MVTec AD—A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection 리뷰
안녕하세요, 오늘은 2019년 CVPR에 발표된 “MVTec AD—A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection” 논문을 리뷰할 예정입니다.
Anomaly Detection에 대해서 지난 2편의 글을 통해 소개드렸었는데요, 오늘 소개드릴 논문은 Unsupervised Anomaly Detection을 다룬 논문이며, Real-World Industrial 데이터셋을 제작하고 benchmark를 세운 논문입니다. 제가 참여 중인 PR-12 스터디에서도 이 논문을 리뷰하였으니 이 글과 함께 보시는 것을 권장드립니다.
- Anomaly Detection 개요: [1] 이상치 탐지 분야에 대한 소개 및 주요 문제와 핵심 용어, 산업 현장 적용 사례 정리
- Anomaly Detection 개요: [2] Out-of-distribution(OOD) Detection 문제 소개 및 핵심 논문 리뷰
- PR-263 Youtube 발표 영상
- 발표 슬라이드
Related Works
Anomaly Detection은 다양한 분야에서 연구가 되고 있는데요, 저는 주로 Image에 대한 Anomaly Detection을 공부하고 있어서 Image에 대한 관련 연구들을 소개드리겠습니다.
Datasets for Anomaly Detection in natural images
우선 One-Class Anomaly Detection 연구에는 주로 MNIST, CIFAR-10 데이터셋이 사용됩니다.

이미 존재하는 데이터셋을 활용하는 방법이 주로 사용되며, 많은 양의 train, test data를 사용할 수 있는 점이 장점이지만, 원래 Anomaly Detection을 위해 제작된 데이터셋이 아니다보니까 다소 부자연스러운 점이 존재합니다. 숫자 0과 숫자 1~9는 누가 봐도 쉽게 구분이 가능하고, 강아지와 비행기도 쉽게 구분이 가능해서 해당 데이터셋에 좋은 성능을 보여도 실용성이 떨어지는 한계가 존재합니다.
Unsupervised Anomaly Detection 데이터셋은 DAGM 2007과 NanoTWICE 데이터셋 2개가 주로 사용됩니다.

DAGM 데이터셋은 총 10가지 도메인의 데이터로 구성되어 있으며, 모델링을 통해 가상으로 결함을 합성하여 만든 데이터셋입니다. NanoTWICE 데이터셋은 nanofibrous material 데이터이며 5장의 정상 데이터와 40장의 결함 데이터로 구성이 되어있습니다. 굉장히 개수가 작죠?
연구 용으로 사용하기엔 두 데이터셋 모두 부족한 점이 많으며, 두 데이터셋 모두 textured surface 검사에만 초점이 맞추어져 있다는 점도 한계입니다. 저자들은 이러한 점에 주목하여 Unsupervised Anomaly Detection을 위한 데이터셋이 필요함을 느꼈고, 직접 제작하게 되었다고 합니다.
Methods for Unsupervised Anomaly Detection
1. Generative Adversarial Network
Unsupervised Anomaly Detection의 대표적인 연구로 Generative Adversarial Network 기반 AnoGAN 이 있습니다.

AnoGAN은 정상 데이터로 GAN을 학습시킨 뒤, Generator와 Discriminator를 고정시킨 뒤, 주어진 input image를 가장 잘 표현하는 latent variable을 back propagation을 통해 찾는 방법을 제안하였으며, 저희 PR-12의 강민국님께서 잘 설명해주신 자료가 있어서 자세한 내용은 이 영상을 참고하셔도 좋을 것 같습니다.
2. Deep Convolutional Autoencoders and Variational Autoencoders (VAE)
그 다음은 지난 Anomaly Detection 개요: [1] 이상치 탐지 분야에 대한 소개 및 주요 문제와 핵심 용어, 산업 현장 적용 사례 정리 글에서 잠시 소개드렸던 Autoencoder 기반의 방법입니다.
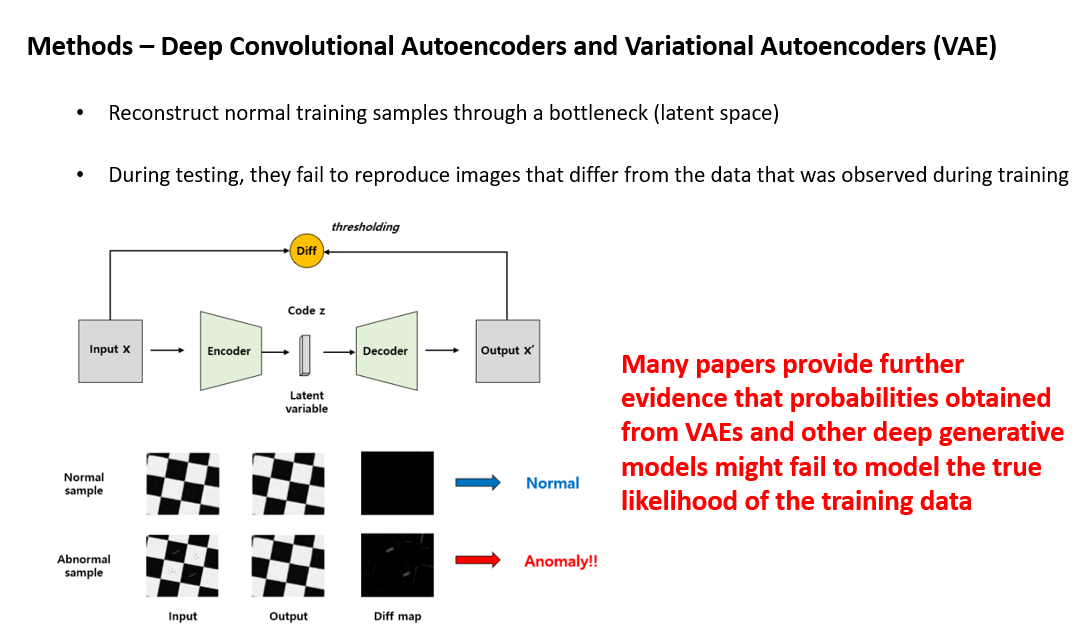
정상 데이터로 Autoencoder를 학습시킨 뒤 test 시에 정상 데이터를 넣으면 잘 복원하고, 결함 데이터를 넣으면 잘 복원하지 못하는 특징을 이용하는 방법입니다. 주로 Deterministic한 Convolutional Autoencoder를 사용하며, Variational Autoencoder나 다른 generative model들은 정상 데이터들의 true likelihood를 잘 모델링하지 못해서 좋지 않은 성능을 보인다고 여러 논문에서 보고하고 있습니다.
3. Features of pre-trained CNN (Feature Dictionary)
다음은 pretrained CNN에서 feature를 추출하여 Anomaly Detection을 하는 Feature Dictionary 방법입니다.
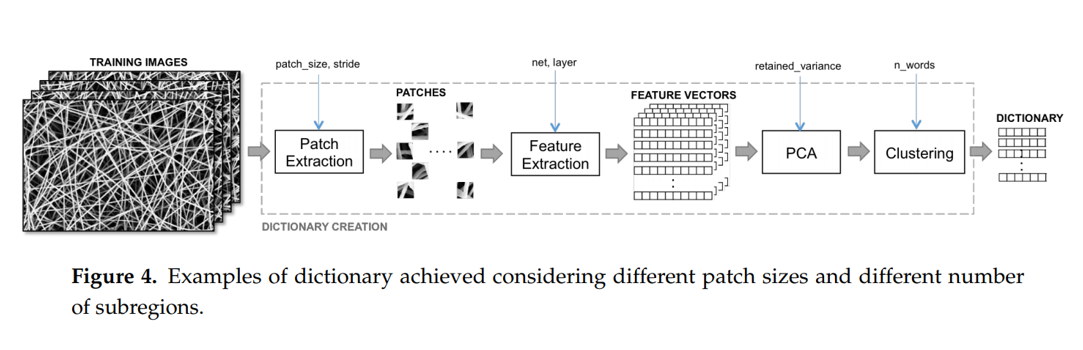
위의 그림은 Anomaly Detection in Nanofibrous Materials by CNN-Based Self Similarity 논문의 방법론을 보여주는 그림입니다.
Input image에서 sliding window로 patch를 추출한 뒤 ImageNet으로 pretraining 시킨 ResNet-18에 feed forward 시켜서 feature vector를 추출합니다. 그 뒤, PCA와 Clustering을 통해 Feature Dictionary를 만들어서 Patch 단위로 정상/결함 분류를 합니다. Test 시에 마찬가지로 Input에서 sliding window로 patch를 뜯어서 Dictionary에 넣어서 정상/결함 판정을 하는 방식이다보니까, 해상도가 큰 image에 대해선 1장을 처리하는데 굉장히 오래 걸리는 한계가 있습니다. 또한 patch size에 따라 성능 변화가 큰 점도 약점입니다.
4. Traditional Methods
마지막으로 Deep Learning 기반이 아닌 전통적인 접근 방법들이 있습니다. 정상 image로부터 hand-crafted feature를 추출하여 사용하는 방식이며, texture object에 대해선 Gaussian Mixture Model(GMM) 기반의 Texture Inspection Model 을, non-texture object에 대해선 Shape-based Matching 기반의 Variation Model 을 사용합니다.
MVTec-AD Dataset
자, 이제 오늘의 본론인 MVTec-AD 데이터셋에 대해 설명드리겠습니다. 앞서 설명드렸던 DAGM, NanoTWICE의 아쉬웠던 부분들을 개선하며 총 15종류의 도메인의 데이터셋을 구축하였습니다. 크게는 Texture와 Object로 구분을 하였고, 각각 5가지, 10가지 종류의 도메인 데이터로 구성이 되어있습니다. 고해상도 산업용 RGB Sensor를 통해 2048 x 2048 image를 얻은 뒤, 적당한 size (700 x 700 ~ 1024 x 1024)로 crop하여 제작하였습니다. 또한 대부분 통제된 조명 환경에서 image들을 취득하였고, 일부 image들은(아마도 쉬운 도메인?) 다양성을 늘리기 위해 의도적으로 조명 환경을 바꿔서 취득을 하였다고 합니다.
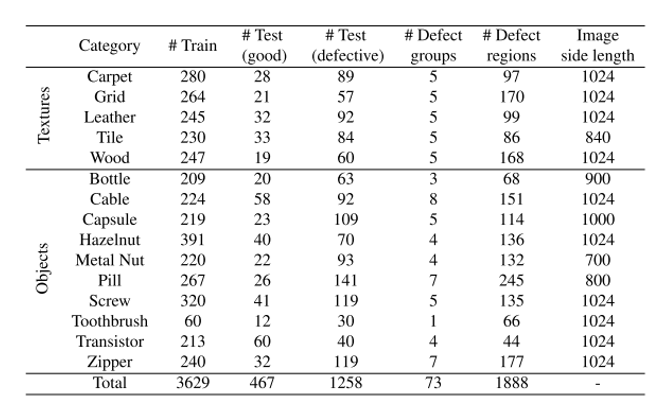
총 3629장의 학습 데이터가 존재하고, 당연히 전부 정상 image 만 존재합니다. 총 1725장의 테스트 데이터가 존재하고 정상과 결함 image가 동시에 존재하며, 결함 image의 개수가 더 많습니다. 결함 image는 실제 산업 현장의 검사 시나리오와 거의 비슷한 결함들을 직접 발생시켜서 취득을 하였다고 합니다.

Texture에 속하는 Carpet, Grid, Leather, Tile, Wood의 경우 비슷한 패턴이 전역적으로 반복되는 특징을 보이고, Object의 경우 거의 정해진 규칙에 맞게 물체들이 배치되어 있고 결함도 지엽적으로 발생하는 것을 알 수 있습니다.
Benchmark
자, 이제 Benchmark 에 대한 설명을 드리도록 하겠습니다. 데이터셋이 제작이 되었으니 앞서 소개드렸던 방법론들을 적용해봐야겠죠? Benchmark에는 총 6가지 방법론을 시도하였습니다.
1. Methods

AnoGAN은 저희 PR-12 스터디에 함께 참여 중이신 이도엽님의 코드 를 이용하였다고 하네요! 멋지십니다 도엽님!
Autoencoder는 MVTec의 선행 연구인 Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders 의 구조를 그대로 사용하였다고 합니다.
CNN Feature Dictionary는 ImageNet Pratrained ResNet-18의 512-d avgpool layer의 output을 사용하였으며, 2개의 Traditional Method는 MVTec의 제품인 HALCON machine vision library를 사용하였다고 합니다.
2. Data Augmentation
Texture image에는 고정된 크기의 patch를 random crop하여 추출한 뒤, random rotation을 적용하였다고 합니다.
Object image에는 image의 특성이 바뀌지 않는 선에서 random translation과 random rotation, random flip 등을 적용하였다고 합니다. 다만 어떤 object에 어떤 augmentation을 적용했는지 구체적인 설명은 되어있지 않습니다.
3. Evaluation
여러분들이 가장 생소해하실 Unsupervised Anomaly Detection의 Evaluation에 대해 설명 드리겠습니다. 미리 예고를 하자면, 잘 정립된 Evaluation Protocol이 없다 보니 본 논문에서도 다소 애매한 방법을 제안하였으며, 아직까지 연구해 야할 여지가 많은 부분 중에 하나입니다.
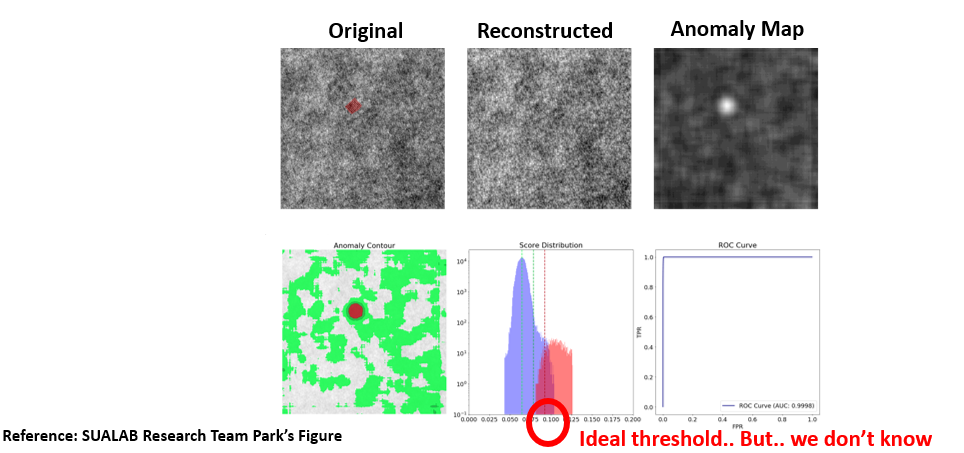
우선 Unsupervised Anomaly Detection의 Output의 형태는 input size와 똑같은 해상도를 갖는 1 channel의 spatial map이며, 이를 앞으로 Anomaly map으로 부르겠습니다. Anomaly map은 각 픽셀마다 0~1 사이의 값을 가지며 1에 가까울 수록 비정상(결함)에 가까운 것을 의미합니다. 이렇게 얻어진 Anomaly Map은 위의 그림의 1행 3열에 있는 것과 같은 형태를 띄며, thresholding과 같은 후처리를 통해 결함 영역만 남기는 작업이 필요합니다. 참고로 위의 그림은 제가 재직 중인 수아랩의 박종호 연구원님이 연구하시며 만든 그림이며, 제 블로그 그림을 무단으로 출처없이 사용하시는 분들이 많이 계시던데 꼭 출처를 밝혀 주시기 바랍니다.
다만, 저희가 가지고 있는 데이터는 모두 정상 데이터라는 가정이 있기 때문에 정상은 남겨두고, 결함 영역만 골라낼 수 있는 이상적인 threshold 값을 정하기가 쉽지 않습니다. 즉, Unsupervised Anomaly Detection은 Anomaly Map의 threshold를 어떻게 정하는 지가 굉장히 중요합니다. 어떤 연구에서는 극소수의 비정상 데이터를 이용해서 thresholding을 하기도 하며, 대부분 정상 데이터의 anomaly map의 최대 값 주변을 threshold로 사용하기도 합니다.
본 논문에서는 각 category 마다 결함의 최소 크기를 정의한 뒤, 학습에 쓰지 않은 정상 validation set에서 점점 threshold를 키워준 뒤, connected component (아마도 blob을 의미하는 듯)들이 앞에서 지정한 최소 크기 이하가 되는 시점의 threshold를 구하여 사용하였다고 합니다. 이 과정에서 사람의 prior가 들어간 셈이죠? 즉, 완벽한 evaluation metric은 아닌 셈입니다.
4. Evaluation Metric
Evaluation Metric으로는 위에서 정의한 threshold를 이용하는 Metric과 threshold에 independent한 Metric을 사용하고 있습니다. 우선 Classification에는 앞서 구한 threshold을 이용하여 분류를 하였을 때의 Accuracy를 Evaluation Metric으로 사용하였습니다. 다만, thresholding을 한 뒤, Anomaly map에서 threshold보다 큰 값이 존재하면 결함으로 판단하였는지, 아니면 thresholding을 한 뒤, 남아있는 connected component가 각 category 마다 지정한 최소 크기보다 크면 결함으로 판단하였는지가 중요한데 이에 대한 설명은 논문에 누락되어 있습니다.
Segmentation에는 relative per-region overlap (이라 쓰고 IoU라 부릅니다..)와 ROC curve의 면적인 AUROC 2개의 Evaluation Metric을 사용하였습니다. 참고로 AUROC는 threshold에 independent한 지표입니다.
5. Experimental Results
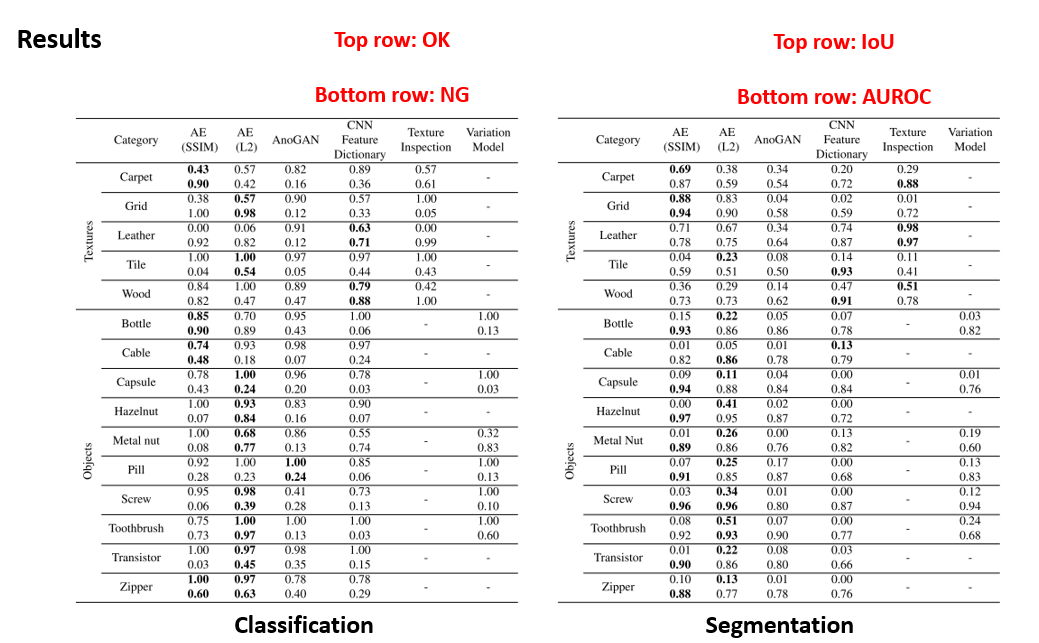
앞서 정리한 방법론들을 15가지의 데이터셋에 적용하여 Evaluation하여 얻은 Metric 값들이 표에 정리가 되어있습니다.
왼쪽 표는 Classification 실험 결과를 보여주고 있으며, 각 Category마다 2개의 row로 값이 존재하는데, 위의 row는 OK test set의 Recall, 아래 row는 NG test set의 Recall을 의미합니다.
오른쪽 표는 Segmentation 실험 결과를 보여주고 있으며, 각 Category의 위의 row는 IoU를, 아래 row는 AUROC를 나타내고 있습니다.
Texture image에 대해선 데이터셋 마다 우세했던 방법론이 다른 경향을 보여주고 있으며, 대체로 Autoencoder와 CNN Feature Dictionary 방법들이 좋은 성능을 보이고 있습니다.
Object image에 대해선 Autoencoder가 다른 방법들에 비해 우수한 성능을 보이고 있으며, 특히 IoU 관점에서 보면 SSIM Autoencoder보다 L2 Autoencoder가 좋은 성능을 보이고 있습니다.
Discussion
마지막으로 각 방법론들에 대해 짧게 분석한 내용이 있어서 요약해서 설명 드리겠습니다.

우선 (a)는 AnoGAN의 실험 결과이며, GAN 특성 상 학습이 불안정하고 mode collapse를 자주 겪었다고 합니다. 또한 데이터셋에 shape, orientation 등의 변화가 많은 데이터셋에 취약한 모습을 보였다고 합니다.
(b)는 Autoencoder의 실험 결과이며 대체로 SSIM AE와 L2 AE 모두 안정적으로 학습이 되었고 대체로 성능도 좋았습니다. 다만, 일부 Category에 대해선 small detail을 잘 복원하지 못하고 blurry한 복원을 하였는데, 이는 Autoencoder의 고질적인 문제입니다. 또한 high-frequency한 영역에 대해서도 잘 복원하지 못해서 과검(False Positive)가 많이 발생하는 문제도 겪었다고 합니다.
(c)는 CNN Feature Dictionary의 실험 결과이며, 원래 논문도 texture image에 적용하기 위해 제안된 만큼 texture 데이터셋에서 좋은 성능을 보였지만, object 데이터셋에서는 대체로 취약한 모습을 보였다고 합니다.
마지막으로 (d)는 Texture Inspection Model, (e)는 Variation Model의 실험 결과를 보여주고 있으며, 대체로 좋지 않은 성능을 보이며, 실제로 일부 데이터셋에서는 좋은 성능을 보이지만 전체적으로 봤을땐 낮은 성능을 보이고 있습니다.
결론
오늘은 2019년 CVPR에 발표된 MVTec-AD 데이터셋과 벤치마크를 다룬 논문을 정리하였습니다. Unsupervised Anomaly Detection을 위한 잘 정의된, Real-World와 유사한 최초의 데이터셋을 제작하였다는 점에서 큰 의미를 갖고 있는 논문이라 생각합니다. 또한 Unsupervised Anomaly Detection에 적용될만한 후보군들을 잘 정리하여 Benchmark를 잘 정립한 점도 좋은 것 같습니다. 하지만 Evaluation Metric 부분에선 아직까지 사람이 개입을 하고 있고, 다소 애매한 점도 존재합니다. 가장 아쉬운 점은 실험을 돌려보기 위한 Source Code가 전혀 공개가 되지 않아서 논문에서 제시하고 있는 성능을 뽑아보는 것이 불가능합니다. 그나마 도엽님의 AnoGAN 정도만 돌려볼 수 있네요. 오늘도 읽어주셔서 감사합니다!