Tutorials of Object Detection using Deep Learning [5] Training Deep Networks with Synthetic Data Bridging the Reality Gap by Domain Randomization Review
안녕하세요, Tutorials of Object Detection using Deep Learning 다섯 번째 포스팅입니다. 이번 포스팅에서는 Object Detection의 성능 중 정확도를 개선하는 방법 중 Domain Randomization 기법을 이용한 논문에 대해 설명을 드릴 예정입니다. 오늘 리뷰할 논문의 제목은 “Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization” 이며 NVIDIA에서 2018년 CVPR Workshop에 발표한 논문입니다. 논문의 내용 중에 핵심적인 부분만 글로 작성할 예정이며 더 자세한 부분은 해당 논문 을 참고하시면 좋을 것 같습니다.
이전 포스팅들은 다음과 같습니다.
Tutorials of Object Detection using Deep Learning: [1] What is object detection
Tutorials of Object Detection using Deep Learning: [2] First Object Detection using Deep Learning
Tutorials of Object Detection using Deep Learning: [3] The application of Object Detection
Tutorials of Object Detection using Deep Learning: [4] How to measure performance of object detection
Introduction
Deep neural network를 학습시키는 방법론에 대한 연구는 과거에도, 최근에도 굉장히 많이 다뤄지고 있습니다. 이러한 논문들은 주로 MNIST, CIFAR-10, LSUN, COCO, VOC 등 공개된 데이터셋에 대해서 성능을 검증합니다. 하지만 저희가 실제 현업에서 Deep neural network를 적용하기 위해서는 직접 데이터를 취득하고 가공해야 하는 과정이 필수로 들어가게 됩니다. 이 논문에서는 Object Detection을 이용하여 자동차를 인식하는 문제에 대해 다루고 있습니다.
직접 데이터셋을 구축해야 하는 경우, 데이터를 취득하고 Labeling을 하는데 많은 시간과 비용이 드는 문제가 있습니다. 이러한 문제를 해결하기 위한 선행 연구로 graphic simulator를 이용하여 실제 이미지와 비슷하게 생긴 이미지를 생성하는 연구들이 많이 존재합니다. 하지만 이렇게 graphic simulator로 이미지를 생성하는 과정도 simulator를 제작하는 시간과 비용, 인력 등이 필요한 것은 마찬가지이며 이 또한 한계라고 주장하고 있습니다.
본 논문에서는 이러한 점에 주목해서 실제 데이터를 많이 모으기 힘든 상황에서 OpenAI의“Domain Randomization” 이라는 기법을 Object Detection 문제에 적용하여, 저비용으로 대량의 이미지를 합성하여 데이터셋을 만들고, 정확도를 향상시키는 방법에 대해 제안하고 있습니다.
본 논문의 Contribution을 정리하면 다음과 같습니다.
- Domain Randomization 기법을 Object Detection에 적용하는 방법을 제안
- Domain Randomization에 “flying distractors”라는 새로운 요소를 제안하여 정확도를 향상
- Domain Randomization의 주요 parameter들에 대한 분석을 통해 각각의 중요성을 평가
Previous Work
Synthetic 데이터셋
Deep neural network를 학습시키기 위해 이미지를 합성하여 만드는 연구는 다양하게 진행이 되어왔습니다. 논문에서 예시로 든 Synthetic 데이터셋 중 Object Segmentation 혹은 Object Detection과 관련이 있는 데이터셋은 다음과 같습니다.
- SYNTHIA (http://synthia-dataset.net/)
- GTA V (https://arxiv.org/pdf/1608.02192.pdf)
- Sim4CV (https://sim4cv.org/#portfolioModal2)
- Virtual KITTI (http://www.europe.naverlabs.com/Research/Computer-Vision/Proxy-Virtual-Worlds)

각각의 데이터셋은 링크를 들어가시면 자세하게 확인이 가능하며 본 논문에서는 비교군으로 Virtual KITTI를 사용하였습니다. Virtual KITTI 외에 나머지 데이터셋도 굉장히 고 퀄리티의 Synthetic 데이터셋이라 혹시 관심있으신 분들은 참고하여도 좋을 것 같습니다.
Synthetic 데이터셋을 이용한 선행 연구
이러한 Synthetic 데이터셋을 이용하여 deep neural network를 학습시키는 선행 연구는 “On Pre-Trained Image Features and Synthetic Images for Deep Learning” 이란 연구가 있습니다. 본 논문과의 차이점은 선행 연구에서는 pretrained weight를 사용하며 앞 단의 layer는 freezing시키는 식으로 fine-tuning을 하는 반면, 본 논문에서는 freezing시키는 방법을 사용하지 않는 것이 더 성능이 좋다고 주장을 하고 있습니다.
또한 다른 선행 연구로는 “Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks?” 라는 제목의 논문이며 Photorealistic Synthetic 데이터셋을 이용하여 자동차를 detection하는 문제를 해결하였습니다. 본 논문과 굉장히 비슷한 문제 상황이며, 단지 차이점으론 선행 연구는 Photorealistic Synthetic 데이터셋을 사용하였고, 본 논문은 Domain Randomization 기반의 Synthetic 데이터셋을 사용한 점이 있습니다.
이제 본 논문의 주가 되는 Domain Randomization에 대해 설명을 드리겠습니다.
Domain Randomization
본 논문에서 사용하고 있는 Domain Randomization은 아래 그림 2 에 잘 제시가 되어있습니다.
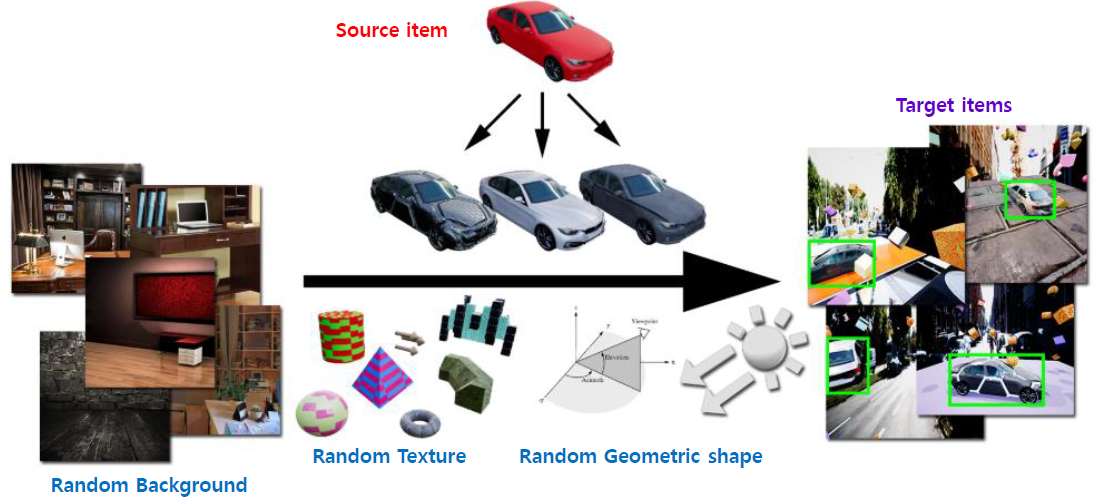
위 그림에서 볼 수 있듯이, 우리가 찾고자 하는 source item, 즉 object(자동차)의 3D 모델과, 임의의 배경, 텍스처 이미지들이 준비물이 됩니다. 이 때 임의의 배경 이미지는 기타 다른 데이터셋에서 가져오면 되고, 가장 좋은 것은 실제 환경과 유사한 배경(자동차를 예를 들면 도로 배경)이면 좋지만 그렇지 않은 배경을 이용하여도 무방한 것으로 보입니다. 실제로 논문에서 제시한 그림은 실내 이미지를 사용한 것을 확인할 수 있습니다. 또한 본 논문에서 “flying distractors” 라 부르는 임의의 geometric shape를 이용하여 더 좋은 성능을 낼 수 있다고 설명하고 있습니다. 이러한 방식으로 임의의 배경에 임의의 텍스처를 삽입하고, source item을 임의의 geometric shape를 이용하여 임의의 위치에 합성하면 Object Detection 학습에 필요한 이미지와 Label(bounding box annotation)을 쉽게 제작할 수 있습니다.
그림 3은 논문에서 설명하고 있는 구체적인 Domain Randomization 기법, flying distractors 를 보여주고 있습니다.

이제 생각해볼 점은, 이렇게 생성한 이미지가 과연 realistic한지, 그리고 이러한 이미지로 학습을 시키는 것이 좋은 정확도를 달성하는데 도움이 될 수 있을지 입니다. 먼저 첫번째 질문에 대한 대답은 “No” 입니다.

그림 4를 보시면 윗줄은 Virtual KITTI dataset, 아랫줄은 Domain Randomization을 이용해 생성한 이미지를 의미합니다. 한눈에 보기에도 아래의 이미지들이 훨씬 조잡하고 이상하다고 느끼실 겁니다. 하지만 Domain Randomization을 이용하면 좋은 점이, Virtual KITTI와 같이 공을 들여서 데이터를 생성해내는 것보다 훨씬 간단하고 빠르게 이미지를 생성이 가능하다는 점입니다. 본 논문에서는 Unreal Engine을 이용하여 1200x400 해상도의 이미지를 초당 30장씩 생성할 수 있다고 제시하고 있습니다. Virtual KITTI의 경우 segmentation, depth 계산, optical flow 계산 등 여러 복잡한 계산이 수반되어서 Domain Randomization에 비해 더 많은 시간이 소요되며, Virtual KITTI 논문에서는 1242x375 이미지를 생성할 때 초당 약 5~8장 생성이 가능하다고 제시하고 있는 점을 보면, 더욱 빨리 이미지를 생성할 수 있으며, 난이도 또한 훨씬 낮다는 장점이 있습니다.
이제 생각해볼 점은, 이렇게 쉽고 빠르게 만들어 낸 조잡한 이미지들로 학습을 시키면 정확도가 더 좋을 지 당연히 의문을 품을 수 있습니다. 이에 대한 대답은 “Yes” 입니다. 물론 엄밀하게 따지면 동등한 비교는 아닙니다. VKITTI 데이터셋은 약 2500장인 반면 Domain Randomization으로 생성한 데이터셋은 약 10만장으로 개수가 많이 차이가 납니다. 이 점에 대해서는 논문에서도 언급을 하고 있습니다.
Although our approach uses more images, these images come essentially for free since they are generated automatically. Note that this VKITTI dataset was specifically rendered with the intention of recreating as closely as possible the original real-world KITTI dataset (used for testing).
동등한 비교는 아니지만, 본 논문의 요지를 생각해볼 때, VKITTI보다 나은 성능을 보이는 것이 목적이 아니라, 데이터가 부족해서 생성을 해야 하는 상황에서 VKITTI와 같이 세세하고 복잡하고 느린 과정을 거치지 않아도 손쉽게 VKITTI와 거의 유사한 성능을 내는 것을 목적 으로 하고 있기 때문에 큰 문제는 없을 것 같다고 생각합니다. 이를 감안해서 결과를 확인하시면 좋을 것 같습니다.
실험 결과
이제 설명드릴 내용은 Domain Randomization을 이용하여 데이터셋을 합성하였을 때 얼마나 정확도가 좋아지는지에 대한 내용입니다.
우선 Object Detection의 대표적인 방법론들에 대해 VKITTI로 학습하였을 때와, Domain Randomization을 이용하여 학습시켰을 때의 각각의 Real-world KITTI test set 500장에 대한 정확도를 측정한 결과는 아래 그림 5와 같습니다.
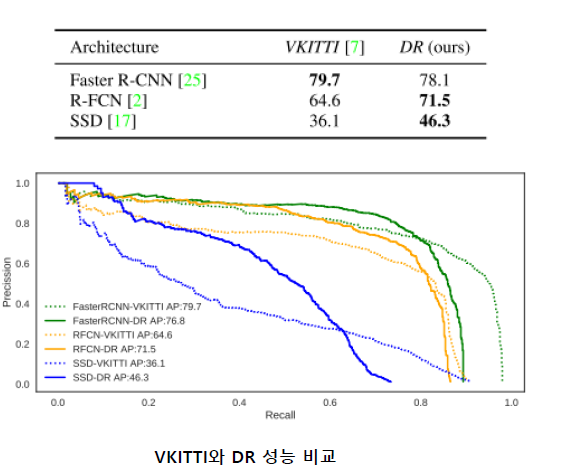
Faster R-CNN에서는 약간 VKITTI에 비해 낮게 측정이 되었지만, R-FCN, SSD에서는 VKITTI에 비해 꽤 정확한 수치를 보이는 것을 확인할 수 있습니다. 비슷하기만 해도 좋은 상황에서 더 좋은 성능을 보이고 있습니다.(물론 더 많은 학습 데이터를 사용하였지만..)
또한 그림 6에서는 실제 Detection 결과를 예시로 보여주고 있습니다.

위의 그림은 Faster R-CNN을 이용한 결과이며, VKITTI와 Domain Randomization에서 모두 실제 이미지는 학습에 사용하지 않았음에도 불구하고 실제 이미지에 대해 정확하게 예측을 하는 것을 보여주고 있습니다.
마지막으로 그림 7 에서는 실제 이미지를 이용하여 fine-tuning을 하는 상황을 가정하고, 그 때의 정확도를 비교하고 있습니다.
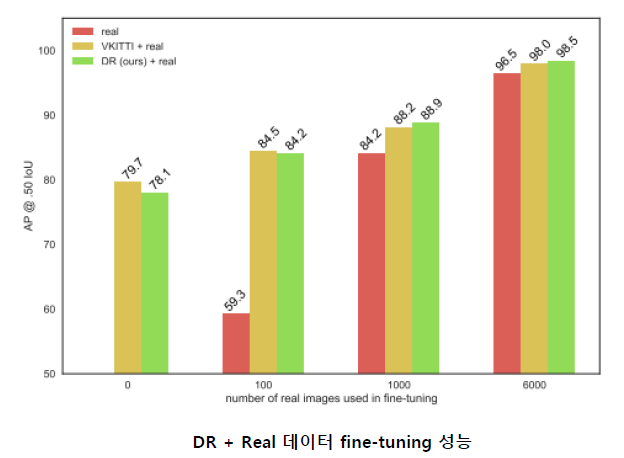
실제 상황을 가정하면, 초기에는 데이터가 부족할 수 있지만, 일정 시간이 지나서 real 데이터가 취득이 될 수 있습니다. 이러한 상황을 고려해서 본 논문에서는 Real-world KITTI 데이터셋으로 fine tuning을 하였고, 이 때 사용한 KITTI 데이터셋의 개수에 따른 성능 변화를 보여주고 있습니다. 당연히 real 데이터로만 학습을 하면 낮은 성능을 보이고, real 데이터가 충분히 축적이 되면 6000장의 예시처럼 비교적 높은 정확도를 보일 수 있습니다. 이러한 경우에도 Domain Randomization으로 생성한 데이터를 같이 사용하는 경우에 가장 높은 성능을 낼 수 있는 것을 확인할 수 있습니다. 즉 데이터가 부족한 초반 부분부터, 데이터가 충분히 쌓인 후반 부분에 걸쳐서 Domain Randomization이 사용될 수 있습니다.
이 외의 논문에서 더 다루고 있는 이야기는 학습을 시킨 구체적인 parameter들에 대한 이야기, 일정 방법들을 적용하였을 때의 성능 변화를 보여주는 ablation study, pretrained weight를 freezing하였을 때와 그렇지 않았을 때의 성능 비교 등 자잘한 내용이 더 있지만 이는 더 적지는 않았습니다. 혹시 직접 구현을 해보고 싶으신 분들은 논문을 참고하시면 좋을 것 같습니다.
결론
이번 포스팅에서는 Object Detection에서 성능 중에 정확도를 올리기 위한 연구들 중 Domain Randomization을 이용하여 synthetic 데이터를 합성하여 학습을 하는 방법에 대해 설명을 드렸습니다. 이 방법은 실제 현업에 적용하여야 할 때 생각해 봄 직한 방법으로 생각됩니다. 예를 들면 앞서 3번째 글에서 소개드린 Object Detection 적용 사례 들 중 축구의 경우 축구 게임을 응용하는 방법, 무인 가판대에는 Domain Randomization을 이용하는 방법 등 가상으로 데이터를 합성하는 연구를 다양한 데이터셋에 대해 적용하면 좋은 효과를 볼 수 있을 것이라고 생각이 됩니다.
다음 포스팅에서는 마찬가지로 정확도를 올리기 위한 최신 논문 한 편을 선정해서 리뷰를 진행할 예정입니다.
혹시 글을 읽으시다가 잘 이해가 되지 않는 부분은 편하게 댓글에 질문을 주시면 답변 드리겠습니다.
참고 문헌
- Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization 논문
- Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World 논문
- SYNTHIA 데이터셋
- Playing for data: Ground truth from computer games. 논문
- Sim4CV 데이터셋
- Virtual KITTI 데이터셋
- On Pre-Trained Image Features and Synthetic Images for Deep Learning 논문
- Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks? 논문