ICCV 2019 paper preview
안녕하세요, 이번 포스팅에서는 2019년 10월 27일 ~ 11월 2일 우리나라 서울에서 개최될 ICCV 2019 학회의 accepted paper들에 대해 분석하여 시각화한 자료를 보여드리고, accepted paper 중에 제 관심사를 바탕으로 22편의 논문을 간단하게 리뷰를 할 예정입니다. 최근 모든 학회들이 다 그렇듯이 전체 accepted paper가 폭발적으로 많아지고 있습니다. 논문 수가 많다 보니 하나하나 읽기에는 시간이 많이 소요가 되어서 제목만 보고 논문 리스트를 추리게 되었습니다.
당부드리는 말씀은 제가 정리한 논문 리스트에 없다고 재미 없거나 추천하지 않는 논문은 절대 아니고 단지 제 주관에 의해 정리된 것임을 강조 드리고 싶습니다.!!
ICCV 2019 Paper Statistics
메이저 학회에 대한 미리보기 형식의 블로그 글들을 여러 편 썼는데 이번에는 5번째 글을 작성하게 되었습니다.
매번 하던 것처럼 이번에도 ICCV 2019에 몇 편의 논문이 submit되고 accept되는 지 경향을 시각화하였습니다.
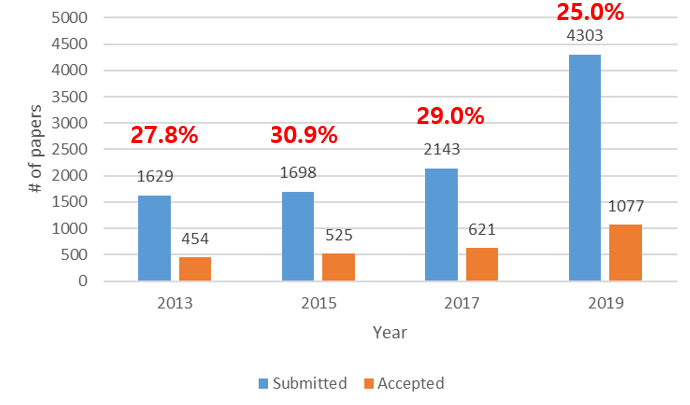
격년으로 진행되어오는 학회인데 2017년까지만 해도 학회에 제출되는 논문의 규모가 약간씩 상승하는 경향을 보였습니다. 그런데 올해에는 2년전에 비해 제출된 논문의 수가 약 2배가량 커졌으며 이에 따라 acceptance rate도 25%대로 크게 떨어진 것을 확인할 수 있습니다. 이러한 경향은 CVPR 2019과도 거의 동일한 것이 흥미로운 점입니다. (2017년 대비 제출된 논문 2배 증가, acceptance rate 30% 25% 감소)
또한 어떤 키워드의 논문들이 많이 제출되는지 경향을 분석하기위해 간단한 python script를 작성해보았습니다.
단순하게 논문 제목에 포함된 키워드를 분석하여 시각화를 하였으며, 코드는 해당 repository 에서 확인하실 수 있습니다. (Star는 저에게 큰 힘이됩니다!)
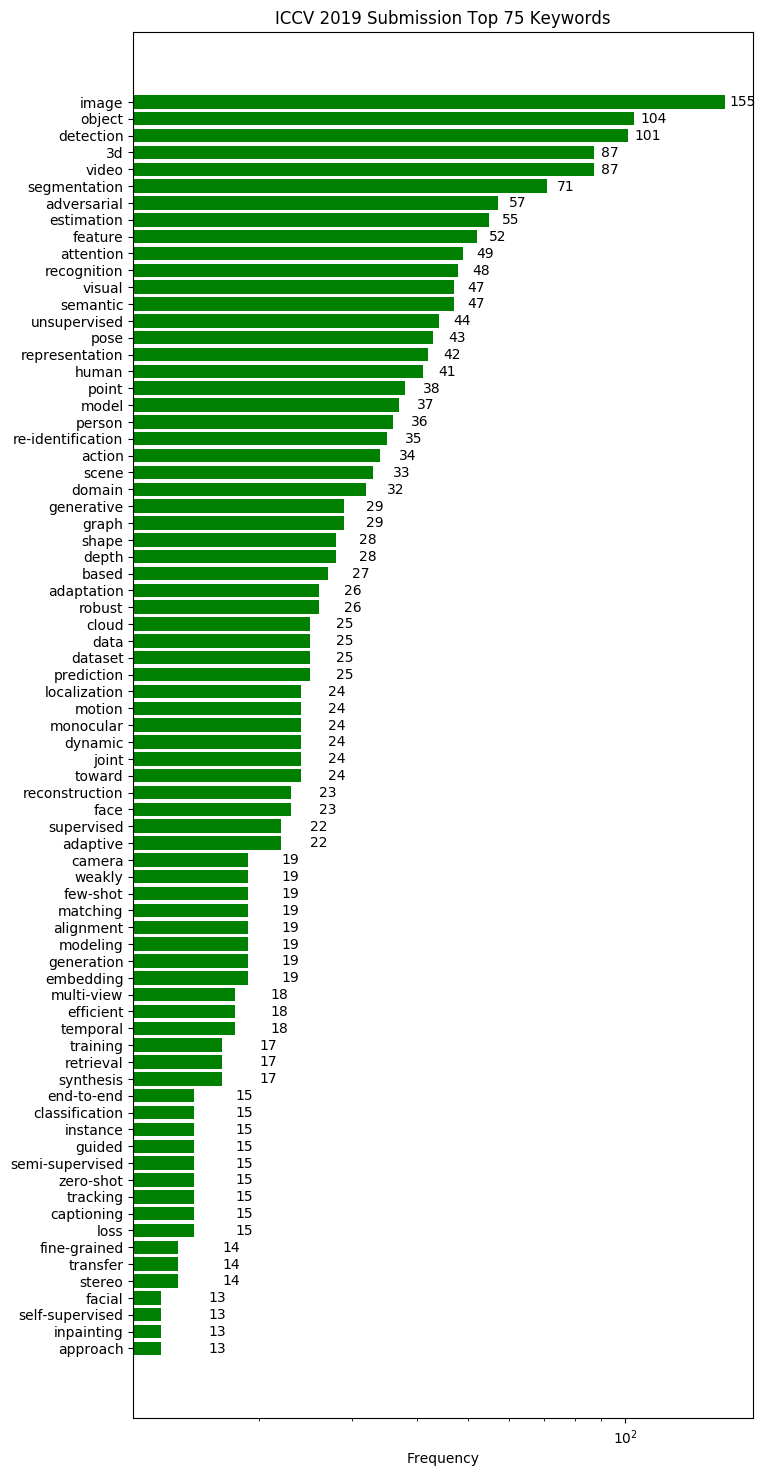
Computer Vision 학회이다 보니 image, video, object 등 general한 키워드들이 주를 이루고 있고, attention, unsupervised, re-identification 등의 키워드를 가진 논문들이 빈도가 증가하였습니다. 이러한 키워드 정보를 참고하면 최근 학회에 제출되는 논문들의 트렌드를 파악하는데 도움이 될 수 있습니다.
참고로 올해는 총 1077편의 논문이 accept 되었고 저는 이 논문들 중 22편을 선정해서 간단하게 소개를 드릴 예정입니다.
ICCV 2019 주요 논문 소개
앞서 말씀드렸듯이 accept된 논문을 모두 다 확인하기엔 시간과 체력이 부족하여서, 간단하게 훑어보면서 재미가 있을 것 같은 논문들을 추려보았습니다. 총 22편의 논문이며, 8편의 oral paper, 14편의 poster paper로 준비를 해보았습니다. 각 논문에서 제안한 방법들을 그림과 함께 간략하게 소개드릴 예정이며, 논문의 디테일한 내용은 직접 논문을 읽어 보시는 것을 추천 드립니다.
1. Human uncertainty makes classification more robust
- Topic: Image Classification, Robustness
- CIFAR-10 데이터셋을 기반으로 사람의 label을 취득하여 얻은 CIFAR-10H soft label 데이터셋을 제작하였고, 이를 이용하여 학습을 시키면 모델의 일반화 성능이 좋아짐을 실험적으로 증명함.
- 논문의 내용을 요약하여 ppt로 제작하였습니다. 자세한 내용은 해당 ppt를 참고하시면 될 것 같습니다.
- 논문 리뷰 PPT
2. Exploring Randomly Wired Neural Networks for Image Recognition (Oral)
- Topic: Image Classification
- Neural Architecture Search(NAS)에서 human이 설정한 constraint에 의존하지 않고 모든 layer를 random하게 생성하는 Randomly Wired Neural Network 구조를 제안함.
- 3가지의 Random graph model (ER, BA, WS)를 이용하여 Random하게 wiring하는 network 구조를 생성하였고 우수한 성능을 보이는 것을 확인함.
- PR-12 이진원님 한글 리뷰 영상
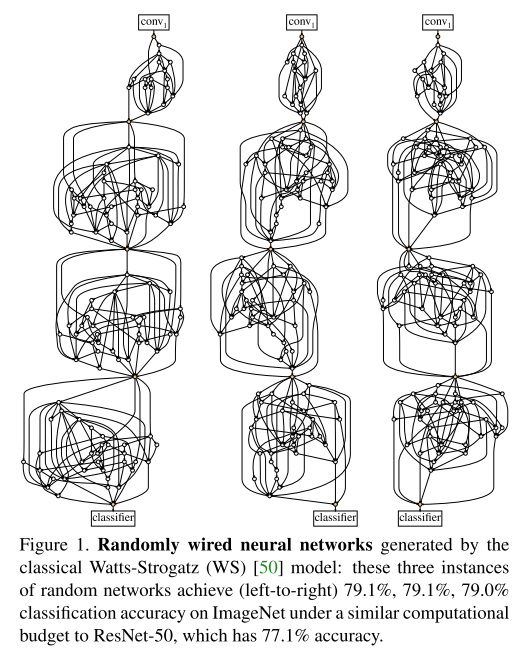
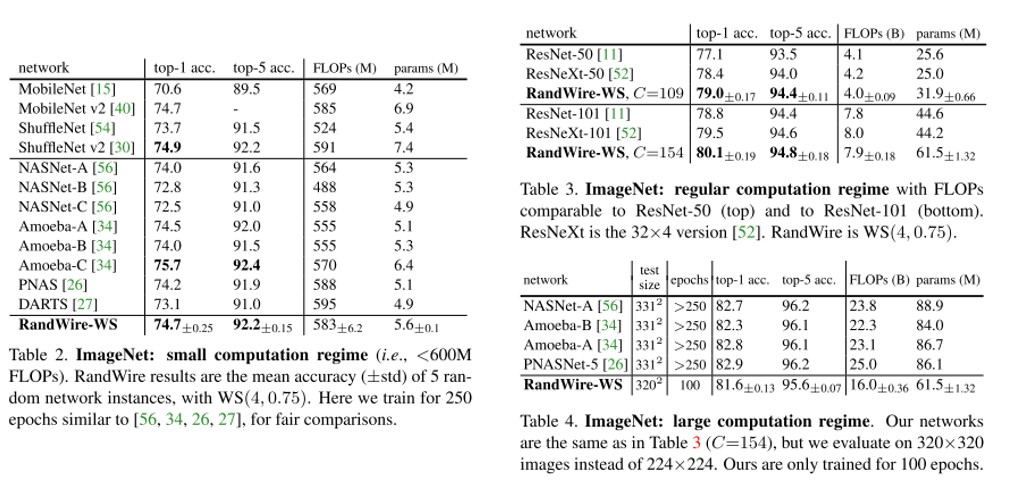
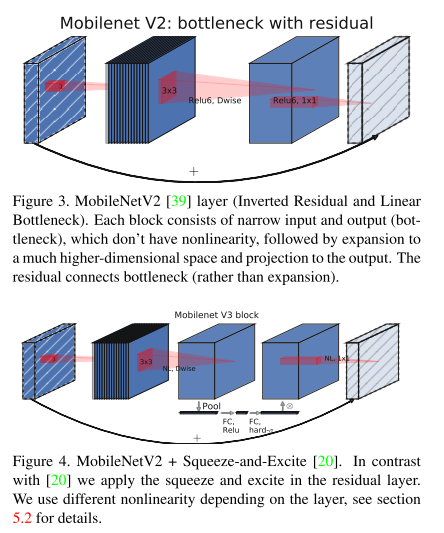
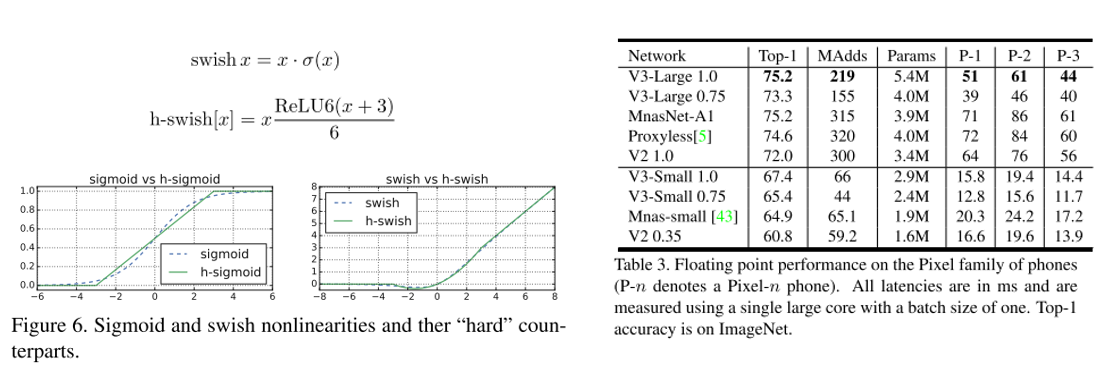
3. Searching for MobileNetV3 (Oral)
- Topic: Image Classification
- Efficient-Oriented CNN의 대표격인 MobileNet의 3번째 버전. MobileNet V2과 MnasNet 등에서 사용된 layer 들을 기반으로 한 구조를 제안하였고, swish nonlinearity를 fixed point 연산에 최적화시킨 hard-swish activation function을 제안함.
- 기존 방법들 대비 우수한 성능을 보였고, classification 외에 object detection, semantic segmentation에도 적용하면 좋은 성능을 보임. 또한 efficient segmentation을 위한 decoder 구조인 Lite Reduced Atrous Spatial Pyramid Pooling(LR-ASPP) 도 제안함.
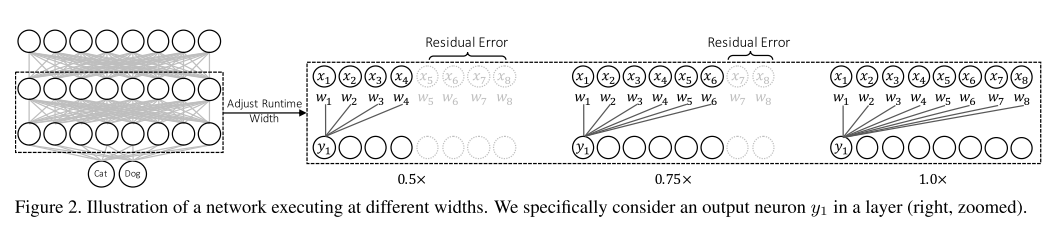
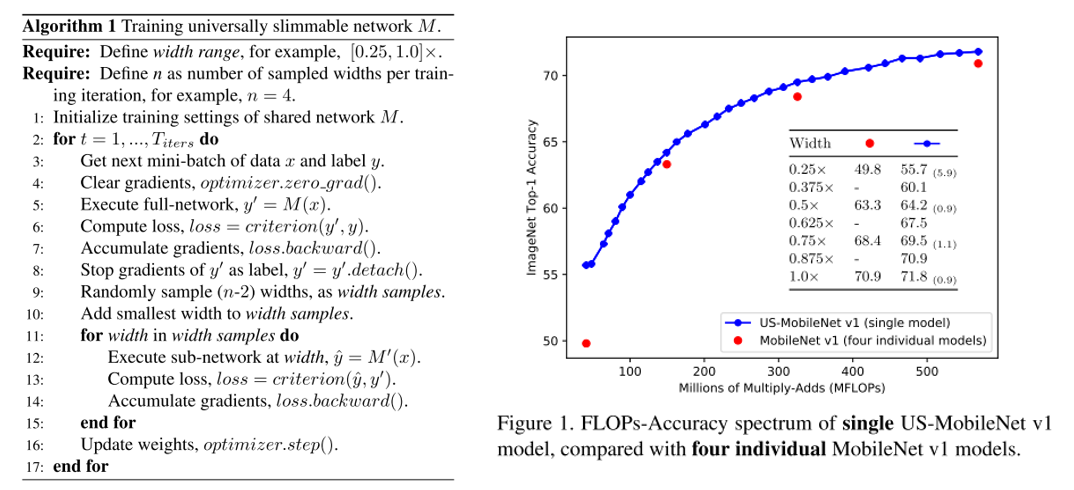
4. Universally Slimmable Networks and Improved Training Techniques
- Topic: Image Classification
- 지난 ICLR 2019 image recognition paper list guide 게시물 에서 다루었던 Slimmable neural network 논문의 후속 논문
- 기존 Slimmable network에서는 미리 지정한 width에 대해서만 동작할 수 있었는데 이러한 문제를 개선하여 임의의 width에서도 동작이 가능한 universally slimmable networks(US-Nets) 구조를 제안하였고, 이를 잘 학습시키기 위한 sandwich rule, inplace distillation 방식을 제안함.
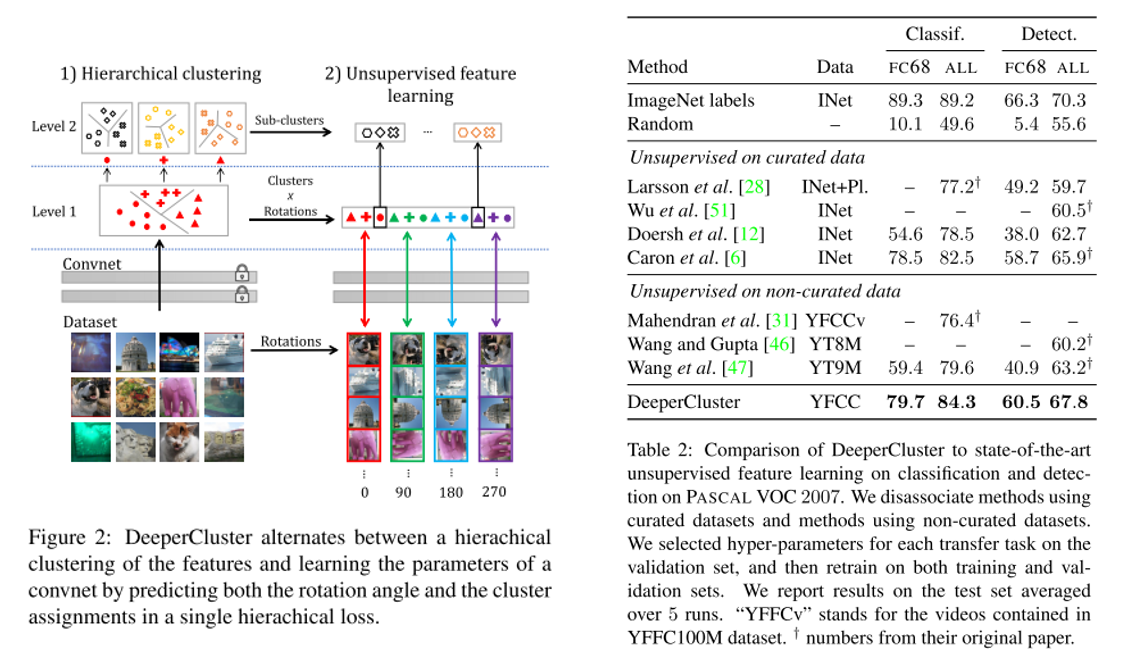
5. Unsupervised Pre-Training of Image Features on Non-Curated Data (Oral)
- Topic: Image Classification, Unsupervised learning
- Annotation이 존재하지 않는(Non-Curated Data) 대량의 데이터셋을 이용하여 ImageNet과같은curated data를 이용하여 pre-training을 하는 것과 비슷한 성능을 내기위한 unsupervised pre-training 기법을 제안함. Self-supervision, clustering이 주된 방법임.
6. Understanding Deep Networks via Extremal Perturbations and Smooth Masks (Oral)
- Topic: Image attribution
- 모델이 input의 어느 부분을 보고 output을 출력하는지 확인하는 문제를 attribution 문제라 하는데 널리 사용되는 back-propagation 방식 대신 perturbation 방식인 Extremal perturbation 을 제안함.
- mask의 넓이와 smoothness에 constraint를 가하는 방식을 이용하며 image 뿐만 아니라 네트워크의 intermediate layer에도 적용 가능함을 보임.

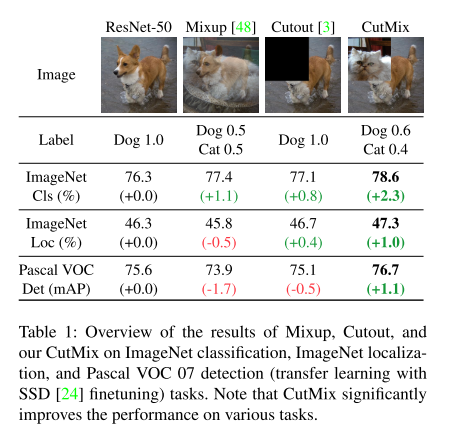
7. CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features (Oral)
- Topic: Image Classification, Data augmentation
- Region 기반 dropout 방식이 모델의 분류 성능을 높이는데 기여하는데 이 때 정보의 손실이 발생하는 단점이 있었음. 이를 개선하기 위해 Mixup 방식을 접목시킨 CutMix augmentation 기법을 제안함.
- Official Code (PyTorch)
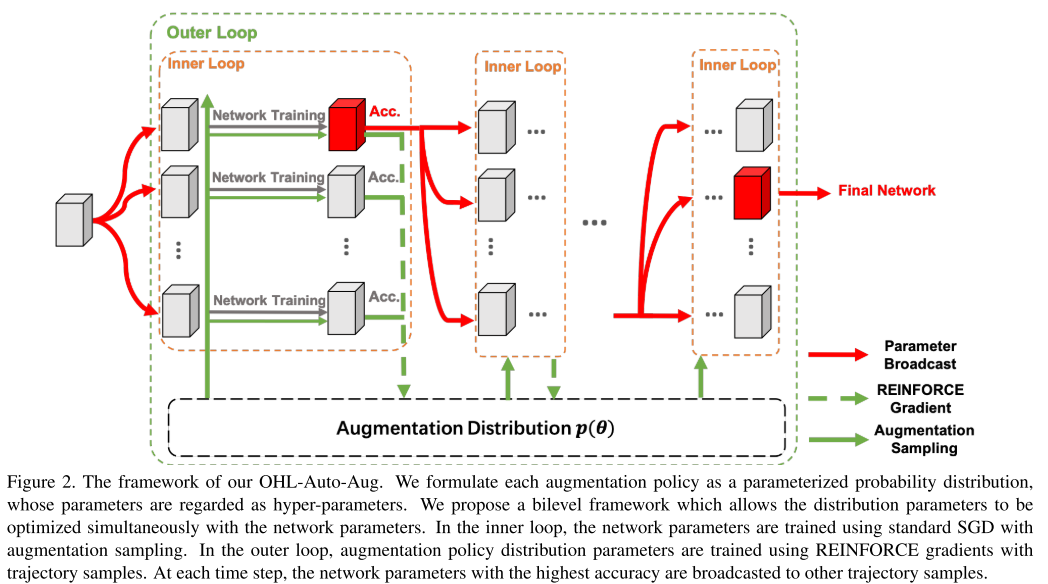
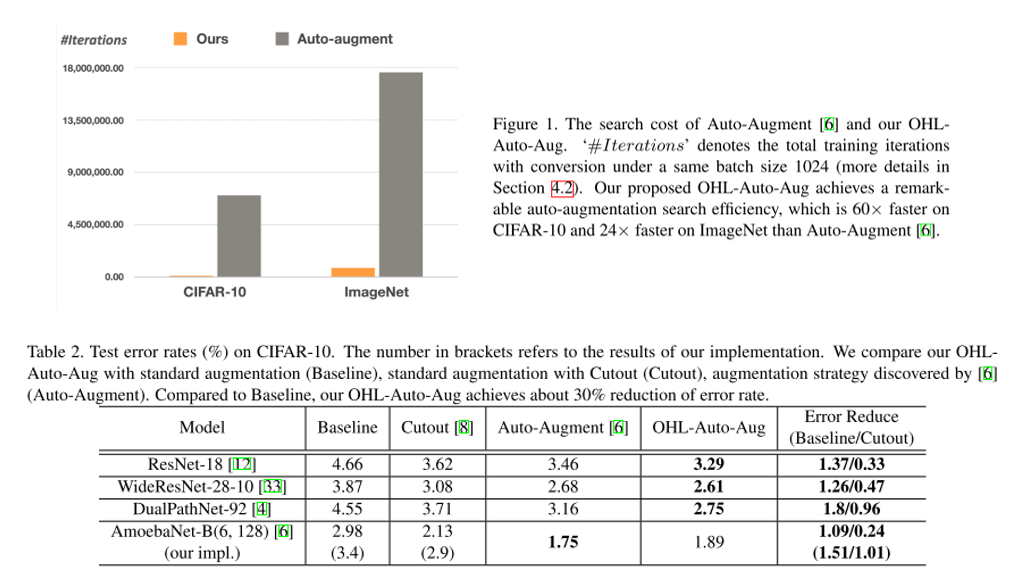
8. Online Hyper-Parameter Learning for Auto-Augmentation Strategy
- Topic: Image Classification, Data augmentation
- Data Auto augmentation을 위한 Online Hyper-parameter learning(OHL-Auto-Aug) 방식을 제안함.
- 기존 Auto augmentation 방식들은 offline 방식이라 search & 재학습을 반복해야 하는데 제안하는 방법은 online 방식으로 진행되고 결과적으로 search cost를 크게 감소시킬 수 있음.
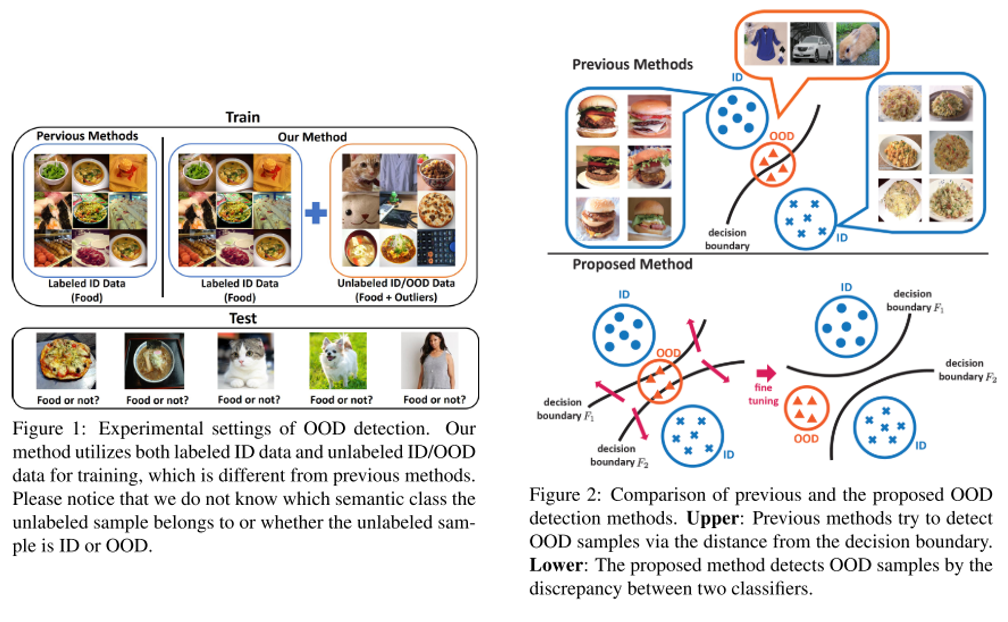
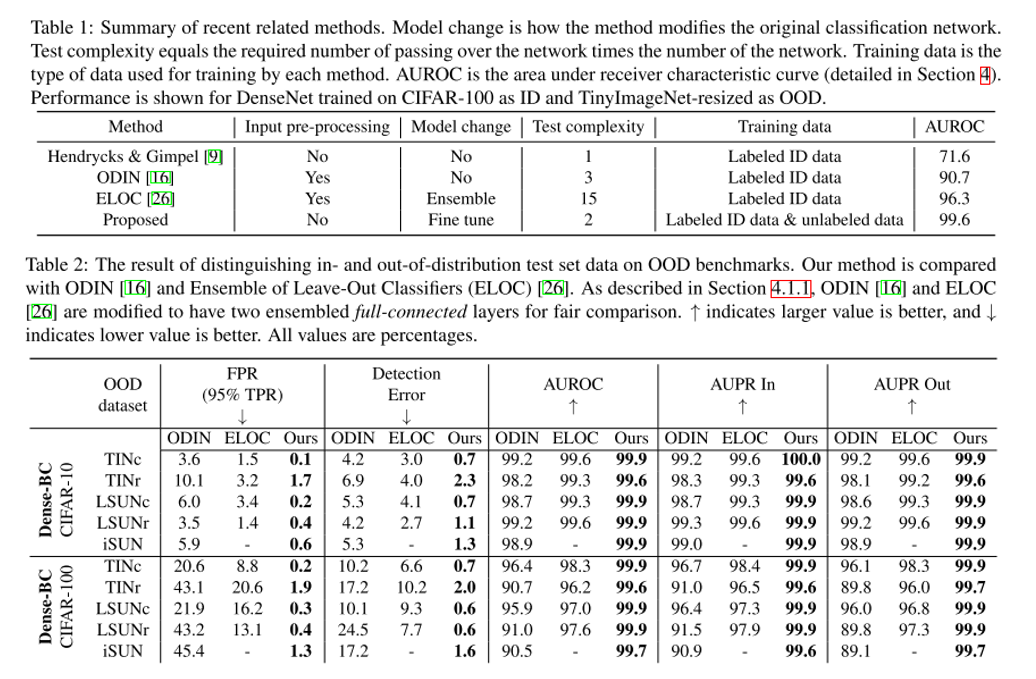
9. Unsupervised Out-of-Distribution Detection by Maximum Classifier Discrepancy
- Topic: Image Classification, Out-of-distribution detection, Anomaly detection
- 이미지 분류 문제에서 정해진 class 외에 아예 생뚱맞은 class의 이미지가 입력으로 들어왔을 때 이를 걸러내는 문제를 out-of-distribution detection 이라고 부름. 본 논문에서는 기존 방식들과는 다르게 unlabeled data를 활용하는 unsupervised setting을 따르며 기존 방식들 대비 우수한 성능을 보임.
- 하나의 feature extractor와 2개의 classifier로 구성이 되어있으며 각각 다른 decision boundary를 갖도록 하는 Discrepancy Loss 를 통해 unsupervised training을 수행함.
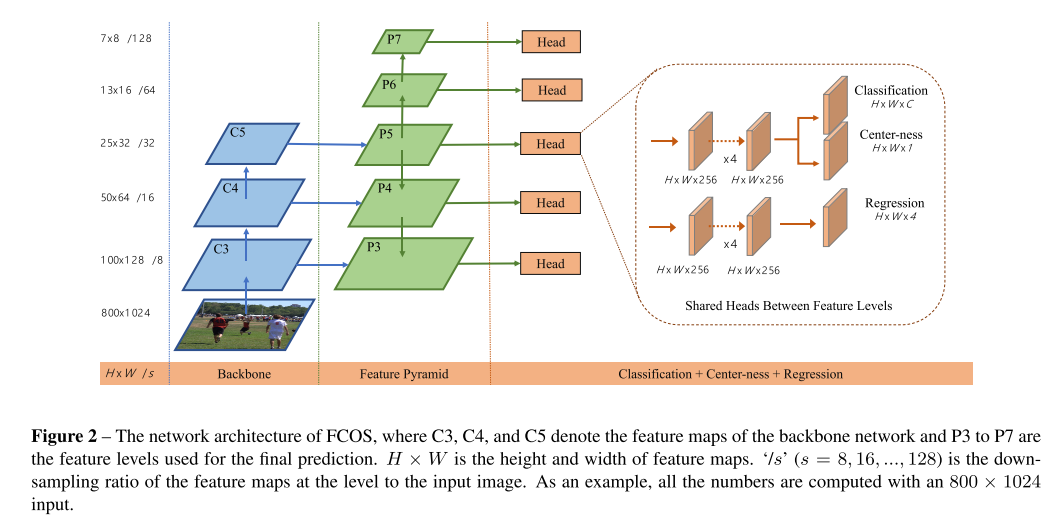
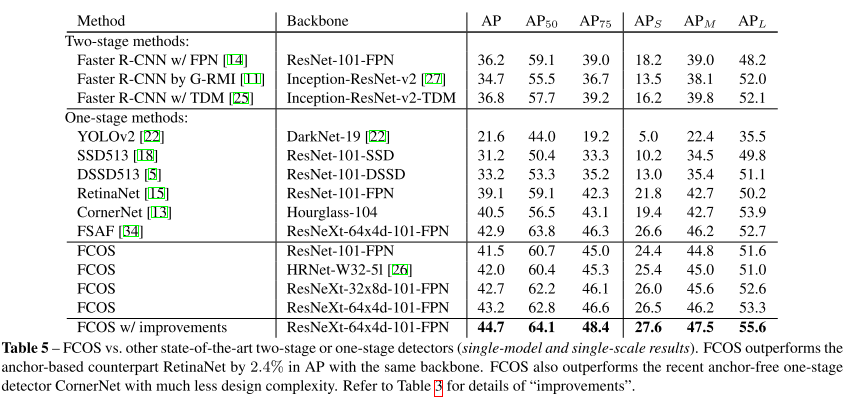
10. FCOS: Fully Convolutional One-Stage Object Detection
- Topic: Object Detection
- 기존 object detection에서 주로 사용되던 anchor box 기반 방식이나 proposal 기반 방식에서 벗어나 pixelwise로 prediction을 하는 Fully-Convolutional one-stage detector(FCOS)를 제안함.
- Anchor box를 사용하면서 생기는 여러 부작용들(training 계산량, hyper-parameter에 민감한 성능 등)을 해결할 수 있으며 기존 방법들 대비 좋은 성능을 보임.
- Official Code (PyTorch)
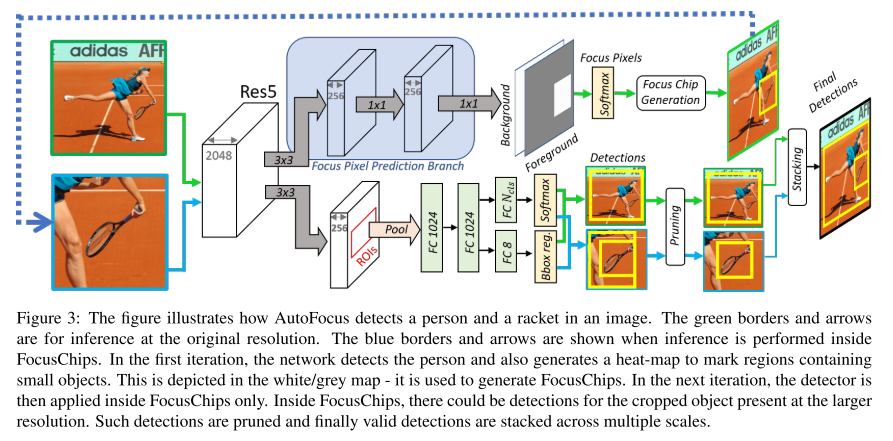
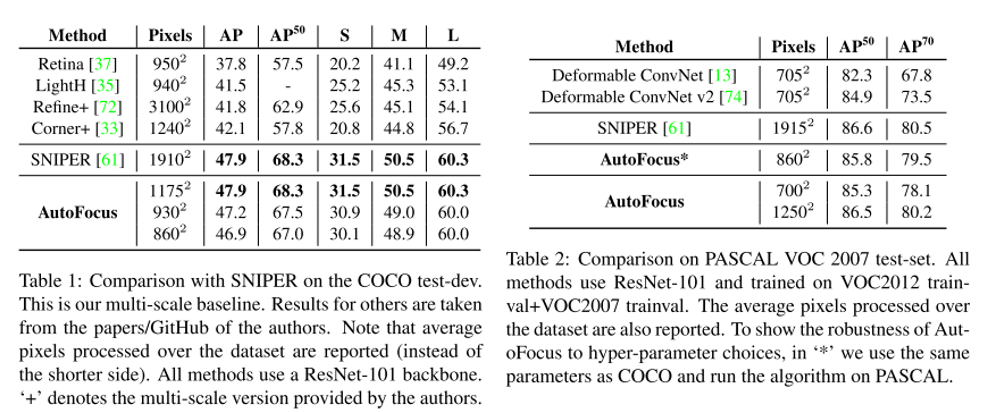
11. AutoFocus: Efficient Multi-Scale Inference
- Topic: Object Detection
- 지난 NeurIPS 2018 image recognition paper guide 게시물 에서 다루었던 SNIPER 논문의 inference 과정에서 발생하는 문제를 개선하기 위한 방법론을 제안함.
- Small object가 존재할 법한 위치를 추출한 결과물인 FocusPixels과 이를 둘러싼 FocusChips를 생성하고 FocusChips에 대해 한 번 더 detect를 수행하여 검출 성능을 높이는 Multi-scale inference 방법을 제안함.
- SNIPER보다 빠른 처리 속도로 비슷한 성능을 낼 수 있는 것이 장점.
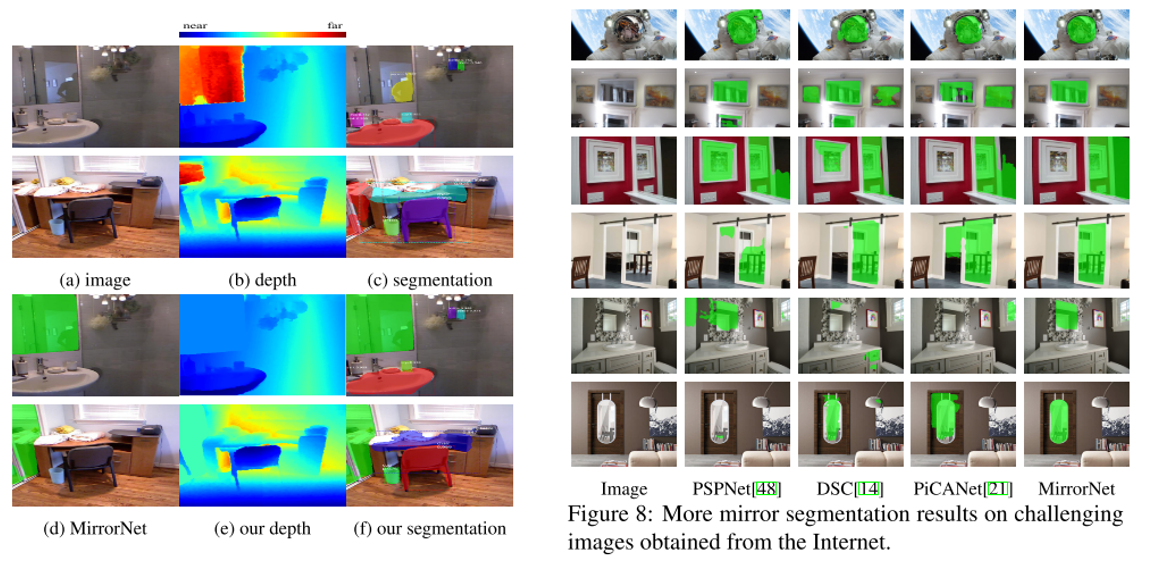
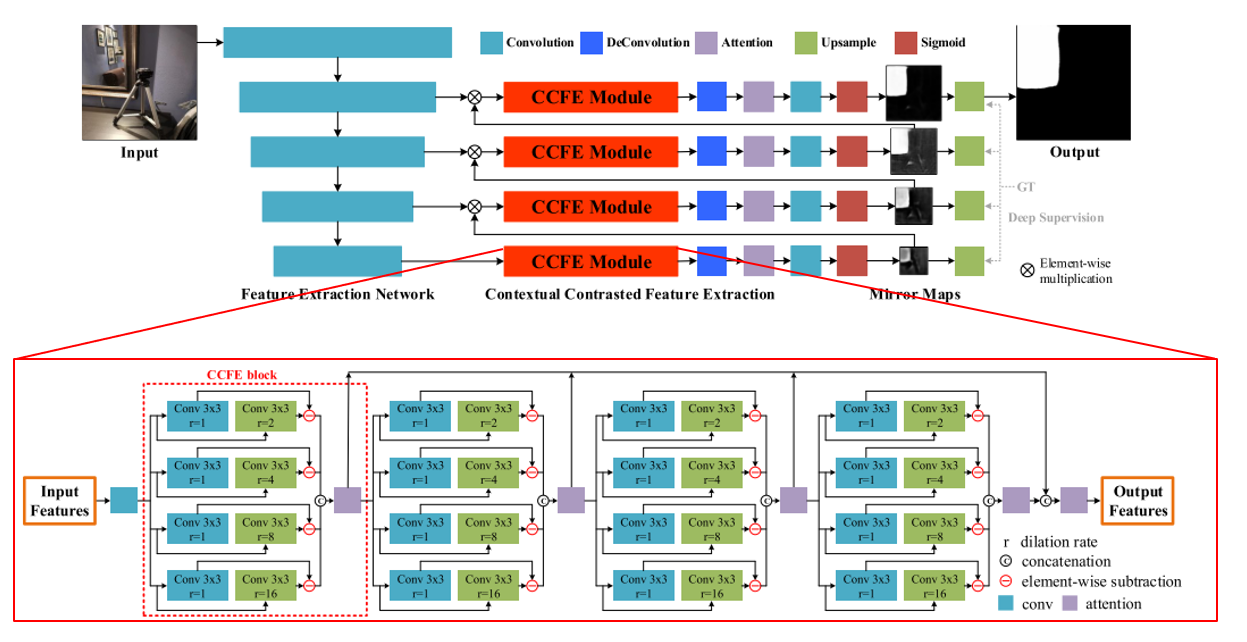
12. Where Is My Mirror?
- Topic: Semantic Segmentation
- 그동안 대부분 Computer Vision 문제에서 거울은 잘 다루지 않아 왔음. 하지만 거울은 일상생활에서 자주 볼 수 있는 물건이며 보이는 것을 반사한다는 특징이 있음.
- 본 논문에서는 이미지로부터 거울 영역을 segmentation하기 위한 데이터셋을 제작하고 MirrorNet 이라는 네트워크 구조를 제안함.
- 최초의 mirror dataset인 MSD는 4,018장의 이미지와 mask로 구성이 되어있음. 참신한 문제 상황이 흥미로운 논문임.
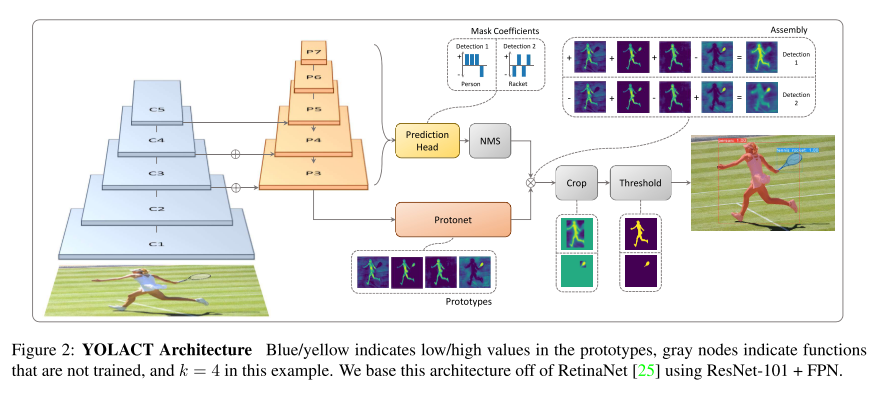
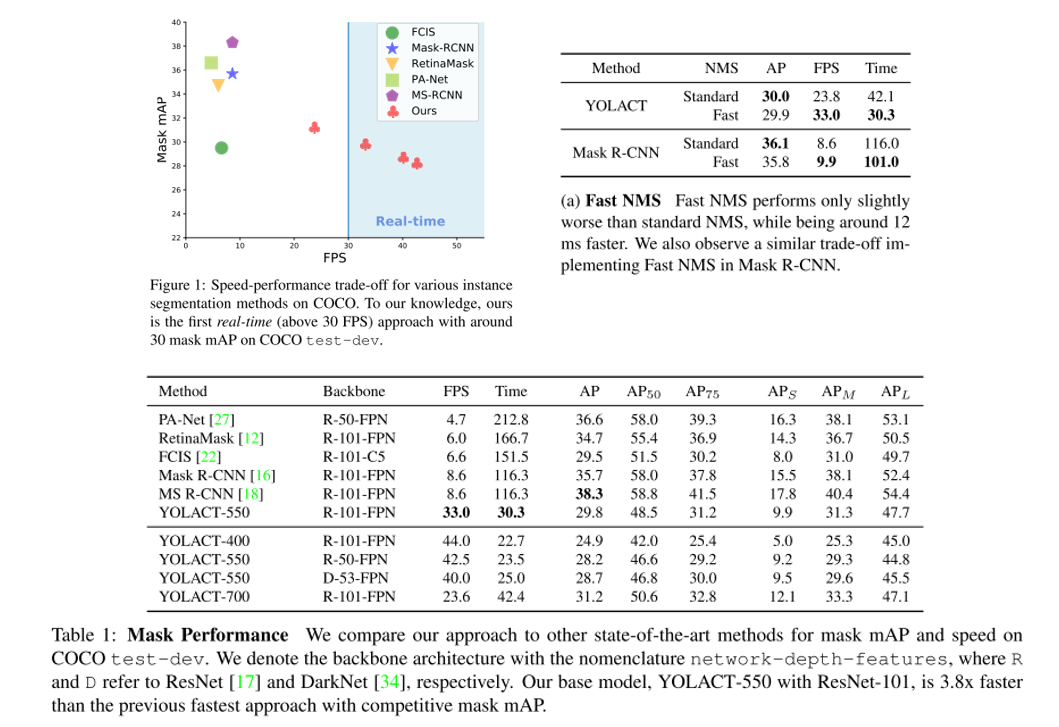
13. YOLACT: Real-Time Instance Segmentation (Oral)
- Topic: Instance Segmentation
- 실시간 instance segmenation을 위한 YOLACT 라는 방법론을 제안함. YOLO 논문과 유사하게 기존 방법들 대비 정확도는 떨어지지만 single GPU로 실시간(30fps 이상) 동작하는 것을 main contribution으로 삼고 있음.
- 약간의 정확도 손실이 발생하는 대신 처리 속도를 늘릴 수 있는 FastNMS 방식도 제안함.
- Official Code (PyTorch)
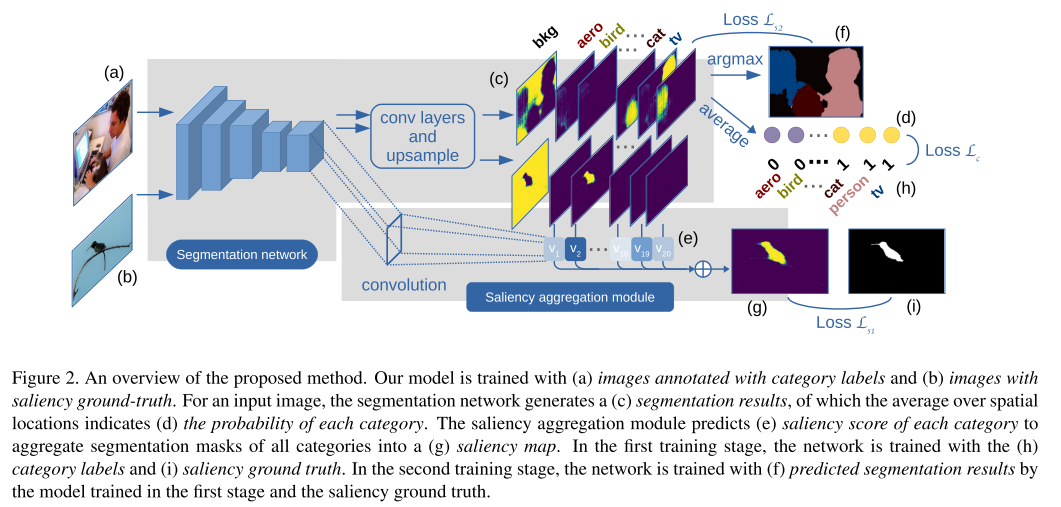
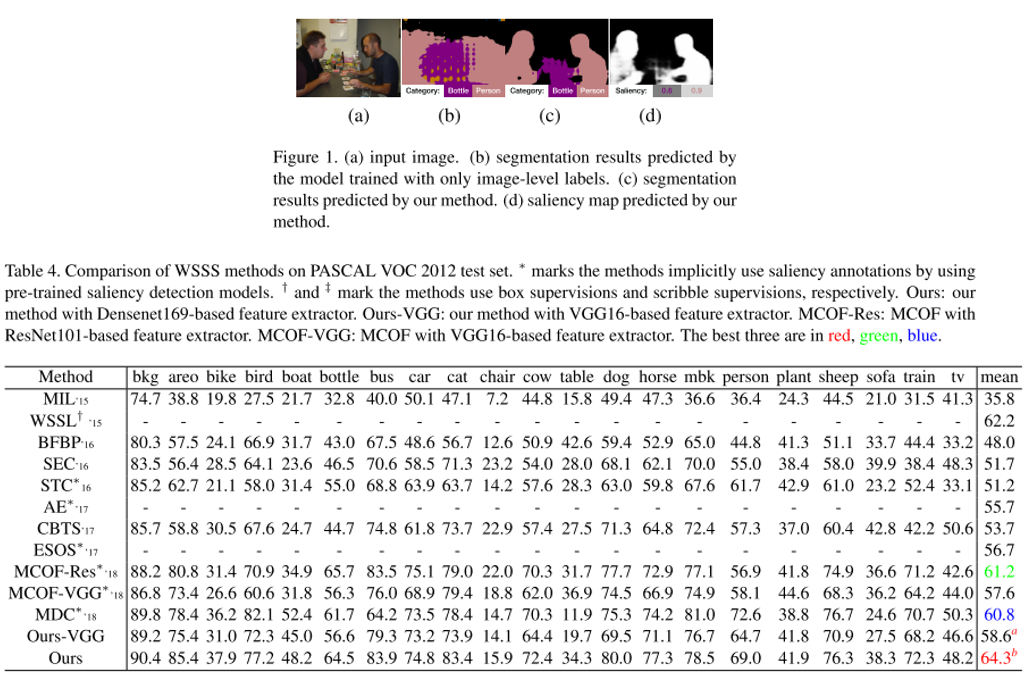
14. Joint Learning of Saliency Detection and Weakly Supervised Semantic Segmentation
- Topic: Semantic Segmentation
- 기존 Weakly Supervised Semantic Segmentation(WSSS) 연구들은 대체로 학습된 Saliency Detection(SD)의 결과물을 이용하는 방식을 사용 해왔음.
- WSSS와 SD를 하나의 network(SS-Net)를 이용하여 동시에 학습시키는 multi-task learning 방식을 제안함.
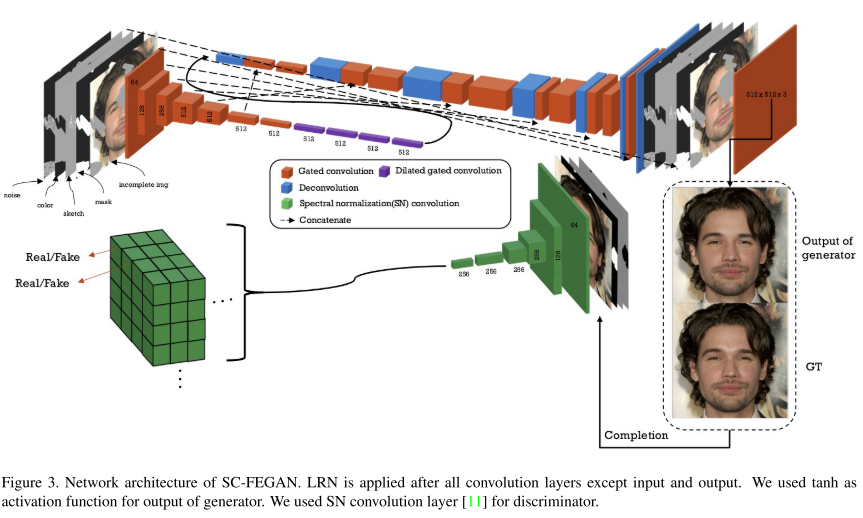
15. SC-FEGAN: Face Editing Generative Adversarial Network With User’s Sketch and Color
- Topic: Generative Model
- 데모 이미지에서 알 수 있듯이 원하는 영역에 스케치를 그려주면 스케치와 주변 context를 보고 그럴싸한 이미지를 그려주는 GAN 구조를 제안함.
- 컬러 이미지, 수정하고자 하는 영역의 mask, HED edge detector를 이용하여 얻은 sketch 등을 이용하며, PartialConv based padding 과 per-pixel loss, perceptual loss, style loss, total variance loss 등을 이용하여 안정적인 학습을 수행함.
- Official Code (TensorFlow)

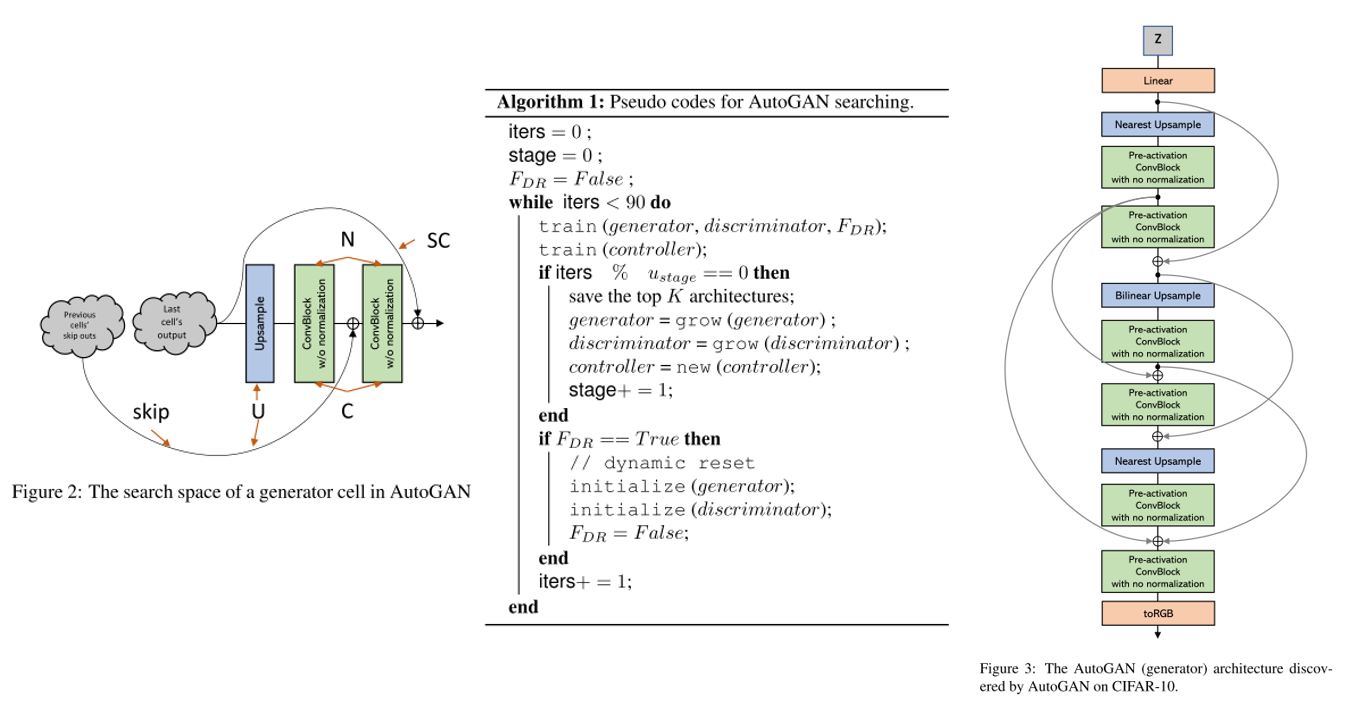
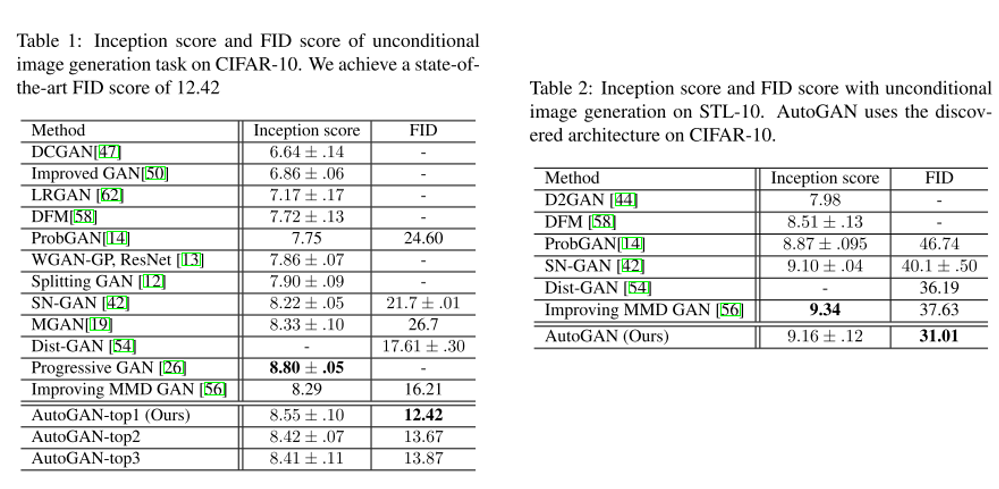
16. AutoGAN: Neural Architecture Search for Generative Adversarial Networks
- Topic: Generative Model, AutoML
- AutoML의 Neural Architecture Search를 GAN에 적용하는 방법론을 제안함.
- Inception score를 reward로 사용하였고 Multi-level architecture search(MLAS)를 적용하여 단계적으로 NAS를 수행함.
- Official Code (PyTorch)
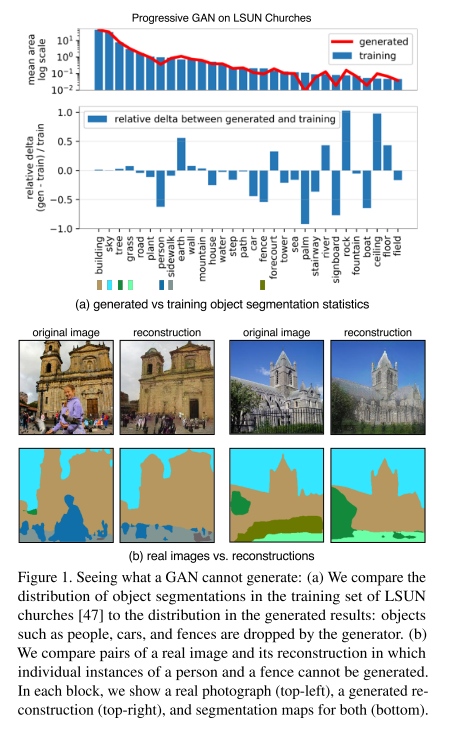
17. Seeing What a GAN Cannot Generate (Oral)
- Topic: Generative Model
- GAN의 고질적인 문제인 mode collapse를 분석하기 위해 distribution level 과 instance level에서 mode collapse를 시각화하는 방법을 제안함. 즉 GAN generator가 생성하지 못하는 것이 무엇인지를 파악하는 것을 목표로 함.
- Target image와 generated image의 object들의 distribution을 확인하기 위해 semantic segmentation network를 사용하여 Generated Image Segmentation Statistics 지표를 측정하고, 이를 토대로 GAN을 분석함. (distribution level)
- 또한 이미지 단위로 특정 클래스가 누락된 GAN으로 생성한 이미지와 실제 이미지를 비교하며 실패 case를 분석하는 instance level의 분석도 수행함.
18. Everybody Dance Now
- Topic: Generative Model,
- Video로부터 Pose를 얻고 이를 통해 다시 Video를 생성하는 과정에서 원본 동영상의 춤 Style을 Transfer 하는 것을 GAN을 통해 수행함.
- 또한 얼굴 합성의 퀄리티를 높이기 위해 별도의 FaceGAN 구조도 사용하여 전반적인 생성된 영상의 품질을 높임.
- Demo Video

19. SROBB: Targeted Perceptual Loss for Single Image Super-Resolution
- Topic: Single Image Super-Resolution
- 17번 논문과 유사하게 segmentation 정보를 사용하는 것이 특징이며 segmentation label로부터 Object, Background, Boundary(OBB) label을 얻은 뒤 이를 이용하여 perceptual loss를 효과적으로 주는 방법을 제안함.
- 실제로 사람이 민감하게 열화를 느끼는 edge 부분에 loss를 반영하는 점이 인상깊으며 실제 Super-Resolution을 통해 얻은 이미지의 퀄리티도 우수한 것을 확인할 수 있음.
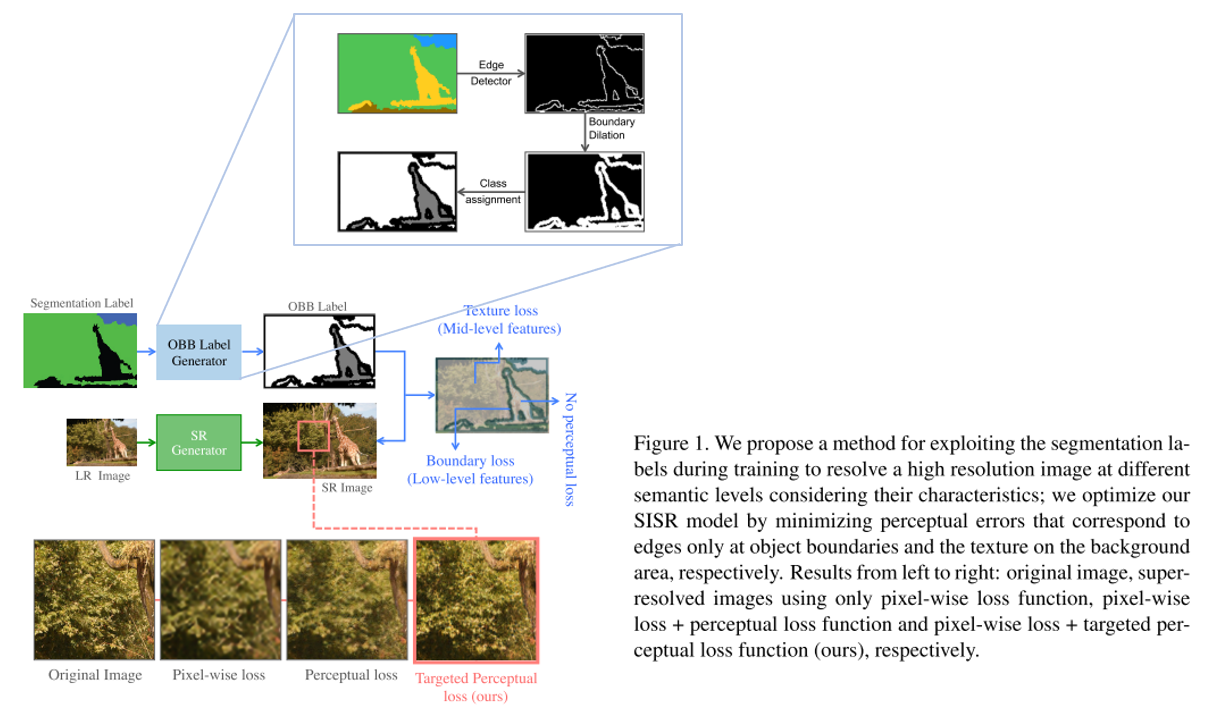
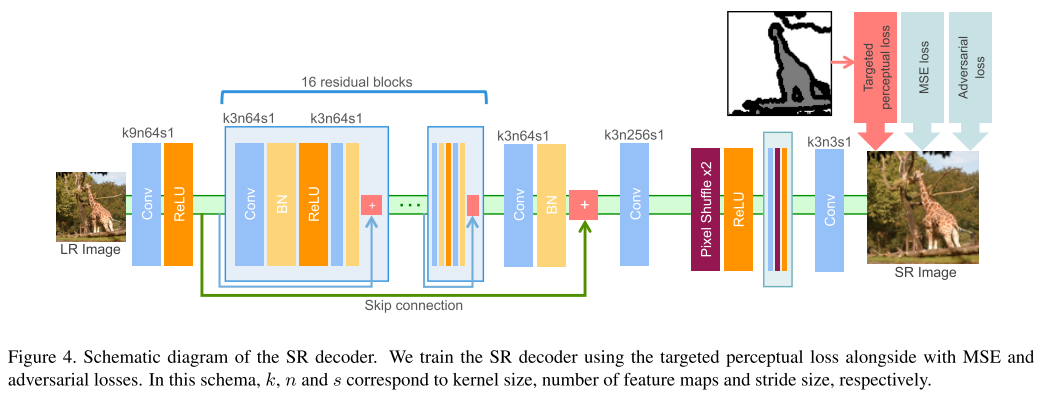
20. Toward Real-World Single Image Super-Resolution: A New Benchmark and a New Model (Oral)
- Topic: Single Image Super-Resolution
- 현존하는 대부분의 Single Image Super-Resolution 논문들은 “Single Image Super Resolution using Deep Learning Overview” 게시물 에서 제기했던 문제점처럼 simulated datasets에 대해 학습이 되고 있음.
- 하지만 실제 LR image의 degradations은 단순한 bicubic downsampling 등의 방식보다 훨씬 복잡한 특징을 가지고 있음. 이러한 문제점을 해결하기 위해 디지털 카메라의 focal length를 조절하며 같은 scene에서 LR-HR pair image를 취득하여 얻은 RealSR 데이터셋을 제작하고, 새로운 모델인 Laplacian pyramid based kernel prediction network (LP-KPN) 을 제안함.
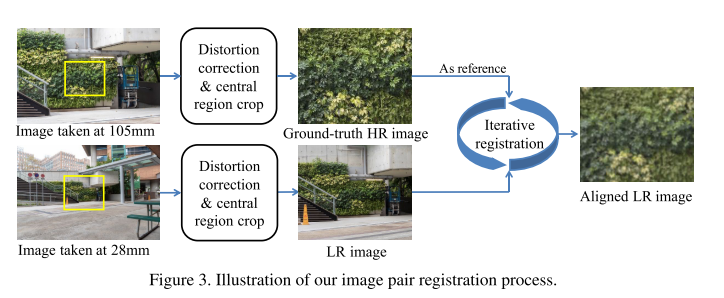
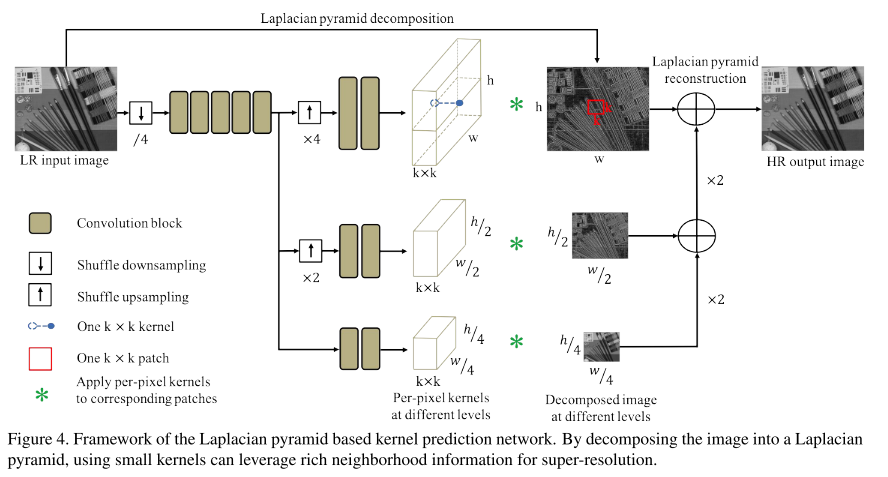
21. Evaluating Robustness of Deep Image Super-Resolution Against Adversarial Attacks
- Topic: Single Image Super-Resolution, Adversarial attack
- 딥러닝 기반 Single image Super-Resolution의 adversarial attack에 대한 Robustness를 분석한 논문. LR image에 약간의 perturbation을 넣어주며 attack을 시도하는 방법을 사용함.
- 3가지 attack method를 제안하였고, state-of-the-art deep super-resolution model들이 adversarial attack에 취약함을 가지고 있음을 입증하고 여러 방법들의 robustness를 이론적, 실험적으로 분석함.

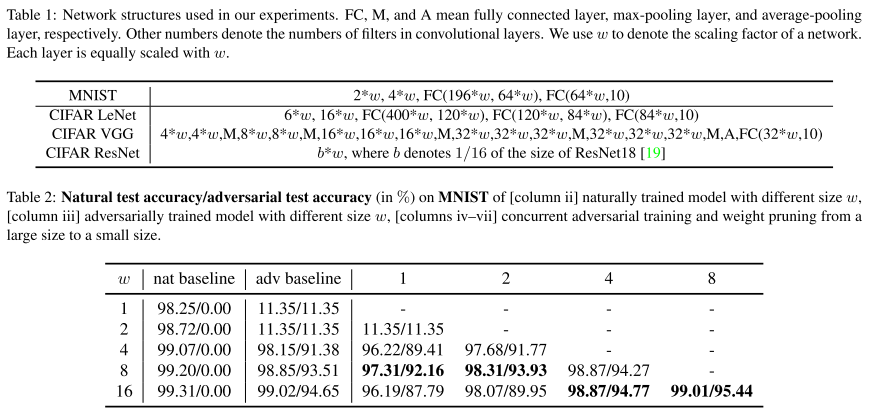
22. Adversarial Robustness vs. Model Compression, or Both?
- Topic: Adversarial attack, Model Compression, Network Pruning
- Deep neural network가 adversarial attack에 취약한 건 잘 알려진 사실이며, Min-max robust optimization 기반 adversarial training을 이용하면 adversarial robustness를 높일 수 있음. 하지만 큰 capacity를 갖는 network를 필요로 함.
- 본 논문에서는 adversarial robustness를 유지하며 모델을 경량화하는 concurrent adversarial training & weight pruning 기법을 제안함.
결론
이번 포스팅에서는 ICCV 2019에 대한 분석 및 주요 논문 22편에 대한 간단한 리뷰를 글로 작성해보았습니다.
제가 정리한 논문 외에도 이번 ICCV 2019에는 양질의 논문들이 많이 제출되었으니 관심있으신 분들은 다른 논문들도 읽어 보시는 것을 권장 드리며 이상으로 글을 마치겠습니다. 감사합니다!