Unsupervised Anomaly Detection Using Style Distillation 리뷰
안녕하세요, 오늘은 제가 재직 중인 Cognex의 연구팀 동료분들이 IEEE Access에 제출하신 “Unsupervised Anomaly Detection Using Style Distillation” 논문을 소개드릴 예정입니다.
Anomaly Detection은 제 주 관심분야이지만 블로그에서 소개드린 적은 많이 없는 것 같네요. 이 글을 보시기 전에 먼저 아래의 글들을 읽고 오시면 더 이해가 수월하실 것 같습니다.
- “Anomaly Detection 개요: [1] 이상치 탐지 분야에 대한 소개 및 주요 문제와 핵심 용어, 산업 현장 적용 사례 정리”
- “Anomaly Detection 개요: [2] Out-of-distribution(OOD) Detection 문제 소개 및 핵심 논문 리뷰”
- “MVTec AD—A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection 리뷰”
Related Works
Unsupervised Anomaly Detection 문제를 해결하기 위해 다양한 접근 방법이 있었습니다.
Generative Adversarial Networks 기반 연구
대표적으로 Generative Adversarial Networks 방법이 있는데요, 위에서 소개드렸던 “MVTec AD—A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection 리뷰” 글을 보시면 AnoGAN에 대해 간단히 소개드린 적 있습니다.
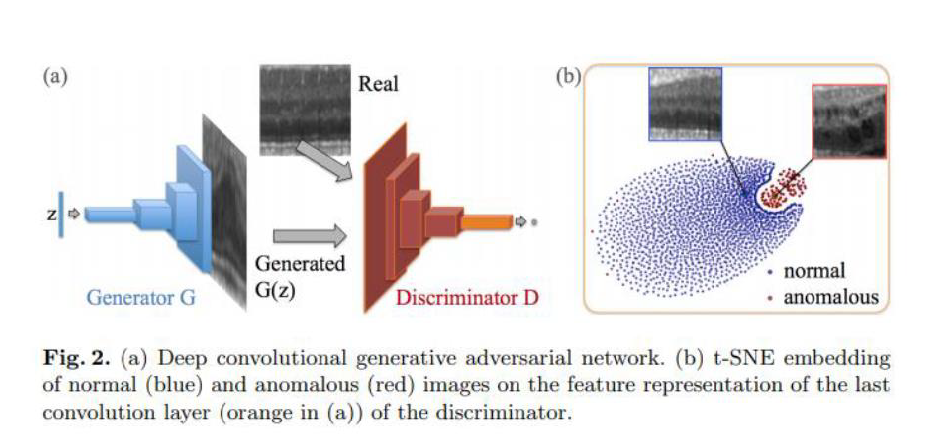
정상 sample들로 GAN을 학습시킨 뒤, Generator와 Discriminator를 고정시키고 test image를 가장 잘 표현할 수 있는 latent variable을 optimization을 통해 찾게 됩니다. Test image가 정상 sample인 경우 학습에서 배운 적이 있기 때문에 Generator가 input과 비슷한 image를 잘 생성하게 됩니다. 반대로, test image가 비정상 sample인 경우 Generator는 잘 생성하지 못하게 되고, 결과적으로 Discriminator를 속이지 못합니다.
다만 이런 방법은 GAN의 고질적인 문제인 학습 불안정성과 Mode Collapse를 자주 겪게 되고, 데이터 셋이 단순하면 잘 되지만 데이터 셋이 복잡한 경우 성능이 매우 떨어지는 문제가 발생합니다. 또한 1장씩 optimization을 수행하는 방식이라 test 하는 데 많은 시간이 소요되는 문제도 있습니다. 이러한 점들을 해결하기 위해 AnoGAN 이후 다양한 연구들이 진행되었습니다.
- “GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training”, 2018 ACCV
- “Skip-GANomaly: Skip Connected and Adversarially Trained Encoder-Decoder Anomaly Detection”, 2019 IJCNN
- “f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks”, 2019 MIA
Deep Convolutional Autoencoders and Variational Autoencoders (VAE) 기반 연구
다음은 최근 주로 사용되고 있는 Convolutional Autoencoder 기반 방법들입니다. “Anomaly Detection 개요: [1] 이상치 탐지 분야에 대한 소개 및 주요 문제와 핵심 용어, 산업 현장 적용 사례 정리” 글에서 잠시 소개드렸듯이 Autoencoder를 정상 sample들로 학습을 시킵니다.
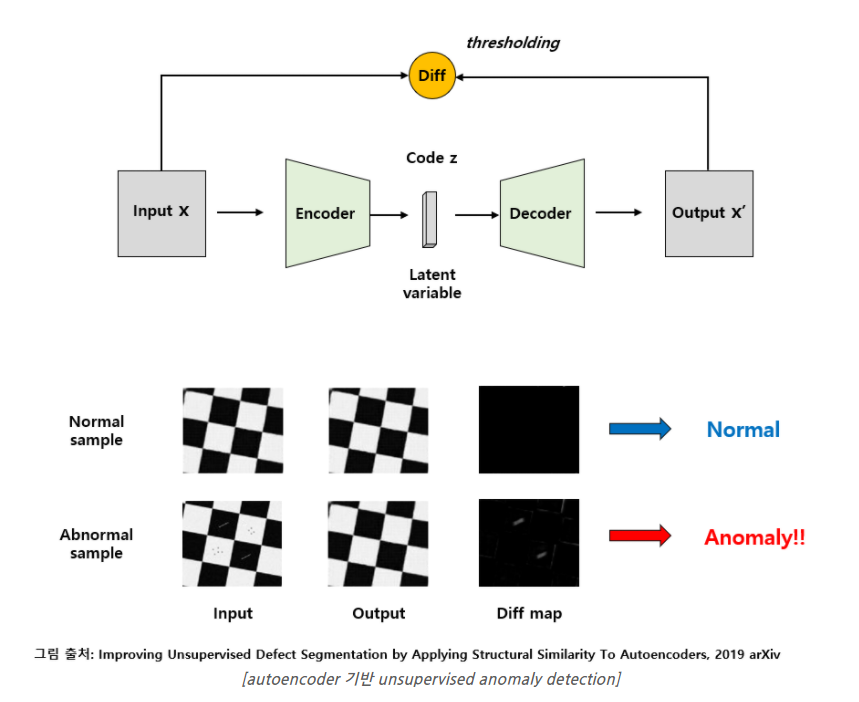
방법은 단순합니다. Input을 Autoencoder에 넣어서 Output으로 Input과 같은 image를 생성하도록 loss function을 설계하여 학습을 시킵니다. 다만 이렇게 되면 단순히 Identity function을 배울 수 있기 때문에 Bottleneck 구조를 차용하여 input의 데이터를 축소시킨 뒤 다시 늘려주는 방식을 통해 input을 외우는 것을 방지합니다. 이렇게 되면 Autoencoder는 정상 sample을 넣어주면 잘 복원하게 학습이 됩니다. 이 때 test image로 비정상 sample을 넣어주면 Autoencoder는 배웠던 대로 정상 sample로 복원하게 되며, Input과 Output의 차이를 구하면 그 영역이 바로 결함 영역이 되는 방식입니다.
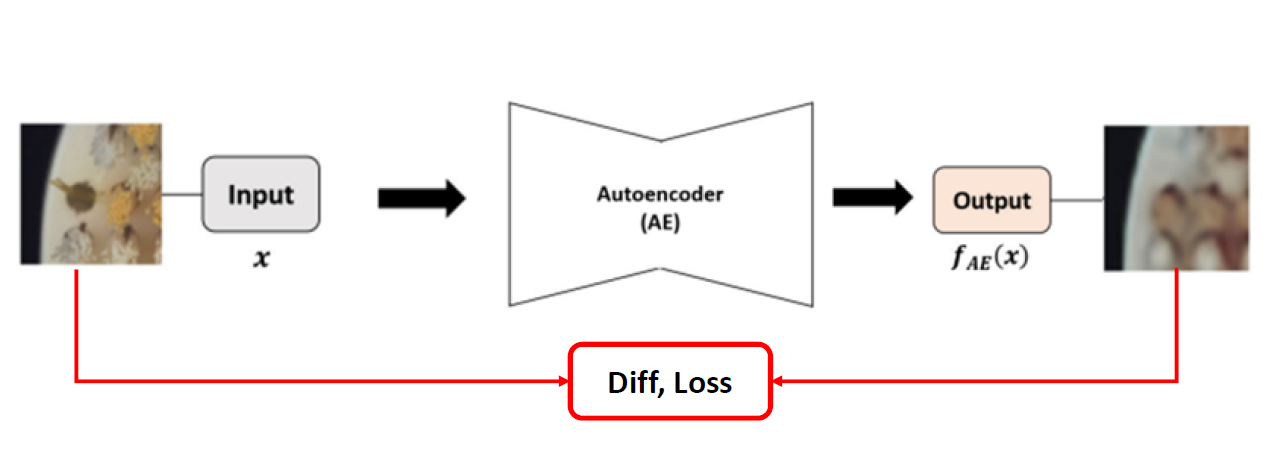
다만 Bottleneck Autoencoder의 구조적인 특징과, Loss function으로 보통 Distance 기반의 L2 loss등을 사용하기 때문에 전체적인 틀은 잘 복원하지만 세부적인 부분, 특히 edge와 같은 high-frequency 영역은 blurry하게 복원하는 한계가 존재합니다.

이를 해결하기 위해 “Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders” 논문에서는 Structural Similarity(SSIM) Loss를 사용하여 Autoencoder를 학습시키는 방법을 제안하였습니다. 검출 성능은 약간 좋아졌지만 여전히 blurry한 output을 내는 문제는 남아있습니다.
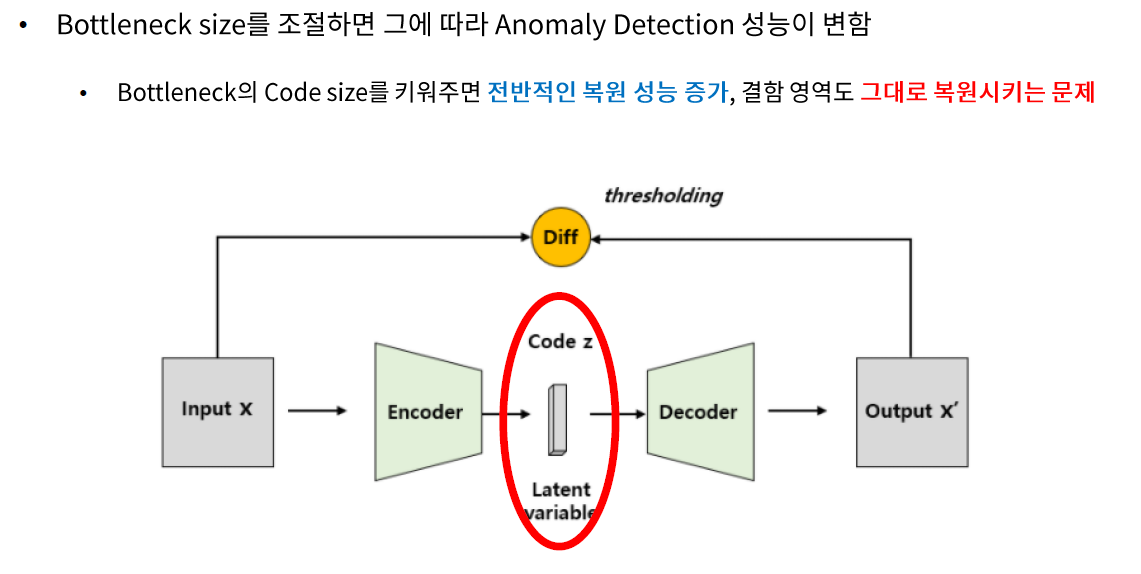
이를 해결하기 위해 Autoencoder의 Latent Variable의 length, 다른 말로는 Code size를 조절하는 방법이 있습니다. Code size를 키워주면 전반적인 복원 성능이 좋아지지만 결함 영역도 그대로 통과시키는 문제가 발생하고, 반대로 Code size를 줄여주면 결함 영역은 잘 뭉개버리지만 정상 영역도 bluury하게 복원시키는 문제가 발생합니다. 즉, 데이터 셋이 바뀔 때 마다 최적의 Code Size를 바꿔주는 방법은 학습 시간도 오래 걸리고 그다지 효율적이진 않습니다.
Unsupervised Anomaly Detection Using Style Distillation
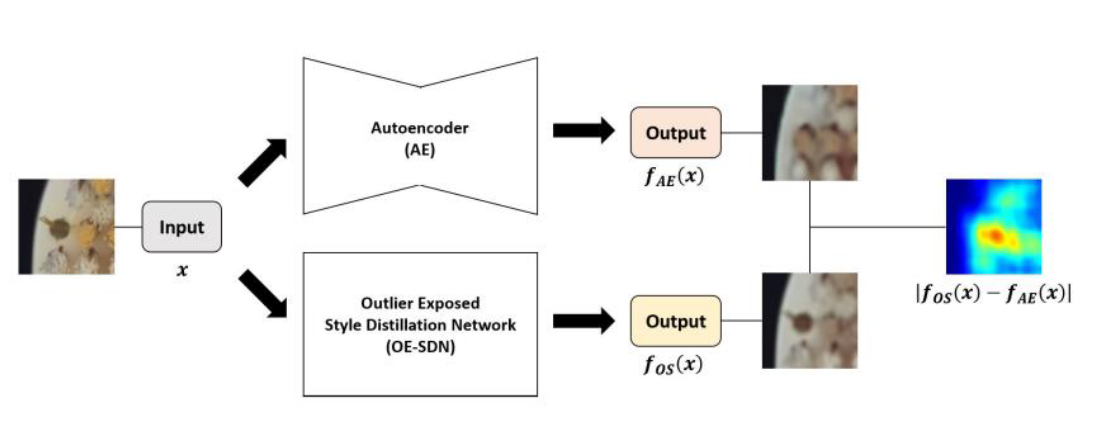
Autoencoder가 Blurry하게 Output을 내는 것을 고치는게 어려우니 그건 그대로 놔두고, Autoencoder가 Blurry하게 Output을 내는 것을 흉내내는 또 하나의 Network를 설계한 뒤, Autoencoder과 그 Network의 Output 간의 차이를 통해 Anomaly Detection을 하는 방식을 제안하였습니다.
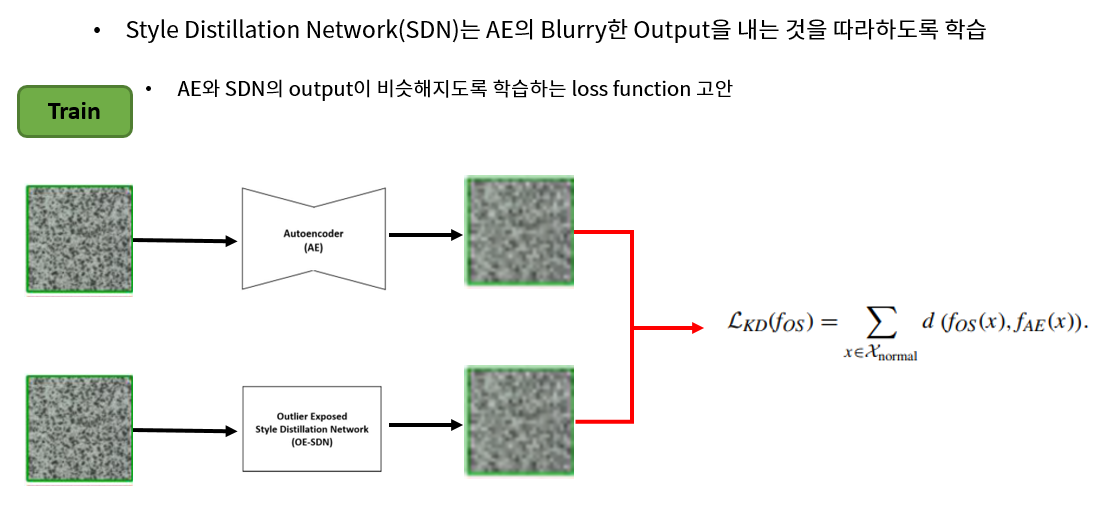
우선 Autoencoder는 원래 하던 대로 학습을 시킵니다. 그 뒤, Autoencoder보다 Network Capacity가 큰 새로운 Network (Style Distillation Network, 이하 SDN)를 가져온 뒤, SDN은 Input은 같은 training image를 사용하지만, 복원해야 하는 Target을 원본이 아닌 Autoencoder의 Output으로 사용합니다. 즉, 그림의 아래의 SDN은 Autoencoder가 복원하는 것을 따라하도록 학습하게 됩니다.

다만 이렇게 되면 저희는 SDN은 Autoencoder의 Blurry한 Output을 내는 것만 배우길 원하는데 학습 데이터의 분포가 다양하지 않은 경우 그냥 뭉개진 training sample들을 외워버리게 됩니다. 예를 들어 MNIST에서 3을 정상 class로 학습시키는 경우, 숫자 3은 생김새가 다 비슷하기 때문에 SDN은 input을 blurry하게 만드는 것이 아닌, 뭉개진 3을 만드는 것 만 배우게 됩니다. 이렇게 SDN이 단순 암기하는 것을 막기 위해 Regularization 기법이 필요합니다.

그래서 “Deep Anomaly Detection with Outlier Exposure”, 2019 ICLR 논문에서 제안한 Outlier Exposure 기법을 이용하였습니다. 이 방법은 Anomaly Detection Network의 더 나은 Representation을 위해 외부 데이터 셋을 사용하는 방법인데요, 저자들은 이 외부 데이터 셋 (Auxiliary 데이터 셋)을 생성하기 위해 다양한 image 변환 기법들을 사용하였고, 그 중에 Rotation이 가장 성능이 좋아서 이를 채택했습니다. 즉 Training 데이터에 Rotation을 가한 뒤 Input으로 넣어주고, SDN의 Output이 이 Input과 같아지도록 학습을 시키는 방식입니다. 그래서 최종 모델은 Outlier-Exposed Style Distillation Network (OE-SDN)이라 부르게 됩니다.
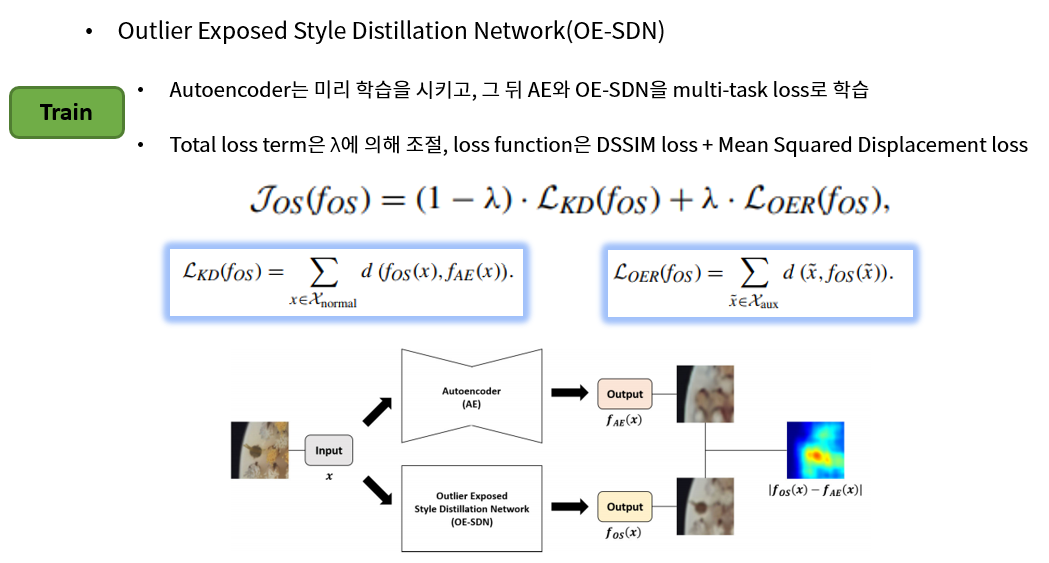
학습 과정은 일단 Autoencoder를 먼저 학습 시킨 뒤, AE와 OE-SDN의 output이 같아지도록 해주는 KD(Knowledge Distillation) loss term과, OE-SDN에 Auxiliary 데이터 셋을 넣어서 복원 시키는 OER(Outlier Exposed Regularization) loss term을 더하여 multi-task learning을 통해 학습을 시키며, 두 loss간의 weight를 lambda로 조절합니다. 논문에서는 0.5 값을 사용했습니다.
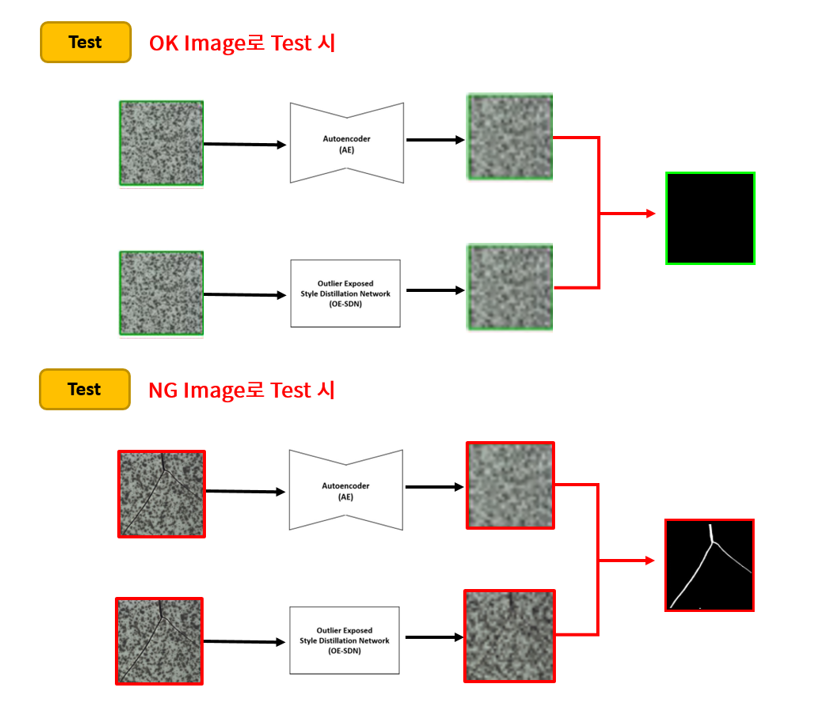
이렇게 학습을 시켜서 원래 Autoencoder와 새로운 OE-SDN 2개의 network를 얻게 되면, 그 뒤에는 input을 두 network에 동시에 넣어준 뒤, 두 Output의 차이를 통해 Anomaly Detection을 하게 됩니다. 이제는 두 network가 모두 blurry하게 output을 내기 때문에 차이를 구하면 blur한 영역에서 차이가 적게 발생하게 되고, 결함 영역만 도드라지게 걸러낼 수 있게 됩니다.
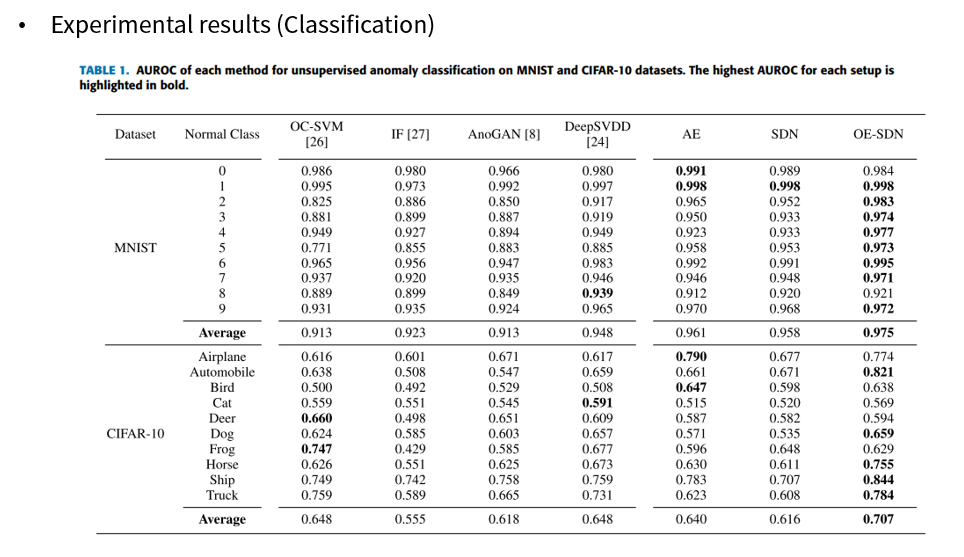
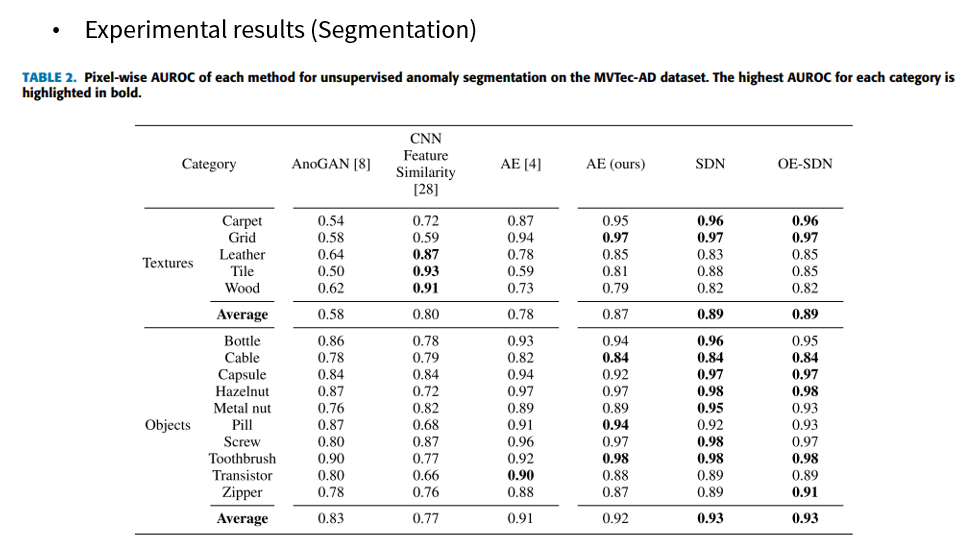
실험 결과 Classification, Segmentation 모두 기존 방법들보다 더 좋은 성능을 달성할 수 있었습니다.
결론
오늘은 제가 근무 중인 Cognex의 연구팀 동료분들이 IEEE Access에 제출하신 “Unsupervised Anomaly Detection Using Style Distillation” 논문을 소개드렸습니다. 명확한 문제점 (AE의 Blurry한 Output)을 직접적으로 해결하는 대신 간접적으로 해결하는 재미난 방법을 제안하였는데요, 이 분야는 아직까지 더 해볼만한 여지가 많이 남아 있는 것 같아서 재밌는 것 같습니다. 긴 글 읽어주셔서 감사합니다.