Improved Regularization of Convolutional Neural Networks with Cutout 리뷰
안녕하세요, 이번 포스팅에서는 이전 글에 이어서 데이터 증강 기법과 관련된 최신 논문에서 사용된 Cutout 기법을 소개 드리려고 합니다. 지난 포스팅에서 다뤘던 Shake-Shake Regularization 기법은 입력 이미지 단계에서의 증강이 아닌, 학습 단계에서 feature map, gradient 단계에서 증강을 하였는데요, 이번에 소개드릴 Cutout 기법은 입력 이미지 단계에서 간단하면서도 참신한 증강 기법을 제안하였습니다. 이번에는 지난 포스팅처럼 긴 코드가 아닌 간단한 구현 코드와 함께 설명을 드릴 예정입니다. 혹시 글이나 코드를 보시다가 잘 이해가 되지 않는 부분은 편하게 댓글에 질문을 주시면 답변 드리겠습니다.
- 다음과 같은 사항을 알고 계시면 더 이해하기 쉽습니다.
- 딥러닝에 대한 전반적인 이해
- Python 언어 및 Tensorflow 프레임워크에 대한 이해
- 이번 포스팅에서 구현한 Cutout의 경우 Image Classification 성능을 측정하였으며, 실제 논문에서 사용한 프레임워크(torch)와 다른 프레임워크를 사용하였기 때문에 완벽한 재현이 되지 않을 가능성이 있습니다
- 이번 포스팅에서도 지난 Classification 구현체의 포스팅의 구조를 사용하였으며 데이터셋은 수아랩의 블로그의 “이미지 Classification 문제와 딥러닝: AlexNet으로 개vs고양이 분류하기” 에서 사용한 개, 고양이 데이터셋을 사용하여 성능을 측정하였습니다.
- 따로 코드를 저장소에 올려 두진 않았으나 본문에 Cutout 코드가 있으니 해당 코드를 사용하시면 됩니다.
논문 소개 (Cutout regularization)
이번 포스팅에서 소개드릴 “Improved Regularization of Convolutional Neural Networks with Cutout” 논문은 지난 포스팅 의 서론에서 다뤘던 Data augmentation 기법에서 소개 드린 입력 이미지 단계의 증강 기법과 관련이 있습니다. 논문에서 예시로 들고 있는 이 그림이 논문의 아이디어를 한눈에 보여주고 있습니다.

그동안 주로 사용되어왔던 입력 이미지 단계에서의 증강 기법은 회전, 반전, 자르기 등의 간단한 방법 변환 외에 Color jittering, noise 주입 등 이미지에 변화를 주지만 원본 이미지와 유사한 형태를 유지하는 특징이 있었습니다. 즉 noise를 주입하거나 반전을 시켜도 사람이 보기에는 원본 이미지와 유사하게 보이도록 증강을 시켰습니다.
하지만 Cutout은 사람이 보기에도 원본 이미지와 차이를 크게 느낄 수 있는 방법을 사용하였습니다. 위에 그림에서 볼 수 있듯이 원본 이미지에 박스 모양, 혹은 다른 도형의 모양 영역을 정하고, 그 영역을 0으로 채워 넣는 방식을 사용하였습니다.
이 논문을 읽으시고 예상되는 반응은 “저게 다야?”, “저렇게 하면 잘 된다고?” 와 같이 정말 간단한 기법이 성능을 향상시키는 것에 대해 놀라움을 금치 못하실 것입니다. 마찬가지로 이러한 방법이 제안된 배경을 이해하기 위해선 선행 연구들을 살펴보면 도움이 될 수 있습니다.
선행 연구
우선, 입력 이미지를 가리는 행위를 Occlusion이라 부르는데 이러한 방식은 2011년 “Deep Learners Benefit More from Out-of-Distribution Examples 논문” 에서 제안이 되었습니다. 해당 방식은 스크래치, 점, 갈겨쓴 모양 등을 이미지에 합성시켜 이미지를 가리는 방식을 사용했고, Cutout은 이미지를 가림과 동시에 해당 영역을 0으로 채워 넣는 방식이 추가된 점이 주요 차이점입니다. 0으로 채워 넣는 방식을 떠올려보면 기존에 CNN에서 흔하게 적용되어 오던 Regularization 기법 하나가 떠오를 것입니다. 무엇일까요?
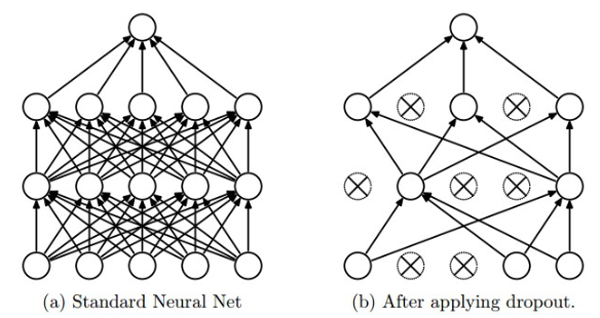
맞습니다. 바로 Dropout입니다. Dropout은 학습 단계에서 Network의 hidden unit activation을 일정 확률로 0으로 바꾸는 방식입니다. 이 방식이 제안되고 나서 굉장히 좋은 regularization 효과를 얻을 수 있었고 굉장히 많이 사용되어왔습니다.
하지만 Dropout은 Fully-connected layer에서는 좋은 효과를 보이지만 Convolutional layer에서는 그만큼 강력한 효과를 얻지는 못했습니다.
그 이유로는 첫째론 Convolutional layer는 fully-connected layer에 비해 파라미터 개수가 훨씬 적다는 점을 들 수 있습니다.
둘째론 Convolutional layer에서는 입력을 Fully-connected layer처럼 1-dimention으로 펼치지 않고 그대로 사용하기 때문에 인접한 픽셀일수록 비슷한 정보를 많이 공유하여 일부 픽셀이 0으로 바뀌어도 주변 픽셀들로 인해 해당 정보가 전달이 될 수 있으므로 Dropout 효과를 크게 얻기 힘들다는 점을 들 수 있습니다.
이를 개선하기 위해 SpatialDropout, probabilistic weighted pooling, max-drop 등 많은 연구가 진행되었습니다.
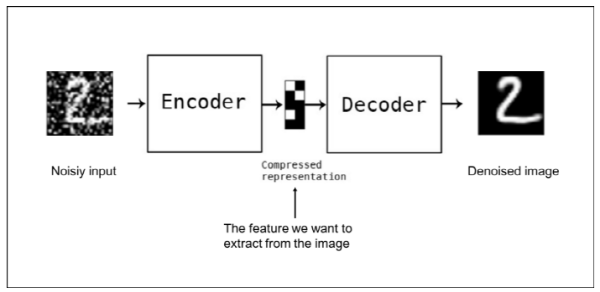
또한 마지막 선행연구로는 Denoising Auto-encoder와 Context Encoder를 설명하고 있습니다.
두 encoder는 모두 입력 이미지를 손상시킨 뒤 auto-encoder를 통해 복원을 해내는 역할을 수행합니다. Denoising auto-encoder는 입력 이미지에 random bernoulli noise를 주입하여 사용하고, Context encoder는 일부 영역을 지워서 사용합니다.
Context encoder의 방식이 Cutout과 유사한 접근으로 이해할 수 있습니다. Context encoder는 지워진 영역을 복원하기 위해 주변 영역의 context를 넓게 이해하도록 학습이 되고 그로 인해 denoising auto-encoder에 비해 high-level feature를 학습한다고 알려져 있습니다.
이미지의 일부 영역을 지우는 방식은 Cutout과 비슷하지만 context encoder는 unsupervised learning model이고, supervised learning model에는 적용된 바가 없다고 서술하고 있습니다.
선행 연구와의 차이점
앞서 소개 드린 3가지 선행 연구와 Cutout은 비슷하면서도 약간의 차이가 있었습니다. 다시 정리하면 Occlusion에서는 이미지를 가리는 것은 같으나 0으로 채우는 방식이 추가가 되었습니다.
Dropout에서는 feature map이 아닌 입력에서 0으로 채우는 방식에서 차이가 있었습니다.
Dropout은 중간 단계의 layer의 feature map에서만 random하게 일부 영역을 지우고 각 feature map의 channel간 독립성이 존재하여 어떤 channel에서는 지워진 영역이 다른 channel에서는 지워지지 않게 되어 불일치성이 일부 존재하게 됩니다. 하지만 Cutout은 입력 단계에서 일부 영역을 지우고 그 결과 중간 단계의 layer에서도 같은 영역 주위를 지우는 것과 같은 효과를 볼 수 있으며 각 feature map의 channel간에도 상관 관계를 갖게 됩니다.
Context encoder에서는 이미지의 일부 영역을 지우는 것은 동일했으나 타겟 learning model에서 차이가 있었습니다.
이러한 차이점들을 종합하면 어떠한 배경에서 Cutout이라는 기법이 시작되었는지 이해가 조금은 될 수 있을 것 같습니다.
구현 방법에 대한 소개

Cutout의 초기 버전은 위의 그림처럼 max-drop과 유사하게 activated feature에서 가장 큰 값을 가지는 영역부분을 0으로 만드는 방식을 사용했습니다. 하지만 임의의 영역을 0으로 만들어도 성능이 큰 차이가 없어서 간단한 구현을 위해 고정된 크기의 영역을 지우는 방식으로 수정을 하였다고 합니다.
Cutout의 영역을 정할 때 어떤 모양의 도형을 사용할 것인지와 도형의 크기를 어떻게 정할 지를 정해야 하는데, 실험적으로 분석한 결과 어떤 모양을 사용하냐 보다는 어떤 크기를 사용할 지가 성능에 더 큰 영향을 줬다고 합니다. 즉 원을 사용하던 네모를 사용하던 이미지의 얼만큼의 영역을 0으로 바꾸는 지가 더 중요합니다. 본 논문에서는 정사각형 모양을 default로 사용하였습니다.
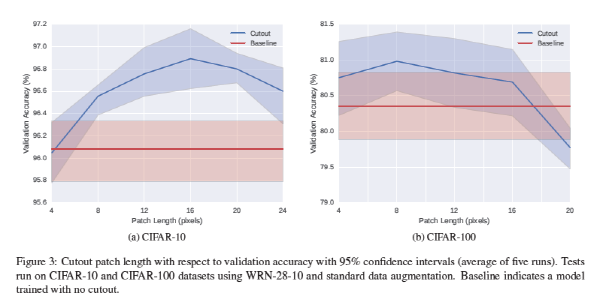
여기서 짚고 넘어가야할 점은 Cutout으로 사용할 정사각형의 크기는 실험적으로 정해야 한다는 점입니다. 위의 그림은 CIFAR-10, CIFAR-100 데이터셋에 대해 정사각형의 cutout을 적용하였을 때, 정사각형의 길이에 따른 Validation accuracy를 비교하고 있습니다. 각 데이터셋마다 최적의 정사각형의 길이가 다르고, 이는 새로운 데이터셋에 대해서는 일일이 정사각형의 크기를 조절해가며 최적의 성능을 내는 크기를 찾아야함을 의미합니다. 어떻게 보면 최적의 정사각형 크기를 실험을 하지 않고 찾는다는 것은 당연히 어려운 이야기지만 약간의 아쉬움이 남는 부분입니다.
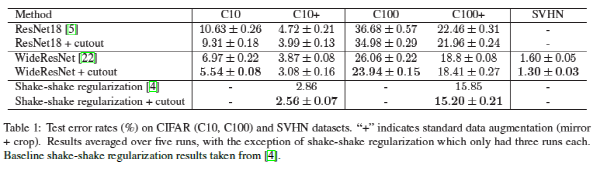
무튼, 최적의 정사각형 크기를 적용하였을 때의 실험 결과는 위의 표에 나와있습니다. 단순한 방법을 추가했을 뿐인데 많게는 2% 포인트 이상의 성능 향상이 있었고, 지난 포스팅에서 다루었던 shake-shake regularization에도 cutout을 적용하면 눈에 띄는 성능 향상이 있었습니다. 굉장히 간단한 방식이지만 성능 향상이 꽤 큰 것을 보면 정말 신기하다고 생각됩니다.
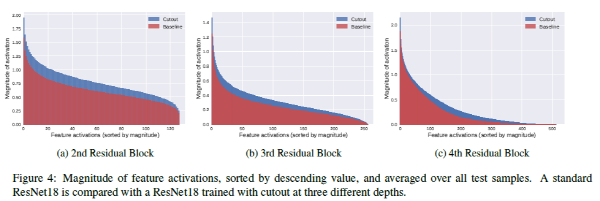
논문의 마지막에는 Cutout의 activation에서의 효과를 짧게 분석을 하였습니다. 위의 그림과 함께 내용을 간단하게 요약하면 cutout을 사용한 경우, 그렇지 않은 경우보다 activation의 크기들이 전체적으로 커지는 효과가 있었고 이는 network로 하여금 더 많은 feature들을 사용하여 prediction을 하는 것으로 보인다는 관찰 결과를 서술하고 있습니다.
여기까지가 논문에 대한 소개였습니다. 요약하자면 Cutout이라는 방식을 제안하게 된 배경을 소개하고 구현 방법에 대한 소개와 실험 결과를 제시하고 있습니다. 비교적 쉬운 내용으로 구성 되어있어 논문을 쉽게 따라오실 수 있을 것이라 생각합니다.
이 방식을 다른 데이터셋에 적용했을 때 성능이 잘 나오는지가 가장 궁금했는데요, 그래서 간단한 실험을 진행하였습니다. 수아랩 블로그의 포스팅에서 사용한 환경에 단지 Cutout 방식만을 적용하였을 때 성능 변화를 측정하여 실험 결과를 정리하였습니다.
본론 (실험 셋팅 + 실험 결과)
이전 포스팅에서는 본론에 코드와 그에 대한 설명으로 인해 굉장히 글이 길었는데, 이번 포스팅에서는 기존 코드에 간단하게 Cutout 코드만 추가하였으므로 Cutout과 관련된 코드만 소개 드리고 나머지 부분은 따로 서술하지 않았습니다.
- 데이터셋: The Asirra dataset
- 성능 평가: 정확도
- 러닝 모델: AlexNet
- 러닝 알고리즘: SGD + Momentum
- 학습 수행 및 테스트: 기존 방식과 모두 동일
Cutout numpy implementation code
def cutout(images, cut_length):
"""
Perform cutout augmentation from images.
:param images: np.ndarray, shape: (N, H, W, C).
:param cut_length: int, the length of cut(box).
:return: np.ndarray, shape: (N, h, w, C).
"""
H, W, C = images.shape[1:4]
augmented_images = []
for image in images: # image.shape: (H, W, C)
image_mean = image.mean(keepdims=True)
image -= image_mean
mask = np.ones((H, W, C), np.float32)
y = np.random.randint(H)
x = np.random.randint(W)
length = cut_length
y1 = np.clip(y - (length // 2), 0, H)
y2 = np.clip(y + (length // 2), 0, H)
x1 = np.clip(x - (length // 2), 0, W)
x2 = np.clip(x + (length // 2), 0, W)
mask[y1: y2, x1: x2] = 0.
image = image * mask
image += image_mean
augmented_images.append(image)
return np.stack(augmented_images) # shape: (N, h, w, C)
Cutout 코드 구현은 Python 라이브러리인 Numpy를 사용하여 구현을 하였습니다. 본 논문과 동일하게 사각형의 mask를 사용하였으며 사각형의 길이는 함수의 인자인 cut_length를 통해 받아옵니다. 그 뒤 입력 이미지에서 임의의 좌표 값을 정해주면 그 좌표를 중심으로 하는 사각형 영역을 0으로 채워주는 방식입니다. 굉장히 구현이 간단하며 쉽게 사용이 가능하리라 판단됩니다.
학습 결과 분석
학습 곡선
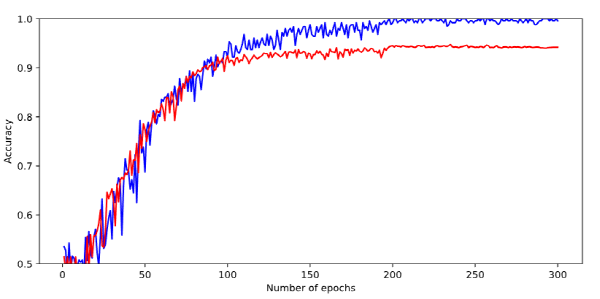
train.py 스크립트를 실행하여 얻은 학습 곡선은 위의 그림과 같습니다. 편의상 매 epoch마다 학습 정확도와 검증 정확도를 얻어서 플롯팅을 하였습니다. 파란 선이 학습 정확도를, 빨간 선이 검증 정확도를 의미하며 학습 정확도는 학습이 진행됨에 따라 100%에 가까워지는 반면, 검증 정확도는 약 94% 정도에서 수렴하는 것을 확인할 수 있습니다.
검증 정확도가 가장 높았던 지점에서의 모델 파라미터들을 체크포인트로 저장을 하여 테스트셋에 대해 성능을 평가하였습니다.
테스트 결과
Asirra 데이터셋의 12,500장의 테스트셋에 대해 성능을 평가한 결과 정확도는 0.9410으로 확인되었습니다.
검증 정확도와 거의 유사하게 측정이 되었으며, Cutout을 사용하지 않았을 때의 정확도인 0.9277에 비해 약 1.3% 포인트의 향상이 있었습니다.
단지 Cutout 증강 기법 하나만 바꿨을 뿐인데 꽤 큰 향상이 있었고, 논문에서 제시한 데이터셋이 아닌 다른 데이터셋에서도 성능이 향상될 수 있음을 보여주고 있습니다.
결론
이번 포스팅에서는 최신 데이터 증강 기법인 Cutout regularization에 대해 정리를 하고 코드 구현 및 실험을 진행하였습니다.
굉장히 간단한 아이디어이면서도 강력한 효과를 보이는 것을 확인할 수 있었고, 여러분들이 사용 중인 모델에도 쉽게 적용이 가능할 것으로 보입니다. 또한 데이터 증강의 중요성을 다시 한번 느낄 수 있는 기회였다고 생각합니다.
Reference
- Cutout 논문
- 수아랩 기술 블로그 포스팅
- The Asirra dataset
- Cutout Torch 구현체
- Dropout 그림
- Denoising auto-encoder 그림