Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning 리뷰
안녕하세요, 지난 Self-Supervised Learning Overview 글 에서 Self-Supervised Learning 의 전반적인 내용들을 다뤘었는데요, 오늘 글에서는 2020년 6월 초 공개된 “Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning” 논문을 소개드릴 예정입니다.
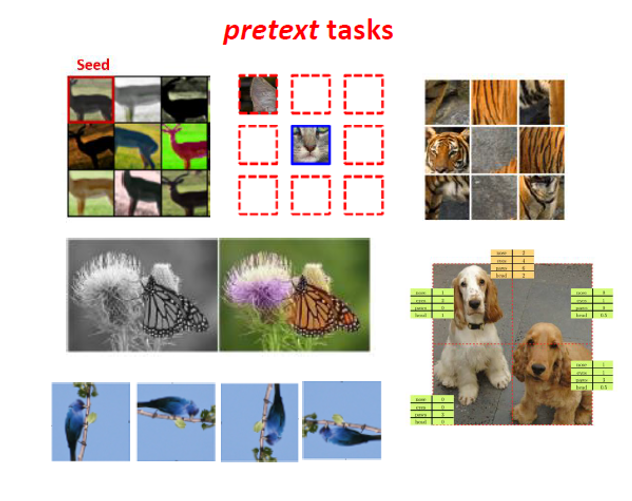
최근 5년간 주옥같은 Self-Supervised Learning 논문들이 쏟아져 나왔고, scratch로부터 학습시킨 (random init) 모델보다는 더 나은 성능을 보였지만 Supervised Learning으로 학습시킨 Feature Extractor보다는 성능이 많이 뒤쳐졌었습니다. 하지만 최근들어 Supervised Learning과 Self-Supervised Learning 사이의 격차가 많이 줄어드는 연구 성과들이 있었습니다. 이 방법론들은 Contrastive Learning 기반의 방식을 사용하여 기존 방식들보다 월등한 성능을 달성하며 큰 주목을 받게 됩니다. 실제로 논문에서도 다음과 같이 설명하고 있습니다.

Contrastive Learning 기반의 Self-Supervised Learning 방법이 제안된 이후, Image Classification 분야에서는 대부분 Contrastive 접근을 하기 시작하였습니다. 오늘 다루는 Bootstrap Your Own Latent 방법론을 설명드리기 전에 2020년의 주요 Contrastive Learning 기반의 Self-Supervised Learning 알고리즘들을 정말 간략히 소개드리고 시작하겠습니다.
Self-Supervised Learning in 2020
Momentum Contrast for Unsupervised Visual Representation Learning.(MoCo) 2019.11
우선 “Momentum Contrast for Unsupervised Visual Representation Learning” 이라는 논문이 2019년 11월쯤 Facebook AI Research에서 공개가 되었습니다.
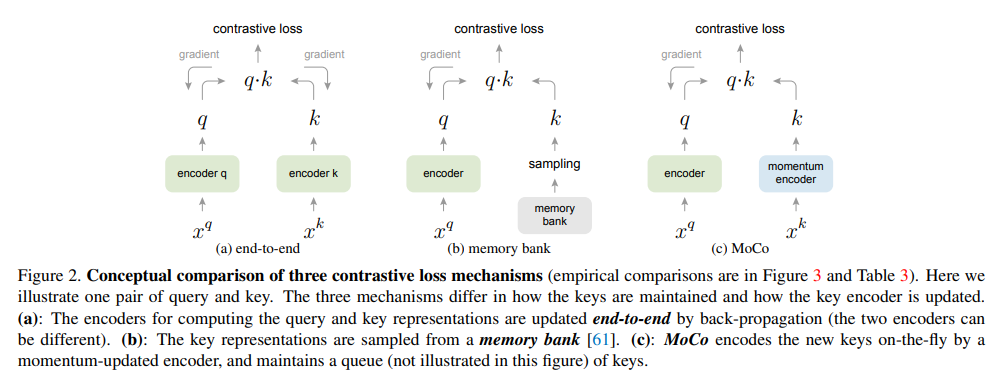
Contrastive Learning 기법을 Unsupervised Visual Representation Learning (Self-Supervised Learning)에 적용시키려는 시도는 전에도 존재했었는데, Contrastive Learning을 간단히 설명드리면, Contrastive Learning 기반 방법론들은 같은 image에 서로 다른 augmentation을 가한 뒤, 두 positive pair의 feature representation은 거리가 가까워 지도록(유사해지도록) 학습을 하고, 다른 image에 서로 다른 augmentation을 가한 뒤, 두 negative pair의 feature representation은 거리가 멀어지도록 학습을 시키는 게 핵심입니다. 하지만 학습이 불안정한 이슈가 있어서, 이를 극복하기 위해 Momentum을 적용하여 성능을 끌어올린 논문입니다.
A Simple Framework for Contrastive Learning of Visual Representations (SimCLR), 2020.1
그 뒤, Google Research와 Brain Team에서 많은 분들이 들어보셨을 “A Simple Framework for Contrastive Learning of Visual Representations” 이라는 논문을 올해 초 공개하였습니다. MoCo에서 큰 폭의 성능 향상이 있었는데, 불과 2달만에 역시나 큰 폭의 성능 향상을 보이며, Self-Supervised Learning의 무궁무진한 가능성을 보여주었습니다.
마찬가지로 Contrastive Learning 기반이며, 특정한 architecture나 memory bank 없이 학습을 시킬 수 있는 아이디어를 제안합니다. 적절한 data augmentation 들을 사용하고, learnable nonlinear transformation와, contrastive loss를 제안하는 등 다양한 아이디어를 보여주고 있습니다.

SimCLR 논문은 저희 PR-12 스터디의 이진원님께서 잘 설명해주신 영상이 있어서 이 영상을 참고하시면 좋을 것 같습니다.
Improved Baselines with Momentum Contrastive Learning.(MoCo v2) 2020.3
MoCo의 짧았던 전성기가 아쉬웠는지, SimCLR이 공개된 지 똑같이 두달 뒤 FAIR에서 MoCo의 2번째 버전인 “Improved Baselines with Momentum Contrastive Learning” 을 공개합니다. 다만 분량이 길진 않고 딱 2페이지 짜리 technical report고, SimCLR의 design choice들을 고려하여 MoCo에 적용하여 성능을 올린 project 입니다. PyTorch Official Code도 공개를 하였습니다.
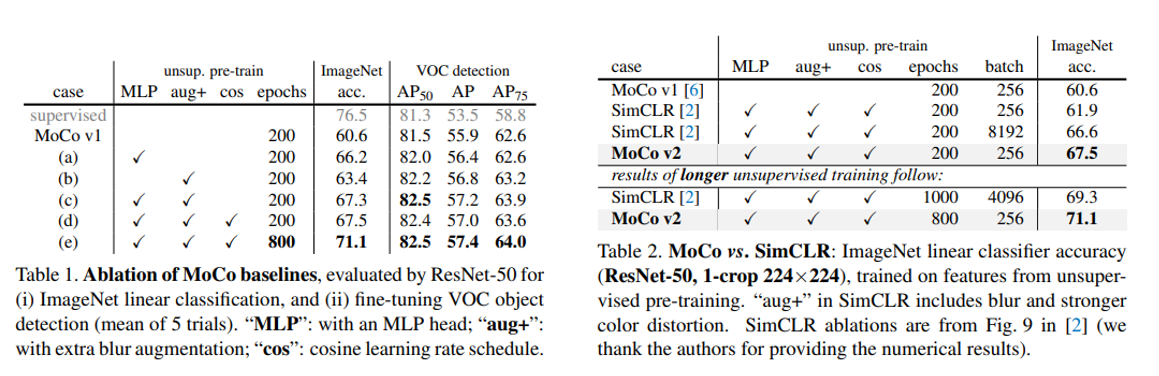
MoCo v1에 비해 v2에서 성능이 많이 향상되었고, 무엇보다 SimCLR의 핵심이었던 무지막지한 batch size(8192)가 아닌 256 batch size에서도 더 좋은 성능을 달성한 점이 가장 큰 장점이라 생각합니다. 자세한 기법이 궁금하신 분들은 위의 technical paper와 코드를 참고하시면 좋을 것 같습니다.
Big Self-Supervised Models are Strong Semi-Supervised Learners.(SimCLR v2) 2020.6
ㅋㅋㅋ.. 이 글을 작성하기 시작한 시점이 6월 18일이었는데, 바로 하루 전날 SimCLR의 2번째 버전이 arxiv에 공개가 되었습니다. 하하하……
“Big Self-Supervised Models are Strong Semi-Supervised Learners” 라는 제목의 논문이고, 제목에서 알 수 있듯이 Semi-Supervised Learning에 초점을 두고 연구를 수행하였습니다. Parameter 수가 큰 모델일 수록, 적은 수의 labeled example만 존재할 때 SimCLR을 사용하면 성능 향상이 크다는 것을 보였고, 이 말은 곧 큰 model이 visual representation learning을 할 때 유리함을 시사하고 있습니다. 다만, 구체적인 downstream task가 정해진 경우에는 너무 큰 model 까지 갈 필요가 없음을 보여주고 있습니다.
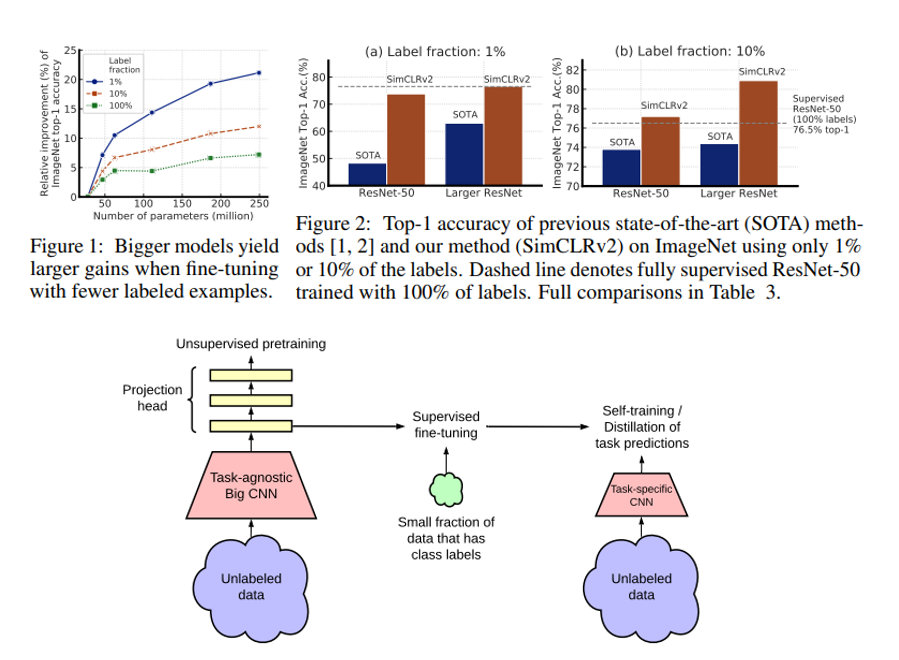
제가 PR-12에서 소개드렸던 “PR-237: FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence” 논문이 Semi-Supervised Learning에서 좋은 성능을 보였었는데, SimCLR v2가 Label Fraction 10%인 상황에서 같은 ResNet-50에서는 Top-1 Accuracy가 6% 포인트 올랐고, 더 큰 모델을 사용하면 Top-1 Accuracy가 9% 포인트 오르는 어마어마한 성능을 자랑합니다. Google Research의 연구 발전 속도는 참 경이롭네요.
FAIR의 MoCo가 PyTorch 코드를 공개한 것처럼, Google의 SimCLR도 TensorFlow 코드를 공개하였으니, 관심있으신 분들은 참고하시면 좋을 것 같습니다.
Bootstrap Your Own Latent 방법론 소개
자, 이제 오늘 소개드릴 Bootstrap Your Own Latent(이하 BYOL) 방법론을 소개드리겠습니다. 앞서 설명드렸던 Contrastive Learning 기반 방법론들은 negative pair를 잘 선택 해줘야하고 이를 위해 customized mining 전략 등이 제안 되었습니다. 또한 굉장히 큰 batch size에서 학습을 시켜야하고, 학습에 사용한 image augmentation option에도 성능 편차가 큰 등 아직까지 안정적으로 학습시키기엔 고려해야할 요소가 많은 점이 문제였습니다. 본 논문에서는 negative pair를 사용하지 않고, 기존 Contrastive Learning 방식들보다 우수한 성능을 달성하였는데요, 어떤 방법을 사용했는지 설명드리도록 하겠습니다.
- 간단한 실험을 통해 얻어낸 Insight
우선 저자들은 negative pair를 사용하지 않고 image들로 부터 양질의 representation을 배우기 위해 image를 2개 이용하는 방식 대신, network를 2개 이용하는 방식을 떠올립니다.
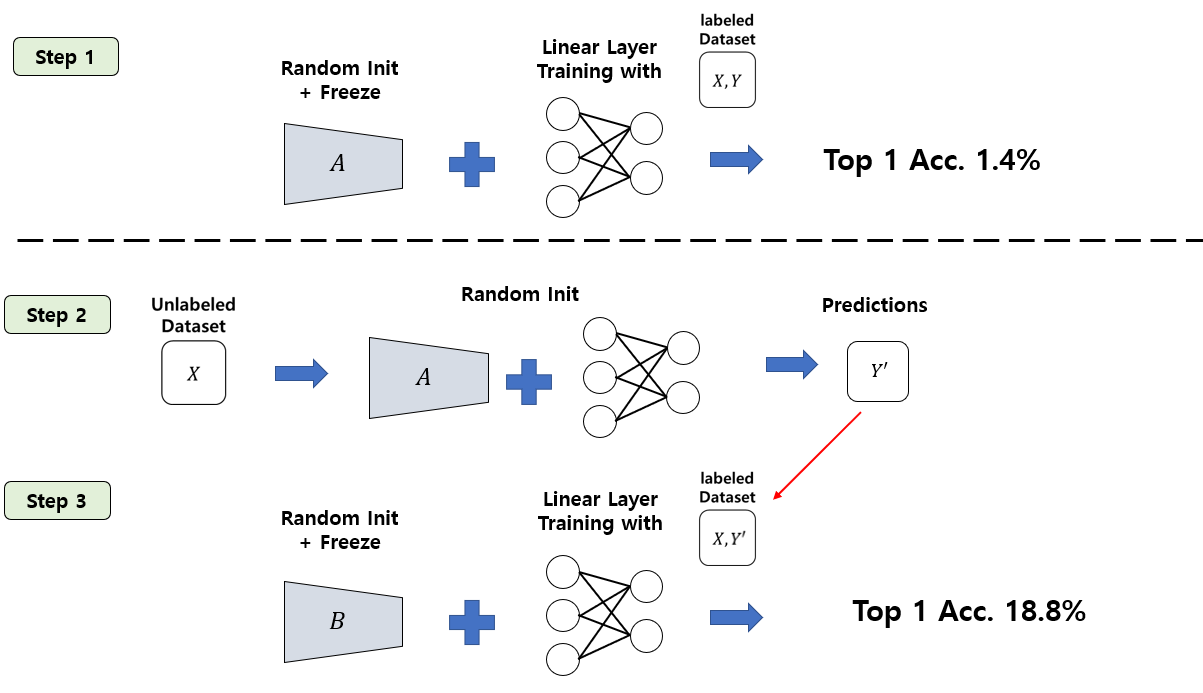
우선 간단한 실험을 하나 진행합니다. Step 1으로 A 라는 network를 random initialization 시킨 뒤 weight를 고정시킵니다. 여기에 Self-Supervised Learning의 evaluation protocol인 linear evaluation protocol을 통해 ImageNet 데이터셋에 대한 정확도를 측정합니다. 즉, random init 후 freeze 시킨 feature extractor에 1개의 linear layer를 붙여서 ImageNet 데이터셋로 학습시킨 뒤 정확도를 측정하는 것입니다. 이 경우, feature extractor가 아무런 정보도 배우지 않은 채 linear layer만 붙였기 때문에 좋은 성능을 얻을 수 없고, 실제로 1.4%의 top-1 accuracy를 달성하였다고 합니다.
Step 2로 unlabeled dataset을 random initialized A network + MLP (뒤에서 자세히 설명드릴 예정)에 feed forward 시켜서 prediction들을 얻어냅니다.
Step3에선 B 라는 network를 하나 준비합니다. B도 마찬가지로 random initialization 시키는데, 바로 linear evaluation을 수행하지 않고, image들을 A network에 feed forward 시켜서 뽑아낸 prediction을 target으로 하여 이 target을 배우도록 학습을 시킵니다. 비유를 하자면, A라는 학생은 모의고사를 볼 때 아무런 답이나 내뱉는 학생인데, 시험을 보기 전 약간의 벼락치기(linear layer training)를 합니다. 그 결과 1.4점의 시험 결과를 얻습니다. B라는 학생은 A 학생이 벼락치기를 하기 전(random initialized A) 답을 적어둔 연습 문제들을 받아서 이 답안들을 배우도록 학습을 한 뒤, 벼락치기를 합니다. 어떻게 보면 A 학생보다 공부 량은 좀 더 많겠죠?
놀랍게도, B network는 random initialized A network가 내뱉은 부정확한 prediction들을 배우도록 학습을 한 뒤 linear evaluation을 하였을 때 18.8%의 top-1 accuracy를 얻을 수 있었다고 합니다. 물론 이 수치는 매우 낮은 수치입니다. 하지만 random initialization을 하였을 때 보다는 굉장히 큰 폭으로 성능이 증가한 셈이죠. 이 간단한 실험이 BYOL의 core motivation이 되었다고 저자들은 서술하고 있습니다.
- BYOL’s architecture
위에서 방금 서술한 방식에서 아이디어를 얻어서 저자들은 다음과 같은 구조를 제안합니다.
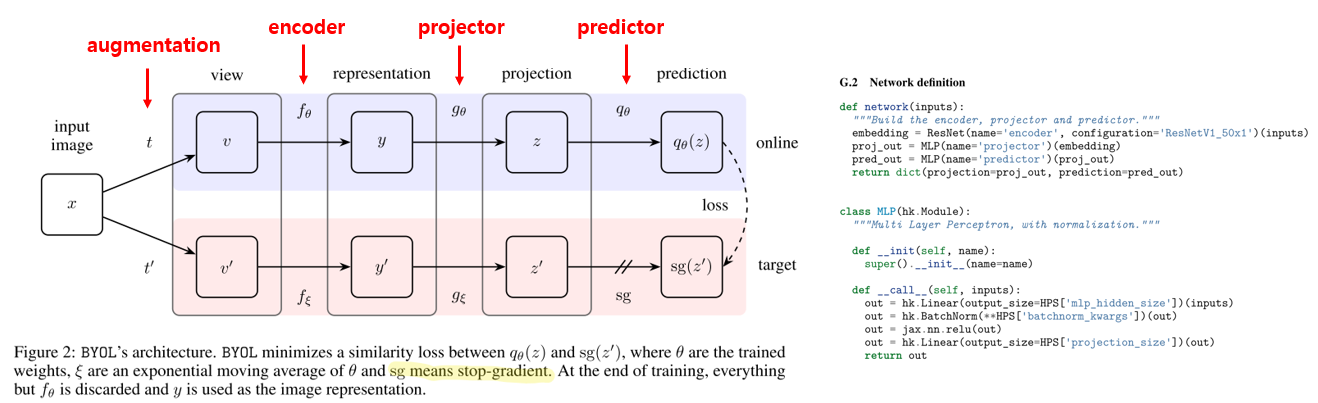
위에서 A와 B 2개의 network로 예시를 들었는데, 이제부터는 online network와 target network로 부를 예정입니다. 각각의 network는 encoder와 projector, predictor로 구성이 되어있으며, 그림에서 표시한 것처럼 각각 f, g, q 로 나타낼 예정입니다. Self-Supervised Learning의 목적은 위의 그림에 있는 representation y를 잘 배워서 downstream task에 잘 활용하는 것이기 때문에, 학습이 끝나면 online network의 encoder를 제외한 나머지 요소들은 사용이 되지 않을 예정입니다. encoder는 resnet50을 사용하였고, projector와 predictor는 MLP를 사용하였습니다.
위의 예시의 A network가 target network의 역할을 한다고 보시면 되고, B network가 online network의 역할을 한다고 이해하시면 됩니다. target network는 online network가 배울 regression target을 생성하게 되고, target network의 weight들은 online network의 weight들의 exponential moving average 값을 사용합니다. 이 부분이 BYOL의 핵심 요소입니다.
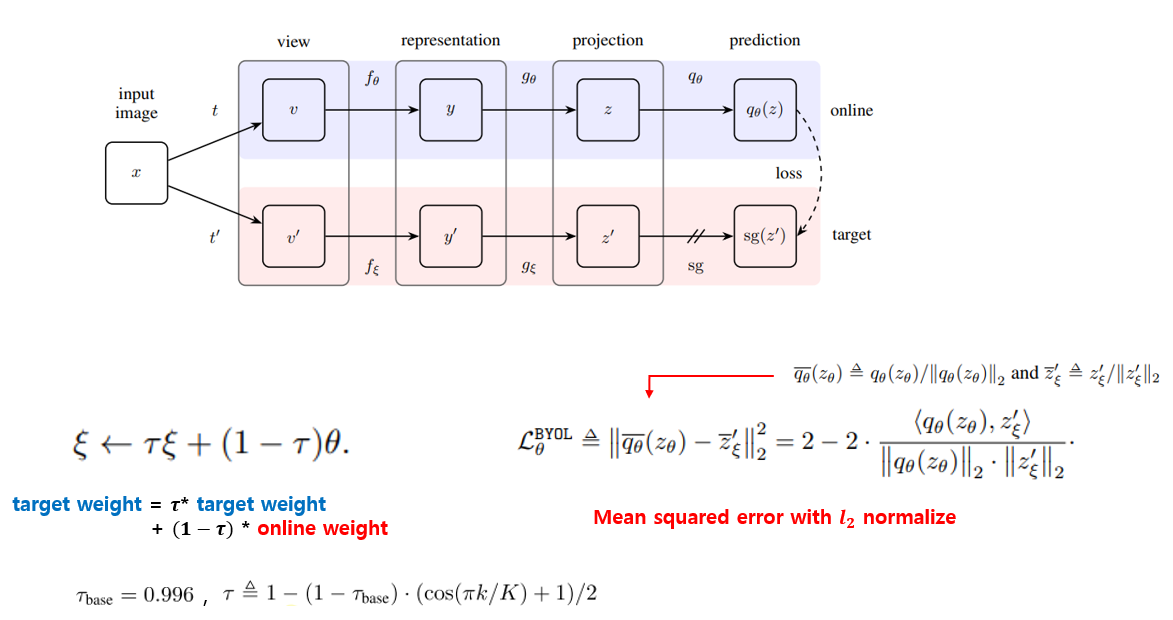
exponential moving average의 coefficient 값으론 0.996을 시작으로 그림의 좌측 하단에 있는 식처럼 iteration에 따라 cosine annealing을 해주었다고 합니다. 0.996부터 시작해서 점점 1에 가까운 값으로 키워주었다고 이해하시면 될 것 같습니다. 또한 loss function으로는 mean squared error function을 사용하였고, online network와 target network의 projection output들에 l2 normalization 시킨 값들간의 mean squred error를 구하여 loss를 계산하게 됩니다.
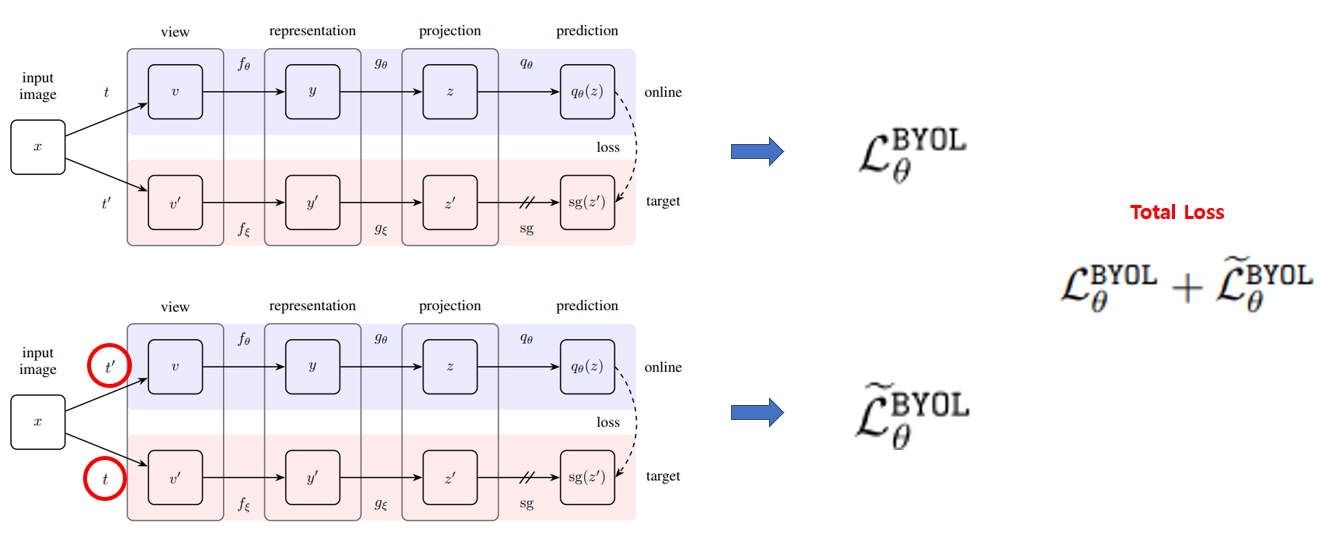
여기에, 한가지 트릭이 더 들어갔는데, loss를 symmetrize(대칭화) 시키기 위해, 사용한 augmentation을 바꿔서 loss를 한번 더 계산합니다. 즉, online network에 t’ augmentation을 가하고 target network에 t augmentation을 가한 뒤 loss를 계산해 줍니다. 그 뒤, 두 loss의 합을 total loss로 사용하여 학습을 시킵니다. 이 때, loss는 online network를 학습시키는 데만 사용이 되며, target network는 exponential moving average에 의해 weight가 결정됩니다. 참고로 그림의 sg는 stop-gradient를 의미하며, back propagation을 시키지 않겠다는 의미입니다!
비유를 하자면.. 과거의 내가 오늘의 스승이 된다.. 로 비유를 할 수 있을 것 같습니다. 과거의 online network들이 target network 속에 녹아들면서 오늘의 스승(target network)이 되는 셈이니까요! ㅋㅋ
여기까지가 BYOL의 핵심 알고리즘이었습니다. 요약하면 다음과 같습니다. 2개의 network (online network, target network)를 사용한다. target network의 weight는 online network의 weight의 exponential moving average에 의해 결정된다. 2개의 network에 서로 다른 augmentation을 적용하여 feature vector(prediction)을 뽑은 뒤, l2 normalize 시킨 후 mean squared error를 최소화시키는 방향으로 online network를 학습시킨다.
- Implementation details
실험을 위한 구현 디테일은 아래 그림에서 확인하실 수 있습니다. 대부분 SimCLR의 셋팅을 따라서 진행을 하였으며, 추가로 학습에 사용한 hyper parameter는 Appendix G에서 확인하실 수 있습니다.
가장 중요한 시사점은, 마지막 부분인 것 같네요. 512개의 Cloud TPU v3 cores를 이용하여 4096 batch size를 사용하였다…. 즉.. 저같은 서민은 학습시킬 여유가 없네요.. ㅠㅠ

실험 결과 및 분석
실험 방식은 Self-Supervised Learning의 표준을 따라서 진행이 됩니다.
- ImageNet linear evaluation & semi-supervised setup
우선 ImageNet 데이터셋에 대해선, ImageNet unlabeled 데이터셋으로 Self Supervised Learning 방식으로 Pre-training을 시킨 뒤, feature extractor(encoder)를 freeze 시키고, linear classifier를 학습시키는 linear evaluation 실험과, 일부분의 labeled training set을 가지고 feature extractor를 fine-tuning 시키는(do not freeze) semi-supervised training 실험을 수행하였습니다.
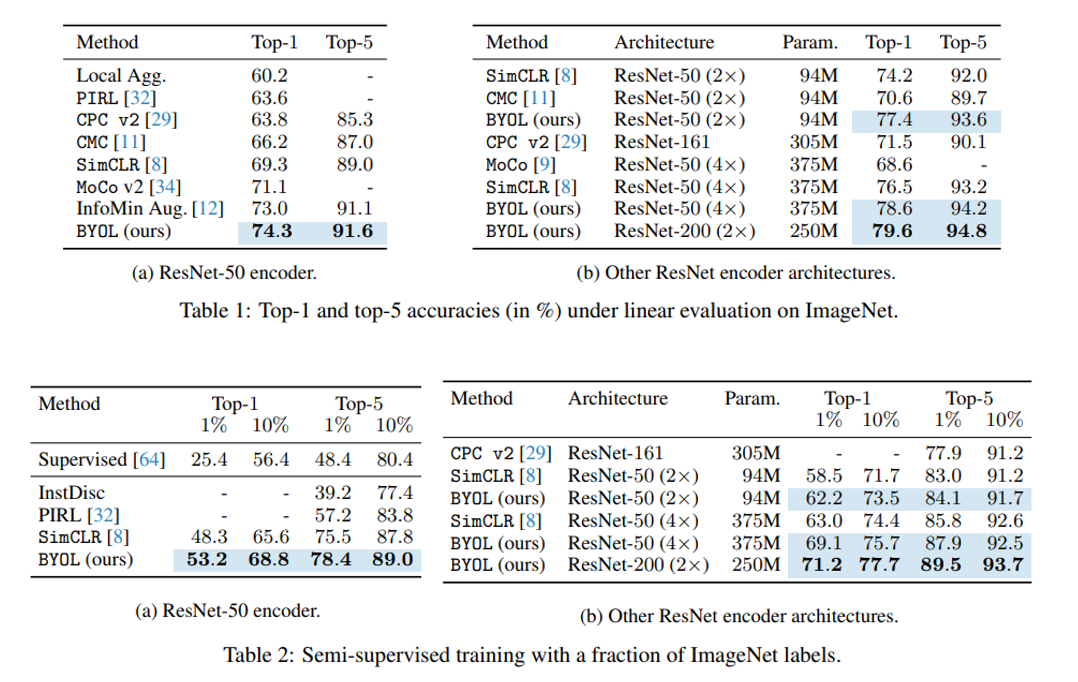
우선 linear evaluation 실험 결과는 위의 그림의 Table 1에 나와있으며, SimCLR, MoCov2, InfoMin Aug 등 선행 연구들보다 더 좋은 성능을 달성하였습니다. 하지만 SimCLR v2에서 같은 ResNet-50 encoder에 Selective Kernel Network(SKNet) 구조를 사용하여 linear evaluation을 하면 74.6%로 BYOL보다 0.3% 포인트 높은 성능을 달성하긴 합니다. (그만해….)
Semi-supervised setup에서는 1%, 10%의 training sample로 fine-tuning을 시켰을 때의 실험 결과를 보여주고 있으며, 기존 방법들 대비 우수한 성능을 보여주고 있습니다. 또한 Supervised [64] 라고 표시되어있는 성능은 아무런 pre-training 없이 학습을 시킨 성능으로 어떻게 보면 random initialization 성능이라고 볼 수 있습니다. 당연히 낮은 성능을 보여줍니다. BYOL이 다른 방법들에 비해 높은 성능을 보이고 있는데, 역시 예상하셨듯이 SimCLR v2에서는 더 높은 semi-supervised 성능을 보이고 있습니다.. 하하..
- Transfer Learning
두번째 실험 결과로는 Classification의 다른 데이터셋으로 Transfer 시키는 실험 결과와, 다른 Task로 Transfer 시킨 실험 결과를 제시하고 있습니다.
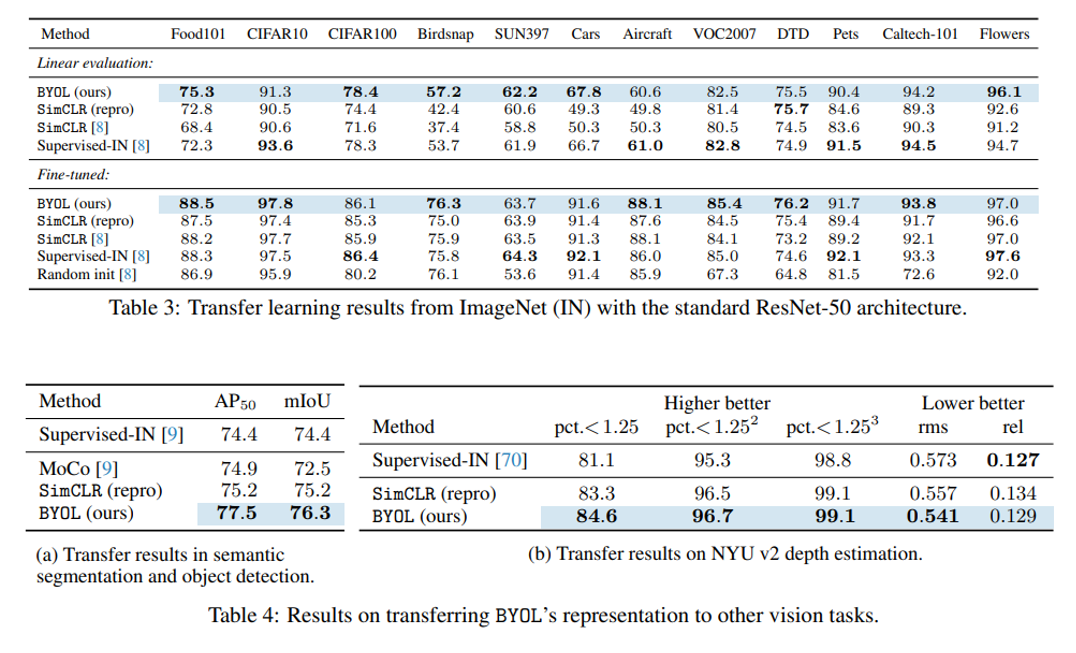
우선 다른 classification 데이터셋으론 Food101, CIFAR 등 12가지 데이터셋을 사용하였고, linear evaluation과 fine-tuning 실험 결과를 보여주고 있습니다. 위의 그림의 Table 3을 보면 대부분의 경우에서 BYOL이 좋은 성능을 보여주고 있으며, 주목할만한 실험 결과는 Fine-tuning 실험에서 Supervised-IN[8]의 결과보다 BYOL의 결과가 더 좋은 경우가 존재한다는 점입니다. (7승 5패!)
이게 무슨 뜻이냐면, 기존에는 default로 ImageNet-Pretrained 셋팅에서 다른 데이터셋에 fine-tuning 시켜왔는데, BYOL을 사용하면 ImageNet-Pretrained 셋팅과 비슷하거나 더 좋은 효과를 볼 수 있다는 점이고, 여기서 주목할 점은 BYOL은 ImageNet의 Label을 아예 사용하지 않고 Self-Supervised Learning으로 학습을 시켰다는 점입니다. 즉, ImageNet의 Label 정보를 사용하지 않고 feature extractor를 학습시켰는데, 여기서 얻은 representation들이 Label을 사용하여 얻은 representation과 견줄만하다는 뜻이며, 개인적으로는 참 신기했던 실험 결과입니다.
마지막으로, Object Detection, Semantic Segmentation, Depth Estimation 등 다른 task에 feature extractor로 사용하였을 때의 실험 결과가 위의 그림의 Table 4를 보면 ImageNet으로 Pre-training을 시켰을 때보다 BYOL을 사용하였을 때 더 좋은 성능을 보이고, SimCLR 보다 더 좋은 성능을 보이는 것을 확인할 수 있습니다.
- Ablations을 통해 얻은 intuitions
글이 길어졌는데, 저자들이 굉장히 다양한 실험을 수행하여 얻은 Intuition들을 2페이지에 걸쳐 정리하였는데, 저는 오늘 이 부분은 짧게 요약하여 전달드릴 예정입니다. 자세한 내용이 궁금하신 분들은 논문을 참고하시면 좋을 것 같습니다.

- SimCLR은 batch size가 작을 때 성능이 많이 망가졌었는데 BYOL은 덜 망가진다!
- Contrastive method에 비해 image augmentation option에 robust하다.
- Exponential moving average coefficient 값에 따라 성능이 약간씩 차이가 존재하지만 대체로 잘 된다! 1이면 constant random network(위의 간단한 실험에서의 A network 역할), 0이면 online weight를 그대로 target weight로 사용. 둘 다 좋은 성능을 보이지 못함. 즉, 적절히 target weight에 좀 delayed 되었지만 안정적인 online network의 weight로 넣어주는 것이 효과적임.
- BYOL과 SimCLR을 InfoNCE objective로 표현하여 두 알고리즘의 근본적인 차이를 분석함. 요약하면 SimCLR은 predictor가 없고 target network가 없음. BYOL은 negative example이 없음. BYOL에 negative example을 주고 학습을 시켰을 때는 오히려 성능이 떨어지지만, 적절한 tuning을 하면 사용하지 않았을 때와 비슷한 성능을 달성할 수 있음. (굳이 사용안하는게 나음)
결론
글이 굉장히 길어졌네요.. 이번 포스팅에서는 Self-Supervised Learning의 2020년 트렌드인 Contrastive Learning 기반 방법들을 간단히 정리하여 소개드렸고, 최근 공개된 BYOL 이라는 알고리즘을 소개드렸습니다. Google과 Facebook 의 양강 구도였는데 DeepMind가 기존 Contrastive Learning 방식이 갖는 한계점들을 하나씩 극복하며 좋은 성능을 달성할 수 있는 연구를 공개하였고, 논문의 내용을 제 나름대로 풀어서 정리를 해보았습니다. 정말 연구의 속도가 너무 빨라서, 잠시 다른 분야를 공부하다오면 금새 3~4편씩 논문이 나와있는 세상에서 살고있네요.. ㅋㅋ 공부하시는 분들 모두 화이팅입니다..!