EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 리뷰
안녕하세요, 이번 포스팅에서는 이틀 전 공개된 논문인 “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks” 논문에 대한 리뷰를 수행하려 합니다. 이 논문은 2019 CVPR에 발표된 “MnasNet: Platform-Aware Neural Architecture Search for Mobile” 의 저자인 Mingxing Tan과 Quoc V. Le 가 쓴 논문이며 Image Classification 타겟의 굉장히 성능이 좋은 Model인 EfficientNet을 제안하였습니다. 논문을 소개 드리기 앞서 이 논문의 결과를 먼저 보여드리고 시작을 하도록 하겠습니다.
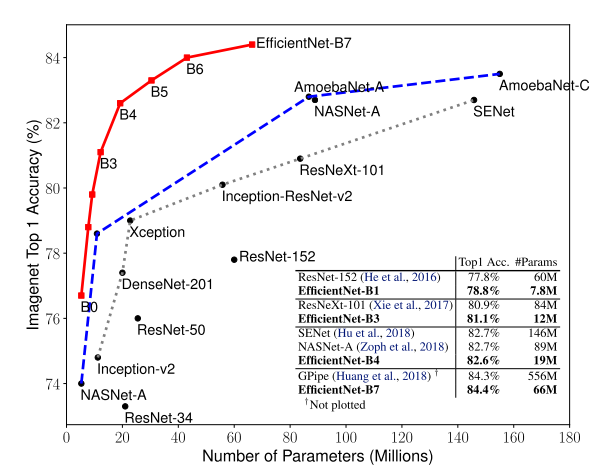
ImageNet 데이터셋에 대해 정확도를 초점으로 한 모델과 Efficient를 초점으로 한 모델들이 굉장히 많이 제안이 되었는데 이러한 모든 모델들의 성능을 크게 상회하는 모델을 제안을 하였다는 점이 저에겐 굉장히 충격이었습니다. 이제 어떻게 이러한 좋은 성능을 달성할 수 있었는지 설명드리도록 하겠습니다.
Model Scaling
일반적으로 ConvNet의 정확도를 높일 때 잘 짜여진 모델 자체를 찾는 방법도 있지만, 기존 모델을 바탕으로 Complexity를 높이는 방법도 많이 사용합니다.
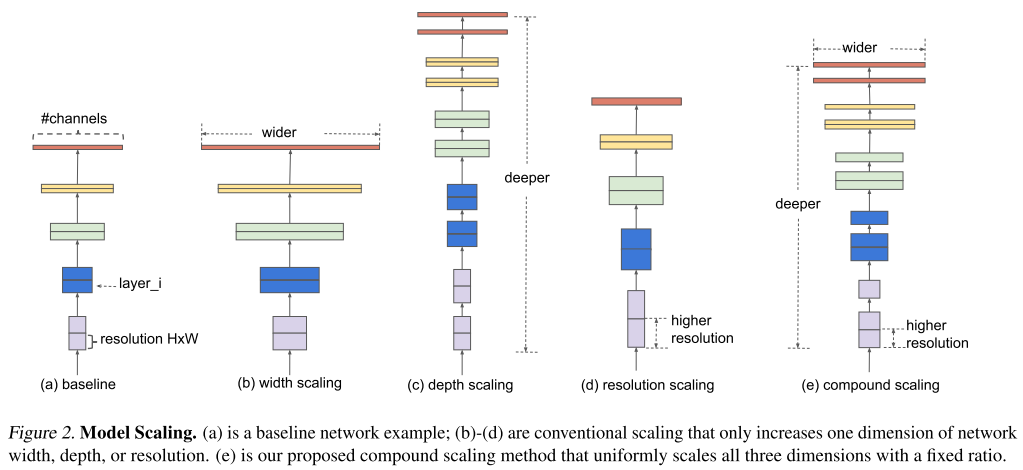
위의 그림은 이미 존재하는 모델의 size를 키워주는 여러 방법들을 보여주고 있습니다. 대표적으로 filter의 개수를(channel의 개수를) 늘리는 width scaling 와 layer의 개수를 늘리는 depth scaling과 input image의 해상도를 높이는 resolution scaling 이 자주 사용됩니다. ResNet이 depth scaling을 통해 모델의 크기를 조절하는 대표적인 모델이며(ex, ResNet-50, ResNet-101) MobileNet, ShuffleNet 등이 width scaling을 통해 모델의 크기를 조절하는 대표적인 모델입니다. (ex, MobileNet-224 1.0, MobileNet-224 0.5) 하지만 기존 방식들에서는 위의 3가지 scaling을 동시에 고려하는 경우가 거의 없었습니다.
또한 3가지 scaling 기법 중에 어떤 기법을 사용할지에 대해서도 마땅한 가이드라인이 존재하지 않고, 실제로 무작정 키운다고 정확도가 계속 오르는 것도 아니라 일일이 실험을 해봐야하는 어려움도 존재하였습니다. 본 논문에서는 실제로 3가지 scaling 기법에 대해 각 scaling 기법마다 나머지는 고정해두고 1개의 scaling factor만 키워가며 정확도의 변화를 측정하였습니다.
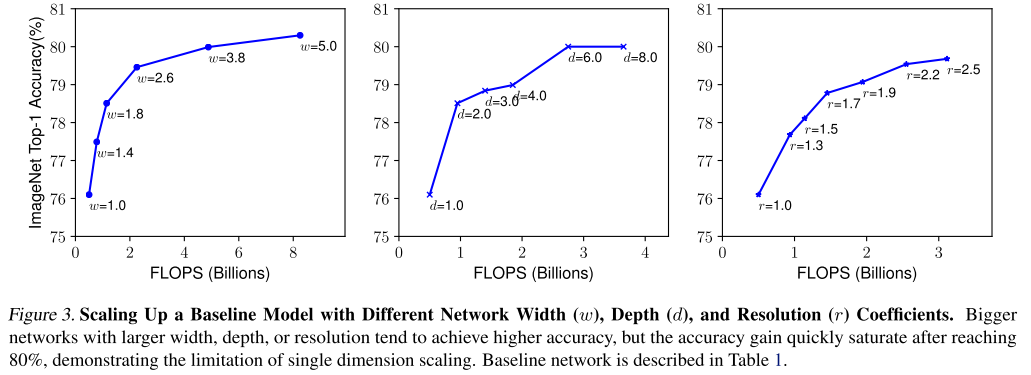
위의 그림을 보시면 width scaling, depth scaling 은 비교적 이른 시점에 정확도가 saturation 되며 그나마 resolution scaling이 키우면 키울수록 정확도가 잘 오르는 것을 확인할 수 있습니다.
비슷한 방식으로 이번엔 depth(d)와 resolution(r)을 고정해두고 width만 조절하며 정확도의 변화를 측정하는 실험을 수행하였습니다.
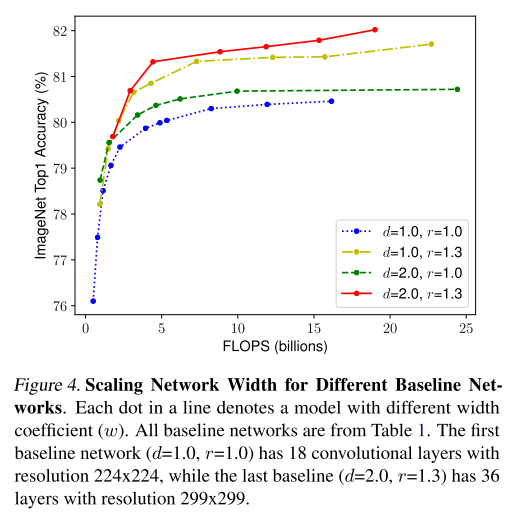
같은 FLOPS 임에도 불구하고 크게는 1.5% 까지 정확도가 차이가 날 수 있음을 시사하고 있습니다. 초록색 선과 노란색 선을 비교하면 depth를 키우는 것 보다는 resolution을 키우는 것이 정확도가 좋음을 알 수 있고, 빨간색 선을 보면 1가지, 혹은 2가지 scaling factor만 키워주는 것 보다 3가지 scaling factor를 동시에 키워주는 것이 가장 성능이 좋음을 실험적으로 보여주고 있습니다.
직관적으로 생각해보면 Input image가 커지면 그에 따라서 receptive field도 늘려줘야 하고, 더 커진 fine-grained pattern들을 학습하기 위해 더 많은 channel이 필요한 건 reasonable한 주장입니다. 즉 모델의 크기를 키워줄 때 위의 3가지 요소들을 동시에 고려하는 것이 좋다는 건 크게 틀린 주장은 아니라고 생각됩니다. 이제 어떻게 이 3가지 요소들을 고려할 것인지에 대해 설명을 드리도록 하겠습니다.
Compound Scaling
위의 실험들을 통해 3가지 scaling factor를 동시에 고려하는 것이 좋다는 것을 간단하게 입증을 하였고, 이번에는 최적의 비율을 찾아서 실제 모델에 적용을 해서 다른 모델들과 성능을 비교하는 과정을 설명 드리겠습니다. 우선 이 논문에서는 모델(F)를 고정하고 depth(d), width(w), resolution(r) 3가지를 조절하는 방법을 제안하고 있는데, 이때 고정하는 모델(F)를 좋은 모델로 선정하는 것이 굉장히 중요합니다. 아무리 scaling factor를 조절해도, 초기 모델 자체의 성능이 낮다면 임계 성능도 낮기 때문입니다. 이 논문에서는 MnasNet과 거의 동일한 search space 하에서 AutoML을 통해 모델을 탐색하였고, 이 과정을 통해 찾은 작은 모델을 EfficientNet-B0 이라 부르고 있습니다.
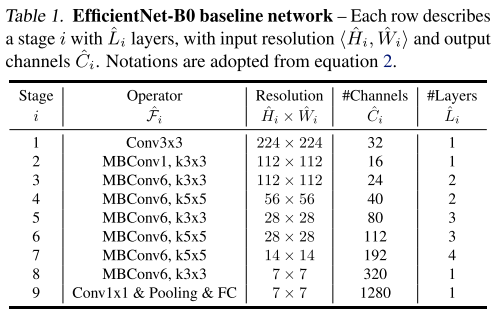
모델 구조는 MnasNet과 거의 유사하며 위의 표와 같은 구조로 구성이 되어있습니다. 이제 이 모델을 기점으로 3가지 scaling factor를 동시에 고려하는 Compund Scaling 을 적용하여 실험을 수행합니다.
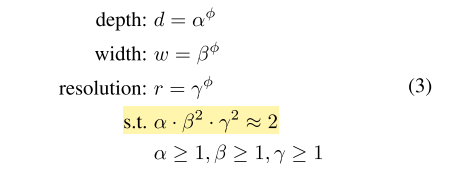
우선 depth, width, resolution 은 각각 알파, 베타, 감마로 나타내며 각각의 비율은 노란색으로 강조한 조건을 만족시켜야 합니다. 이 때 width와 resolution에 제곱이 들어간 이유는 depth는 2배 키워주면 FLOPS도 비례해서 2배 증가하지만, width와 resolution은 가로와 세로가 각각 곱해지기 때문에 제곱 배 증가합니다. 그래서 제곱을 곱해서 계산을 하고 있습니다. 그 뒤 전체 모델의 사이즈는 알파, 베타, 감마에 똑같은 파이만큼 제곱하여 조절을 하게 됩니다. EfficientNet의 알파, 베타, 감마 값은 간단한 grid search를 통해 구하는 방식을 제안하고 있으며, 처음 단계에서는 파이를 1로 고정한 뒤, 타겟 데이터셋에서 좋은 성능을 보이는 알파, 베타, 감마 값을 찾아냅니다. 본 논문에서는 알파 값은 1.2, 베타 값은 1.1, 감마 값은 1.15를 사용하였으며, 방금 구한 3개의 scaling factor는 고정한 뒤 파이를 키워주며 모델의 사이즈를 키워주고 있습니다.
기존 사람이 디자인한 ConvNet, AutoML을 통해 찾은 ConvNet 들과 비교를 한 결과는 다음 표에 나와있습니다.
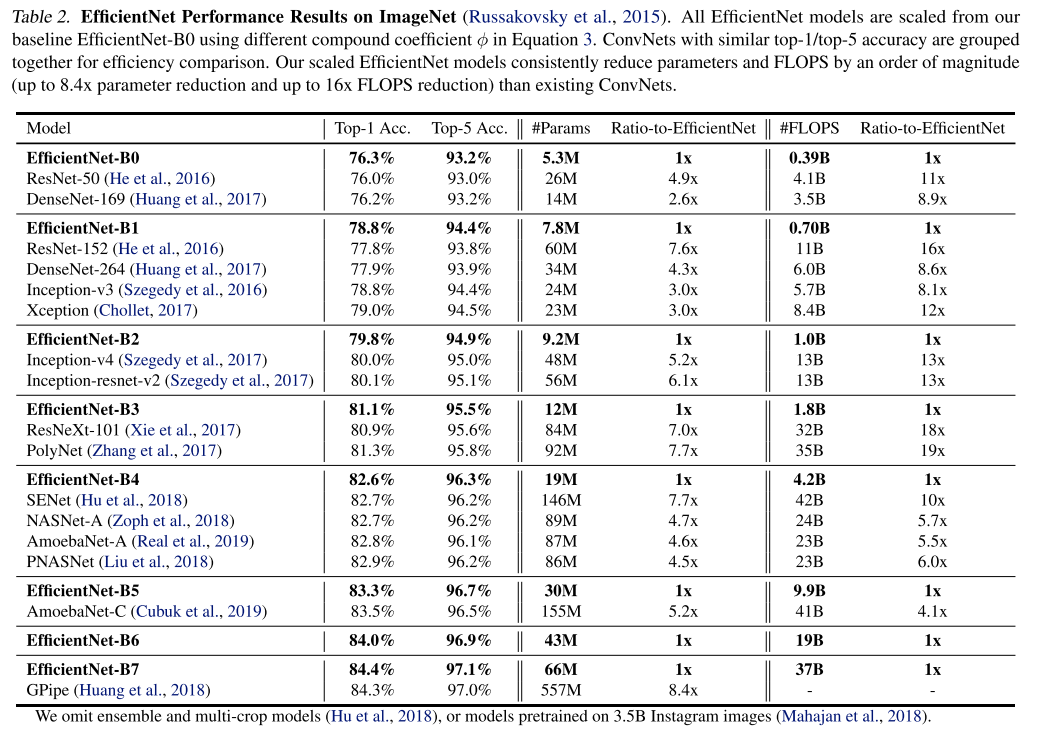
결과를 보시면 아시겠지만 기존 ConvNet들에 비해 비슷한 정확도를 보이면서 parameter수와 FLOPS 수를 굉장히 많이 절약할 수 있는 것을 알 수 있고, 또한 기존에 ImageNet 데이터셋에서 가장 높은 정확도를 달성했던 GPipe 보다 더 높은 정확도를 달성하는 것을 확인할 수 있습니다. 동시에 parameter 수와 FLOPS수도 굉장히 많이 절약할 수 있습니다. 실험결과가 굉장히 좋은 것을 바로 알 수 있습니다. 이 외에도 다양한 실험 결과들은 논문에서 추가로 확인하실 수 있습니다.
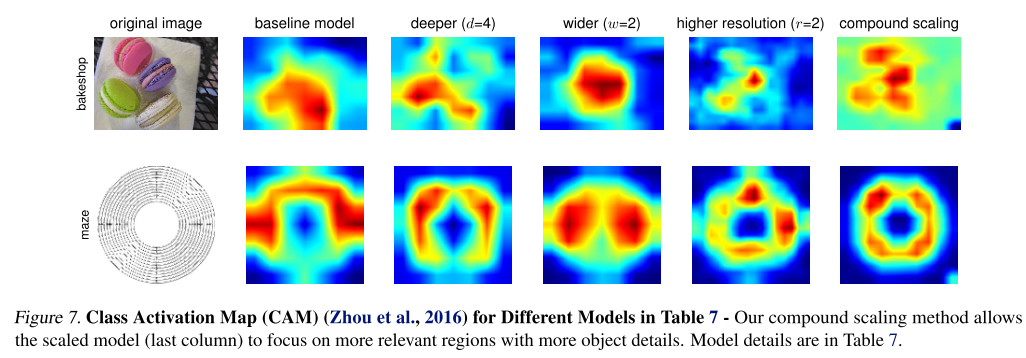
마지막으로 모델이 이미지를 분류할 때 이미지의 어느 영역에 집중했는지 확인할 수 있는 Class Activation Map(CAM)을 뽑아보았는데, 3개의 scaling factor를 각각 고려할 때 보다 동시에 고려하였을 때 더 정교한 CAM을 얻을 수 있다는 점도 인상깊은 결과입니다.
결론
이번 포스팅에서는 최근 나온 EfficientNet에 대한 논문 리뷰를 수행하였습니다. 그동안 Image Classification 분야에서 굉장히 다양한 논문들이 나왔었는데 단순하면서도 직관적인 방법을 통해 월등한 성능을 내는 점이 대단히 인상깊었습니다. 지난번 리뷰한 “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks” 논문처럼 직관적이면서 간단한 방식을 적용하여 우수한 성능을 내는 논문들이 등장하는 점이 인상깊은 것 같습니다. 다음 번에도 재미있는 논문 리뷰 글로 찾아뵙도록 하겠습니다. 감사합니다!