class DenseBlock(nn.Sequential):
def __init__(self, nin, num_bottleneck_layers, growth_rate, drop_rate=0.2):
super(DenseBlock, self).__init__()
for i in range(num_bottleneck_layers):
nin_bottleneck_layer = nin + growth_rate * i
self.add_module('bottleneck_layer_%d' % i, bottleneck_layer(nin=nin_bottleneck_layer, growth_rate=growth_rate, drop_rate=drop_rate))
마지막으로 설명드릴 DenseBlock은 위에서 생성한 bottleneck layer를 각 DenseBlock의 layer 길이에 맞게 차례대로 이어주는 방식으로 구현이 가능하며 for 문을 통해 간단히 구현할 수 있습니다. 각 bottleneck layer의 input feature map(nin)은 첫 feature map의 개수에 growth rate을 더해주는 방식으로 계산할 수 있으며 이는 nin_bottleneck_layer 라는 variable로 정의하였습니다.
DenseNet-BC 구성
다음 설명드릴 부분은 위에서 생성한 module을 기반으로 DenseNet-BC를 구성하는 부분입니다.
class DenseNet(nn.Module):
def __init__(self, growth_rate=12, num_layers=100, theta=0.5, drop_rate=0.2, num_classes=10):
super(DenseNet, self).__init__()
assert (num_layers - 4) % 6 == 0
# (num_layers-4)//6
num_bottleneck_layers = (num_layers - 4) // 6
# 32 x 32 x 3 --> 32 x 32 x (growth_rate*2)
self.dense_init = nn.Conv2d(3, growth_rate*2, kernel_size=3, stride=1, padding=1, bias=True)
# 32 x 32 x (growth_rate*2) --> 32 x 32 x [(growth_rate*2) + (growth_rate * num_bottleneck_layers)]
self.dense_block_1 = DenseBlock(nin=growth_rate*2, num_bottleneck_layers=num_bottleneck_layers, growth_rate=growth_rate, drop_rate=drop_rate)
# 32 x 32 x [(growth_rate*2) + (growth_rate * num_bottleneck_layers)] --> 16 x 16 x [(growth_rate*2) + (growth_rate * num_bottleneck_layers)]*theta
nin_transition_layer_1 = (growth_rate*2) + (growth_rate * num_bottleneck_layers)
self.transition_layer_1 = Transition_layer(nin=nin_transition_layer_1, theta=theta)
# 16 x 16 x nin_transition_layer_1*theta --> 16 x 16 x [nin_transition_layer_1*theta + (growth_rate * num_bottleneck_layers)]
self.dense_block_2 = DenseBlock(nin=int(nin_transition_layer_1*theta), num_bottleneck_layers=num_bottleneck_layers, growth_rate=growth_rate, drop_rate=drop_rate)
# 16 x 16 x [nin_transition_layer_1*theta + (growth_rate * num_bottleneck_layers)] --> 8 x 8 x [nin_transition_layer_1*theta + (growth_rate * num_bottleneck_layers)]*theta
nin_transition_layer_2 = int(nin_transition_layer_1*theta) + (growth_rate * num_bottleneck_layers)
self.transition_layer_2 = Transition_layer(nin=nin_transition_layer_2, theta=theta)
# 8 x 8 x nin_transition_layer_2*theta --> 8 x 8 x [nin_transition_layer_2*theta + (growth_rate * num_bottleneck_layers)]
self.dense_block_3 = DenseBlock(nin=int(nin_transition_layer_2*theta), num_bottleneck_layers=num_bottleneck_layers, growth_rate=growth_rate, drop_rate=drop_rate)
nin_fc_layer = int(nin_transition_layer_2*theta) + (growth_rate * num_bottleneck_layers)
# [nin_transition_layer_2*theta + (growth_rate * num_bottleneck_layers)] --> num_classes
self.fc_layer = nn.Linear(nin_fc_layer, num_classes)
def forward(self, x):
dense_init_output = self.dense_init(x)
dense_block_1_output = self.dense_block_1(dense_init_output)
transition_layer_1_output = self.transition_layer_1(dense_block_1_output)
dense_block_2_output = self.dense_block_2(transition_layer_1_output)
transition_layer_2_output = self.transition_layer_2(dense_block_2_output)
dense_block_3_output = self.dense_block_3(transition_layer_2_output)
global_avg_pool_output = F.adaptive_avg_pool2d(dense_block_3_output, (1, 1))
global_avg_pool_output_flat = global_avg_pool_output.view(global_avg_pool_output.size(0), -1)
output = self.fc_layer(global_avg_pool_output_flat)
return output
첫 번째 Convolution 이후 Dense Block과 Transition Layer들을 차례로 통과시키고 마지막에 global average pooling을 거친 후 fully-connected layer로 연결해주는 부분이 위의 코드에 나와있습니다. 각 module 마다 feature map의 shape이 어떻게 변하는지를 각 모듈의 선언 부분 위의 주석을 통해 기재하였으며 이렇게 각 layer 마다 shape이 변하는 것을 계산하는 과정을 통해 architecture에 대한 이해도가 높아질 수 있습니다.
def DenseNetBC_100_12():
return DenseNet(growth_rate=12, num_layers=100, theta=0.5, drop_rate=0.2, num_classes=10)
def DenseNetBC_250_24():
return DenseNet(growth_rate=24, num_layers=250, theta=0.5, drop_rate=0.2, num_classes=10)
def DenseNetBC_190_40():
return DenseNet(growth_rate=40, num_layers=190, theta=0.5, drop_rate=0.2, num_classes=10)
다음으로 설명드릴 부분은 논문에서 제시하고 있는 3가지 DenseNet-BC 모델들을 위에서 생성한 DenseNet class를 통해 만들어주는 함수입니다. Growth rate, num_layer를 통해 조절이 가능하며 또한 transition layer의 compression 정도, drop out rate 등도 조절하실 수 있습니다.
net = DenseNetBC_100_12()
net.to(device)
이제는 생성한 architecture를 맨 처음 생성한 torch.device에 넣어주면 GPU에서 학습을 할 수 있게 됩니다.
Architecture Summary
앞서 생성한 architecture의 각 연산이 수행된 후의 tensor의 shape을 계산하는 과정이 도움이 된다고 말씀드렸는데, 본인이 계산한 shape과 실제 architecture에서 계산된 shape을 비교하려면 모든 layer에 print 함수를 달아줘야 하는 번거로움이 있습니다. 이러한 번거로움을 쉽게 해결할 수 있는 “torch summary” 라는 라이브러리를 소개 드리려고 합니다.
Keras의 summary() 함수와 비슷한 동작을 하며, 앞서 생성한 net과 input image의 shape만 argument로 넣어주면 자동으로 모든 연산들의 parameter 수, output shape을 계산해줍니다. 또한 Total parameter 수, 학습에 필요한 memory size 등도 계산을 해주는 등 유용한 정보들을 쉽게 확인할 수 있습니다.
torchsummary.summary(net, (3, 32, 32))
이 한 줄만 추가해주면 각 연산마다 output shape이 어떻게 변하는지 확인하실 수 있습니다. 특히 DenseNet의 경우 코드를 구현하면서 densely connectivity가 잘 구현되고 있는지 확인할 필요가 있는데 torch summary를 이용하시면 쉽게 디버깅이 가능합니다.
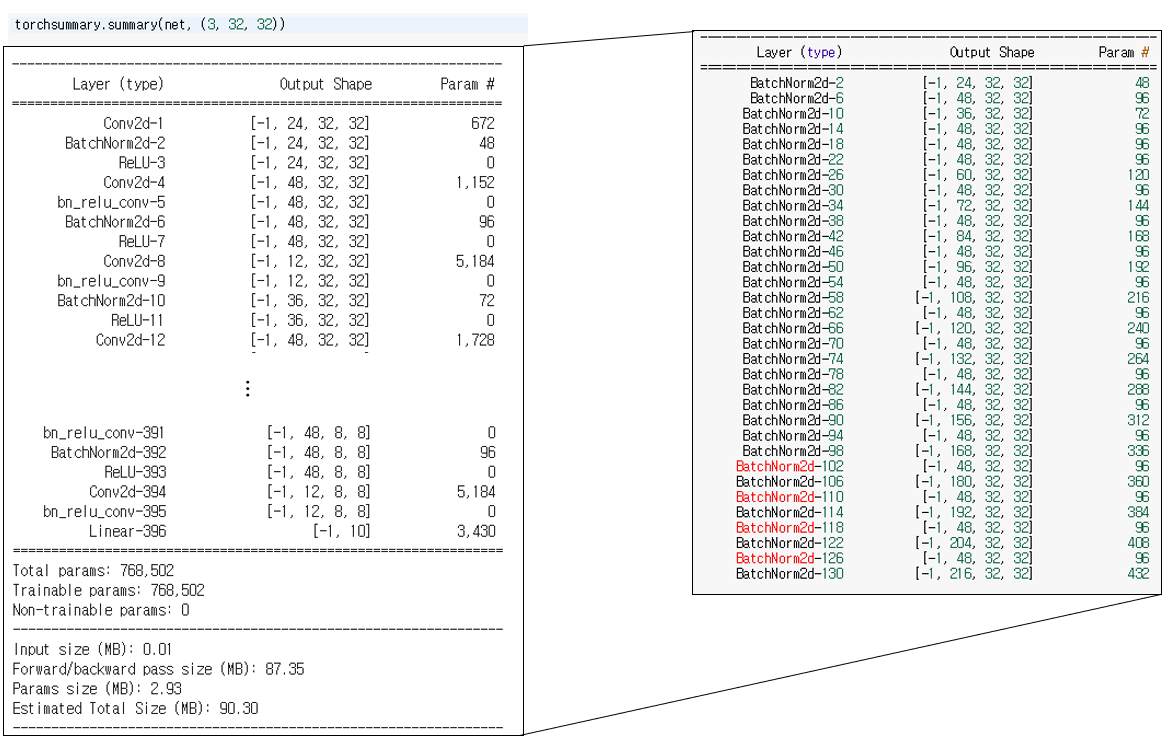
위 그림은 toch summary를 통해 DenseNet의 Model Summary를 수행하고, 그 중 첫번째 DenseBlock의 feature map shape을 요약하고 있습니다. Input feature map이 bn_relu_conv block을 거쳐서 channel이 어떻게 변하는지를 한눈에 볼 수 있으며, bottleneck layer에서 48채널로 변환이 되었다가 이전 feature map과 concat이 되어서 feature map 개수가 증가하는 과정을 확인하실 수 있습니다.
Training
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=initial_lr, momentum=0.9)
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer=optimizer, milestones=[int(num_epoch * 0.5), int(num_epoch * 0.75)], gamma=0.1, last_epoch=-1)
for epoch in range(num_epoch):
lr_scheduler.step()
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
show_period = 100
if i % show_period == show_period-1: # print every "show_period" mini-batches
print('[%d, %5d/50000] loss: %.7f' %
(epoch + 1, (i + 1)*batch_size, running_loss / show_period))
running_loss = 0.0
# validation part
correct = 0
total = 0
for i, data in enumerate(valid_loader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('[%d epoch] Accuracy of the network on the validation images: %d %%' %
(epoch + 1, 100 * correct / total)
)
print('Finished Training')
다음 설명드릴 부분은 학습을 시키는 부분이며 마찬가지로 간단히 구현이 가능합니다. SGD optimizer에 momentum은 0.9를 사용하였고 learning rate는 pytorch의 learning rate scheduling을 이용하여 구현을 하였습니다. 전체 epoch의 50%인 지점과 75%인 지점에서 각각 0.1배씩 곱해주는 방식이므로 lr_scheduler.MultiStepLR 을 이용하여 구현을 하였습니다.
그리고 1 epoch이 끝날 때 마다 validation set으로 accuracy를 측정하고 있으며 이 예제에서는 model selection, learning curve plotting은 구현하지 않았습니다. 필요하신 경우 추가하셔서 사용하시면 됩니다.
Test
Test는 Validation set으로 정확도를 측정한 것과 같이 val_loader를 test_loader로 바꿔주면 쉽게 구현할 수 있습니다.
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(labels.shape[0]):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
Test set에 대해 test를 한 뒤 10가지 클래스마다 정확도를 각각 구하고, 또한 전체 정확도를 구하는 과정이 위에 코드로 구현이 되어있습니다.
결론
이번 포스팅에서는 google colab을 통해 DenseNet-BC를 PyTorch로 구현하고 학습을 해보았습니다. 우선 각 module을 구현하고 이를 조립하는 방식으로 구현을 하였으며 이 외에도 구현한 architecture를 summary 하는 과정까지 설명을 드렸습니다. DenseNet을 구현하는 전체 과정을 이해하셨다면 다른 architecture도 이 코드를 기반으로 구현을 하실 수 있을 것이라 생각합니다. 다음에도 대표적인 architecture를 구현하는 실습을 다룬 포스팅으로 찾아 뵙겠습니다. 감사합니다!
References