ICCV 2019 Review [2] Best Paper SinGAN: Learning a Generative Model from a Single Natural Image 리뷰
안녕하세요, 이번 포스팅에서는 지난 ICCV 2019 소개글에 이어서 Best Paper Award를 받은
“SinGAN: Learning a Generative Model from a Single Natural Image”
논문을 소개 드리고자 합니다. 저는 이번 학회에서 가장 인상깊었던 논문을 꼽으라면 이 논문을 자신있게 꼽을 수 있을 것 같습니다. Best Paper Award 세션에서도 발표를 듣고, 구두 발표도 듣고 포스터 발표도 들을 정도로 논문이 아이디어가 참신하고 여러 응용 사례도 인상깊어서 꼭 리뷰를 해야겠다고 생각을 했습니다.
본 논문의 리뷰를 시작하기에 앞서 본 논문의 결과를 잘 보여주는 사진과 영상 자료를 보여드리고 시작하는 것이 좋을 것 같습니다.

위의 그림은 논문에서 제시하고 있는 여러 Image manipulation 의 결과 예시이며 Single Natural Image로 GAN을 학습시켰음에도 불구하고 굉장히 다양한 응용 사례가 존재하며, 결과도 매우 realistic한 것을 확인할 수 있습니다.
혹시 시간이 되시는 분들은 “SinGAN: Learning a Generative Model from a Single Natural Image” 발표 영상 도 보시는 것을 추천 드립니다. 시간이 없으신 분들은 3분 35초 정도까지의 결과 데모 정도만 보시는 것도 좋습니다!
이제 이 논문에 대해 소개를 드리도록 하겠습니다.
Introduction
GAN에 대해선 자세히 설명을 드리지 않아도 다들 많이 들어보셨을 것이라 생각합니다. 굉장히 많은 연구가 진행되고 있는 분야고, 굉장히 놀랄만한 결과들이 많이 나오고 있습니다. 하지만 얼굴, 침실 등 한가지 종류에 집중하여 생성을 하는 연구들이 대부분이고, 학습을 하기 위해 많은 수의 데이터를 필요로 합니다.
또한 다양한 class로 구성된 데이터셋(e.g. ImageNet)의 distribution을 배우는 것은 여전히 잘 되지 않고, 이를 개선하기 위해 input signal에 conditional한 생성을 하거나 task를 한정짓는 방식(e.g. Super-Resolution, Inpainting, Retargeting) 으로 연구가 되고 있습니다.
이러한 문제점을 발견하면 다음과 같은 생각을 할 수 있습니다.
“적은 수의 image만 가지고, 아니면 아예 1장만 가지고 GAN을 학습시킬 수 없을까?? “
이러한 질문을 가지고 접근한 논문은 오늘 소개드릴 SinGAN 외에도 한 편이 더 있습니다. (이 논문도 ICCV 2019에서 발표가 되었습니다!)
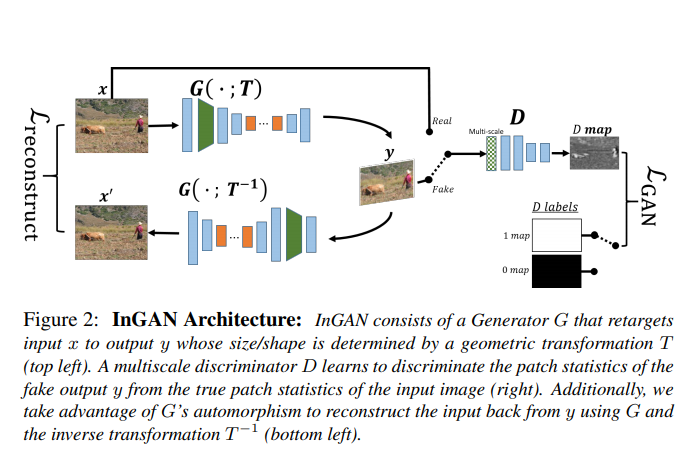
“InGAN: Capturing and Remapping the “DNA” of a Natural Image, 2019 ICCV” 논문도 한장의 Natural Image로 부터 여러 image를 생성하는 연구를 수행하였지만 위에 말씀드린 것처럼 input image에 conditional한 방식을 사용하고 있습니다. 즉 image에서 image로 mapping하는 방식을 사용하고 있는 반면, 본 논문은 unconditional하게, 즉 noise로부터 image를 생성하는 방식을 사용하고 있습니다.
Unconditional Single Image GAN 연구는 Texture Generation 연구가 유일했고, Texture Image에는 좋은 결과를 보이지만 Texture Image가 아닌 Image에는 좋지 않은 결과를 보이고 있습니다.

이러한 점에 주목하여 general한 natural image에 적용할 수 있는 방법을 본 논문이 제안을 하고, Texture Generation 방법보다 우수한 성능을 보이는 것을 위의 그림을 통해 확인할 수 있습니다. 이제 이 논문의 핵심 아이디어들과 실험 결과들을 소개 드리도록 하겠습니다.
Method
Multi-scale architecture
SinGAN의 목표는 single training image의 내부 통계치(distribution)을 배울 수 있는 unconditional generative model을 만드는 것입니다. 이를 위해선 Image의 배열과 Object들의 모양 등의 Global한 특징과, Object의 디테일한 정보, Texture 등 Fine한 특징을 모두 배울 수 있어야 합니다. 이를 위해 coarse-to-fine 하게 image를 생성하는 multi-scale GAN 구조를 사용하였습니다.
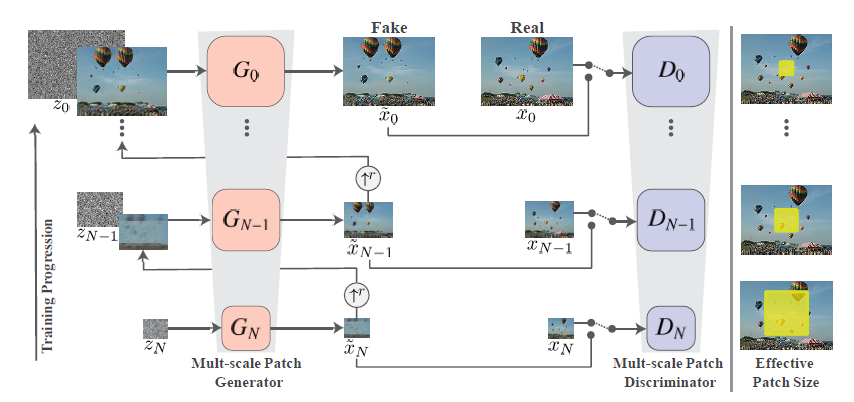
그림에서 x0 는 training image 이고, 아래로 한 단계씩 내려갈수록 r 배(r>1)씩 downsampling 되는 방식입니다. 각 단계마다 Generator는 noise와 이전 단계에서 생성된 결과 image를 input으로 하여 image를 생성하고, 그 단계의 Discriminator는 downsampling된 GT와 생성된 image를 구분하도록 학습이 됩니다. 예외로 제일 첫 단계(맨 밑)에서는 noise만 이용하여 image를 생성합니다. 글보다는 그림을 보시는 것이 이해가 잘 되실 것 같습니다…
앞 단계에서는 downsampling된 GT를 생성하도록 학습을 하다보니 coarse한, global한 특징에 집중을 하여 생성을 하게 되고, 위로 갈수록 fine한 영역에 집중하여 생성을 하게 됩니다. Generator 구조가 kernel 수만 다르고 연산자들은 같다 보니 동일한 receptive field를 갖게 되고, 생성하는 image의 크기만 다르다 보니 그림의 맨 오른쪽 부분처럼 Effective Patch Size 가 달라지면서 coarse-to-fine 하게 학습이 된다고 이해하시면 될 것 같습니다.
참고로 각 Generator는 너무 capacity를 크게 가져가면 training image 자체를 외울 수 있기 때문에 적은 capacity를 갖도록 설계를 하였다고 합니다. 구조는 3x3 Conv-BatchNorm-LeakyReLU 를 5번 반복한 간단한 Fully-Convolutional 구조이고, 제일 coarse한 Generator는 32개의 kernel을 사용하였고, 4개의 scale이 오를때 마다 kernel 개수를 2배로 해주었다고 합니다. 또한 아래 그림과 같은 residual 구조를 이용하여 이미지를 생성하였습니다.
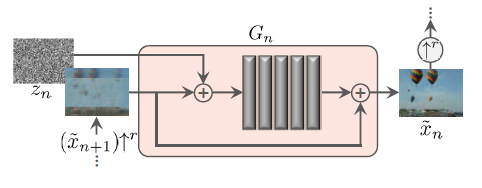
자세한 구조가 궁금하시면 저자의 Official Code(PyTorch) 를 확인하시면 됩니다.
Training
학습은 기존 GAN을 학습시키는 방법과 유사합니다. Adversarial loss와 Reconstruction loss로 구성이 되어있으며, Adversarial loss로는 WGAN-GP loss를 사용하였습니다. Reconstruction loss는 Generator가 생성한 image와 그 단계의 GT(downsampled) image간의 pixel간의 차이를 줄이는 방향으로 학습하기 위해 squred loss를 사용하였습니다. 학습을 위해서 각 단계의 주입되는 noise 셋팅은, 가장 첫 단계인 N 단계에만 고정된 noise를 주입하고, 나머지 단계에서는 noise를 주입하지 않았습니다. 즉 image의 pixel 차이를 줄이는 것에만 집중을 하기 위해 이렇게 셋팅을 하였습니다.
Result
위에서 설명드린 GAN 구조를 이용하여 실험을 수행한 결과를 설명드리겠습니다.
정성적인 실험 결과
GAN 이라는 task의 특성 상 정량적인 결과도 봐야겠지만 정성적인 결과를 보는것도 중요합니다. 이 논문에서도 정량적인 결과와 정성적인 결과를 모두 보여주고 있습니다. 정성적인 결과는 결과 이미지를 보면서 확인할 수 있고, 결과 이미지는 아래 그림을 통해 확인하실 수 있습니다. Generator가 Fully-Convolutional 구조이기 때문에 임의의 해상도를 갖는 이미지를 생성할 수 있다는 점이 흥미로운 점입니다. 또한 고해상도의 이미지도 자연스럽게 생성하는 것을 확인할 수 있습니다.

다음으론 논문에서 제시하고 있는 정량적인 결과에 대해 설명을 드리도록 하겠습니다.
정량적인 실험 결과
정량적인 평가를 위해 저자는 2가지 방법을 사용하였습니다. 첫째론 Amazon Mechanical Turk(AMT)를 이용해 사람들로 하여금 이 image가 Fake인지 Real인지를 구분하는 투표 방식을 사용하였습니다. 두번째 지표로는 기존에 GAN 연구에서 자주 사용되던 Frechet Inception Distance(FID) 를 Single Image에 맞게 변형한 Single Image FID(SIFID) 지표를 고안하여 비교를 하였습니다. 다만 본 포스팅에서는 좀 더 직관적인 실험인 첫번째 지표의 결과만 소개를 드리겠습니다. SIFID 결과가 궁금하신 분들은 본 논문의 6페이지~7페이지를 참고하시면 좋을 것 같습니다.
AMT perceptual study
우선 AMT를 이용하여 2가지 실험 환경에서user study를 수행하였습니다. 첫번째 실험 환경은 Real image와 SinGAN을 통해 생성한 Fake image를 둘 다 보여주고 어느 쪽이 Fake인지 맞히는 Paired 실험이고, 두번째 실험 환경은 Real image 혹은 Fake image 한 장만 보여준 뒤 얼마나 헷갈렸는지를 보는 Unpaired 실험입니다. 각각 실험당 1초의 시간이 주어지고, 한 명의 Worker당 50장의 image를 보여줍니다. 이러한 실험을 coarsest한(N) scale로부터 inference를 할 때와, 그 위의 N-1 scale에서 inference를 할 때의 결과를 비교하였습니다.
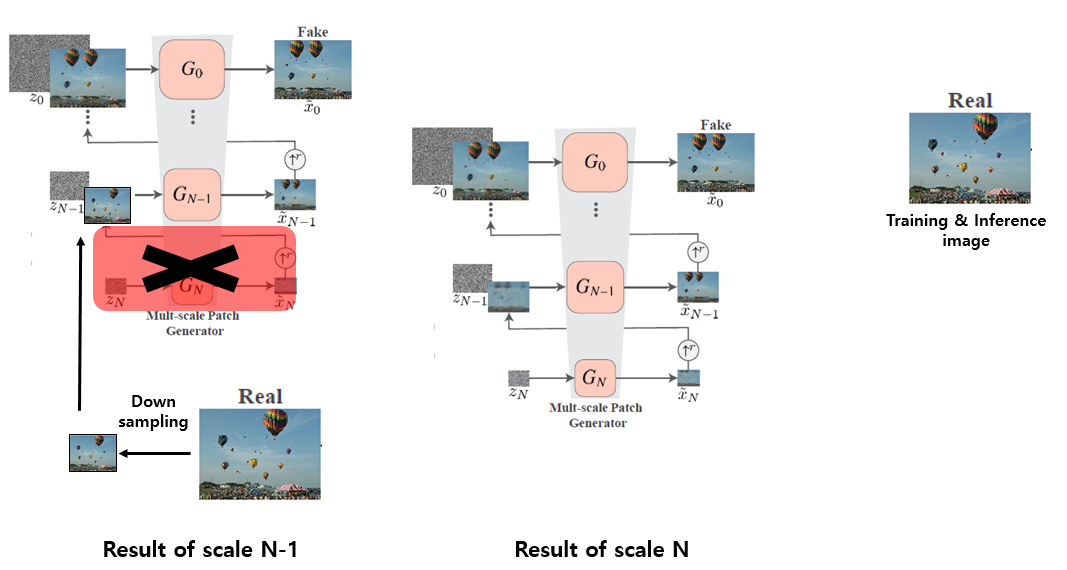
N scale에서 inference를 하는 것은 noise로부터 생성을 하는 것을 의미하고, N-1 scale에서 inference를 하는 것은 input image를 downsampling한 뒤 N-1 번째 Generator의 input으로 넣어주는 방식을 의미하며, 이 부분이 저는 헷갈렸어서 설명하기 위한 그림을 준비하였습니다. 위의 그림과 같이 scale N 일 때와 N-1 일 때의 생성하는 과정의 차이를 설명할 수 있습니다.
이러한 식으로 생성을 하면, 당연히 scale N-1일 때 보다 더 input image와 유사한 모양과 배열을 갖는 이미지가 생성이 될 것이라고 생각할 수 있습니다. 본 논문에서는 scale N ~ N-2 까지 바꿔가며 실험을 하였고 그에 대한 결과 예시는 아래 그림과 같습니다.
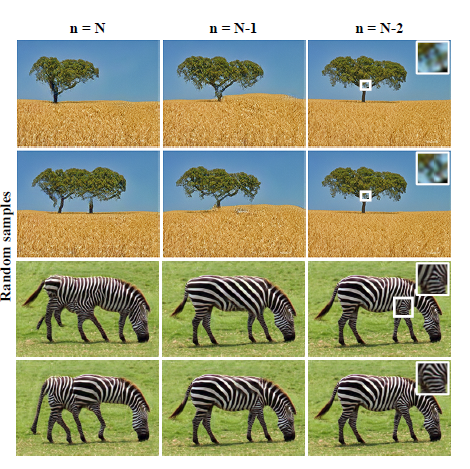
가장 coarse한 단계부터 생성을 하면 random noise로부터 시작을 하기 때문에 원본과 모양이 많이 다른 이미지가 생성이 될 수 있지만 얼룩말 그림처럼 실제론 존재하지 않는 다리 모양을 가지게 되는 부작용이 발생합니다. 반대로, scale N-2의 결과를 보면 texture나 배열의 변화가 매우 적은 것을 확인할 수 있습니다. 실험적으로 scale N-1 일 때 다양성도 보장이 되고 원본의 형태도 유지하면서 inference를 하여 이미지를 생성할 수 있음을 보이고 있으며, AMT perceptual study 결과도 좋은 결과를 보입니다.

Scale N 일 때 unpaired의 경우 약 43%의 confusion 정도를 보이지만 Scale N-1 일 때에는 거의 47%의 confusion을 보이는 것을 확인할 수 있습니다. 이상적인 경우는 50%의 confusion 보이는 것을 감안하면 그럴싸하게 생성을 하고 있어서 사람이 보기에도 굉장히 헷갈리고 있다는 것을 확인할 수 있습니다.
Applications
마지막으로 다룰 부분은, 이 연구의 꽃이라고 부를 수 있는 여러 응용 사례입니다. 단순히 하나의 image로 학습을 시켜서 이 image와 비슷한 image들을 여러 개 생성하는 결과만 보였다면 큰 흥미를 느끼지 못했을 것입니다. 이러한 점을 저자도 고려했는지 무려 5가지의 Application을 보여주고 있습니다. 아마 이 글의 앞부분 소개 드린 데모 동영상을 보셨다면 쉽게 이해하실 수 있을 것이라 생각합니다.
모든 응용 사례는 한 장의 image에 대해 학습이 끝나면 추가적인 architecture의 변화나 추가적인 fine tuning등을 필요로 하지 않는 것이 장점이며, 학습에 사용한 image와 다른 image를 주입하는 방식이기 때문에 scale N이 아닌 더 위의 단계 (n<N) 에서 inference를 수행합니다. 각각 application에 대해 자세하게 설명을 드리도록 하겠습니다.
Single Image Super Resolution
Super Resolution 실험을 위해 reconstruction loss에 100의 weight를 주고 low-resolution image 한 장으로 학습을 시킨 뒤, test시에는 upsampling한 image를 제일 마지막 Generator G0에 noise와 함께 입력을 해줍니다. High-resolution output을 얻기 위해 이러한 과정을 k 번 반복하였고, 결과 비교를 위해 Internal method인 Deep Image Prior(DIP), Zero-Shot Super Resolution(ZSSR) 방식, 학습 데이터를 많이 필요로 하는 external method인 SRGAN, EDSR 등과 결과를 비교하였습니다.

실험 결과, distortion quality인 RMSE(낮을수록 좋음)는 높지만 perceptual quality인 NIQE(낮을수록 좋음)은 다른 internal method들에 비해 낮은 것을 확인할 수 있고, 학습 데이터를 필요로 하는 SRGAN과 비슷한 perceptual quality를 보임을 확인할 수 있습니다. 생성된 결과 이미지만 봐도 꽤 그럴싸하게 Super Resolution을 하고 있음을 알 수 있습니다. 무려 1장의 이미지만 사용해서 얻은 결과입니다.!!
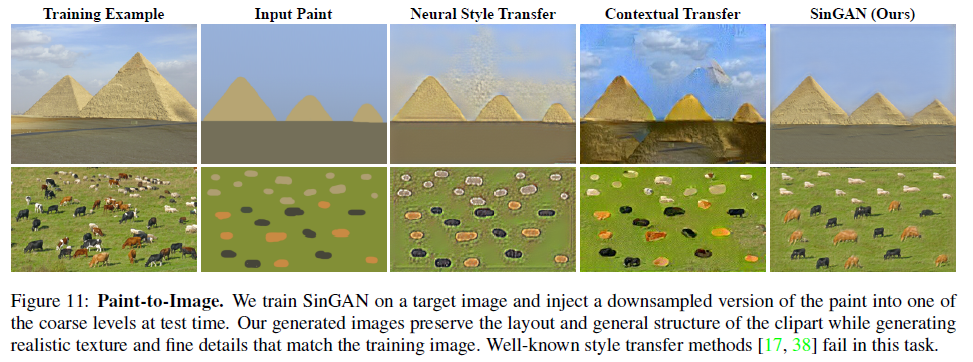
Paint-to-Image Style Transfer
다음은 Paint image로부터 Image로 생성해내는 Style Transfer 실험이며 input으로 paint image를 scale N-1 혹은 N-2 에 downsampling하여 넣어주면 학습에 사용한 image의 style을 가진 image로 생성하는 예시를 보여주고 있습니다. 아래 그림을 보면 꽤 그럴싸한 생성 결과를 보여주고 있습니다.
Harmonization
다음은 image에 다른 object를 삽입하였을 때, 주변 배경과 조화를 이루며 object를 변형시키는 Harmonization task에 SinGAN을 적용한 결과를 보여주고 있습니다. Background image로 학습을 시킨 뒤, object를 삽입한 image로 test한 결과이며, 아래 그림을 보면 꽤 자연스러운 결과를 보여주고 있습니다.

Editing
다음으로 설명드릴 task는 Image에서 일부 영역들을 복사+붙여넣기 하여 편집을 했을 때, 편집된 image를 주변에 자연스럽게 어우러지도록 만들어주는 Editing 예시 입니다. 아래 결과 그림을 보시면 포토샵에 들어있는 기능인 Content Aware Move 기능보다 더 자연스러운 결과를 보여주는 것을 확인할 수 있습니다.

Single Image Animation
마지막 Application은 Single Image Animation이며 한 장의 Image로부터 짧은 video clip을 생성하는 것을 의미하며, object 들이 움직이는 것처럼 보이게 하는 것이 목표입니다. 결과 예시는 데모 영상 을 통해 확인하실 수 있으며 꽤 자연스러운 동영상을 만들 수 있음을 확인할 수 있습니다.
결론
이번 포스팅에서는 ICCV 2019에 Best Paper로 선정된 “SinGAN: Learning a Generative Model from a Single Natural Image” 논문을 자세하게 리뷰하였습니다. 오로지 한 장의 Image만으로 학습시켜서 다양한 형태의 Image를 생성하기 위한 GAN 구조를 제안하였고, 굉장히 흥미롭고 좋은 결과를 보이는 5가지 Application을 소개하였습니다. 결과를 보시면 왜 이 논문이 Best Paper로 선정이 될 수 밖에 없는지 공감을 하실 것으로 생각합니다. 저자가 PyTorch로 구현한 코드 또한 공개를 해두었으니 관심있으신 분들은 적용해보셔도 좋을 것 같습니다. 생각보다 글이 길어졌는데 긴 글 읽어주셔서 감사합니다!