Transformers in Vision: A Survey [1] Transformer 소개 & Transformers for Image Recognition
안녕하세요, 오늘은 자연어 처리(NLP)에서 압도적인 성능을 보여주며 주류로 자리잡은 Transformers 모델을 컴퓨터 비전에 적용하려는 시도들을 정리한 서베이 논문인 “Transformers in Vision: A Survey” 를 읽고 간단히 정리해볼 예정입니다. 논문의 분량이 많은 만큼 여러 편에 걸쳐서 소개드릴 예정이며, 1편에서는 Transformer에 대해 간단히 소개 드리고, Transformer를 Image Recognition에 적용한 대표 연구들을 소개드릴 예정입니다.
What is a Transformer?
제가 Deep Learning에 입문했을 때만 해도 자연어 처리 분야에서는 RNN을 주로 사용하고, RNN의 long term dependency 문제를 해결하기 위해 고안된 LSTM 방법론이 있다! 정도만 공부하고 제 관심 분야가 아니라서 공부를 안했는데 각종 커뮤니티에 Transformer, BERT, GPT 등 생소한 용어들이 자주 보이기 시작했습니다.
그래서 간단히 공부를 해보니 “Attention Is All You Need” 논문에서 제안한 Transformer라는 모델이 자연어 처리의 다양한 분야에서 SOTA를 휩쓸고 있었고, 이를 잘 활용하기 위해 대용량의 Unlabeled 데이터셋을 활용하여 Self-Supervised Learning으로 학습을 시킨 뒤 Downstream task에 Fine-tuning을 시키는 BERT(Bidirectional Encoder Representations from Transformers), GPT(Generative Pre-trained Transformer) 등이 뒤따라서 출현했음을 알게 되었습니다.
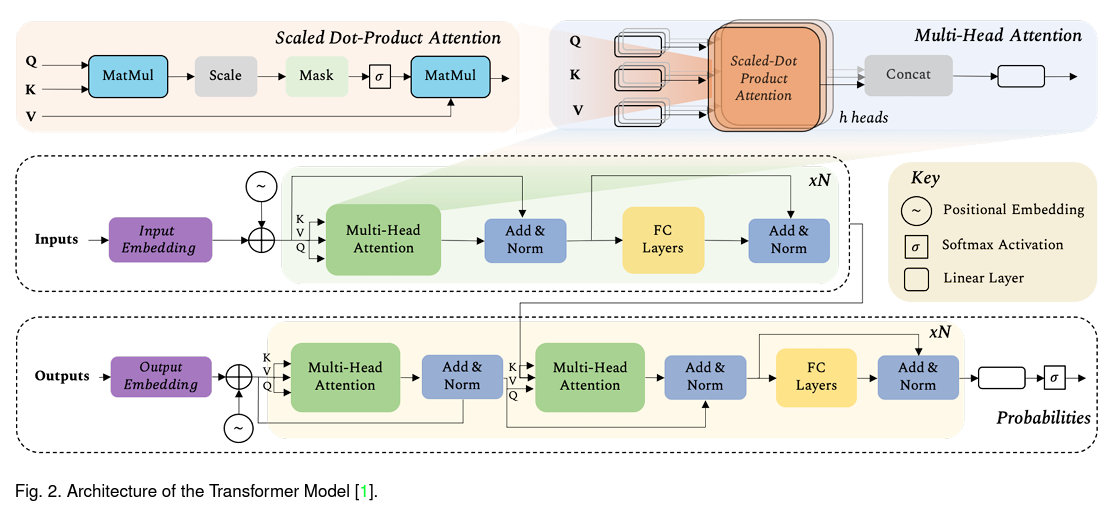
Transformers의 성공 요소는 크게 Self-Supervision 과 Self-Attention 으로 나눌 수 있습니다. 세상엔 굉장히 다양한 데이터가 존재하지만, Supervised Learning으로 학습을 시키기 위해선 일일이 annotation을 만들어줘야 하는데, 대신 무수히 많은 unlabeled 데이터들을 가지고 모델을 학습 시키는 Self-Supervised Learning을 통해 모델을 학습 시킬 수 있습니다. 컴퓨터 비전의 Self-Supervised Learning 연구들은 “Unsupervised Visual Representation Learning Overview: Toward Self-Supervision” 글에 정리해 두었으니 먼저 읽고 오시는 것을 권장 드립니다. 무튼, 자연어 처리에서도 Self-Supervised Learning을 통해 주어진 막대한 데이터 셋에서 generalizable representations을 배울 수 있게 되며, 이렇게 pretraining시킨 모델을 downstream task에 fine-tuning 시키면 우수한 성능을 거둘 수 있게 됩니다.
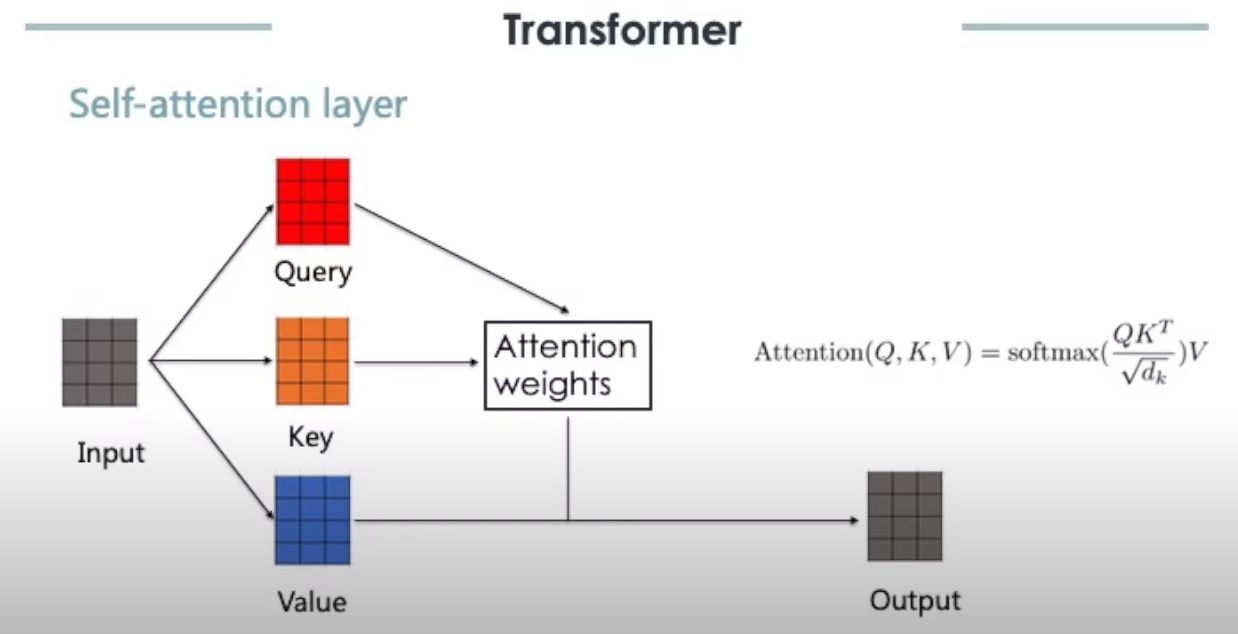
또 다른 성공 요소인 Self-Attention은 말 그대로 스스로 attention을 계산하는 것을 의미하며 CNN, RNN과 같이 inductive bias가 많이 들어가 있는 모델들과는 다르게 최소한의 inductive bias를 가정합니다. Self-Attention Layer를 통해 주어진 sequence에서 각 token set elements(ex, words in language or patches in an image)간의 관계를 학습하면서 광범위한 context를 고려할 수 있게 됩니다. 더 자세한 내용이 궁금하신 분들은 Transformer 논문을 직접 읽어 보시는 것을 추천 드립니다.
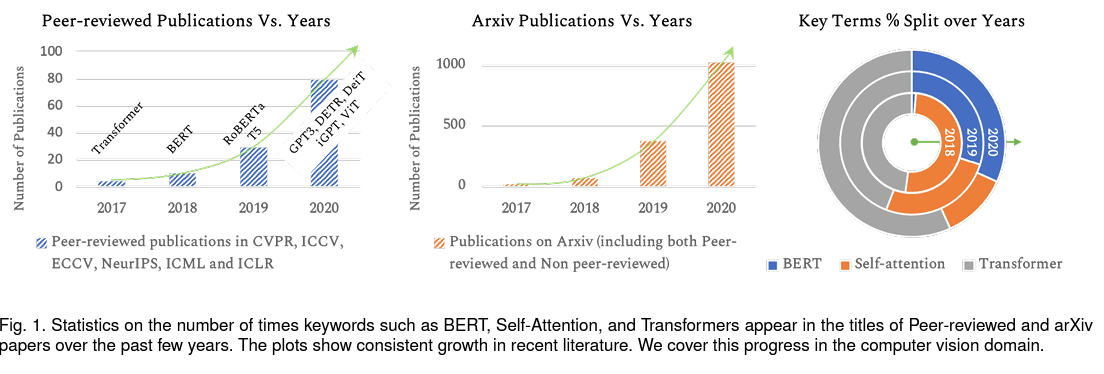
위의 그림을 보시면 알 수 있듯이 매년 Top-tier 학회, arxiv에 Transformer 관련 연구들이 빠른 속도로 늘어나고 있고 작년(2020년)에는 거의 전년 대비 2배 이상의 논문이 제출이 되었습니다. 바야흐로 Transformer 시대가 열린 셈이죠. 근데 주목할만한 점은 Transformer가 자연어 처리 뿐만 아니라 강화 학습, 음성 인식, 컴퓨터 비전 등 다른 task에도 적용하기 위한 연구들이 하나 둘 시작되고 있다는 점입니다. 그래서 오늘은 컴퓨터 비전에 Transformer를 적용한 연구들을 간략히 정리해볼 예정입니다.
Transformers & Self-Attention in Vision
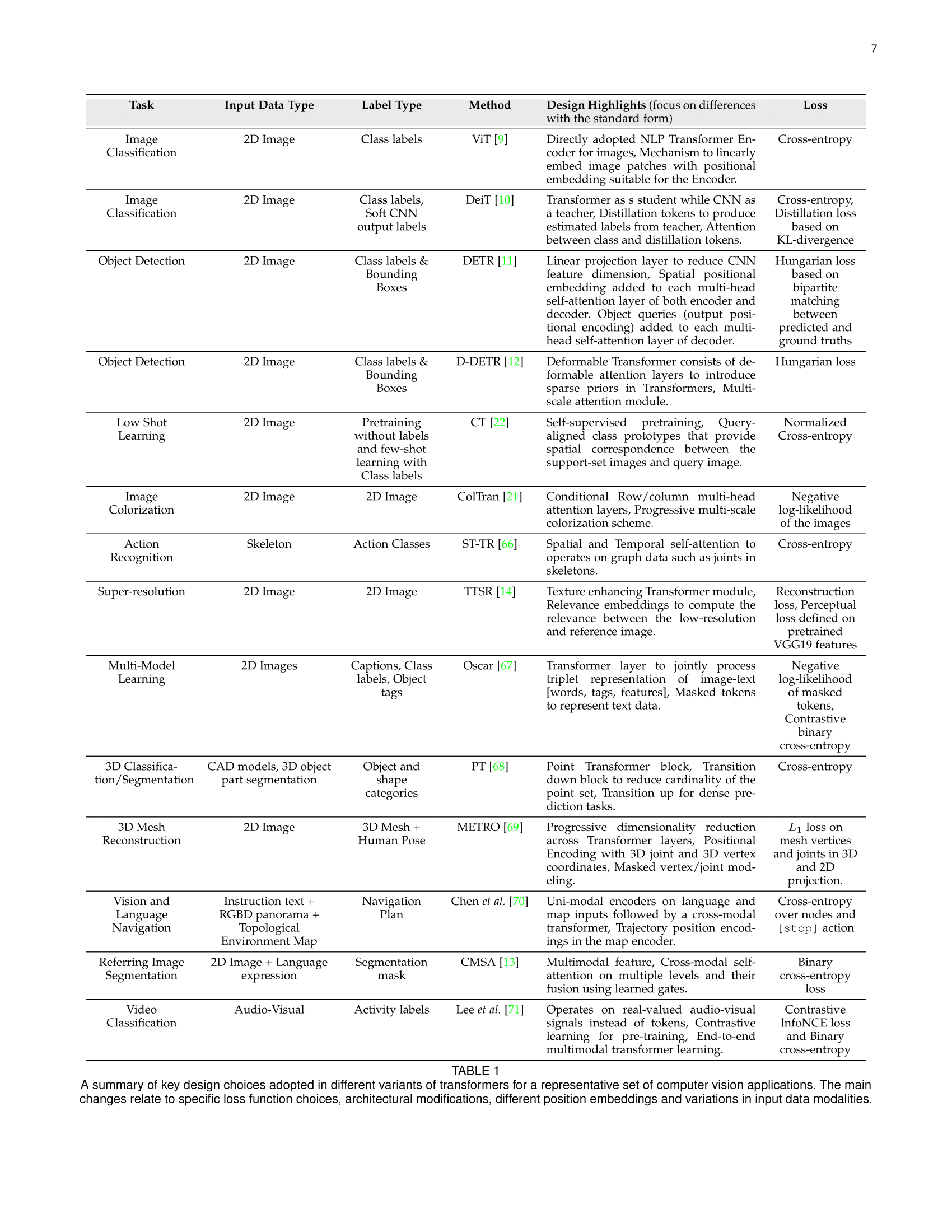
논문에서는 컴퓨터 비전에 Transformer을 적용시킨 연구들을 크게 10가지 task로 나눠서 정리를 해두었습니다.
- Image Recognition (Classification)
- Object Detection
- Segmentation
- Image Generation
- Low-level Vision
- Multi-modal Tasks
- Video Understanding
- Low-shot Learning
- Clustering
- 3D Analysis
분량이 너무 막대한 만큼 모든 task를 오늘 다 소개 드리긴 어려울 것 같고 컴퓨터 비전하면 가장 먼저 떠오르는 Image Recognition을 다룬 연구들을 소개 드리겠습니다.
컴퓨터 비전에 Deep Learning을 적용하는 연구들을 생각하면 가장 먼저 떠오르는 것이 바로 Convolutional Neural Network (CNN) 입니다. AlexNet을 필두로 굉장히 다양한 방법들이 제안되었고 우수한 성능을 보였지만 단점도 존재합니다. 우선 고정된 size의 convolution filter size (window size)를 사용하기 때문에 receptive field 밖에 있는 pixel과의 relation을 배울 수 없습니다. 또한 convolution filter의 weight 값들은 학습이 끝나면 고정된 값을 사용하기 때문에 input에 약간의 변화가 생겨도 dynamically 변화하지 못합니다. 이러한 단점들은 Self-Attention과 Transformer를 사용하면 해결할 수 있는데요, 대표적인 연구들을 하나씩 소개 드리겠습니다.
Non-local Neural Networks
Non-local means 연산은 image denoising에 주로 사용되던 방법인데, 핵심 아이디어를 바탕으로 Neural Network에 적용시킨 연구가 제안되었습니다. 논문의 제목은 “Non-local Neural Networks” 이며 2018 CVPR에 발표되었습니다.
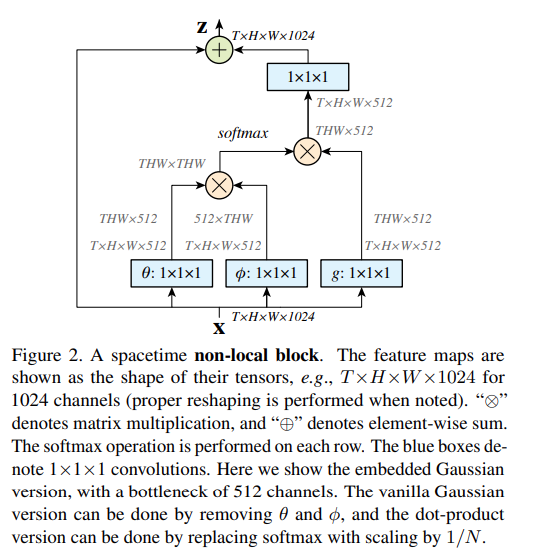
Non-local block을 통해 spatial, temporal 축에서 모두 long-range dependency를 확보할 수 있게 됩니다. 즉, input image (혹은 feature map)에서 특정 pixel과 나머지 모든 pixel 들 간의 relation을 weighted sum 형태로 계산하면서 relation을 배울 수 있게 됩니다. 즉, self-attention의 일종이라고 볼 수 있으며, CNN에서는 주어진 거리 밖에 있는 pixel과는 아무런 relation도 배울 수 없었지만 Non-local Neural Network는 그 것이 가능해지는 셈입니다. 논문에서는 3D 데이터인 Video의 Classification에 적용을 하였지만 2D Image에 적용해도 성능 향상을 얻을 수 있는 방법입니다.
제가 참여했었던 TensorFlow KR 논문 읽기 모임 PR-12의 김태오님께서 이 논문을 한글로 잘 설명해주신 영상 자료가 있어서 같이 참고하시면 좋을 것 같습니다.
Criss-Cross Attention
다음은 2019 ICCV에서 발표된 “CCNet: Criss-Cross Attention for Semantic Segmentation” 논문에서 제안한 Criss-Cross Attention입니다. 위에서 설명드린 Non-local block을 사용하면 full-image contextual information을 모델링할 수 있지만 memory와 computational cost가 매우 크다는 한계가 있습니다. 전체 feature map에 대해 dense한 attention map 을 계산해야하기 때문인데 이를 극복하기 위해 sparse하게 attention map을 계산하는 Criss-Cross Attention 방법을 제안합니다.
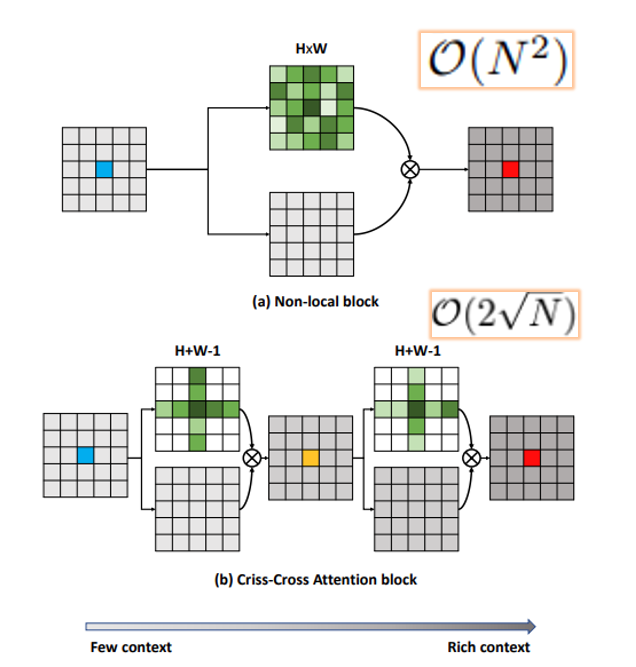
이러한 방법을 통해 아주 미미하게 정확도가 떨어질 순 있지만 계산 복잡도를 크게 줄일 수 있습니다.
제가 참여했었던 TensorFlow KR 논문 읽기 모임 PR-12의 김태오님께서 이 논문을 포함하여 CNN에 Attention을 적용한 사례들을 한글로 잘 설명해주신 영상 자료가 있어서 같이 참고하시면 좋을 것 같습니다.
Stand-alone Self-Attention
다음은 2019 NeurIPS에서 발표된 “Stand-Alone Self-Attention in Vision Models” 논문에서 제안한 Stand-Alone Self-Attention입니다.
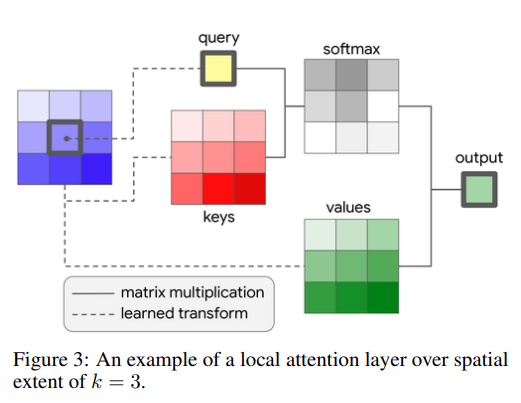
이 논문에서는 모든 Convolutional Layer를 Local Self-Attention Layer로 대체하는 방법을 제안합니다. 이 Local Self-Attention Layer를 ResNet-50에 적용하면 더 적은 수의 파라미터와 연산량으로 더 높은 정확도를 달성할 수 있다고 합니다.
Local Relation Networks
다음은 2019 ICCV에서 발표된 “Local Relation Networks for Image Recognition” 논문에서 제안한 Local Relation Network입니다.
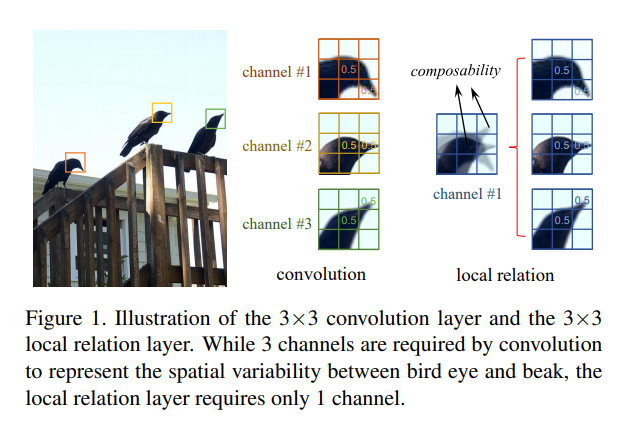
앞서 말씀 드렸듯 CNN은 학습이 끝난 뒤에는 weight가 고정되기 때문에 input의 변화에 따라 weight를 adaptive하게 수정하지 못하는 단점을 가지고 있었습니다. 이러한 점에 주목하여 미분 가능한 Local Relation Layer를 제안하였습니다. 이 Layer는 같은 window에 있는 pixel들간의 compositional relation에 기반하여 adaptive하게 weight aggregation을 수행하는 방법을 제안합니다. 위의 그림과 같이 새의 눈과 부리의 spatial variability를 표현하기 위해 기존 CNN은 3개의 채널이 필요했다면, Local Relation Layer는 오로지 1개의 채널로 이를 표현할 수 있게 되는 셈입니다.
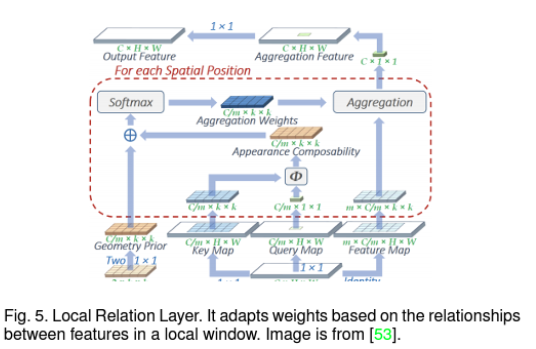
자세한 Layer 동작 방식은 위의 그림과 같으며 자세한 내용은 논문을 참고하시면 좋을 것 같습니다.
Attention Augmented Convolutional Networks
다음은 2019 ICCV에서 발표된 “Attention Augmented Convolutional Networks” 논문에서 제안한 Attention Augmented Convolutional Networks입니다. CNN의 translation equivariance (입력의 위치가 변하면 출력도 동일하게 위치가 변하는 성질)은 유지하면서 Self-Attention 메커니즘을 적용하기 위한 Relative Position Encoding 기반의 연산을 제안합니다.
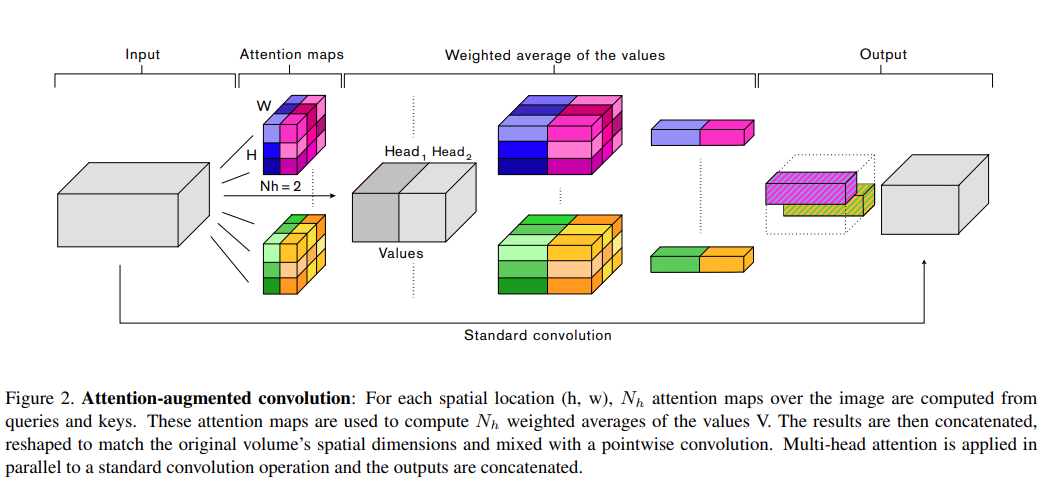
모든 Convolution 연산을 Self-Attention 연산으로 대체하면 연산 효율을 높일 수 있지만 최고 성능은 Convolution 연산과 같이 쓸 때 달성할 수 있으며, 위의 그림과 같이 Self-Attention을 통해 나온 Output과 일반 Convolution 연산을 통해 나온 Output을 concatenate 하여 사용합니다.
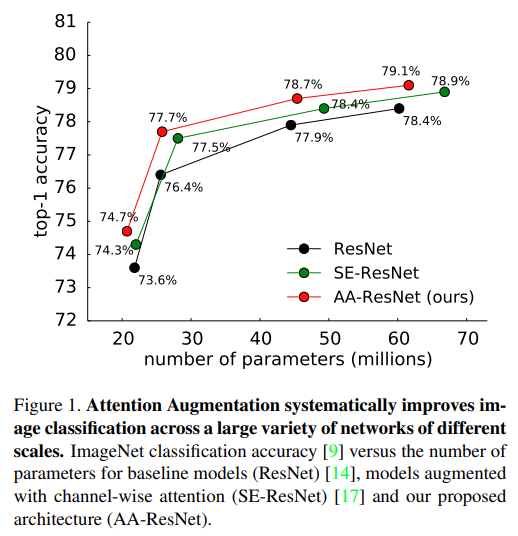
비슷한 방법을 다룬 연구인 Channel-wise로 Attention Augmented 시키는 Squeeze-Excitation Network (SENet)보다 더 좋은 성능을 달성할 수 있었다고 합니다.
Vectorized Self-Attention
다음은 2020 CVPR에서 발표된 “Exploring Self-attention for Image Recognition” 논문에서 제안한 Vectorized Self-Attention입니다. 일반 Convolution 연산은 feature aggregation과 transformation (by activation function)을 연달아서 처리하는 게 일반적입니다. 논문에서는 Self-Attention을 사용하여 feature aggregation과 transformation을 별도로 수행하며, transformation에는 element-wise perceptron layer가 사용됩니다.
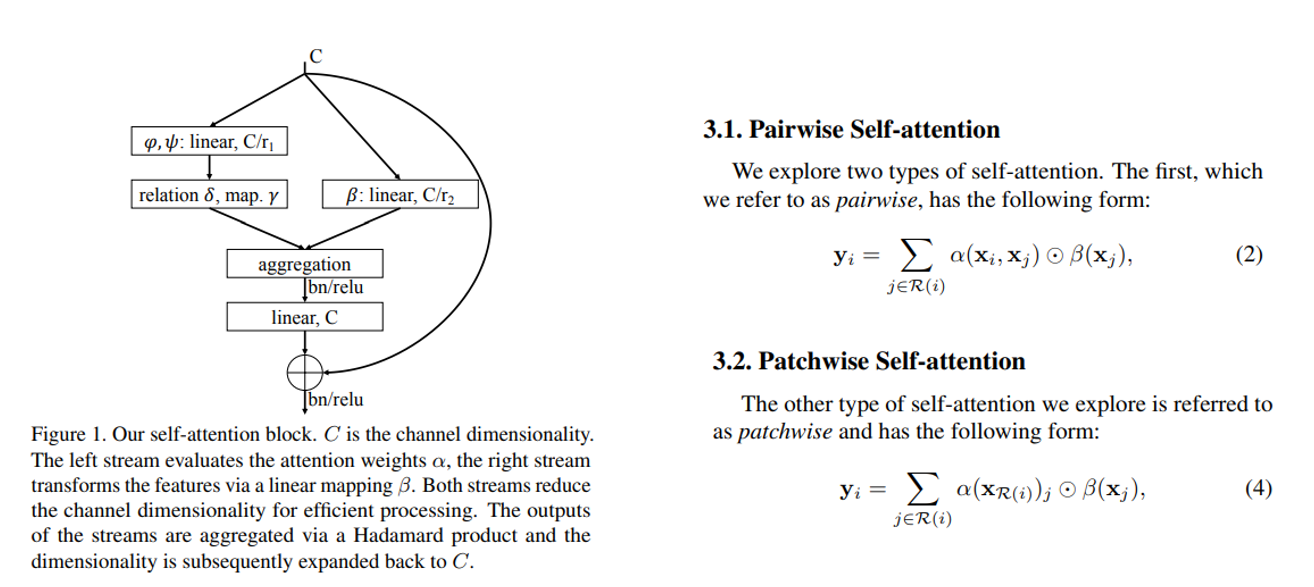
논문에서는 feature aggregation에 Pairwise Self-Attention과 Patch-wise Self-Attention, 2개의 Self-Attention 기법을 사용합니다. 두 연산 모두 spatial과 channel dimension에 대한 weight를 학습하는 Vector Attention 을 사용합니다. 이렇게 구성한 Self-Attention Networks (SAN)을 통해 더 적은 수의 parameter로 ImageNet 데이터 셋에서 ResNet보다 우수한 성능을 거둘 수 있었다고 합니다. 또한 adversarial perturbation에 robust해지는 효과도 얻을 수 있고 test image에 unseen transformations이 적용될 때에도 일반화 성능이 좋아지는 효과를 얻을 수 있었다고 합니다.
Vision Transformer (ViT)
다음은 처음으로 Large-scale 컴퓨터 비전 데이터 셋에서 CNN에 견줄 만한 성능을 보여준 Vision Transformer (ViT) 입니다. 2020년 10월 발표된 따끈 따끈한 논문이고 제목은 “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” 입니다.
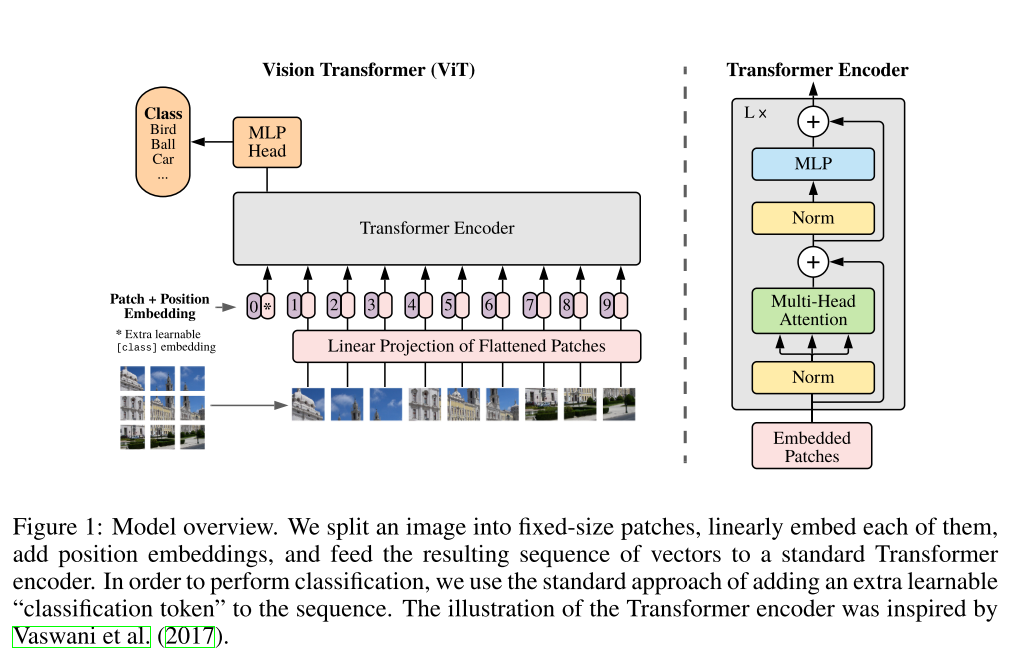
Transformer를 활용하기 위해 Input Image를 여러 개의 patch로 쪼개서 CNN (ResNet)에 넣어서 feature map을 뽑아낸 뒤 flatten 시켜서 Transformer encoder에 넣어줍니다. 그 뒤 Classifier를 붙여서 학습을 시킵니다.
여기서 중요한 점이 있는데, Transformer 기반의 방법들은 무수히 많은 양의 데이터 셋으로 pre-training을 시킨 뒤 downstream task (e.g. ImageNet)에 fine-tuning을 시켜야 좋은 성능이 보장됩니다. 하지만 실험에서 사용한 대용량의 데이터셋은 Google 내부에서만 사용하고 있는 300 million image 데이터 셋인 JFT-300M이라 Google이 아닌 연구 집단에서는 같은 방법을 적용해도 좋은 성능이 나올 수 없다는 뜻입니다.
CNN과 Transformer를 비교해보면, CNN은 translation equivariance 등 inductive bias가 많이 들어가 있는 모델이라 비교적 적은 수의 데이터로도 어느정도 성능이 보장이 되는 반면, Transformer는 inductive bias가 거의 없는 모델이라 많은 수의 데이터가 있어야 성능이 향상됩니다. 이 점이 Transformer의 장점이자 단점이 될 수 있는 부분인데 Google에서는 많은 수의 데이터를 통해 장점으로 승화시킨 점이 인상깊지만 많은 수의 데이터를 확보하기 어려운 분야에서는 적용하기 어렵다는 단점도 잘 보여주는 것 같습니다. 제가 참여했었던 TensorFlow KR 논문 읽기 모임 PR-12의 이윤성님께서 이 논문을 한글로 잘 설명해주신 영상 자료가 있어서 같이 참고하시면 좋을 것 같습니다.
Data-efficient Image Transformer (DeiT)
마지막은 2020년 12월 발표된 “Training data-efficient image transformers & distillation through attention” 이며 공개된지 두 달이 채 되지 않은 아주 따끈따끈한 논문입니다. ViT는 Google에서 발표한 논문이었다면 DeiT는 Facebook에서 발표한 논문입니다.
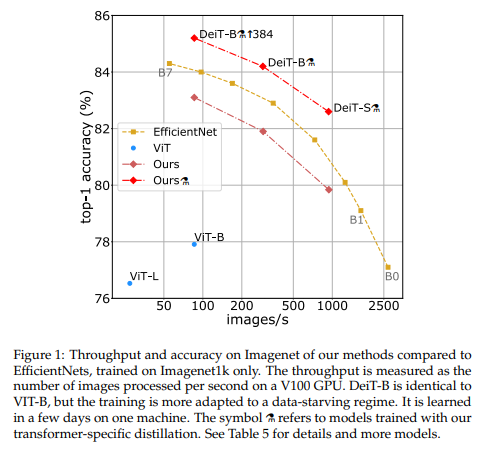
위의 그림에서 알 수 있듯이 기존의 ViT는 물론이고 AutoML로 찾은 ImageNet에 최적화 된 CNN architecture인 EfficientNet보다도 더 우수한 성능을 보여주는 결과를 발표하여 큰 이목을 끌었습니다. 그림의 빨간 점선으로 되어있는 것은 논문에서 제안한 transformer-specific distillation 기법을 적용하였을 때의 성능을 의미합니다.
Transformer 계열 방법으로 CNN에 견줄만한 성능을 낸 점도 굉장히 인상 깊은데 더욱 놀라운건 ViT의 핵심 요소였던 JFT 와 같은 어마어마한 규모의 데이터셋으로 Pre-training을 시키는 과정 없이 좋은 성능을 달성하였다는 점입니다. 즉, 무수히 많은 데이터를 구축하지 않아도 되고, 굉장히 긴 시간과 비용이 소요되는 pre-training이 없어도 된다는 뜻이니 훨씬 범용성이 있는 모델을 만든 셈입니다.
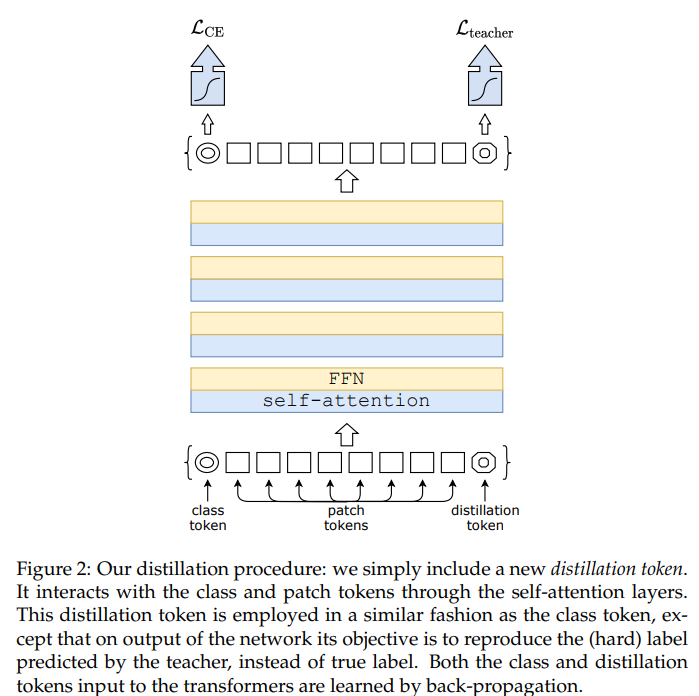
대부분의 구조는 ViT의 Vision Transformer에서 출발하였고 큰 변화는 없습니다. 성능 향상에 큰 기여를 한 첫번째 요인은 CNN에서 성능 향상에 큰 기여를 했었던 data augmentation, optimization, regularization 등의 기법을 적절하게 적용한 점입니다. 두번째 요인은 knowledge distillation이며 CNN에서 괄목할 만한 성과를 보여준 RegNet을 teacher model로 사용하여 teacher model의 output을 활용하고, class token에 distillation token을 추가하여 모델을 효과적으로 학습시키는 데 성공합니다.
제가 참여했었던 TensorFlow KR 논문 읽기 모임 PR-12의 이진원님께서 이 논문을 한글로 잘 설명해주신 영상 자료가 있어서 같이 참고하시면 좋을 것 같습니다.
결론
오늘은 자연어 처리에서 시작해서 이제는 다양한 분야에서 우수한 성능을 보여주고 있는 Transformer에 대해 간단히 알아보고, 컴퓨터 비전의 가장 대표적인 분야인 Image Recognition에 Self-Attention과 Transformer가 적용된 사례들을 알아봤습니다. 다음 편에서는 Object Detection, Segmentation 등에 Transformer를 적용한 사례들을 소개드리겠습니다.
comments powered by Disqus