Deep Learning Image Classification Guidebook [4] Squeeze-and-Excitation Network (SENet), ShuffleNet, CondenseNet, MobileNetV2, ShuffleNetV2, NASNet, AmoebaNet, PNASNet, MnasNet
안녕하세요, 지난 Deep Learning Image Classification Guidebook [3] 에 이어서 오늘은 2018년 공개된 주요 CNN architecture들에 대한 설명을 드릴 예정입니다. 2018년에서는 모델의 경량화를 다룬 여러 논문들, CNN architecture에 큰 패러다임 시프트를 가져온 AutoML을 이용한 Neural Architecture Search(NAS) 논문들이 주를 이루고 있습니다. 오늘 소개드릴 논문은 다음과 같습니다.
- Squeeze-and-Excitation Network (SENet)
- ShuffleNet
- CondenseNet
- MobileNetV2
- ShuffleNetV2
- NASNet
- AmoebaNet
- PNASNet
- MnasNet
2018년 제안된 CNN architecture 소개
Squeeze-and-Excitation Network (SENet), 2018
처음 소개드릴 architecture는 2018년 CVPR에서 발표된 “Squeeze-and-Excitation Networks” 라는 논문이며 SENet 이라는 이름으로 불립니다. 2017년 ILSVRC에서 1위를 차지하여 유명해진 모델이기도 합니다.
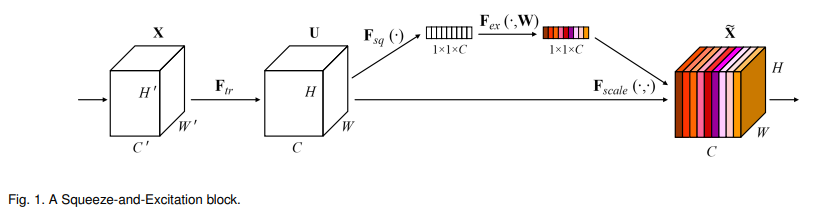
위의 그림이 이 논문의 핵심을 보여주는 Squeeze-Excitation block을 보여주고 있습니다. 우선 Squeeze 연산 에서는 feature map을 spatial dimension (H x W)을 따라서 합쳐주는 과정이 진행되며 이 때 저희가 지난 포스팅들을 통해서 봤었던 Global Average Pooling이 사용됩니다.
그 뒤 Excitation 연산 이 뒤따르며, input vector를 같은 모양을 갖는 output vector로 embedding 시키는 간단한 self-gating 메커니즘을 통해 구현이 됩니다. 즉 여기선 channel 마다 weights를 주는 느낌을 받을 수 있으며 이를 channel 방향으로 attention을 준다고도 표현을 합니다. 그림을 보시면 excitation 연산을 통해 vector에 색이 입혀진 것을 확인할 수 있으며, 이렇게 색이 매겨진 vector와 input feature map U를 element-wise로 곱하면 output feature map이 생성되며, output feature map에 각 channel마다 아까 구한 weight(색)들이 반영이 되어있는 것을 확인할 수 있습니다.
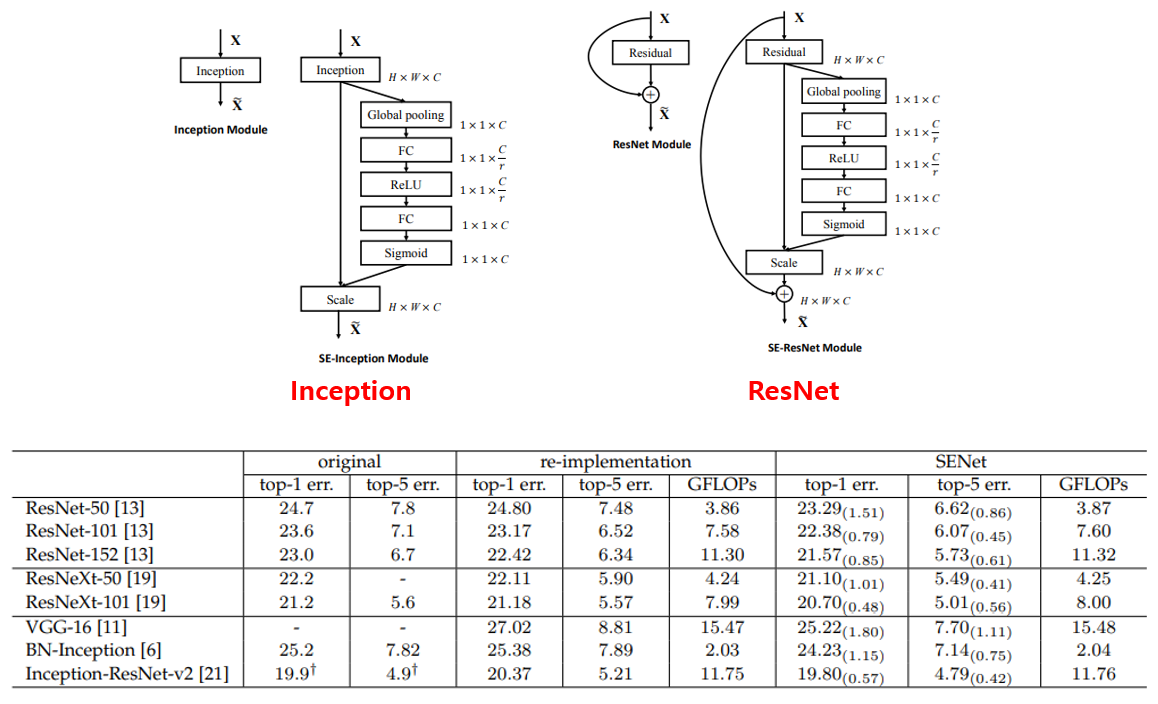
Squeeze-Excitation block의 가장 큰 장점으로는 이미 존재하는 CNN architecture에 붙여서 사용할 수 있다는 점입니다. 즉, ResNet 등 잘 알려진 network 구조에서 squeeze-excitation block을 추가하면 SE-ResNet이 되는 셈이죠. 위의 그림과 같이 Inception module, ResNet module에도 부착이 가능하며 실제로 저자들이 ResNet, ResNext, Inception 등에 SE block을 추가한 결과 미미한 수치의 연산량은 증가하였지만 정확도가 많이 향상되는 결과를 제시하였습니다.
이 외에도 ablation study를 여러 개 수행하였는데, 간단히 요약을 드리겠습니다. Inception과 ResNet에 SE block을 추가한 위의 그림을 자세히 보시면 FC layer를 거쳐서 channel이 C에서 C/r로 줄어들었다가 다시 C로 돌아오는 형태를 확인하실 수 있습니다. 이 r을 reduction ratio라 하는데, 여러 reduction ratio에 대해 실험을 한 결과 대부분 비슷했으나 정확도와 complexity를 동시에 고려하면 16이 최적임을 실험적으로 밝혔습니다. 또한 Squeeze 연산에서 Max와 Average 연산 중 Average 연산이 더 효과적이고, Excitation operation에서는 ReLU, Tanh보다 Sigmoid를 쓰는 것이 효과적임을 실험적으로 보이고 있습니다.
ShuffleNet, 2018
다음은 2018년 CVPR에 “ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile” 라는 제목으로 발표된 ShuffleNet 입니다. MobileNet과 마찬가지로 이진원 선배님의 PR-12 발표 영상 과 발표 슬라이드 에 잘 정리가 되어있어서 ShuffleNet은 핵심만 간단히 설명하겠습니다.
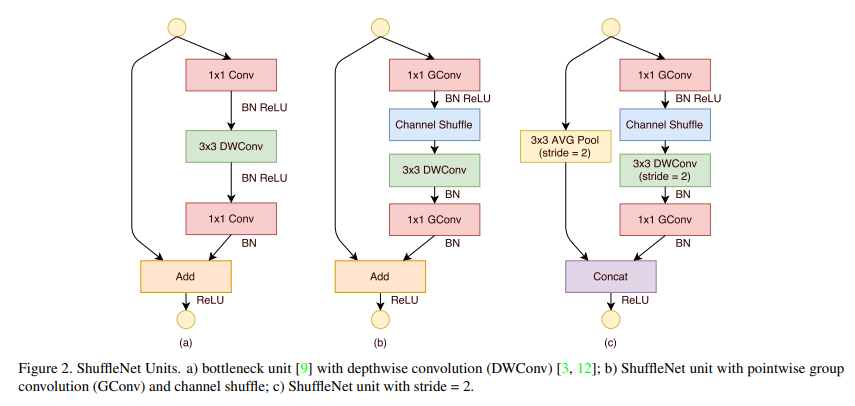
ShuffleNet은 지난 포스팅에서 소개 드렸던 MobileNet과 같이 경량화된 CNN architecture를 제안하였으며 AlexNet과 ResNext에서 봐서 이제는 친숙할 법한 Group Convolution 과 본인들이 제안한 Channel Shuffle 이 ShuffleNet의 핵심입니다. Depthwise Separable Convolution 연산이 제안된 이후 경량화된 CNN에는 필수로 사용이 되고 있었는데, 예전에는 연산량을 줄이기 위해 제안되었던 1x1 convolution 연산이 이제는 전체 연산 중에 많은 비율을 차지하게 되었습니다. 이 점에서 출발해서 1x1 convolution 연산에 Group Convolution을 적용하여 MobileNet보다 더 효율적인 구조를 제안했습니다. MobileNet과 ShuffleNet의 이러한 경쟁 구도가 선순환으로 이어지게 됩니다. MobileNet V2가 ShuffleNet에 이어서 공개가 되었으며 자세한 설명은 뒤에서 드리도록 하겠습니다.
CondenseNet, 2018
다음은 2018년 CVPR에 “CondenseNet: An Efficient DenseNet using Learned Group Convolutions” 라는 제목으로 발표된 CondenseNet 입니다. 이 논문도 MobileNet, ShuffleNet과 같이 Mobile Device 등 computational resource가 제한된 기기에서 CNN을 돌리기 위해 경량화 된 architecture를 제안한 논문이며, 제목에서 알 수 있듯이 Learned Group Convolution이라는 방법을 DenseNet에 접목시키는 방법을 제안하고 있습니다. 여기에 Network Pruning의 아이디어도 접목이 됩니다. Network Pruning은 layer 간의 중요하지 않은 연결을 제거하는 방식이며, 이러한 아이디어가 CondenseNet에 들어가 있습니다.
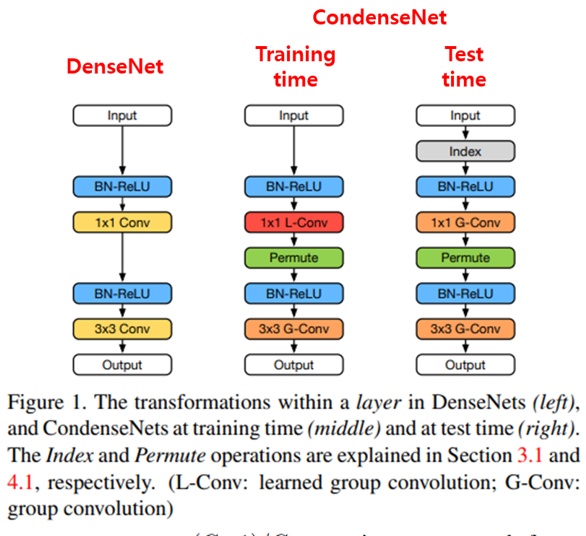
위의 그림은 기존 DenseNet (왼쪽 그림)과 CondenseNet의 차이를 간단히 보여주고 있으며, 가운데 그림은 CondenseNet의 학습 단계의 모습을, 오른쪽 그림은 CondenseNet의 test 단계의 모습을 보여주고 있습니다.

CondenseNet의 learned group convolution은 위의 그림으로 설명이 가능합니다. 우선 저희가 잘 알고 있는 group convolution이 사용이 되고, Group 개수인 G는 hyper-parameter입니다. 여기에 condensation factor C 라는 hyper-parameter가 더 존재합니다. Condensation이란 사전적 의미는 응결, 압축 등이며 실제로 압축시키는 의미로 사용이 됩니다. 위의 그림은 G=C=3인 경우를 보여주고 있으며, 학습 과정은 C-1개의 Condensing Stage, 1개의 Optimization Stage로 구성이 되어있고, 각 Stage는 G개의 group으로 나뉘어져 있습니다.
C-1 개의 Condensing Stage를 거치면서 결과적으로 1/C 개의 connection을 제외하고 나머지 connection들은 제거되는 구조로 되어있으며, 실제로 위의 그림을 자세히 보시면 각 group별로 빨간색, 초록색, 노란색으로 구분이 되어있고, connection 또한 group의 색과 같은 색으로 칠해져 있습니다. Stage가 지날수록 점점 connection들이 사라져서 Optimization Stage에서는 1/3개의 Connection들만이 남아있게 됩니다. Test 단계에서 학습때의 결과를 사용하게 되며, 그림에서 2번과 4번 feature map의 경우 아무런 connection도 존재하지 않고 5번, 12번 feature map은 2가지 group과 연결이 되어있는데, 이를 Index Layer를 통해서 순서를 맞춰준 뒤 group convolution을 해주는 방식으로 구성이 되어있습니다.
정리하면, Condensing Stage를 통해 학습 과정에서 자동으로 sparse한 network를 만들 수(중요한 connection만 남길 수) 있었고, 이 과정이 마치 Pruning을 학습을 통해 자동으로 하는 것과 같은 느낌을 받을 수 있습니다.
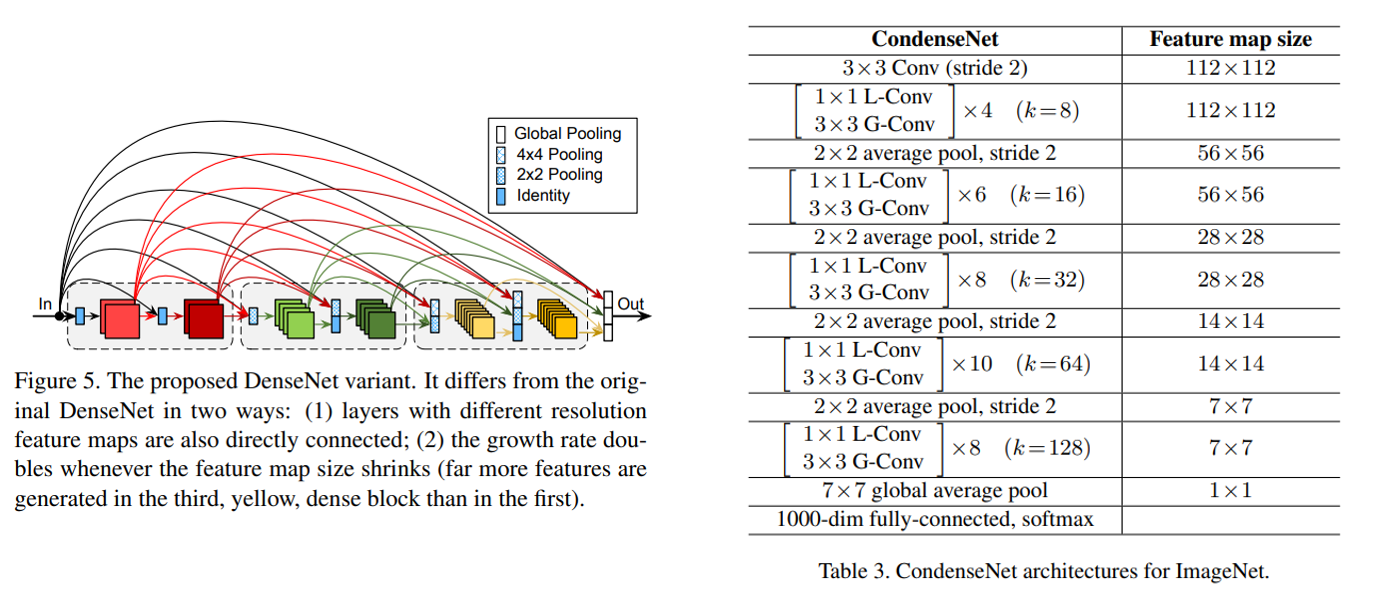
CondenseNet은 DenseNet에서 약간의 변화가 이뤄졌는데, 첫번째론 다른 resolution을 갖는 feature map간에도 densely 연결을 하였고, 이 때 pooling을 통해 resolution을 맞춰주고 있습니다. 두번째론 feature map의 size가 줄어들 때, growth rate를 2배 키워주고 있습니다. 오른쪽 표는 ImageNet 데이터셋에 대한 CondenseNet의 architecture를 보여주고 있습니다. 1x1 learning group convolution과 3x3 group convolution을 여러 번 쌓아서 사용하고 있습니다.
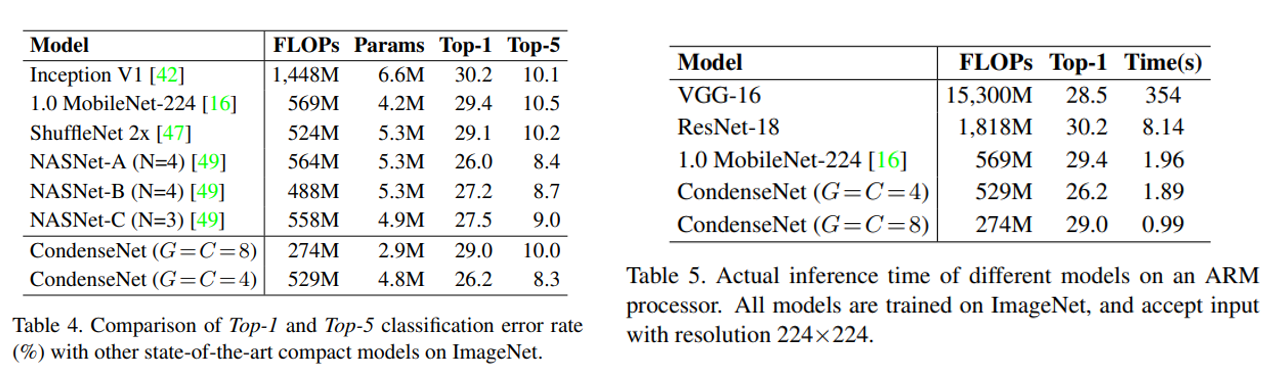
CondenseNet은 MobileNet, ShuffleNet, NASNet 등과 비교하였을 때 더 적은 연산량과 parameter를 가지고 더 높은 정확도를 보이고 있음을 확인할 수 있으며, 실제 ARM processor에서 inference time을 측정하였을 때도 MobileNet보다 거의 2배 빠른 처리 속도를 보였습니다. 이 외에도 여러 ablation study가 수행이 되었는데 관심있으신 분들은 논문을 참고하시기 바랍니다.
MobileNetV2, 2018
이 논문도 2018년 CVPR에 “MobileNetV2: Inverted Residuals and Linear Bottlenecks” 제목으로 발표가 되었으며 지난 포스팅에서 소개 드렸던 MobileNet의 두번째 버전이며 이번에도 이진원 선배님의 PR-12 발표 영상 과 발표 슬라이드 에 자세히 설명이 되어있기 때문에 저는 핵심만 요약드릴 예정입니다.
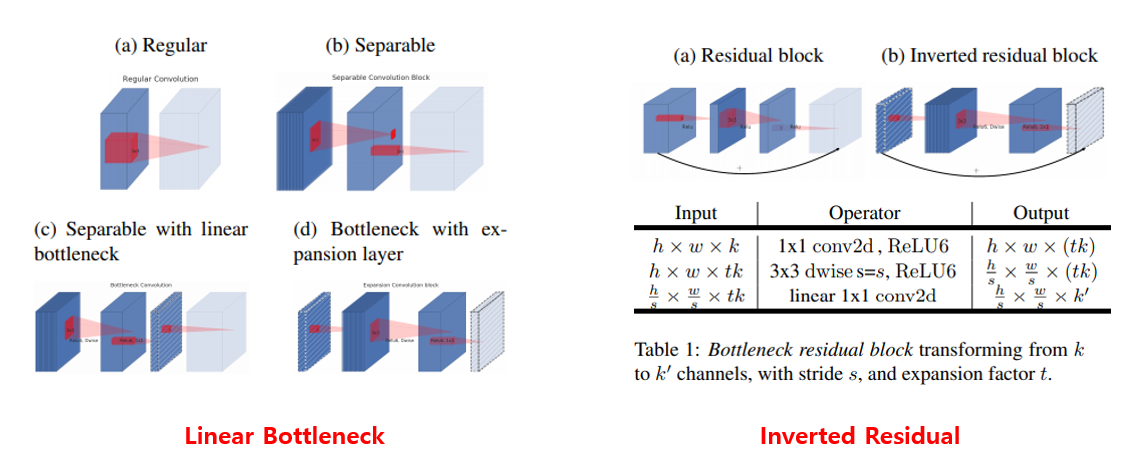
우선 MobileNetV1의 핵심이었던 Depthwise Separable Convolution이 역시 MobileNetV2에도 사용이 되며, Linear Bottlenecks 아이디어와 Inverted Residual 아이디어가 MobileNetV2의 가장 큰 변화입니다.
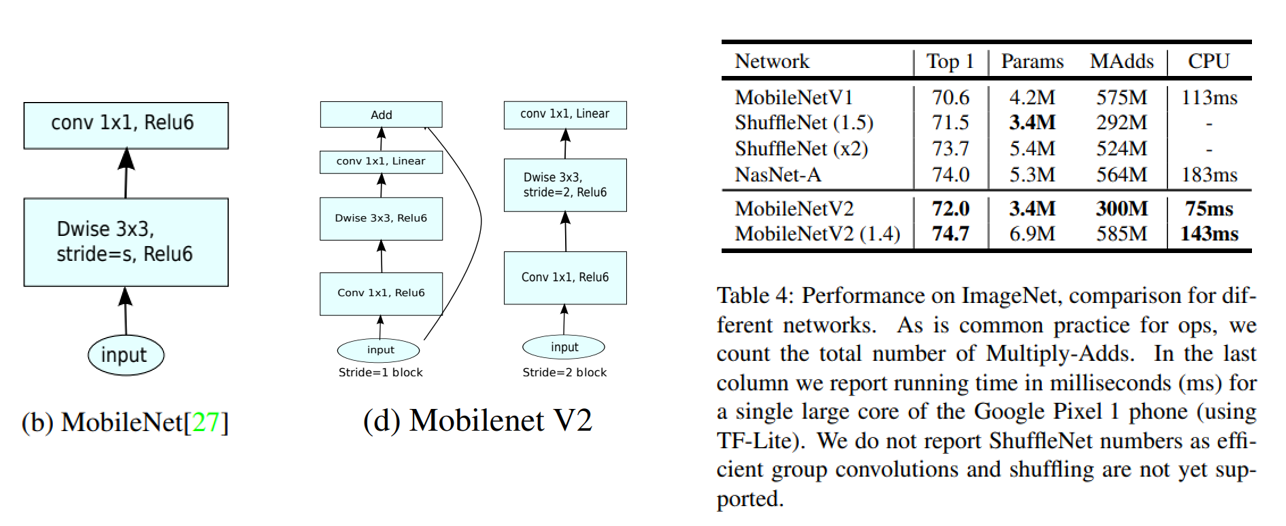
MobileNet의 convolution block과 MobileNetV2의 convolution block의 차이는 위의 그림과 같으며 architecture를 업그레이드하면서 동시에 정확도와 parameter 개수, 연산량 등 모든 지표에서 성능이 좋아지는 것을 확인할 수 있습니다. 즉 완벽한 의미의 업그레이드를 이뤘다고 볼 수 있습니다.
이 외에도 논문에서 Object Detection, Semantic Segmentation등 다른 task에 대해서도 MobileNetV2를 backbone architecture로 사용하면 좋은 성능을 얻을 수 있음을 보이며 논문이 마무리됩니다. 더 깊은 이해가 필요하신 분들은 위에 인용한 발표 영상을 보신 뒤, 논문을 읽어보시는 것을 권장드립니다.
ShuffleNetV2, 2018
이번에는 ShuffleNet의 2번째 버전인 ShuffleNetV2 이며 ECCV 2018에 “ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design”라는 제목으로 발표가 되었습니다. 짐작가시겠지만 ShuffleNet을 바탕으로 성능을 개선시킨 후속 연구이며 이번에도 경량화 아키텍처의 양질의 발표 자료를 만들어 주신 이진원 선배님의 PR-12 발표 영상 과 발표 슬라이드 자료를 바탕으로 간단히 소개 드리려 합니다.
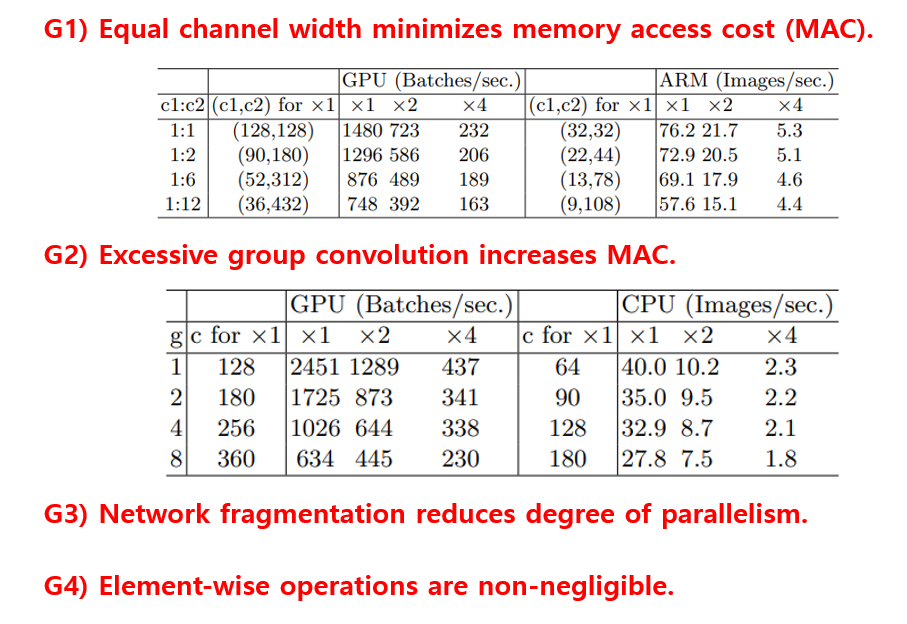
일단 논문의 제목에 있는 Practical Guideline에서 알 수 있듯이, 실제로 사용하는 입장에서 network architecture를 설계해야 함을 강조하고 있습니다. FLOPs(Floating Point Operations Per Second)는 기존 연구 들에서 주로 목표로 삼아오던 지표인데 이는 실제로 mobile device에서 CNN을 사용하는데 있어서 가장 중요한 지표가 아닙니다. 본 논문에서는 실제 동작 시간인 takt time 혹은 throughput 지표, memory access cost 지표 등 실제로 중요한 지표를 고려하여 CNN architecture를 설계하는 방법을 제안합니다. 위의 그림에 논문에서 제안한 4가지 가이드라인이 정리가 되어있습니다.
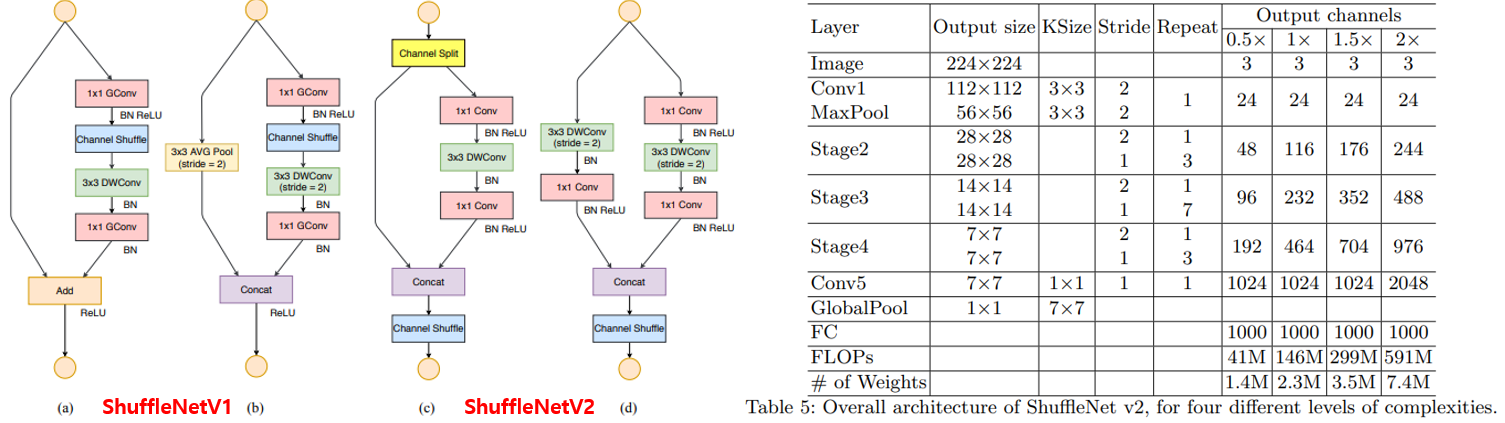
위의 4가지 요소들을 고려하여 building block과 architecture를 수정하였으며, 그 결과 ShuffleNetV1은 물론 MobileNetV2 보다 비슷한 정확도에서 더 빠른 처리 속도를 보였습니다. 두 모델간의 경쟁이 참 치열하죠? 여담이지만 MobileNet은 3번째 버전 MobileNetV3이 2019년 ICCV에 발표가 되었는데 ShuffleNetV3은 언제쯤 공개가 될지 궁금합니다 ㅎㅎ
NASNet, 2018
다음은 2018년 CVPR에 “Learning Transferable Architectures for Scalable Image Recognition” 라는 제목으로 발표된 NASNet 입니다. 이 논문은 AutoML을 이용하여 architecture를 찾는 Neural Architecture Search(NAS)를 통해 ImageNet과 같은 비교적 규모가 큰 데이터셋에 적용시키기 위한 방법을 제안하였습니다.
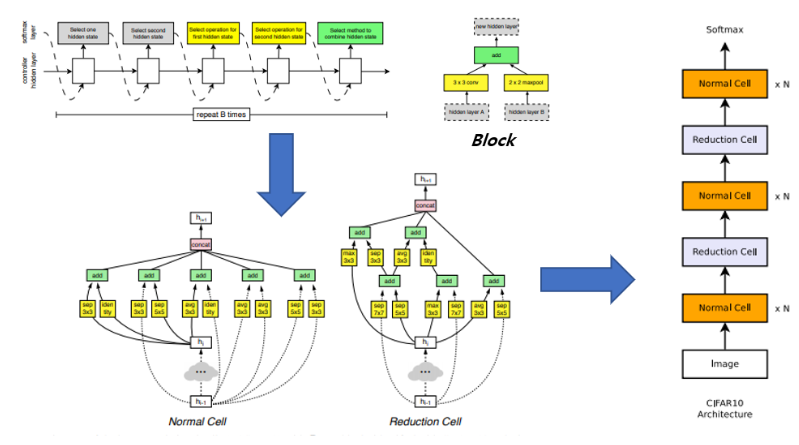
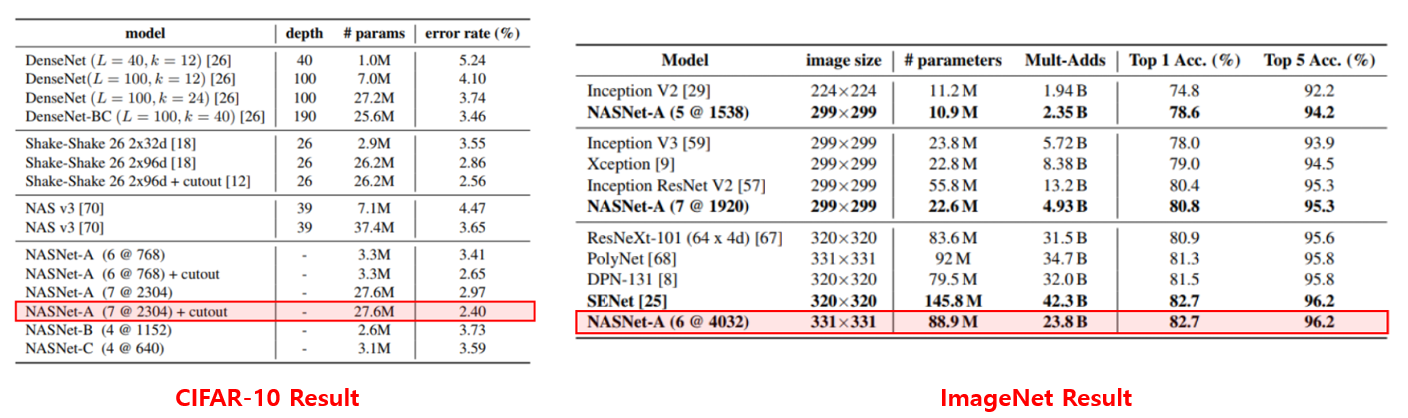
2017년 ICLR에 발표된 NAS의 시초격인 “Neural Architecture Search with reinforcement learning” 논문은 CIFAR-10과 같은 작은 데이터셋에 대한 최적의 architecture를 찾기 위해 800대의 GPU로 약 한달정도 search를 해야하기 때문에, ImageNet에 대해선 거의 수백년이 걸린다는 한계가 있습니다. NASNet은 이를 극복하기 위해 작은 데이터셋에서 찾은 연산들의 집합인 Convolution Cell을 큰 데이터셋에 적절하게 재활용을 하는 방법을 제안하였고, 그 결과 ImageNet 데이터셋에 대해서 기존 SOTA 논문이었던 SENet 보다 더 적은 파라미터수와 연산량으로 동등한 정확도를 달성하는 결과를 보여주고있습니다.
NASNet 논문에 대한 상세한 리뷰는 제 블로그 글 을 통해 확인하실 수 있습니다. 또한 발표자료 형태로도 제작을 하였는데 관심 있으신 분들은 Slideshare PPT 자료도 참고하시면 좋을 것 같습니다.
AmoebaNet, 2018
이번에 소개드릴 논문도 NAS 논문이며, 2018년 2월 arXiv에 공개되고 2019년 AAAI에 “Regularized Evolution for Image Classifier Architecture Search” 제목으로 발표된 AmoebaNet 입니다.
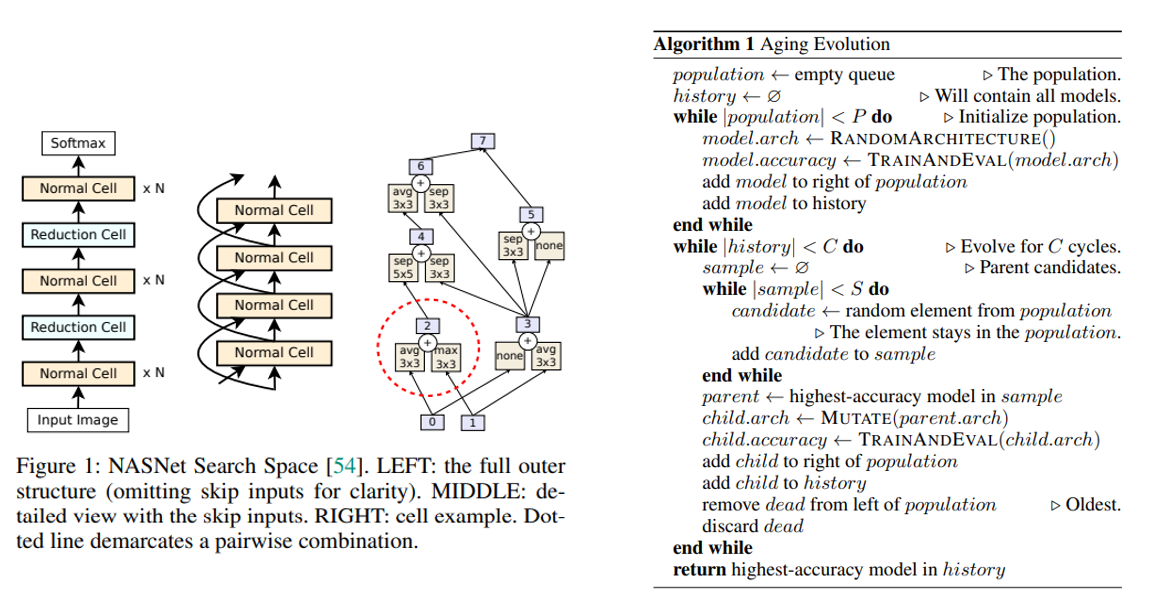
기존 NAS, NASNet 등의 연구에서는 강화학습을 기반으로 architecture search를 수행하였는데, AmoebaNet에서는 Evolutionary Algorithms(진화 알고리즘)을 기반으로 architecture를 찾는 방법을 제안하였습니다. 다만 architecture search에서 중요한 역할을 하는 search space는 NASNet의 search space를 그대로 사용하였고, 실제로 두 방식의 최종 test accuracy도 거의 비슷하게 측정이 됩니다. 위의 그림과 같은 search space와 aging 기반 토너먼트 selection 진화 알고리즘을 바탕으로 architecture search를 수행합니다.
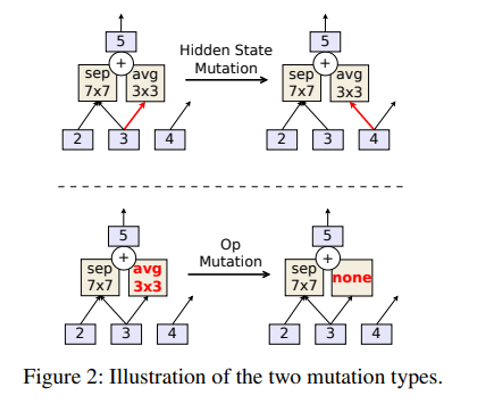
진화 알고리즘에서 다양한 가능성을 만들어주는 돌연변이(mutation) 생성 방법에는 2가지 방법이 있는데 각 연산의 output을 연결해주는 곳(Hidden state)에 mutation을 가하는 방법과, 각 연산자를 바꾸는 방법이 사용됩니다.
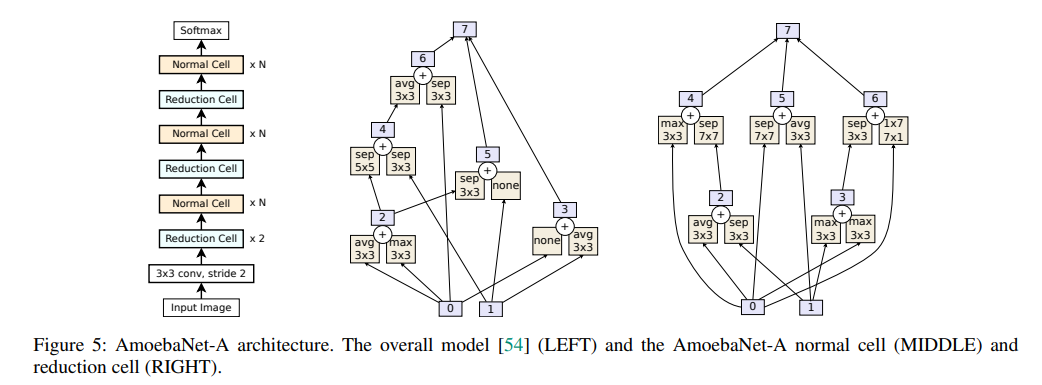
진화 알고리즘을 바탕으로 찾은 AmoebaNet-A의 architecture는 다음과 같으며, NASNet과 마찬가지로 Normal Cell과 Reduction Cell을 여러 번 반복하는 구조로 되어있습니다.
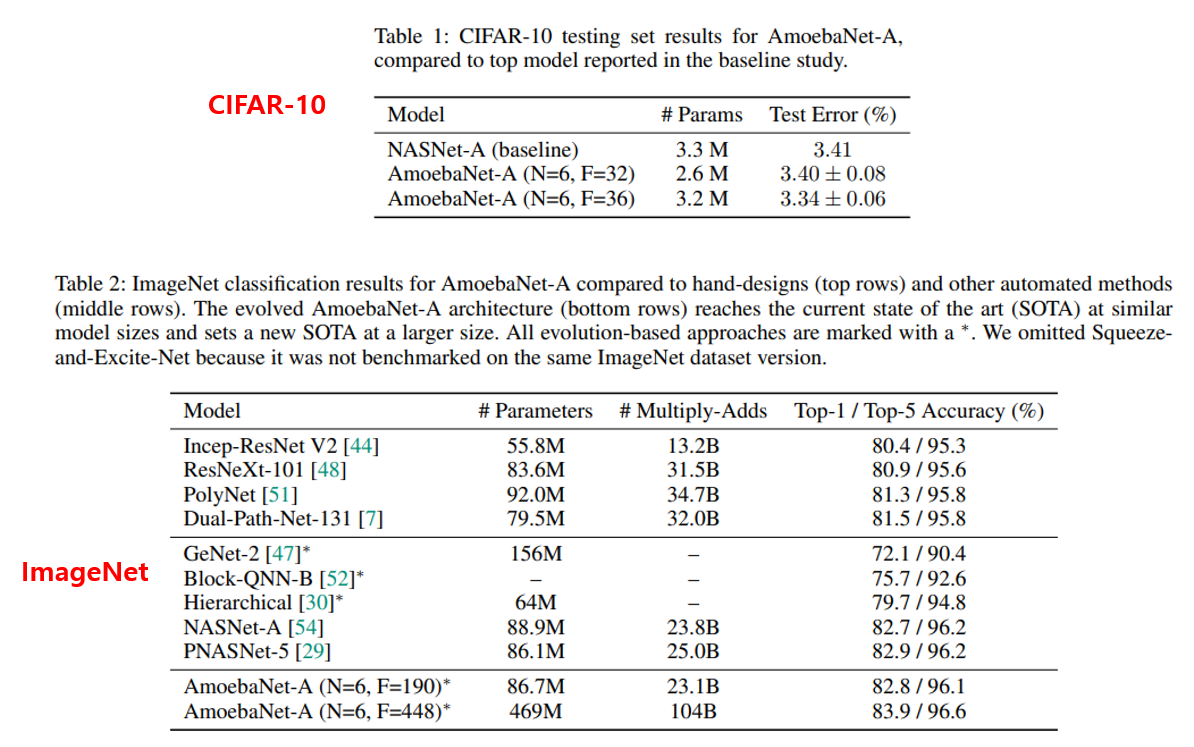
AmoebaNet의 architecture의 크기를 결정하는 요소는 stack 당 normal cell을 쌓는 개수인 N과 convolution 연산의 output filter의 개수인 F에 의해 결정되며, F과 F를 키워주면 parameter 개수, 연산량이 증가하지만 정확도도 증가하는 경향을 보이며, ImageNet 데이터셋에 대해서 F를 448로 크게 키워주는 경우 기존 NASNet, 바로 다음 설명드릴 PNASNet 보다 약간 더 높은 정확도를 달성하는 결과를 보여주고 있습니다. 다만 NASNet, PNASNet 자체도 성능이 꽤 높은 편이라 AmoebaNet이 압도적인 성능을 보여주진 못합니다. 그래도 진화 알고리즘을 architecture search에 접목시켰다는 점에서 많이 인용되는 논문인 것 같습니다.
추가로 제가 최근에 작성했던 “AutoML-Zero:Evolving Machine Learning Algorithms From Scratch” 논문 리뷰 에서는 진화 알고리즘을 바탕으로 architecture보다 더 low-level의 정보들을 바탕으로 전체 머신러닝 알고리즘을 설계할 수 있는 가능성을 보여주기도 했습니다. 연구의 발전 속도가 굉장히 빠르죠? ㅎㅎ
PNASNet, 2018
이번엔 2018년 ECCV에 “Progressive Neural Architecture Search” 제목으로 발표된 PNASNet 입니다. NAS에 “점진적인” 이라는 뜻을 갖는 Progressive를 붙인 것에서 알 수 있듯이, Cell 구조에 들어가는 연산들을 하나하나 추가하는 과정을 통해 Cell을 형성하며, 이 때 Sequential Model-Based Optimization(SMBO) 방식이 사용됩니다. Search space는 NASNet에서 사용한 것을 거의 참고하였으며, NASNet의 search space에 있던 13개의 연산 중 거의 사용되지 않은 5개의 연산을 제거하고 8개의 연산만 사용하였습니다. 중요한 건 아닌데, 13개의 연산 중 버려진 연산은 다음과 같습니다.

큰 kernel을 갖는 max pooling과 1x3 + 3x1 convolution도 제거가 된 점은 저는 수긍이 갔지만, 사람이 자주 사용하던 연산인 1x1 convolution과 3x3 convolution이 제외된 점은 다소 놀라웠습니다. 마치 사람이 제안한 방법이 인공지능에게 선택 받지 못한 느낌이 들었네요.. 아니면 3x3 convolution 대신 3x3 dilated convolution, depthwise-separable convolution이 더 효과적이기 때문에 선택받지 못한 것 같기도 합니다.
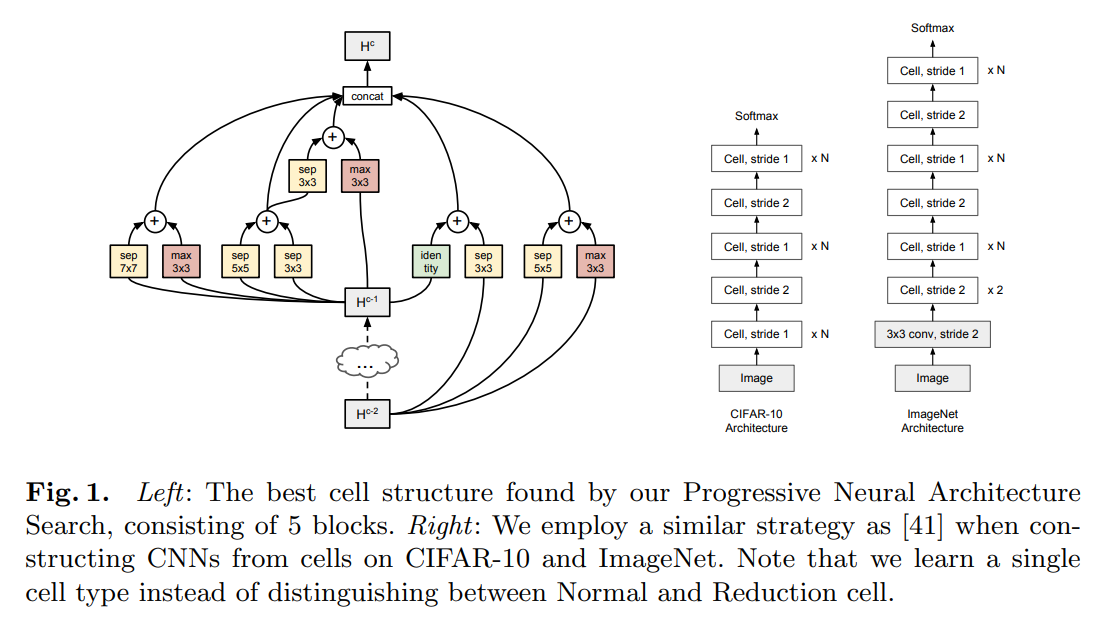
위의 그림은 SMBO를 이용하여 architecture search를 하여 찾은 Cell 구조를 보여주고 있으며, NASNet, AmoebaNet과는 다르게 Normal Cell과 Reduction Cell로 나눠서 찾지 않았고 하나의 Cell만 찾은 뒤, Stride를 조절하여 feature map의 가로, 세로 크기를 줄여줍니다.
MnasNet, 2018
오늘의 마지막 논문은 2018년 arXiv에 공개되고 2019년 CVPR에 “MnasNet: Platform-Aware Neural Architecture Search for Mobile” 제목으로 발표된 MnasNet 입니다. 이전 NAS 논문들은 정확도에 초점을 두어서 굉장히 오랜 시간 GPU를 태워가면서 거대한 CNN architecture를 찾는데 집중했다면, 이 논문에서는 Mobile Device에서 돌릴 수 있는 가벼운 CNN architecture를 NAS를 통해 찾는 것을 목표로 연구를 시작합니다.
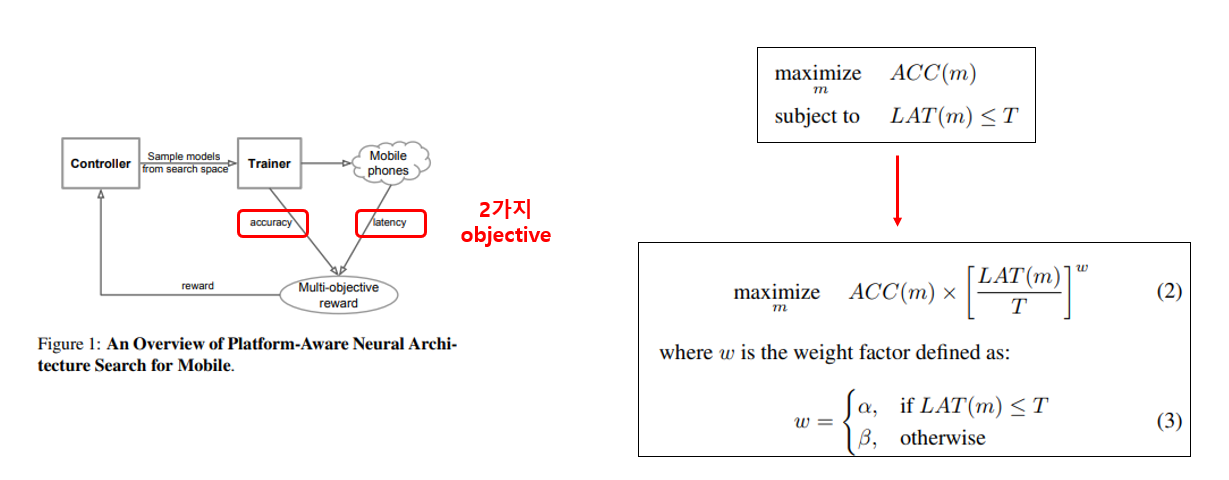
그래서 정확도와 Latency 2가지를 동시에 고려할 수 있게 objective function을 위의 그림과 같이 정의합니다. 즉, 정확도도 높이지만 Latency도 줄여야 좋은 점수를 받을 수 있는 것입니다. 그 외에는 NAS, NASNet 과 같이 RL 기반으로 architecture search를 수행하며, search space에서 약간의 변화가 있습니다.
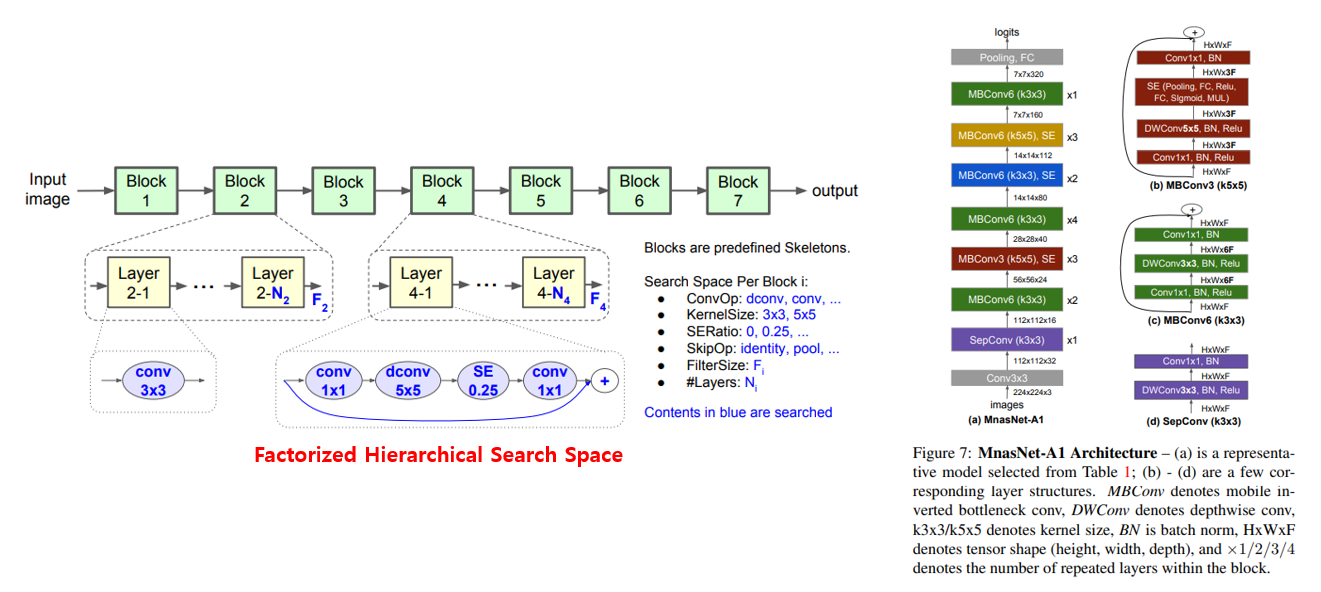
NASNet, PNASNet 등에서는 Cell을 구성하는 여러 연산들을 옵션으로 두고 Cell을 찾은 뒤 그 Cell을 반복해서 쌓는 구조를 사용하였다면, MnasNet에서는 각 Cell 마다 다른 구조를 갖지만 하나의 Cell에는 같은 연산을 반복시키는 구조로 search space를 가져갑니다. 이렇게 search space를 가져감으로써 다양성과 search space의 크기의 적절한 균형을 얻을 수 있었다고 합니다.
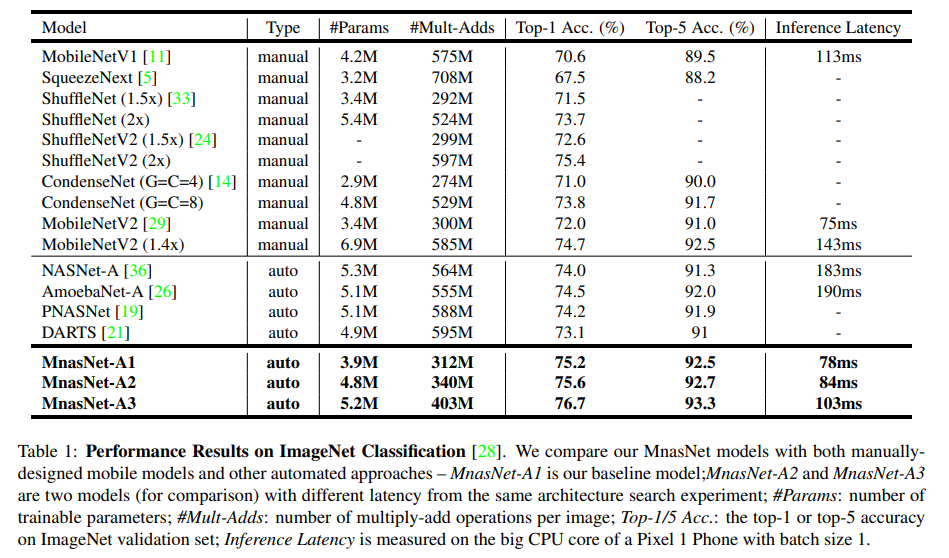
제가 그동안 설명 드렸던 경량 CNN architecture들과 MnasNet의 성능을 비교한 결과가 위에 나와있으며, 사람이 디자인한 구조들, 정확도를 타겟으로 한 AutoML NAS 기반의 방법들에 비해서 더 빠른 속도로 더 높은 정확도를 얻을 수 있었습니다. 즉, 이 논문에서 목표로 했던 정확도와 Latency 두 마리 토끼를 다 잡은 셈이죠. MnasNet 덕분에 경량 CNN architecture 연구의 동향도 사람이 디자인하는 것에서 AutoML을 이용한 NAS 쪽으로 방향이 바뀌게 되며, 추후 연구들은 다음 포스팅에서 설명 드리도록 하겠습니다.
이후 NAS 연구들에 대한 간단한 정리
위에서 NAS, NASNet, AmoebaNet, PNASNet, MnasNet 5가지 방법에 대해 소개를 드렸는데, 이 방법들 모두 사람이 만든 CNN architecture보다 더 높은 정확도를 달성하는 데 성공하였지만, search에 수백, 수천 gpu days가 소요되는 점은 여전히 풀어야할 숙제였습니다.
이 논문들 이후에는 search에 소요되는 시간을 줄이려는 연구들이 많이 제안이 되었고, 대표적인 방법이 RL 기반의 Efficient Neural Architecture Search via Parameter Sharing(ENAS) 와, Gradient Descent 기반의 DARTS: Differentiable Architecture Search (DARTS) 등이 있으며, 해당 논문들 덕분에 거의 single gpu로 하루만에 search가 가능한 수준까지 빠르게 올라오게 됩니다. ENAS와 DARTS는 한글로 작성된 양질의 자료들이 많아서 따로 다루진 않겠습니다. 관심 있으신 분들은 구글링을 해보시면 좋은 글들을 많이 찾으실 수 있을 것입니다. ㅎㅎ
결론
오늘 포스팅에서는 2018년 제안된 9가지의 CNN architecture(Squeeze-and-Excitation Network (SENet), ShuffleNet, CondenseNet, MobileNetV2, ShuffleNetV2, NASNet, AmoebaNet, PNASNet, MnasNet)에 대해 설명을 드렸습니다.
다음 포스팅에서는 2019년 제안된 CNN architecture 연구들을 소개드릴 예정입니다. 읽어주셔서 감사합니다!
Reference