Self-training with Noisy Student improves ImageNet classification Review
안녕하세요, 이번 포스팅에서는 11월 11일 무려 3일 전! 공개된 논문인 “Self-training with Noisy Student improves ImageNet classification” 논문에 대한 리뷰를 수행하려 합니다. 이 논문은 제가 전에 리뷰했었던 EfficientNet 논문을 기반으로 ImageNet 데이터셋에 대해 또 한 번 State-of-the-art(SOTA)를 갱신하며 주목을 받을 것으로 기대 중인 논문입니다! 이번에도 논문을 소개 드리기 앞서 실험 결과를 먼저 보여드리고 시작하겠습니다.
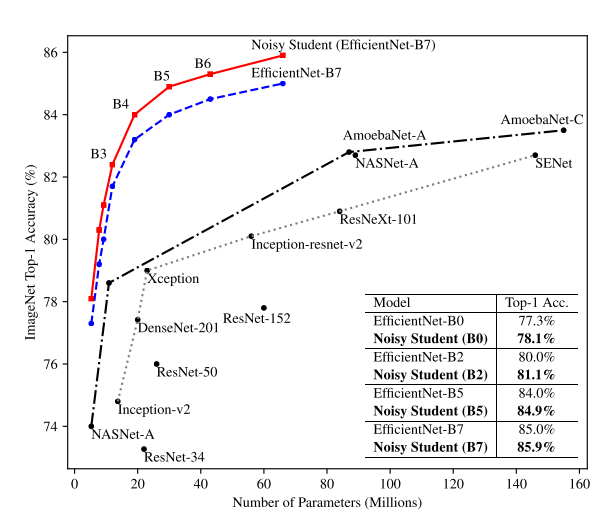
저번에 다뤘던 EfficientNet의 실험 결과 그림과 굉장히 유사한 그림을 논문에서 제시하고 있습니다. 워낙 EfficientNet이 기존 방법들에 비해 월등한 성능을 달성해서 그런지, 성능 향상 폭이 적어 보일 수 있지만.. 그래도 최고의 성능을 달성하였고, 그 과정에서 사용한 방법이 굉장히 간단해서 의미가 있는 결과라고 생각합니다. 이제 어떠한 방식들을 적용했는지 설명을 드리도록 하겠습니다.
Image Classification의 연구 동향
2012년 모두가 알고 계실 AlexNet을 기점으로 굉장히 많은 Image Classification Network들이 제안이 되었습니다. 시간이 흐를수록 연구자들이 집중하는 연구의 방향이 꽤 많이 바뀌고 있음을 느껴서 제가 논문을 읽으면서 느낀 점을 간략하게 정리를 해보았습니다.
- 2012년 ~ 2016년: AlexNet, VGG, googLeNet, ResNet, DenseNet, SENet 등 사람이 이런저런 시도를 하면서 그럴싸한 네트워크를 디자인하는 흐름
- 2016년 말 ~ 2018년: AutoML을 이용한 Neural Architecture Search(NAS)를 이용해서 최적의 구조를 찾고, 탐색에 필요한 시간을 획기적으로 줄이고 줄인 만큼 큰 구조를 만들어내는데 집중
- Neural Architecture Search with Reinforcement Learning (2016.11 공개)
- NASNet, ENAS, PNASNet, DARTS, AmoebaNet 등 많은 연구 진행
- 2018년 ~ 2019년 초중반: AutoML에서 찾은 구조를 기반으로 사람이 튜닝을 하며 성능 향상
- GPipe, EfficientNet 등 많은 연구 진행
- 2019년 초중반: 수십억장의 web-scale extra labeled images 등 무수히 많은 데이터를 잘 활용하여 ResNeXt로도 SOTA를 달성
- Billion-scale semi-supervised learning for image classification (2019.5 공개)
- Fixing the train-test resolution discrepancy (2019.6 공개)
- 2019 말(지금): labeled web-scale extra images 대신 web-scale extra unlabeled images을 써서 Self-Training을 활용하여 SOTA 달성
- 2020: ????
2016년 NAS 연구가 처음 공개된 이후 얼마 지나지 않아 굉장히 많은 논문들이 쏟아져 나왔고, 처음엔 비현실적인 GPU Cost를 요구해서 꿈만 같은 연구라 생각했는데, 불과 1년만에 하나의 GPU로 하루만에 학습을 시킬 수 있는 방법들이 제안이 되었고 연구가 굉장히 빠르게 진행이 되어왔습니다.
거기에, AutoML로 찾은 모델을 사람이 튜닝하여 성능을 대폭 개선시키더니, 올해에는 쉽게 구할 수 있는 Web-Scale의 수십억 장의 데이터를 활용하여 모델의 임계 성능을 끌어올리기도 하였습니다. 그리고 오늘 소개드릴 논문은 위의 연구 방향들을 종합하여 또 다시 최고 성능을 달성하였다고 볼 수 있습니다.
Image Classification 분야는 다른 분야에 비해 굉장히 많은 연구가 굉장히 빠르게 진행이 되고 있는데요, 내년에는 또 어떤 논문들이 나올지 기대가 됩니다. 현재 ImageNet Top-1 Accuracy가 가장 높은 결과가 87.4%인데 머지않아 90%를 넘기는 논문이 나오지 않을까 기대해봅니다.
Self-training with Noisy Student
본 논문의 핵심 아이디어는 간단한 사진으로 정리가 가능합니다. 논문에는 알고리즘만 제시가 되어있는데, 설명을 돕기 위해 핵심 내용을 그림으로도 정리를 하였습니다.
Self-Training
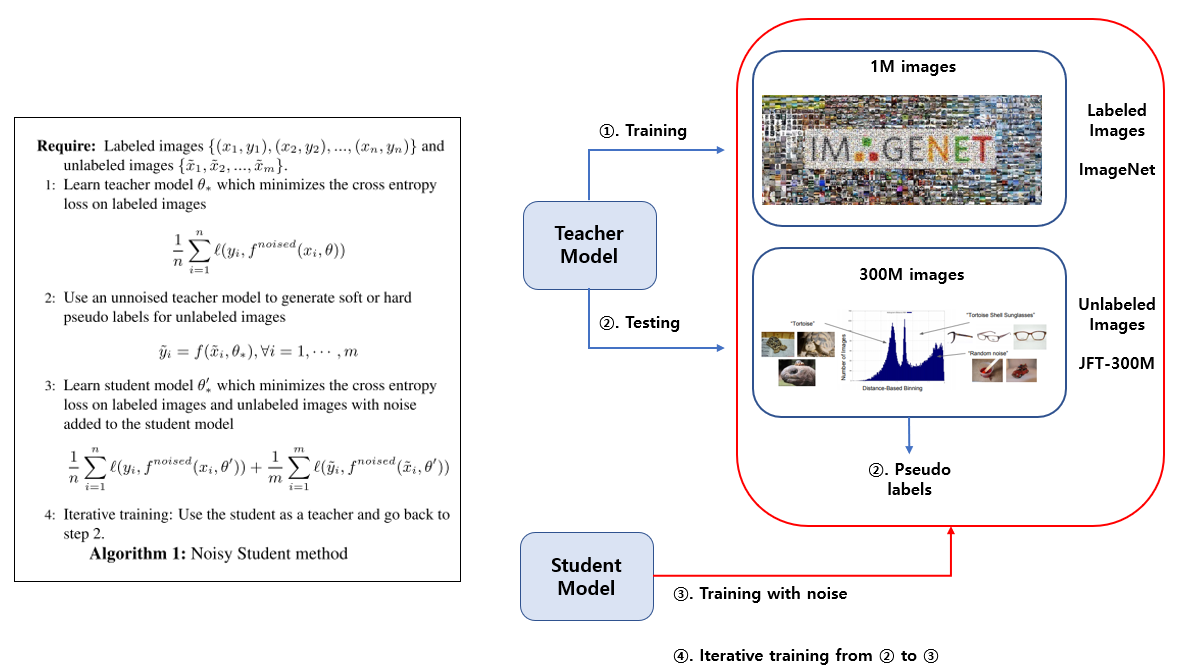
우선 Labeled 데이터셋인 ImageNet을 이용하여 Teacher Model 을 학습을 시킵니다. 그 뒤 Unlabled 데이터셋인 JFT-300M을 Teacher Model 에 흘려 보내서 prediction 값을 구한 뒤 이를 pseudo label로 사용을 합니다. 이렇게 얻은 JFT-300M 데이터셋의 pseudo label과 기존에 사용하던 ImageNet의 label을 이용하여 Student Model 을 학습시킵니다. 이 때 Student Model에 noise를 주입하여 학습을 시킵니다. 이 과정을 반복하며 iterative 하게 학습을 시키면 알고리즘이 끝이 납니다.
Teacher – Student 구조를 보면 Knowledge Distillation를 떠올릴 수 있습니다. Knowledge Distillation은 Student Model을 작게(Compression) 만드는 것이 목표이고 Labeled 데이터셋만 사용하여 학습을 하는 부분이 이 논문과의 차이점입니다.
Noise 기법
또한 논문에 제목에서도 언급했듯이 Self-Training 외에도 Noisy Student Model이 이 논문의 또 다른 핵심 아이디어입니다. Student Model을 학습시킬 때 “Stochastic Depth” , “Dropout” , “RandAugment” 등 Random한 학습 기법들을 사용하였고, 이러한 기법들을 Noise라 부르고 있습니다. 각각에 대한 방법론이 궁금하신 분들은 방법론을 누르시면 논문이 연결되니 참고하시면 좋을 것 같습니다.
Fix train-test resolution discrepancy
또한 최근 좋은 성능을 보였던 “fix train-test resolution discrepancy” 방법론 또한 적용을 하였습니다. 우선 첫 350 epoch 동안은 작은 resolution으로 학습을 시킨 뒤, 1.5 epoch 동안 unaugmented labeled images에 대해 큰 resolution으로 fine-tuning을 시키는 방법을 의미합니다. 해당 방법론을 제안한 논문과 유사하게, fine-tuning 동안은 shallow layer를 freeze시켜서 실험을 하였다고 합니다.
Iterative Training
마지막으로, 아까 보여드렸던 그림의 4번인 Iterative training 방식은 반복적으로 새로운 pseudo label을 만들고, 이를 이용하여 Student Model을 학습시키는 것을 의미합니다. 이 과정에서 약간의 트릭이 들어갑니다.
우선 설명에 앞서 트릭에 사용된 3가지 EfficientNet의 모델은 각각 이름이 B7, L0, L1, L2 이며 뒤로 갈수록 모델의 size가 커지는 것을 의미하며, 각각 모델에 대한 Architecture Detail은 아래 그림에서 확인하실 수 있습니다.
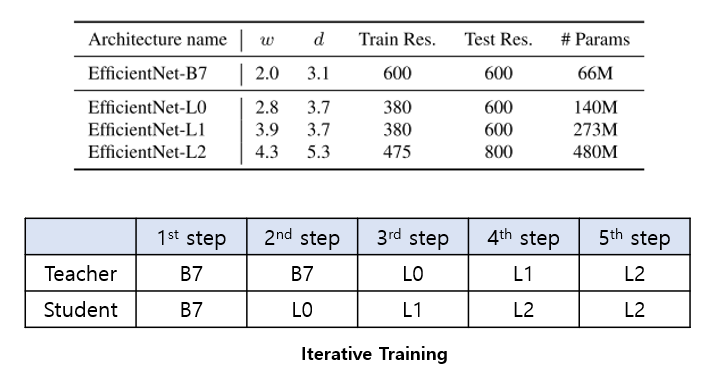
처음에는 Teacher와 Student 모두 EfficientNet-B7 로 학습을 진행합니다. 그 뒤, Teacher는 EfficientNet-B7, Student는 EfficientNet-L0로 학습을 진행합니다. 그 뒤 Teacher는 EfficientNet-L0, Student는 EfficientNet-L1으로 학습을 진행합니다. 그 뒤 Teacher는 EfficientNet-L1, Student는 EfficientNet-L2로 학습을 진행합니다. 마지막으로 Teacher는 EfficientNet-L2, Student는 EfficientNet-L2로 학습을 진행합니다. 이 과정은 위의 그림의 표에서도 확인하실 수 있습니다.
실험 결과
이번 단락에서는 본 논문에서 제시하고 있는 실험 결과들을 설명드릴 예정입니다. Appendix에도 여러 실험 결과들이 있지만 그 결과들은 제외하고 본문에 있는 결과 위주로 설명을 드리겠습니다.
ImageNet 실험 결과
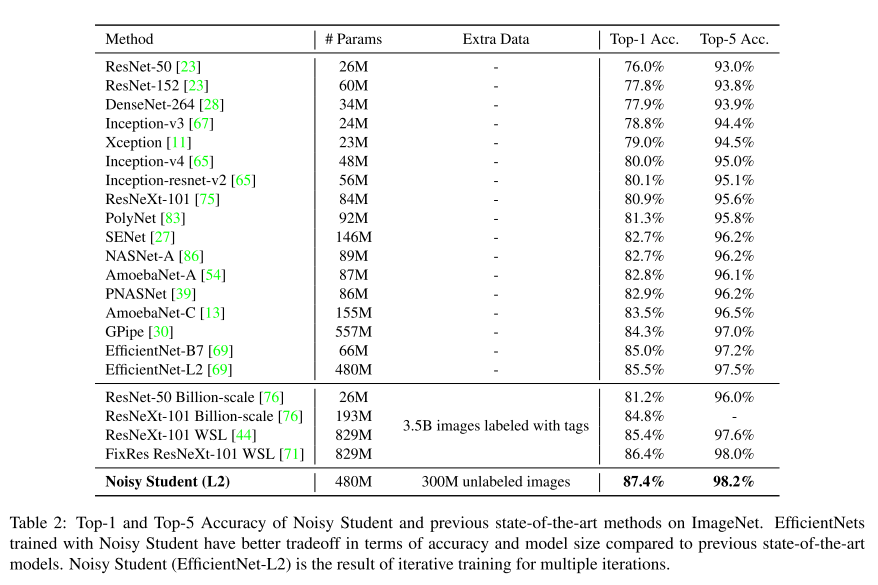
ImageNet 실험 결과는 위의 표에서 확인하실 수 있으며, ImageNet 데이터셋에 대해 다른 선행 연구들을 모두 제치고 가장 높은 Top-1, Top-5 Accuracy를 달성을 하였습니다. 또한 가장 좋은 성능을 보였던 Noisy Student (L2) 은 기존 SOTA 성능을 달성했던 모델들보다 적은 수의 Parameter를 보유하고 있고, 학습에 사용한 Extra Data의 크기도 더 적고, Label도 사용하지 않고 달성한 결과라 더 의미가 있다고 볼 수 있습니다.
이 외에도, 글의 맨 처음 부분에 보여드린 첫번째 그림의 결과는 Iterative Training을 하지 않고, EfficientNet-B0 부터 EfficientNet-B7 까지 Noisy Student 알고리즘으로 학습을 시켰을 때의 결과를 보여주고 있으며, 제안하고 있는 알고리즘이 모든 경우에서 효과적임을 보여주고 있습니다.
Robustness 실험 결과
다음 소개드릴 결과는 올해 Dan Hendrycks 라는 제가 좋아하는 연구자가 모델의 신빙성, Robustness 측정을 위해 제안한 벤치마크 test set인 ImageNet-C, ImageNet-P, ImageNet-A 을 이용한 실험 결과입니다.

ImageNet-C, ImageNet-P 데이터셋은 “Benchmarking Neural Network Robustness to Common Corruptions and Perturbations, 2019 ICLR” 논문에서 제안이 되었고 이미지에 blurring, fogging, rotation, scaling 등 흔히 발생할 수 있는 Corruption 과 Perturbation 들을 적용시켜서 만든 데이터셋입니다.
ImageNet-A 데이터셋은 “Natural Adversarial Examples, 2019 arXiv” 에서 제안이 되었으며 기존 Classification network들이 공통적으로 어려워하는 실제 Natural Image들을 모아서 만든 데이터셋입니다.

각 데이터셋에 대한 실험 결과는 위의 그림에서 확인하실 수 있습니다. 우선 ImageNet-C의 평가에 사용된 mCE 지표와 ImageNet-P의 평가에 사용된 mFR 지표는 낮을수록 좋은 값을 의미하며, 본 논문에서 제안하고 있는 방식이 기존 모델들 대비 좋은 성능을 보여주고 있음을 확인할 수 있습니다.
또한 ImageNet-A 데이터셋에서는 굉장히 높은 정확도를 보여주고 있습니다. Noisy Student 방식처럼 외부의 데이터셋을 사용한 ResNeXt-101 WSL 모델은 ImageNet-A 에 취약한 모습을 보이지만 Noisy Student는 굉장히 잘 버티는 점과, EfficientNet-L2도 그럭저럭 잘 버티는 점이 인상깊은 부분이었습니다. 이는 EfficientNet 자체가 Natural Adversarial Example에 꽤 견고한 모델임을 보여주고 있고, 견고한 Baseline에 Noisy Student를 적용하면 훨씬 견고해질 수 있음을 보여주고 있습니다.
저는 실험 결과를 보고 본 논문에서 제안한 Noisy-Student 알고리즘이 robustness에 초점을 맞춘 연구가 아님에도 불구하고 3가지 데이터셋에서 모두 월등한 성능을 달성한 점이 굉장히 인상깊었습니다.
Adversarial Attack 실험 결과
마지막으로 설명드릴 실험 결과는 Adversarial Attack에 얼마나 robust하게 버티는지를 평가한 실험입니다. Adversarial Attack에 많이 사용되는 FGSM 공격을 EfficientNet에 가하였을 때의 성능을 측정하였고, EfficientNet에 Noisy Student 알고리즘을 적용하였을 때의 성능을 측정하여 비교를 하였습니다.
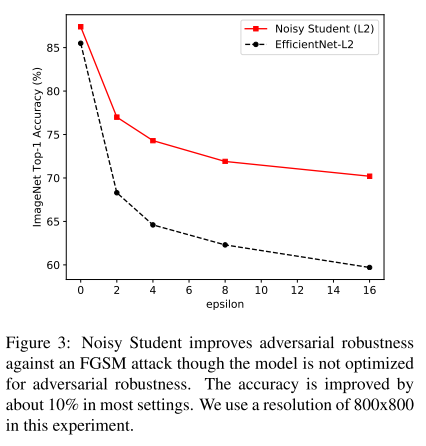
실험 결과는 위의 그림에서 확인하실 수 있으며 EfficientNet과 비교하였을 때 전반적으로 Adversarial Attack에 Robust함을 보여주고 있습니다.
결론
이번 포스팅에서는 작성 시점 기준 3일전 공개된 “Self-training with Noisy Student improves ImageNet classification” 논문에 대한 리뷰를 수행하였습니다. 그동안 주로 Image Classification에 관련된 논문들을 주로 다뤘었는데, 그 중에서도 결과가 가장 인상깊고, 적용한 아이디어가 간단하면서도 성능이 우수해서 신기하면서도 재미있게 리뷰를 했던 것 같습니다. 특히, ImageNet 데이터셋에 Accuracy에 초점을 맞춰서 연구를 했는데, 부가적으로 모델의 Robustness가 매우 증가한 점이 인상 깊었습니다. 2019년이 얼마 남지 않았는데, 올해가 가기 전에 또 한번 SOTA가 갱신이 될지, 내년에는 또 어떤 재미있는 방식들이 제안될지 기대를 하면서 글을 마무리하겠습니다.