Anomaly Detection 개요: [1] 이상치 탐지 분야에 대한 소개 및 주요 문제와 핵심 용어, 산업 현장 적용 사례 정리
안녕하세요. 이번 포스팅에서는 Anomaly Detection(이상 탐지)에 대해 소개를 드리고자 합니다. Anomaly Detection이란, Normal(정상) sample과 Abnormal(비정상, 이상치, 특이치) sample을 구별해내는 문제를 의미하며 수아랩이 다루고 있는 제조업뿐만 아니라 CCTV, 의료 영상, Social Network 등 다양한 분야에서 응용이 되고 있습니다. 그러나 Anomaly Detection 용어 외에도 다양한 용어가 비슷한 의미로 사용되고 있어서 이 용어들을 기준에 따라 정리하고 각 용어에 대해 자세히 설명하겠습니다. 이어질 포스팅에서는 Anomaly Detection 연구 분야에서 다루는 Out-of-distribution(OOD) Detection 문제에 대해 여러 논문과 함께 깊이 있게 소개할 예정입니다.
Anomaly Detection 연구 분야 용어 정리
Anomaly Detection은 학습 데이터 셋에 비정상적인 sample이 포함되는지, 각 sample의 label이 존재하는지, 비정상적인 sample의 성격이 정상 sample과 어떻게 다른지, 정상 sample의 class가 단일 class 인지 Multi-class 인지 등에 따라 다른 용어를 사용합니다. 이 용어들을 정리하기 위해 학계에서 다뤄지고 있는 Anomaly Detection 논문 서베이를 수행하고 각 논문을 참고하여 용어를 정리해보았습니다.
- 논문 서베이 자료는 “awesome-anomaly-detection” GitHub Repository 에서 확인하실 수 있습니다.
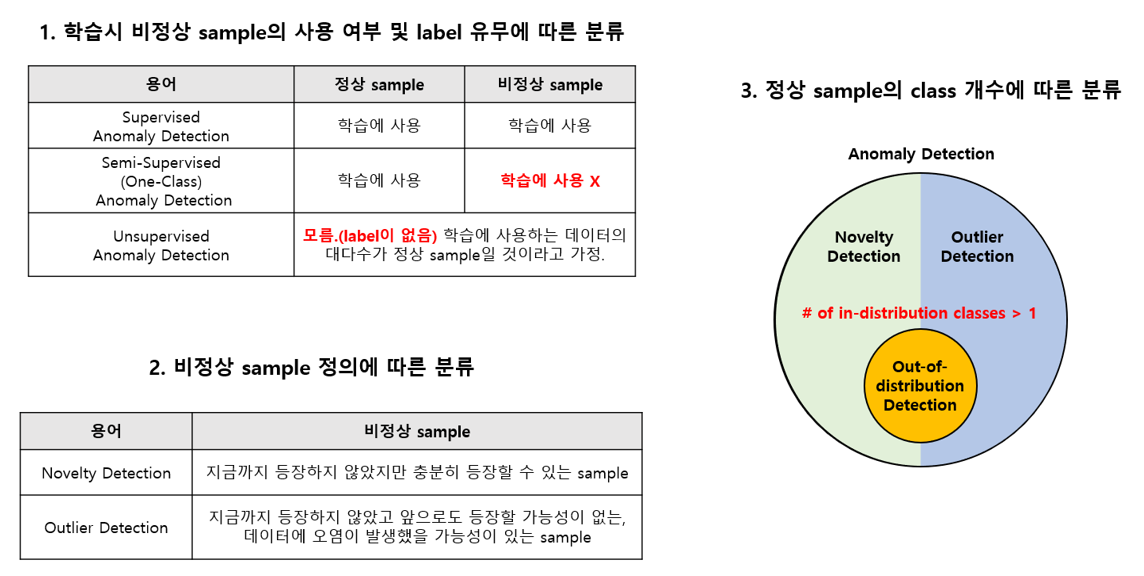
1. 학습시 비정상 sample의 사용여부 및 label 유무에 따른 분류
- Supervised Anomaly Detection
주어진 학습 데이터 셋에 정상 sample과 비정상 sample의 Data와 Label이 모두 존재하는 경우 Supervised Learning 방식이기 때문에 Supervised Anomaly Detection이라 부릅니다. Supervised Learning 방식은 다른 방법 대비 정확도가 높은 특징이 있습니다. 그래서 높은 정확도를 요구로 하는 경우에 주로 사용되며, 비정상 sample을 다양하게 보유할수록 더 높은 성능을 달성할 수 있습니다.
하지만 Anomaly Detection이 적용되는 일반적인 산업 현장에서는 정상 sample보다 비정상 sample의 발생 빈도가 현저히 적기 때문에 Class-Imbalance(불균형) 문제를 자주 겪게 됩니다. 이러한 문제를 해결하기 위해 Data Augmentation(증강), Loss function 재설계, Batch Sampling 등 다양한 연구가 수행되고 있습니다.
- 장점: 양/불 판정 정확도가 높다.
- 단점: 비정상 sample을 취득하는데 시간과 비용이 많이 든다. Class-Imbalance 문제를 해결해야 한다.
- Semi-supervised (One-Class) Anomaly Detection
Supervised Anomaly Detection 방식의 가장 큰 문제는 비정상 sample을 확보하는데 많은 시간과 비용이 든다는 것입니다. 제조업의 경우를 예로 들면, 수백만 장의 정상 sample이 취득되는 동안 단 1~2장의 비정상 sample이 취득되는 상황이 종종 발생합니다.
제조업에서 Supervised Learning 방식으로 학습하기 위해 각 class 당 최소 100장의 이미지가 필요하다고 가정하면, 실제로는 sample 1억 장을 모아야 100장 정도의 비정상 sample을 확보할 수 있습니다. 이런 상황에서는 데이터 셋을 확보하는데 굉장히 오랜 시간이 소요되겠죠?
이처럼 Class-Imbalance가 매우 심한 경우 정상 sample만 이용해서 모델을 학습하기도 하는데, 이 방식을 One-Class Classification(혹은 Semi-supervised Learning)이라 합니다. 이 방법론의 핵심 아이디어는 정상 sample들을 둘러싸는 discriminative boundary를 설정하고, 이 boundary를 최대한 좁혀 boundary 밖에 있는 sample들을 모두 비정상으로 간주하는 것입니다. One-Class SVM 이 One-Class Classification을 사용하는 대표적인 방법론으로 잘 알려져 있으며, 이 아이디어에서 확장해 Deep Learning을 기반으로 One-Class Classification 방법론을 사용하는 Deep SVDD 논문이 잘 알려져 있습니다.
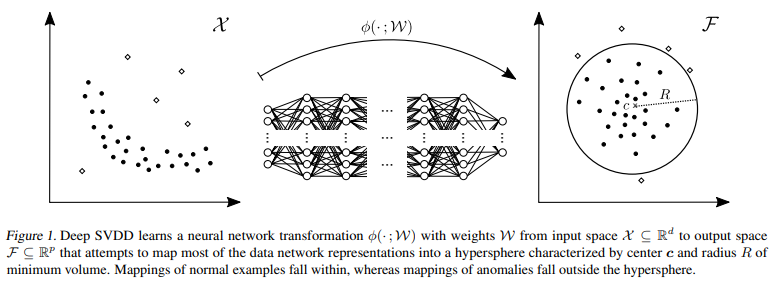
이 외에도 Energy-based 방법론 “Deep structured energy based models for anomaly detection, 2016 ICML” , Deep Autoencoding Gaussian Mixture Model 방법론 “Deep autoencoding gaussian mixture model for unsupervised anomaly detection, 2018 ICLR” , Generative Adversarial Network 기반 방법론 “Anomaly detection with generative adversarial networks, 2018 arXiv” , Self-Supervised Learning 기반 “Deep Anomaly Detection Using Geometric Transformations, 2018 NeurIPS” 등 다양한 시도가 이뤄지고 있습니다.
- 장점: 비교적 활발하게 연구가 진행되고 있으며, 정상 sample만 있어도 학습이 가능하다.
- 단점: Supervised Anomaly Detection 방법론과 비교했을 때 상대적으로 양/불 판정 정확도가 떨어진다.
- Unsupervised Anomaly Detection
위에서 설명드린 One-Class(Semi-supervised) Anomaly Detection 방식은 정상 sample이 필요합니다. 수많은 데이터 중에 어떤 것이 정상 sample 인지 알기 위해서는 반드시 정상 sample에 대한 Label을 확보하는 과정이 필요합니다. 이러한 점에 주목해, 대부분의 데이터가 정상 sample이라는 가정을 하여 Label 취득 없이 학습을 시키는 Unsupervised Anomaly Detection 방법론도 연구가 이뤄지고 있습니다.
가장 단순하게는 주어진 데이터에 대해 Principal Component Analysis(PCA, 주성분 분석)를 이용하여 차원을 축소하고 복원을 하는 과정을 통해 비정상 sample을 검출할 수 있습니다. , Neural Network 기반으로는 대표적으로 Autoencoder 기반의 방법론이 주로 사용되고 있습니다. Autoencoder는 입력을 code 혹은 latent variable로 압축하는 Encoding과, 이를 다시 원본과 가깝게 복원해내는 Decoding 과정으로 진행이 되며 이를 통해 데이터의 중요한 정보들만 압축적으로 배울 수 있다는 점에서 데이터의 주성분을 배울 수 있는 PCA와 유사한 동작을 한다고 볼 수 있습니다.
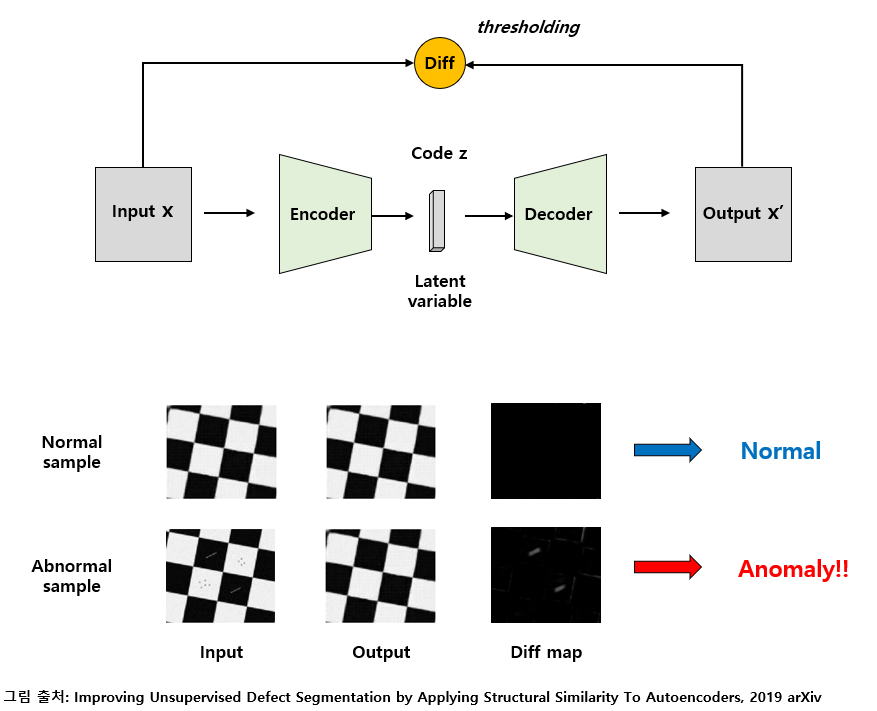
Autoencoder를 이용하면 데이터에 대한 labeling을 하지 않아도 데이터의 주성분이 되는 정상 영역의 특징들을 배울 수 있습니다. 이때, 학습된 autoencoder에 정상 sample을 넣어주면 위의 그림과 같이 잘 복원을 하므로 input과 output의 차이가 거의 발생하지 않는 반면, 비정상적인 sample을 넣으면 autoencoder는 정상 sample처럼 복원하기 때문에 input과 output의 차이를 구하는 과정에서 차이가 도드라지게 발생하므로 비정상 sample을 검출할 수 있습니다.
다만 Autoencoder의 code size (= latent variable의 dimension) 같은 hyper-parameter에 따라 전반적인 복원 성능이 좌우되기 때문에 양/불 판정 정확도가 Supervised Anomaly Detection에 비해 다소 불안정하다는 단점이 존재합니다. 또한 autoencoder에 넣어주는 input과 output의 차이를 어떻게 정의할 것인지(= 어떤 방식으로 difference map을 계산할지) 어느 loss function을 사용해 autoencoder를 학습시킬지 등 여러 가지 요인에 따라 성능이 크게 달라질 수 있습니다. 이렇듯 성능에 영향을 주는 요인이 많다는 약점이 존재하지만 별도의 Labeling 과정 없이 어느정도 성능을 낼 수 있다는 점에서 장단이 뚜렷한 방법론이라 할 수 있습니다.
하지만 Autoencoder를 이용하여 Unsupervised Anomaly Detection을 적용하여 Defect(결함)을 Segment 하는 대표적인 논문들에서는 Unsupervised 데이터 셋이 존재하지 않아서 실험의 편의를 위해 학습에 정상 sample들만 사용하는 Semi-Supervised Learning 방식을 이용하였으나, Autoencoder를 이용한 방법론은 Unsupervised Learning 방식이며 Unsupervised 데이터 셋에도 적용할 수 있습니다. Autoencoder 기반 Unsupervised Anomaly Detection을 다룬 논문들은 다음과 같습니다.
- Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders
- Deep Autoencoding Models for Unsupervised Anomaly Segmentation in Brain MR Images
- MVTec AD – A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection
Autoencoder 기반의 anomaly detection 방법론에 대한 설명은 마키나락스 김기현님 블로그 글 에 잘 정리가 되어있어 따로 다루진 않을 예정입니다.
- 장점: Labeling 과정이 필요하지 않다.
- 단점: 양/불 판정 정확도가 높지 않고 hyper parameter에 매우 민감하다.
2. 비정상 sample 정의에 따른 분류
다음은 비정상 sample의 정의에 따른 분류입니다. 이 분류는 기준이 엄밀하게 정의가 되지 않아 틀린 부분이 있을 수도 있습니다. 이 점 미리 양해 바라며 나름대로 정리한 내용을 설명하겠습니다.
저는 비정상 sample을 정의하는 방식에 따라 크게 Novelty Detection과 Outlier Detection으로 구분합니다. 다만 종종 두 방법론을 합쳐서 Anomaly Detection라 부르기도 합니다. 개인적인 생각으로는 Novelty Detection과 Outlier Detection은 용어가 가지는 뉘앙스의 차이가 존재하다고 느껴서, 예시를 통해 두 용어의 차이를 설명을 드리겠습니다.
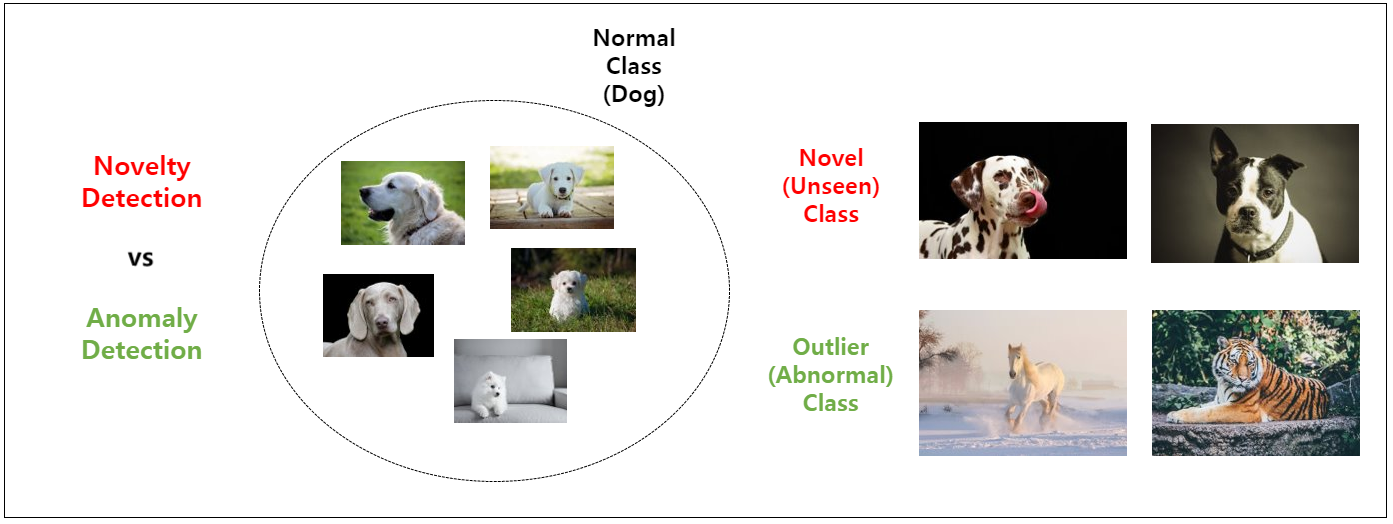
강아지를 normal class로 정의를 한 경우를 예로 들겠습니다. 현재 보유 중인 데이터 셋에 이전에 없던 형태의 새로운 강아지가 등장하는 경우, 이러한 sample을 Novel sample, Unseen sample 등으로 부를 수 있습니다. 그리고 이러한 sample을 찾아내는 방법론을 Novelty Detection이라 부를 수 있습니다.
마찬가지로 새로운 sample이 등장했을 때, 이번엔 강아지가 아닌 호랑이, 말, 운동화, 비행기 등 강아지와 전혀 관련 없는 sample이 등장한다고 가정해보겠습니다. 이러한 sample들을 Outlier sample, 혹은 Abnormal sample이라 부르며, 이러한 sample을 찾아내는 문제를 Outlier Detection이라 부를 수 있습니다.
사실 두 용어의 기준이 명확하진 않습니다. 어떻게 보면 혼재되어서 사용이 되는 것이 당연한 현상이라 볼 수 있습니다. 굳이 두 용어를 구분하면, 위에서 예시로 설명드렸던 관점에서의 뉘앙스 차이로 구분하는 방법이 있다고 이해하시면 좋을 것 같습니다.
Novelty Detection은 지금까지 등장하지 않았지만 충분히 등장할 수 있는 sample을 찾아내는 연구, 즉 데이터가 오염이 되지 않은 상황을 가정하는 연구와 관련된 용어라고 할 수 있고, Outlier Detection은 등장할 가능성이 거의 없는, 데이터에 오염이 발생했을 가능성이 있는 sample을 찾아 내는 연구와 관련된 용어 정도로 구분하여 정리할 수 있습니다.
3. 정상 sample의 class 개수에 따른 분류
앞서 설명드린 두 가지 기준은 데이터 셋이 정상 sample이 단일 class로 구성이 되어있고, 단순 양/불 판정을 하는 경우에 대해서만 가정했지만, 실제 환경에서는 정상 sample이 여러 개의 class로 구성될 수 있습니다.
그러나 정상 sample이 Multi-Class인 상황에서도 위의 Novelty Detection, Outlier Detection 기준을 똑같이 적용할 수 있습니다. 보통 이러한 경우 정상 sample이라는 표현 대신 In-distribution sample이라는 표현을 사용합니다.
In-distribution 데이터 셋에 위의 예시 그림처럼 흰색 강아지만 있는 것이 아니라, 골든 레트리버, 닥스훈트, 도베르만, 말티즈 등 4가지 종류의 강아지 sample들이 존재한다고 가정하면, 불독 sample은 Novel sample, 호랑이 sample은 Outlier sample로 간주할 수 있습니다.
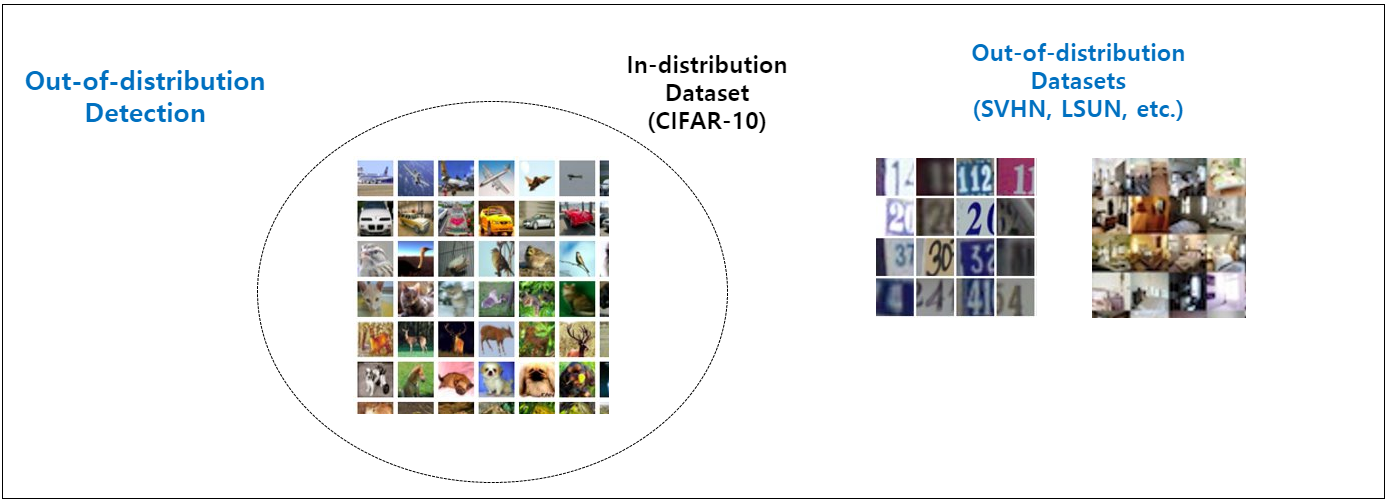
이렇게 In-distribution 데이터 셋으로 network를 학습시킨 뒤, test 단계에서 비정상 sample을 찾는 문제를 Out-of-distribution Detection 이라 부르며 학계에서는 널리 사용되는 주요 Benchmark 데이터 셋들을 이용하여 실험을 수행하고 있습니다. 예를 들면 In-distribution 데이터 셋으로 CIFAR-10을 가정하고 Classifier를 학습시킵니다. 그 뒤, 실내 이미지 데이터 셋인 LSUN, 숫자 관련 데이터 셋인 SVHN 등을 Out-of-distribution 데이터 셋으로 가정한 뒤 test 시에 In-distribution 데이터 셋인 CIFAR-10은 얼마나 정확하게 분류를 하는지, LSUN, SVHN 등 Out-of-distribution 데이터 셋은 얼마나 잘 걸러낼 수 있는지를 살펴보는 방식을 사용하고 있습니다.
대부분의 연구에서 주로 사용하는 SoftMax 기반 classifier는 class 개수를 정해 놓고 가장 확률이 높은 class를 결과로 출력하는 방식이기 때문에, 위에서 예시로 들었던 4가지 종류의 강아지를 구분하는 classifier에 호랑이 이미지를 넣어주면 사람은 비정상 sample이라고 구분할 수 있는 반면 classifier는 4가지 class 중 하나의 class로 예측을 하게 됩니다. 이러한 Outlier sample을 걸러 내기 위해 Out-of-distribution Detection 알고리즘을 사용할 수 있습니다.
또한 불독 이미지처럼 Novel 한 sample이 관찰됐을 때 이를 걸러낸 뒤, classifier가 기존에 있는 4가지 class 대신 불독이 새로 추가된 5가지 class를 구분하도록 학습하는 Incremental Learning 방법론과도 응용할 수 있습니다. Out-of-distribution Detection의 문제 정의와 주요 논문들은 다음 포스팅에서 더 구체적으로 다룰 예정이니 다음 포스팅을 기대해주세요!
이렇게 총 3가지 분류 방법으로 용어를 정리하였고, 이를 한 장의 그림으로 요약하면 다음과 같습니다.
각 용어가 지니는 의미와 문제 상황 등을 잘 이해하신다면 추후 Anomaly Detection 관련 논문을 읽으실 때 도움이 될 것이라 생각합니다.
Anomaly Detection의 다양한 적용 사례
위에서 Anomaly Detection의 방법론, 문제 상황 등을 정리하였다면 이번엔 산업 전반적인 분야의 대표적인 적용 사례들을 하나씩 소개드릴 예정입니다. 대부분의 예시는 “Deep Learning for Anomaly Detection: A Survey,” 2019 arXiv 2019년에 작성된 서베이 논문을 참고하여 작성하였습니다.
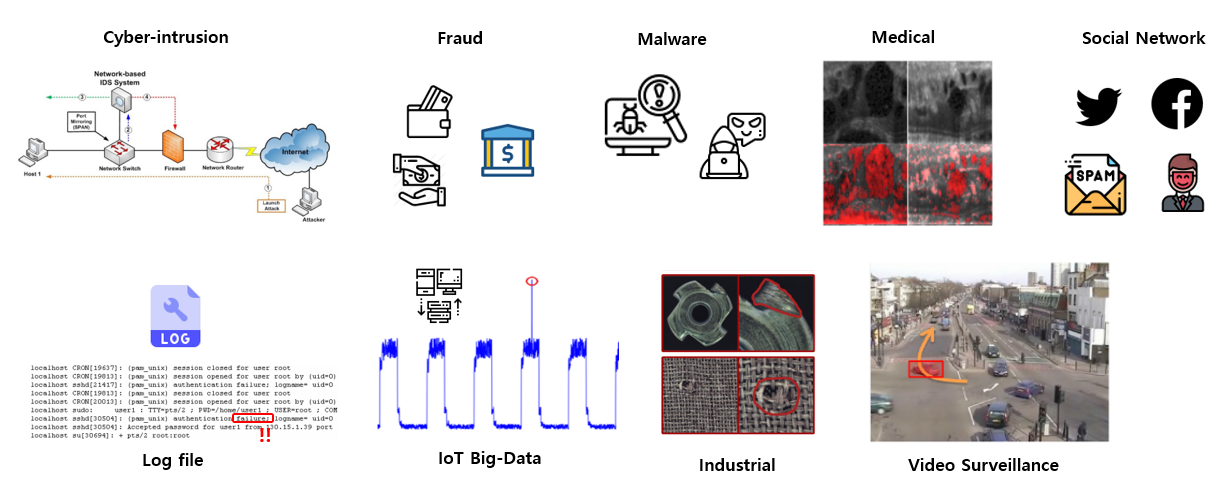
Anomaly Detection이 적용될 수 있는 주요 사례는 다음과 같습니다.
- Cyber-Intrusion Detection: 컴퓨터 시스템 상에 침입을 탐지하는 사례. 주로 시계열 데이터를 다루며 RAM, file system, log file 등 일련의 시계열 데이터에 대해 이상치를 검출하여 침입을 탐지함.
- Fraud Detection: 보험, 신용, 금융 관련 데이터에서 불법 행위를 검출하는 사례. 주로 표로 나타낸(tabular) 데이터를 다루며 Kaggle Credit Card Fraud Detection 과 같은 공개된 challenge도 진행된 바 있음.
- Malware Detection: Malware(악성코드)를 검출해내는 사례. Classification과 Clustering이 주로 사용되며 Malware tabular 데이터를 그대로 이용하기도 하고 이를 gray scale image로 변환하여 이용하기도 함.
- Medical Anomaly Detection: 의료 영상, 뇌파 기록 등의 의학 데이터에 대한 이상치 탐지 사례. 주로 신호 데이터와 이미지 데이터를 다루며 X-ray, CT, MRI, PET 등 다양한 장비로부터 취득된 이미지를 다루기 때문에 난이도가 높음.
- Social Networks Anomaly Detection: Social Network 상의 이상치들을 검출하는 사례. 주로 Text 데이터를 다루며 Text를 통해 스팸 메일, 비매너 이용자, 허위 정보 유포자 등을 검출함.
- Log Anomaly Detection: 시스템이 기록한 log를 보고 실패 원인을 추적하는 사례. 주로 Text 데이터를 다루며 pattern matching 기반의 단순한 방법을 사용하여 해결할 수 있지만 failure message가 새로운 것이 계속 추가, 제외가 되는 경우에 딥러닝 기반 방법론을 사용하는 것이 효과적임.
- IoT Big-Data Anomaly Detection: 사물 인터넷에 주로 사용되는 장치, 센서들로부터 생성된 데이터에 대해 이상치를 탐지하는 사례. 주로 시계열 데이터를 다루며 여러 장치들이 복합적으로 구성이 되어있기 때문에 난이도가 높음.
- Industrial Anomaly Detection: 산업 속 제조업 데이터에 대한 이상치를 탐지하는 사례. 각종 제조업 도메인 이미지 데이터에 대한 외관 검사, 장비로부터 측정된 시계열 데이터를 기반으로 한 고장 예측 등 다양한 적용 사례가 있으며, 외관상에 발생하는 결함과, 장비의 고장 등의 비정상적인 sample이 굉장히 적은 수로 발생하지만 정확하게 예측하지 못하면 큰 손실을 유발하기 때문에 난이도가 높음.
- Video Surveillance: 비디오 영상에서 이상한 행동이 발생하는 것을 모니터링하는 사례. 주로 CCTV를 이용한 사례가 주를 이루며, 보행로에 자전거, 차량 등이 출현하는 비정상 sample, 지하철역에서 넘어짐, 싸움 등이 발생하는 비정상 sample 등 다양한 종류의 비정상 케이스가 존재함.
소개 드린 9가지 예시 외에도 다양한 분야에서 Anomaly Detection이 적용될 수 있으며, 하나의 모델로 모든 문제를 잘 풀기가 어려워서 각 도메인의 특성을 잘 반영하려는 시도들이 논문을 통해 드러나고 있는 것 같습니다.
결론
지금까지 이상치 탐지 (Anomaly Detection) 분야에 대한 전반적인 내용을 크게 연구 분야 용어 정리를 통한 연구 방향 소개와 각종 산업 현장의 적용 사례로 나눠서 설명을 드렸습니다.
학계와 여러 게시물 등에서 Anomaly Detection, Novelty Detection, Outlier Detection 등 여러 용어가 혼재된 채 사용이 되고 있어서 이를 처한 문제 상황에 따라 용어를 정리를 해보았고, 보유하고 있는 데이터 셋의 특징에 따라 Supervised, One-Class(Semi-Supervised), Unsupervised로 나눠서 각각의 특징과 장단점을 소개 드렸습니다. 또한 정상 sample의 class 개수가 여러 개인 상황일 때에도 Anomaly Detection 문제를 다룰 수 있으며, 이때는 Out-of-distribution Detection이라는 용어로 주로 사용이 되며, 학계에서 어떻게 이 문제를 정의하고 실험하는지, 왜 중요한지 등에 대해 알아보았습니다.
또한 Anomaly Detection이 실제 산업 현장에서 적용되는 대표적인 9가지 사례를 소개 드리고, 각각 사례가 어떤 문제를 풀고 있는지, 어떠한 데이터를 주로 다루는지 등을 알아보았습니다.
이어지는 포스팅에서는 위에서 소개 드린 Out-of-distribution Detection이 학계에서 어떻게 연구가 되고 있는지 초창기 논문부터 최신 논문까지 논문을 리뷰하며 각각 논문들의 특징들을 요약하여 설명을 드릴 예정입니다.
Reference
- “awesome-anomaly-detection” GitHub Repository
- Larry M. Manevitz, Malik Yousef. “One-Class SVMs for Document Classification.” Journal of Machine Learning Research, 2001.
- Lukas Ruff, et al. “Deep One-Class Classification.” In International Conference on Machine Learning (ICML), 2018.
- Shuangfei Zhai, et al. “Deep structured energy based models for anomaly detection.” In International Conference on Machine Learning (ICML), 2016.
- Bo Zong, et al. “Deep autoencoding gaussian mixture model for unsupervised anomaly detection.” In International Conference on Learning Representations (ICLR), 2018
- Dan Li, et al. “Anomaly detection with generative adversarial networks.” arXiv, 2018.
- Izhak Golan, Ran El-Yaniv. “Deep Anomaly Detection Using Geometric Transformations.” In Conference on Neural Information Processing Systems (NeurIPS), 2018.
- 마키나락스 김기현님 블로그 글
- Raghavendra Chalapathy, Sanjay Chawla. “Deep Learning for Anomaly Detection: A Survey.” arXiv, 2019.
- Kaggle Credit Card Fraud Detection