EfficientDet : Scalable and Efficient Object Detection Review
안녕하세요, 이번 포스팅에서는 이틀 전 11월 20일에 공개된 논문인 “EfficientDet: Scalable and Efficient Object Detection” 논문에 대한 리뷰를 수행하려 합니다.
이 논문은 제가 지난번에 리뷰했던 “EfficientNet: Improving Accuracy and Efficiency through AutoML and Model Scaling” 의 저자들이 속한 Google Brain 팀에서 쓴 논문이며, EfficientNet이 Image Classification 문제를 타겟으로 논문을 작성하였다면, 이번 EfficientDet은 제목에서 알 수 있듯이 Object Detection 문제를 타겟으로 논문을 작성하였습니다.
EfficientNet의 내용과 겹치는 내용이 많기 때문에 원활한 이해를 위해서는 EfficientNet 리뷰 포스팅을 먼저 보고 오시는 것을 권장드립니다.
마찬가지로, 논문을 소개 드리기 앞서 이 논문의 결과를 먼저 보여드리고 시작을 하도록 하겠습니다.
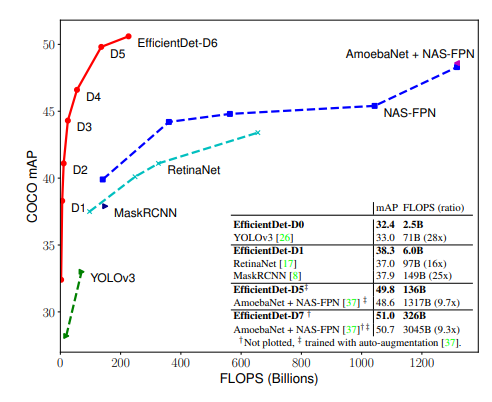
Object Detection을 주제로 한 논문이 굉장히 많이 나왔는데, AutoML을 이용하여 찾은 Feature Pyramid Network 구조와, AutoML로 찾은 굉장히 큰 Backbone Architecture인 AmoebaNet을 섞어서 사용한 것이 COCO 데이터셋에서 가장 좋은 성능을 보이고 있었습니다. 이러한 모든 모델들의 성능을 크게 상회하는, 특히 연산량, 연산 속도 관점에서는 굉장히 효율적인 모델을 제안을 하였다는 점이 인상깊었습니다. 이제 어떻게 이러한 좋은 성능을 달성할 수 있었는지 설명 드리도록 하겠습니다.
Main Challenge and Solution
Speed와 Accuracy는 Trade-Off 관계를 가지기 때문에 높은 정확도와 좋은 효율을 동시에 잡기는 굉장히 어려운 일입니다. 이러한 두마리 토끼를 잡기 위해선 모델을 굉장히 잘 설계하여야 합니다. 본 논문에서는 Object Detection에서 이러한 모델을 설계하기 위해 고려하여야 할 점 중 크게 2가지를 Challenge로 삼았습니다.
Challenge 1. Efficient multi-scale feature fusion
Feature Pyramid Network(FPN)는 2017년 공개된 이후 대부분의 Object Detection 연구에서 사용되고 있습니다. One-Stage Detector의 대표격인 모델인 RetinaNet, M2Det, AutoML의 Neural Architecture Search를 FPN 구조에 적용한 NAS-FPN 등 FPN을 적용하고, 성능을 개선하고자 하는 연구들이 많이 진행이 되어왔습니다. 하지만 선행 연구들은 모두 서로 다른 input feature들을 합칠 때 구분없이 단순히 더하는 방식을 사용하고 있음을 지적하였습니다.
서로 다른 input feature들은 해상도가 다르기 때문에 output feature에 기여하는 정도를 다르게 가져가야 함을 주장하며, (단순히 더하면 같은 weight로 기여하게 됨) 간단하지만 효과적인 weighted bi-directional FPN(BiFPN) 구조를 제안하였습니다. 이 구조를 사용하면 서로 다른 input feature들의 중요성을 학습을 통해 배울 수 있으며, 이를 통해 성능을 많이 향상시킬 수 있었습니다. 자세한 구조는 아래에서 다루도록 하겠습니다.
Challenge 2. Model scaling
EfficientNet에서 제안한 Compound Scaling 기법은 모델의 크기와 연산량를 결정하는 요소들(input resolution, depth, width)을 동시에 고려하여 증가시키는 방법을 의미하며, 이 방법을 통해 높은 성능을 달성할 수 있었습니다. 이러한 아이디어를 Object Detection에도 적용을 할 수 있으며, backbone, feature network, box/class prediction network 등 모든 곳에 적용을 하였습니다.
Main Contribution
즉 이 논문에서 제안하는 핵심 내용은 크게 2가지이며, BiFPN과 Model Scaling을 적용하여서 COCO 데이터셋에서 가장 높은 정확도를 달성하였고, 기존 연구들 대비 매우 적은 연산량(FLOPS)으로 비슷한 정확도를 달성할 수 있음을 보여주고 있습니다. 본 논문의 Contribution을 정리하면 다음과 같습니다.
- Weighted bidirectional feature network (BiFPN)을 제안하였다.
- Object Detection에도 Compound Scaling을 적용하는 방법을 제안하였다.
- BiFPN과 Compound Scaling을 접목하여 좋은 성능을 보이는 EfficientDet 구조를 제안하였다.
이제 각 핵심 내용들을 자세히 설명드리도록 하겠습니다.
BiFPN
Cross-Scale Connections
Feature Pyramid Network를 이용한 방법들을 모아둔 그림은 다음과 같습니다.
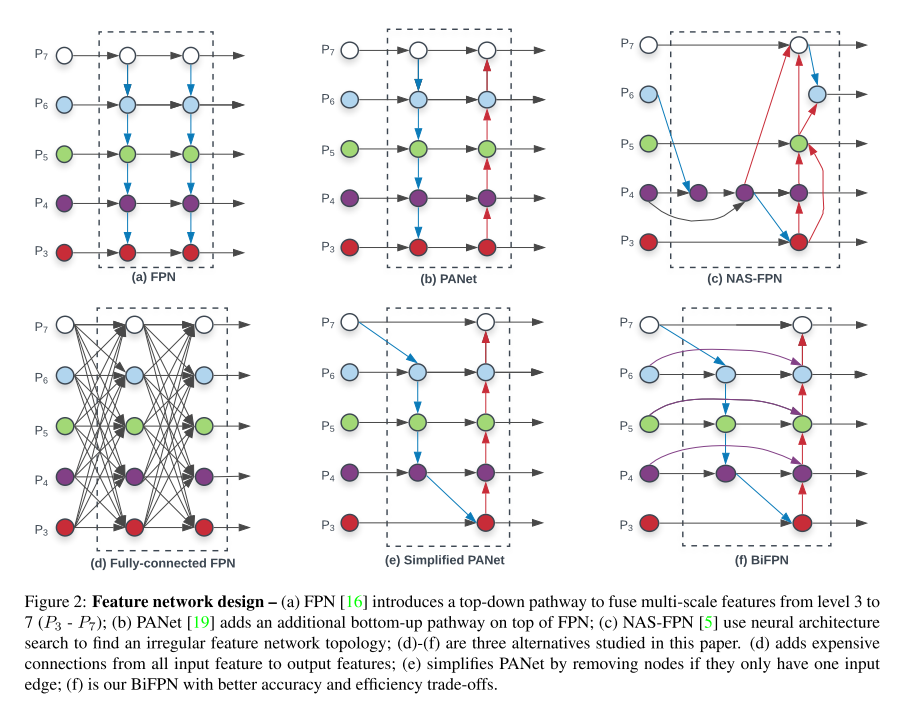
여기에서 (a) 방식이 전통적인 FPN 구조를 의미하고, (b) PANet은 추가로 bottom-up pathway를 FPN에 추가하는 방법을 제안하였습니다.
(c)는 AutoML의 Neural Architecture Search를 FPN 구조에 적용하였고, 불규칙적인 FPN 구조를 보이는 것이 특징입니다. 또한 (a)와 (b) 구조는 같은 scale에서만 connection이 존재하지만, (c) 구조부터는 scale이 다른 경우에도 connection이 존재하는 Cross-Scale Connection 을 적용하고 있습니다.
(d)와 (e)는 본 논문에서 추가로 제안하고 실험을 한 방식이고, 마지막 (f) 방식이 본 논문에서 제안하고 있는 BiFPN 구조를 의미합니다.
(e) Simplified PANet 방식은 PANet에서 input edge가 1개인 node들은 기여도가 적을 것이라 생각하며 제거를 하여 얻은 Network 구조를 의미하고, 여기에 (f) 그림의 보라색 선처럼 같은 scale에서 edge를 추가하여 더 많은 feature들이 fusion되도록 구성을 한 방식이 BiFPN입니다. 또한 PANet은 top-down과 bottom-up path를 하나만 사용한 반면, 본 논문에서는 이러한 구조를 여러 번 반복하여 사용을 하였습니다. 이를 통해 더 high-level한 feature fusion을 할 수 있음을 주장하고 있습니다.

BiFPN의 성능 향상을 살펴보기 위해 2가지 ablation study를 하였습니다. Table 3에서 저자는 같은 backbone인 EfficientNet-B3에서 FPN을 BiFPN으로 바꿨을 때의 성능을 측정하였고, mAP는 약 4.1 증가하였고 parameter 수와 FLOPS도 적게 사용하고 있음을 보여주고 있습니다. Table 4에서는 위에서 보여드렸던 여러 Feature Network 방식들에 따라 성능이 어떻게 바뀌는지를 분석한 결과이며 BiFPN을 사용하였을 때 가장 좋은 성능을 보임을 확인할 수 있습니다.
Weighted Feature Fusion
FPN에서 서로 다른 resolution의 input feature들을 합칠 때, 일반적으로는 같은 해상도가 되도록 resize를 시킨 뒤 합치는 방식을 사용합니다. 하지만 앞에서 말씀드렸듯이 모든 input feature들을 동등하게 처리를 하고 있는 점을 문제점으로 인식하고, 본 논문에서는 이 점을 개선하기 위해 각 input feature에 가중치를 주고, 학습을 통해 가중치를 배울 수 있는 방식을 제안하였습니다. 총 3가지 방식을 제안하고 있으며 각 방식을 하나의 그림으로 정리하면 다음과 같습니다.
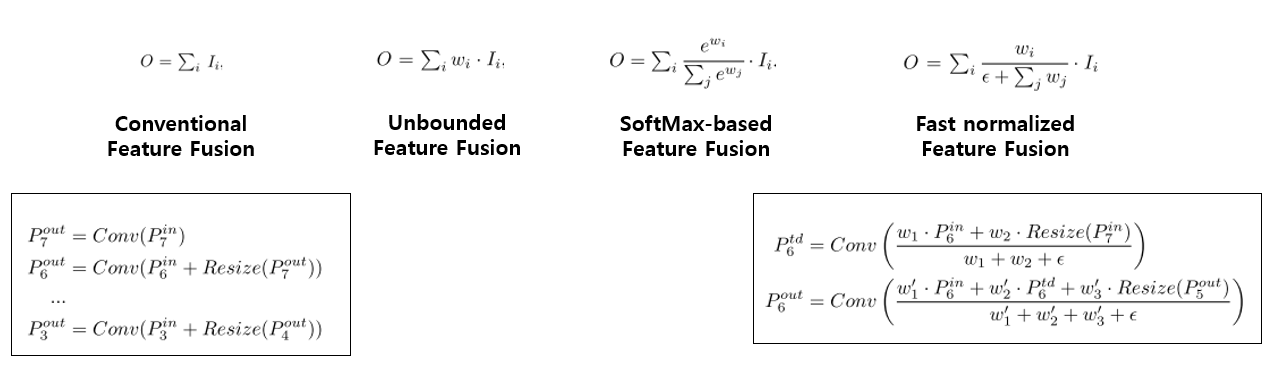
우선 weight는 scalar (per-feature)로 줄 수 있고, vector (per-channel)로 줄 수 있고 multi-dimensional tensor (per-pixel)로 줄 수 있는데, 본 논문에서는 scalar를 사용하는 것이 정확도와 연산량 측면에서 효율적임을 실험을 통해 밝혔고, scalar weight를 사용하였습니다.
Unbounded fusion은 말 그대로 unbounded 되어있기 때문에 학습에 불안정성을 유발할 수 있습니다. 그래서 weight normalization을 사용하였다고 합니다.
SoftMax-based fusion은 저희가 익히 알고 있는 SoftMax를 사용한 것이지만, 이는 GPU 하드웨어에서 slowdown을 유발함을 실험을 통해 보여주고 있습니다.
그래서 본 논문은 Fast normalized fusion 방식을 제안하였습니다. 우선 weight들은 ReLU를 거치기 때문에 non-zero임이 보장이 되고, 분모가 0이 되는 것을 막기 위해 0.0001 크기의 입실론을 넣어주었습니다. Weight 값이 0~1사이로 normalize가 되는 것은 SoftMax와 유사하며 ablation study를 통해 SoftMax-based fusion 방식보다 좋은 성능을 보임을 보여주고 있습니다.
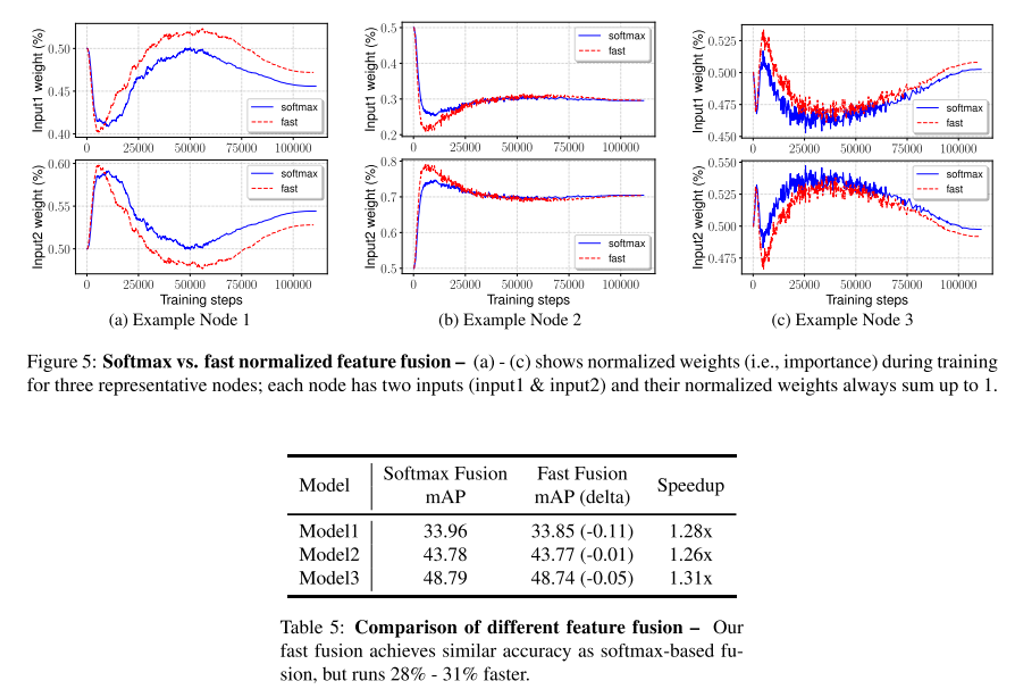
위의 표 5는 SoftMax fusion과 Fast Fusion을 비교한 결과이며, Fast Fusion을 사용하면 약간의 mAP 하락은 있지만 약 30%의 속도 향상을 달성할 수 있습니다. 또한 그림 5를 보시면, input 1과 input 2의 weight를 training step에 따라 plot한 결과인데, 학습을 거치면서 weight가 빠르게 변하는 것을 보여주고 있고, 이는 각 feature들이 동등하지 않게 output feature에 기여를 하고 있음을 보여주고 있으며, Fast fusion을 사용하여도 SoftMax fusion과 양상이 비슷함을 보여주고 있습니다.
EfficientDet
위에서 설명드린 BiFPN을 기반으로 EfficientDet 이라는 One-Stage Detector 구조를 제안하였습니다.
EfficientDet Architecture
EfficientDet의 backbone으로는 ImageNet-pretrained EfficientNet을 사용하였습니다. BiFPN을 Feature Network로 사용하였고, level 3-7 feature에 적용을 하였습니다. 또한 top-down, bottom-up bidirectional feature fusion을 반복적으로 사용하였습니다.
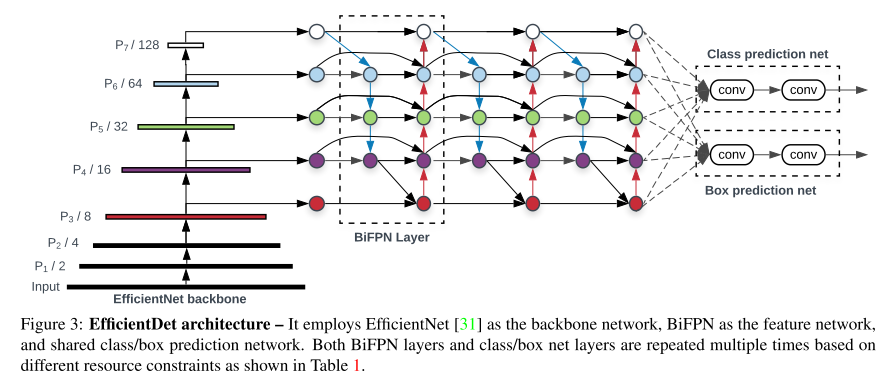
EfficientDet Architecture는 위의 그림과 같습니다. 별다른 특이점이 없어서 그림만 봐도 쉽게 이해하실 수 있습니다.
Compound Scaling
Backbone network에는 EfficientNet-B0 부터 B6까지 사용을 하였으며 마찬가지로 ImageNet-pretrained network를 가져와서 사용을 하였습니다. 실험에 사용한 Compound Scaling configuration은 아래 그림에서 확인하실 수 있습니다.
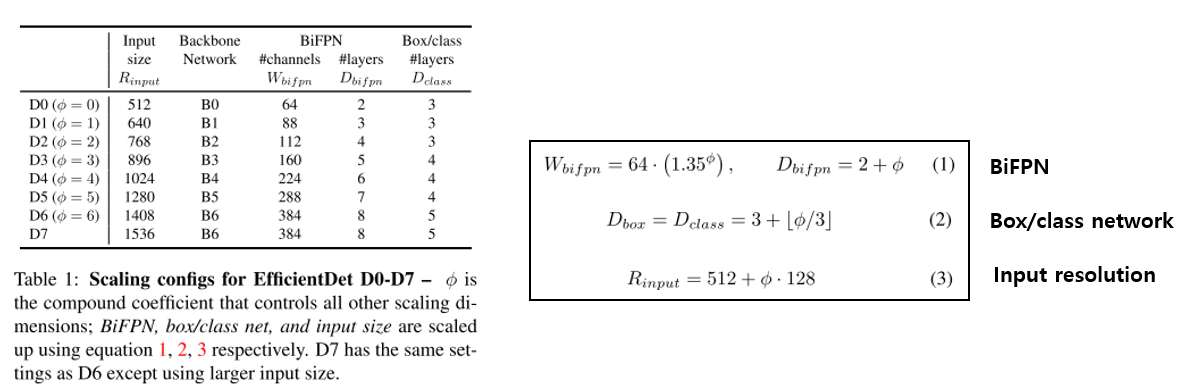
저희가 알던 Compound Scaling처럼 input의 resolution과 backbone network의 크기를 늘려주었고, BiFPN과 Box/class network 도 동시에 키워주는 것을 확인하실 수 있습니다. 각 network마다 어떻게 키워줬는지는 위의 그림의 (1) ~ (3)에서 확인하실 수 있습니다.
실험 결과
이제 위에서 설명 드린 EfficientDet 구조가 기존 논문들의 방식 대비 얼마나 성능이 좋은지를 보여드릴 차례입니다. 사실 맨 처음 이미 결과를 보여드려서 다들 예상을 하고 계실 것이라 생각합니다.
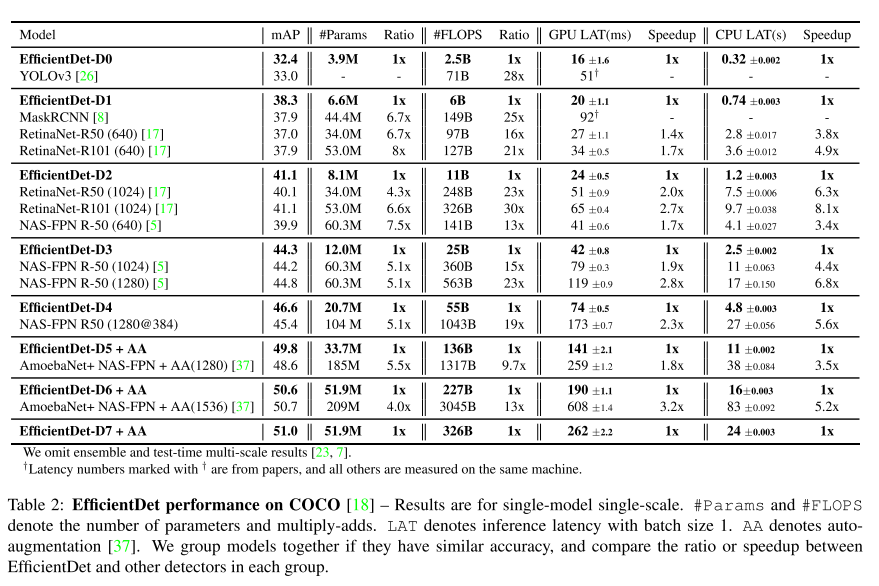
역시나 COCO 데이터셋에서 가장 높은 mAP를 달성하여, 2019년 11월 기준 State-of-the-art(SOTA) 성능을 보이고 있으며, 기존 방식들 대비 연산 효율이 압도적으로 좋음을 확인할 수 있습니다.
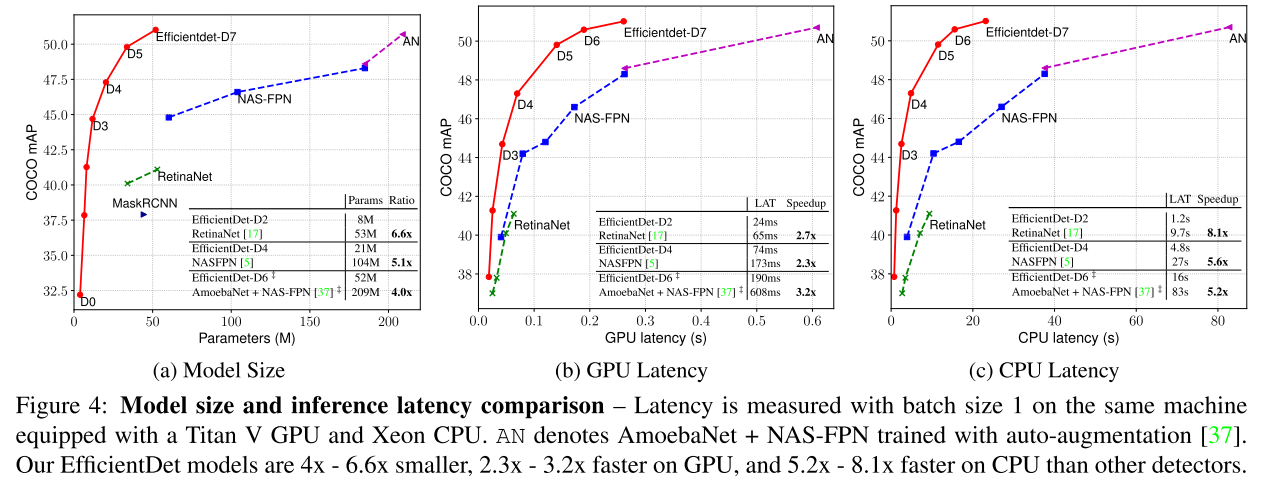
모델의 크기, 즉 parameter 수와, Inference Latency를 GPU와 CPU에서 측정한 실험 결과도 이 논문의 위력을 잘 보여주고 있습니다. 단순히 FLOPS가 적다고 해서 항상 Inference Latency가 적다는 보장이 없기 때문에 실제 Inference Latency를 보여주고 있고, 이러한 결과는 참 유용한 것 같습니다. 그림을 보시면 아시겠지만 정확도도 높고, 모델 크기도 작고, Latency도 낮아서 빠르게 동작할 수 있음을 보여주고 있습니다. 논문에서는 정확히 어떤 셋팅에서 학습을 시켰는지에 대한 자세한 내용도 확인하실 수 있습니다.
결론
이번 포스팅에서는 이틀 전 11월 20일에 공개된 논문인 “EfficientDet: Scalable and Efficient Object Detection” 에 대해 자세히 리뷰를 해보았습니다. Object Detection도 굉장히 다양한 논문들이 2018년을 기점으로 쏟아져 나왔었는데 단숨에 서열을 정리해버린 점도 인상깊었고, 성능도 성능이지만 Latency 관점에서도 너무 효율적이라 COCO 데이터셋같이 연구용 데이터셋 뿐만 아니라, 실제 데이터셋, 실제 제품, 실제 application에서도 충분히 적용해봄직한 논문이라고 생각이 들었습니다. Object Detection에도 EfficientNet을 적용하였으니, 조만간 Semantic Segmentation, Instance Segmentation에도 EfficientNet을 적용한 EfficientSeg? 같은 논문이 나오지 않을까 예상해보면서 글을 마무리짓겠습니다. 감사합니다!