CVPR 2019 overview
안녕하세요, 이번 포스팅에서는 2019년 6월 15일 ~ 21일 미국 롱비치에서 개최될 CVPR 2019 학회의 accepted paper들에 대해 분석하여 시각화한 자료를 보여드리고, accepted paper 중에 이미지 인식, 영상 처리와 관련이 있는 논문 20편에 대해 제 주관적으로 리스트를 정리해보았습니다. 오늘 다루지 않을 주제들은 자연어 처리(NLP), 강화학습(RL), 로봇 제어 등이며 이러한 주제들은 제가 배경지식이 많이 없어서 정리를 하지 못한 점 양해 부탁드립니다!
전체 accepted paper가 약 1300편이다보니 하나하나 읽어보는 것은 불가능하여서, 제가 제목만 보고 재미있을 것 같은 논문 위주로 정리를 해보았습니다.
당부드리는 말씀은 제가 정리한 논문 리스트에 없다고 재미 없거나 추천하지 않는 논문은 절대 아니고 단지 제 주관에 의해 정리된 것임을 강조 드리고 싶습니다.
CVPR 2019 Paper Statistics
지난번 소개드렸던 SIGGRAPH 2018 , NeurIPS 2018 , ICLR 2019 에 이어서 4번째 학회 Overview 글을 작성하게 되었습니다. 매번 하던 것처럼 이번에 다룰 CVPR 2019는 최근 몇 편의 논문이 submit되고 accept되는 지 조사를 해보았습니다.
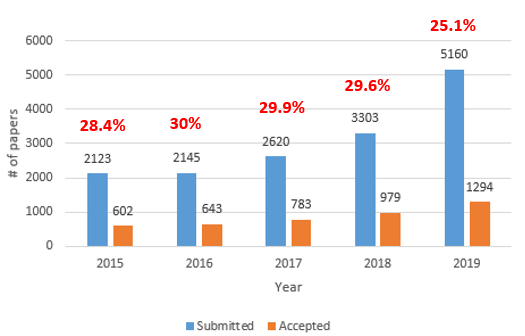
그림을 보면 매년 제출되는 논문 편수도 증가하고 있고, 그에 따라서 accept되는 논문들의 편수도 증가를 하고 있습니다. 불과 2년전에 비해 규모가 약 2배가량 커졌으며 약 30% 대의 acceptance rate를 보이다가, 올해는 제출된 논문 편수가 약 2000편 가까이 증가를 하면서 25%대로 acceptance rate가 크게 떨어진 것을 확인할 수 있습니다.
CVPR은 어떤 키워드의 논문들이 많이 제출되는지 확인하기 위해 간단한 python script를 작성해서 논문 제목에 포함된 키워드를 분석하여 시각화를 진행하였습니다. 시각화를 진행한 코드는 해당 repository 에서 확인하실 수 있습니다.
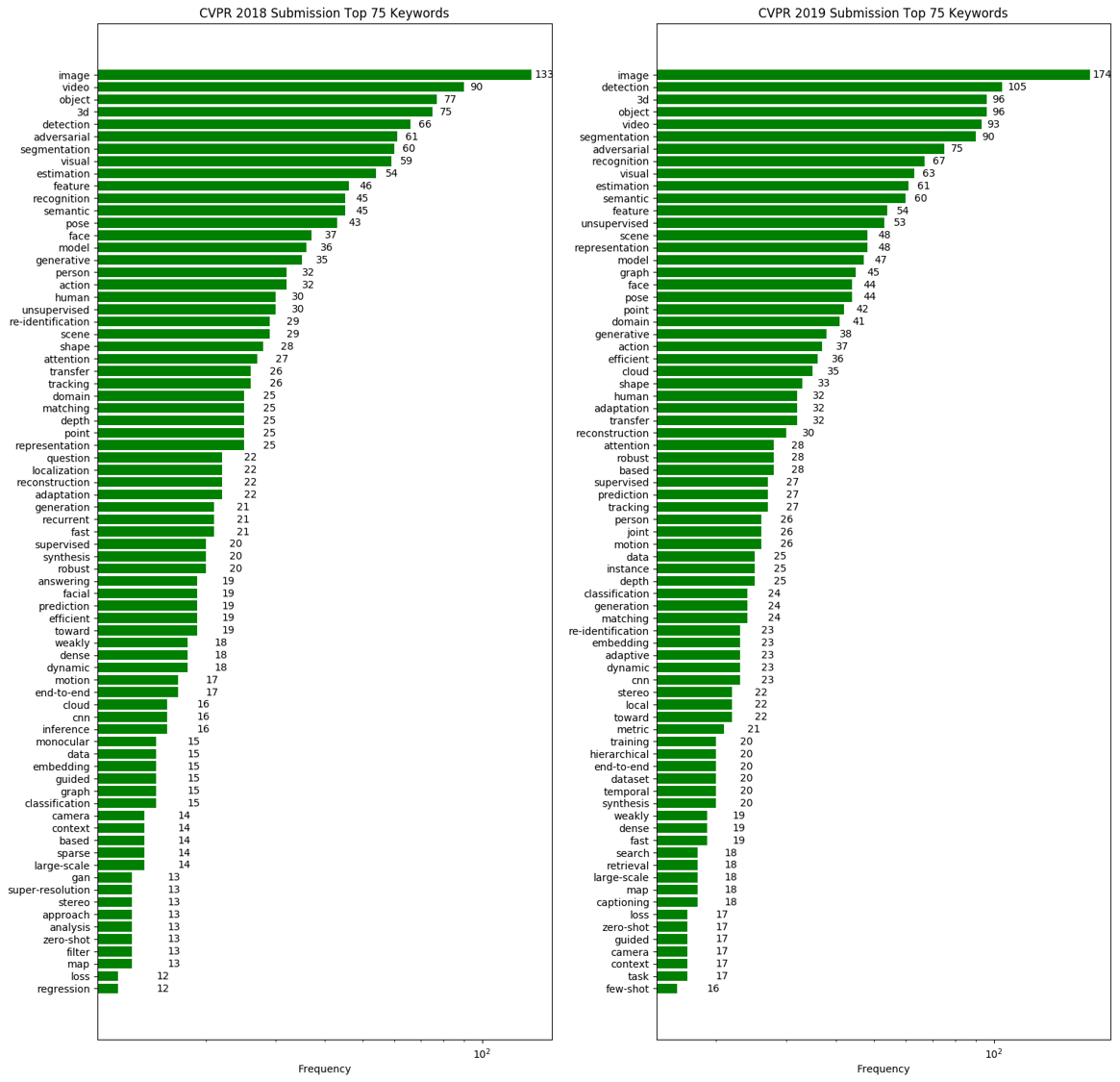
Computer Vision 학회이다 보니 image, video, object 등 general한 키워드들이 주를 이루고 있고, 주목할 만한 점은 2018년 대비 graph, representation, cloud 등의 키워드를 가진 논문들이 약 2배 이상 빈도가 증가하였습니다. 이러한 키워드 정보를 참고하면 최근 학회에 제출되는 논문들의 트렌드를 파악하는데 도움이 될 수 있습니다.
참고로 올해는 총 1294편의 논문이 accept 되었고 그 중 288편이 oral presentation에 선정이 되었습니다. 저는 이 논문들 중 20편을 선정해서 간단하게 소개를 드릴 예정입니다.
CVPR 2019 주요 논문 소개
앞서 말씀드렸듯이 CVPR 2019에 accept된 논문을 모두 다 확인하기엔 시간과 체력이 부족하여서, 간단하게 훑어보면서 재미가 있을 것 같은 논문들을 추려보았습니다. 총 20편의 논문이며, 8편의 oral paper, 12편의 poster paper로 준비를 해보았습니다. 각 논문에서 제안한 방법들을 그림과 함께 간략하게 소개드릴 예정이며, 논문의 디테일한 내용은 직접 논문을 읽어 보시는 것을 추천 드립니다.
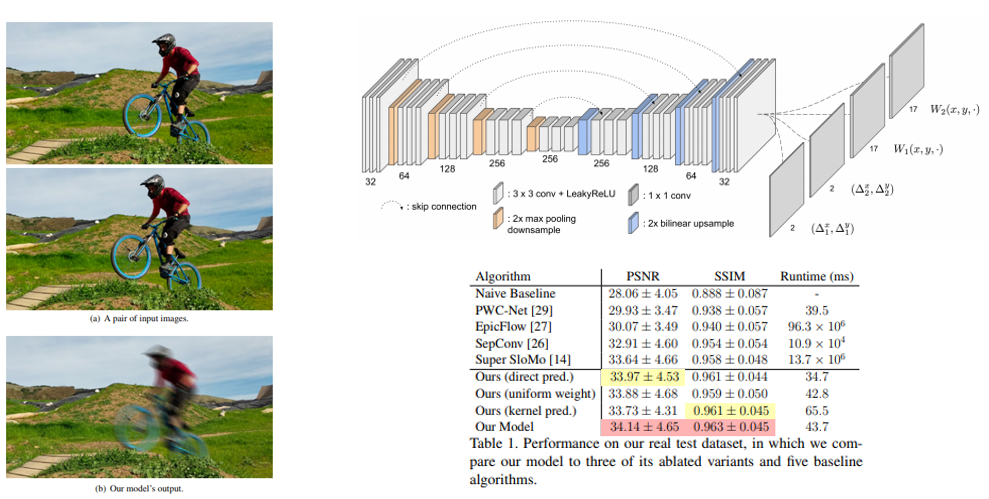
1. Learning to Synthesize Motion Blur (Oral)
- Motion Blur를 제거하는 연구가 아닌, Cinematography, artful photo 등에 활용하기 위한 Motion Blur를 그럴싸하게 합성하는 연구이며, 연속된 unblurred image pair를 이용하여 blur image를 합성하는 CNN 구조 를 제안함.
- Motion Blur 생성을 위한 Large-scale synthetic training dataset을 생성하는 과정도 논문에서 다루고 있음.
- Demo Video
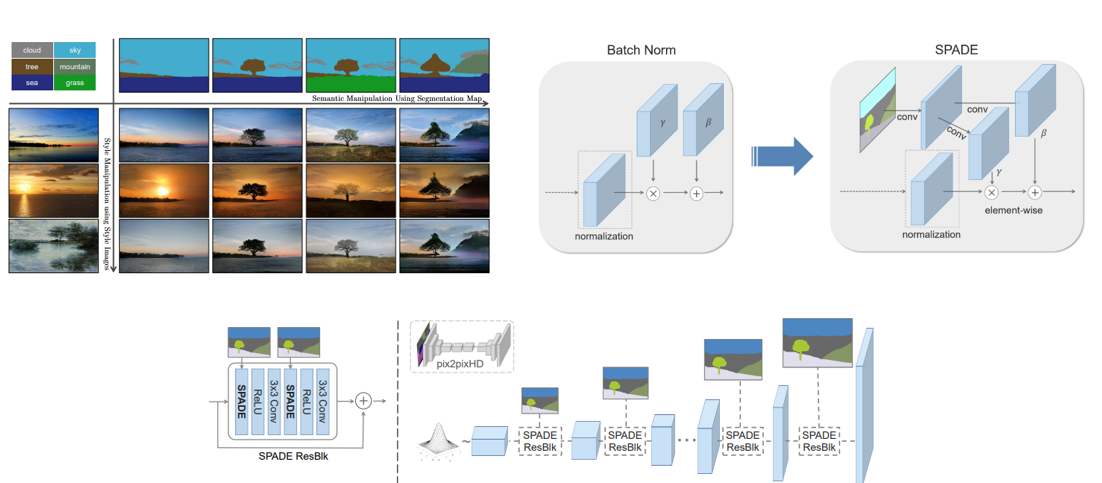
2. Semantic Image Synthesis with Spatially-Adaptive Normalization (Oral)
- Input semantic layout(segmentation map)을 이용하여 photorealistic image를 생성하는 방법을 다루고 있으며, Spatially-adaptive normalization 방법을 제안함.
- Demo Code
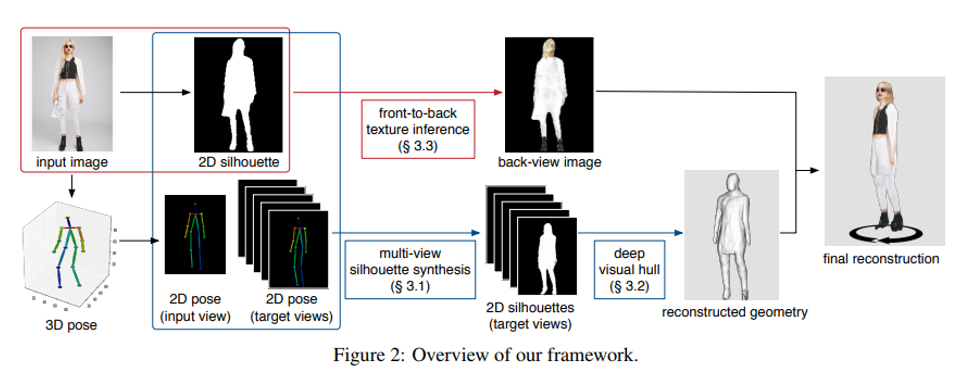
3. SiCloPe: Silhouette-Based Clothed People (Oral)
- Single image로부터 textured 3D model을 reconstruct하는 방법 을 제안함.
- 2D Silhouette을 기반으로 3D joint 정보를 이용하여 3D shape를 생성해내며 실생활에 여러 application에 접목이 가능한 수준으로 보임.
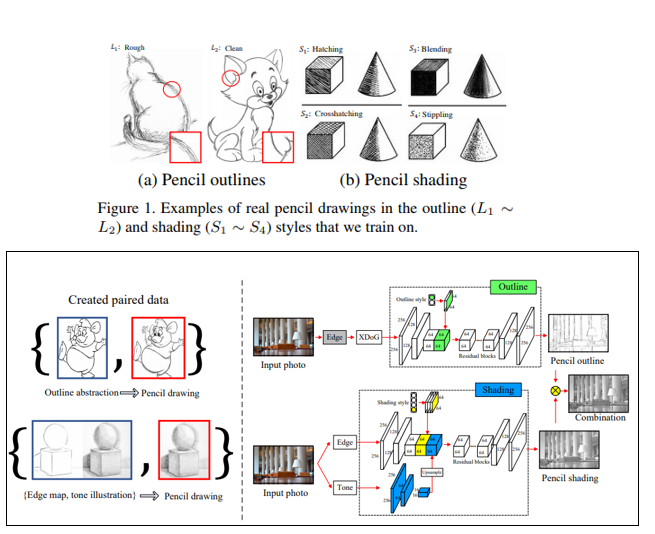
4. Im2Pencil: Controllable Pencil Illustration from Photographs
- Controllable한 photo-to-pencil image translation 방법을 제안함.
- Pencil outline(rough, clean)과 Pencil shading(4가지)를 변화시키며 pencil image를 생성해낼 수 있는 것이 장점이며, 이를 학습시키기 위한 training data pair를 생성하는 과정도 논문에서 다루고 있음.
- Demo Code

5. End-to-End Time-Lapse Video Synthesis from a Single Outdoor Image
- 하나의 이미지로부터 time-lapse video를 생성해내는 방법을 제안하였으며, End-to-End로 학습이 되는 것이 특징임.
- 학습 단계에서는 time-lapse video와 image sequence를 사용하지만 Inference 단계에서는 오로지 single image만 필요하며 multi-frame joint conditional GAN 기반 방법론을 제안함.

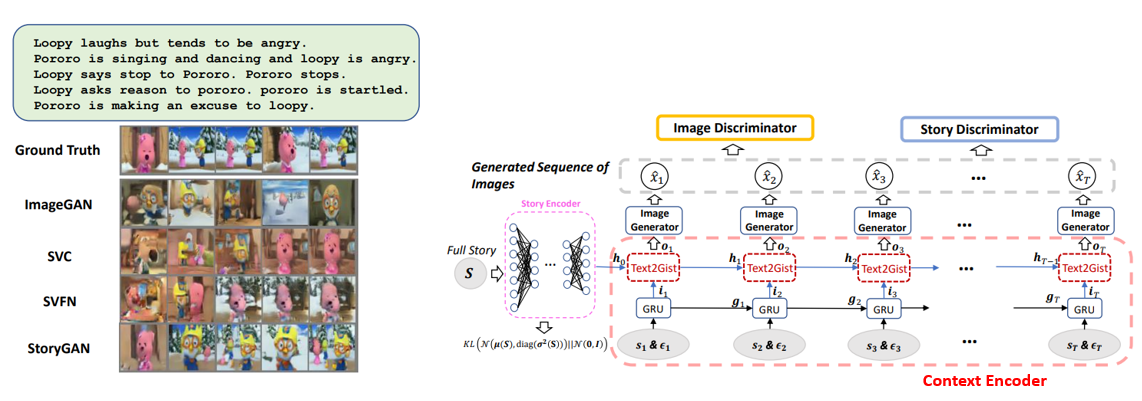
6. StoryGAN: A Sequential Conditional GAN for Story Visualization
- Story로부터 주요 문장들을 추출하여 각 문장에 해당하는 이미지를 생성하는 Story Visualization 이라는 새로운 task를 제안하였고, 이를 학습하기 위한 StoryGAN이라는 모델을 제안함.
- Story Encoder, Context Encoder, Image Discriminator, Story Discriminator 등 다양한 model들로 구성이 되어있으며 Sequential Conditional GAN을 기반으로 한 방법을 제안함.
7. Image Super-Resolution by Neural Texture Transfer
- Reference-based Super-Resolution 방법을 제안하였으며, 기존 CrossNet은 input image와 유사한 High Resolution image를 reference로 사용하면(아래 그림의 U) 성능이 잘 나오지만 그렇지 않은 이미지(아래 그림의 L)를 reference로 사용하면 artifact가 발생하는 문제가 있음.
- 이를 해결하기 위해 유사하지 않은 high-resolution reference image를 사용해도 adaptively texture를 transferring하는 방법 을 제안함.
- Demo Code

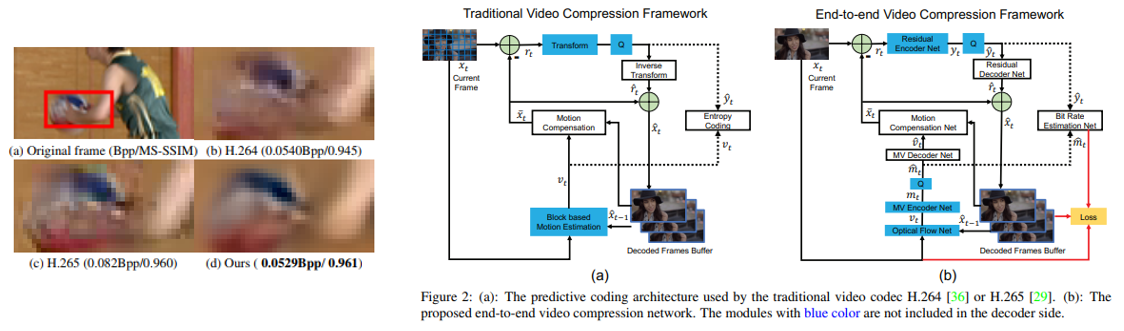
8. DVC: An End-to-end Deep Video Compression Framework (oral)
- 최초의 end-to-end video compression deep model 을 제안함.
- 전통적인 video compression에서 중요한 역할을 차지하는 motion information, residual information을 encoding하는 부분을 deep model을 적용하여 성능을 향상시킴.
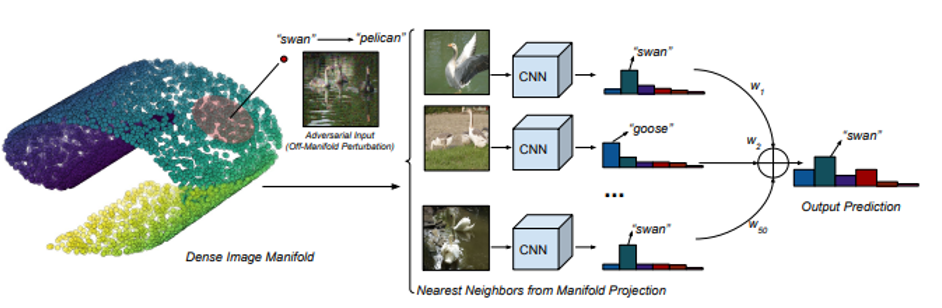
9. Defense Against Adversarial Images using Web-Scale Nearest-Neighbor Search (oral)
- 대용량의 데이터셋을 활용하여 image manifold를 구축하고, 이를 이용하여 adversarial attack을 방어하는 방법을 제안 함.
- 또한 이러한 nearest neighbor defenses를 방어하기 위한 2개의 attack method를 제안함.
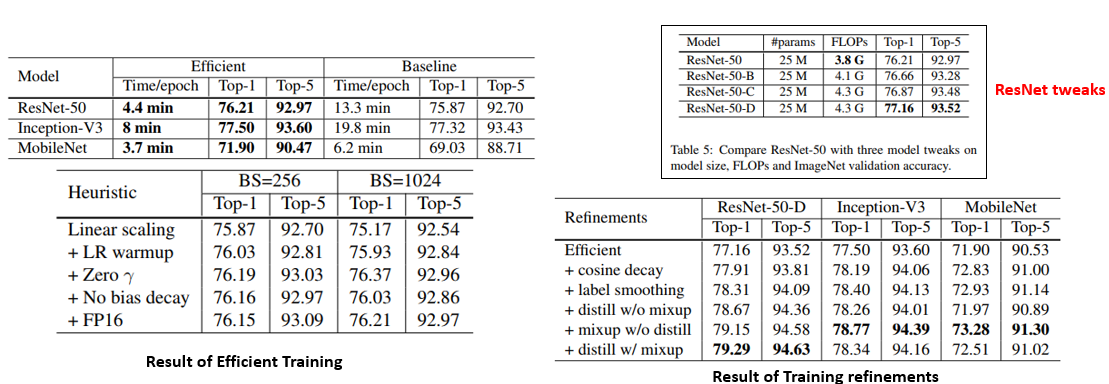
10. Bag of Tricks for Image Classification with Convolutional Neural Networks
- 잘 된다고 알려져 있는 여러 technique들을 ResNet-50에 적용 을 하여 성능을 75.3%에서 79.3%까지 개선시킴.
- 학습을 효율적으로 하기 위한 방법들과, 학습 과정에 관여하는 여러 요소들을 변화시키며 ablation study를 수행하였고 굉장히 실험적이지만 실용적인 논문임.
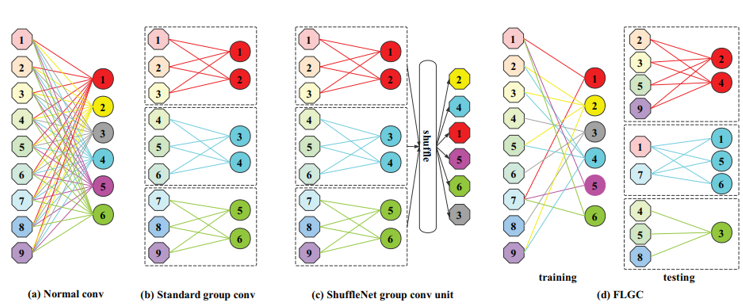
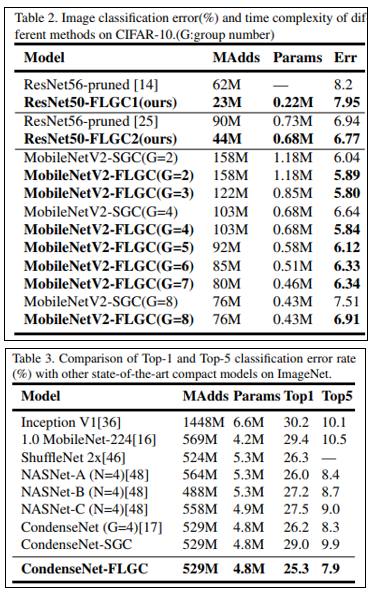
11. Fully Learnable Group Convolution for Acceleration of Deep Neural Networks
- 기존의 Group Convolution 과정은 유저가 관여하는 부분이 존재하는데, 이러한 부분을 학습을 통해 배울 수 있도록 하는 방법 을 제안함.
- Index re-ording을 위한 효과적인 학습 방법을 제안하였으며, 기존 Group Convolution 대비 높은 성능을 보임을 증명함.
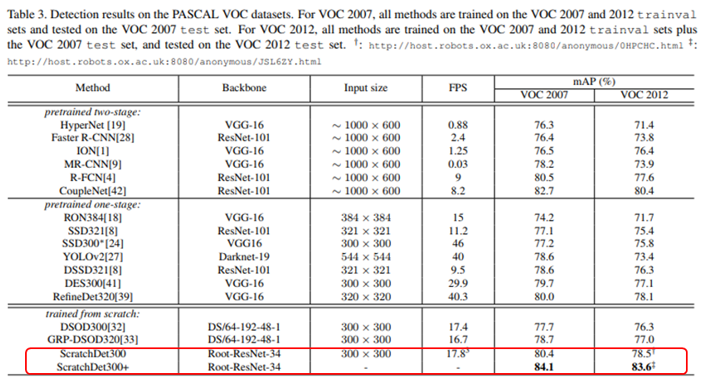
12. ScratchDet:Exploring to Train Single-Shot Object Detectors from Scratch (oral)
- 대부분의 Object Detection 모델들은 ImageNet과 같이 classification task에서 pretraining을 거친 CNN 구조를 사용하는 경우가 대부분이고, 이는 비효율적임.
- 이를 개선하기 위해 Batch Normalization에 초점을 두고 Scratch로부터 학습을 해도 그렇지 않았을 때와 비슷한 성능을 낼 수 있음 을 보임.
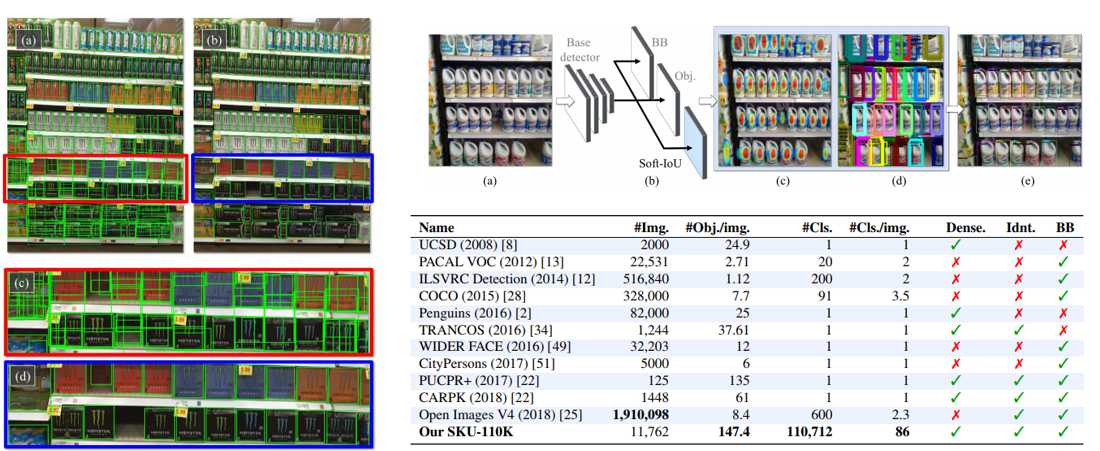
13. Precise Detection in Densely Packed Scenes
- 빽빽하게 밀집 되어있는 object 들은 기존의 detector들로는 검출하기 힘든 한계가 있음.
- 이를 개선하기 위해 public dataset(SKU-110K)을 공개하고, 좋은 성능을 내기 위한 방법론을 제안함.
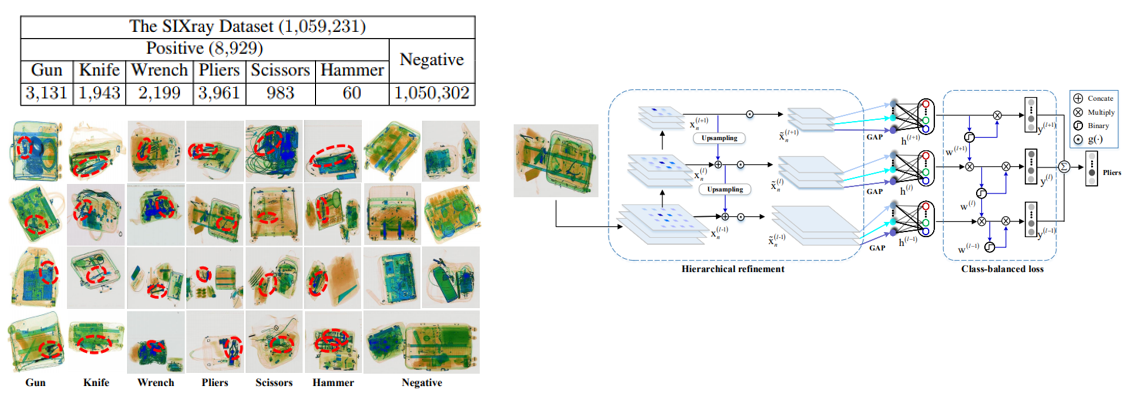
14. SIXray: A Large-scale Security Inspection X-ray Benchmark for Prohibited Item Discovery in Overlapping Images
- 6가지의 class와 8929개의 위험 물질이 포함 되어있는 총 1,059,231개의 이미지로 구성된 X-ray Dataset을 구축하여 공개함.
- 또한 class-balanced hierarchical refinement, class-balanced loss function을 이용하여 X-ray image에 대해 object localization을 하는 방법을 제안함.
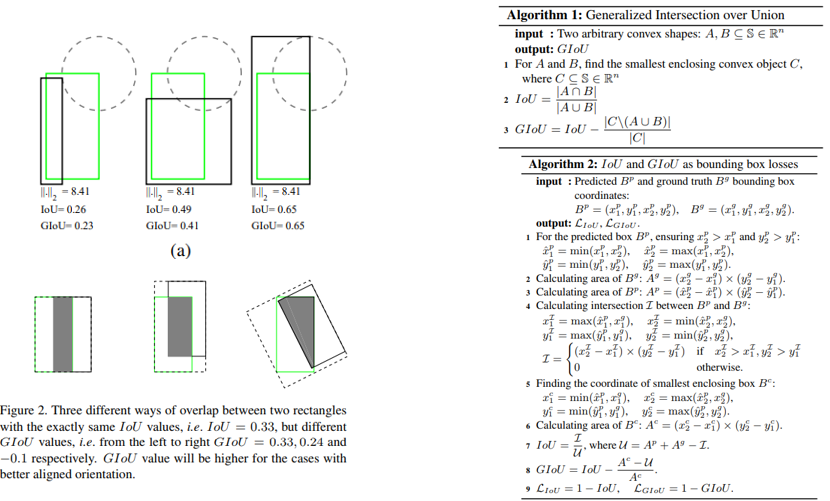
15. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
- 기존에 Object Detection의 metric으로 사용하는 IoU를 object detection의 bounding box loss에 반영하기 위한 방법 을 제안함.
- 또한 기존 IoU가 담지 못하는 정보들을 반영하기 위해 Generalized IoU라는 metric을 제안함.
16. Bounding Box Regression with Uncertainty for Accurate Object Detection
- 대부분 Object Detection 데이터셋에는 Bounding box coordinate의 애매성과 labeling noise가 존재함.
- 하지만 위에서 언급한 것처럼 object detection의 bounding box loss에는 이러한 것들이 반영이 되어있지 않아서, bounding box regression에 uncertainty를 도입함.
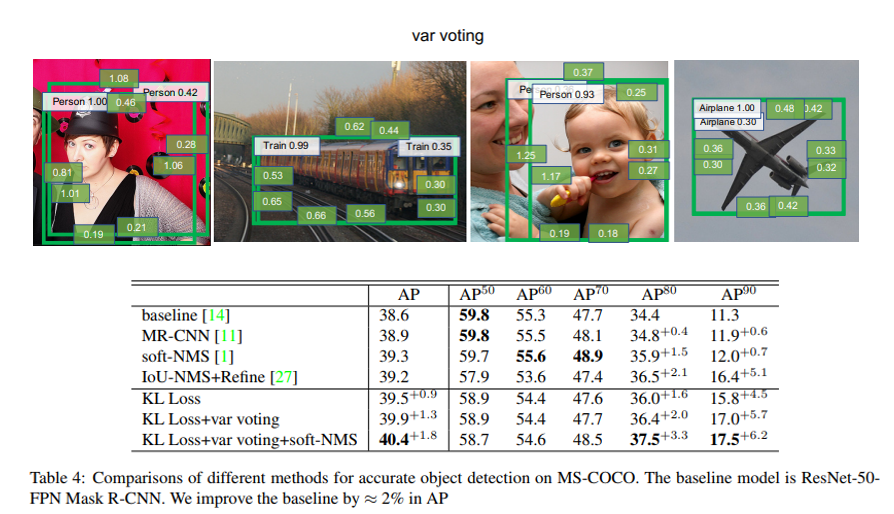
17. UPSNet: A Unified Panoptic Segmentation Network (oral)
- Semantic Segmentation과 Instance Segmentation을 합친 Panoptic Segmentation 문제를 위한 Network 구조 를 제안함.
- Semantic Head는 deformable convolution 기반, Instance Head는 Mask R-CNN 기반으로 구성이 되고 Parameter-free Panoptic Head까지 합쳐져서 end-to-end로 학습이 진행됨.
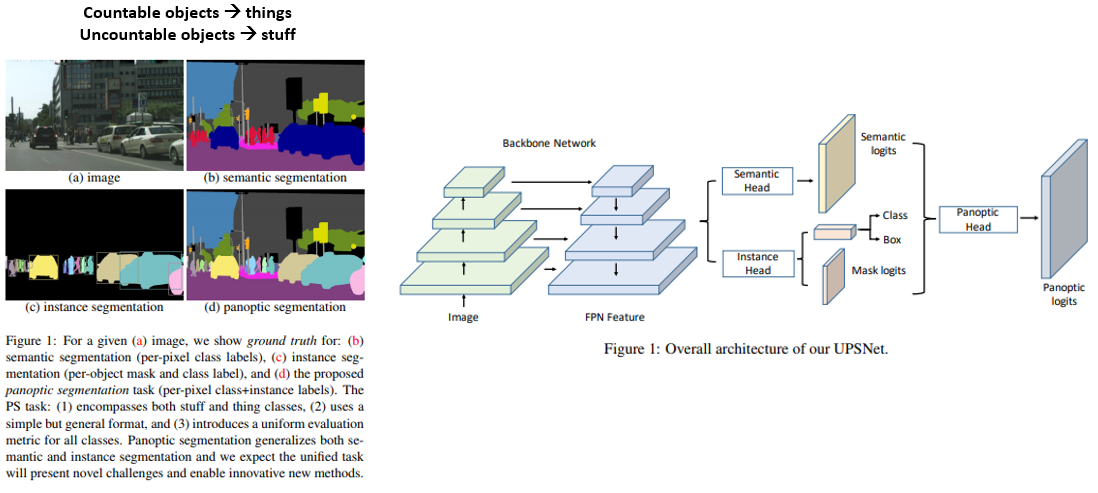
18. SFNet: Learning Object-aware Semantic Correspondence (Oral)
- Semantic correspondence 문제를 위한 SFNet 이라는 network 구조를 제안함.
- Training pair를 제작하는 것이 비용이 많이 소모되는데, 이를 해결하기 위해 single image에 binary foreground mask만 있으면, 여기에 synthetic geometric deformation을 적용하여 학습 데이터를 구성하는 방법을 제안하고 benchmark에 대해 state-of-the-art 성능을 달성함.
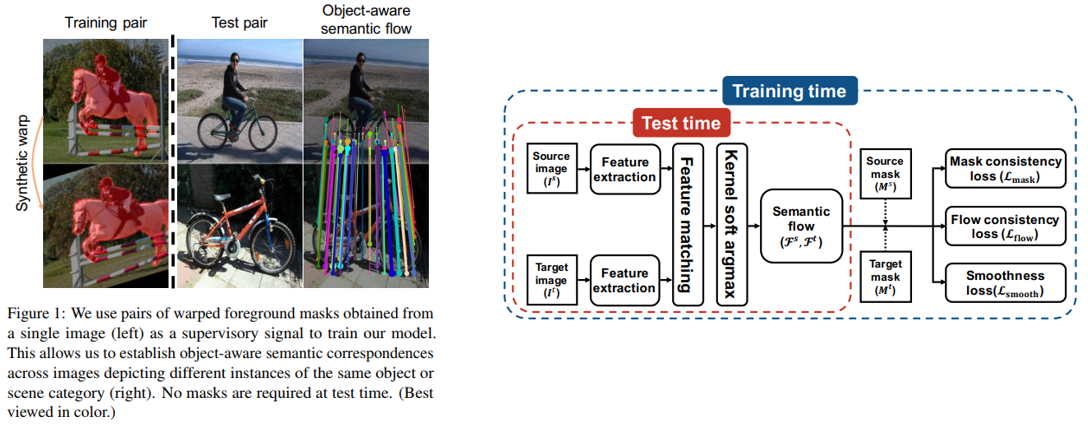
19. Fast Interactive Object Annotation with Curve-GCN
- Graph Convolutional Network 기반 빠르고 interactive한 object annotation tool 을 제안함.
- Human annotator가 잘못 예측된 지점을 수정할 수 있고, 이러한 수정이 근처의 point들에만 반영이 되므로 효율적임.
- Demo Code
20. FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference
- Image-level의 Weakly Supervised Semantic Segmentation(이하 WSSS) 문제에 stochastic inference 를 도입하는 방법론을 제안함.
- 하나의 network에서 여러 개의 Class Activation Map을 생성하고 이를 종합하여 WSSS 성능을 높이는 방법을 제안하였으며, 학습 과정에 큰 수정을 하지 않아도 적용이 가능하다는 장점이 있음.

결론
이번 포스팅에서는 CVPR 2019에 대한 분석 및 논문 리뷰를 글로 작성해보았습니다.
제가 정리한 논문 외에도 양질의 논문들이 많이 있으니 관심있으신 분들은 다른 논문들도 읽어 보시는 것을 권장 드리며 이상으로 글을 마치겠습니다. 감사합니다!