ICLR 2020 image recognition paper preview
안녕하세요, 이번 포스팅에서는 2020년 4월 26일 ~ 30일 에티오피아 아디스아바바에서 열리는 ICLR 2020 학회에 accept된 687편의 논문들 중 제 관심사인 이미지 인식과 관련이 있는 21편의 논문을 추려서 간단하게 요약하여 설명을 하는 글을 작성할 예정입니다. 제 블로그의 주요 학회 Preview 글은 이번이 5번째를 맞이하게 되었습니다!
이전 글들은 다음과 같습니다.
ICLR 2020 Paper Statistics
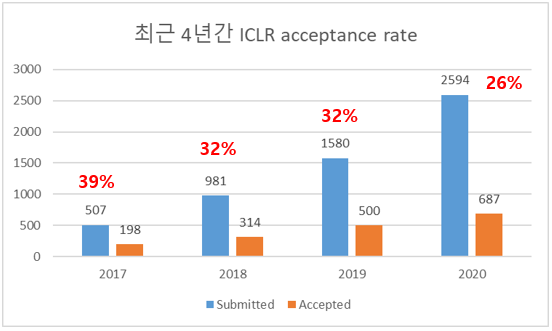
작년은 제출된 1580편 중에 500편이 accept 되었는데, 올해는 제출된 논문 수는 2594편으로 작년 대비 64% 증가하였고, accepted paper 수는 687편으로 작년 대비 37% 증가하였습니다. 이에 따라 acceptance rate도 32%에서 26%로 크게 떨어진 것을 확인할 수 있습니다.
작년과 마찬가지로 ICLR OpenReview Data Repository를 참고하여 ICLR 2020에 제출된 논문들의 통계 자료를 인용하였습니다.
우선 올해는 작년과 다르게 8점 만점으로 rating을 주었고 accepted paper는 평균 6.24점의 rating을, rejected paper는 평균 3.42점의 rating을 받았다고 합니다. 또한 키워드 분석에선 Compositionality, Disentanglement, QuestionAnswering, DeepLearningTheory 등의 키워드를 포함하는 논문이 평균 rating이 높았다고 합니다.
올해는 총 687편의 논문이 발표가 될 예정이며, 이 중 48편은 oral paper, 108편은 spotlight paper입니다. 저는 이 논문들 중 21편을 추려서 소개를 드릴 예정입니다.
ICLR 2020 Image Recognition 관련 논문 소개
앞서 말씀드렸듯이 제 관심사에 의거하여 21편의 논문을 추렸고, 5편의 oral paper, 5편의 spotlight paper, 11편의 poster paper로 준비를 하였습니다. 비율을 정해 놓고 선택한 것은 아니고 제목과 Abstract 정도만 보고 추렸으며, 오늘 소개 드리지 않은 논문들도 굉장히 재미있는 논문이 많으니 오해 없으시길 바랍니다!
1. Federated Learning with Matched Averaging (Oral)
- rating: 8 / 8 / 8, avg 8
- 스마트폰, 차량, 센서 등 edge device들은 자체적으로 많은 양의 데이터를 취득하여 학습할 수 있지만 data privacy, network bandwidth limitation 등의 문제로 인해 모든 데이터를 data center로 전송하여 중앙에서 학습을 진행하고 다시 뿌려주는 것이 비효율적임.
- 이를 해결하기 위해 각 edge device(client)에서 각각의 축적된 데이터셋으로 locally 학습을 한 뒤, 각 client에서 학습된 local model들을 합쳐서 하나의 shared global model 로 합쳐주는 방법을 Federated Learning 이라 부르며 향후 많은 주목을 받을 것으로 개인적으로 기대하는 연구 분야임.
- Local model 들을 합쳐주는 방식으로 각 model들의 parameter들을 client dataset의 크기에 비례하게 averaged element-wise로 합쳐주는 FedAvg 방식이 대표적인 방식이며, 이 외에도 client local cost function에 proximal term을 추가한 FedProx 등 여러 연구들이 진행이 되고 있음.
- FedAvg 등의 방식은 Neural Network Parameter의 permutation invariant nature (NN의 parameter의 순서를 바꿔도 같은 local optima에 도달할 수 있음) 로 인해 좋은 성능을 달성하기 어려우며 이를 해결하기 위해 Probabilistic Federated Neural Matching(PFNM) 방식이 제안됨.
- 하지만 PFNM 방식은 Modern architecture에 대해 적용하면 성능 향상이 거의 없음을 밝히고, 이를 개선하기 위해 layers-wise federated learning 알고리즘인 Federated Matched Averaging (FedMA) 방식을 제안하였고, real dataset에도 적용 가능함을 실험적으로 보임. 다만 여기에서 말하는 Modern architecture는 1-layer LSTM과 VGG-9 정도의 단순한 구조임.
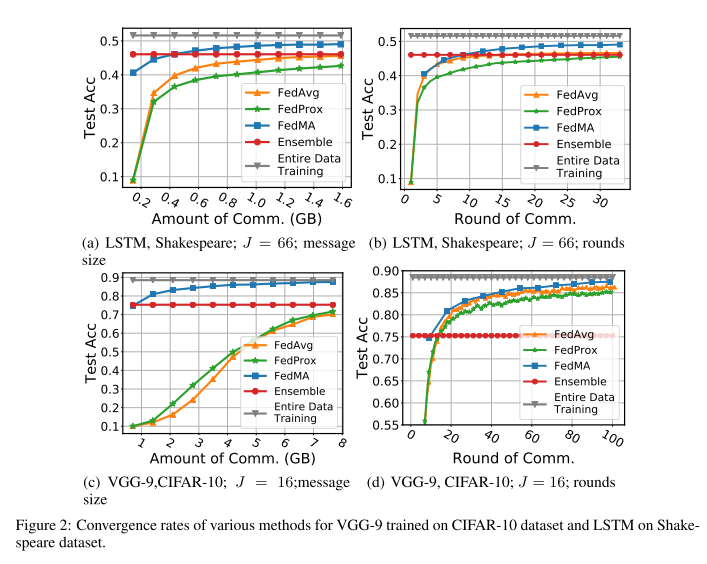
- 성능은 정확도로 평가하였고, data center와 client가 주고 받는 total message size의 양을 늘렸을 때의 결과와, communication round를 늘렸을 때의 결과를 보여주고 있으며 본 논문에서 제안한 FedMA 방식이 가장 우수한 성능을 보임.
2. Restricting the Flow: Information Bottlenecks for Attribution (Oral)
- rating: 8 / 8 / 8, avg 8
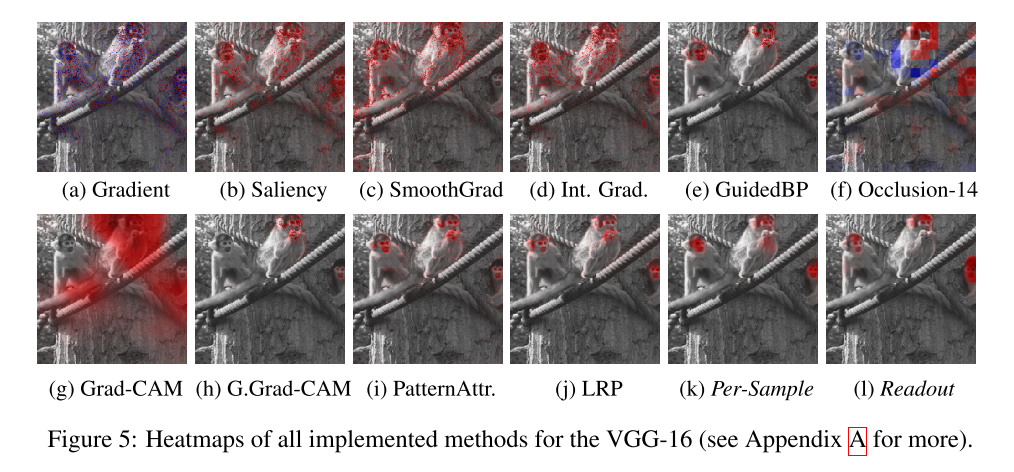
- 해석 가능한 머신러닝 연구에서 자주 사용되는 Attribution 은 주어진 input sample에 대해 model이 어느 부분을 보고 예측을 하였는지를 heatmap 형태로 살펴보는 연구를 의미하며 대표적으로 사용되는 방식이 Occlusion 방식, Grad-CAM 방식 등이 있다.
- Information bottleneck 개념을 attribution 문제에 적용하는 방법을 제안하였음. Bottleneck을 기존 neural network에 주입하고 activation map에 noise를 주입하여 information flow를 제안하는 것이 핵심 아이디어이며, 이를 통해 중요도가 떨어지는 activation은 noise로인해 대체되면서 attribution의 quality가 좋아지는 것을 보임.
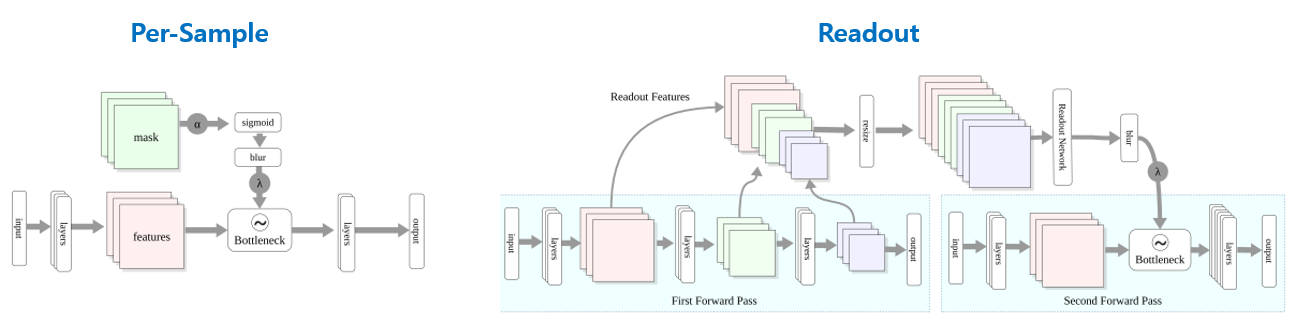
- bottleneck의 parameter를 배우기 위해 single sample만 사용하는 Per-Sample Bottleneck 방식과 전체 데이터셋을 사용하는 Readout Bottleneck 2가지 방식을 제안함.
3. BackPACK: Packing More Into Backprop (Oral)
- rating: 8 / 8 / 8, avg 8
- Engineering 관련 논문이며 우리가 사용하는 대부분의 딥러닝 framework에서 지원하는 automatic differentiation 방식들은 오로지 average mini-batch gradient 계산만 최적화가 되어있음. 하지만 mini-batch gradient의 variance를 구하거나 Hessian을 approximation하는 등 다양한 계산들도 이론적으로는 gradient 계산처럼 최적화할 수 있음.
- 하지만 이러한 계산들은 대부분의 라이브러리에서 최적화가 되어있지 않아서 연구자가 직접 구현해야 하는 어려움이 있었음. 이러한 계산을 도와주는 BackPACK 이라는 framework를 제작하였고 이는 PyTorch에 바로 적용이 가능함.
- Demo Link

4. Adversarial Training and Provable Defenses: Bridging the Gap (Oral)
- rating: 8 / 6 / 8, avg 7.33
- Adversarial Training은 adversarial attack에 의해 생성된 adversarial inputs을 활용하여 학습을 하는 방식을 뜻하고 대체로 강인하게 방어를 하지만 모든 attack을 버틸 수 있다는 guarantee가 부족함. Provable Defenses은 특정 attacker에 대해 강인하게 버틸 수 있다는 guarantee가 있지만 adversarial training보다 standard accuracy가 낮은 단점이 있음. 이러한 두 가지 방식을 동시에 고려하는 학습 방법을 본 논문에서 제안함.
- 매 iteration마다 verifier 는 convex relaxation을 이용하여 network를 certify하는데 집중하고, adversary 는 이 convex relaxation 안에서 실패를 유발할 수 있는 input을 찾는데 집중하도록 하는 layerwise adversarial training 방식을 제안하였고, CIFAR-10 데이터셋에 대해 2/255 L-infinity perturbation에 대해 우수한 성능을 보임.
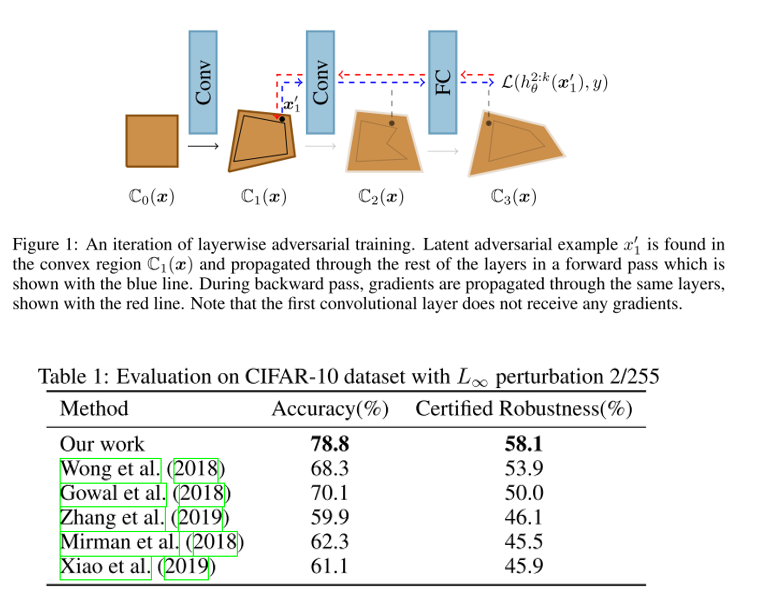
5. Comparing Fine-tuning and Rewinding in Neural Network Pruning (Oral)
- rating: 8 / 6 / 8, avg 7.33
- Network Pruning은 inference cost를 줄이기 위해 자주 사용되는 technique임. 지난 포스팅에서 다뤘던 Lottery Ticket Hypothesis 연구가 큰 주목을 받았으며, 이 논문에서 제안하는 것처럼 한번 pruning을 한 뒤 남은 weight들을 다시 initialize해주는 방법을 rewinding 이라고 표현함.
- 본 논문에서는 기존에 pruning에서 주류로 사용되던 fine-tuning, 2019 ICLR에서 제안된 reinitialization 대비 rewinding이 가지는 장점을 분석하였고, rewinding을 잘 사용하기 위한 방법들을 여러 실험들 통해 분석하고 정리하고 있음.
6. Enhancing Adversarial Defense by k-Winners-Take-All (Spotlight)
- rating: 8 / 8 / 8, avg 8
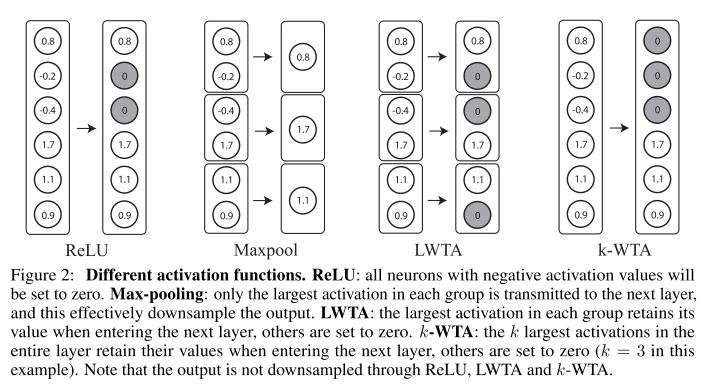
- gradient-based adversarial attack을 잘 방어할 수 있는 간단한 방식을 제안함. Neural Network를 구성할 때 주로 사용되는 activation function(ex, ReLU)을 대체하기 위한 k-Winners-Take-All(k-WTA) 라는 이름의 activation function을 제안하였고, 이를 이용하면 학습 단계에서 거의 무시할만한 overhead만 추가했음에도 gradient-based adversarial attack에 강인하게 방어를 할 수 있음을 보임.
- 또한 k-WTA network의 불연속성이 gradient-based attack을 잘 막을수 있는지 이론적으로 분석하였고 실험 결과로도 효과성을 입증함.
7. NAS-Bench-102: Extending the Scope of Reproducible Neural Architecture Search (Spotlight)
- rating: 8 / 8 / 8, avg 8
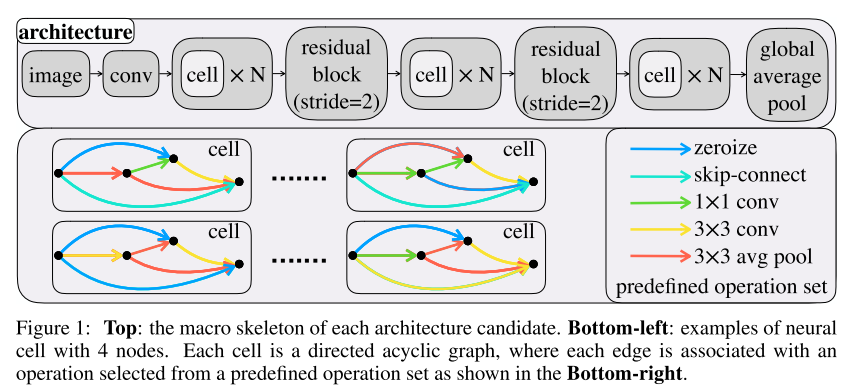
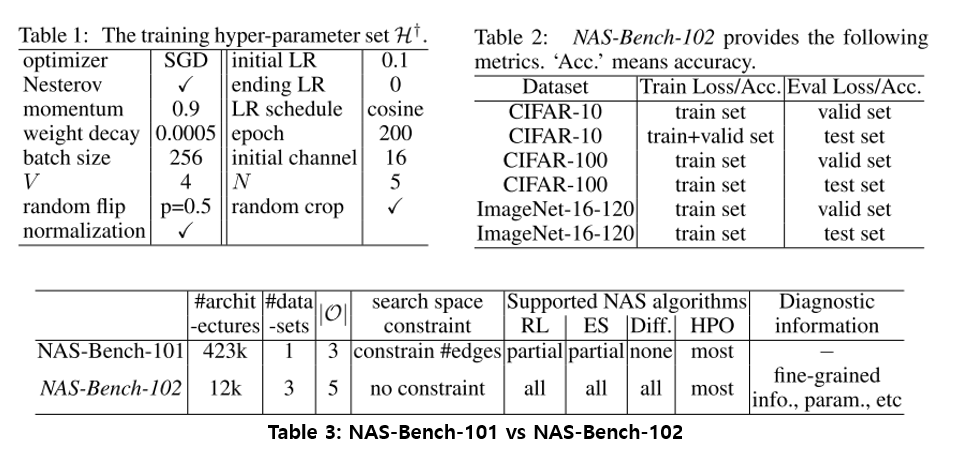
- Neural Architecture Search(NAS) 연구는 최근 1~2년 사이에 굉장히 많은 수의 연구가 진행이 되어왔지만 각 방법마다 search space도 다르고 실험 환경(e.g., hyper-parameters, data augmentation, regularization)도 다 다르게 되어 있어서 공정한 비교가 어려웠음.
- 이를 해결하기 위해 search space를 고정하고 NAS algorithm들을 공정하게 비교할 수 있는 NAS-Bench-102를 제작하고 공유함.
8. And the Bit Goes Down: Revisiting the Quantization of Neural Networks (Spotlight)
- rating: 8 / 6 / 8 / 6, avg 7
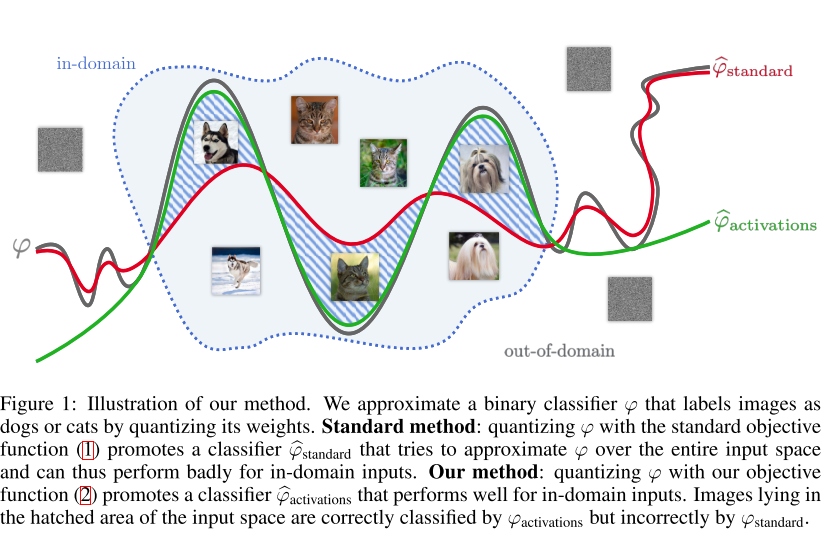
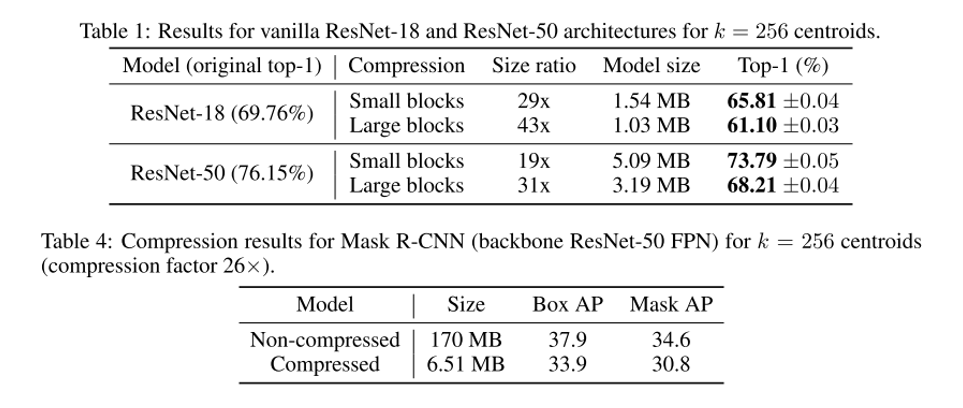
- CNN의 memory footprint를 줄이기 위해 quantization을 많이 사용하는데, 기존에 주류로 사용되던 방식인 scalar quantizers (Deep Compression) , vector quantizers 등 weight에 집중하는 방식과는 다르게 network output, activation에 집중하는 방법을 제안하였음.
- Product Quantization에 기반하여 ResNet 기반 architecture에서 State of the art 성능을 달성하였으며, Mask R-CNN에도 적용이 가능함을 보임. 또한 제안하는 방식은 labeled data 없이도 quantization이 가능하며 CPU에서 효과적인 inference를 가능하게 함.
9. Drawing early-bird tickets: Towards more efficient training of deep networks (Spotlight)
- rating: 8 / 6 / 6, avg 6.67
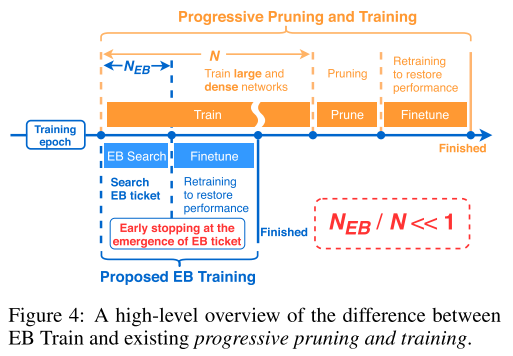
- 이번에도 Lottery Ticket Hypothesis 연구의 후속 연구이며 winning ticket을 찾기 위해 반복적인 prune-retrain 과정을 거쳐야 하는 것을 문제로 지적하며 극 초기 학습 단계에서 winning ticket을 찾는 early-bird ticket 찾는 방법을 제안함. 큰 learning rate에서 early stopping, low-precision training 등 low-cost training 기법들을 활용하고 있음.
- 또한 early-bird ticket을 identify하기 위해 적은 계산량으로 구할 수 있는 mask distance metric 을 제안함.
10. Rethinking the Security of Skip Connections in ResNet-like Neural Networks (Spotlight)
- rating: 6 / 8 / 6, avg 6.67
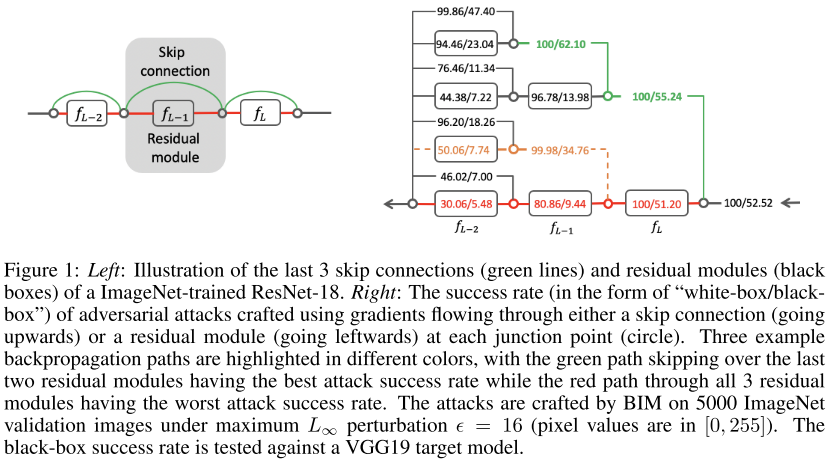
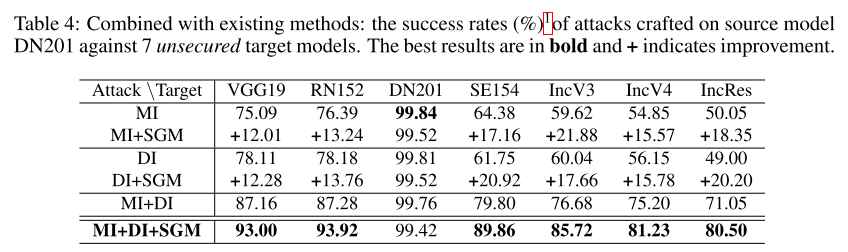
- 6번에서는 adversarial attack을 방어하는데 초점을 두었다면, 본 논문은 공격에 초점을 두었으며, ResNet 이후 굉장히 당연하게 사용되고 있는 skip connection이 highly transferable한 adversarial example을 생성하는데 사용이 될 수 있음을 보임.
- Skip Gradient Method(SGM) 이라는 방법을 제안하였고, 다양한 실험을 통해 기존 방법들 대비 효과적으로 attack을 할 수 있음을 보이고 있고, 기존 존재하는 technique들과 결합하여 사용하면 큰 격차로 State-of-the-art 성능을 달성할 수 있음을 보임.
11. FasterSeg: Searching for Faster Real-time Semantic Segmentation (Poster)
- rating: 6 / 8 / 8, avg 7.33
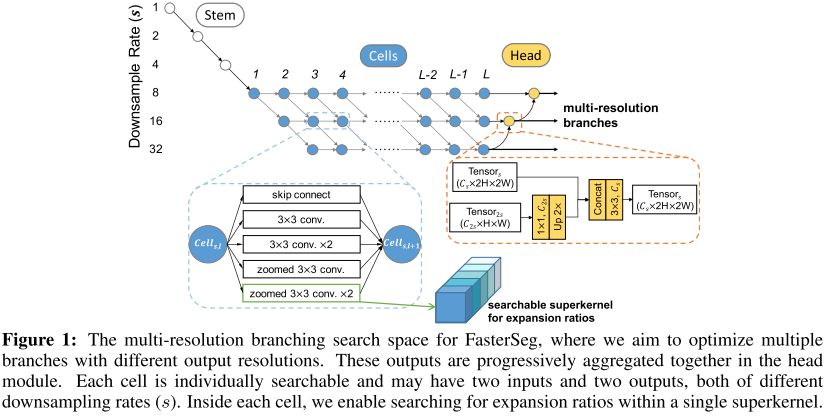
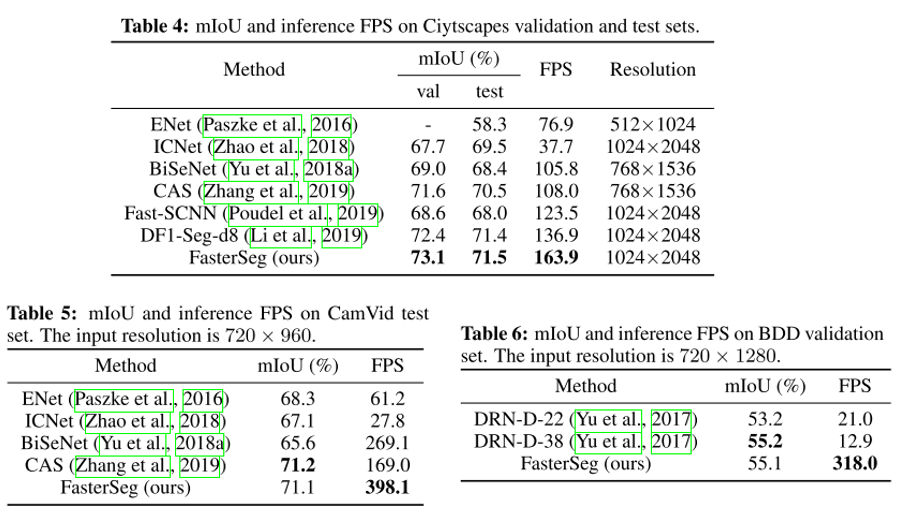
- Neural Architecture Search(NAS)를 Semantic Segmentation에 적용한 연구이며 실시간 inference를 위해 기존에 사람이 제안하여 좋은 결과를 달성하였던 hand-crafted 방식인 multi-resolution branches를 NAS의 search space에 녹여내는 방식인 FasterSeg 을 제안함.
- 또한 latency-constrained search 과정에서 발생하는 “architecture collapse”를 해결하기 위한 decoupled and fine-grained latency regularization 을 제안하였고, search 초기에 teacher-student co-searching 을 적용하여 더 좋은 정확도를 달성함.
- 3가지 데이터셋에서 모두 실시간 적용 가능한 FPS 하에서 기존 방법들 대비 우수한 성능(mIoU)을 보이는 것을 확인할 수 있음.
12. Classification-Based Anomaly Detection for General Data (Poster)
- rating: 8 / 8 / 6, avg 7.33
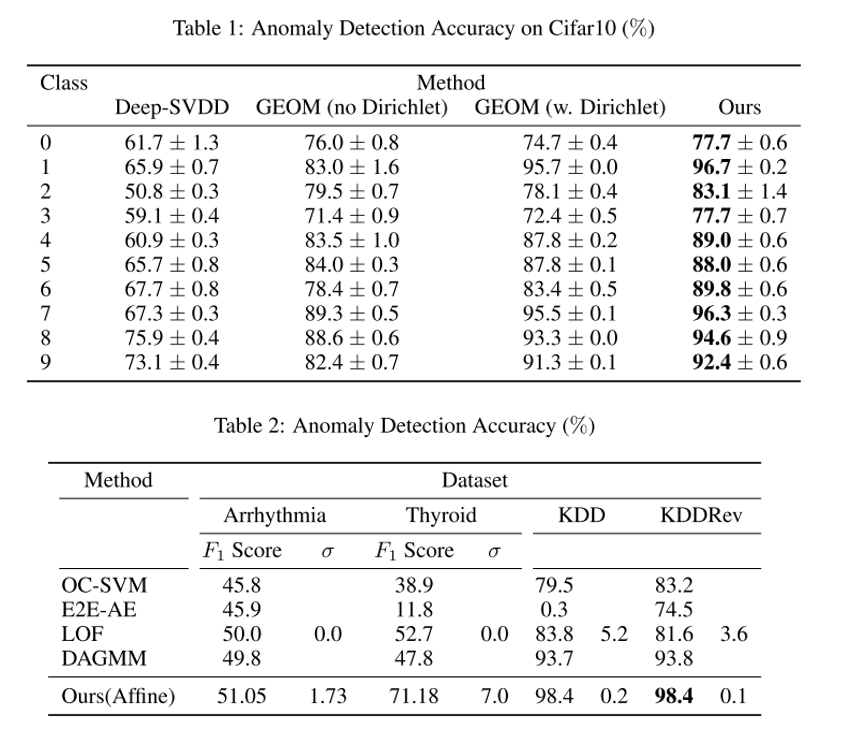
- Classification 기반 Anomaly Detection 연구로는 Deep SVDD 방식과, Geometric-transformation Classification(GEOM) 방식이 대표적임.
- 다만 기존 연구들은 training set에 포함된 sample에는 잘 동작하나 Generalization 성능은 크게 떨어지는 문제를 가지고 있음. 이를 극복하기 위해 open-set classification 에서 활용되는 idea를 anomaly detection에 접목시키는 연구를 수행하였고, 위에서 소개한 Deep SVDD와 GEOM의 핵심 idea를 합쳐서 일반화 성능을 높인 GOAD 라는 방법론을 제안함.
13. How the Choice of Activation Affects Training of Overparametrized Neural Nets (Poster)
- rating: 6 / 8, avg 7
- Overparametrized neural network는 gradient-based method를 통해 학습을 시키면 적은 training error를 가지게 만들 수 있다는 것은 잘 알려진 사실이며 최근 여러 논문 들에서 이론적인 분석이 진행됨.
- 다만 activation function에 대한 이론적인 분석은 잘 수행이 되지 않아서 본 논문에서는 모든 지점에서 미분 가능한 smooth activation function (tanh, swish, polynomial 등)과 그렇지 않은 non-smooth activation function (ReLU, SELU, ELU) 등에 대해 이론적인 분석을 수행함. 다만 논문이 수식이 굉장히 많고 Theorem으로 가득 차 있어서 읽기 전에 각오를 단단히 하는 것을 권장함.
14. Towards Stabilizing Batch Statistics in Backward Propagation of Batch Normalization (Poster)
- rating: 6 / 8 / 6, avg 6.67
- 거의 이제는 필수로 사용되는 Batch Normalization(BN)은 작은 batch size를 사용할 때 성능이 저하되는 것이 문제였음. 이를 개선하기 위해 Group Normalization 등의 연구가 수행되어왔지만 이러한 연구들은 기존 BN보다 성능이 낮게 측정되거나 부가적인 nonlinear operation을 추가해야 하는 단점이 있음.
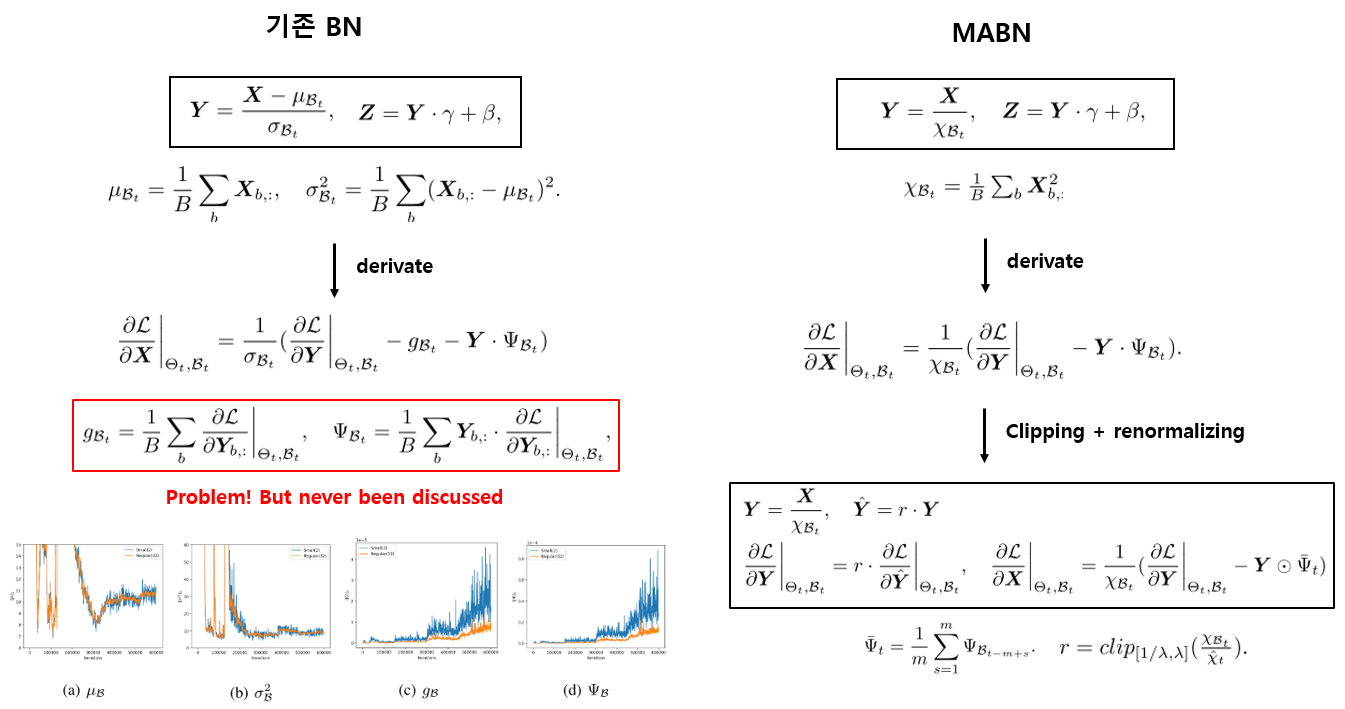
- 본 논문에서는 기존 BN 자체에 집중을 하였고, backward propagation에서 그동안 다뤄지지 않았던 2가지 batch statistics에 주목을 하였고 기존 BN이 작은 batch size에서 잘 동작하지 않은 이유를 분석함. 아래 그림의 빨간 네모 영역으로 강조한 2가지 batch statistics가 작은 batch size에서는 학습을 진행할수록(x축 = iteration) 값이 진동하는 것을 확인할 수 있으며, 이로 인해 성능 저하가 발생함.
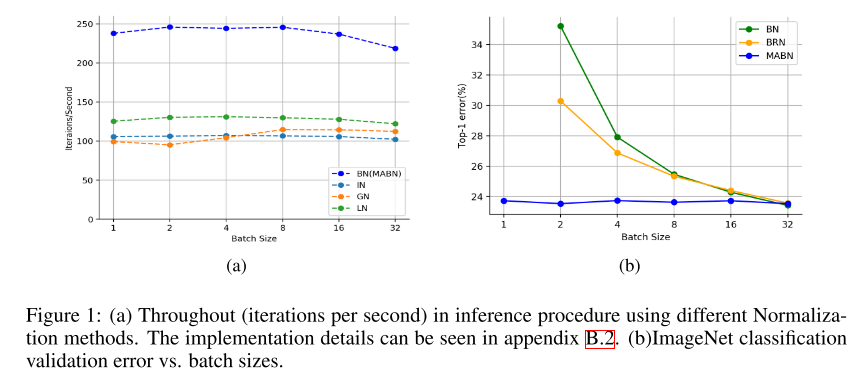
- 이에 기반하여 Moving Average Batch Normalization(MABN) 을 제안함. MABN을 이용하면 작은 batch size에서도 부가적인 nonlinear operation 없이 정확도를 유지할 수 있음을 이론적, 실험적으로 입증함.
- batch statistics를 moving average statistics로 대체하고, feature map X를 normalizing하는 부분을 단순하게 치환하면서 statistics의 수를 줄이고, convolutional kernel의 weight을 centralizing 해주는 방법을 적용함. 또한 학습의 안정성 확보를 위해 BRN에서 사용한 clipping과 renormalizing 기법을 적용하여 좋은 성능을 달성함.
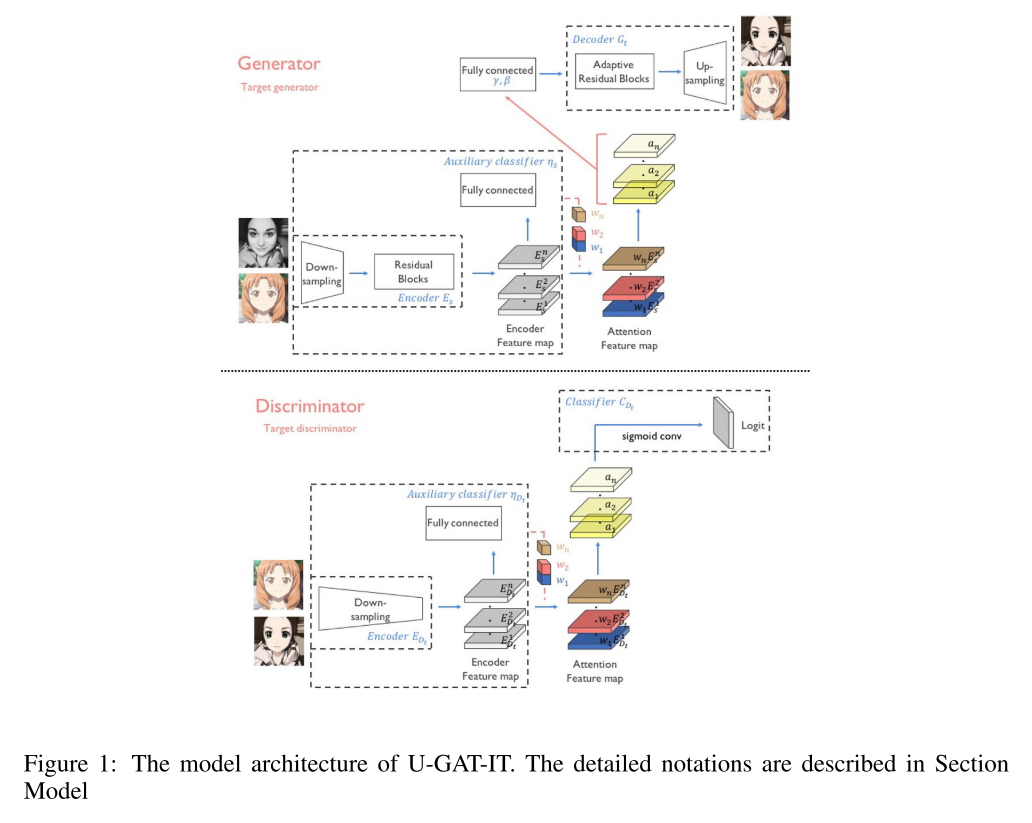
15. U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation (Poster)
- rating: 6 / 8 / 6, avg 6.67
- Unsupervised Image-to-image Translation 연구이며 두 domain 간 변환을 할 때 차이가 나는 영역에 집중하여 변환을 하기 위한 Attention module을 이용하였음.
- 변환을 할 때 데이터셋에 따라서 얼만큼 바꿔줄지를 network가 스스로 학습할 수 있게 도와주는 AdaLIN(Adaptive Layer-Instance Normalization) 기법을 제안하였으며 고정된 network architecture, hyper-parameter 환경에서 기존 모델들 대비 우수한 성능을 보임.
- Official Code: TensorFlow / Pytorch

16. Deep Double Descent: Where Bigger Models and More Data Hurt (Poster)
- rating: 8 / 6 / 6, avg 6.67
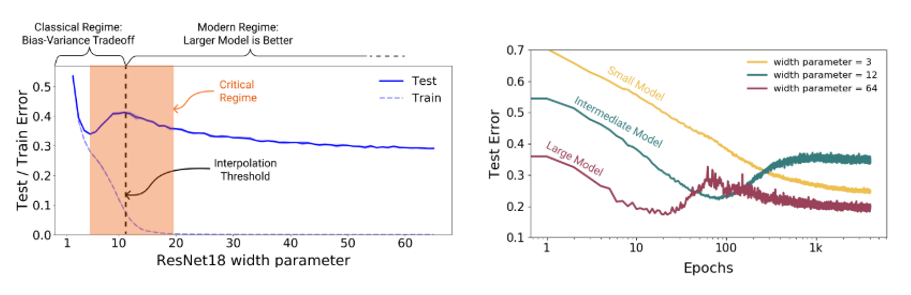
- Deep learning 모델의 size를 키워주면 성능이 어느 순간까지는 좋아지다가 나빠지는 현상이 일반적으로 알고 있던 사실이었는데, 모델의 크기를 계속 키워주면 다시 한번 descent를 하는 현상인 Double Descent 현상을 관찰하고 이를 분석함. 이러한 현상을 통해 Effective Model Complexity(EMC)라는 새로운 complexity measure를 제안하고, 이 measure에 대해 일반화된 double descent를 추측함.
- Model size 뿐 아니라 Training Epoch을 늘려줘도 비슷한 현상이 관찰되며 이 현상은 training sample에 label noise가 포함되어 있는 경우에는 더 잘 관찰이 됨.
- OpenAI blog 글
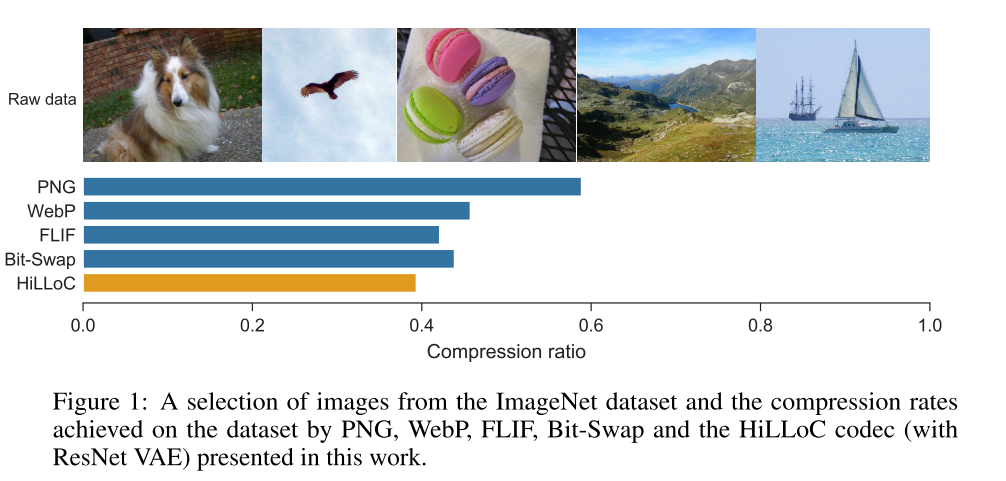
17. HiLLoC: lossless image compression with hierarchical latent variable models (Poster)
- rating: 6 / 6 / 8, avg 6.67
- 지난 2019 ICLR Preview 26번 논문 에서 소개했던 BB-ANS 연구를 기반으로 더 큰 image에 대해서도 lossless compression을 할 수 있는 Hierarchical Latent Lossless Compression(HiLLoc) 방법을 제안하였으며, full size ImageNet 데이터셋에 대해 State of the art compression 성능을 달성함.
- 또한 lossless compression의 편한 prototyping을 위한 open source Craystack 을 제작하여 공개함.
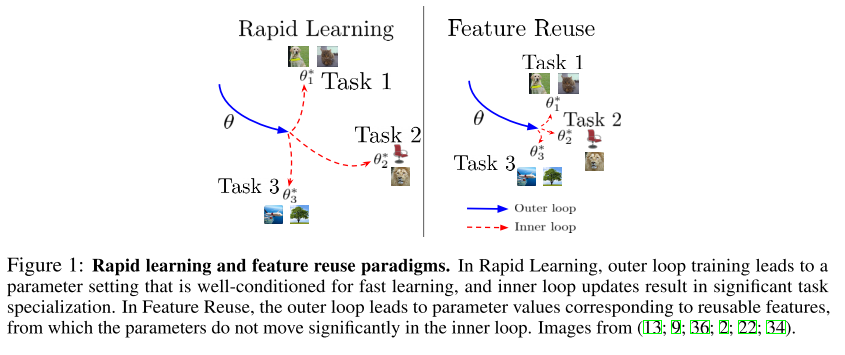
18. Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML (Poster)
- rating: 8 / 3 / 8, avg 6.33
- Few-shot learning 관련 Meta-learning 연구 중 대표격인 Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks (MAML) 은 큰 주목을 받아왔음. 하지만 MAML이 효과적인 이유는 잘 밝혀진 바가 없음.
- 본 논문에서는 2가지 가능성 – Representation 에서의 크고 효과적인 변화를 주기 때문이라는 rapid learning 과 meta training 시 이미 high quality의 feature를 포함하고 있다는 주장인 feature reuse 중 어느 것이 MAML의 좋은 성능에 기여하는지 분석하기 위한 ablation studies를 수행하였고 후자 feature reuse 가 실제로 많은 기여를 하고 있음을 밝힘.
- [PR-213: Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML] Youtube Link
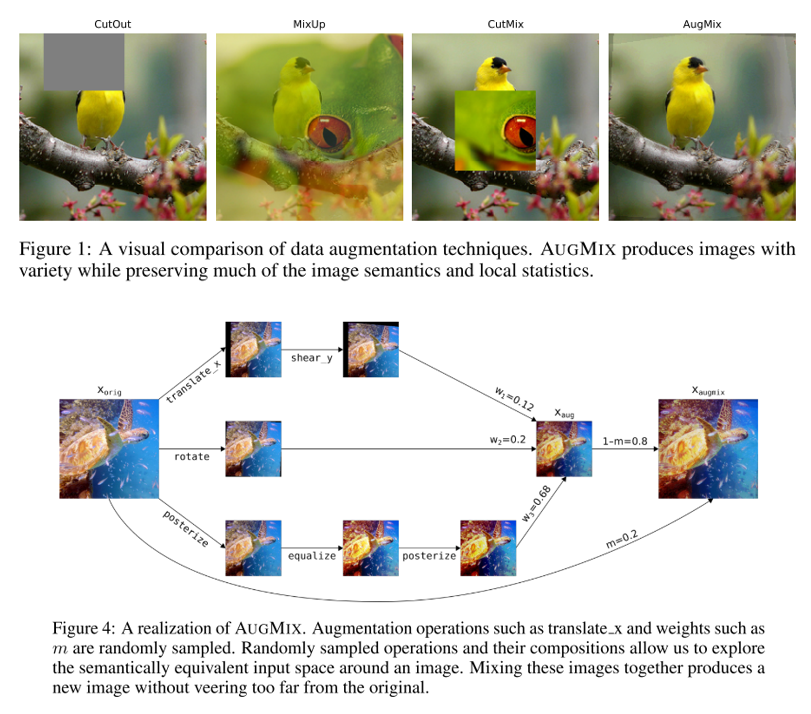
19. AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty (Poster)
- rating: 8 / 3 / 8, avg 6.33
- 실제로 deep learning을 이용하여 image classifier를 학습시킬 때, train 과 test sample들의 distribution이 다른 경우 정확도가 떨어지는 경우를 자주 관찰할 수 있음. 하지만 이런 문제를 해결하기 위한 연구는 많이 진행이 되지 않음. 본 논문은 모델의 robustness를 개선하고 uncertainty를 측정하기 위해 쉽게 구현이 가능한 AugmentAndMix(AugMix) 라는 방법을 제안함.
- original input x 와 augmix를 통해 얻은 2개의 sample인 x_augmix1, x_augmix2 에 대해 Jensen-Shannon Divergence(JSD) 를 구한 뒤, 이를 loss에 반영하여 3개의 sample의 distribution이 유사해지도록 하는 JSD Consistency Loss term을 추가하여 학습을 시키고, 이는 neural network의 response를 smooth하게 해주는 효과를 얻을 수 있음.
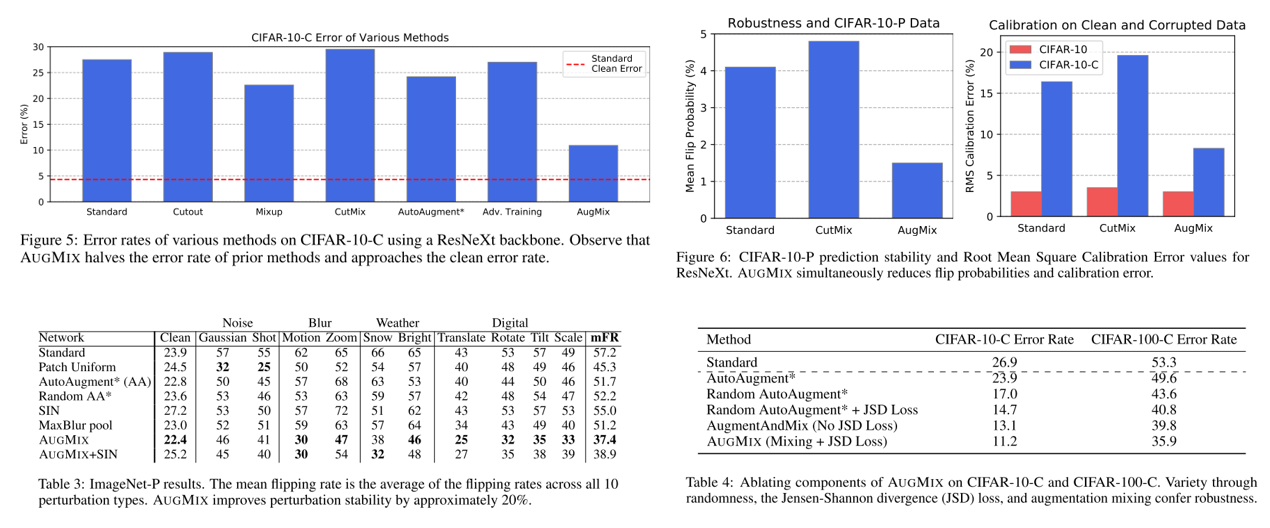
- AugMix를 이용하면 robustness와 uncertainty measure를 크게 향상시킬 수 있으며, CIFAR-10/100-C, ImageNet-C, CIFAR-10/100-P, ImageNet-P 데이터셋에 대해 State of the art 성능을 달성함.
20. Adversarial AutoAugment (Poster)
- rating: 6 / 6 / 6, avg 6
- Augmentation 관련 연구 중 최근 좋은 성능을 달성하여 유명해진 AutoAugment 는 막대한 계산량을 필요로 해서 large-scale problem을 해결하기엔 현실적인 어려움이 있음.
- 이를 해결하기 위해 adversarial method를 적용한 Adversarial AutoAugment 라는 방법론을 제안함. Augmentation policy network는 target network의 training loss를 높이는 것에 집중을 하고, target network는 일반화 성능을 높이기 위해 harder example로부터 robust feature들을 배우는데 집중을 하도록 adversarially 학습을 수행함.
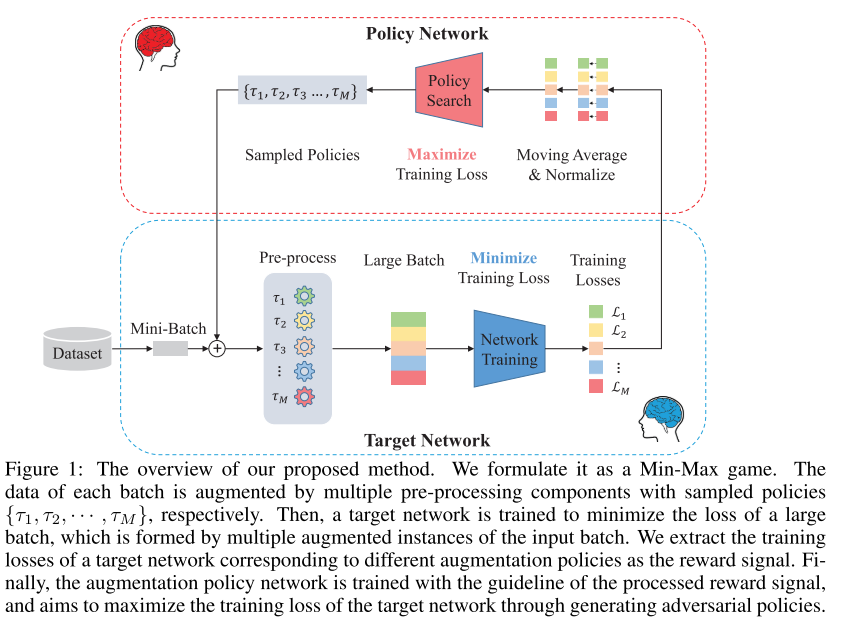
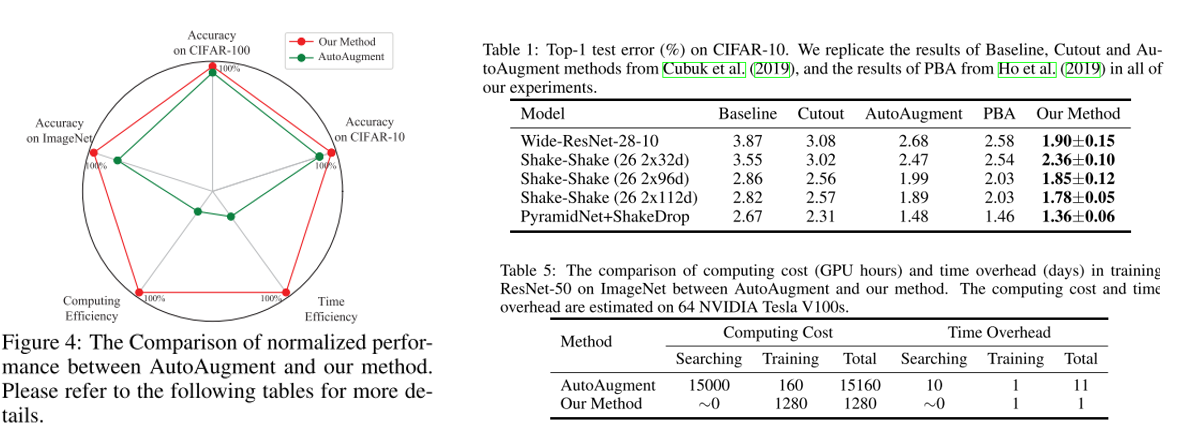
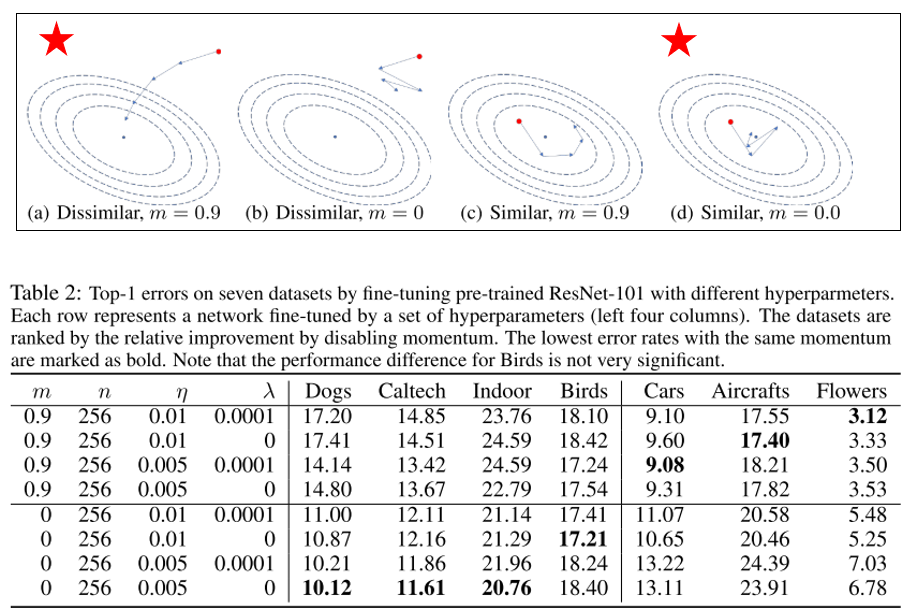
21. Rethinking the Hyperparameters for Fine-tuning (Poster)
- rating: 6 / 6 / 6, avg 6
- pretrained ImageNet으로부터 fine-tuning을 하는 과정은 다양한 computer vision task에서 표준으로 자리를 잡았음. 대부분은 scratch로부터 학습을 할 때 사용했던 hyper-parameter를 임시로 설정한 뒤 그대로 fine-tuning에 사용을 하거나 복잡한 hyper-parameter search 과정을 거쳐야 함. 본 논문에서는 fine-tuning을 할 때 중요하게 고려하여야 하는 hyper-parameter에 대해 관찰을 하였고, 이를 다양한 transfer learning benchmark에 대해 실험적으로 분석하였음.
- 일반적으로는 learning rate와 batch size에 집중을 많이 하는데, momentum 은 잘 다루지 않아 왔음. (일반적으로 0.9 값을 대부분 사용해 왔음) 하지만 momentum value가 fine-tuning 성능에 큰 영향을 줄 수 있으며 fine-tuning을 할 때에는 오히려 momentum을 0으로 사용하는 경우가 더 좋은 결과를 보일 수도 있으며, 이러한 경향은 데이터셋마다 다름을 관찰함.
- 요약하면, Source domain이랑 유사한 target domain 에서는 작은 momentum 값을 이용하는 것이 좋고, source domain과 target domain이 다른 경우에는 큰 momentum 값을 이용하는 것이 유리함.
- fine-tuning을 위한 optimal hyper-parameter는 dataset에도 dependent하고, target domain과 source domain 사이의 similarity에도 관련이 있으며, scratch로부터 학습을 할 때 사용했던 hyper-parameter 셋팅과 다른 값이 최적일 수 있음을 실험적으로 보임.
결론
이번 포스팅에서는 ICLR 2020에 accept된 논문 중 제 관심사인 이미지 인식과 관련이 있는 21편의 논문을 추려서 간단하게.. (요약을 드리려 했으나 설명을 하다 보니 분량이 많이 길어졌네요.. ) 리뷰를 해보았습니다. 각 논문들이 단순하게 실험하고 결과를 보고하는 것이 아니고, 결과에 대해 논리적으로 분석을 잘 하고, 재미있게 설명을 하고 있어서 즐겁게 공부했던 것 같습니다.
제가 소개 드린 21편의 논문 외에도 재미있는 논문이 많으니 관심있으신 분들은 다른 논문들도 읽어 보시는 것을 권장 드립니다. 긴 글 읽어 주셔서 감사합니다!