Unsupervised Visual Representation Learning Overview: Toward Self-Supervision
안녕하세요, 이번 포스팅에서는 Unsupervised Learning 연구 분야 중에 하나인 Self-Supervised Learning 에 대해 소개를 드리고자 합니다.
이름에서 스스로 Supervision을 주어서 학습을 한다고 유추할 수 있으며 우리말로는 자기지도학습 이라고 부릅니다. 2018년 삼성 AI 포럼에서 AI 분야의 전설적인 존재인 얀 르쿤 교수는 Self-Supervised Learning이 미래의 먹거리이자 Real AI로 가기 위해선 이 분야가 발전해야 한다고 역설하였습니다.
전설의 얀 르쿤 교수가 집중을 하고 있는 분야이기도 하고, 실제로 학계에서도 요즘 굉장히 많은 주목을 받고 있는 Self-Supervised Learning이 무엇인지 설명 드리기 위해 대표적인 논문을 시간 순서로 간략하게 정리를 하면서 설명을 드릴 예정입니다.
또한, 같은 내용을 PR-12에서 발표한 영상 자료도 필요하신 분들은 참고하셔도 좋을 것 같습니다. 아래의 내용을 발표자료를 통해 발표한 25분 내외의 동영상입니다.
Self-Supervised Learning 이란?
딥러닝 모델을 학습시키기 위해 여러가지 요소를 고려해야 하지만, 제 개인적으론 가장 중요한 것은 양질의 데이터라고 생각합니다. 최근에는 학계에서 주로 사용하던 ImageNet을 넘어서 수천만장 규모의 데이터셋들이 공개가 되고 있고 자유롭게 저작권이 없는 Image들을 크롤링하여 자체적으로 데이터셋을 제작하여 사용하기도 합니다.
Supervised Learning(지도 학습)은 2010년대에 접어들면서 굉장히 높은 성능을 달성하였지만 그러한 성능을 달성하기 위해선 무수히 많은 양의 데이터가 필요하고, 데이터를 사용하기 위해선 각 샘플마다 labeling을 해주어야 하는 점이 많은 시간과 비용을 필요로 하게 됩니다.
이러한 단점들을 해결하기 위해 여러가지 연구 주제들이 나오고, 활발하게 연구가 진행이 되고 있습니다. 유사한 task에서 학습된 network의 weight를 가져와서 target task에 적용하는 Transfer Learning, Domain Adaptation 사례와, 가지고 있는 데이터셋 중에 일부만 labeling을 하여 학습을 시키는 Semi-Supervised Learning 사례, 주로 Segmentation에서 기존의 label (segmentation mask) 보다 적은 비용으로 얻은 label (class, point, scribble, bounding box 등)을 이용하여 학습을 시키는 Weakly-Supervised Learning 등이 있습니다. 이 외에 아예 label을 이용하지 않는 Unsupervised Learning이 있고, 쉽게 유추하실 수 있듯이 가장 성능을 내기 어려운 분야입니다.
이러한 Unsupervised Learning 중에 한 분야에 속하는 연구 주제가 바로 Self-Supervised Learning 입니다. 이름에서 유추할 수 있듯이 Supervision을 스스로 준다는 것을 의미하며, Unsupervised Learning 방식을 따라서 데이터셋은 오로지 레이블이 존재하지 않는(Unlabeled) 데이터만 사용을 합니다. 이때 사용되는 데이터는 image가 될 수도 있고, text, speech, video 등 다양한 종류의 데이터가 될 수 있습니다.
우선 Unlabeled 데이터들을 이용하여 사용자가 새로운 문제를 정의하며 정답도 사용자가 직접 정해줍니다. 이 때, 사용자가 정의한 새로운 문제를 논문 들에서는 pretext task 라고 부르고, 앞으로도 이렇게 부를 예정입니다. Network로 하여금 만든 pretext task를 학습하게 하여 데이터 자체에 대한 이해를 높일 수 있게 하고, 이렇게 network를 pretraining 시킨 뒤 downstream task로 transfer learning을 하는 접근 방법 이 Self-Supervised Learning의 핵심 개념입니다. 아직 정확히 와 닿지 않으실 거라 생각합니다. 그래서 실제 논문들이 제안한 pretext task들을 소개를 드리며 이해를 도울 예정입니다.
본 포스팅에서는 image 인식 분야 위주로 소개를 드릴 예정이며, text 데이터에 Self-Supervised Learning을 적용하여 큰 혁신을 가져온 논문으로는 여러분들이 많이 들어 보셨을 BERT, GPT 등이 있지만 이번에는 다루지 않을 예정입니다.
Pretext Tasks in Self-Supervised Visual Representation Learning
오늘 포스팅에서는 Image를 이용한 대표적인 pretext task를 7가지 정도로 추려서 소개를 드리려고 합니다. 2014년부터 작년까지 제안이 되었던 대표적인 논문들로 선정을 하였으며 시간 순으로 소개를 드리려 합니다. 제가 오늘 소개 드리는 방법 외에도 많은 연구들이 진행이 되고 있으며, Self-Supervised Learning 주제로 나온 논문들의 리스트를 잘 정리해 놓은 repository가 있어서 공유 드립니다.
Exemplar, 2014 NIPS
첫번째로 소개드릴 방법론은 ”Discriminative unsupervised feature learning with exemplar convolutional neural networks” 라는 논문에서 제안된 Exemplar 라는 이름의 pretext task입니다.

학습 데이터로부터 Considerable한 gradient를 가지고 있는 영역이 object가 존재할 법한 위치라고 판단하여 해당 영역을 patch로 crop하여 가져옵니다. 이렇게 하나의 image로부터 얻어온 patch를 Seed patch라 부릅니다.
각 image마다 얻어온 Seed patch에 저희가 일반적으로 augmentation에 사용하는 transformation들을 적용하여 patch의 개수를 늘려줍니다. 그 뒤, Classifier로 하여금 하나의 Seed patch로부터 생성된 patch들을 모두 같은 class로 구분하도록 학습을 시킵니다.
이 때 주목해야할 점은 하나의 image가 하나의 class를 의미하게 되는 것입니다. Self-Supervised Learning에서는 Unlabeled 상황을 가정하기 때문입니다. 이러한 방식을 이용하면 생기는 가장 큰 문제는 큰 데이터셋에 적용하기 어렵다는 점입니다. 예를 들어 ImageNet 데이터셋을 사용한다고 가정하면 학습 데이터가 약 100만장이니, Classifier는 100만개의 class를 구분하도록 학습이 되어야 합니다. 당연히 학습이 잘 안되고 학습에 필요한 memory도 굉장히 커지게 되는 문제가 발생합니다.
초기에 나온 연구라 명확한 한계점을 가지고 있지만, 그래도 Self-Supervised Learning의 연구의 시초가 되었고, pretext task를 제안하고 성능을 측정하여 공개하였다는 점이 의미가 큰 것 같습니다.
Context Prediction, 2015 ICCV
다음 소개드릴 방법론은 ”Unsupervised Visual Representation Learning by Context Prediction” 라는 논문에서 제안된 Context Prediction 또는 Relative Patch Location 라는 이름의 pretext task입니다.
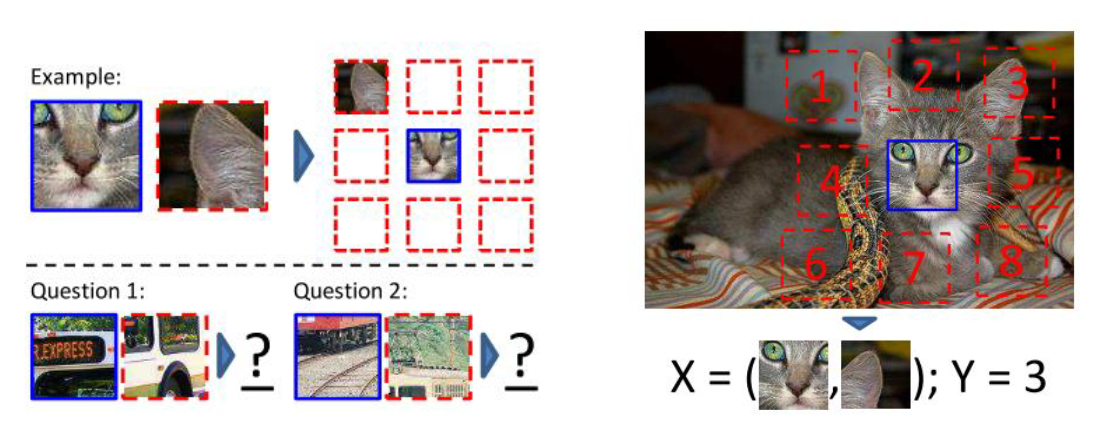
이름에서 유추할 수 있듯이, Patch 간의 상대적인 위치를 예측하는 Pretext task를 의미하며, 한 장의 Image로부터 가로 3칸, 세로 3칸, 총 9칸의 Patch를 얻은 뒤, 가운데 Patch를 기준으로 나머지 패치가 어느 위치에 있는지를 classifying 하도록 학습을 시킵니다.
위의 예시 그림으로 예를 들면 고양이의 얼굴(파란 네모)과 왼쪽 귀(빨간 점선 네모) 2개의 Patch를 network에 넣어주면 network는 1 이라는 출력을 하도록 학습을 하게 됩니다. 전체 Image에서 지엽적인 두 개의 patch만 보고 상대적인 위치를 맞추는 문제이다 보니 사람에게 물어봐도 높은 정확도를 달성할 수 없는 어려운 문제이며, 이를 잘 풀기 위해선 Image에 대해 전반적인 이해를 할 수 있어야 합니다. (위의 그림의 두가지 Question이 있는데 저는 단번에 답을 말할 수 없었습니다.)

Network에게 2장의 patch를 동시에 보여주어야 하기 때문에 network 구조에 약간의 변화를 주게 됩니다. AlexNet을 기반으로 pair classification을 위한 구조를 제안하였고, 학습 과정에서 발생할 수 있는 몇몇 trivial solution 들을 방지하기 위해 2가지 트릭을 사용하였습니다. 첫째론, 각 patch 간의 gap을 두어서 딱 붙어있지 않도록 구성하였고, 둘째론 정확히 상하좌우 n 픽셀 위치에서 patch를 취득하지 않고, x, y 방향으로 약간의 움직임을 추가하여 patch를 얻었다고 합니다. 하지만 이러한 트릭을 써도 trivial solution이 전부 해결되지는 않았다고 합니다. 자세한 내용은 논문에서 확인하실 수 있습니다.
Jigsaw Puzzle, 2016 ECCV
다음 소개드릴 방법론은 ”Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles” 라는 논문에서 제안된 Jigsaw Puzzle 이라는 이름의 pretext task입니다.
위에 Context Prediction 문제에선 9개의 Patch로부터 상대적인 위치를 예측했다면, 이번에는 뒤죽박죽 섞어 놓고 원래의 배치로 돌아가기 위한 permutation을 예측하는 문제를 의미합니다.

위의 그림의 sample image를 보면 가운데 patch를 기준으로 1번 위치(좌상단)의 patch와 2번 위치의 patch(상단)는 거의 비슷한 모양을 하고 있어서 애매성을 가중시킬 수 있으며, 이 sample image 뿐만 아니라 다양한 image들에서 이러한 문제가 발생할 수 있습니다. 그래서 이 논문은 비슷한 접근이지만 좀 더 명확한 답을 찾을 수 있는 jigsaw puzzle 문제를 제안하였습니다.
9개의 patch로 만들 수 있는 순열(permutation)은 9! = 362,880 개로 굉장히 많은 경우의 수가 존재하고, 이를 모두 학습에 이용한다면 Classifier는 362,880 class classification을 배워야 하는 문제가 발생합니다. 본 논문의 저자는 순열의 특성 상 비슷한 값을 가지는 순열이 많기 때문에 (ex, 123456789, 123456798) 모든 경우의 수를 다 이용하지 않고, 유사한 순열은 제거하면서 딱 100개의 순열을 사용하여 100-class classification을 학습시키도록 변화를 주었다고 합니다.
Context Prediction에서 Network 구조에 변화를 주었던 것처럼 본 논문도 AlexNet 기반으로 변화를 준 Context-Free Network(CFN) 구조를 제안하였습니다.
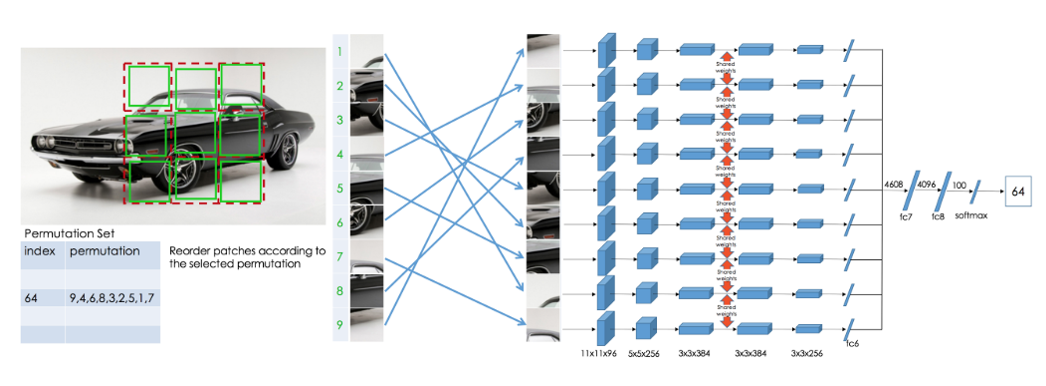
9장의 Patch를 input으로 받는 구조이고, 모두 weight를 share하는 Siamese Network 방식으로 구현을 하였고, AlexNet보다 적은 수의 Parameter를 이용하도록 설계하였다고 합니다. 자세한 구조는 논문을 참고하시면 좋을 것 같습니다.
Autoencoder-Base Approaches
이번에는 하나의 논문을 소개 드리는 것이 아니고, 비슷한 접근 방식으로 진행된 4가지의 논문을 간략하게 소개 드리겠습니다. 4가지 방식 모두 Autoencoding 방식이며 방식이 다르고 이름도 다릅니다.
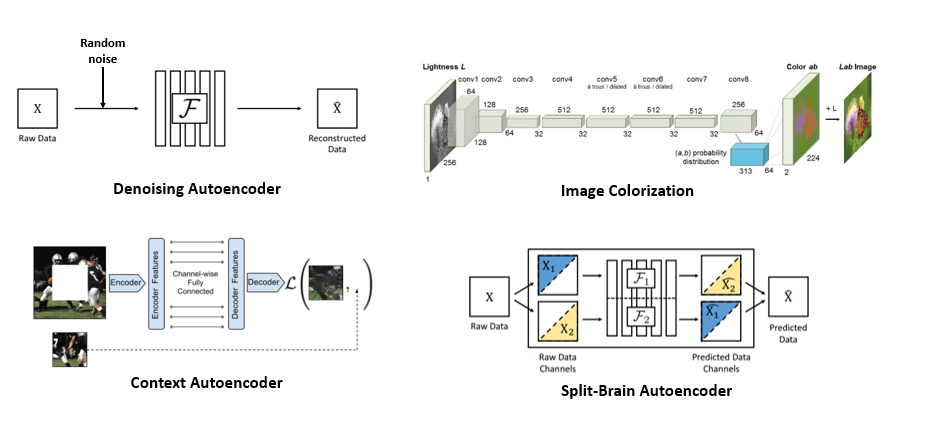
우선 Denoising Autoencoder 는 워낙 유명한 방식이며 input image에 random noise를 주입한 뒤 복원을 하도록 학습을 시키는 방식입니다.
다음 소개드릴 Image Colorization 은 2016년 ECCV에서 발표된 논문이며 1channel image로부터 3channel color image로 생성해내는 것을 학습시키는 방법을 제안하였고 이 때 사용한 Encoder를 가져와서 Self-supervised learning task에 적용을 한 결과를 제시하고 있습니다.
다음 Context Autoencoder 는 2016년 CVPR에서 발표된 논문이며 image의 구멍을 뚫은 뒤 그 영역을 복원하는 것을 학습시키는 방식을 제안하고 있습니다.
마지막으로 Split-Brain Autoencoder 논문은 2017년 CVPR에 발표된 논문이며 Image Colorization의 후속 연구라고 할 수 있습니다. 다채널 image에서 channel을 쪼갠 뒤, 각각 channel을 예측하도록 학습을 시키는 방식에서 Split-Brain 이라는 이름이 붙게 되었으며, 예를 들면 RGB-D image에 대해 RGB image를 F1에 넣어서 Depth image를 예측하도록 학습을 시키고, Depth image를 F2에 넣어서 RGB image를 예측하도록 학습을 시킨 뒤 두 결과를 종합하는 방식으로 학습이 진행이 됩니다.
Count, 2017 ICCV
다음은 ”Representation Learning by Learning to Count” 라는 논문에서 제안된 Count 라는 pretext task입니다.
앞선 Context Prediction, Jigsaw Puzzle, Autoencoding 방식들은 input image에 무언가의 변형을 준 뒤 이를 원 상태로 돌아오도록 학습을 하는 방식을 이용했다면, 이 방식은 이러한 패러다임에서 벗어나서 image로부터 특징 값들을 vector 형태로 추출하여 비교하는 방식을 제안하였습니다. 이해를 돕기 위해 논문의 그림을 보며 자세한 설명을 드리겠습니다.

위의 그림에서는 강아지 사진에 대해 4개의 특징 값 (코, 눈, 발, 머리)가 가상으로 존재한다고 가정합니다. (Label로 주는 것이 아니고 가상으로 존재한다고 생각하면 됩니다.) 이러한 특징 값들은 위의 예시와 같이 image를 4조각으로 쪼개면 특징 값도 나눠 가져가게 됩니다. 하지만 image를 자르지 않고 단순히 rotation을 시키거나 scale을 바꿔주는 등의 변화를 가하면 특징 값 자체는 유지가 됩니다. 이러한 발상에서 착안하여 아래와 같은 학습 방법을 제안합니다.

우선 input image x (강아지 사진)에서 일정 구역(노란 실선)을 정한 뒤 이 구역에 downsampling(D)을 적용하여 1장의 patch를 얻고, tiling(T)을 적용하여 4장의 patch를 얻습니다. 그 뒤 위에 소개 드렸던 다른 pretext task 논문들과 유사하게 weight를 sharing하는 AlexNet에 통과시켜서 마지막에 feature vector를 얻습니다. 그 뒤, downsampling을 하여 얻은 patch와 tiling을 해서 얻은 4장의 patch의 합이 같아지도록 학습을 시키며 이 때는 l2 loss가 사용이 됩니다.
하지만 network가 모든 feature vector들을 0으로 출력하면 위의 loss를 0으로 쉽게 만들 수 있습니다. 이러한 trivial solution을 피하기 위해 input image x 가 아닌 다른 image y (배 사진)을 random 하게 가져와서 downsampling을 적용한 뒤 x에 대해 추출한 feature vector들과 값이 달라지도록 해주는 contrastive loss를 추가하여 loss function을 설계하였습니다.
Multi-task, 2017 ICCV
다음은 ”Multi-task Self-Supervised Visual Learning” 라는 논문에서 제안된 Multi-task Learning 방식입니다.
Multi-task Learning이란 여러가지의 task를 동시에 학습하면서 상호 보완적인 효과를 보는 학습 방법을 의미합니다.
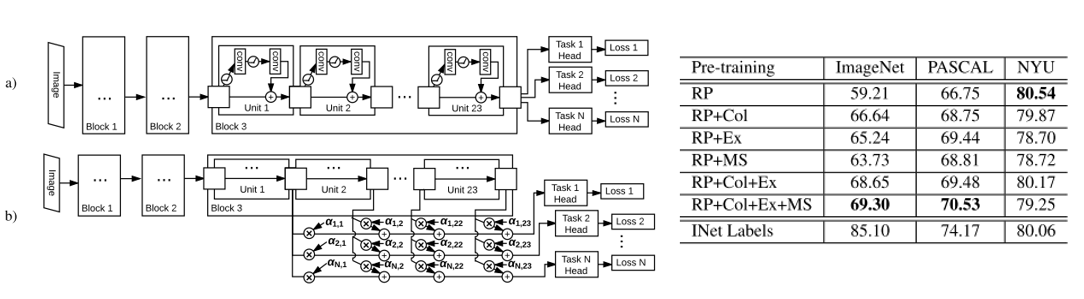
이러한 아이디어를 Self-Supervised Learning에 적용하여 재미를 본 논문이며, 위에서 소개 드렸던 Relative Patch Location(Context Prediction), Colorization, Exemplar 방식과, video 기반의 Self-Supervised Learning 방식 중에 하나인 Motion Segmentation까지 총 4개의 pretext task를 동시에 학습시켜서 기존 방식들보다 좋은 성능을 달성할 수 있음을 보여주고 있습니다.
Rotation, 2018 ICLR
마지막으로 소개드릴 방법은 ”Unsupervised representation learning by predicting image rotations” 라는 논문에서 제안된 Rotation 이라는 pretext task입니다.
위의 방법들 중 가장 이름이 직관적이며 방식도 매우 단순합니다. Input image가 있으면 이 image에 0도, 90도, 180도, 270도 회전을 random 하게 준 뒤, 원본을 기준으로 이 image가 몇도 rotation이 적용되었는지를 구분하는 4-class classification 문제입니다.
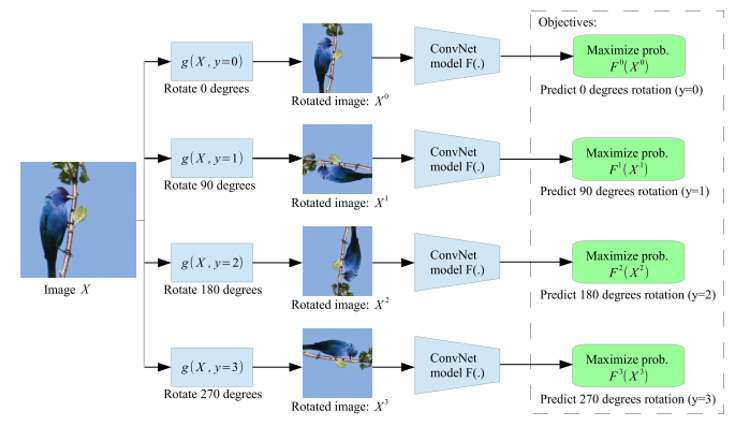
본 논문에서 실험에서 사용한 ImageNet, CIFAR-10 등 대부분의 데이터셋은 사람이 취득한 image들로 구성이 되었고, 사람은 보통 사진을 찍을 때 up-standing 하게 사진을 찍기 때문에 따로 데이터셋을 구성할 때 별다른 필터링을 거치지 않았다고 합니다. 다만 축구공과 같이 둥그런 object의 경우 회전을 가하여도 구분이 되지 않는 sample 들은 학습에 안 좋은 영향을 줄 수 있긴 합니다만 개수가 많지 않아서 따로 걸러내지 않고 사용하는 것 같습니다. 또한 Unsupervised Learning의 관점이기 때문에 image를 걸러내면 순간 Unsupervised가 아니게 됩니다.
Network는 Network-In-Network(NIN)을 기반으로 RotNet 이라는 구조를 제안하였고, 학습 시에 batch를 구성할 때 각 image마다 4가지 rotation 중 하나를 random하게 적용하는 방식보다, 각 image에 대해 4가지 rotation을 다 적용하여 한번에 network가 4가지 image를 동시에 보도록 학습을 시키는 것이 성능이 더 좋았다는 등의 technique도 이용하고 있습니다.
또한 rotation을 2가지만 사용하거나 8가지를 사용하는 방법도 적용해보았으나 4가지를 사용할 때 가장 성능이 좋아서 4가지 rotation을 사용하였습니다. 더 자세한 내용은 논문을 참고하시면 좋을 것 같습니다.
Task & Dataset Generalization of Self-Supervised Learning
위에서 총 10편의 논문을 간단히 소개드렸는데요, 이렇게 각각 논문에서 제안한 pretext task로 network를 학습을 시키는 이유는 단지 그 pretext task를 잘 풀기 위함이 아니라, 이러한 방식으로 Unsupervised pretraining을 시켜서 다음에 이어질 task인 downstream task에 이용하기 위함입니다.
그래서 unsupervised pretraining의 효과를 확인하기 위해 논문 들에서는 Self-Supervised Learning으로 Network를 pretraining 시킨 뒤 모든 weight들을 freeze 시킵니다. Pretraining을 통해 얻은 weight들이 얼마나 feature를 잘 뽑는지, representation을 얼마나 잘 배웠는지 에 초점을 두기 때문입니다.
그 뒤 마지막 layer에 linear classifier를 붙여서 logistic regression을 통해 downstream task를 학습을 시켜줍니다. 이 때 downstream task는 supervised learning 방식으로 학습이 진행되며, 이 부분이 처음에는 혼동을 일으키기도 합니다. 가장 혼동을 일으키는 실험인 ImageNet classification task에 대해 설명을 드리겠습니다.
Task Generalization: ImageNet Classification
대부분의 논문들에서 Self-Supervised Learning에 사용하는 데이터셋인 ImageNet 데이터셋을 이용한 실험 결과입니다. 이 부분이 혼동을 일으키는 이유는, Self-Supervised Learning을 할 때는 ImageNet 데이터셋을 unlabeled 형태로, 즉 image들만 이용해서 학습을 시키고, downstream task에서는 ImageNet 데이터셋을 image와 label을 모두 이용하여 Supervised Learning으로 학습을 시키기 때문입니다. Self-Supervised Learning과 Downstream Task에서 같은 데이터셋을 사용하기 때문에 생기는 문제이며, label이 있으면 그냥 처음부터 Supervised Learning으로 학습을 시키면 되지 않느냐는 질문이 나올 수 있는 부분입니다.
제가 처음에 결과를 보고 들었던 생각이 위의 질문이었는데 weight를 freeze 시키는 점에 주목을 하면 결과가 이해가 잘 될 수 있습니다. Weight를 freeze시킨다는 건 feature extractor를 고정시킨다는 것과 동일한 뜻이며, 여기에 굉장히 단순한 linear layer 하나만 붙여서 학습을 시켜서 좋은 성능을 내기 위해선 전적으로 feature extractor가 많은 역할을 수행하여야 합니다. 즉 feature extractor가 얼마나 성능이 좋은지 를 간접적으로 확인할 수 있는 방법이 위의 방법이라고 생각하시면 될 것 같습니다.
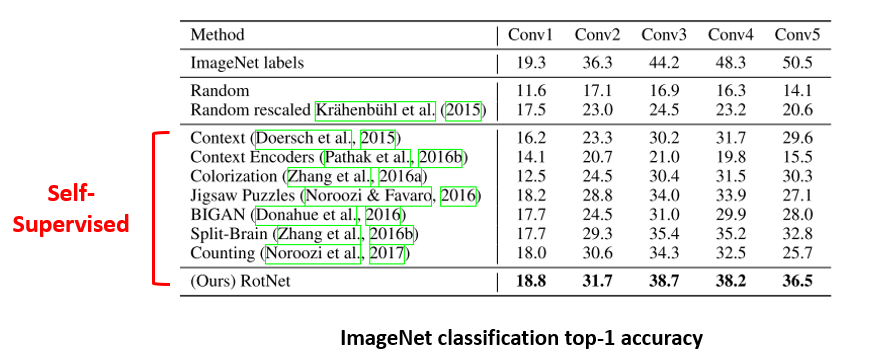
위의 표는 ImageNet Classification의 Top-1 Accuracy들을 보여주고 있으며, 첫번째 row의 ImageNet labels 결과는 ImageNet 데이터셋을 이용하여 Supervised 방식으로 학습을 시키고 Conv layer들을 freeze 시킨 뒤, 각 Conv layer 뒤에 linear layer를 붙여서 학습을 시켜 얻은 결과를 의미합니다. 당연히 기존 AlexNet은 3개의 Fully-Connected Layer를 사용하였기 때문에 AlexNet의 성능보다 많이 떨어지게 됩니다.
그 다음 Random, Random rescaled는 Conv layer들을 random initialization 시킨 뒤 여기에 linear layer를 붙여서 학습을 했을 때의 성능을 의미합니다. 이 경우에는 feature extractor는 아무런 정보도 담고 있지 않기 때문에 오로지 linear layer에 의존하여 학습을 하여야 하기 때문에 linear layer를 사용할 때의 lower bound 성능으로 이해를 할 수 있습니다.
빨간색 선으로 묶어 둔 부분은 Self-Supervised 방식으로 Conv layer들을 pretraining 시킨 뒤 freeze하고 linear layer를 붙여서 학습을 했을 때의 성능을 의미하며 이 표는 Rotation 논문에서 가져온 자료입니다. 위에서 BIGAN을 제외한 나머지 방법들은 소개를 드렸고 대부분 고만고만한 성능을 보이지만 Rotation 방식이 그나마 가장 좋은 성능을 보이고 있습니다. 하지만 여전히 ImageNet labels 보다는 성능이 많이 부족한 것을 확인할 수 있습니다. 그래도 label을 쓰지 않고 Conv layer들을 학습시켜도 label을 사용하였을 때의 feature extractor와 어느 정도는 비슷한 품질을 보일 수 있음에 의의를 둘 수 있습니다.
Dataset Generalization: PASCAL VOC
이번 실험 결과는 Self-Supervised Learning에서는 ImageNet 데이터셋을 이용하고, Downstream task로는 PASCAL VOC의 Classification, Object Detection, Segmentation task를 이용할 때의 결과를 설명드리겠습니다. Task Generalization은 feature extractor의 성능을 평가한다는 부분이 다소 와 닿지 않았는데, Dataset Generalization 실험은 확실하게 이해가 되는 결과인 것 같습니다.
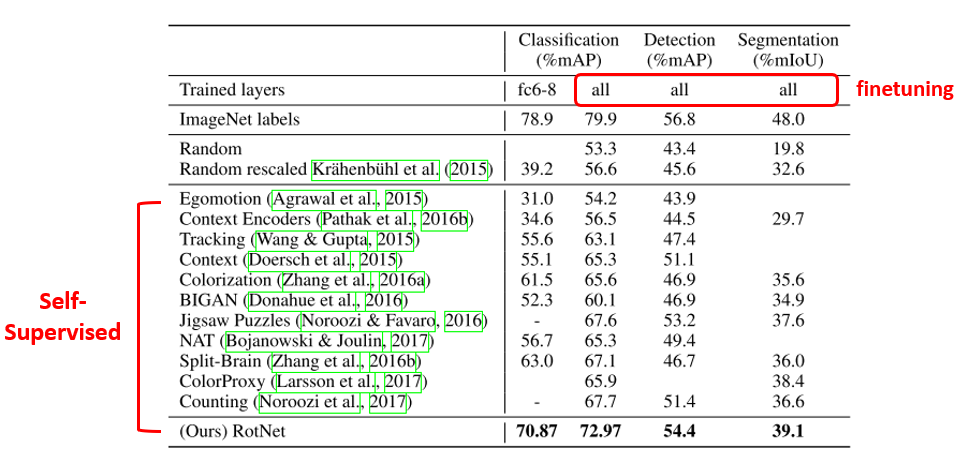
ImageNet 실험과 사용한 방식들은 거의 비슷하고 이 결과에는 Video를 이용한 Self-Supervised Learning 방식들도 실험에 추가를 하였습니다. 역시나 Rotation의 결과가 가장 좋았고, 이번엔 Linear layer를 붙여서 feature extractor의 품질을 보는 것이 아니라, ImageNet을 이용하여 pretraining을 시킨 뒤 다른 데이터셋으로 finetuning을 하였을 때 얼마나 성능이 좋은 지 를 보는데 집중을 하였다고 생각하시면 될 것 같습니다.
대부분 저희가 다른 데이터셋에 대해 학습을 시킬 때, 일반적으로 ImageNet pretrained weight을 이용하는 경우가 많은데, 이러한 방식을 통해 얻은 성능이 위의 표에 ImageNet labels 결과입니다.
Random, Random rescaled 결과는 말 그대로 random weight로부터 학습을 한 결과이며 다른 말로는 scratch로부터 학습을 했다고도 부르며, 그 때의 결과를 보여주고 있습니다. 성능이 낮은 이유는 실험을 전체 30 epoch밖에 돌리지 않았기 때문이며 실제로 더 긴 epoch를 돌리면 scratch로부터 학습을 해도 준수한 성능을 얻을 수 있긴 합니다. 하지만 ImageNet pretrained weight를 쓰면 얻을 수 있는 이점 중에 하나인 학습의 빠른 수렴을 강조하기 위해 epoch를 적게 두고 실험을 한 것으로 보입니다.
대부분의 Self-Supervised 방식이 논문이 발표된 시간 순으로 성능이 좋아지는 것을 확인할 수 있고, Rotation을 사용하였을 때의 결과는 Classification이나 Segmentation에서는 다소 낮은 성능을 보였지만 Object Detection에서는 거의 근소한 차이의 성능을 달성할 수 있음을 보여주고 있습니다. 실제로 Object Detection에서 ImageNet pretraining이 과연 최선의 방법인가? 라는 식의 논문들을 뒷받침해줄 수 있는 결과라고 생각이 됩니다.
Self-Supervised Learning을 의미 있게 사용하려면?
Network를 학습시킬 때 default로 ImageNet pretraining을 하는 경우가 대부분입니다. 하지만 Natural Image가 아닌 다른 Domain (ex, Depth image, CT, MRI 등 의료 image 등)에 대해 학습을 해야 하는 경우를 가정하면, 해당 Domain에서 ImageNet 역할을 해줄 대량의 데이터셋을 구축하기 위해선 Labeling을 해야 하고 이 과정에서 많은 돈과 시간이 소요가 될 수 있습니다.
하지만 Self-Supervised Learning을 이용한다면 오로지 많은 수의 Image만 있으면 Network를 pretraining 시킬 수 있기 때문에 Natural Image가 아닌 Domain 에서 ImageNet과 같이 pretraining 시킬 데이터셋이 없다면, 혹은 Image는 많은데 Label이 없다면, Self-Supervised Learning이 좋은 대안이 될 수 있을 것이라 생각합니다.
결론
이번 포스팅에서는 Unsupervised Learning 중에 한 분야인 Self-Supervised Learning에 대해 소개를 드리는 글을 작성해보았습니다. 그리고 Image를 이용한 대표적인 Self-Supervised Learning 논문들을 간단히 리뷰를 하였고 총 10가지의 pretext task를 소개드렸습니다. 또한 성능을 Task Generalization, Dataset Generalization 2가지 방식으로 측정을 하는 이유, 결과 등을 설명을 드렸습니다. 마지막으론 Self-Supervised Learning을 의미 있게 사용하기 위한 제 생각을 정리해보았습니다. 요즘 굉장히 핫한 분야이며 단순히 Image 뿐만 아니라 NLP, RL 쪽에서도 논문이 많이 나오는 분야라 주목하셔도 좋을 것 같습니다. 다음에는 Self-Supervised Learning의 최신 연구들도 소개를 드리도록 하겠습니다. 감사합니다!
comments powered by Disqus