Fast and Accurate Model Scaling 리뷰
안녕하세요, 오늘은 CVPR 2021에서 발표 예정인 Facebook Research의 “Fast and Accurate Model Scaling” 논문을 소개드릴 예정입니다. 제목에서 유추가 가능하 듯 모델의 크기를 조절해주는 (Scaling) 방법을 다룬 논문이며, 항상 모델의 크기를 키워주면 정확도가 좋아지지만 그에 따라서 처리 속도가 느려 지는 Trade-off 관계를 가지는데 이를 잘 타개하기 위한 방법을 제안한 논문입니다.
이 논문과 관련 있는 연구들이 EfficientNet과 RegNet인데 두 연구 모두 제가 정리한 적이 있는데요, 이 두 연구를 잘 모르시는 분들은 먼저 이 자료들을 보고 오시는 것을 권장 드립니다.
- “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 리뷰”
- “CNN Architecture A to Z”
Related Works
2012년 ImageNet 분류 대회에서 우수한 성능을 거뒀던 AlexNet 이후로 굉장히 다양한 CNN architecture들이 탄생되었습니다. 유명한 VGG, ResNet 등은 하나의 모델에서 Layer 개수를 늘려 정확도를 높이기도 하였는데요, 이처럼 하나의 작은 block 혹은 architecture에서 출발하여 network의 크기를 키워주는 방식을 Model Scaling 이라 부릅니다. 일반적으로 가장 많이 쓰이는 것은 Layer의 개수 (depth)를 늘려주는 방식이며, 종종 각 Convolution Layer의 Filter 개수 (Width)나 Input Image의 Resolution을 키워 주기도 합니다. 이렇게 되면 연산량, 처리 속도는 느려지지만, 그만큼 정확도가 좋아지는 효과를 보입니다.
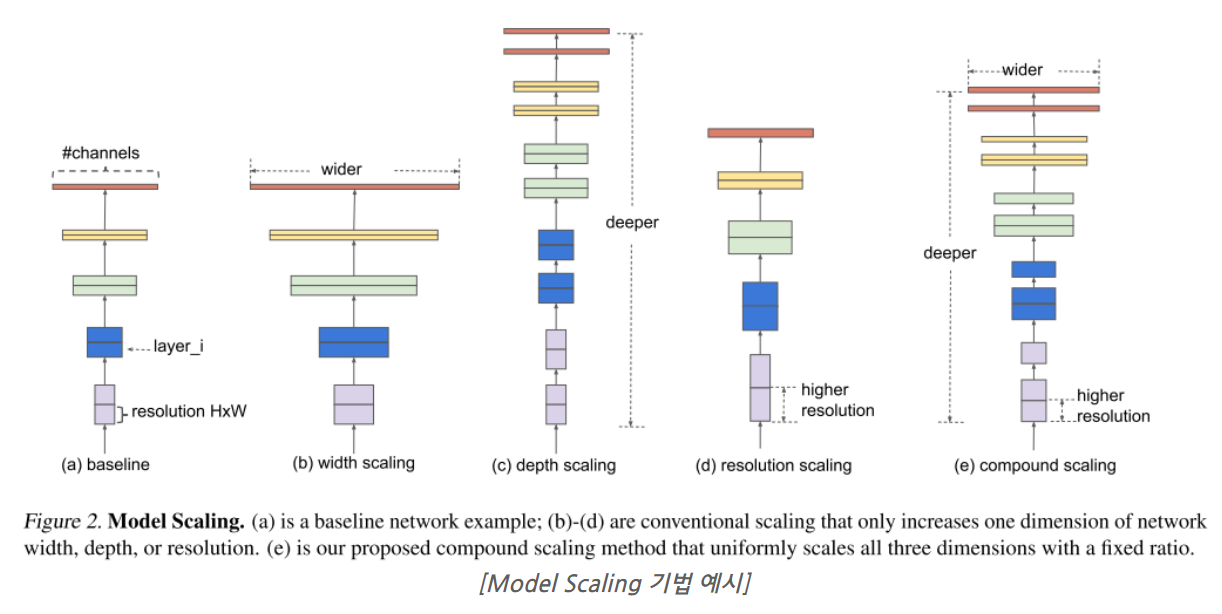
그리고 아직까지도 많이 사용되고 많은 논문 들에서 타겟으로 삼아지고 있는 EfficientNet 에서는 위의 그림과 같이 width, depth, resolution 3가지 factor를 동시에 고려하여 키워주는 Compound Scaling 이라는 기법을 제안하였고, 실제로 큰 성능 향상을 이뤘습니다. 다만 EfficientNet 논문에서는 width, depth, resolution 3가지를 동시에 키워 주긴 하지만 어떤 것에 더 높은 가중치를 둘 지는 별다른 고려 없이 단순히 Grid Search를 통해 찾았는데요, 본 논문에서는 실제 Hardware에서 빠르게 동작하는 것도 같이 고려하여 Model을 Scaling 해주는 기법을 제안합니다.
Complexity of Scaled Models
일반적으로 모델의 크기를 고려할 때 FLOPS (Floating Point Operations), Parameters (Parameter 개수), Activations (Activation 개수)를 고려합니다. 예전 논문들에서는 FLOPS, Parameters 정도만 언급하기도 했었습니다. Activations는 말 그대로 Activation의 개수이며 정확히는 Conv Layer를 통과하여 나온 Tensor의 element 개수인 셈입니다.
결론 먼저 말씀드리면 실제 연산 처리 속도를 고려해야 할 때, FLOPS와 Parameter 개수는 그다지 큰 도움이 되지 못합니다. 그래서 나온 것이 바로 Activations입니다. 특히 Parameter 개수는 Input Resolution과 무관하게 결정되는 요소이다 보니 Input Resolution이 커지면 연산 속도도 느려 지고 GPU Memory도 더 많이 소모하지만 Parameter 개수는 변하지 않습니다.

Table 1에서는 depth, width, resolution 중 하나의 dimension을 키워줬을 때 같은 FLOPS에서 Params, Acts 가 각각 어떻게 변하는 지를 표로 나타내고 있고, Table 2에서는 2개 혹은 3개의 Dimension을 동시에 고려했을 때 같은 FLOPS에서 Params, Acts가 어떻게 변하는 지를 나타내고 있습니다. 어떻게 이런 식이 유도되는지는 실제로 FLOPS, Params, Acts를 계산해보시면 알 수 있습니다.
Runtime of Scaled Models
이론적인 값보다는 실제로 GPU에서 얼마나 빠르게 동작하는 지가 중요하겠죠? 3가지 요소 (depth, width, resolution)의 scaling에 따른 FLOPS, Params, Acts의 변화를 살펴봤으니 실제 runtime에서 동작 시켰을 때의 시간을 측정해봅니다.
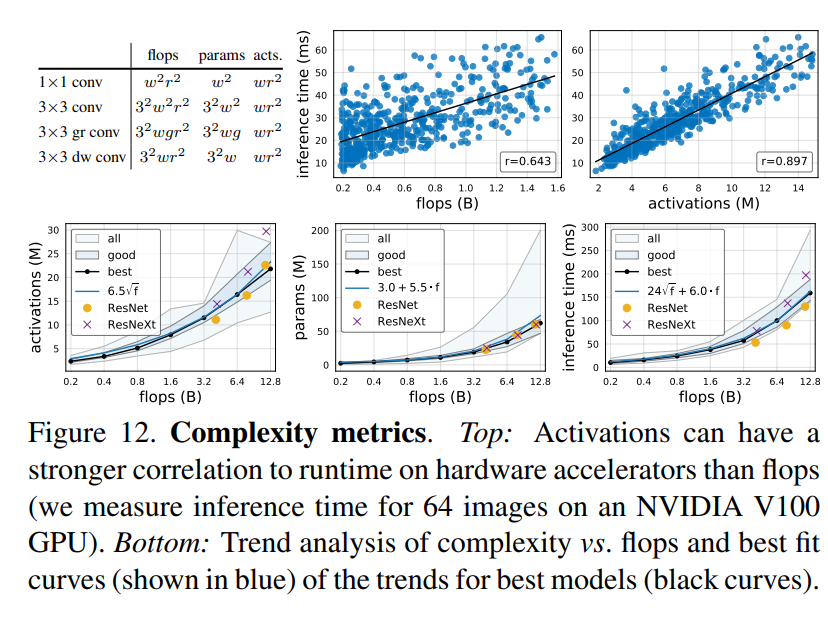
사실 이미 RegNet 논문에서도 FLOPS 보다는 Activations가 실제 Runtime에서의 Inference Time과 훨씬 더 높은 Correlation을 가지는 것을 밝혔었는데 본 논문에서도 Params까지 같이 고려해서 Y 축은 1 epoch를 학습시키는데 소요되는 시간으로 설정한 뒤, X 축으로 FLOPS, Params, Acts을 두고 그래프를 그려봅니다.
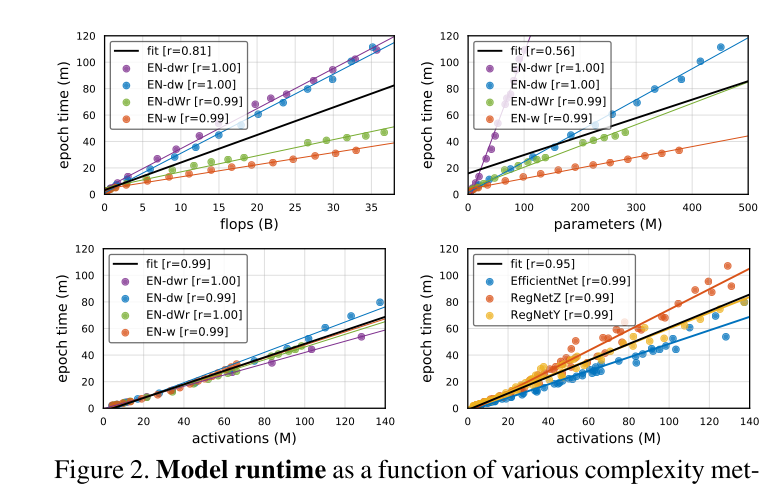
역시나 Params가 가장 Epoch Time과 Correlation이 적었고 Acts는 매우 높은 Correlation을 가지고 있습니다. 그림의 우측 하단을 보면 단순히 EfficientNet 뿐만 아니라 RegNet Z, RegNet Y등 다른 network에서도 비슷한 경향을 보이는 것을 알 수 있습니다.
Fast Compound Model Scaling
Runtime에 가장 중요한 영향을 주는 요소가 Activations임을 알아냈으니 모델의 크기를 키워줄 때 Activations의 증가를 최소한으로 하도록 설계를 하는 것이 중요하겠죠?
아까 설명 드렸던 Table 1, 2를 보면 width, depth, resolution 중에서 width를 증가시키면서 network를 scaling하는 것이 Activations를 가장 적게 증가시키는 것을 알 수 있었습니다. 그렇다고 width만 증가시키면 최적의 정확도를 얻기 힘들겠죠? 그래서 width를 중점적으로 증가시키되, depth와 resolution도 동시에 증가시키는 방법을 제안합니다.

여기서는 간단하게 width에 Alpha 만큼 가중치를 두고, depth와 resolution에는 각각 (1- Alpha)/2 만큼 가중치를 두도록 parameterize 시킵니다. 여기서 Alpha가 0이면 depth와 resolution만 scaling 해주는 셈이고, Alpha가 1/3이면 3가지 요소를 동등하게 고려하는 셈이겠죠? Alpha를 1/3보다 큰 값을 사용하면 width에 더 많은 가중치를 줄 수 있게 됩니다. 논문에서는 Alpha의 default 값으로 0.8을 사용하였고 이를 dWr scaling 이라고 표현합니다. 또한 이렇게 Width에 높은 가중치를 주는 scaling 방식을 Fast Scaling 이라고 표현합니다.
실험 결과
논문에서는 Baseline Network로 EfficientNet, RegNet Y, RegNet Z을 사용하였고 각각 Network에 대한 Details은 다음과 같습니다.

또한 공정하면서도 재현 가능한 결과를 얻기 위해 simple & weak optimization setup과 difficult & strong setup을 동시에 고려하여 학습을 시켰습니다. 학습에 대한 Details은 다음과 같습니다.

논문에선 실험 결과가 굉장히 다양하게 제시가 되어있는데 저는 핵심만 간단히 설명 드리겠습니다. 자세한 결과가 궁금하신 분들은 논문의 7페이지 ~ 9페이지를 참고하시면 좋을 것 같습니다.
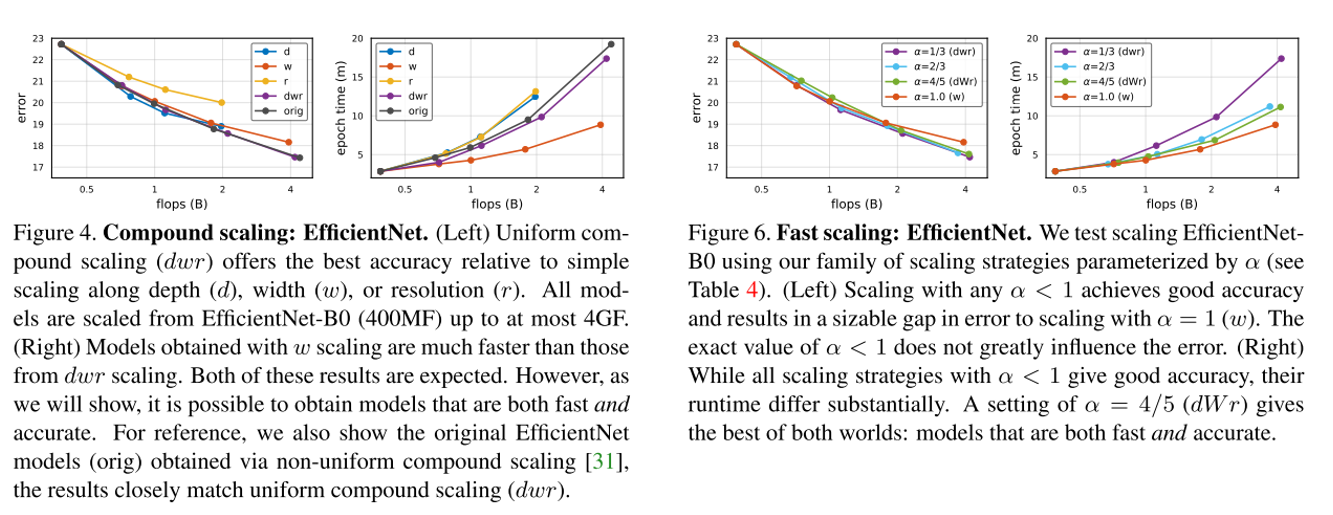
우선 Figure 4는 저희가 잘 알고 있는 EfficientNet의 Compound scaling에 대한 실험 결과입니다. Figure 4의 좌측 그림을 보면 역시 depth, width, resolution을 각각 scaling 해줄 때 보다 동시에 (dwr, orig) 키워주는 것이 더 낮은 error rate를 얻을 수 있음을 보여주고 있습니다. EfficientNet 논문에서는 depth, width, resolution을 non-uniform 하게 키워줬는데 (orig), depth, width, resolution을 uniform하게 키워줘도 (dwr) 비슷한 error rate를 얻을 수 있었다고 합니다. 또한 Figure 4의 오른쪽 그림은 Runtime을 나타내고 있는데 역시 width만 키워주는 방식이 Activations를 적게 증가시켜서 Runtime이 가장 빨랐고 그 뒤를 dwr, orig이 따르고 있습니다.
Figure 6은 방금 설명 드린 Compound Scaling (dwr)에서 width의 가중치를 키워준 Fast Scaling의 실험 결과를 보여주고 있습니다. Alpha 값을 키워줘도 비슷한 error rate를 얻을 수 있었지만 Runtime에서는 Alpha를 키워줄수록 Runtime이 더 줄어드는 것을 알 수 있습니다. 즉, Compound Scaling에서 Width에 가중치를 더 키워주는 방식이 정확도는 비슷한데 더 빠르게 동작할 수 있다는 뜻입니다. 이러한 경향은 EfficientNet 뿐만 아니라 RegNet Y, RegNet Z에서도 관찰이 됩니다.
결론
오늘 소개 드린 “Fast and Accurate Model Scaling” 논문은 모델의 크기를 키워주는 Model Scaling 기법을 다룬 논문입니다. 기존에 EfficietNet에서 제안되었던 Compound Scaling 기법이 주를 이루고 있었는데 실제 Runtime에서 빠르게 동작하기 위해선 FLOPS, Parameters가 아니라 Activations를 고려해야함을 주장하며, Activations를 가장 적게 증가시키는 방법은 Width를 키워주는 방식임을 밝히며 이를 이용한 Fast Scaling 기법을 제안하였습니다. 논문 자체가 굉장히 쉽게 읽히고 전달하고자 하는 메시지도 명확하지만 의미가 큰 것 같아서 좋은 논문인 것 같습니다. 긴 글 읽어 주셔서 감사합니다.
comments powered by Disqus