Bag of Tricks for Image Classification with Convolutional Neural Networks Review
안녕하세요, 이번 포스팅에서는 2019년 CVPR에 공개된 논문인 “Bag of Tricks for Image Classification with Convolutional Neural Networks” 논문에 대한 리뷰를 수행하려 합니다.
이 논문을 소개 드리기 앞서 이 논문에서 제시하고 있는 결과를 먼저 보여드리고 시작하겠습니다
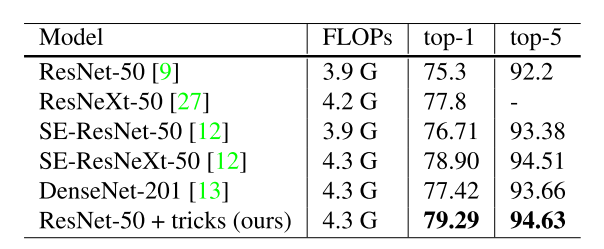
AlexNet 이후로 굉장히 많이 다뤄진 ImageNet Classification task를 다룬 논문이며, 굉장히 많이 사용되고 있는 ResNet 은 다들 잘 아실 거라고 생각합니다. ResNet 외에도 ResNext, 앞선 포스팅에서 다뤘던 DenseNet , 2017년 ILSVRC 우승한 SENet(Squeeze-Excitation Network) 등 Architecture를 바꾸면서 정확도를 높이는 연구가 주를 이뤘습니다.
하지만 정확도를 높이는 방법에는 Architecture를 바꾸는 방법만 존재하지 않습니다. 딥러닝을 연구하시는 분들은 다들 이런 경험이 있으실 겁니다.
Ex) “야 길동아, Cosine Annealing Learning Rate Scheduling을 쓰면 성능이 좋아진다던데 한번 해보렴~ Optimizer도 AMSGrad라는게 나왔던데 한번 써보자~”,
“야 철수야, 너 한번 Batch Normalization을 써 보는건 어떻겠니? 아니면 1x1 convolution을 여기 저기에 넣어봐~ Residual Connection도 넣어보고~”
학습에 관여하는 여러가지 요소들이 각각 활발하게 연구가 되고 있는데, 이를 다 합쳐서 실험을 수행한 논문은 많이 없다 보니 사용자가 일일이 모든 요소들을 바꿔가면서 실험을 해야 하고, 많은 시간이 필요한 문제는 다들 많이 겪어 보셨을 것입니다.
이 논문에서는 Architecture는 ResNet-50을 기준으로 Architecture는 크게 건드리지 않고 항간에 떠도는 여러가지 꿀팁들(이 논문에서는 Trick이라 언급)을 모아서 실험을 해보니 여러 방법들을 적용하기 전보다 ImageNet Top-1 Accuracy가 무려 4%나 증가하는 놀라운 결과를 제시하고 있습니다. 이제 각각 어떤 방법들을 적용해서 얼마나 성능이 좋아졌는지 설명을 드리도록 하겠습니다.
Baseline 학습 방법론
우선 이 논문에서 Baseline으로 삼은 Architecture인 ResNet-50을 학습시킨 방법에 대해 설명을 드리도록 하겠습니다.
우선 전처리 방법은 다음과 같습니다.
- Randomly sample an image and decode it into 32-bit floating point raw pixel values in [0, 255].
- Randomly crop a rectangular region whose aspect ratio is randomly sampled in [3/4, 4/3] and area randomly sampled in [8%, 100%], then resize the cropped region into a 224-by-224 square image.
- Flip horizontally with 0.5 probability.
- Scale hue, saturation, and brightness with coefficients uniformly drawn from [0.6, 1.4].
- Add PCA noise with a coefficient sampled from a normal distribution N(0, 0.1).
- Normalize RGB channels by subtracting 123.68, 116.779, 103.939 and dividing by 58.393, 57.12, 57.375, respectively.
저희가 일반적으로 알고 있는 전처리 기법들을 사용하였으며 크게 생소한 부분은 없으니 자세한 설명은 생략해도 될 것 같습니다.
그 뒤 모든 Conv, FC layer의 weight는 Xavier Initialization을 통해 Initialization을 해주었고, Batch Normalization의 감마는 1로, 베타는 0으로 Initialization을 해주었습니다. Optimizer는 NAG(Nesterov Accelerated Gradient) 알고리즘을 사용하였고, 8개의 GPU, Batch Size=256 환경에서 120 Epoch을 학습시켰습니다. Initial Learning Rate는 0.1로 설정을 하였고, 매 30, 60, 90번째 epoch마다 1/10을 해주는 Step Decay를 사용하였습니다.
적용한 학습 방법론 소개
이번 장에서는 이 논문에서 성능을 높이기 위해 적용한 방법론들에 대해 설명을 드릴 예정입니다. 학습을 효율적으로 시키기 위한 Efficient Training 파트, 모델의 구조를 약간 수정하는 Model Tweaks 파트, 마지막으로 정확도를 높이기 위한 Training Refinement 파트 크게 3가지 파트로 나뉘어져 있으며, 각각 파트에 대해 자세히 설명을 드리도록 하겠습니다.
1. Efficient Training
딥러닝 학습에 관여하는 하드웨어들이 최근 굉장히 빠르게 성장을 해왔습니다. 그에 따라 더 큰 batch size를 사용하거나, 더 낮은 numerical precision을 사용하면서 학습을 더 효율적으로 시키는 방법들이 가능해졌습니다. 이번 파트에서는 이러한 효율적인 학습 방법들을 적용하여 학습 속도와 정확도를 올리는 방법을 설명드릴 예정입니다.
논문에서는 크게 Large-batch training 과 Low-precision training 으로 나눠서 방법론을 제시하고 있습니다. 우선 Large batch training에 대해 설명을 드리면, 일반적으로 convex 문제를 풀 때, batch size가 크면 그만큼 수렴이 느려진다고 알려져 있는데요, 이러한 문제를 풀기 위해 다양한 연구들이 진행되었습니다.
1-A. Linear scaling learning rate
Accurate, large minibatch SGD: training imagenet in 1 hour 논문에 따르면 batch size를 키워주면, 그 만큼 linear하게 learning rate를 키워주는 것이 좋다고 언급하고 있습니다. 이러한 방식을 본 논문에서도 실험을 해보았습니다. 즉 batch size=256, initial learning rate=0.1일 때, 만약 batch size를 b 로 키워주면 initial learning rate도 0.1 * b/256 으로 키워주는 것을 의미합니다.
1-B. Learning rate warmup
이 방식도 위에서 소개 드린 논문에서 제안한 방법이며, learning rate는 초기에 설정한 값을 기반으로 줄여주는 방식을 사용한다고 주로 알고 있는데, 이와는 반대로 초기에 learning rate를 0으로 설정하고 이를 일정 기간동안 linear하게 키워주는 방식을 의미합니다.
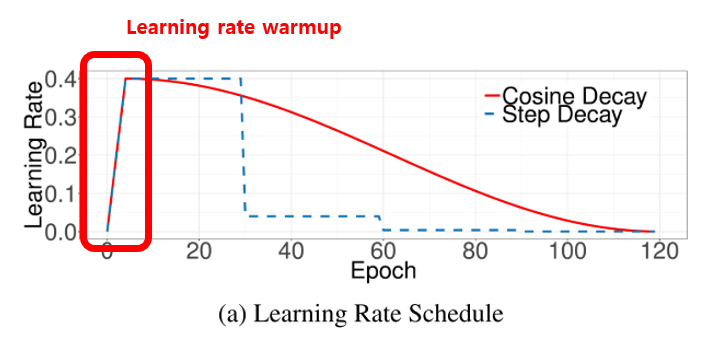
위의 그림에 빨간색 박스로 표시한 부분이 Learning rate warmup을 보여주고 있으며 5 epoch 동안 조금씩 learning rate를 키워서 저희가 설정하는 값인 initial learning rate 값까지 키워주고, 이러한 heuristic이 학습에 도움이 된다고 알려져 있습니다.
1-C. Zero Gamma in BatchNorm
다음은 사소한 heuristic인데, Batch Normalization layer에서 x 와 곱해지는 값인 감마는 베타와 마찬가지로 학습할 수 있는 learnable parameter이므로 학습 전 initialization을 해줘야합니다.

일반적으로 감마는 1로, 베타는 0으로 initialization을 하는데, ResNet 구조와 같이 residual connection이 존재하는 경우에는 감마를 0으로 초기화해주는 것이 학습 초기 단계에 안정성을 높여준다고 합니다.
1-D. No bias decay
저희가 자주 사용하는 technique인 L2 regularization은 일반적으로 weight와 bias에 모두 적용을 합니다. 하지만 Highly scalable deep learning training system with mixed-precision: Training imagenet in four minutes. 논문에 의하면 weight에만 decay를 주는 것이 overfitting을 방지하는데 효과적이라고 언급하고 있어서 이 논문 또한 weight 외에는 decay를 사용하지 않는 heuristic을 적용하였습니다. 즉 bias 뿐만 아니라 Batch Normalization의 감마, 베타 또한 decay가 적용되지 않습니다.
1-E. Low-precision training
일반적으로 Neural Network는 32-bit floating point(FP32) precision을 이용하여 학습이 진행됩니다. 하지만 최신 하드웨어에서는 lower precision 계산이 지원되면서 속도에서 큰 이점을 얻을 수 있습니다. 예를 들자면, NVIDIA V100은 FP32 에서는 14TFLOPS일 때 FP16에서는 100 TFLOPS가 가능하며 전체적인 학습 속도도 FP32 대비 FP16에서 약 2~3배 빠르다고 합니다.

위의 그림은 해당 링크의 글 에서 인용을 하였는데요, FP32에서 FP16으로 precision을 줄이게 되면 수를 표현할 수 있는 범위가 줄어들게 되는 단점이 있습니다. 이로 인해 학습 성능이 저하될 수 있는데, 이를 해결하기 위한 학습 방법을 제안한 Mixed precision training 방식을 적용하여 학습을 시켰습니다.
Efficient Training 실험 결과
앞서 소개 드린 5가지 방법들을 적용하였을 때의 성능이 어떻게 변하는지에 대한 ablation study 결과는 아래 그림에서 확인하실 수 있습니다.
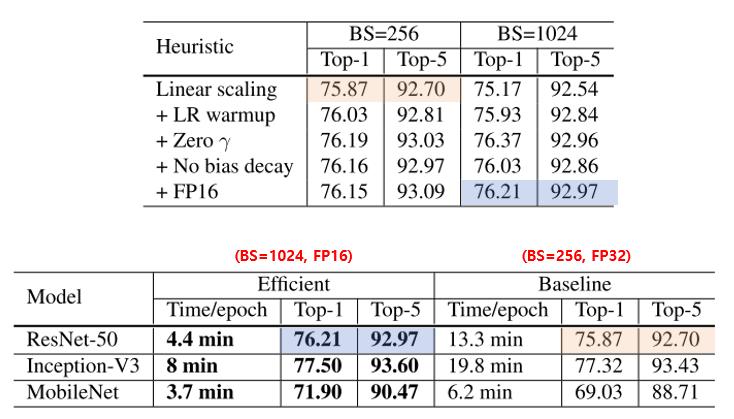
우선 아무런 방법도 적용하지 않았을 때의 ResNet-50의 실험 결과가 위의 그림의 주황색으로 음영을 넣은 부분 의 결과인 75.87%이며 각각의 heuristic을 하나씩 추가하였을 때의 결과가 나와있습니다. 모든 방식을 다 적용하였을 때의 결과는 파란색으로 음영을 넣은 부분 의 결과인 76.21% 입니다. Efficient Training에서는 약 0.3% 밖에 정확도가 오르지 않았지만 학습 속도가 약 3배 빨라지는 장점이 있었습니다.
2. Model Tweaks
이번 파트에서는 ResNet architecture에 약간의 모듈들을 수정하여 성능을 올리는 방법을 제안하고 있습니다. 우선 Baseline으로 삼은 ResNet-50의 architecture는 아래 그림과 같이 나타낼 수 있습니다.
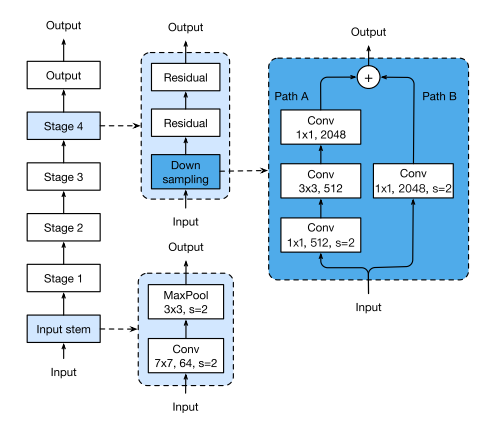
이 그림에서 파란색으로 색칠된 영역인 Input stem에 변화를 준 ResNet-C 와 Stage 4의 Down sampling block 의 구조를 변경한 ResNet-B , ResNet-D 를 제안하였습니다.
각각의 Architecture에서 바뀐 block 구조와 그에 따른 정확도 변화는 아래 그림에서 확인할 수 있습니다.
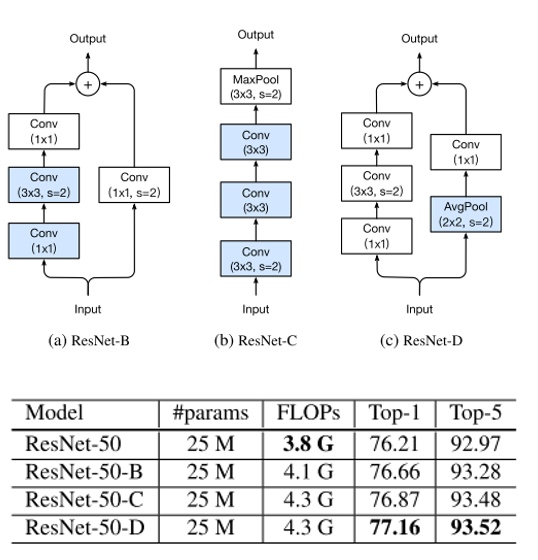
ResNet-D에서 가장 정확도가 좋았으며, 약간의 FLOPS가 증가하였지만 Top-1 Accuracy가 거의 1% 증가하는 것을 확인할 수 있습니다.
3. Training Refinement
이번 파트에서는 정확도를 올리기 위한 4가지 학습 방법들을 제안하고 있습니다.
3-A. Cosine Learning Rate Decay
이제는 많이들 들어보셨을 Cosine Learning rate decay 방법은 SGDR: stochastic gradient de- scent with restarts. 논문에서 제안된 방식이며 제 블로그의 “Shake-Shake Regularization Review & TensorFlow code implementation” , “Pelee Tutorial [2] PeleeNet PyTorch Code Implementation” 등에서도 다뤘던 방식입니다. 이 방식을 적용하여 성능을 향상시킬 수 있었다고 합니다.
3-B. Label Smoothing
다음 소개드릴 방식은 inception-v2를 제안한 논문인 Rethinking the inception architecture for computer vision 에서 사용한 방식인 label smoothing 방식입니다. 원래는 classification network를 학습시킬 때 정답은 1 나머지는 0인 one-hot vector를 label로 사용하는데, 0 대신 작은 값을 갖는 label을 사용하는 방식을 의미하며 아래 식과 같이 label을 smoothing할 수 있습니다.

이 때 K 값은 전체 class의 개수를 의미하며 입실론 값으론 0.1을 사용하였다고 합니다.
3-C. Knowledge Distillation
Distilling the knowledge in a neural network 논문에서 제안한 방법인 Knowledge Distillation 또한 잘 알려진 방법이며 성능이 좋은 teacher model을 이용하여 student model이 적은 연산 복잡도를 가지면서 teacher model의 정확도를 따라가도록 학습을 시키는 방법을 의미합니다.
Teacher model로 ResNet-50보다 큰 모델인 ResNet-152를 사용하였고, 이를 이용하여 student model인 ResNet-50을 학습시켰습니다.
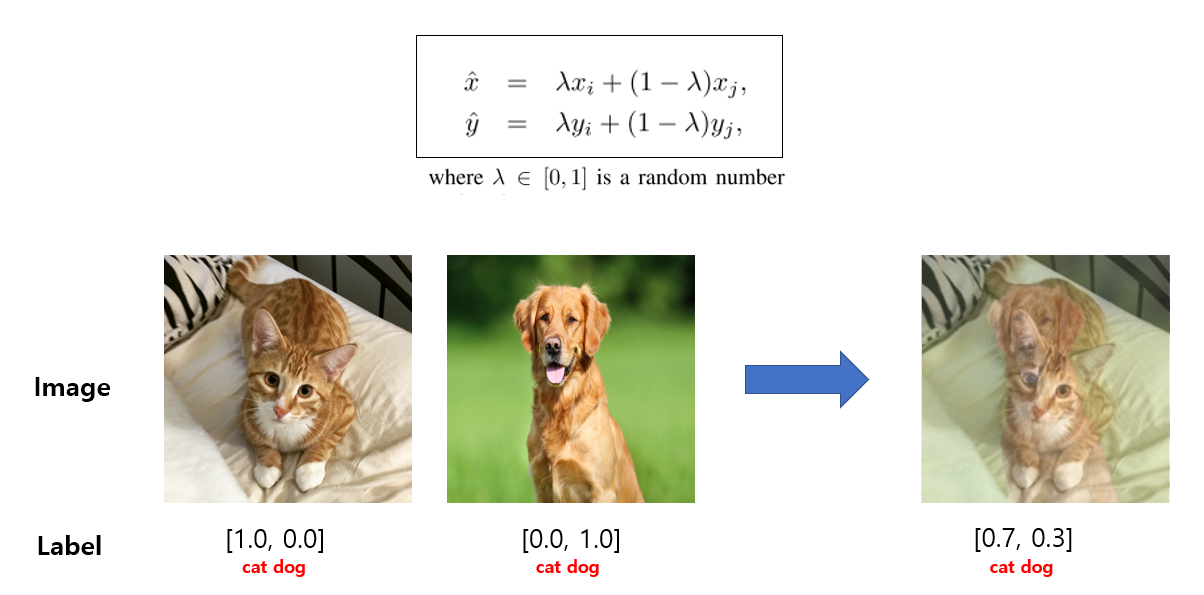
3-D. Mixup Training
마지막으로 소개드릴 Mixup augmentation은 mixup: Beyond empirical risk minimization. Data에 dependent한 augmentation 기법이며 두 데이터의 이미지와 label을 각각 weighted linear interpolation 하여 새로운 sample을 생성하는 기법을 의미하며 아래 그림과 같이 나타낼 수 있습니다.
Training Refinement 실험 결과
위에서 설명 드린 4가지 방법을 적용하였을 때 실험 결과는 다음과 같습니다.
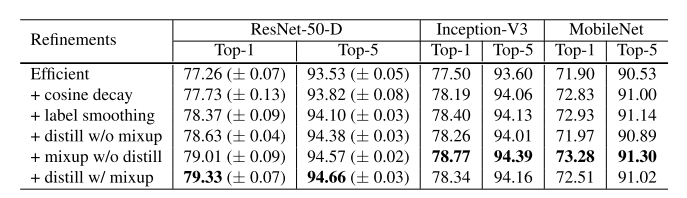
앞선 방법들(Efficient Training, Model Tweaks)이 적용된 결과에 위에서 설명 드린 4가지 방법을 차례대로 적용하였을 때 정확도가 얼마나 향상되는지 표를 통해 확인할 수 있습니다. 각 방법을 적용하면 적게는 0.4%에서 많게는 0.7%까지 정확도가 향상되는 것을 확인할 수 있습니다.
Transfer Learning 실험(Object Detection, Semantic Segmentation)
이번 파트에서는 앞서 찾은 Classification 모델에 적용하였던 여러 방법들을 다른 task인 Object Detection, Semantic Segmentation에 적용하였을 때에도 성능이 좋아지는지 확인하기 위한 실험을 수행하였습니다.
우선 Object Detection은 VGG-19를 base로 하는 Faster-RCNN에 대해 실험을 진행하였고, Semantic Segmentation은 Fully Convolutional Network(FCN)에 대해 실험을 수행하였습니다.
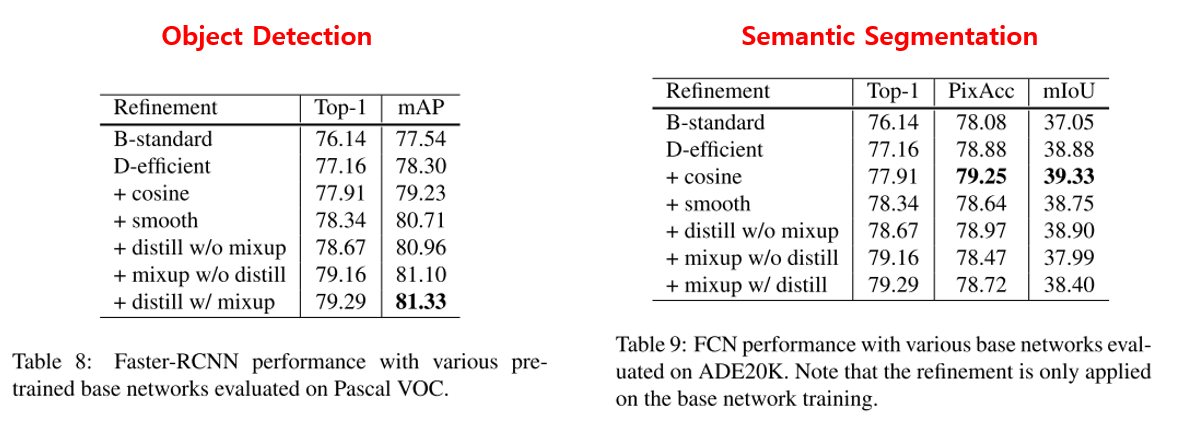
실험 결과는 위의 표에 나와있으며 적용하기 전에 비해 성능이 대체로 향상되는 것을 확인할 수 있습니다. 다만 Semantic Segmentation의 경우 label smoothing, mixup 등은 오히려 안 좋은 효과를 내었습니다.
결론
이번 포스팅에서는 CVPR 2019에 발표된 논문인 “Bag of Tricks for Image Classification with Convolutional Neural Networks” 논문을 리뷰해보았습니다. 굉장히 실험적인 논문이며 인용한 논문이 굉장히 많았고, 이들에 대해 모든 실험을 통해 성능을 올릴 수 있음을 보여주고 있다는 점이 인상깊었습니다. 앞으로 Image Classification 학습에 관여하는 여러 요소들을 고려할 때 이 논문을 참고하면 좋을 것 같네요! 다음 번에도 재미있는 논문 리뷰 글로 찾아뵙도록 하겠습니다. 감사합니다!
References
- Accurate, large minibatch SGD: training imagenet in 1 hour
- Highly scalable deep learning training system with mixed-precision: Training imagenet in four minutes. 논문
- Floating Point 비교 그림
- Mixed precision training 논문
- SGDR: stochastic gradient de- scent with restarts. 논문
- Rethinking the inception architecture for computer vision 논문
- Distilling the knowledge in a neural network 논문
- mixup: Beyond empirical risk minimization. 논문