SIGGRAPH 2018 review [2] 사람의 지각을 반영한 visibility metric 및 논문 4편 소개
안녕하세요, 지난 편에 이어서 이번 포스팅에서는 SIGGRAPH 2018 학회에서 흥미로웠던 논문 여러 편에 대해 간단히 소개를 드리고, 그 중 가장 재미있게 들었던 논문 한편에 대한 리뷰를 다룰 예정입니다. 주로 이미지 인식 분야 관련 논문을 소개해드릴 예정이며, 제 관심 분야가 아닌 논문들은 제가 배경지식이 없어서 소개를 드리지 못하는 점 양해 부탁드리며 글을 시작하겠습니다.
논문 소개 및 리뷰
올해 SIGGRAPH 2018에 accept된 논문은 총 167편으로 최근 5년간 약 120편 전후로 accept이 되었는데 올해 약 40편정도가 증가하였습니다. 최근 10년간 SIGGRAPH의 논문 acceptance rate는 해당 링크 에서 참고를 하였고, 2018년의 통계 자료는 아직 제공이 되지 않아서 제가 직접 accepted paper list에서 편수를 세서 계산을 하여 작성을 하였습니다.
총 167편 중에 이미지 인식 분야와 관련이 있고 딥러닝을 이용한 5편의 논문을 준비해보았습니다. 그 중 제가 관심있게 들었던 1편은 좀 더 자세하게 리뷰를 진행하고, 나머지 4편은 짧게 소개 드릴 예정입니다.
분량 상 5편만 선정하게 되었지만 다른 논문들도 재미있는 주제들이 많이 있으니 관심 있으신 분들은 해당 링크 를 참고하시면 좋을 것 같습니다.
Dataset and metrics for predicting local visible differences 논문 리뷰
이번에 소개드릴 Dataset and metrics for predicting local visible difference 논문 은 제가 학회에서 제일 흥미롭게 들었던 논문이며 앞서 소개 드린 연구들과 마찬가지로 딥러닝을 이용하였고, 이미지와 관련이 있는 논문입니다. 논문을 요약하면 다음과 같습니다.
- 두 이미지 간의 차이를 나타내는 metric은 크게 Quality metric과 Visibility metric으로 나눌 수 있다.
- Quality metric은 두 이미지 간의 차이를 계산을 통해 구할 수 있으며 PSNR, SSIM 등이 있다. 하지만 두 지표는 사람이 실제로 느끼는 차이를 잘 반영하지 못한다.
- 사람이 두 이미지를 봤을 때 느끼는 차이를 나타내는 Visibility metric을 예측하는 딥러닝 모델을 제안한다.

위 그림은 아래의 배심원들은 기존의 컴퓨터로 계산한 Quality metric들을 의미하고 각 테스트 샘플마다 quality metric을 이용하여 점수를 매기는 과정을 보여주고 있습니다. 이렇게 약간의 차이를 사람은 잘 느낄 수 있지만 기존의 Quality metric으로는 구분할 수 없기 때문에 Visibility metric이 필요하며 이 Visibility metric을 CNN을 통해 예측하는 과정을 논문에서 설명하고 있습니다.
- 논문의 Contribution
본 논문은 “사람이 인식하는 두 이미지 간의 시각적 차이” 를 CNN을 이용하여 예측하는 방법을 다루고 있습니다. 우선 CNN을 학습시키기 위해선 학습 데이터가 필요한데, 그 데이터는 사람이 직접 제작을 해야 하기 때문에 학습 데이터부터 취득을 해야 합니다. 본 논문에서는 우선 존재하는 이러한 데이터셋 자체가 부족하고 거의 없다시피 하므로 Public하고 비교적 규모가 큰 데이터셋을 제작 을 하였고 이게 이 논문의 첫번째 Contribution입니다.
또한 사람이 직접 취득한 데이터다 보니 Ground Truth로 사용하기엔 noisy할 가능성이 높습니다. 우선 전 세계에 있는 모든 사람의 분포를 담을 수 없을 뿐만 아니라, 직접 사람이 차이를 느낀 부분을 labeling을 해야 하는데, labeling을 하는 과정에서도 human error가 발생할 수 있기 때문에 통계적 모델링 방법으로 Ground Truth를 제작 하게 됩니다. 이게 이 논문의 두번째 Contribution입니다.
마지막으론 당연히 선행 연구들보다 성능이 좋았고, 이를 실제 application에 어떻게 적용하여 사용할 수 있는지 3가지 실험을 진행하였습니다. 또한 이 논문에서 다루고 있는 연구들을 기존 선행 연구에 적용을 하여 재학습을 시키면 성능이 향상되는 것도 확인을 하였습니다. 이러한 실험들을 통해 성능을 검증한 것 이 이 논문의 마지막 Contribution입니다.
- 논문의 방법론
논문에서 방법론을 소개하는 부분은 크게 “데이터셋을 제작하는 부분” 과 “CNN 구조를 설계하고 학습시키는 부분” 2가지로 구성이 되어있습니다.
“데이터셋 제작”
우선 “데이터셋을 제작하는 부분”에 대해 설명을 드리면 우선 Visible distortion 관련 소규모의 데이터셋들을 하나로 모아서 Stimuli 라는 본인들이 제작한 데이터셋을 구축을 하였습니다. 그 뒤에는 직접 사람에게 labeling을 시켜서 Ground Truth를 취득 하는 과정으로 진행이 되고 있습니다. 이 때 labeling이란 원본 이미지와 distortion이 존재하는 이미지를 동시에 보여주었을 때, distortion이 존재하는 이미지에서 어느 부분에서 distortion을 느끼는지를 pixel 단위로 marking 하는 것을 의미합니다. 저자들은 이 과정을 편하고 정확하게 수행하기 위하 아래와 같은 조건에서 실험을 진행하였습니다.

- 편의성을 위해 web 기반 software를 제작하여 labeling 진행
- 총 46명의 실험자로부터 labeling을 통해 visibility 마킹 데이터 취득
- 동일한 환경에서 여러 번에 나눠서 실험 진행하여 피로로 인한 부정확성을 줄임. 물론 보수도 제공
- 동일한 위치에 distortion 강도를 3단계로 나눠서 차례대로 마킹 진행
- 한 이미지에 대해서 3장의 Ground Truth 취득 가능
물론 더 많은 실험자에 대해서 데이터를 취득하면 좋겠지만 현실적으로 비용과 시간적인 측면을 고려해서 46명에 대해 실험을 진행한 것으로 보입니다. 이 분야에 대해 연구가 더 활발해진다면 더 큰 데이터셋이 나오지 않을까 기대해봅니다.
이제 제작한 데이터셋을 어떻게 Ground Truth로 사용하는지에 대해 설명을 하겠습니다. 본 논문에서는 이러한 실험을 통해 얻은 raw data를 그대로 Ground Truth로 사용하지 않고 앞서 contribution 부분에서도 설명 드렸듯이 여러 human error를 고려하여 통계적 모델링 방법을 사용하여 raw data를 재구성을 하게 됩니다. 본 논문에서는 labeling tool이 손에 익숙하지 않아서 생기는 error, 같은 이미지를 같은 사람에게 보여줬을 때 결과가 일치하지 않는 error, 이미지의 일부 영역은 아예 집중하지 않아서 마킹을 하지 않는 error 등을 대표적인 human error로 예시를 들고 있습니다.
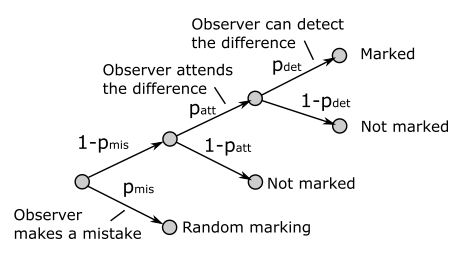
이 그림이 raw data를 통계적으로 처리하는 과정을 보여주고 있습니다. 이 부분에 대해서 간단하게 설명을 드리면 마킹 tool로 인해 발생하는 실수에 대한 확률 “mistake” , 실험자가 해당 픽셀에 주의를 기울일 확률인 “attend” , 실험자가 해당 픽셀에서 차이를 발견할 확률인 “detect” 크게 3단계로 구성이 되어있습니다.
“mistake” 의 경우 정신물리학 연구에서 흔히 사용되는 실수를 확률로 모델링하는 기법이며 일반적으로 0.01 값을 사용한다고 합니다.
“attend” 의 경우 사람이 모든 픽셀에 대해 잘 주의를 기울이면 문제가 없는데 간혹 굉장히 눈에 잘 띄는 차이이지만 실험자가 해당 영역을 아예 관찰하지 않는 경우도 발생한다고 합니다. 이러한 경우를 방지하기 위해 실험자가 해당 픽셀에 주의를 기울일 확률을 모델링합니다.
마지막으로 “detect” 의 경우 실험자가 해당 지역에 집중하였을 때 차이를 발견할 확률을 모델링합니다. 자세한 내용은 논문에서 확인하실 수 있습니다. 이러한 통계적 모델링을 통해 보다 더 정확한 Ground Truth를 제작할 수 있었다고 합니다.
“CNN 구조 설계 및 학습”
이렇게 취득한 데이터셋을 학습시키기 위한 CNN 구조를 제안하고 있습니다. 우선 두 이미지가 pair로 들어가야 하는데, 이러한 상황에서 자주 사용되는 Siamese CNN 기반으로 network 구조를 제안하였습니다.
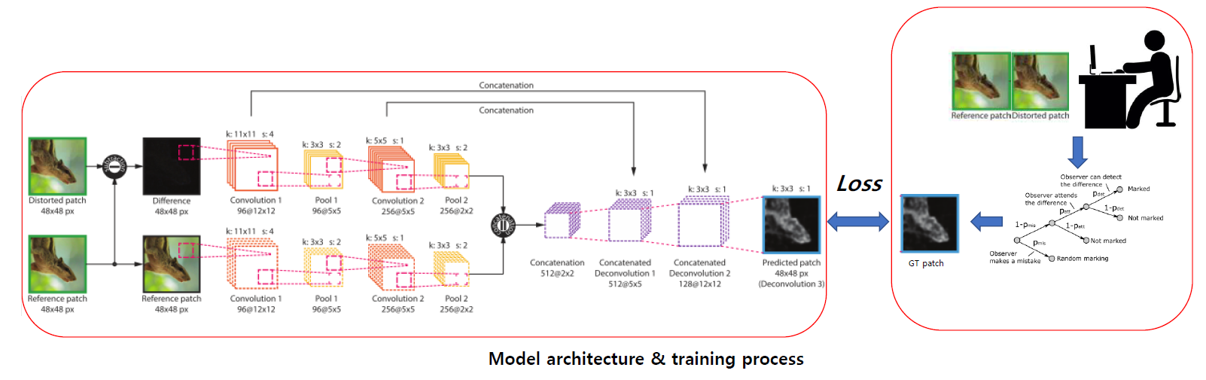
다만 기존의 Siamese CNN과는 다르게 각 branch 마다 weight를 sharing하지 않았고, 이미지를 48x48 patch로 분할하여 학습과 테스트를 진행하였습니다. 학습 관련 detail한 parameter들은 논문에서 확인하실 수 있습니다. 요점은 두 이미지를 CNN에 넣어서 visibility map을 출력하도록 모델을 구성하였고 학습을 시켰다는 점이며 선행 연구들과 비교하였을 때 우수한 성능을 달성하였다고 합니다.
- 대표적인 Application 소개
마지막으로 본 논문에서 제안하고 있는 3가지 application에 대해 설명을 드리도록 하겠습니다.
JPEG Compression
일반적으로 영상을 압축할 때 손실 압축과 비손실 압축 2가지로 나눌 수 있는데 그 중 손실 압축의 대표적인 방법으로 JPEG이 있습니다. 저희가 흔히 보는 .jpg , .jpeg 등의 확장자를 가진 이미지가 다 JPEG을 통해 압축한 이미지들입니다. 압축률을 높일수록 파일 크기는 줄어들지만 화질도 감소하게 됩니다. 이러한 점을 고려하였을 때, 이미지마다 더 압축을 시켜도 사람이 크게 열화를 느끼지 못하는 경우에는 더 압축을 해도 되지만 일반적으로는 그렇지 않고 고정된 압축률을 사용을 하고 있습니다. 즉, “사람이 느끼기에 괜찮은 정도” 를 알 수 있으면 압축률을 adaptive하게 가져갈 수 있습니다.
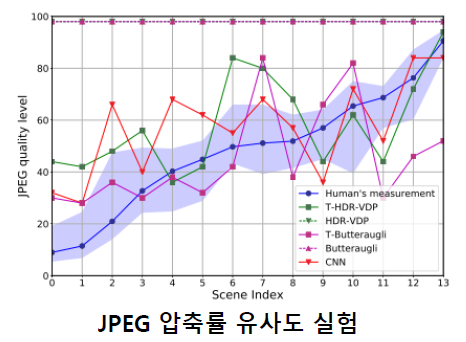
본 논문에서는 4AFC(four alternative forced choice)라는 실험 방법을 통해 사람이 느끼는 열화 정도와 본인들의 방법으로 찾은 열화 정도의 유사성을 비교하는 실험을 진행하였습니다. 실험 결과 사람의 경향(파란색 선)과 CNN의 경향(빨간색 선)이 비교적 일치하는 것을 확인할 수 있고, 대부분의 경우(14장 중 11장)에 CNN의 예측 결과가 사람의 경향보다 압축 정도를 적게 가져가므로 부가적으로 발생하는 부작용(사람이 열화를 인지함)은 거의 없다고 주장하고 있습니다. 본 논문의 방식을 사용하면 사람이 느끼기에 문제가 없을 정도로 압축을 하면서 고정 압축률을 사용하였을 때보다 약 60% 정도 file size를 줄일 수 있는 장점이 있습니다.
Super-Resolution
위의 JPEG 압축 실험과 유사하게 이미지 Super-Resolution에 대해서도 비슷한 실험을 진행하였고, 얼만큼 down sampling 한 뒤 Super-Resolution을 시켜야 사람이 열화라고 느끼는 지를 예측하는 실험을 진행하였습니다. 실험에는 1.1배 ~ 6배 down sampling을 하여 실험을 진행하였습니다.
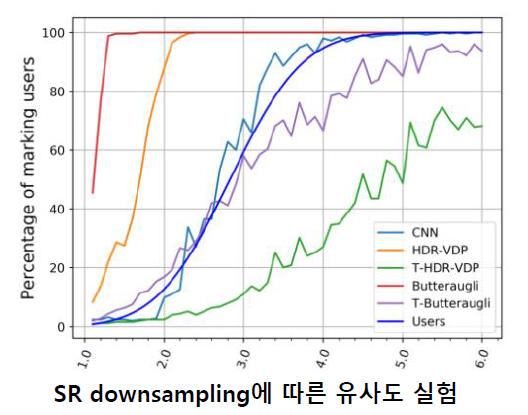
결과 그래프를 보면 사람의 경향성(파란색 선)과 CNN의 경향성(하늘색 선)이 거의 일치하는 것을 확인할 수 있습니다. 이러한 경향을 알면 Super-Resolution을 할 때 어느 정도까지 upscaling을 시킬 수 있는지를 별도의 User Test 없이 알 수 있다는 장점이 있으며, 이는 시간과 비용 절약에 큰 도움을 줄 수 있습니다.
Content-adaptive watermarking
마지막 사례는 실용적인 사례를 잘 보여주고 있습니다. 이미지에 티 안 나게 watermark를 삽입해야 할 때 어느 위치에 어느 강도를 주어야 할지를 파악할 때 본 논문의 방식을 사용할 수 있습니다. 기존의 경우 일일이 강도를 조절해가며 사람에게 보이는지 아닌지를 파악하는 과정을 거쳤는데 이를 간단히 대체할 수 있는 방법을 제안하고 있습니다.

위의 그림을 보면 왼쪽 column이 원본 이미지이고 가운데 column 이미지가 워터마크가 삽입된 이미지이며 오른쪽 column은 각 위치마다 삽입된 워터마크의 강도를 의미합니다. 흰색일수록 진하게 삽입을 한 것이며 육안으로 보기에 워터마크가 삽입된 이미지에서 워터마크를 찾기가 굉장히 어렵습니다.
3가지 사례 모두 본 논문의 연구를 실용적으로 사용하는 방법에 대해 다루고 있으며, 3가지 사례뿐만 아니라 이미지를 처리하는 모든 그래픽스 application 연구의 성능 조절에 본 연구를 활용할 수 있을 것으로 기대가 됩니다.
이미지 인식 분야 관련 논문 간단 리뷰
1. What Characterizes Personalities of Graphic Designs?
이 논문은 아래의 그림에서 알 수 있듯이 그래픽 디자인 이미지가 있으면 해당 이미지의 personality(성격)을 예측하는 딥러닝 모델을 제안하고 있습니다. 또한 이미지의 어떤 부분이 해당 성격에 긍정적인, 혹은 부정적인 영향을 주고 있는지를 나타내는 sensitive map까지 얻을 수 있습니다.
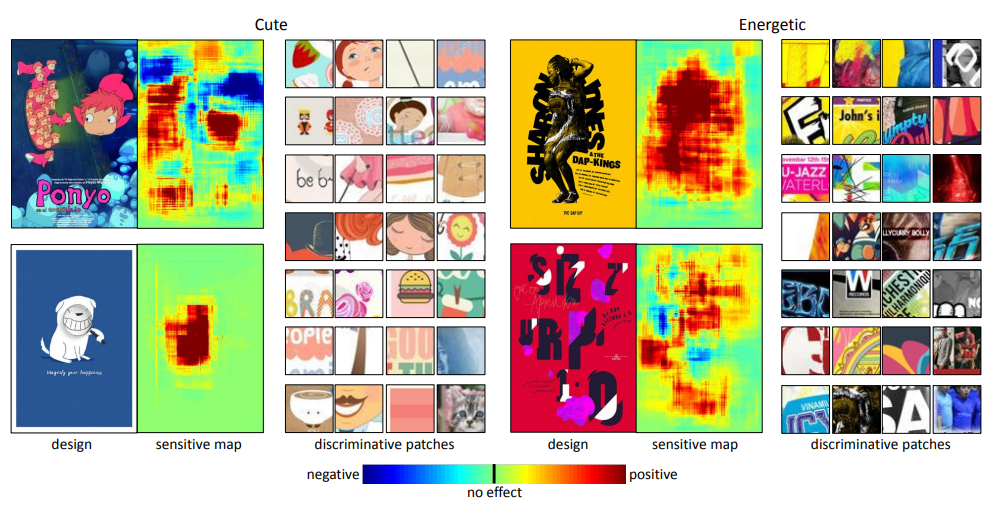
포스터 데이터셋을 이용하였으며 총 15가지의 Personality에 대해 분류를 하는 문제를 해결하였고, 선행 연구들에 비해 높은 정확도를 달성한 논문입니다. 개인적으로 연구를 하다가 직접 데이터셋을 취득해야 할 때 포스터 이미지들, 책 표지 이미지들을 활용하였었는데 비슷한 관점에서 다룬 논문이라 흥미로웠습니다. 또한 sensitive map도 비교적 정교하게 얻을 수 있어서 이를 활용할 수 있는 여러 방식이 있을 것 같습니다.
2. Semantic Soft Segmentation

이 논문은 제목에서 잘 나와있듯이 semantically meaningful region들을 soft하게 segmentation하는 연구를 다루고 있습니다. 기존 semantic segmentation, instance segmentation에 대해서만 논문을 읽었었는데 semantic soft segmentation 이라는 분야에 대해 처음 접할 수 있었던 논문이었습니다. 기술적인 자세한 내용은 본 논문을 참고하시면 좋을 것 같습니다.

이 논문의 방식을 통해 위의 그림처럼 관심있는 object만 남기고 배경을 제거하는데 사용할 수도 있고 혹은 기존의 배경을 다른 배경으로 바꾸는 데도 활용이 가능합니다. 이를 통해 여러 재미있는 응용 사례들이 나오지 않을까 기대해봅니다.
3. Neural Best-Buddies: Sparse Cross-Domain Correspondence

이 논문은 원본 이미지에 해당하는 특징점들(원)을 다른 도메인의 이미지에 대해서 찾는 연구를 진행하였습니다. 예를 들면 고양이와 사자 이미지를 준비하고 고양이의 코 영역을 선택하면 사자의 코 영역을 얻을 수 있게 됩니다. 이러한 연구를 Pairwise Keypoint Matching라 부르는데 주로 같은 도메인에 대해서 연구를 진행한 반면 본 연구는 다른 도메인에 대해서 접근을 한 점이 특징이라 할 수 있습니다. 즉 훨씬 어려운 문제에 대해 접근을 하였습니다.

이 연구를 이용한 사례를 예로 들면 위의 그림과 같이 1번째 column과 5번째 column이 모델에 pair로 들어가는 이미지이고 가운데 2, 3, 4번째 column은 두 이미지를 이용하여 가중치를 둬서 합성한 이미지입니다. 서로 다른 도메인의 이미지이지만 Keypoint matching을 통해 비교적 정확하게 이미지 합성을 하는 것을 확인할 수 있습니다. 이 연구 또한 실제 application에 잘 접목을 시키면 재미있는 결과들이 나올 것으로 기대가 됩니다.
4. FaceVR: Real-Time Facial Reenactment and Eye Gaze Control in Virtual Reality
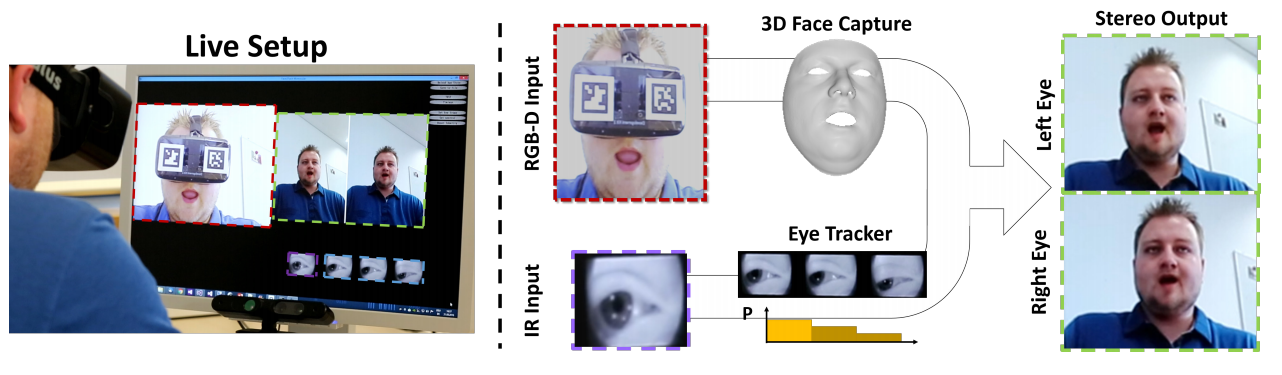
이 논문은 제목에서 알 수 있듯이 Virtual Reality와 관련이 있는 연구입니다. 입력으로 VR 고글을 통해 취득한 RGB-D input과 IR camera를 이용해 찍은 동공의 이미지를 이용하여 두 눈이 바라보고 있는 방향을 고려하여 고글을 쓰지 않았을 때의 얼굴을 합성해내는 연구를 진행하였습니다. 또한 이 모든 과정이 제목에 나와있듯이 실시간으로 처리가 가능합니다.

위의 그림은 input에 따른 output 얼굴 합성 결과를 보여주고 있으며, 아래 그림은 시선에 따라 얼굴의 변화를 합성하는 것을 보여주고 있습니다. 위의 row가 input이고 아래 row가 output인데 합성된 output 이미지지만 꽤 그럴싸한 것을 확인할 수 있습니다. 이를 통해 여러 application에 접목이 가능할 것으로 보여집니다.
결론
이번 포스팅에서는 SIGGRAPH 학회에서 재미있게 들었던 논문에 대해 리뷰를 진행하였습니다. SIGGRAPH에서 느낀 점 중에 가장 핵심은 다른 학회들에 비해 실제 생활과 연관이 있는, 즉 application 지향적인 연구들이 많다는 점 이었습니다. 저희가 연구를 하는 이유도 실생활에서 사용을 하는 것을 목표로 하는 경우가 많기 때문에 실생활에 딥러닝을 접목시키기를 원하시는 분들은 SIGGRAPH을 통해 많은 영감을 얻으실 수 있을 것이라 생각됩니다. 긴 글 읽어 주셔서 감사합니다. 다음 번에도 더 알찬 내용으로 찾아 뵙도록 하겠습니다. 감사합니다.
참고 문헌
- SIGGRAPH Paper Acceptance rate 자료
- What Characterizes Personalities of Graphic Designs? 논문
- Semantic Soft Segmentation 논문
- Neural Best-Buddies: Sparse Cross-Domain Correspondence 논문
- FaceVR: Real-Time Facial Reenactment and Eye Gaze Control in Virtual Reality 논문
- Dataset and metrics for predicting local visible differences 논문