Learning From Noisy Large-Scale Datasets With Minimal Supervision 리뷰
안녕하세요, 이번 포스팅에서는 딥러닝에서 학습 모델, 학습 알고리즘만큼 중요한 데이터셋과 관련된 연구를 소개 드리려 합니다. 오늘 리뷰할 논문은 2017년 CVPR(Computer Vision and Pattern Recognition) 학회에 발표된 “Learning From Noisy Large-Scale Datasets With Minimal Supervision” 이라는 논문이며 Supervised Learning에서 이미지만큼 중요한 labeling과 관련된 논문입니다. 혹시 글을 읽으시다가 잘 이해가 되지 않는 부분은 편하게 댓글에 질문을 주시면 답변 드리겠습니다.
Introduction
저희는 하루에도 데이터가 수만 장씩 쏟아지는 빅데이터 시대에 살고 있습니다. 그런데 왜 딥러닝을 연구할 때 아직도 6년 전에 제작된 ImageNet 데이터셋보다 큰 데이터셋을 사용하지 않을까요?
이번 포스팅에서 소개드릴 “Learning From Noisy Large-Scale Datasets With Minimal Supervision” 논문은 위의 질문과 관련이 있습니다.
일반적으로 저희가 사용할 수 있는 CIFAR-10, ImageNet, MNIST 등의 데이터셋은 수많은 시간을 들여 잘 검토하여 만든 데이터셋이기 때문에 Labeling이 정확하게 되어있습니다.
하지만 실제로 수많은 데이터를 취득해서 데이터셋으로 사용하는 경우 일일이 검토하는데 시간과 비용이 많이 소모됩니다. 그렇다고 검토를 하지 않으면 잘못된 label이 존재할 가능성이 매우 높습니다.
이러한 잘못 labeling된 것들을 “noisy label” 혹은 “labeling noise” 라 부르는데, 이들은 학습 모델이 구분할 때 헷갈리게 하여 구분 성능을 저하시킬 수 있습니다.
본 논문에서는 이러한 문제들을 해결하기 위한 방법론을 제안하였습니다.
Google Open Images Dataset
본 논문에서 사용한 데이터셋은 Google의 Open Images 라는 천만 장 이상으로 구성 되어있는 굉장히 큰 데이터셋입니다. 이 데이터셋의 특이한 점은 한 이미지에 여러 class가 존재할 수 있다는 점입니다. 예를 들어 아래 그림과 같이 카프레제 샐러드 이미지가 있으면 이 이미지는 ‘토마토’ 라는 class이기도 하면서 ‘야채’라는 class이기도 합니다.

이렇게 하나의 이미지의 여러 class의 label이 존재하고 이를 분류하는 문제를 “Multi-labeled classification” 문제라 부릅니다. 기존 ImageNet, CIFAR-10 등의 쉽게 접할 수 있는 데이터셋들은 대부분 하나의 이미지가 하나의 class에 해당하는 경우를 주로 다뤘는데, 현실에서 저희가 접할 수 있는 이미지들은 하나의 이미지에 여러 개의 class가 존재하는 경우가 더 자주 있습니다. 그러므로 이제는 multi-labeled image에 대해서도 관심을 가지는 것이 좋을 것 같다고 개인적으로 생각합니다.
다시 데이터셋에 대한 이야기로 돌아오면, 이 데이터셋은 굉장히 많은 수의 multi-labeled image를 제공하고 있으며 총 6,012가지의 class로 구성이 되어있습니다.
또한 일부는 object detection에도 적용이 가능하도록 bounding box도 제공을 하고 있습니다.
최근 kaggle에서는 object detection, visual relationship detection challenge 가 진행 중이고 굉장히 흥미로울 것 같습니다.
본 논문에서는 bounding box는 사용하지 않고 classification을 위한 multi-labeled image를 사용하였습니다.
본 논문에서 사용한 데이터셋의 특징을 정리하면 다음과 같습니다.
- 총 6,012개의 unique class를 갖는 multi-labeled image set
- 학습 9,011,219장, total annotation 79,156,606개, 이미지당 약 8.8개의 annotation
- 테스트 167,056장, total annotation 2,047,758개, 이미지당 약 12.3개의 annotation
- 1/4 (약 4만장)에 대해 사람이 약 27%(약 1만장)의 데이터 cleaning하여 이를 Label Cleaning Network를 위한 training set으로 활용
- 나머지(약 3만장)를 image classification에 대한 test set으로 활용
- 이 외의 데이터는 정답(Ground Truth)이 없으므로 사용하지 않음
앞서 말씀드렸던 것처럼 labeling noise가 얼만큼 존재하는지 확인하기 위해 본 논문에서는 전체 이미지에서 약 4만 장의 이미지를 추출하여 사람이 검토를 한 결과 약 27% 비율로 labeling noise가 존재하는 것을 확인하였습니다. 즉 4장 중에 1장은 labeling이 잘못 되어있다고 할 수 있습니다. 이렇게 검토하여 수정된 약 1만장의 데이터를 label clean을 수행하는 network의 학습에 이용하였고 나머지 데이터(약 3만장)는 성능 평가를 위해 사용하였습니다. 이 외의 약 12만장의 데이터는 정답(Ground Truth)가 없으므로 성능 평가에서 제외하였습니다.
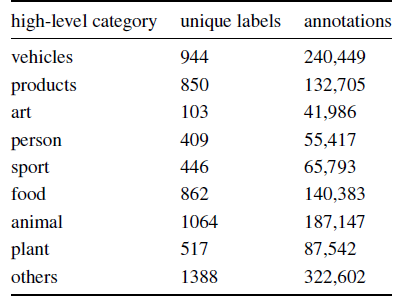
데이터셋의 분포를 분석하면, 6012개의 class를 크게 8가지 종류로 분류를 할 수 있습니다. “animal” class가 1064가지로 가장 많고, “art” class가 103가지로 가장 적으며, “others” class 또한 1388가지로 많습니다.
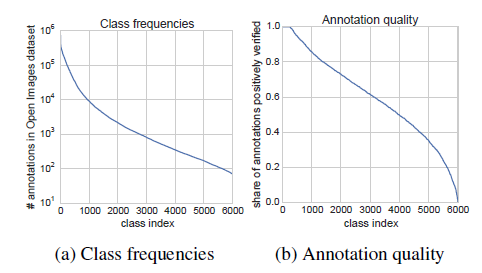
또한 6012개의 class간의 불균형이 존재합니다. 우선 class간 이미지 개수의 불균형이 존재합니다.
‘vehicle’ class의 경우 이미지가 약 90만장이 존재하지만 ‘honda nsx’ class의 경우 70장 밖에 존재하지 않습니다. 대체로 계층적으로 class를 구분하였을 때 high-level에 가까울수록 당연히 이미지의 개수가 많고, 굉장히 low-level의 세부적인 class일수록 이미지의 개수가 적은 분포를 보입니다.
또한 6012개의 class간 annotation 품질 차이가 존재합니다. 어떤 class는 틀린 label이 없는 반면 심한 경우에는 전부 틀린 label만 존재하는 경우도 존재합니다.
선행 연구
Noisy label에 대한 접근법은 크게 3가지로 나뉩니다.
첫번째 방법은 noisy label을 학습에 포함시키고, noisy-robust한 알고리즘을 연구하는 방법이고, 두번째 방법은 noisy label을 찾아내어 학습에서 제외하거나 수정하여 사용하는 방법입니다.
세번째 방법은 적은 수의 noise가 없는 label과 noisy한 label을 학습에 같이 사용하는 semi-supervised learning 방식입니다.
본 논문은 3가지 방법의 특징들을 결합한 방식을 제안하였습니다. 선행 연구들과 비슷한 점도 있지만 약간의 차이가 존재하고 자세한 차이는 논문의 소개가 되어있습니다.
본 포스팅에서는 글이 너무 길어질 것을 염려하여 수 많은 선행연구에 대한 소개는 생략을 하였습니다. 혹시 관심이 있으실 것 같은 분들을 위해 논문과 링크를 공유하도록 하겠습니다.
- Noise-robust Algorithm
- Label Cleaning Method
- Semi-Supervised Learning(SSL) Method
구현 방법
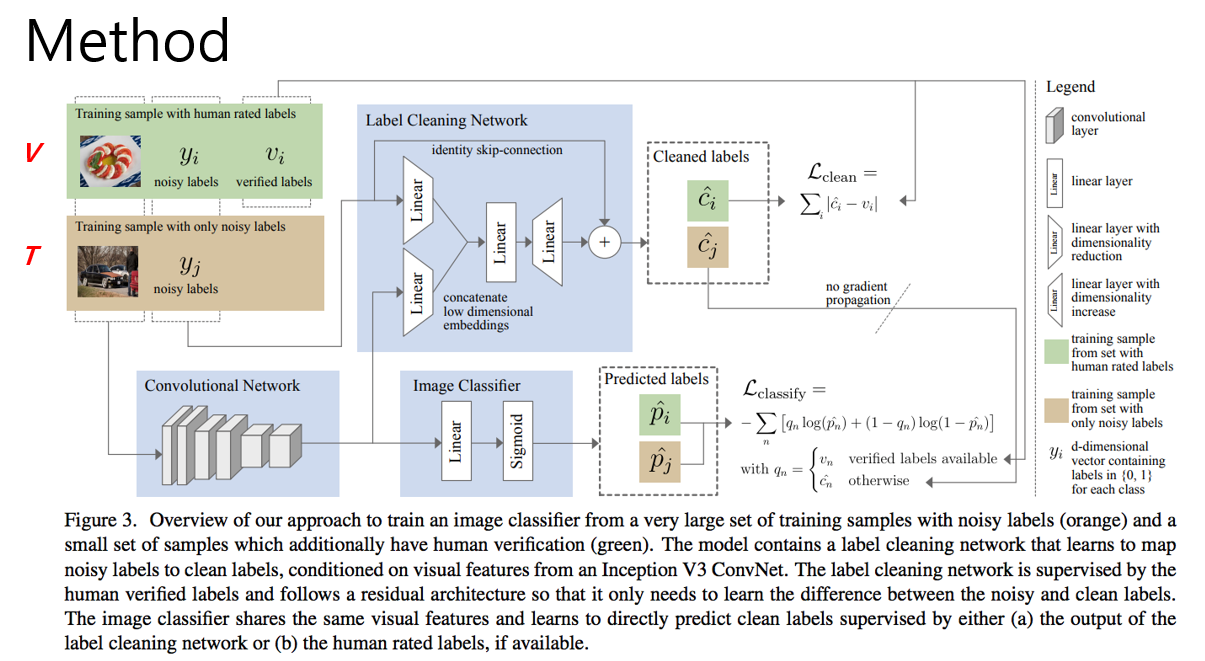
본 논문에서는 여러 task를 동시에 수행하는 “multi-task learning” 관점에서 학습 모델의 architecture를 구성하였습니다. 전체 architecture는 labeling cleaning network와 image classification network 총 2개의 network로 구성이 되어있으며 잘못된 label을 수정하는 task와, 이미지에 대한 label을 예측하는 task를 동시에 학습하는 방식을 사용하였습니다. 이러한 방식을 논문에서는 하나의 그림을 통해 설명을 하고 있습니다. 위의 그림 하나만 이해하면 전체 architecture를 이해할 수 있습니다.
이번 포스팅에서는 이 그림을 바탕으로 논문의 내용을 설명할 예정이며, 학습 데이터, label cleaning network, image classification network 총 3가지 요소를 구분하여 설명을 할 예정입니다. 이제 각 요소를 하나씩 설명을 하도록 하겠습니다.

우선 학습 데이터는 900만장의 noisy한 데이터 집합인 T 집합과 1만장의 정제된 V 집합으로 구성이 되어있습니다. 본 논문에서 T의 크기는 V보다 훨씬 크다고 가정을 하고 있고 실제로도 전체 데이터에서 일부만 정제하여 사용하는 것이 의미가 있습니다.
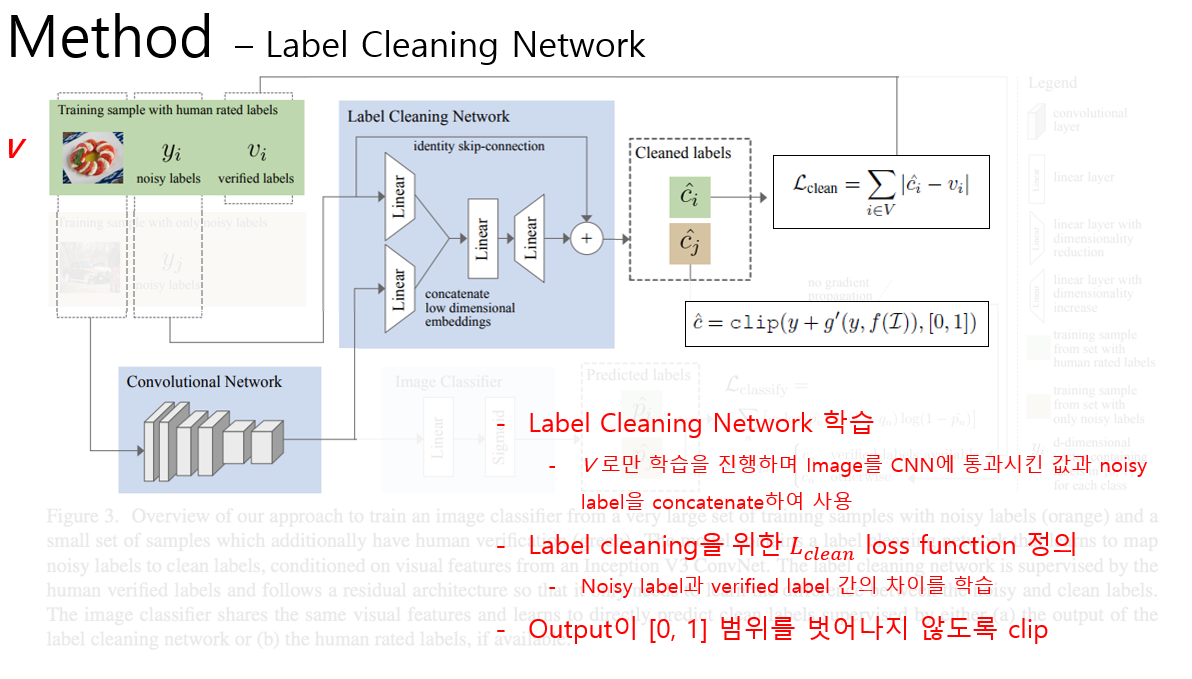
다음 설명드릴 내용은 Label Cleaning Network입니다. 학습에는 V 집합만을 사용하며, Image Classification Network와 Convolutional Network를 공유합니다. 우선 noisy label과 Convolution network에 이미지를 통과시켜 얻은 feature map을 network에 입력으로 넣어줍니다. 그 뒤 하나로 concatenate 시키고 두번의 linear layer를 거친 뒤, 입력 label의 skip-connection을 거친 뒤, 값을 0~1 사이로 clip하여 예측 label 값을 출력합니다. Skip-connection을 넣어 줌으로써 실제 정답인 verified label과 input인 noisy label의 차이 값 만을 학습하게 되어 더 효율적이라고 주장을 하고 있습니다. Loss function은 Label cleaning network를 통해 출력된 label과 실제 정답(Ground Truth) label간의 차이의 절대값으로 사용하였습니다. 차이의 제곱 등의 다른 loss function 사용하지 않은 이유는 차이의 제곱 등의 다른 loss function은 label을 smooth하는 효과가 있기 때문에 sparse한 label을 예측해야 하는 task에는 어울리지 않는다고 주장을 하고 있습니다. 역시 성능이 가장 잘 나오는 loss function을 사용한 것으로 판단이 됩니다.
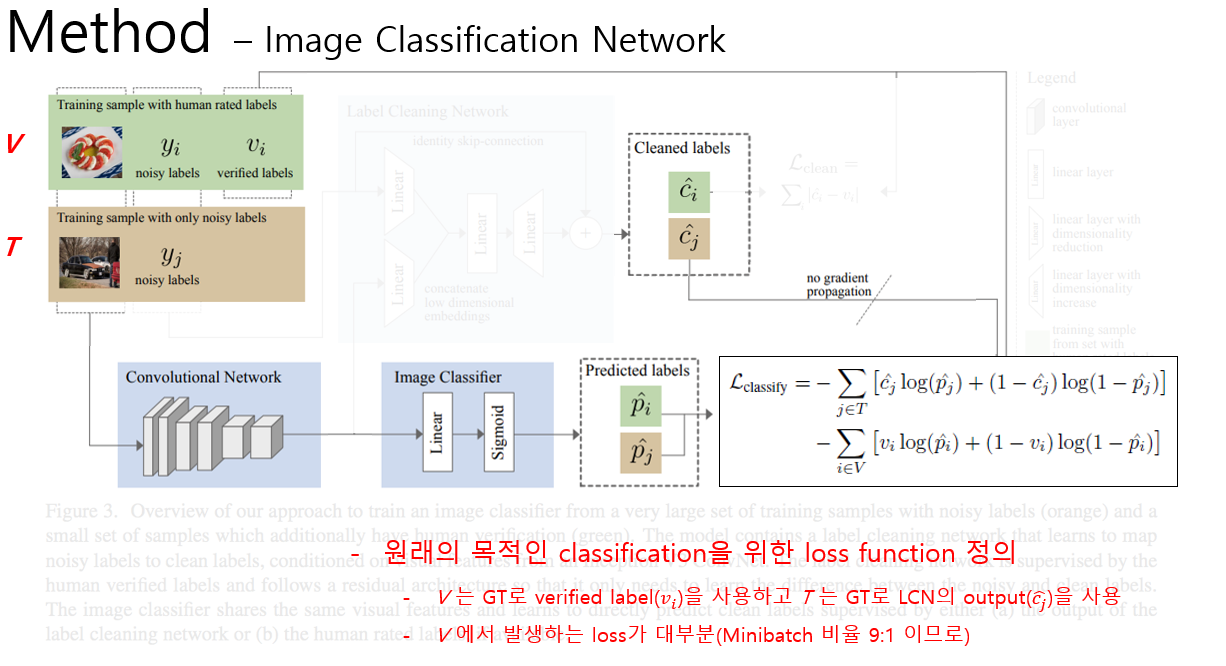
다음 설명드릴 내용은 입력 이미지가 주어졌을 때 label을 예측하는 Image Classification Network입니다. 학습에는 T 집합과 V 집합을 동시에 사용하며, mini batch 구성 시 T : V = 9 : 1 비율로 구성을 하여 학습을 진행합니다. V 집합을 사용할 때는 Classification label(정답)이 존재하므로 verified label을 정답으로 사용하여 Classification 망을 학습시킵니다. 하지만 T 집합을 사용할 때는 Classification label(정답)이 존재하지 않으므로 앞서 설명한 Label Cleaning Network를 거쳐 나온 값을 Classification label로 사용하였습니다. 이 때, Classification Network와 Label Cleaning Network가 둘다 label을 전부 0으로 예측하는 것을 방지하기 위해 gradient propagation을 하지 않도록 구현을 하였습니다.
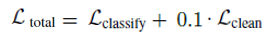
학습 시에는 Label Cleaning Network와 Image Classification Network를 동시에 학습을 시키는데, V 집합의 데이터는 두 network 학습에 모두 관여를 하는 반면, T 집합의 데이터는 오로지 Image Classification Network의 학습에만 관여하는 것이 특이한 점입니다. 또한 두 loss 값의 scaling을 위해 Label Cleaning Network의 loss 값에 0.1을 곱한 weighted loss를 사용하였습니다.
실험 결과
드디어 기다리던 실험 결과입니다. 실험 결과를 설명 드리기 앞서 어떻게 성능을 측정했는지 와 어떤 모델들과 비교하였는지를 먼저 설명을 드리고자 합니다.
성능 평가 지표
본 논문에서 사용한 dataset인 Open Image에 대한 표준 평가 절차가 존재하지 않아서 논문의 저자들이 평가 방법을 고안하였습니다. 일반적으로 class의 개수가 많을 때 사용하는 metric인 MAP(Mean Average Precision)을 사용하였고, 추가로 class agnostic average precision이라는 metric도 사용하였습니다.
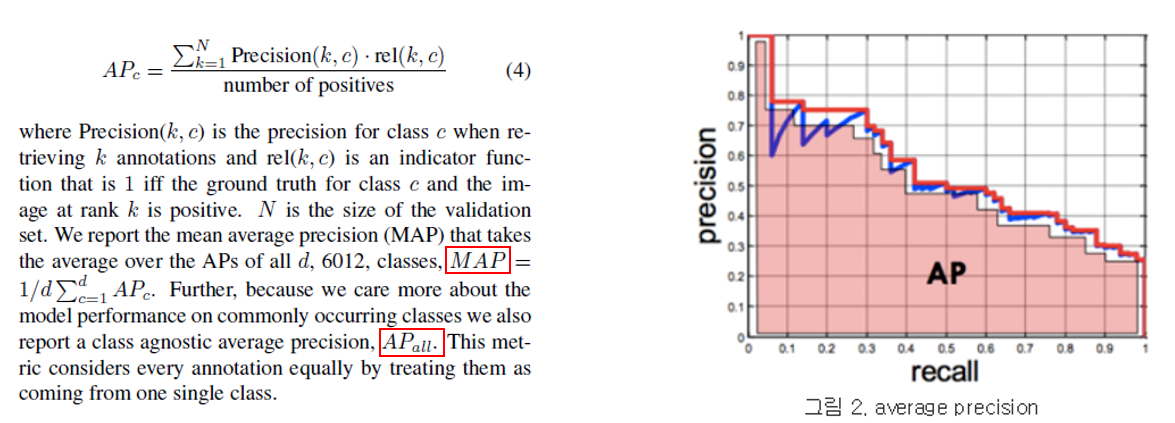
MAP를 계산하기 위해 각 class 마다 average precision을 계산을 해야 합니다. Average precision은 Precision-Recall 그래프를 그린 뒤 그래프의 아래 넓이에 해당합니다. 각 class마다 average precision을 구한 뒤 그 것을 평균내면 MAP를 계산할 수 있습니다. Class agnostic average precision은 class에 무관하게, 즉 다 하나의 class라고 생각하고 average precision을 계산하는 방식입니다. 본 논문에서는 이 두가지 metric을 통해 비교 모델들과 성능을 비교하였습니다.
비교 모델
성능 비교를 위해 Baseline 성능으로 noisy label을 그대로 사용하여 같은 image classification network에 학습한 결과로 사용하였습니다. 또한 비교 모델로 동일한 V 집합을 이용하여 Baseline에 fine-tuning을 진행한 결과들도 포함을 시켰습니다. 즉, Baseline에 V 집합만을 사용하여 fine-tuning을 한 결과와, Baseline에 V 집합과, T 집합의 일부를 포함시켜 fine-tuning을 진행한 결과를 비교군으로 삼았습니다.
실험 결과
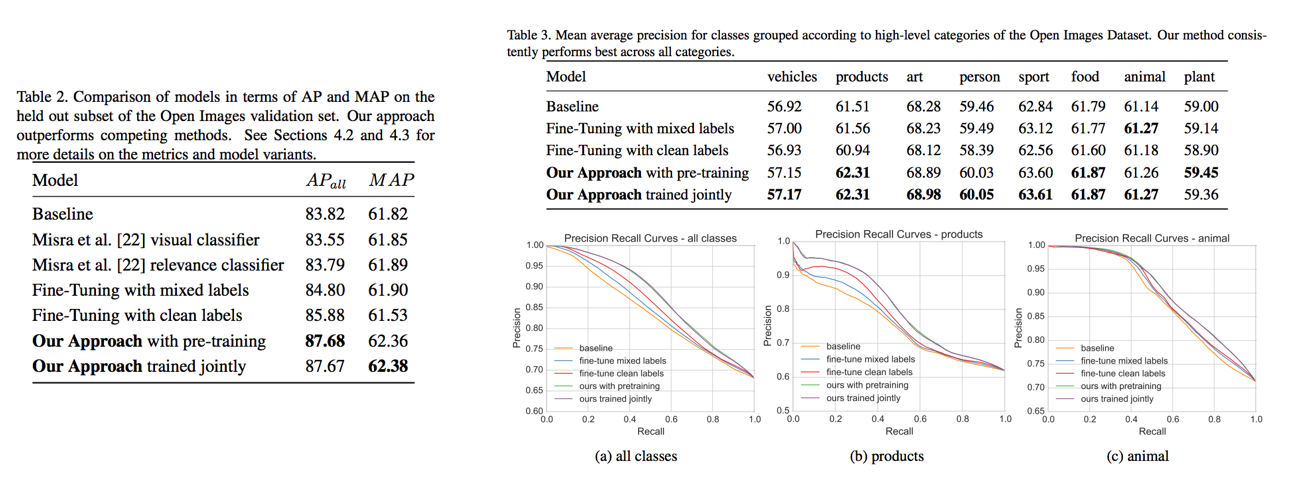
실험 결과 기존 Baseline 모델, 비교 모델 들에 비해 2가지 성능 평가 지표에서 모두 높은 성능을 달성하였습니다. 또한 본 논문에서 제시한 방법도 실험을 2가지로 나눠서 진행을 했는데, 첫 번째 방식인 “Our Approach with pre-training”은 Label Cleaning Network를 먼저 학습시킨 뒤 두 network를 동시에 학습하는 방법을 의미하고, 두 번째 방식인 “Out Approach trained jointly”는 pre-training 없이 두 network를 시작부터 동시에 학습하는 방법을 의미합니다. 간단하게 생각해보면 첫번째 방식이 더 좋을 수도 있을 것이라 생각할 수 있습니다. 그 이유는 학습 단계에서 T 집합으로 모델을 학습할 때, 초기의 Label Cleaning Network는 학습이 덜 되어서 결과로 내뱉는 cleaned label이 부정확할 수 있는데, Image Classification Network에서는 이 부정확한 Label Cleaning Network의 결과를 Ground Truth로 사용하기 때문에 학습이 부정확하게 될 수 있지 않냐는 걱정이 생길 수 있습니다. 하지만 실험 결과 성능에 큰 차이가 없었고, 이는 초반에 불안정하게 학습이 되어도, 학습이 진행됨에 따라 optimal로 향해 가는 것은 변함이 없음을 의미합니다.
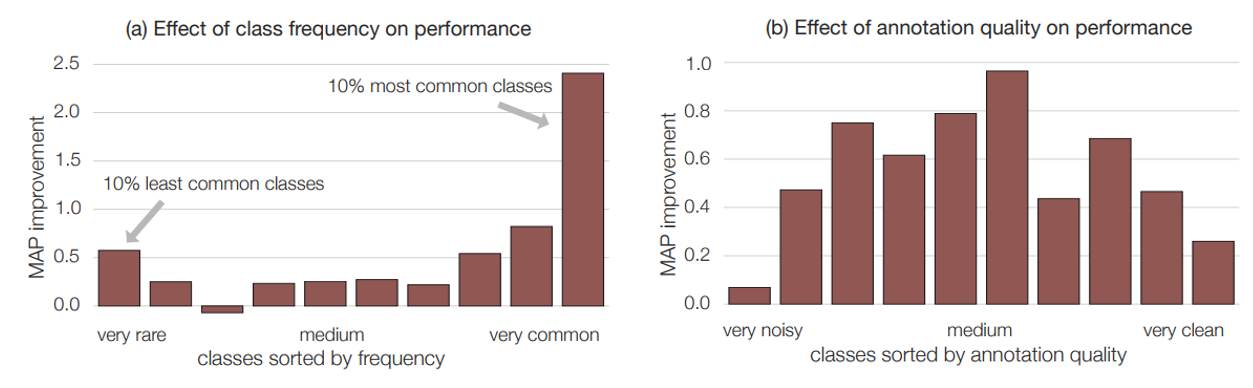
또한 성능 향상을 분석하기 위해 class의 frequency와 annotation quality에 따른 성능 향상 정도를 비교하였습니다. 대체로 annotation quality에는 무관하게 전반적으로 MAP 성능이 향상된 반면, class frequency에서는 데이터의 개수가 가장 많았거나 가장 적은 샘플일수록 MAP 성능 향상이 큰 분포를 보였습니다.
무튼, 정리하면 기존의 방법론들을 이용하여 측정한 실험 결과들보다 높은 성능을 보이는 것을 확인하였고 앞서 나눴던 8종류의 high-level class에 대해서도 모두 성능이 향상되는 것을 확인할 수 있었습니다. 아래 그림은 해당 논문의 실험 결과 이미지의 예시입니다.

결론
이번 포스팅에서는 데이터셋에 labeling noise가 존재하는 경우에 label cleaning과 image classification 두가지 task를 동시에 학습하여 구분 성능을 높이는 방법을 소개 드렸습니다. 또한 Google의 Open Images라는 굉장히 큰 데이터셋에 대해서 multi-labeled image classification을 하는 과정과 성능 수준을 확인할 수 있었습니다.
Labeling noise에 대한 연구는 이전부터 진행이 되어왔고 앞으로도 많은 연구가 진행될 것으로 전망됩니다. 또한 본 논문에서는 multi-labeled image classification에 대한 설명 위주로 되어있는데, label cleaning을 주 목표로 할 때, label cleaning 성능이 어느 정도인지, 저희가 주로 사용하는 single-labeled image classification에서도 잘 적용할 수 있는지 등 생각해볼 점이 많은 논문이었습니다.
위의 내용을 보시고 혹시 이해가 잘 되지 않거나 설명을 더 듣고 싶은 부분은 언제든지 편하게 댓글로 남겨 주시면 감사하겠습니다. 다음에도 여러분들이 흥미로워 할 만한 재미있는 최신 논문들의 리뷰로 찾아 뵙겠습니다.
Reference
- Google Open Images 데이터셋
- Precision-Recall 그림
- “Learning From Noisy Large-Scale Datasets With Minimal Supervision” 논문