Reproducible PyTorch를 위한 randomness 올바르게 제어하기!
안녕하세요, 오늘 글에서는 여러분이 많이 사용하시는 PyTorch의 완벽한 실험 재현을 위해 고려해야 할 randomness를 올바르게 제어하는 방법을 설명드릴 예정입니다.
저 또한 나름대로 random seed를 통제하며 실험을 해왔는데, 같은 random seed로 학습을 시켜도 학습 결과가 매번 달라지는게 이상해서 이유를 찾다 보니 PyTorch의 공식 Reproducibility 문서를 발견해서, 이를 소개드리고 누락된 내용은 보충한 뒤, 간단한 toy example에서 돌려보고 확인해볼 예정입니다.
PyTorch 실험의 재현 가능성을 위해 고려해야 할 4가지 요소
우선 저희가 사용하는 random과 관련있는 기능들은 다 난수 발생기, Random Number Generator(RNG)를 통해 생성된 난수를 기반으로 구현되어 있습니다. 이 때, 이 난수 발생기에는 random seed를 설정할 수 있고, random seed를 설정하면 매번 같은 순서로 난수가 발생됩니다. 이는 컴퓨터 프로그래밍을 공부해보신 분들은 다들 잘 아실 것이라 생각합니다.
다만 저희가 사용하는 PyTorch에는 random과 관련된 요소가 여러개 존재해서, 각각의 요소들이 무엇인지 살펴보고, 각 요소들의 randomness를 제어하기 위한 방법들을 알아보겠습니다.
오늘 사용할 예제 코드는 colab을 통해 작성하였고, 해당 링크 에서 확인하실 수 있습니다.
직접 돌려보실 분들은 이 코드를 본인의 구글 드라이브로 사본 저장하신 뒤 colab을 통해 실행하시면 됩니다. 새롭게 돌려보고 싶은 경우 [런타임] - [런타임 초기화] 버튼을 누르고 다시 실행하시면 됩니다.
1. PyTorch Randomness
우선 저희가 사용하는 메인 프레임워크인 PyTorch의 random seed를 고정할 수 있습니다.
import torch
torch.manual_seed(random_seed)
위와 같이 한 줄만 입력해주면 torch.블라블라 를 통해 발생하는 randomness들이 통제가 됩니다. 다만 CUDA 함수를 사용하는 PyTorch 함수들 중에 nondeterministic한 함수가 존재한다고 합니다. 대표적인 예시가 atomic operation, 그 중에서도 atomicAdd 인데요, 이 연산이 포함되어있는 함수들은 대표적으로 forward kernel 중에는
torch.Tensor.index_add_() ,
torch.Tensor.scatter_add_() ,
torch.bincount()
연산이 있고, backward kernel 중에는
torch.nn.functional.embedding_bag() ,
torch.nn.functional.ctc_loss() ,
torch.nn.functional.interpolate()
이 존재한다고 합니다.
이 6가지 연산을 사용하고 계시다면, 현재로서는 nondeterminism을 피할 방법이 없다고 합니다! ㅠㅠ
이 외에도 backward path에 repeat_interleave() 연산도 index_add_() 연산을 기반으로 구현이 되어있어서 nondeterministic하게 동작한다고 합니다.
2. CuDNN
사실 저는 random seed를 torch와 numpy만 고정해두고 사용했었는데, 실험 결과가 재현이 안되어서 찾다가 발견한 것이 바로 CuDNN 이었습니다. CuDNN은 딥러닝에 특화된 CUDA library로 주로 환경 설정을 할 때 CUDA와 CuDNN을 함께 설치하고, 대부분 딥러닝 프레임워크에서 필수적으로 사용되는 라이브러리입니다. Randomness 제어를 위한 설정법은 두 줄이면 됩니다.
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False

간단하죠? 하지만 위와 같이 cudnn의 deterministic 옵션을 켰을 때 발생하는 부작용이 있습니다. 바로, 연산 처리 속도가 감소되는 문제입니다. nondeterministic 하게 사용할 때 보다 얼마나 느려지는 지는 어떤 연산들을 사용하여 모델을 구성하고 학습을 시켰는 지에 따라 달라질 수 있습니다. 그래서 저는 이 옵션은 모델을 막 구현해서 실험하는 초기 단계에 사용하기 보다는, 모델과 코드를 배포해야 하는 연구 후반 단계에 사용하는 것을 권장드립니다.
3. Numpy
PyTorch의 공식 문서에서 설명하고 있는 마지막 요소는 Numpy 입니다. Scikit-learn 등 딥러닝에 도움이 되는 주요 라이브러리도 Numpy를 backend로 사용하고 있고, PyTorch로 코드를 짤 때 대부분 Numpy로 data를 받아오고, metric을 계산하는 경우가 많아서 Numpy의 random seed도 고정을 해주어야 합니다. 마찬가지로 1줄로 random seed를 설정할 수 있습니다.
import numpy as np
np.random.seed(random_seed)
여기까지 하면 끝일까요? 저도 끝인 줄 알았습니다.. 하지만 간단한 튜토리얼 코드를 짜서 돌려본 결과 아쉽게도 학습 결과가 완벽하게 재현이 되지 않았습니다.
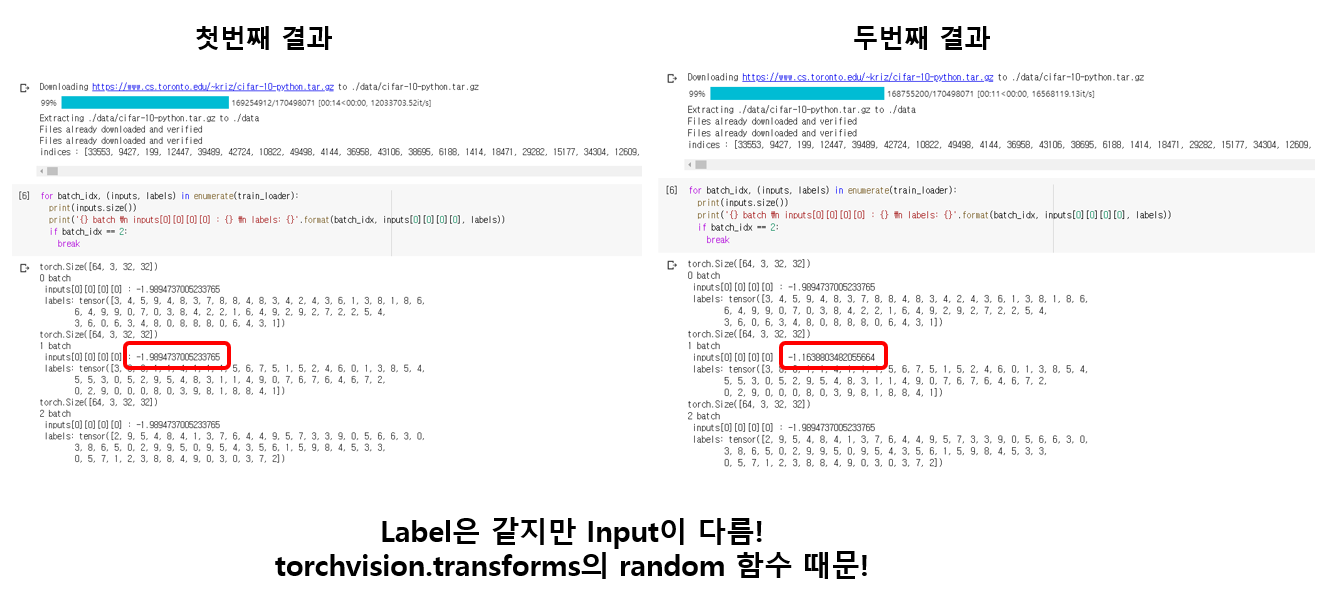
data loader를 정의한 뒤 3개의 batch를 뽑아서 각 batch의 첫번째 image의 가장 왼쪽 위의 픽셀 값과, 각 batch의 64개의 label들을 프린트하였더니 label은 정확히 일치했지만 image의 pixel 값이 다른 것을 발견했습니다. 원인을 찾다 보니, 제가 dataset 구성할 때 사용한 torchvision의 transforms 함수 때문이었습니다.
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
여기의 RandomCrop(), RandomHorizontalFlip() 함수에서도 randomness가 존재하는데, 찾아보니 torchvision의 transforms은 torch, numpy, cudnn이 아닌 python random 라이브러리에 의해 randomness가 결정이 된다고 합니다. 하하..
torchvision의 transforms를 대부분 사용하실 텐데 이 경우에는 마지막으로 python random 라이브러리도 randomness를 제어해주셔야 합니다.
4. Random
import random
random.seed(random_seed)
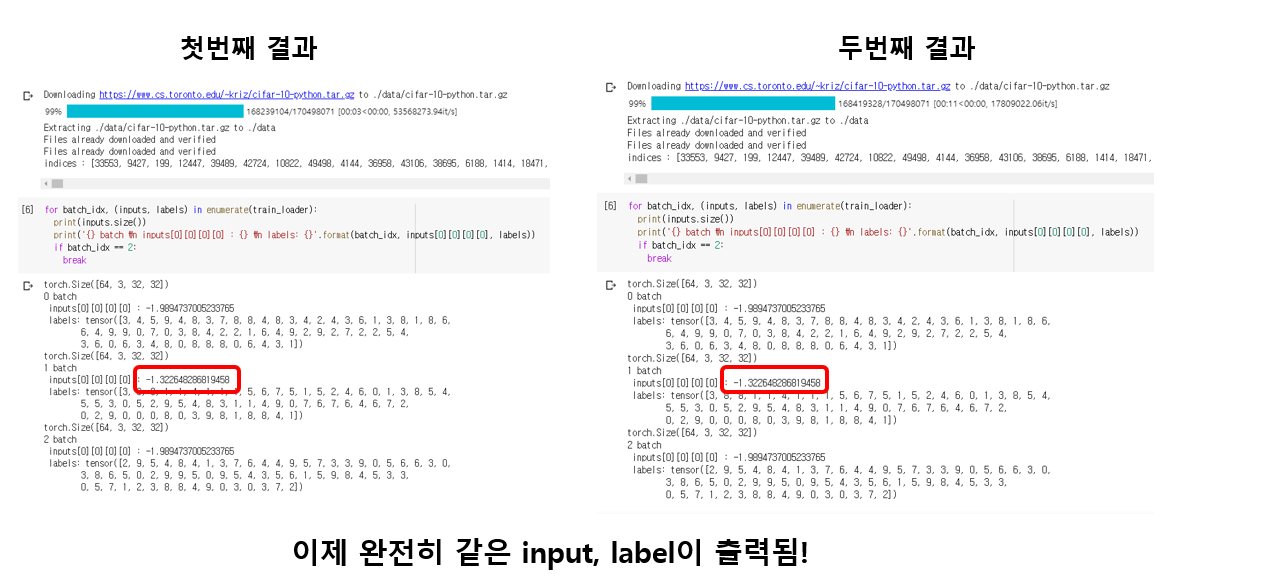
자, 이제 data loader를 통해 batch를 뽑으면 정확히 똑같은 image와 label이 출력되는 것을 확인할 수 있었습니다.
모델 선언, training 및 validation 재현 여부 검증
Torchvision Model 가져오기
이제 실험에 사용할 model을 정의할 건데요, 직접 network를 구현하지 않고, torchvision에서 제공하고 있는 resnet 18을 사용할 예정입니다. torch hub에는 여러 model들이 구현이 되어 있어서 아래와 같이 몇 줄의 명령어만 입력하면 모델을 가져올 수 있습니다. torch hub에 대해 궁금하신 분들은 해당 링크 를 통해 확인하실 수 있습니다.
entrypoints = torch.hub.list('pytorch/vision', force_reload=True)
print(entrypoints)
net = torch.hub.load('pytorch/vision', 'resnet18', pretrained=False)
torch hub에서 제공하고 있는 vision model 들 중에 저는 resnet 18을 가져와서 사용할 예정이고, pretrained는 False로 두어 random initialized resnet을 사용할 예정입니다. torchvision의 resnet 구현체 를 보시면 Convolution Filter의 weight는 kaiming normal로 초기화를 해주는데, 과연 매번 같은 weight로 초기화 되는지 확인해봅시다.

첫번째 Conv Filter의 weight만 출력을 해보았는데요, 정확히 일치하는 것을 확인할 수 있습니다. 대부분 torch.nn 연산을 통해 model이 선언이 되고, torch.manual_seed 에서 randomness가 통제가 되고 있기 때문입니다.
Training & Validation
자, 이제 마지막으로 선언한 data loader와 model을 바탕으로 학습을 시켜보겠습니다. 편의상 2 epoch만 학습을 시킬 예정이고, 100 iteration 마다 training loss를 출력하도록 코드를 구성해서 학습을 시켜보았습니다. 재현이 잘 되겠죠??
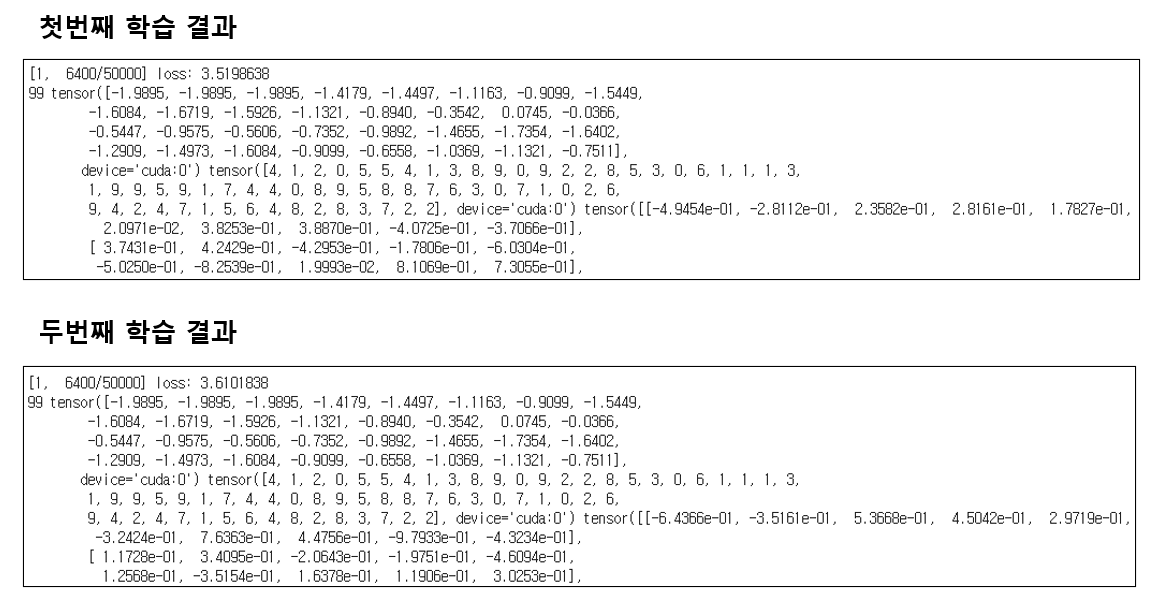
놀랍게도(?!) 100 iteration 후 값을 찍어보니 input과 label은 동일한 순서로 들어가고 있음에도 불구하고 loss도 다르고, output 값도 다른 것을 확인할 수 있었습니다. 즉, model의 학습된 weight가 다르다는 얘기겠죠? 왜 그런것일까요.. 이 부분은 저도 정확한 원인을 잘 모르겠습니다.. 아시는 분 계시면 댓글로 부탁드리겠습니다!
열심히 구글링을 한 결과, 공식 문서에는 없는 내용이지만 pytorch의 official repository의 issue를 찾다가 저와 같은 고민을 하신 분들이 많고, 해결 책을 찾으신 분이 계셔서 그분이 정리해주신 내용을 바탕으로 아래의 두줄을 추가해주었습니다.
(출처: https://github.com/pytorch/pytorch/issues/7068)
torch.cuda.manual_seed(random_seed)
torch.cuda.manual_seed_all(random_seed) # if use multi-GPU
그 뒤 드디어, 100 iteration이 지난 후 정확히 같은 loss 값과 output 출력 값을 얻을 수 있었습니다.
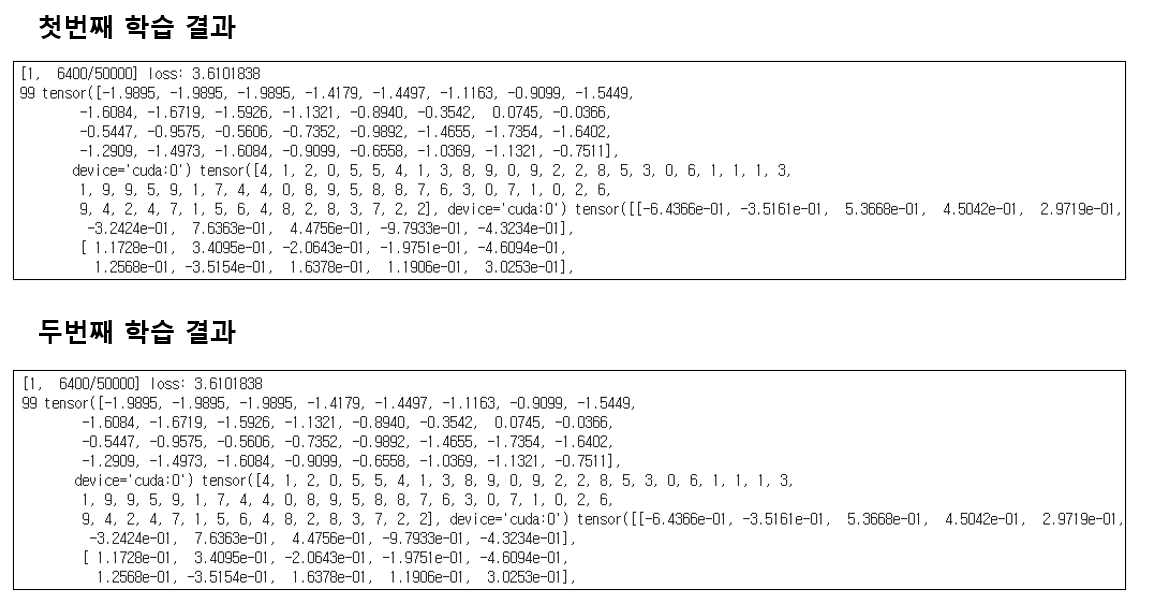
또한 100 iteration 뿐만 아니라 전체 2 epoch을 학습시켰을 때의 loss 값의 변화와 validation accuracy까지 정확히 일치하는 것을 확인하였습니다.

드디어 모든 실험 환경이 재현이 되었습니다! 워낙 random한 요소가 많이 들어가 있어서 그런지 굉장히 어렵게 실험 환경의 randomness를 제어할 수 있었습니다.
결론
오늘 포스팅에서는 PyTorch의 100% 재현되는 실험 환경을 구축하기 위해 고려해야할 요소들을 살펴보고, 간단한 toy example에서 검증을 해보았습니다. 오늘의 핵심을 7줄로 나타내면 다음과 같습니다.
torch.manual_seed(random_seed)
torch.cuda.manual_seed(random_seed)
torch.cuda.manual_seed_all(random_seed) # if use multi-GPU
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(random_seed)
random.seed(random_seed)
이러한 점들을 잘 고려하셔서 코드를 관리하시면 누구나 같은 결과를 얻을 수 있겠죠? 재현이 가능한 실험 환경을 구축하시는데 도움이 되셨으면 좋겠습니다! 읽어주셔서 감사합니다!
보너스! TensorFlow의 Reproducibility!
TensorFlow는 제가 사용하지 않아서 정리를 따로 안했는데, 찾아보니 잘 정리된 블로그 포스팅이 있어서 공유드립니다.
전반적인 방식은 PyTorch와 거의 유사한 듯 합니다.
def set_seeds(seed=SEED):
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
def set_global_determinism(seed=SEED, fast_n_close=False):
"""
Enable 100% reproducibility on operations related to tensor and randomness.
Parameters:
seed (int): seed value for global randomness
fast_n_close (bool): whether to achieve efficient at the cost of determinism/reproducibility
"""
set_seeds(seed=seed)
if fast_n_close:
return
logging.warning("*******************************************************************************")
logging.warning("*** set_global_determinism is called,setting full determinism, will be slow ***")
logging.warning("*******************************************************************************")
os.environ['TF_DETERMINISTIC_OPS'] = '1'
os.environ['TF_CUDNN_DETERMINISTIC'] = '1'
# https://www.tensorflow.org/api_docs/python/tf/config/threading/set_inter_op_parallelism_threads
tf.config.threading.set_inter_op_parallelism_threads(1)
tf.config.threading.set_intra_op_parallelism_threads(1)
from tfdeterminism import patch
patch()
이 두 함수를 선언하고 코드의 초입 부분에 호출하시면 아마도 100% 재현이 가능하지 않을까 싶네요! (해볼 생각은 없습니다! ㅋㅋ)