Image Data Augmentation Overview
안녕하세요, 오늘은 Image Recognition 분야에서 거의 필수로 사용되는 Data Augmentation, 데이터 증강 기법들을 정리해볼 예정입니다. “A survey on Image Data Augmentation for Deep Learning” 논문을 기반으로 제가 공부했던 내용들을 정리했으며, 여러 방법론들의 핵심만 짧게 소개드릴 예정입니다.
Data Augmentation 기법이란?
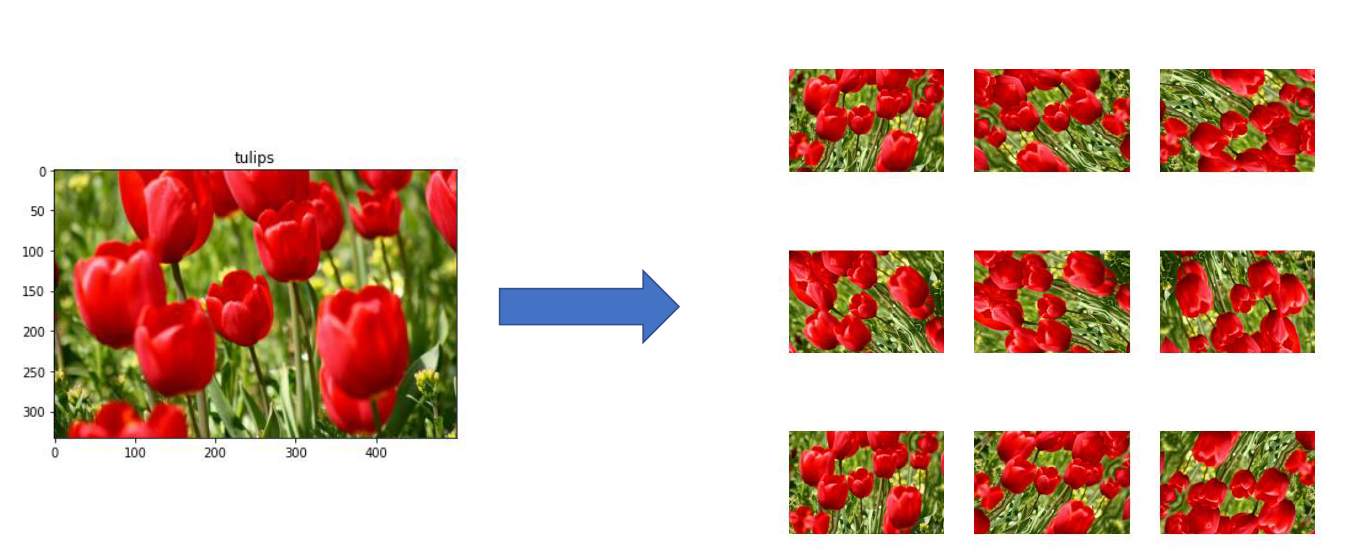
Data Augmentation은 데이터의 양을 늘리기 위해 원본에 각종 변환을 적용하여 개수를 증강시키는 기법입니다.
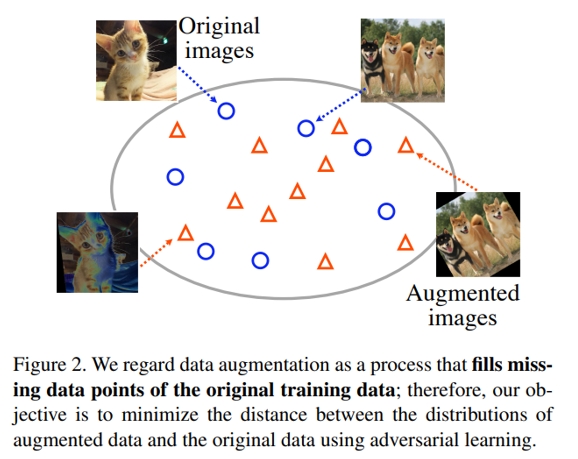
위의 그림과 같이 original training data의 비어 있는 data point 들을 Augmentation을 통해 채운다고 표현하기도 합니다.
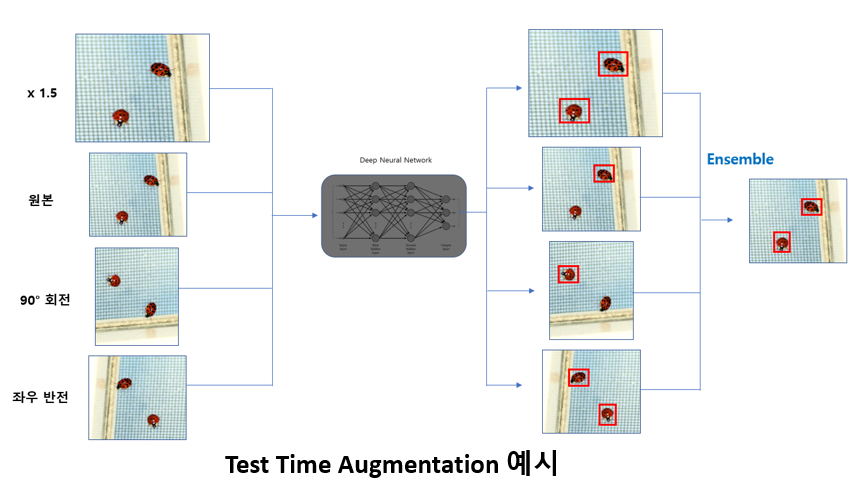
보통 Training 단계에서 많이 사용되지만 위의 그림처럼 Test 단계에서도 사용이 가능하며, 이를 Test-Time Augmentation (TTA) 라고 부릅니다. 한 장의 Test image를 여러 장으로 증강시켜 inference를 시킨 뒤 나온 output을 ensemble하는 방식이며 Kaggle과 같은 챌린지에서 많이 사용이 되는 기법입니다.
Image Manipulation 기반 방법론
이제 본격적으로 Data Augmentation 기법들을 하나씩 살펴보겠습니다.
Pixel-Level Transforms

우선 Pixel 단위로 변환을 시키는 Pixel-Level Transform은 대표적으로 Blur, Jitter, Noise 등을 이미지에 적용하는 기법입니다. Gaussian Blur, Motion Blur, Brightness Jitter, Contrast Jitter, Saturation Jitter, ISO Noise, JPEG Compression 등 다양한 기법이 사용됩니다.
Spatial-Level Transforms

다음으론 Image 자체를 변화시키는 Spatial-Level Transform입니다. 대표적으로 Flip과 Rotation이 있으며, Image의 일부 영역을 잘라내는 Crop도 많이 사용됩니다.
이 Augmentation을 사용할 때 주의해야할 점은 Detection (Bounding Box), Segmentation (Mask) Task의 경우 Image에 적용한 Transform을 GT에도 동일하게 적용을 해줘야 하고, Classification의 경우 적용하였을 때 Class 가 바뀔 수 있음을 고려하여 적용해야 합니다. (Ex, 6을 180도 회전하면 9)
“PatchShuffle Regularization”, 2017
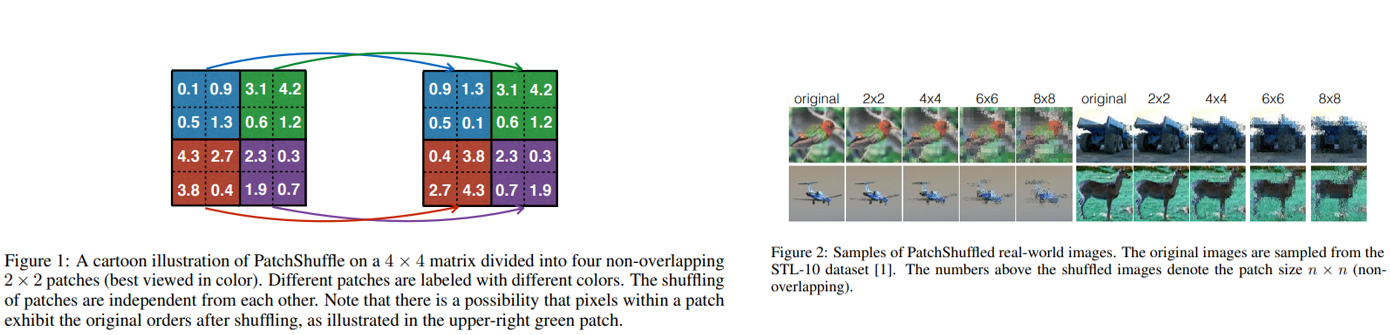
N x N non-overlapping sliding window 내의 feature 값들을 random 하게 shuffle해주는 기법을 제안한 논문이며, sliding window의 크기인 N이 hyper parameter입니다. 적용하면 성능이 올라가긴 하지만 N 값에 따라 성능이 크게 좌지우지되는 점이 아쉬운 점입니다.
“Data Augmentation by Pairing Samples for Images Classification”, 2018
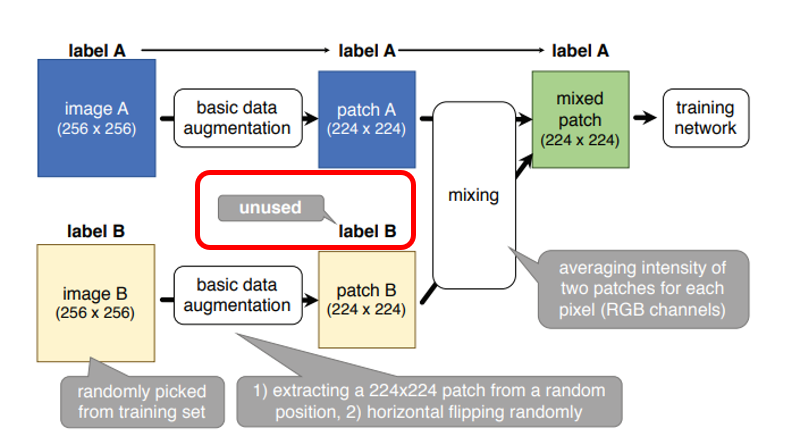
2장의 image A, B를 training set에서 random하게 추출한 뒤 224 크기로 random crop한 뒤 random horizontal flip을 적용합니다. 그렇게 해서 얻은 2장의 patch를 평균을 내서 mixed patch를 만들어 줍니다. 이 때 Label은 A의 label을 그대로 사용합니다. Image는 A와 B가 섞여 있지만 Label은 A만 사용이 되는 점이 약간 애매한 부분입니다.
“Improved Mixed-Example Data Augmentation”, 2018

두 image를 mixing 하는 기존 방법들을 개선시킨 논문이며 단순히 두 image를 평균을 내는 방식을 넘어서 위의 그림과 같은 8종류의 Mixing 방법을 제안하였습니다. 후술할 CutMix, Mosaic 기법의 형태를 보이는 방법들도 제안한 점이 특징입니다.
“MixUp: Beyond Empirical Risk Minimization”, 2018
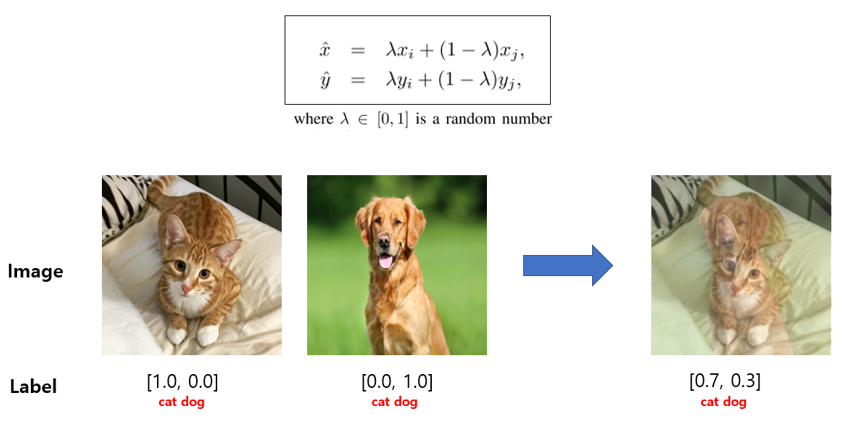
다음은 워낙 유명한 방법이죠. 두 image와 Label을 0~1 사이의 lambda 값을 통해 Weighted Linear Interpolation 해주는 기법입니다. 보통 lambda 값은 beta distribution을 통해 뽑아냅니다. 이 방법은 굉장히 단순하지만 모델의 일반화 성능도 좋아지고 corrupt label의 memorization을 방지해주고, adversarial example에 sensitive해지는 등 다양한 효과를 얻을 수 있습니다.
“Data augmentation using random image cropping and patches for deep CNNs”, 2018
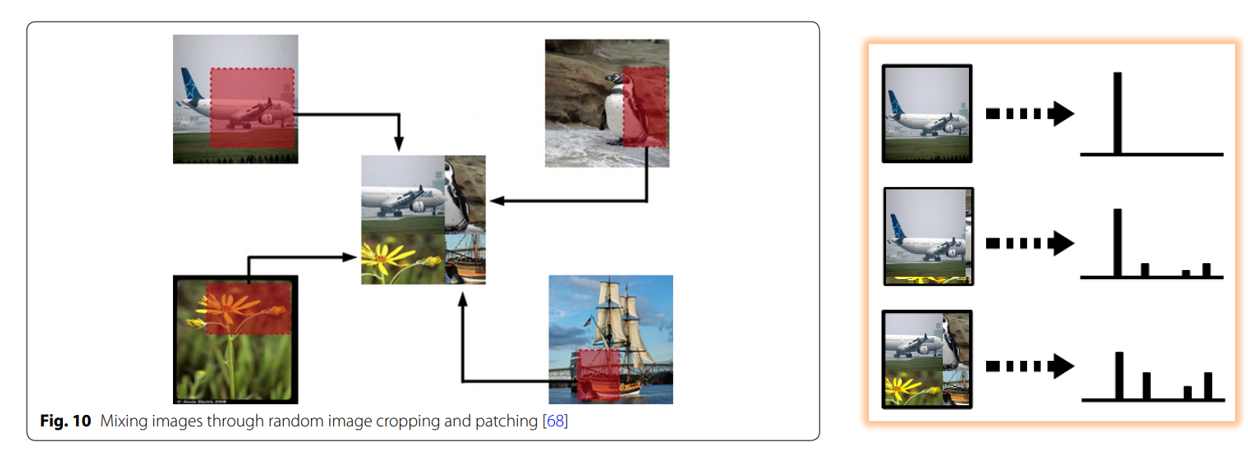
다음은 4장의 image에서 random crop한 patch들을 합쳐서 한 장으로 만드는 random image cropping and patching (RICAP) 기법을 제안한 논문입니다. 또한 mixup처럼 label도 4개를 patch의 면적 비율에 따라 섞어서 soft label을 만들어서 학습을 시키는 방법입니다.
다만 이렇게 patch를 random crop하는 경우 위의 그림의 펭귄 image를 예로 들면, 배경 부분이 crop된 경우 patch에는 펭귄이 아예 존재하지 않는데 생성된 image에는 펭귄의 label이 부여될 수 있겠죠? 이런 점이 이 방식의 약점이며, 이러한 점을 고려한 비슷한 방법으론 제 블로그에서 다뤘었던 YOLO v4 의 Mosaic Augmentation 기법이 있습니다.

Mosaic Augmentation도 4장의 image를 합치지만 random crop 하는 대신 resize하여 버려지는 영역 없이 다 사용하게 된다는 장점이 있습니다. RICAP 방식은 Object Detection 에서는 사용할 수 없었지만 Mosaic 방식은 Object Detection에서도 사용이 가능한 방식입니다.
“Manifold Mixup: Better Representations by Interpolating Hidden States”, 2018
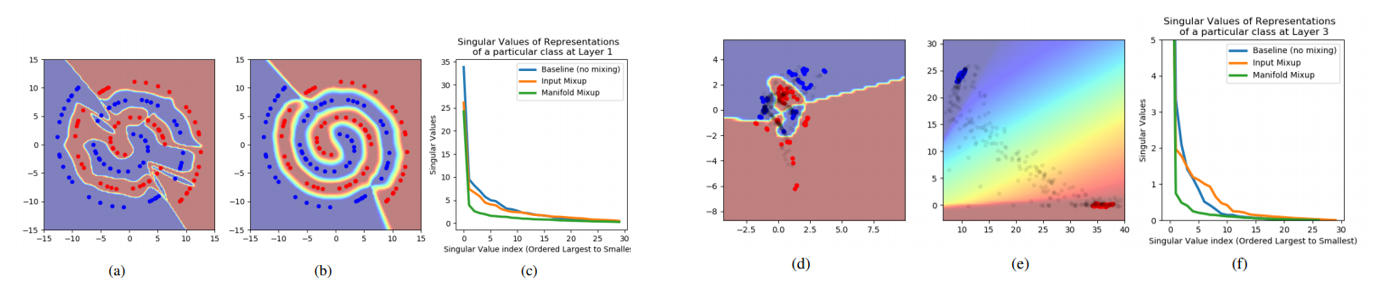
Mixup을 input image가 아닌 hidden representation 혹은 feature map (Manifold) Level에서 해주는 방식을 제안한 논문입니다. 이 방식을 통해 decision boundary를 smooth하게 해줄 수 있고 Mixup과 마찬가지로 다양한 이점을 누릴 수 있다고 합니다.
“Random Erasing Data Augmentation”, 2017

방금까지는 섞는 방식들이었다면 이번에는 지우는 방식이며, 이 논문은 input image의 random한 크기의 bounding box를 만든 뒤 그 안을 random noise, ImageNet mean value, 0, 255 등으로 채워서 학습을 시키는 방법을 제안하였습니다.
“Improved Regularization of Convolutional Neural Networks with Cutout”, 2017
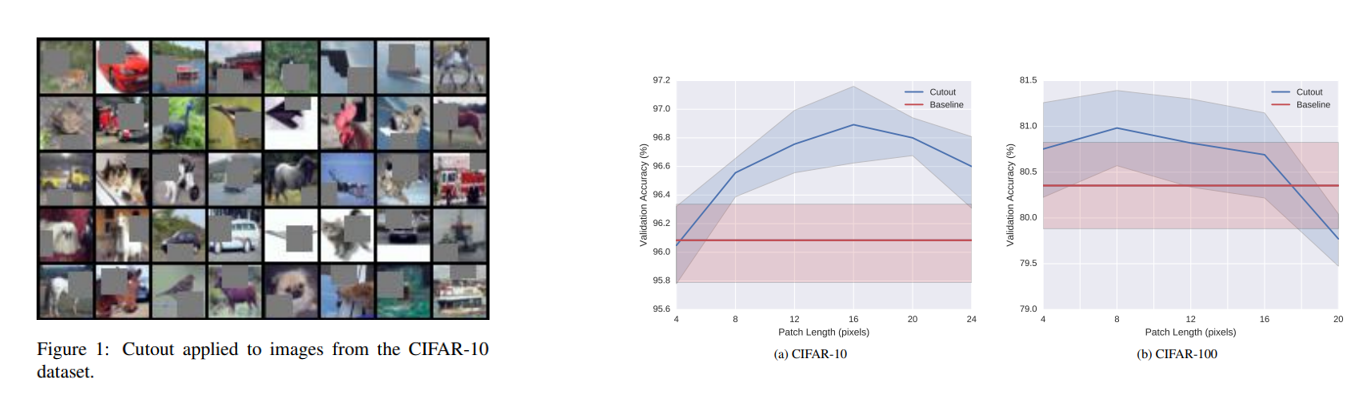
이번엔 random 한 bounding box를 0으로 채우는 방식인 Cutout입니다. Box의 크기에 따라 성능이 크게 바뀌는 점이 특징이고, 이 논문은 제 블로그 에서 이미 다룬 적이 있으니 이 글을 참고하시면 좋을 것 같습니다.
“Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond”, 2018

이 논문에선 image를 grid로 나눈 뒤 patch를 매 iteration 마다 random하게 지우면서 학습시키는 방법을 제안하였습니다. 이를 통해 Network가 image에 있는 object의 한 부분에만 집중하는 것이 아니라 다양한 부분을 보면서 예측하게 해주는 효과를 얻을 수 있습니다.

Grad-CAM과 같은 attribution 방법을 사용하였을 때 object의 더 넓은 영역을 보면서 예측하는 것을 확인할 수 있으며, 이를 통해 Weakly-Supervised Localization에 적용 가능함을 보이고 있습니다.
“CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features”, 2019

다음은 우리 나라 멋진 연구원분들의 멋진 연구 성과인 CutMix입니다. MixUp은 두 image를 섞는 방식이고, Cutout은 image의 box를 쳐서 지우는 방식이었다면, CutMix는 두 방법을 합친 방법입니다. A image에서 box를 쳐서 지운 다음 그 빈 영역을 B image로부터 patch를 추출하여 집어넣습니다. Patch의 면적에 비례하여 Label도 섞어주는 방식입니다. 이 방법을 적용하면 성능이 많이 좋아져서 저도 각종 challenge에 참여할 때 필수로 사용하는 기법 중에 하나입니다.
“AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty”, 2019
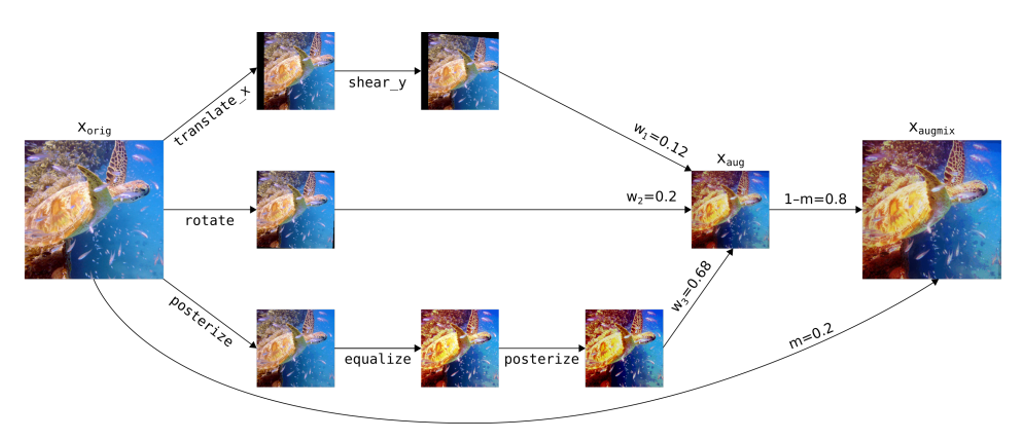
다음은 한 장의 image에 여러 augmentation 기법들을 직렬, 병렬로 연결한 뒤 원본과 다시 섞어주는 AugMix 라는 방법입니다. 이 방법은 일반 Test Accuracy를 높이려고 나온 방법은 아니고, ImageNet-C, ImageNet-P와 같은 Robustness를 측정하기 위해 나온 데이터 셋에서의 성능을 높이기 위해 제안된 방법입니다.
“SmoothMix: A Simple Yet Effective Data Augmentation to Train Robust Classifiers”, 2020
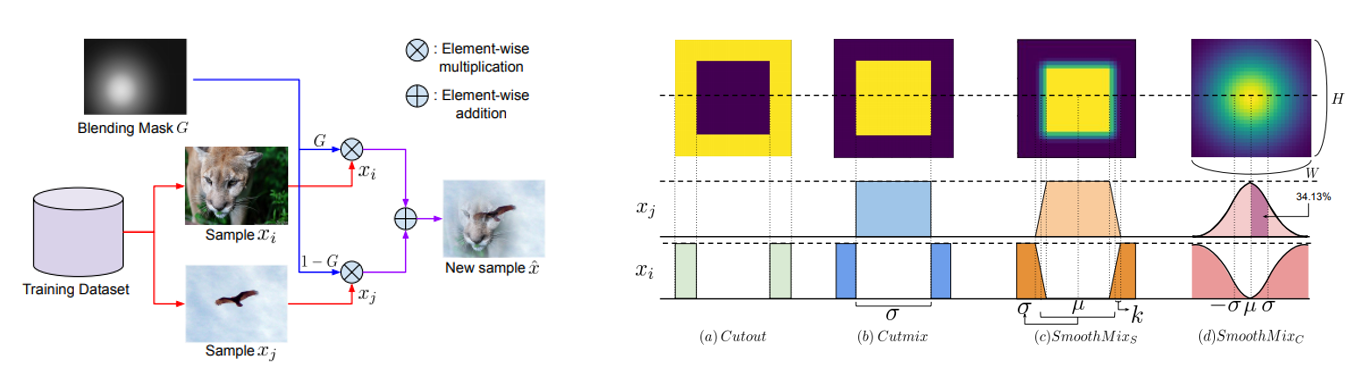
이번에도 우리 나라 멋진 연구원분들이 참여하신 논문이며, CutMix는 patch를 잘라 붙이는 과정에서 edge 영역에서 급격한 변화가 생기는 strong edge 문제가 발생하는데, 이를 완화시키기 위해 경계 영역을 smooth하게 섞어주는 SmoothMix 방식을 제안하였습니다. CutMix보다 test accuracy는 약간 낮지만 robustness는 더 좋아지는 결과를 보입니다.
“PuzzleMix: Exploiting Saliency and Local Statistics for Optimal Mixup”, 2020

이번에도 역시 우리 나라 멋진 연구원분들이 발표하신 논문이며 각 image의 saliency information을 보존하면서 섞어주는 방식인 PuzzleMix 방법을 제안하였습니다. 이를 통해 각 image의 local statistics를 보존할 수 있고 기존 Mix 계열보다 더 높은 일반화 성능을 보이고, Adversarial Attack에도 Robust해지는 효과를 얻을 수 있습니다.
“The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization”, 2020

기존의 Augmentation 기법들은 대체로 Input image 자체를 섞거나 지우거나 자르거나 하는 방식 등을 통해 변화를 주는 방식이었다면, 이 논문에서 제안한 DeepAugment 기법은 기 학습된 Image-to-Image Network (Ex, Autoencoder, Super Resolution Network)의 weight와 activation에 변화를 주는 방식으로 Augmentation을 하는 방법을 제안하였습니다. DeepAugment를 사용하면 기존 영상 처리 기법들로는 생성하기 어려운 다양한 유형의 image를 생성할 수 있고, semantically consistent한 image를 생성할 수 있다는 장점이 있으며, 이 방법을 사용하면 Robustness가 크게 증가하는 효과를 얻을 수 있습니다.
Generative Model 기반 방법론
다음은 Generative Model, 대체로 GAN 기반의 Augmentation 기법인데 제가 서베이 논문을 읽었을 땐 아직 이 분야는 더 많은 좋은 연구들이 나올 가능성이 높아 보인다고 느꼈습니다.
“GAN-based Synthetic Medical Image Augmentation for increased CNN Performance in Liver Lesion Classification”, 2018
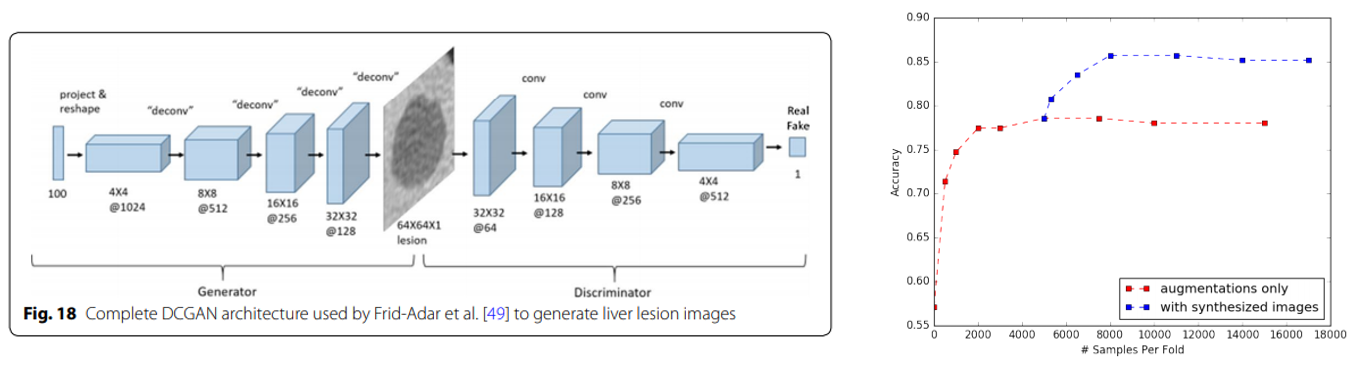
DCGAN을 통해 생성한 Liver Lesion image들을 추가로 학습에 사용해서 분류 성능을 높인 논문입니다.
“Data Augmentation in Emotion Classification Using Generative Adversarial Networks”, 2017

CycleGAN을 통해 생성한 얼굴 감정 분류 데이터를 학습에 사용하여 Class imbalance를 완화시켜 분류 성능을 높인 논문입니다.
“SinGAN: Learning a Generative Model from a Single Natural Image”, 2019

한 장의 image로 GAN을 학습시켜서 비슷한 수많은 그럴싸한 image를 생성해내는 기법인 SinGAN입니다. 이 논문은 제 블로그 에서도 다룬 적이 있어서 이 글을 참고하시면 좋을 것 같습니다.
이 SinGAN을 이용해 Data Augmentation도 가능하긴 하지만 image 한 장에 GAN 하나씩 학습을 시켜야 하는데, 학습 시간이 생각보다 길어서 가지고 있는 image가 많으면 Data Augmentation도 굉장히 오래 걸린다는 한계도 존재합니다.
AutoML 기반 방법론
마지막 AutoML 기반 방법론은 최적의 Data Augmentation Policy를 AutoML을 통해 찾는 방법을 제안하고 있습니다.
“AutoAugment: Learning Augmentation Policies from Data”, 2018

NAS 초기 논문과 비슷하게 RNN controller를 통해 Augmentation Policy를 뽑고, Network를 학습시켜서 Validation accuracy를 뽑은 뒤 이를 강화 학습(PPO)의 reward로 사용하여 학습시키는 방법을 제안하였습니다.
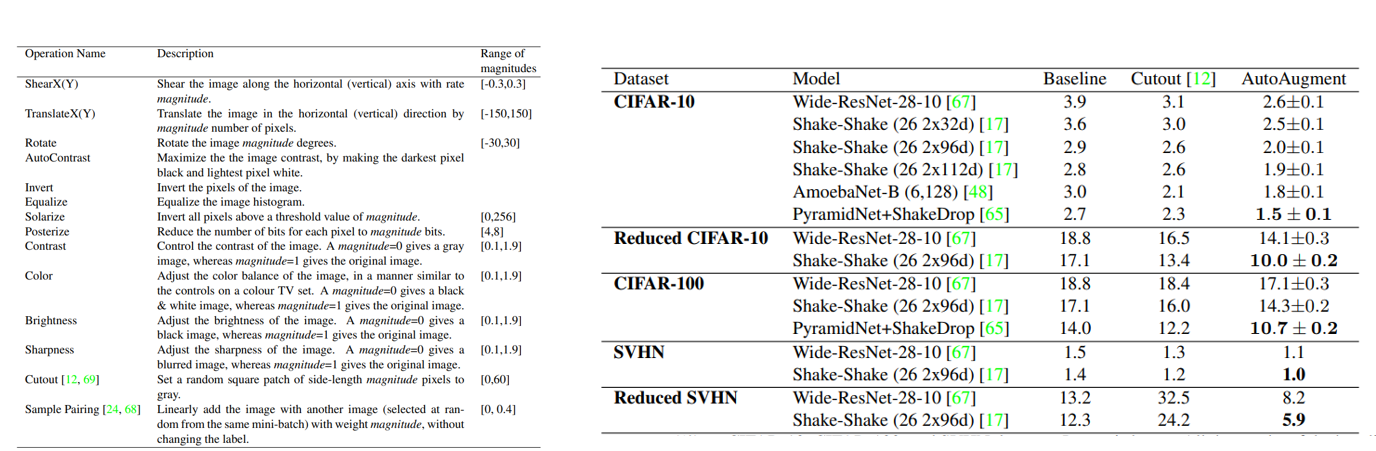
총 16가지 Augmentation 기법들을 Search Space로 사용하였고, 높은 성능을 달성할 수 있었지만 굉장히 많은 Computational Cost와 Time을 소모하기도 합니다.
“Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules”, 2019
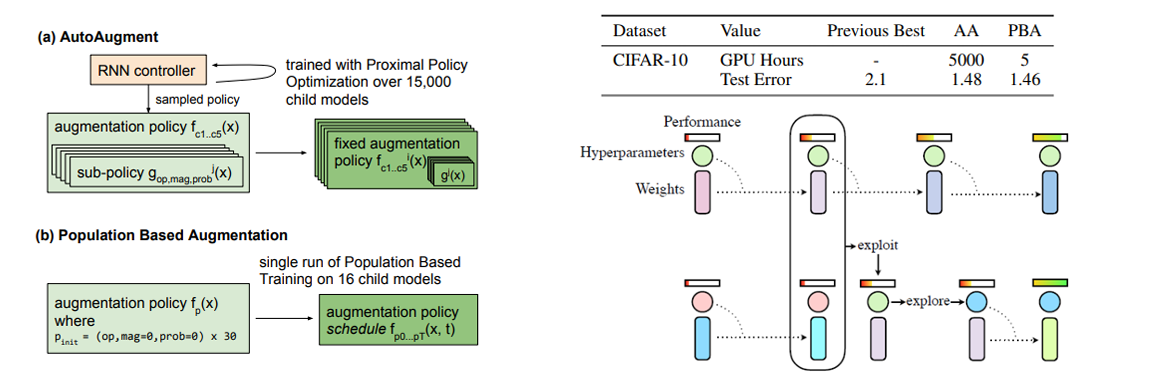
Hyper Parameter Optimization 기법 중 하나인 Population Based Training (PBT) 알고리즘 기반 방식이며, AutoAugment 대비 거의 1000배 빠른 Search 시간을 보여주면서 동시에 비슷한 정확도를 달성할 수 있습니다. 성능이 좋은 모델의 weight는 복제하고(exploit), 그 parameter에 약간의 변형 (explore)를 주는 방식입니다.
“Fast AutoAugment”, 2019
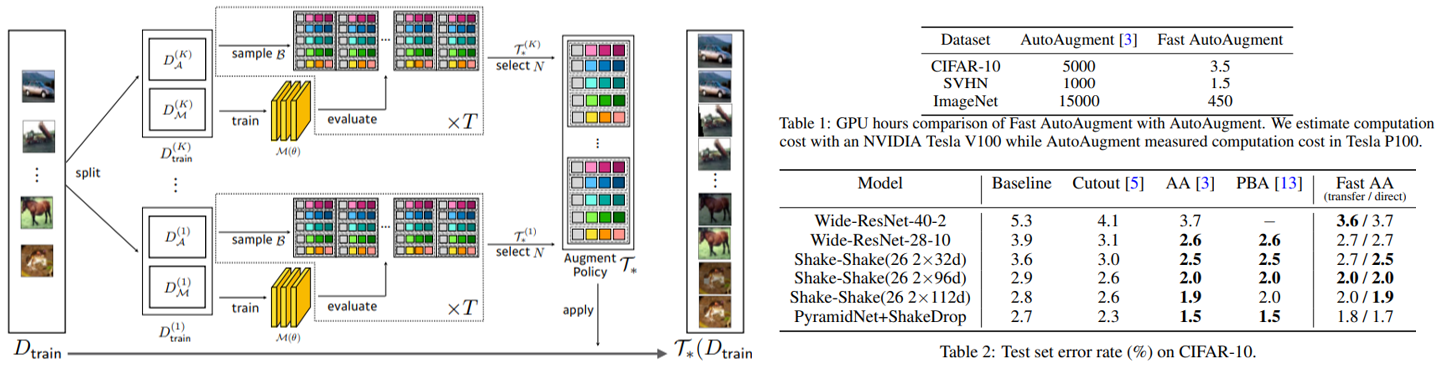
다음은 제가 운영 중인 SNUAI 스터디의 운영진 선배님이시자 이제는 교수님으로 멋진 연구들을 진행하고 계신 임성빈 교수님의 Fast AutoAugment입니다.
Bayesian Optimization 기법인 Tree-structured Parzen Estimator(TPE) 방법을 통해 Augmentation Policy를 추출하고, 학습시킨 모델을 validation을 하는 과정에서 augmentation을 적용하면서 Search 시간을 획기적으로 줄일 수 있고 PBA 보다도 더 빠르면서 비슷한 정확도를 달성할 수 있습니다.
“Faster AutoAugment: Learning Augmentation Strategies using Backpropagation”, 2019

RCNN처럼 Fast 가 있으면 Faster 도 있습니다. Faster AutoAugment는 미분 불가능한 image operation들을 미분 가능하게 해주는 gradient approximation 기법을 통해 discrete search space를 continuous search space로 relaxing 시켜주면서 gradient-based optimization을 통해 더 빠르게 search를 할 수 있는 방법을 제안합니다.
이러한 방법은 gradient-based NAS의 대표적인 방법인 “DARTS: Differentiable Architecture Search” 에서 영감을 얻었다고 합니다. Fast AutoAugment보다 훨씬 빠르지만 약간 정확도는 떨어지는 결과를 보이고 있습니다. ImageNet 데이터 셋에서 2.3 GPU hour로 Search가 된다는 점은 굉장히 인상깊은 것 같습니다.
“RandAugment: Practical automated data augmentation with a reduced search space”, 2019
위의 방법들은 AutoML로 꾸역꾸역 최적의 Augmentation Policy를 찾는 방법이었는데, 아예 찾는 것을 생략하고 매 batch를 추출할 때마다 여러 Augmentation 옵션들 중에서 random하게 추출해서 적용을 하는 기법을 제안합니다. 엄청 단순한데 성능도 엄청 좋습니다. 바로 RandAugment 기법입니다.

위의 그림과 같이 코드 단 몇 줄로 쉽게 구현이 가능하고 성능도 엄청 좋습니다. 전체 transform 중에 몇 개씩 뽑을 지(N)와 Augmentation의 강도를 어느 정도로 줄지(M)이 hyper parameter이며, 엄청 단순한데 성능이 되게 잘 나와서 CutMix와 마찬가지로 제가 각종 Challenge에서 필수로 사용하는 기법입니다.
“UniformAugment: A Search-free Probabilistic Data Augmentation Approach”, 2020
마지막은 RandAugment에서 hyper parameter search를 해야 하는 점에서 출발하여 아예 search 없이 random하게 augmentation을 확률적으로 적용하는 UniformAugment라는 기법을 제안한 논문입니다.
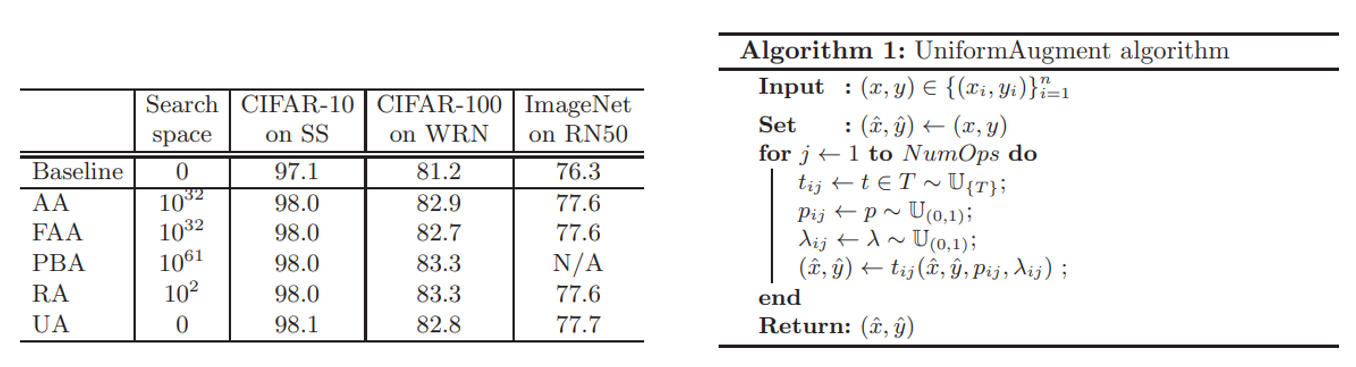
매 batch를 뽑을 때 RandAugment처럼 N개를 고정해서 추출하는 것이 아니라, 모든 연산을 0 과 1 사이의 확률 값을 통해 넣을 지 말지를 정하고, Magnitude도 0 과 1 사이의 확률 값을 통해 정하게 됩니다. 즉, N과 M을 Probabilistic 하게 바꿔주면서 아예 hyper parameter가 사라지게 됩니다. 이렇게 하면 tuning이 필요 없으며 RandAugment에 준하는 성능을 얻을 수 있다고 합니다. 이 방법도 다음에 기회가 되면 사용해볼 예정입니다.
결론
오늘은 Image Data Augmentation 서베이 페이퍼를 기반으로 각종 논문들을 짤막하게 소개 드렸습니다. 각 방법들의 디테일한 정보들이 궁금하시면 원 논문을 참고하시는 것을 추천 드립니다. 긴 글 읽어 주셔서 감사합니다.
comments powered by Disqus