Pelee Tutorial [1] Paper Review & Implementation detail
안녕하세요, 오늘은 지난 DenseNet 논문 리뷰에 이어서 2018년 NeurIPS에 발표된 “Pelee: A Real-Time Object Detection System on Mobile Devices” 라는 논문을 리뷰하고 이 중 Image Classification 부분인 PeleeNet을 PyTorch로 구현할 예정입니다. 해당 논문을 리뷰한 ppt 자료는 해당 링크 에서도 확인이 가능합니다.
Introduction
오늘 설명드릴 Pelee 논문은 제목에서 알 수 있듯이 Mobile Device에서 Deep Learning을 수행하기 위한 architecture를 제안하고 있습니다. 제목에는 Object Detection만 나와있지만 논문에서는 Image Classification, Object Detection 2가지 task에 모두 적용을 하여 실험을 진행합니다. Classification에 사용되는 architecture는 PeleeNet 이라는 이름을 가지고 있고, 이 PeleeNet을 Object Detection의 대표적인 1-stage detector인 SSD에 적용시킨 것이 Pelee 입니다. 이번 포스팅에서는 PeleeNet, Pelee 두 가지를 모두 리뷰할 예정이며 다음 포스팅에서는 PeleeNet을 직접 PyTorch로 구현할 예정입니다.
PeleeNet: An Efficient Feature Extraction Network
이 논문의 출발점은 지난 번 리뷰하였던 DenseNet입니다. 논문에서는 DenseNet을 기반으로 여러 tuning을 통해 DenseNet보다 더 정확하고 빠른 architecture인 PeleeNet을 제안하고 있습니다. 바뀐 점은 크게 5가지이며 한 가지씩 설명을 드리도록 하겠습니다.
1. Two-way Dense Layer
기존 DenseNet에서 사용된 BottleNeck Layer는 1x1 conv + 3x3 conv의 조합으로 이루어져 있었는데, PeleeNet에서는 다양한 scale의 receptive field를 갖기 위해 2방향의 Dense Layer를 사용하였습니다.
이러한 접근 방법은 GoogLeNet(2015)에서 영감을 받았다고 합니다.
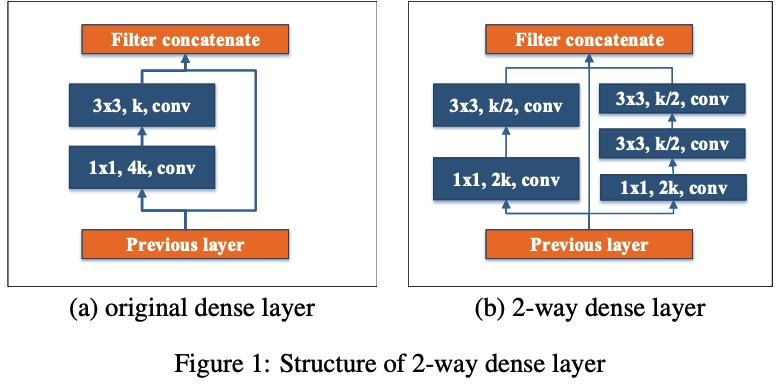
새로 생긴 1x1 conv + 3x3 conv + 3x3 conv는 큰 object들의 pattern을 위해 추가가 되었으며, 비슷한 연산량과 parameter 수를 가지기 위해 각 feature map의 개수를 조절하고 있는 것을 그림에서 확인하실 수 있습니다.
2. Stem Block
다음 설명드릴 Stem Block은 Inception-v4(2017)과, 지난 Object Detection 최신 논문 리뷰 포스팅 에서 다뤘던 DSOD(2017) 논문에서 영감을 받았으며, 첫번째 Dense Block 이전에 위치합니다.
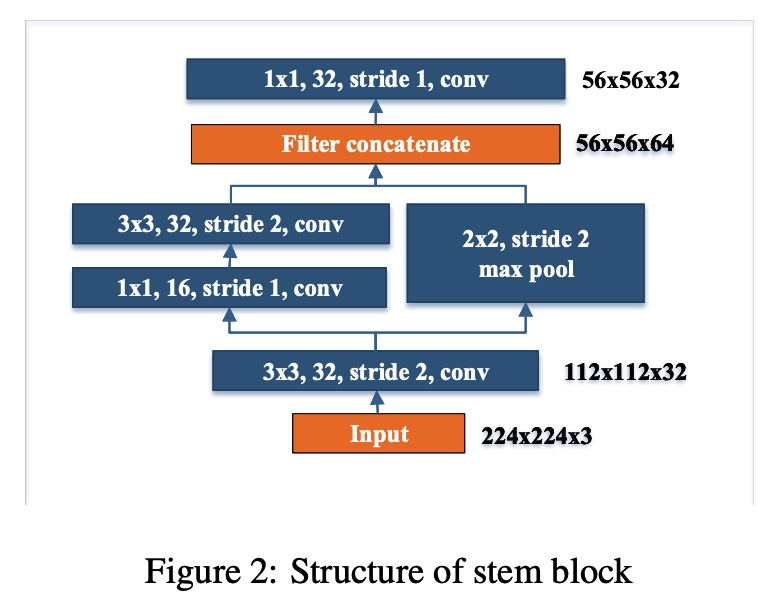
Input image의 크기를 가로, 세로 4배 줄여주어 전체 architecture가 cost-efficient 해지게 하는 역할을 합니다. 또한 적은 연산량으로 feature expression ability를 높여줄 수 있다고 논문에서 주장하고 있습니다.
3. Dynamic Number of Channels in Dense Layer
지난 DenseNet 리뷰를 보셨다면 DenseNet의 bottleneck layer 구조를 떠올리실 수 있을 것입니다. 1x1 convolution을 통해 growth rate의 4배에 해당하는 feature map을 만들었다가 3x3 convolution을 통해 다시 줄이는 방식이 사용이 되었습니다.
이러한 bottleneck 구조는 연산량을 줄이기 위해 사용이 되는데, 아직 feature map이 많이 쌓이지 않은(feature map의 개수가 적은) 초기의 Dense Layer에서는 4 * growth rate보다 input feature map의 개수가 적게 됩니다. 이러한 경우에 오히려 연산량을 늘리게 되는 문제가 발생합니다. 이를 개선하기 위해 Stem Block과 Two-way Dense Layer 등을 사용을 하였고, 또한 각 Stage마다 Dense Layer의 개수를 가변적으로 가져가는 구조를 취했습니다.
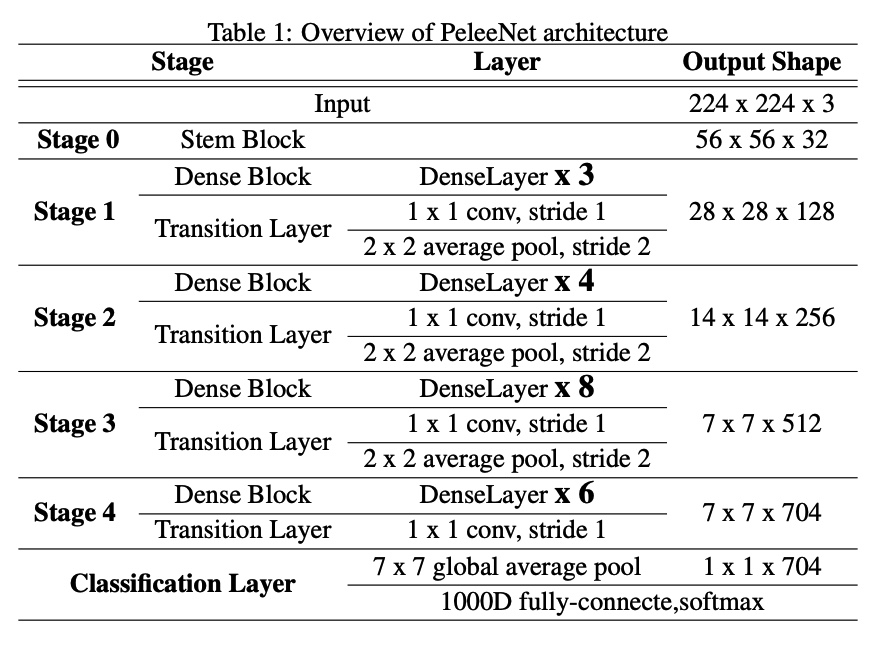
PeleeNet의 전체 architecture는 위의 표와 같고 이 때 growth rate(=k)는 32를 사용하였습니다.
직접 계산을 해보시거나 다음 포스팅에서 코드 구현 후 torch summary를 통해 확인을 해보시면 dense layer 내에서 입력 feature map의 개수가 2*growth rate보다 적은 경우는 가장 첫 dense layer 연산밖에 없는 것을 확인하실 수 있습니다.
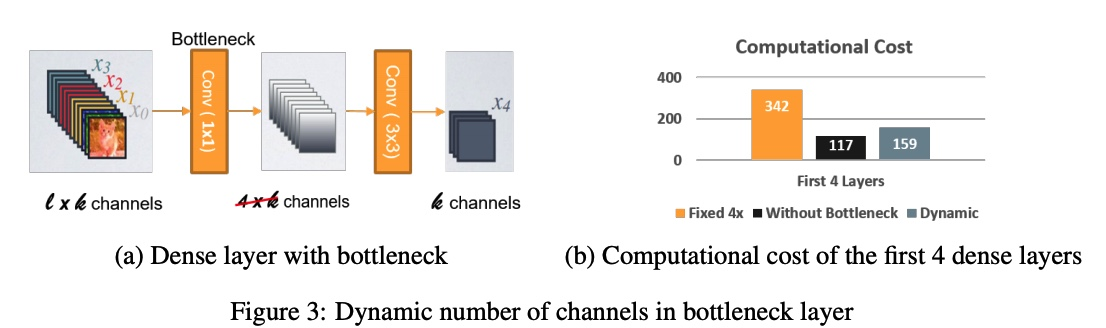
이러한 방식을 가져감으로써 초기의 dense layer에서 연산량을 크게 절약할 수 있습니다.
4. Transition Layer without Compression
기존의 DenseNet에서는 Transition Layer에서 feature map의 개수가 줄어드는 compression이 수행이 되었습니다. 하지만 저자가 실험을 한 결과 transition layer에서의 compression이 feature expression 성능을 저하시키는 것을 확인하였고, 결국 compression을 사용하지 않았습니다.
5. Composite Function
PeleeNet에서는 기존 DenseNet에서 사용되었던 pre-activation 구조(BN-ReLU-Conv) 대신 저희가 일반적으로 사용하는 post-activation 구조(Conv-BN-ReLU)를 사용하였습니다. 이렇게 하면 Infernece 단계에서 Batch Normalization이 Convolution 연산과 합쳐질 수 있어서 연산 가속이 가능하다는 장점이 있으며 정확도 감소를 막기 위해 마지막 Dense Block(Stage 4) 이후 1x1 convolution을 추가하여 feature의 표현력을 증가시켰습니다.
실험 결과
본 논문에서는 PeleeNet의 성능을 분석하기 위해 여러 실험들을 수행하였습니다. 우선 DenseNet과 비교하기 위해 baseline으로 DenseNet-41을 만들고 이를 customized Stnaford Dogs 데이터셋을 이용하여 성능을 측정하였습니다. 데이터셋에 대한 디테일은 논문에 나와있습니다.
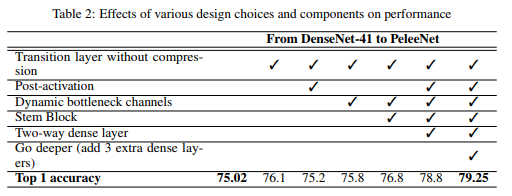
위에서 설명드린 5가지의 변한 점들을 적용함에 따라 성능이 어떻게 변하는지 ablation study를 수행하였으며 기존 DenseNet-41에 비해 정확도가 크게 증가한 것을 확인할 수 있습니다.
DenseNet 외에 다른 mobile device target CNN들과도 성능을 비교하였고 결과는 다음 표와 같습니다.
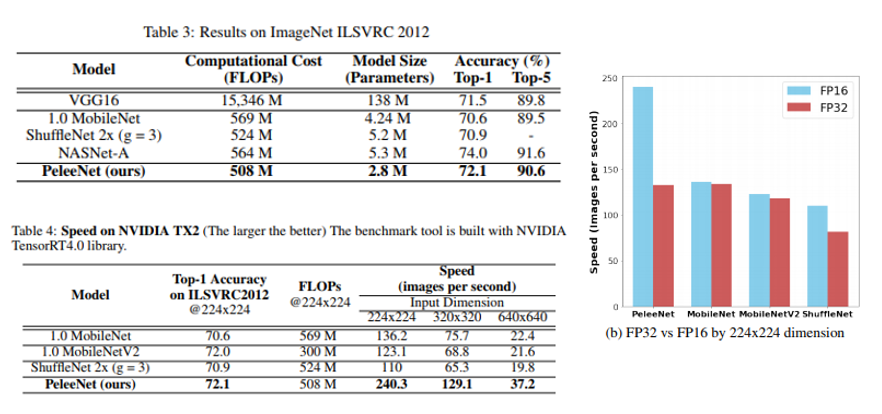
우선 비슷한 Computational Cost를 갖는 다른 CNN 구조들에 비해 적은 수의 parameter를 가지고 있고 NASNet-A 다음으로 높은 정확도를 보이고 있습니다. AutoML을 통해 찾은 NASNet-A의 위엄을 다시 한번 확인할 수 있는 자료이기도 합니다.
또한 NVIDIA의 Jetson TX2 보드에서 실제 processing time을 측정하기도 하였고 이 때는 Inference 가속을 위해 TensorRT library를 사용하였습니다. 실험 결과 MobileNet, ShuffleNet들에 비해 정확하면서 약 2배 정도의 FPS를 보이고 있는 것을 확인하실 수 있습니다.
FLOPs가 비슷한데 속도 차이가 나는 이유는 MobileNet, ShuffleNet에 사용되는 Depthwise-Separable Convolution 연산이 Jetson TX2의 FP16 연산과 호환이 되지 않아서 가속 효과를 보기 힘들기 때문입니다. 실제로 위의 그림을 보시면 PeleeNet은 FP16에서 속도가 빨라지는 반면, Depthwise-Separabel Convolution이 포함 되어있는 MobileNet, ShuffleNet은 가속 효과가 미미한 것을 확인하실 수 있습니다. Jetson Board 외에도 iPhone8에서도 실험을 수행하였으며 논문에서 확인하실 수 있습니다.
Pelee: A Real-Time Object Detection System
다음 설명드릴 부분은 Object Detection의 대표적인 모델인 SSD를 optimize시키고, Feature Extractor 역할을 하는 Backbone CNN으로 PeleeNet을 사용한 Pelee 입니다. 사실 논문 제목에서도 Object Detection을 언급하고 있지만, 정작 논문에서는 Classification에 대한 내용이 주를 이루고, Object Detection은 거창한 연구를 수행하지는 않았습니다. Pelee의 주요 특징은 다음과 같습니다.
1. Feature Map Selection
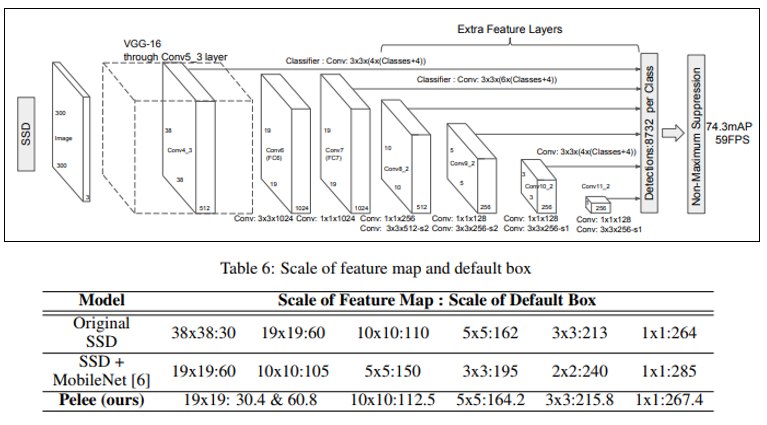
Original SSD는 6가지의 scale의 feature map에 대해 detection을 수행합니다. SSD 기반의 SSD + MobileNet 방식도 6가지의 scale을 사용하였는데, Pelee는 연산량을 줄이기 위해 38x38 feature map은 사용하지 않고 5가지의 scale만 사용하였습니다.
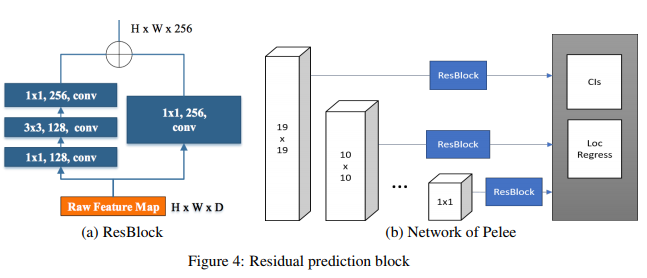
2. Residual Prediction Block
SSD 구조의 Prediction Block을 Residual Block으로 사용한 것도 Pelee의 특징이며 아래 그림과 같은 ResBlock을 사용하였습니다.
3. Small Convolutional Kernel for Prediction
마지막으로 바로 위의 그림에 있는 Residual Prediction Block에 1x1 convolution kernel을 사용하여 연산량을 줄이는 방식을 제안하였습니다. 굉장히 단순한 아이디어들로 구성이 되어있습니다.
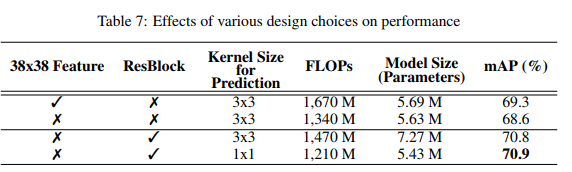
위의 3가지 특징을 순차적으로 적용함에 따라 Detector의 연산량과 정확도(mAP)가 어떻게 변하는지에 대해 ablation study를 한 결과는 위의 표에 나와있습니다.
실험 결과
Pelee의 성능을 검증하기 위해 속도를 타겟으로 한 다른 Object Detection 모델들과 성능을 비교하였으며, 대표적인 데이터셋인 PASCAL VOC 2007, COCO 데이터셋에 대해 검증을 진행하였습니다.
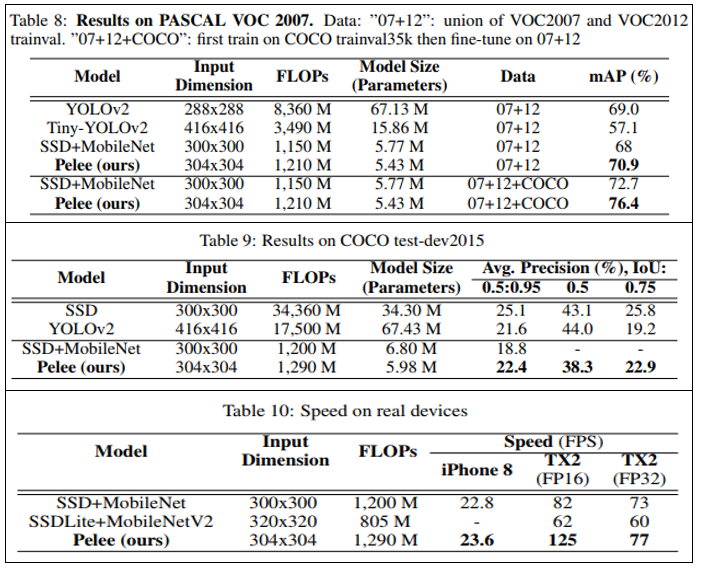
논문에서 제시하고 있는 실험 결과 표들을 한눈에 정리하였으며 대체로 빠르고 정확하다는 것을 확인하실 수 있습니다. 또한 마찬가지로 Jetson Board에서는 FP16일 때 가속 효과가 크다는 사실도 Classification 실험 결과와 일치하는 것을 확인하실 수 있습니다.
결론
이번 포스팅에서는 2018년 NeurIPS에 발표된 “Pelee: A Real-Time Object Detection System on Mobile Devices” 라는 논문을 리뷰해보았습니다. 방법들이 어렵지 않아 쉽게 이해가 가능하며 눈에 보이는 수치적인 성능도 좋은 편이라 각자 연구에도 적용해보시는 것을 추천드립니다. 다음 편에는 논문의 내용 중 Classification을 다룬 PeleeNet을 PyTorch로 구현하는 과정을 설명드릴 예정입니다. 감사합니다!