ICLR 2019 참석 후기 및 단순하고 효과적인 Network Pruning 방법론을 다룬 Best Paper 리뷰
안녕하세요, 이번 포스팅에서는 2019년 5월 6일 ~ 9일 미국 뉴올리언스에서 개최된 ICLR 2019 학회의 다녀온 뒤 느낀 점들과, 학회가 어떤 식으로 구성이 되고 진행이 되는지 간단하게 소개를 드리고자 합니다.
글 작성에 앞서 좋은 학회에 참석할 기회를 주신 수아랩에 감사의 말씀을 드립니다!
ICLR 2019 Simple Overview
우선 ICLR 2019에 대한 간단한 소개와 주요 논문 간단 리뷰는 지난번 제 개인 블로그에 작성하였던
“ICLR 2019 image recognition paper list guide”
글에서 확인하실 수 있습니다.
이 글에서 말씀드린 것처럼 매년 학회의 규모가 커지면서 2019년 올해에는 약 1600편 정도가 제출이 되었고, 그 중 500편이 accept이 되었습니다. 이 중 23편이 Oral Paper로 선정이 되었으며 이 중 2편의 논문이 Best Paper에 선정이 되었습니다.
[5/6(월) Workshop]
ICLR 학회는 4일간 진행이 되었고, 그 중 첫날 Workshop이 진행이 되었습니다. 총 9가지 주제로 개최가 되었고 각 주제마다 벽에 포스터가 붙어있고, 관련 연사들이 발표를 하는 방식으로 진행이 되었습니다. Workshop의 주제들은 다음과 같습니다.
- The 2nd Learning from Limited Labeled Data (LLD) Workshop: Representation Learning for Weak Supervision and Beyond
- Deep Reinforcement Learning Meets Structured Prediction
- Debugging Machine Learning Models
- Structure & Priors in Reinforcement Learning (SPiRL)
- AI for Social Good
- Safe Machine Learning: Specification, Robustness, and Assurance
- Representation Learning on Graphs and Manifolds
- Reproducibility in Machine Learning
- Task Agnostic Reinforcement Learning (TARL)
Workshop에는 아직 publish되지 않은 연구들을 소개하는 것이 주를 이뤘고, 실제로 학회장에서 발표를 들었던 연구들이 ICLR 이후에 개최되는 Major 학회인 ICML에 accept되는 경우도 여럿 보았습니다. 학회에 오면 아직 세상에 널리 공개가 되지 않은 최신 연구들의 진행 상황을 눈앞에서 보고 들을 수 있다는 것이 가장 큰 장점이라고 생각합니다. 또한 하루동안 Workshop이 진행되다 보니 같은 시간에 듣고 싶은 발표가 겹치는 경우가 발생할 수 있는데, 이를 위해 ICLR 측에서 모든 Workshop 발표들을 동영상으로 녹화하여 무료로 공개를 하였습니다. 하루동안 진행된 모든 발표 동영상은 해당 링크 에서 확인하실 수 있습니다.
[5/7(화) – Expo]
학회의 둘째 날에는 주요 기업에서 AI를 적용하고 있는 사례를 소개하는 Expo가 열렸습니다. 5개의 기업이 참여를 하였으며 각각 기업별 주제는 다음과 같습니다.
- AI Research using PyTorch: Bayesian Optimization, Billion Edge Graphs and Private Deep Learning (Facebook)
- Computational Problems in Travel Marketing (Expedia)
- Representation Learning to Rich AI Services in NAVER and LINE (NAVER and LINE)
- NLP Architect by Intel AI Lab (Intel AI)
- Machine Learning for Musical Creativity (Google AI)
각 발표의 자료는 공개가 되지 않았지만 세부 내용이 궁금하신 분들은 해당 링크 에서 확인하실 수 있습니다.
[5/7 – 9 (화-목) – Poster Session]
이번 ICLR에는 총 500편의 논문이 발표가 되었으며 모든 논문들은 화요일부터 목요일동안 포스터 발표를 진행하였습니다. 하루에 오전(11:00 ~ 13:00) 타임과 오후(16:30 ~ 18:30) 타임으로 나뉘어서 진행이 되었으며, 각 타임마다 약 80~90편 정도의 포스터가 발표되었습니다. 각 타임마다 주제가 나뉘어져 있진 않았지만 제가 개인적으로 돌아다니면서 분류를 해보았습니다.
- 화요일 오전: Computer Vision 전반
- 화요일 오후: Adversarial Learning, Neural Architecture Search, Algorithm Robustness
- 수요일 오전: Reinforcement Learning, Meta Learning
- 수요일 오후: Learning Theory, Gradient Descent Technique, Quantization
- 목요일 오전: Natural Language Processing
- 목요일 오후: Variational Auto-Encoder, Etc.
물론 제가 분류해 놓은 주제로만 포스터가 구성이 된 것은 아니지만, 대체로 그날의 트렌드 정도는 위와 같이 구분 지을 수 있었습니다. 각 요일마다 발표된 논문들은 해당 링크 에서 확인하실 수 있으며, 실제로도 비슷한 요일에 비슷한 주제들이 모여 있는 것을 확인하실 수 있습니다.
[5/6 – 9 (월-목) Oral Presentation]
마지막으로 소개드릴 Oral Presentation은 총 23편의 논문이 발표되었고, 각 발표는 15분으로 시간이 정해져 있었습니다. 15분이 길면 길수도 있지만 논문 한 편을 소개하기에는 굉장히 짧은 시간이라 다들 본인의 논문의 핵심만 설명하는 방식으로 발표를 진행하였습니다. 모든 구두 발표는 facebook ICLR 페이지를 통해서 실시간으로 생중계가 되었으며, 비디오로 남아있어서 발표 영상이 궁금하신 분들은 해당 링크 를 통해 확인하실 수 있습니다. 이제 구두 발표 중에 인상깊게 들었고, 이번 ICLR Best Paper에도 선정이 된 “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural” 라는 논문을 소개 드리도록 하겠습니다.
“The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks” Review
1. Introduction
오늘 리뷰할 논문은 Network Pruning에 관련된 논문입니다. Network Pruning은 2015년 NIPS에 발표된 Learning both Weights and Connections for Efficient Neural Networks 논문이 가장 잘 알려져 있습니다.
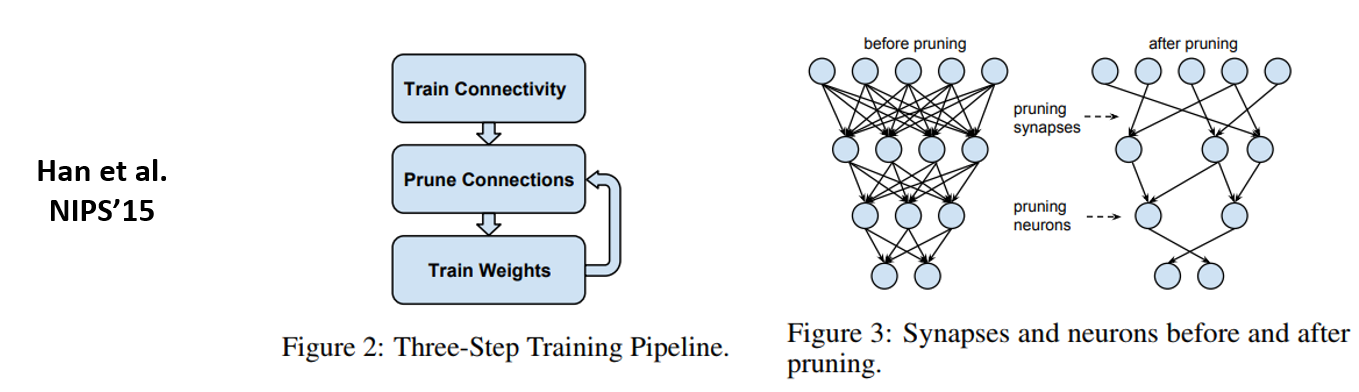
위의 그림은 Network Pruning하면 가장 많이 인용되는 그림이며, 그림에 나와있는 것처럼 Neural Network를 학습시킨 뒤 불필요한 connection들을 제거를 합니다. 이렇게 가지치기를 해준 뒤에는 남아있는 Network를 재 학습시키며 성능을 Pruning하기 전과 비슷하게 유지하는 것을 목표로 하게 됩니다.
다만 Pruning을 통해 찾은 network를 random weight로 initialization시키는 방식(from scratch)을 이용하여 학습을 시키면 pruning해서 얻은 accuracy에 크게 못 미치는 정확도를 보이는 것이 고질적인 문제였습니다. 이에 대한 여러 추측이 있었는데 그 중 가장 그럴싸한 주장은 pruning을 통해 찾은 network는 parameter 수가 작아져서 small capacity를 가지고 있기 때문에 parameter 수가 많은 기존 network 보다 학습시키기 어렵다는 주장이며, 최근 나온 network pruning 관련 논문들도 이 문제를 해결하는데 초점을 두고 있습니다.
이 논문 저자는 pruning된 network를 잘 학습시키기 위한 방법을 제안하였으며, 이를 복권에 당첨된다고 표현을 하였습니다. 본 논문에서는 lottery ticket 혹은 winning ticket이라는 용어를 많이 사용하며, 본 논문에 제목에 나와있는 lottery ticket hypothesis에 대해 설명을 드리도록 하겠습니다.
2. Main Idea & Method
본 논문에서는 dense 한 neural network와 이 network를 pruning하여 얻은 subnetwork가 있을 때, 아래 그림의 조건을 만족시키는 subnetwork가 존재한다는 가설을 세우고 연구를 시작하였습니다.

위의 그림에서 첫번째 줄의 f(x; W) 는 기존의 neural network를 의미하고, 기존 neural network를 t iteration 만큼 학습을 시켜서 test accuracy a 를 얻음을 의미합니다. 두번째 줄도 비슷한 의미를 가집니다. f(x; m*W) 는 기존 neural network f를 pruning하여 얻은 subnetwork를 의미하고, 마찬가지로 t’ iteration 만큼 학습을 시켜서 test accuracy a’ 를 얻는 다는 상황을 의미합니다. 이 때 이 논문에서 말하는 lottery ticket은 3번째 줄의 조건(모델의 parameter 수도 적으면서 test accuracy도 높고, 학습에 필요한 iteration 수까지 적은 )을 만족하는 subnetwork를 의미합니다.
저희가 자주 사용하는 deep neural network는 본인보다 성능이 좋으면서, 학습도 잘 되는 subnetwork(lottery ticket)을 가지고 있다는 가설을 세우고 연구를 수행하고 있습니다. 이 논문에서는 기존 neural network보다 성능이 좋은 lottery ticket을 어떻게 찾을 수 있는지 실험을 통해 발견을 하였고, 이에 대한 방법론과 실험 결과를 나열하는 방식으로 논문을 구성하고 있습니다.
서론의 이야기만 들으면, 굉장히 어려운 방법을 통해 lottery ticket을 찾을 것 같은데, 방법론은 실제로 매우 간단합니다.

본 논문에서 발견한 winning ticket을 찾는 방법은 다음과 같습니다. 우선 여기 나와있는 1~4번의 방법 중 3번까지는 기존에 진행하는 network pruning과 동일하며 4번의 방법만 추가된 것입니다. 여기서 주목할 것은 1번 방법에 빨간 네모로 강조해둔 weight initialization 입니다. 처음 neural network를 initialization 하였을 때의 그 초기 weight들을 저장하고 있다가, 학습시키고 pruning을 한 뒤에 subnetwork의 weight에 다시 넣어주는 굉장히 간단한 방식을 제안하고 있습니다. 이 과정을 그림으로 나타내면 다음과 같습니다.
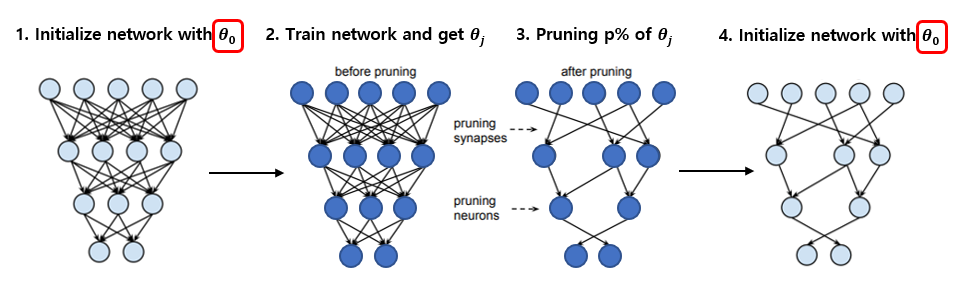
구분이 쉽게 그림에서 weight 값을 neuron의 색을 바꿔서 표현하였으며, 그림의 1번에서 초기화한 weight 값을 그대로 4번 그림에서 사용한다고 이해하시면 됩니다. 정말 간단한 방식인데 좋은 성능을 보일 수 있다는 것이 신기하면서도 대단한 발견이라고 생각이 됩니다.
3. Experiment & Result
본 논문에서는 총 3가지의 실험 셋팅에 대해 실험을 진행하여 알고리즘의 성능을 검증하였습니다.
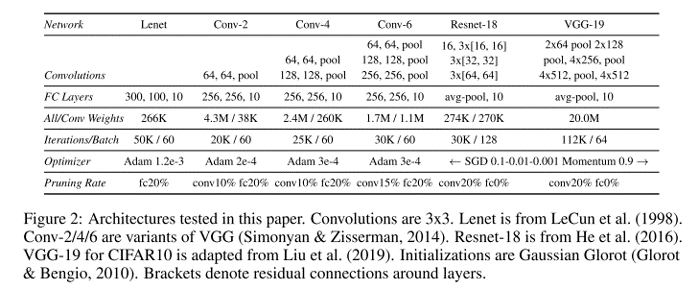
첫번째 실험은 MNIST 데이터셋에 대해 Convolution 연산 없이 Fully-connected layer로만 구성이 되어있는 LeNet 구조 로 실험을 하였고, 두번째 실험은 CIFAR10 데이터셋에 대해서는 간단한 Conv, Pooling layer로 만든 ConvNet 구조 에 대해 실험을 하였습니다. 마지막으로 CIFAR10 데이터셋에 대해 비교적 큰 모델인 VGG-19, ResNet-18 을 이용하여 실험을 진행하였습니다.
각 실험에서 사용한 network와 hyper-parameter 셋팅은 다음 표에서 확인하실 수 있습니다.
3-1. Result - Fully-connected architecture(LeNet) for MNIST
우선 LeNet에 대한 실험은 layer-wise pruning을 적용하였으며 단순하게 각 layer마다 weight의 magnitude가 작은 순서대로 pruning을 하는 방식을 사용했습니다. 또한 모든 weight를 한번에 pruning 하는 one-shot pruning 대신 여러번에 걸쳐서 pruning하는 iterative pruning 방식을 사용하였습니다.
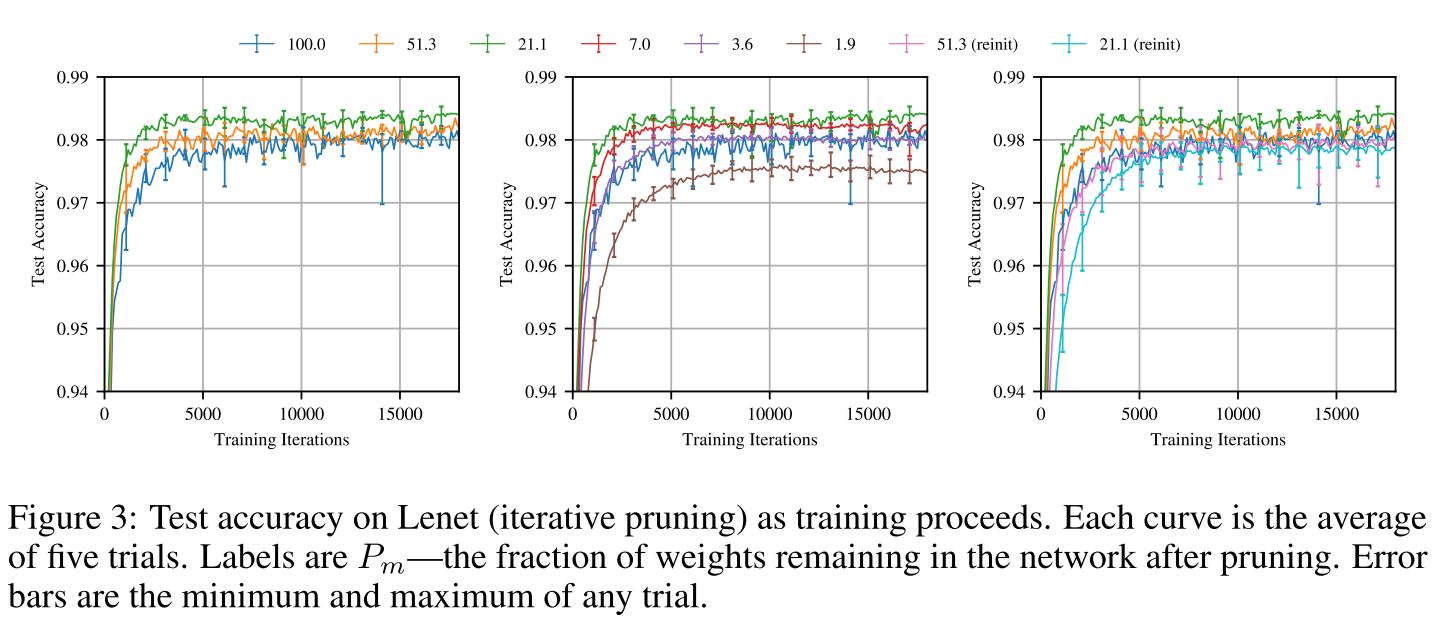
실험 결과는 위의 그림과 같으며 winning ticket 방식을 적용하면, 적용하지 않았을 때(reinit)에 비해 월등한 성능을 보이는 것을 확인할 수 있습니다. 또한 pruning을 하기 전(100.0)에 비해 test accuracy도 조금씩 증가하는 양상을 보이고 있습니다.
3-2. Result - Simple ConvNet for CIFAR10
Simple ConvNet의 실험 결과도 앞서 설명한 LeNet의 실험 결과와 거의 유사한 양상을 보입니다. 마찬가지로 reinit을 하였을 때 보다 winning ticket 방식을 적용하였을 때 더 좋은 성능을 보였으며, 이번에는 heuristic으로 dropout 을 같이 사용하였더니 더 성능이 좋아졌다는 결과를 제시하고 있습니다.
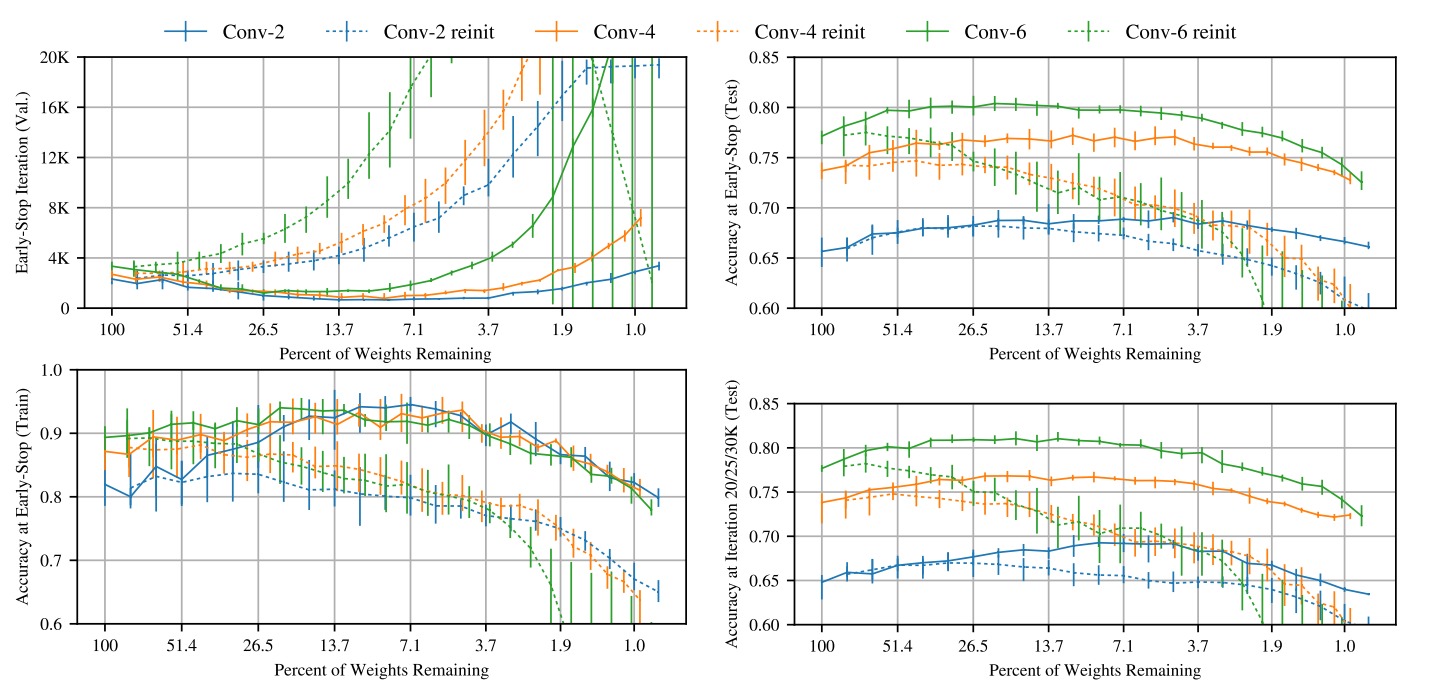
결과 그래프를 보시면 대부분 reinit을 사용하였을 때 보다 winning ticket을 사용하였을 때 early stop iteration가 작은 것을 확인하실 수 있습니다. 이는 network의 수렴이 빨리 된다는 것을 의미하며, test accuracy 도 높은 것을 확인할 수 있습니다. 또한 90% 이상 pruning을 하였을 때에도 pruning을 하기 전과 비슷한 정확도가 유지가 되는 것을 확인할 수 있으며, dropout까지 섞어 쓰면 수렴은 다소 늦게 하지만 더 높은 test accuracy를 얻을 수 있음을 보여주고 있습니다.
3-3. Result - Deep ConvNet(VGG-19, ResNet-18) for CIFAR10
마지막으로 소개드릴 실험 결과에서는 앞선 실험과 동일하게 iterative pruning 을 사용하였지만 앞선 두개의 실험과는 다르게 layer-wise pruning 대신 global pruning 을 사용하였습니다. 즉, 각 layer 마다 pruning을 하는 대신 모든 layer의 weight에 대해 한번에 pruning을 하는 방식을 사용하였습니다. 이렇게 한 이유는 VGG-19의 경우 첫 번째 layer와 두 번째 layer, 마지막 layer의 parameter수를 비교하면 각각 1.7K개, 37K개, 2.4M개로 굉장히 많이 차이가 나는데, 만약 각 layer마다 pruning을 적용한다면 parameter 수가 적은 layer가 bottleneck이 될 수 있습니다. 90% pruning을 예로 들면 마지막 layer는 240만개에서 24만개로 parameter 수가 줄어들어도 24만개면 충분하다고 생각할 수 있는데, 첫번째 layer의 경우 1700개에서 170개로 줄어들게 되고, 170개는 굉장히 적은 숫자의 parameter이기 때문에 제대로 학습이 되기 어렵게 됩니다. 이러한 이유로 global pruning 을 사용하였고, 실제로도 global pruning을 사용할 때가 성능이 더 좋은 것을 확인할 수 있습니다.
또한 이 실험에서도 heuristic이 들어가는데 이번에는 learning rate warmup 을 사용하였습니다. Learning rate warmup 이란 초기의 learning rate를 초반 iteration 동안 linear하게 증가시키는 방법을 의미합니다. 우선 0.1의 initial learning rate를 사용하면 network가 학습이 잘 되지만 pruning을 할 시 winning ticket을 찾지 못하고, 0.01의 learning rate를 사용하면 winning ticket은 찾지만 높은 정확도를 얻을 수 없는 문제가 발생합니다. 이를 해결하기 위해 learning rate warmup을 사용하였으며 그 결과 winning ticket도 찾고, 높은 정확도도 얻을 수 있었다고 합니다.
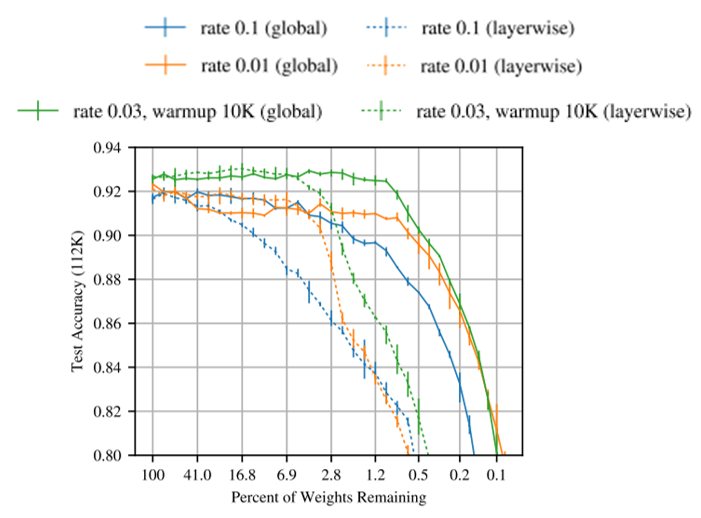
위의 그림은 앞서 소개드린 2가지 기법인 global pruning 과 learning rate warmup 의 효용을 보여주고 있습니다. 위의 그림에서 실선은 global pruning 방식을, 점선은 layer-wise pruning 방식을 의미하며 대부분의 경우에서 점선보다 실선이 test accuracy가 높은 것을 확인하실 수 있습니다. 또한 주황색 선은 learning rate warmup 을 사용하기 전의 결과를, 초록색 선은 learning rate warmup 을 사용한 후의 결과를 보여주고 있으며 초록 선이 대부분 주황색 선보다 test accuracy가 높은 것을 확인하실 수 있습니다. 즉 논문에서 사용한 2가지 기법이 모두 좋은 성능을 보임을 확인하실 수 있습니다.
4. Discussion & Future Work
4-1. Discussion
위의 실험 결과를 보시면 아시겠지만 굉장히 heuristic이 많이 개입되어있지만, 실험 결과가 좋은 것을 느끼실 수 있을 것입니다. 실제로 이 논문의 리뷰어들도 이러한 점을 지적하였고, 논문 저자들도 이를 인정하고 있습니다. 논문에서 언급하고 있는 이 논문의 한계점과 future work들은 다음과 같습니다.
우선은 MNIST, CIFAR10 과 같은 작은 데이터셋에 대해서만 검증을 한 점을 한계로 말하고 있습니다. 추후 더 큰 데이터셋(ex, ImageNet) 등에 대해 검증을 할 예정이라 언급하고 있습니다.
또한 본 논문에서 사용한 pruning 방식은 단순히 magnitude에 따라 pruning을 하는 방식인데 이러한 방식은 저희가 주로 사용하는 library나 hardware 단계에서 속도 적인 이점을 얻을 수 없다는 한계를 가지고 있습니다. 이를 개선하기 위해 structured pruning과 같은 다른 pruning technique에도 winning ticket 방식을 적용해볼 것이라고 언급을 하고 있습니다.
마지막으로는 각 실험마다 굉장히 다양한 heuristic이 적용이 되었는데, 이에 대한 명확한 reasoning이 부족한 것을 한계로 삼고 있습니다.
4-2. Future Work
이 논문이 제출되었을 때, 리뷰어 들로부터 어떠한 리뷰를 받았는지 확인해보기 위해 ICLR Open Review 에서 진행된 리뷰 내용들을 읽고 요약을 해보았습니다.
우선 ICLR 2019에 제출된 다른 pruning 논문 2편 ( “SNIP: Single-shot Network Pruning based on Connection Sensitivity” , “Rethinking the Value of Network Pruning” ) 과 비교를 해봤으면 좋겠다는 리뷰가 있었고, 위에 한계로 언급하였던 내용인 더 큰 데이터셋에 대한 검증 여부도 리뷰에 포함이 되어있습니다. 또한 실험에 ConvNet 구조에 사용한 Batch Normalization으로 인해 winning ticket을 heuristic 없이 찾기 힘든 것이 아니냐는 질문도 있었습니다.
이러한 리뷰를 바탕으로 지금의 논문이 완성이 되었고, 단순한 방식이고 다소 heuristic이 많이 개입이 되었지만 굉장히 직관적이고 좋은 성능을 보이고 있어서 ICLR 2019의 best paper로 선정이 된 것이 아닌가 개인적으로 생각해봅니다.
5. Next Paper “The Lottery Ticket Hypothesis at Scale, 2019 arXiv”
앞서 설명드린 리뷰어들의 리뷰를 바탕으로 어떠한 후속 연구가 진행되고 있는지 찾아보던 중에 위의 제목을 가진 논문을 찾아서 간단히 읽고 정리를 하였습니다.
우선 제목에서 알 수 있듯이 MNIST, CIFAR10 보다 큰 데이터셋인 ImageNet에 대해 lottery ticket hypothesis를 검증하였으며, SNIP, “Rethinking the Value of Network Pruning” 논문과도 성능을 비교하는 내용을 논문에서 확인할 수 있습니다.
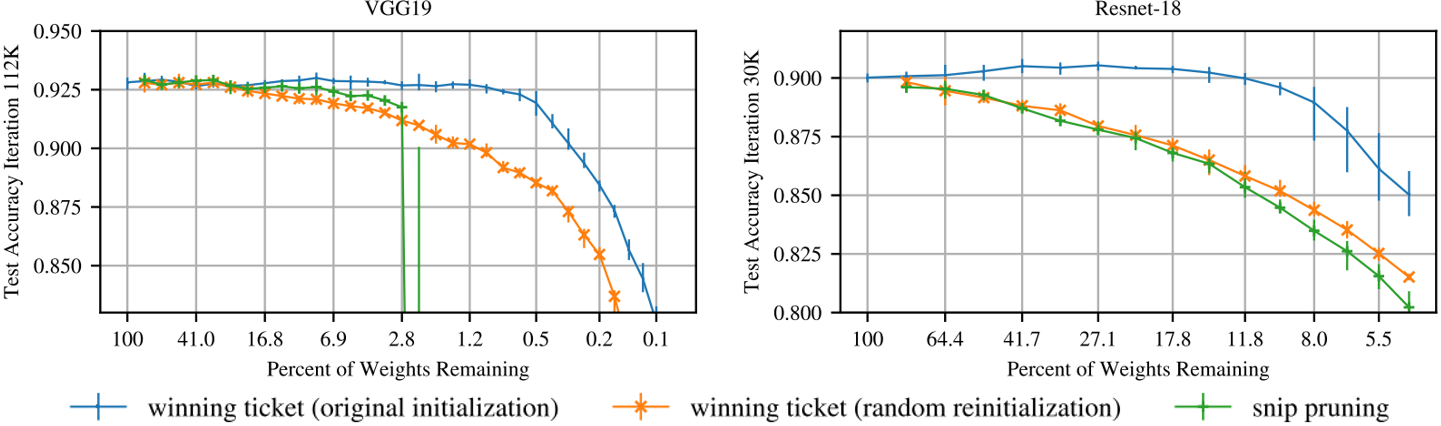
실험 결과 본인들의 방법이 두 논문의 방법보다 성능이 좋은 것을 실험적으로 보이고 있습니다. 다만 ImageNet에 대해서는 위에서 설명 드린 weight initialization 방식을 사용하면 성능이 잘 나오지 않아서 초기의 initialization weight 대신 약간의 학습이 진행된 뒤의 weight를 가져오는 late resetting 방식을 제안합니다. 이번에도 heuristic이 굉장히 많이 적용되었지만 마찬가지로 실험 결과가 좋아서 흥미로운 논문인 것 같습니다. 관심 있으신 분들은 이 논문도 읽어 보시는 것을 권장 드립니다.
결론
이번에는 ICLR 2019에 직접 다녀온 뒤 블로그 글을 작성을 하였습니다. ICLR 학회의 각 요일마다 어떠한 프로그램들이 진행되는지 소개 드렸고, 각 프로그램마다 참고할 수 있는 자료를 같이 소개 드렸습니다. 또한 각 프로그램마다 느낀 점들을 간략하게 소개 드렸고, 2편의 Best Paper 중 Network Pruning과 관련 있는 “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks”에 대해 리뷰를 해보았습니다. 최근 학계에서 굉장히 핫한 학회에 참석하다 보니 자극도 많이 받을 수 있었고, 최신 연구들의 흐름도 느낄 수 있어서 보람이 있었습니다.

마지막으로 ICLR 2019가 열렸던 도시 뉴올리언스의 Ernest N. Morial Convention Center 앞에서 찍은 사진을 보여드리면서 글을 마치도록 하겠습니다! 읽어주셔서 감사합니다!
comments powered by Disqus