Fast Style Transfer PyTorch Tutorial
안녕하세요, 오늘은 Style Transfer를 PyTorch로 실습하는 과정을 설명드릴 예정입니다. 고흐풍을 다른 그림에 입히는 예제는 다들 인터넷에서 한번쯤은 보셨을 것입니다. 저 또한 인터넷으로만 보다가 직접 학습시키고 test를 해보고 싶어서 코드를 찾다가 pytorch의 example repository 에 잘 짜여진 code가 있어서 이전 포스팅들과 마찬가지로 효율적인 실습을 위해 ipynb 형태로 가공하였습니다.
실습 코드는 해당 github repository 에 업로드 해두었으니 다운 받으셔서 사용하시면 됩니다.
Battle Ground Video Demo using fast-style-transfer
이번 실습에는 제가 즐겨하는 게임인 배틀그라운드의 플레이 영상을 이용할 예정입니다. 사실 이 포스팅을 작성해야겠다고 생각한 계기도 게임을 하다가 문득 떠오른 아이디어에서 출발하였으며, 혹시 이 게임을 잘 모르시는 분들을 위해 간략하게 소개를 드리면 다음과 같습니다.

100인의 플레이어가 전투에 필요한 물자들을 얻고 최종 1인을 향해 플레이하는 생존 게임이며 에란겔(도심, 산), 미라마(사막), 사녹(열대우림), 비켄디(설원) 크게 4가지 테마의 맵이 존재합니다. 그래서 저는 각 맵 간의 style transfer를 해보면 재미있겠다는 호기심 하나로 이번 실습 코드를 준비해보았으며, 결과를 미리 보여드리면 다음과 같습니다.
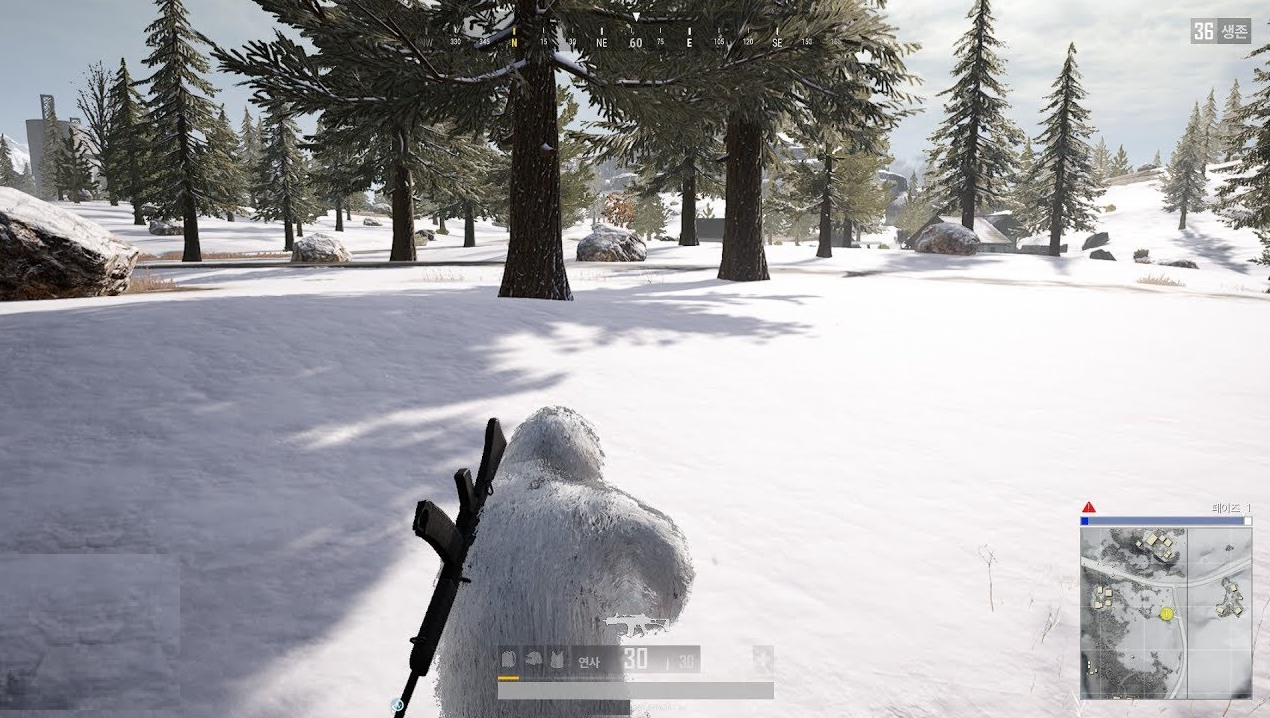
우선 Style Transfer의 Style이 되는 이미지는 위의 그림과 같이 설원을 배경으로 플레이한 이미지를 준비해보았습니다.
이러한 배경의 style을 전혀 다른 테마인 미라마(사막), 사녹(열대우림)에 입혔을 때의 모습은 다음과 같습니다. 아래의 데모 영상 2개는 제가 직접 플레이한 영상을 가져온 것이며, 왼쪽이 원본, 오른쪽이 설원의 style을 입혔을 때의 결과를 보여주고 있습니다.


이제 어떻게 이러한 결과를 얻으실 수 있는지 차근차근 설명을 드리도록 하겠습니다.
논문 간단 소개
오늘 다룰 논문은 Perceptual Losses for Real-Time Style Transfer and Super-Resolution (2016, ECCV) 라는 논문이며, 논문에 제목에서 알 수 있듯이 Perceptual loss라는 것을 제안하였고 Real-Time으로 동작할 만큼 빠른 방법을 제안하였습니다.
기존 방법과 차이점
Style Transfer의 초기 논문이라 부를 수 있는 Image Style Transfer Using Convolutional Neural Networks (2016, CVPR) 은 pretrained된 network에 content image와 style image를 쌍으로 넣어줘서 매번 학습을 통해 style transfer를 하는 방식이다보니, content image가 바뀔 때 마다 다시 학습을 시켜야 하므로 많은 연산을 수행하여야 하는 단점이 있습니다.
본 논문은 이러한 문제를 해결하기 위해 network에 style image 1장을 학습시키고 그 network를 그대로 이용하는 방법을 제안하였습니다. 즉 여러 장의 content image로 style transfer(inference)를 할 때 기존 방법처럼 매번 재학습을 시키지 않고 단순히 inference만 하면 되기 때문에 Real-Time으로 동작이 가능하다는 장점이 있습니다.
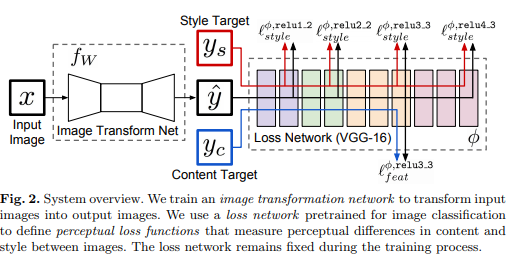
위의 그림은 본 논문의 transformation network 구조를 보여주고 있습니다. 오늘 실습에서는 위의 구조를 구현하고 학습을 돌리고 테스트를 해볼 예정입니다.
논문의 자세한 내용이 궁금하신 분들은 본 논문을 읽어보시거나, 본 논문을 리뷰해놓은 다른 blog 글들을 참고하시면 더 이해가 잘 되실 것이라 생각합니다.
Requirements
지난 PyTorch ipynb 실습과 마찬가지로 google colab 을 이용하여 실습을 진행할 예정이며 ipynb를 google drive에 업로드한 뒤 colab으로 실행하시면 아무런 셋팅 없이 바로 코드를 실행해볼 수 있습니다.
또한 이번에는 이전 실습들과는 다르게 준비해야 할 것들이 많습니다. 그만큼 컨텐츠가 다양해졌다는 것을 의미하며, 이번 실습을 통해 얻어가실 수 있는 것들은 다음과 같습니다.
- Google Drive 연동 (2GB 이상의 용량 필요)
- COCO Dataset 다운로드 및 loading
- Transfer Learning을 위한 checkpoint 저장
- Style Transfer 결과를 이미지 혹은 동영상으로 저장
Code Implementation
pytorch example 코드를 기반으로 여러분들이 쉽게 실습을 해보실 수 있도록 정리한 ipynb 코드를 하나하나 설명드리도록 하겠습니다.
1. Google Drive 연동
from google.colab import drive
drive.mount("/content/gdrive")
google drive는 단 두줄로 연동이 가능하며 해당 code block을 실행하시고 권한 요청을 승인하시면 저희 코드에서 google drive에 접근이 가능하게 됩니다. 즉, google drive에 있는 파일을 read 할 수도 있고, 실습 결과물들을 google drive에 저장을 할 수도 있게 됩니다.
2. COCO dataset 다운로드 & Style Image 준비
본 논문에서는 network 학습을 위해 COCO 2014 training dataset을 사용하였는데, 용량이 13GB로 큰 편이라 대부분 Google Drive를 무료로 사용 중이신 분들은 용량이 15GB로 제한되기 때문에 실습에 무리가 있을 수 있습니다. 그래서 저는 비교적 용량이 적은 COCO 2017 validation dataset을 이용하였으며, 대신 training epoch을 키워주는 방식을 사용하였습니다. 용량이 많으신 분들은 원 논문처럼 COCO 2014 training set을 사용하시는 것을 권장합니다.
- COCO 2014 training: 약 80000장 / 13GB
- COCO 2017 validation: 약 5000장 / 1GB –> epoch을 16배 키워서 사용할 예정
COCO 2017 validation set은 해당 링크 를 클릭하시면 다운받으실 수 있으며, 다운 받으셔서 압축을 해제하신 후 google drive에 업로드하시면 됩니다. 혹은 압축파일 자체를 업로드하시고 google drive 내에서 압축 해제를 하셔도 무방합니다.
학습에 필요한 COCO dataset이 준비가 되셨다면, 이제는 style image를 준비하시면 됩니다. 저는 위에서 보여드린 것 처럼 배틀그라운드의 4가지 테마의 맵 중에 설원 테마인 비켄디의 플레이 이미지 1장을 준비하였습니다. 마찬가지로 style image도 google drive에 업로드를 하신 뒤에 잘 업로드가 되었는지 확인하실 수 있습니다.
style_image_location = "/content/gdrive/My Drive/Colab_Notebooks/data/vikendi.jpg"
style_image_sample = Image.open(style_image_location, 'r')
display(style_image_sample)
style image가 제대로 출력이 되지 않으면 아마 경로가 잘못되었을 가능성이 높으므로 경로를 잘 확인해주시면 됩니다.
3. 학습 parameter 설정
다음 설명드릴 부분은 학습 parameter들과 network를 구성하는 module class를 생성하는 부분입니다.
batch_size = 8
random_seed = 10
num_epochs = 64
initial_lr = 1e-3
checkpoint_dir = "/content/gdrive/My Drive/Colab_Notebooks/data/"
content_weight = 1e5
style_weight = 1e10
log_interval = 50
checkpoint_interval = 500
#running_option = "test"
running_option = "test_video"
#running_option = "training"
우선 batch size는 원 논문에서는 4를 사용하였지만 저는 빠른 학습을 위해 8을 사용하였습니다. 또한 전체 학습 epoch는 원 논문에서는 2 epoch을 사용하였지만 저는 batch size와 dataset의 개수가 다르기 때문에 iteration 수를 맞춰주기 위해 64를 사용하였습니다. batch size와 training epoch는 본인이 구성하신 데이터셋과 GPU 환경에 맞게 조절하셔서 사용하시면 됩니다.
running_option은 뒤에 설명드릴 training과 test 중 어떤 task를 수행할지를 나타내며 처음에는 training으로 설정하시고, 학습이 끝난 뒤에는 test 혹은 test_video로 설정하시면 됩니다.
4. Module Class 생성
Module Class는 기존 코드의 구조를 거의 그대로 사용하였으며 이해하시는데 큰 무리가 없으실 것으로 생각합니다.
class VGG16(torch.nn.Module):
def __init__(self, requires_grad=False):
super(VGG16, self).__init__()
vgg_pretrained_features = models.vgg16(pretrained=True).features
self.slice1 = torch.nn.Sequential()
self.slice2 = torch.nn.Sequential()
self.slice3 = torch.nn.Sequential()
self.slice4 = torch.nn.Sequential()
for x in range(4):
self.slice1.add_module(str(x), vgg_pretrained_features[x])
for x in range(4, 9):
self.slice2.add_module(str(x), vgg_pretrained_features[x])
for x in range(9, 16):
self.slice3.add_module(str(x), vgg_pretrained_features[x])
for x in range(16, 23):
self.slice4.add_module(str(x), vgg_pretrained_features[x])
if not requires_grad:
for param in self.parameters():
param.requires_grad = False
def forward(self, X):
h = self.slice1(X)
h_relu1_2 = h
h = self.slice2(h)
h_relu2_2 = h
h = self.slice3(h)
h_relu3_3 = h
h = self.slice4(h)
h_relu4_3 = h
vgg_outputs = namedtuple("VggOutputs", ['relu1_2', 'relu2_2', 'relu3_3', 'relu4_3'])
out = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3)
return out
class ConvLayer(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride):
super(ConvLayer, self).__init__()
reflection_padding = kernel_size // 2
self.reflection_pad = nn.ReflectionPad2d(reflection_padding)
self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size, stride)
def forward(self, x):
out = self.reflection_pad(x)
out = self.conv2d(out)
return out
class ResidualBlock(nn.Module):
"""ResidualBlock
introduced in: https://arxiv.org/abs/1512.03385
recommended architecture: http://torch.ch/blog/2016/02/04/resnets.html
"""
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.conv1 = ConvLayer(channels, channels, kernel_size=3, stride=1)
self.in1 = nn.InstanceNorm2d(channels, affine=True)
self.conv2 = ConvLayer(channels, channels, kernel_size=3, stride=1)
self.in2 = nn.InstanceNorm2d(channels, affine=True)
self.relu = nn.ReLU()
def forward(self, x):
residual = x
out = self.relu(self.in1(self.conv1(x)))
out = self.in2(self.conv2(out))
out = out + residual
return out
class UpsampleConvLayer(nn.Module):
"""UpsampleConvLayer
Upsamples the input and then does a convolution. This method gives better results
compared to ConvTranspose2d.
ref: http://distill.pub/2016/deconv-checkerboard/
"""
def __init__(self, in_channels, out_channels, kernel_size, stride, upsample=None):
super(UpsampleConvLayer, self).__init__()
self.upsample = upsample
reflection_padding = kernel_size // 2
self.reflection_pad = nn.ReflectionPad2d(reflection_padding)
self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size, stride)
def forward(self, x):
x_in = x
if self.upsample:
x_in = nn.functional.interpolate(x_in, mode='nearest', scale_factor=self.upsample)
out = self.reflection_pad(x_in)
out = self.conv2d(out)
return out
class TransformerNet(nn.Module):
def __init__(self):
super(TransformerNet, self).__init__()
# Initial convolution layers
self.encoder = nn.Sequential()
self.encoder.add_module('conv1', ConvLayer(3, 32, kernel_size=9, stride=1))
self.encoder.add_module('in1', nn.InstanceNorm2d(32, affine=True))
self.encoder.add_module('relu1', nn.ReLU())
self.encoder.add_module('conv2', ConvLayer(32, 64, kernel_size=3, stride=2))
self.encoder.add_module('in2', nn.InstanceNorm2d(64, affine=True))
self.encoder.add_module('relu2', nn.ReLU())
self.encoder.add_module('conv3', ConvLayer(64, 128, kernel_size=3, stride=2))
self.encoder.add_module('in3', nn.InstanceNorm2d(128, affine=True))
self.encoder.add_module('relu3', nn.ReLU())
# Residual layers
self.residual = nn.Sequential()
for i in range(5):
self.residual.add_module('resblock_%d' %(i+1), ResidualBlock(128))
# Upsampling Layers
self.decoder = nn.Sequential()
self.decoder.add_module('deconv1', UpsampleConvLayer(128, 64, kernel_size=3, stride=1, upsample=2))
self.decoder.add_module('in4', nn.InstanceNorm2d(64, affine=True))
self.encoder.add_module('relu4', nn.ReLU())
self.decoder.add_module('deconv2', UpsampleConvLayer(64, 32, kernel_size=3, stride=1, upsample=2))
self.decoder.add_module('in5', nn.InstanceNorm2d(32, affine=True))
self.encoder.add_module('relu5', nn.ReLU())
self.decoder.add_module('deconv3', ConvLayer(32, 3, kernel_size=9, stride=1))
def forward(self, x):
encoder_output = self.encoder(x)
residual_output = self.residual(encoder_output)
decoder_output = self.decoder(residual_output)
return decoder_output
단순한 구조로 이루어져있으므로 별다른 설명은 하지 않도록 하겠습니다.
5. Util Function 정의
이미지를 처리하거나, loss 계산에 사용되는 gram matrix 등 여러 util function들을 정의한 부분입니다.
""" Util Functions """
def load_image(filename, size=None, scale=None):
img = Image.open(filename)
if size is not None:
img = img.resize((size, size), Image.ANTIALIAS)
elif scale is not None:
img = img.resize((int(img.size[0] / scale), int(img.size[1] / scale)), Image.ANTIALIAS)
return img
def save_image(filename, data):
img = data.clone().clamp(0, 255).numpy()
img = img.transpose(1, 2, 0).astype("uint8")
img = Image.fromarray(img)
display(img)
img.save(filename)
def post_process_image(data):
img = data.clone().clamp(0, 255).numpy()
img = img.transpose(1, 2, 0).astype("uint8")
#img = Image.fromarray(img)
return img
def gram_matrix(y):
(b, ch, h, w) = y.size()
features = y.view(b, ch, w * h)
features_t = features.transpose(1, 2)
gram = features.bmm(features_t) / (ch * h * w)
return gram
def normalize_batch(batch):
# normalize using imagenet mean and std
mean = batch.new_tensor([0.485, 0.456, 0.406]).view(-1, 1, 1)
std = batch.new_tensor([0.229, 0.224, 0.225]).view(-1, 1, 1)
batch = batch.div_(255.0)
return (batch - mean) / std
6. 데이터셋 로딩, 주요 기능 정의
다음 설명드릴 부분은 위에서 다운로드받은 COCO dataset을 loading하고, training과 test에 필요한 주요 기능들을 정의하는 부분입니다.
np.random.seed(random_seed)
torch.manual_seed(random_seed)
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Lambda(lambda x: x.mul(255))
])
style_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.mul(255))
])
print(glob.glob("/content/gdrive/My Drive/Colab_Notebooks/data/COCO/val2017/*"))
train_dataset = datasets.ImageFolder("/content/gdrive/My Drive/Colab_Notebooks/data/COCO", transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size)
transformer = TransformerNet()
vgg = VGG16(requires_grad=False).to(device)
optimizer = torch.optim.Adam(transformer.parameters(), initial_lr)
mse_loss = nn.MSELoss()
style = load_image(filename=style_image_location, size=None, scale=None)
style = style_transform(style)
style = style.repeat(batch_size, 1, 1, 1).to(device)
features_style = vgg(normalize_batch(style))
gram_style = [gram_matrix(y) for y in features_style]
데이터셋은 torchvision.datasets.ImageFolder 라는 편리한 기능을 이용하여 loading을 하였고, resize와 centor crop등의 전처리를 거치게됩니다.
또한 위에서 정의한 Module Class들을 이용하여 network를 구성한 뒤 adam optimizer, loss function 등을 정의하게 됩니다.
7. Transfer Learning, Inference 를 위한 checkpoint loading
transfer_learning = False
ckpt_model_path = os.path.join(checkpoint_dir, "ckpt_epoch_63_batch_id_500.pth")
if transfer_learning:
checkpoint = torch.load(ckpt_model_path, map_location=device)
transformer.load_state_dict(checkpoint['model_state_dict'])
transformer.to(device)
이 부분은 colab을 이용하신다면 필수로 거쳐야 하는 부분입니다. colab은 GPU를 연속으로 8시간 사용 이 가능하기 때문에, 학습이 8시간보다 오래 소요되는 경우에는 8시간마다 다시 colab의 런타임을 초기화해줘야하는 문제가 발생합니다. 그러므로 8시간동안 학습된 모델을 저장하고 있어야 8시간 뒤에 이어서 학습을 할 수 있습니다.
transfer_learning option이 True인 경우 google drive에 저장된 checkpoint에서 학습을 이어서 시작하실 수 있으며, 새로 학습을 시작하거나, 학습이 끝나서 inference를 하는 경우에는 해당 옵션을 False로 설정하시면 됩니다.
8. Training Phase
다음 설명드릴 부분은 training 부분이며 위에서 설명드린 transfer_learning을 하는 경우에는 저장된 checkpoint에서 진행 중인 epoch를 받아와서 그 지점부터 이어서 학습하고, 그렇지 않은 경우에는 첫 epoch부터 학습을 시작하게 됩니다.
if running_option == "training":
if transfer_learning:
transfer_learning_epoch = checkpoint['epoch']
else:
transfer_learning_epoch = 0
for epoch in range(transfer_learning_epoch, num_epochs):
transformer.train()
agg_content_loss = 0.
agg_style_loss = 0.
count = 0
for batch_id, (x, _) in enumerate(train_loader):
n_batch = len(x)
count += n_batch
optimizer.zero_grad()
x = x.to(device)
y = transformer(x)
y = normalize_batch(y)
x = normalize_batch(x)
features_y = vgg(y)
features_x = vgg(x)
content_loss = content_weight * mse_loss(features_y.relu2_2, features_x.relu2_2)
style_loss = 0.
for ft_y, gm_s in zip(features_y, gram_style):
gm_y = gram_matrix(ft_y)
style_loss += mse_loss(gm_y, gm_s[:n_batch, :, :])
style_loss *= style_weight
total_loss = content_loss + style_loss
total_loss.backward()
optimizer.step()
agg_content_loss += content_loss.item()
agg_style_loss += style_loss.item()
if (batch_id + 1) % log_interval == 0:
mesg = "{}\tEpoch {}:\t[{}/{}]\tcontent: {:.6f}\tstyle: {:.6f}\ttotal: {:.6f}".format(
time.ctime(), epoch + 1, count, len(train_dataset),
agg_content_loss / (batch_id + 1),
agg_style_loss / (batch_id + 1),
(agg_content_loss + agg_style_loss) / (batch_id + 1)
)
print(mesg)
if checkpoint_dir is not None and (batch_id + 1) % checkpoint_interval == 0:
transformer.eval().cpu()
ckpt_model_filename = "ckpt_epoch_" + str(epoch) + "_batch_id_" + str(batch_id + 1) + ".pth"
print(str(epoch), "th checkpoint is saved!")
ckpt_model_path = os.path.join(checkpoint_dir, ckpt_model_filename)
torch.save({
'epoch': epoch,
'model_state_dict': transformer.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': total_loss
}, ckpt_model_path)
transformer.to(device).train()
학습을 돌리시면 일정 주기(log_interval)마다 학습 loss를 출력하고, 매 epoch마다 checkpoint를 저장하는 방식으로 구현을 하였습니다. 또한 checkpoint에는 transformation network의 state와 optimizer의 state, epoch, loss 등을 저장합니다.
9. Test(Inference) Phase
다음 설명드릴 부분은 학습된 transformation network에 content image로 style transfer를 하는 과정을 보여주고 있습니다. 제가 올려놓은 ipynb에는 이미지 한장을 입력으로 하여 test를 하는 코드와, video를 입력으로 하여 test를 하는 코드를 둘다 만들어두었습니다. 이 글에서는 video를 입력으로 하는 부분을 설명드리도록 하겠습니다.
if running_option == "test_video":
with torch.no_grad():
style_model = TransformerNet()
ckpt_model_path = os.path.join(checkpoint_dir, "ckpt_epoch_63_batch_id_500.pth")
checkpoint = torch.load(ckpt_model_path, map_location=device)
# remove saved deprecated running_* keys in InstanceNorm from the checkpoint
for k in list(checkpoint.keys()):
if re.search(r'in\d+\.running_(mean|var)$', k):
del checkpoint[k]
style_model.load_state_dict(checkpoint['model_state_dict'])
style_model.to(device)
cap = cv2.VideoCapture("/content/gdrive/My Drive/Colab_Notebooks/data/mirama_demo.mp4")
frame_cnt = 0
fourcc = cv2.VideoWriter_fourcc(*'XVID') #cv2.VideoWriter_fourcc(*'MP42')
out = cv2.VideoWriter('/content/gdrive/My Drive/Colab_Notebooks/data/mirama_demo_result.avi', fourcc, 60.0, (1920,1080))
while(cap.isOpened()):
ret, frame = cap.read()
try:
frame = frame[:,:,::-1] - np.zeros_like(frame)
except:
break
print(frame_cnt, "th frame is loaded!")
content_image = frame
content_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.mul(255))
])
content_image = content_transform(content_image)
content_image = content_image.unsqueeze(0).to(device)
output = style_model(content_image).cpu()
#save_image("/content/gdrive/My Drive/Colab_Notebooks/data/vikendi_video_result/" + str(frame_cnt) +".png", output[0])
out.write(post_process_image(output[0]))
frame_cnt += 1
cap.release()
out.release()
cv2.destroyAllWindows()
inference는 학습이 다 끝난 후 저장된 checkpoint를 불러와서 model을 구성한 뒤 시작합니다. 저장된 checkpoint는 앞서 설명드린 github reopository 에 업로드를 해두었으니, 해당 file을 download 받으시면 별도의 학습 없이 바로 test를 하실 수 있습니다.
Test에 사용할 video sample도 google drive에 업로드를 한 뒤에, opencv의 VideoCapture를 통해 불러와줍니다.
style transfer를 적용할 video의 경로, 결과물 video가 저장될 경로를 알맞게 설정해주시고 해당 code block을 실행하시면 매 frame마다 inference를 한 뒤에 video 형태로 저장이 되는 것을 확인하실 수 있습니다.
결론
이번 포스팅에서는 실시간으로 동작이 가능한 Fast Style Transfer를 직접 구현해보고 cumstom dataset으로 test를 하는 과정을 설명드렸습니다. 코드는 길지만 어렵게 짜여져있지 않아서 쉽게 이해하실 수 있고, 직접 본인의 dataset으로 training과 test를 해보실 수 있도록 ipynb 스크립트로 정리를 하여 공유를 드렸습니다.
또한 비디오로 입출력을 하는 과정, colab에서 학습을 이어하기 위한 transfer learning, google drive 연동 등 다양한 컨텐츠를 다루고 있어서 꼭 이번 실습 뿐만 아니라 여러분이 pytorch를 사용하실 때도 요긴하게 쓰일 수 있는 방법이니 잘 익혀두시는 것을 권장드립니다. 혹시 코드를 보시고 이해가 안되시는 부분이나 막히는 부분이 있으면 편하게 댓글 남겨 주시면 감사하겠습니다. 읽어주셔서 감사합니다.
Referencecomments powered by Disqus