Single Image Super Resolution using Deep Learning Overview
안녕하세요, 이번 포스팅에서는 이전 포스팅에서 주로 다뤘던 영상 인식(Image Recognition) 분야가 아닌 영상 처리(Image Processing) 분야 중 “Single Image Super Resolution”이라는 분야에 대해 소개를 드리고 Super Resolution에 딥러닝을 적용하는 연구 동향에 대해 소개드릴 예정입니다. 또한 현재 방식들의 한계와 풀어야할, 혹은 풀고 있는 문제들이 무엇이 있는지에 대해 소개를 드릴 예정입니다.
전반적인 내용은 작년 발표된 2편의 서베이 논문 “Deep Learning for Single Image Super-Resolution: A Brief Review” , “A Deep Journey into Super-resolution: A survey” 논문을 참고하여 작성을 하였습니다.
이 포스팅을 발표 자료(PPT)로 제작한 자료는 Slideshare 에도 업로드를 해두었으니 편하신 자료로 보시면 좋을 것 같습니다. 이제 본격적으로 내용을 소개 드리도록 하겠습니다.
Image Super Resolution이란?

이번 포스팅의 주제인 Image Super Resolution(이하 SR)은 저해상도(Low Resolution) 이미지를 고해상도 이미지(High Resolution) 이미지로 변환시키는 문제를 의미합니다. 이미지 SR은 크게 하나의 이미지를 이용하는지, 여러 이미지를 이용하는지에 따라 Single Image Super Resolution(이하, SISR), Multi Image Super Resolution(이하, MISR)로 나뉘는데 주로 SISR에 대한 연구가 주를 이루고 있습니다.
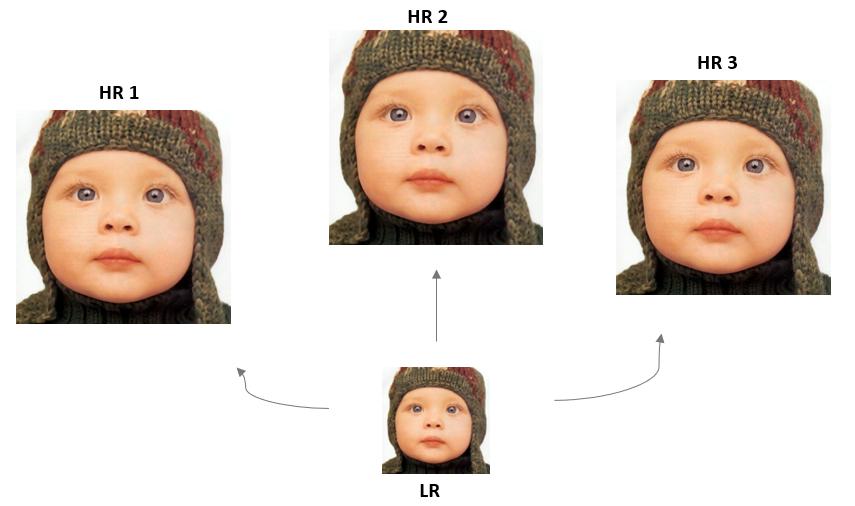
Super Resolution은 저해상도 이미지를 고해상도로 복원을 해야 하는데, 복원해야 하는 타겟인 고해상도의 이미지가 정답이 여러 개 존재할 수 있습니다. 정확히 말하면 유일한 정답이 존재하지 않는, 정의할 수 없는 문제를 의미합니다. 이러한 경우를 Regular Inverse Problem 혹은 Ill-Posed Problem이라 부릅니다.
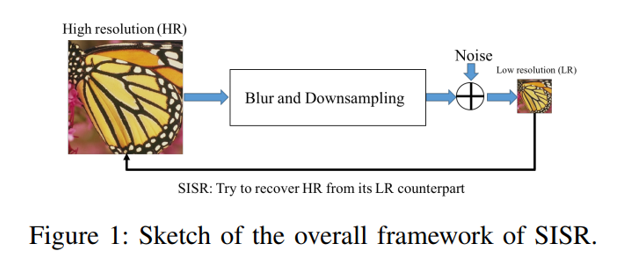
이러한 어려움을 타개하기 위해 대부분 위의 그림과 같은 framework를 따라서 연구를 수행하고 있습니다. 우선 고해상도의 타겟 이미지를 Ground Truth(GT)로 정의하고, 이를 Low Resolution image로 만들기 위해 blurring, down sampling, noise 주입 등을 거쳐 저해상도 이미지로 만듭니다. 그 뒤 모종의 방법을 통해 저해상도 이미지를 GT로 복원시키도록 모델을 학습시키는 구조를 따릅니다. 이러한 점이 Single Image Super Resolution의 근본적인 한계이며, 저해상도 이미지를 만들 때 사용한 distortion, down sapling 기법이 무엇이었는지에 따라 Super Resolution의 성능이 달라질 수 있습니다.
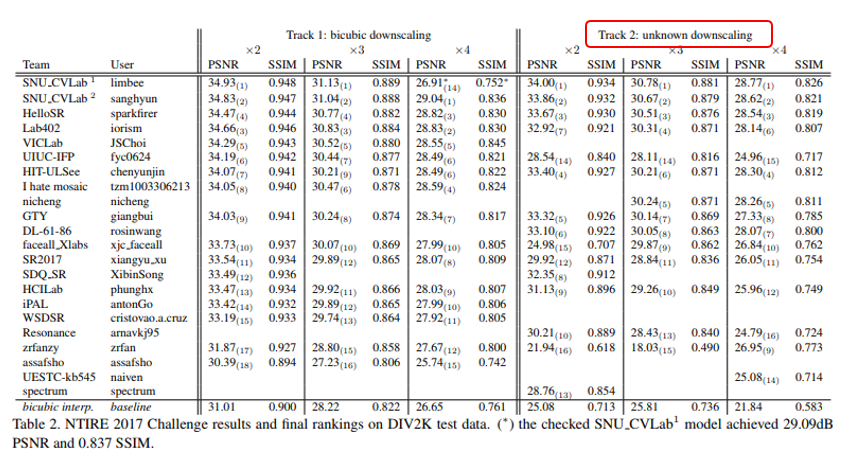
실제로 2017년 CVPR 워크샵에서 진행된 Image Restoration 챌린지인 NTIRE 2017에서는 일반적으로 사용하는 bicubic down sampling 데이터셋 외에, 방법을 알 수 없는 down sampling으로 만든 저해상도 데이터셋 2개에 track에 대해 모두 성능이 잘 나오도록 모델을 구성하는 것을 목표로 챌린지를 개최하기도 하였습니다. 위의 결과표를 자세히보면 track 1에서 우수한 성능을 냈던 모델임에도 불구하고 track 2에서는 거의 PSNR이 10 가량 떨어지는 모델도 존재하는 것을 알 수 있습니다.
일반적으로 논문 들에서는 bicubic down sampling한 데이터셋을 사용하고 있으며, 실생활에서 Super Resolution을 사용하고자 하는 경우에는 unknown down sampling도 고려를 해야 함을 알 수 있습니다.
Super Resolution의 적용 사례
최근에 예전 인기를 끌었던 드라마 하얀거탑(2007)의 리마스터 버전이 화제가 되었습니다. 과거의 TV들에서 사용하던 HD(1280 x 720) 해상도의 영상을 최신 TV에 맞게 UHD(3840 x 2160)으로 변환하여 더욱 선명한 화질로 감상을 할 수 있어서 많은 호평을 받았습니다. 이 때에도 딥러닝을 이용한 SR 기술이 사용되었으며(물론 하얀거탑의 경우 SR 뿐만 아니라 다양한 기법들이 적용이 되었습니다), TV 외에도 많은 분야에서 SR 기법이 적용되고 있습니다.
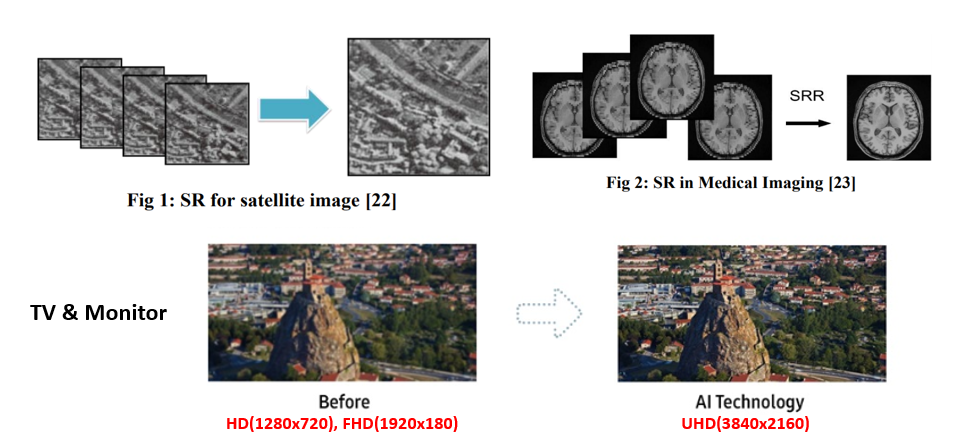
예를 들어, 우주에서 촬영한 이미지의 경우 초고해상도의 카메라로 촬영을 하여도 거리가 멀기 때문에 피사체의 크기가 작아서 분별이 어려운 문제가 있는데, 이 때에도 SR이 적용될 수 있습니다. 위의 그림은 해당 논문 에서 참조를 하였습니다. 이렇게 SR은 TV, 모니터 등 하드웨어의 발전과 함께 필요성과 중요성이 커지는 추세이며 딥러닝을 적용한 지는 아직 5년이 채 되지 않아 잠재력이 무궁무진한 분야라고 할 수 있습니다.
Super Resolution의 대표적인 접근 방법
일반적으로 SIngle Image Super Resolution 문제를 접근하는 방식은 크게 3가지가 존재합니다.
- Interpolation-based method
- Reconstruction-based method
- (Deep) Learning-based method
저희가 주로 사용하는 이미지 변환 라이브러리(OpenCV, PIL)을 통해 image resize 함수를 사용해보신 경험이 한번쯤은 있을 것입니다. 이러한 방식이 대표적인 Interpolation-based method 이며, interpolation 옵션을 다르게 사용하는 경우 이미지의 품질이 달라지는 것을 경험해보신 적이 있을 것입니다. Bicubic, Bilinear, Nearest Neighbor 등 다양한 interpolation 옵션이 있으며, 일반적으로 이미지의 해상도를 키워주는 경우에는 Bicubic, Bilinear, Lanczos interpolation을 사용합니다.

다만 이러한 방식을 사용해보신 분들은 다들 느끼셨겠지만 말 그대로 이미지를 크게 만들어줄 뿐, 디테일한 부분은 blur가 존재하거나 열화가 존재하는 것을 확인할 수 있습니다. 이를 해결하기 위해 Reconstruction-based method 와 Learning-based method가 나왔으며, 오늘 다루는 글에서는 Deep Learning-based method 를 중점적으로 소개드릴 예정입니다.
딥러닝을 이용한 Single Image Super Resolution
딥러닝이 연구자들에게 각광을 받게 된 시점은 다들 잘 아시는 ImageNet ISLVRC에서 우수한 성능을 거둔 AlexNet이 나온 2012년입니다. 이 시점 이후로 굉장히 다양한 분야에 딥러닝을 적용하고자 하는 시도가 나왔고 Super Resolution에도 자연스럽게 딥러닝이 적용이 되기 시작했습니다.
1. SRCNN, first deep learning based super resolution
딥러닝을 처음으로 Super Resolution에 적용한 논문인 “Image Super-Resolution Using Deep Convolutional Networks, 2014 ECCV” 은 SRCNN 이라는 이름으로 불리며, 2014년 ECCV에 공개된 논문입니다.
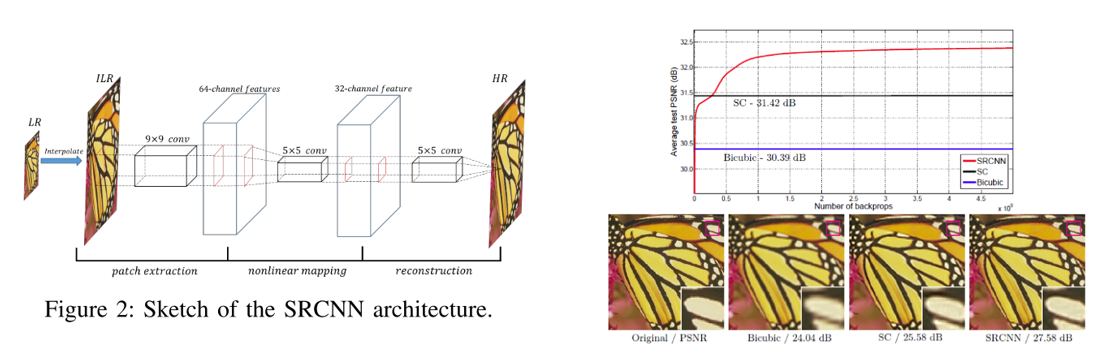
논문이 나온 시기가 시기인지라 요즘처럼 수백개의 layer를 쌓진 않았고 단 3개의 convolutional layer만 사용하였으며 딥러닝을 적용하지 않은 방법들에 비해 높은 성능 수치를 보이며 Super Resolution 분야에도 딥러닝을 적용할 수 있다는 가능성을 보인 논문입니다. 흥미로운 점은 architecture를 구성할 때, 각각 convolutional layer가 가지는 의미를 전통적인 Super Resolution 관점에서 해석하고 있으며 각각 layer가 patch extraction, nonlinear mapping, reconstruction을 담당하고 있다고 서술하고 있습니다.
2. Efficient single image super resolution
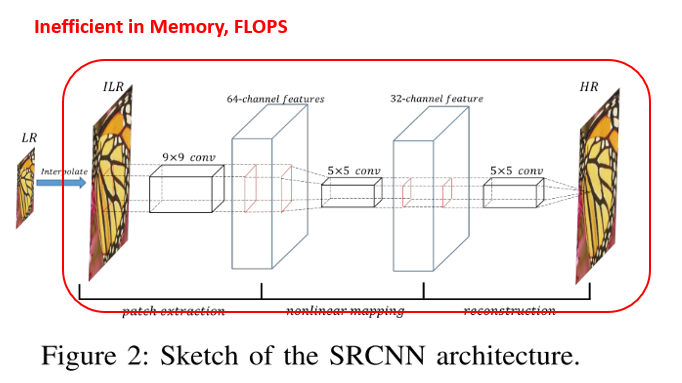
다음 소개드릴 두 논문은 위의 그림처럼 기존 SRCNN에서 input LR 이미지를 HR 이미지의 해상도로 interpolate시킨 뒤(Early Upsampling or Pre Upsampling이라 부릅니다.) convolution 연산을 하는 과정에서 비효율적인 연산이 발생하고 있음을 지적하며, 이를 개선하기 위한 방법들을 제안하고 있습니다.
2-1. FSRCNN
우선 “Accelerating the Super-Resolution Convolutional Neural Network, 2016 ECCV” 논문은 SRCNN의 저자가 낸 후속 논문이며 FSRCNN 이라는 모델 이름을 가지고 있습니다.
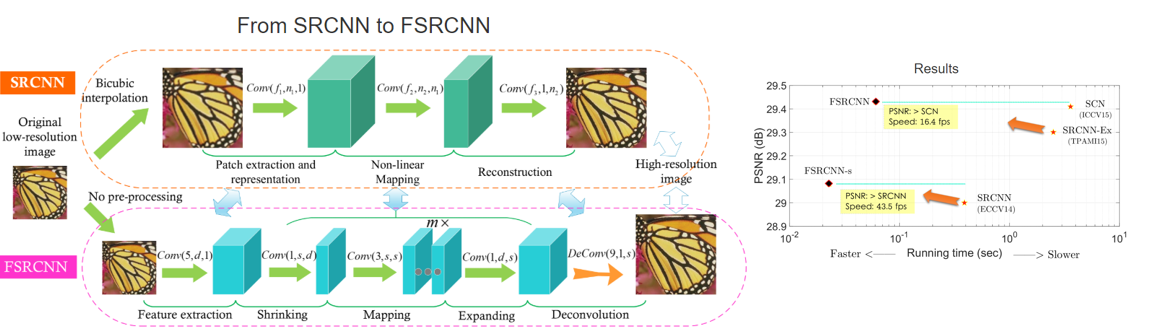
Input으로 들어가는 LR 이미지를 그대로 convolution layer에 집어넣는 방식을 사용하였고, 마지막에 feature map의 가로, 세로 크기를 키워주는 deconvolution 연산을 사용하여 HR 이미지로 만드는 것이 가장 큰 특징입니다. 이렇게 LR 이미지를 convolution 연산을 하게 되면 키워주고자 하는 배수에 제곱에 비례하여 연산량이 줄어들게 됩니다. 그 결과 SRCNN에 비해 굉장히 연산량이 줄어들었고 거의 실시간에 준하는 성능을 보일 수 있음을 강조하고 있습니다. 또한 연산량이 줄어든 만큼 convolution layer의 개수도 늘려주면서 정확도(PSNR)도 챙길 수 있음을 보여주고 있습니다.
2-2. ESPCN
다음 소개드릴 논문은 “Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network, 2016 CVPR” 이며 ESPCN 이라는 모델 이름을 가지고 있습니다. 마찬가지로 LR 이미지를 그대로 convolution layer에 집어넣지만 마지막에 feature map의 가로, 세로 크기를 키워주는 부분이 FSRCNN과 다릅니다. 이 논문에서는 sub-pixel convolutional layer 라는 구조를 제안하였으며, 이 연산은 pixel shuffle 혹은 depth to space 라는 이름으로도 불리는 연산입니다.
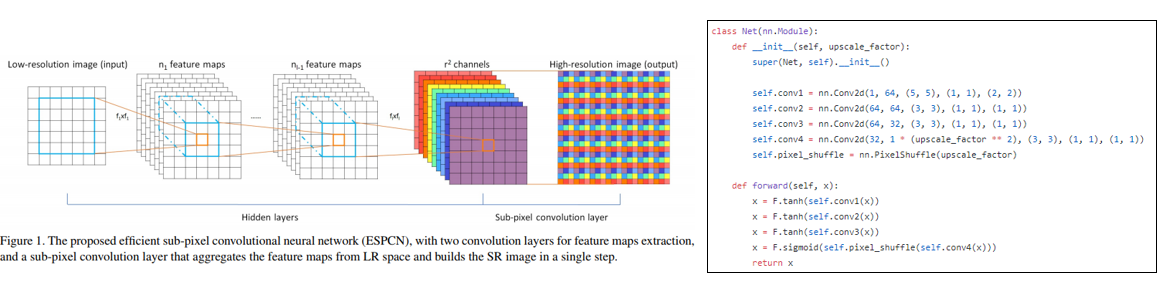
만약 r배의 up scaling을 하고자 하는 경우, Convolutional layer를 거친 뒤 마지막 layer에서 feature map의 개수를 r 제곱개로 만들어 준 뒤, 각 feature map의 값들을 위의 그림처럼 순서대로 배치하여 1 채널의 HR 이미지로 만들어 주게 됩니다. 이러한 방식을 통해 효율적인 연산이 가능하고, 하나의 layer를 통해 upscaling을 하는 대신, 여러 layer의 결과들을 종합하여 upscaling을 할 수 있어서 정확도 또한 좋아질 수 있습니다. 즉 ESPCN은 FSRCNN의 deconvolution layer 대비 여러 장점을 얻을 수 있으며, 이 때 사용된 sub-pixel convolutional layer는 추후 연구되는 Super Resolution 연구에 많은 영향을 주고 있습니다.
3. Deeper network for image super resolution
위에서 소개 드린 3개의 논문은 모두 딥러닝을 사용하긴 했지만, 저희가 알고 있는 지식인 “Convolution layer의 개수를 많이 쌓으면 정확도가 좋아진다” 의 방향과는 다소 다른 것을 알 수 있습니다. 이에 대해서 SRCNN 논문에서 convolutional layer를 깊게 쌓고 filter 개수도 늘려보는 실험을 하였지만 좋은 성능을 달성하지 못하면서 울며겨자먹기로 shallow한 구조를 채택하고 있습니다. 이러한 장벽을 부수고 deep한 구조를 제안한 논문이 2016년 공개가 되었는데, 이 논문에 대해서 간단히 설명 드리도록 하겠습니다.
3-1. VDSR
“Accurate Image Super-Resolution Using Very Deep Convolutional Networks, 2016 CVPR” 논문은 VDSR 이라는 이름으로 불리며 논문의 제목에서 알 수 있듯이 Very Deep한 ConvNet 구조를 사용하여 Super Resolution을 수행하였으며 Deep network를 사용함으로써 기존 방법들 대비 높은 정확도를 달성하게 됩니다.
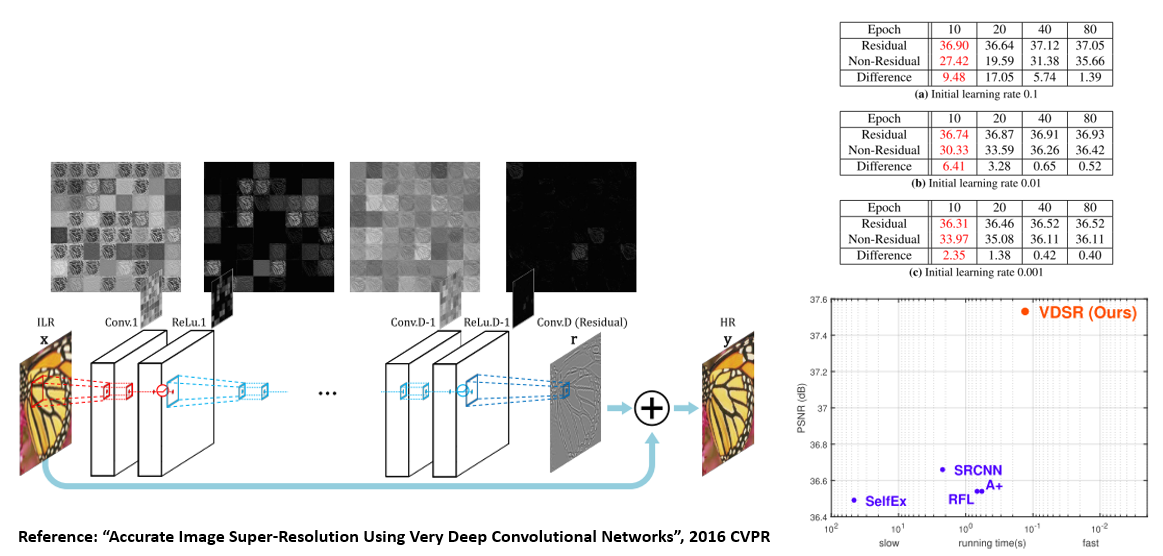
우선 VGG 기반의 20-layer convolutional network를 제안하였고, 원활한 학습을 위해 input image를 최종 output에 더해주는 방식인 residual learning 을 사용하였습니다. 또한 초기에 높은 learning rate를 사용하여 수렴이 잘 되도록 하기 위해 gradient clipping 도 같이 수행을 하고 있습니다. 이러한 방식들을 종합한 결과 deep network를 통해 기존 방법들 대비 정확도도 높일 수 있고, 학습 또한 잘 수렴할 수 있음을 보이고 있습니다. 이 논문 또한 추후 연구된 Super Resolution 논문들에 막대한 영향을 준 논문이라 할 수 있습니다.
3-2. After VDSR..
VDSR 이후 굉장히 다양한 Deep network 구조들이 제안이 되었으며, 하나하나 리뷰하기엔 글이 너무 길어질 것 같아서, 서베이 논문의 그림을 빌려 간단히 소개만 하고 넘어가고자 합니다.
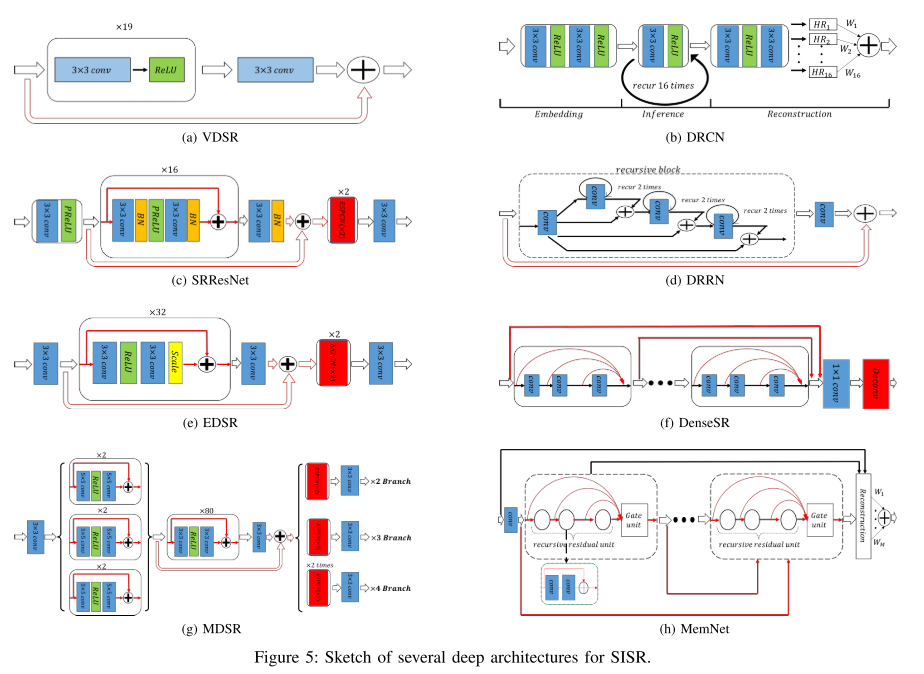
이미지 인식 분야에서 제안되었던 방법인 ResNet, DenseNet, 등에서 아이디어를 얻어서 Super Resolution에 적용하고 있으며, SRResNet 에서는 Batch Normalization을 사용하였으나 EDSR 에서는 오히려 Batch Normalization을 제외하는 것이 전반적인 성능에 도움이 된다는 결과를 보이고 있는 점이 흥미롭습니다. 위의 그림에 서술된 논문들은 다음과 같습니다.
- “DRCN, 2016 CVPR”
- “SRResNet, 2017 CVPR”
- “DRRN, 2017 CVPR”
- “EDSR, MDSR, 2017 CVPRW”
- “DenseSR, 2017 CVPR”
- “MemNet, 2017 CVPR”
4. Generative Adversarial Network(GAN) for Super Resolution
이번에는 딥러닝하면 이제는 가장 먼저 떠오르는 GAN! 을 Super Resolution에 접목한 논문을 소개드리고자 합니다.
4-1. SRGAN
“Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network”, 2017 CVPR” 이라는 논문이며 SRGAN 이라는 이름으로 잘 알려진 논문입니다.

이 논문에서 위에 소개드린 SRResNet 구조도 제안이 되었으며 기존 Super Resolution 들은 MSE loss를 사용하여 복원을 하다보니 PSNR 수치는 높지만 다소 blurry 한 output을 내고 있음을 지적하며, 사람 눈에 그럴싸하게 보이는 복원을 하기 위해 GAN을 접목시키는 방법을 제안하고 있습니다.
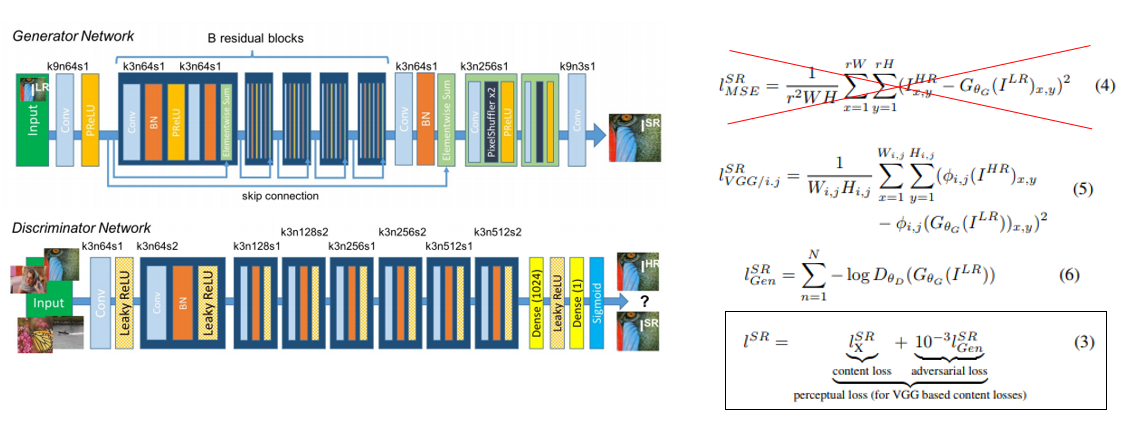
이미지를 복원하는 Generator network와, GT와 Generator의 output을 구분하는 Discriminator로 구성이 되어있으며 GAN loss 뿐만 아니라 기존 MSE loss 대신 style transfer에서 사용하는 VGG loss 도 같이 사용을 하여 Perceptual Loss 라는 loss를 제안하고 있습니다. 실험 결과에서는 PSNR 수치는 떨어지지만 사람 눈에 보기엔 보다 더 그럴싸한 결과를 낼 수 있음을 제시하고 있으며, 키워주고자 하는 배수가 커질수록 효과를 더 볼 수 있습니다. 실제로 SRGAN 논문에서는 4배수에 대해 실험을 수행하고 있습니다.
4-2. After SRGAN..
이번에도 GAN을 SR에 적용한 후속 논문들을 간단하게 소개드리고 넘어가겠습니다. 대표적으로 3개의 논문을 예시로 들 수 있으며, 각각 논문의 링크는 다음과 같습니다.
5. Summary
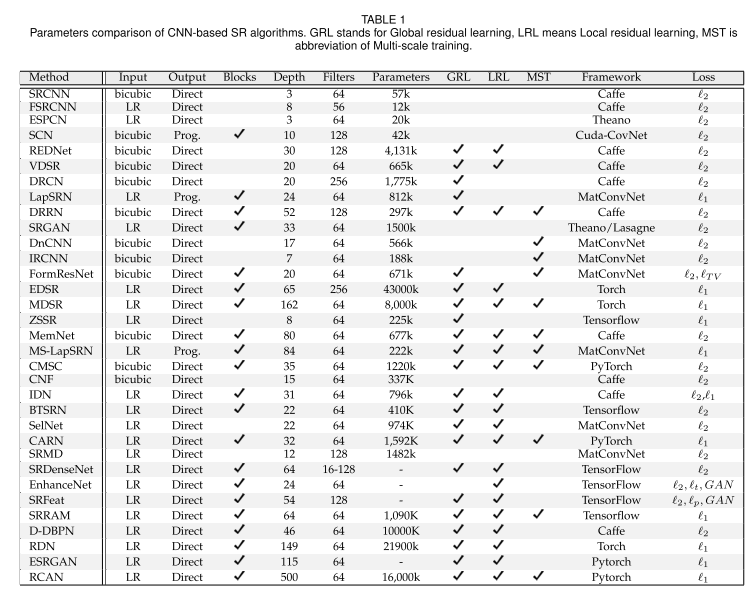
위에서 다양한 방법들을 소개드렸는데, 분량 관계로 다 소개드리지 못한 점 양해 부탁드리며, 서베이 논문에서 정리해 놓은 대표적인 벤치마크 데이터셋과 각 모델들의 성능을 한 눈에 볼 수 있게 모아둔 자료로 대신하고자 합니다.
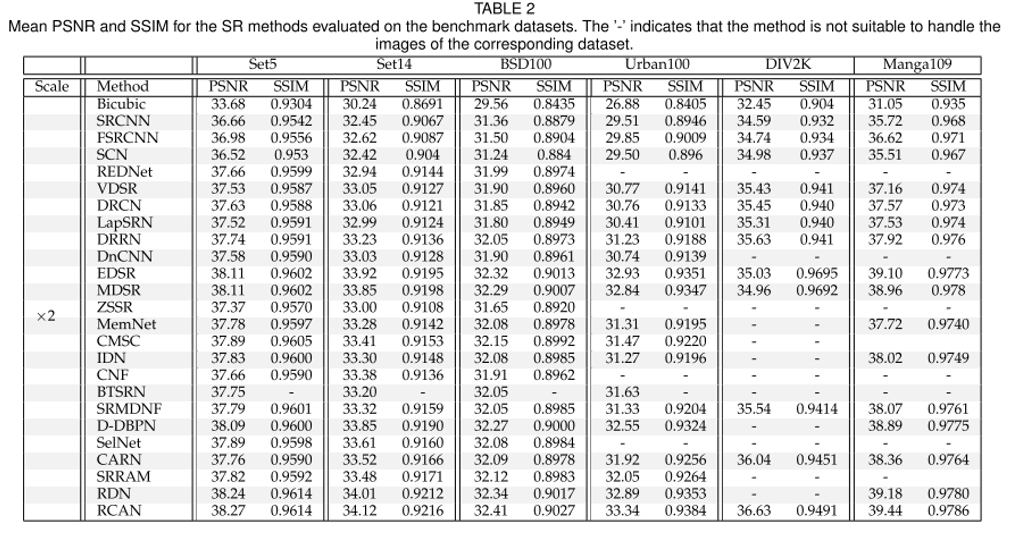
서베이 논문에 의하면 RCAN 이라는 논문이 대체로 성능 지표인 PSNR, SSIM 이 높은 것을 확인할 수 있으며 5년 사이에 초기 모델인 SRCNN 대비 꽤 많은 성능 향상이 있었음을 확인할 수 있습니다.
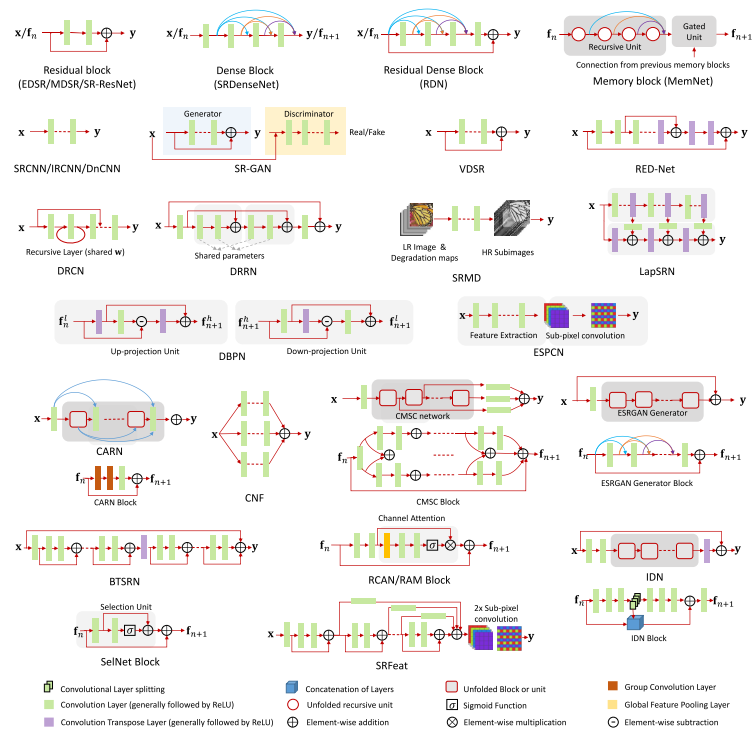
또한 각 모델들의 architecture 구조를 그림으로 나타낸 자료 또한 서베이 논문을 통해 확인할 수 있습니다.
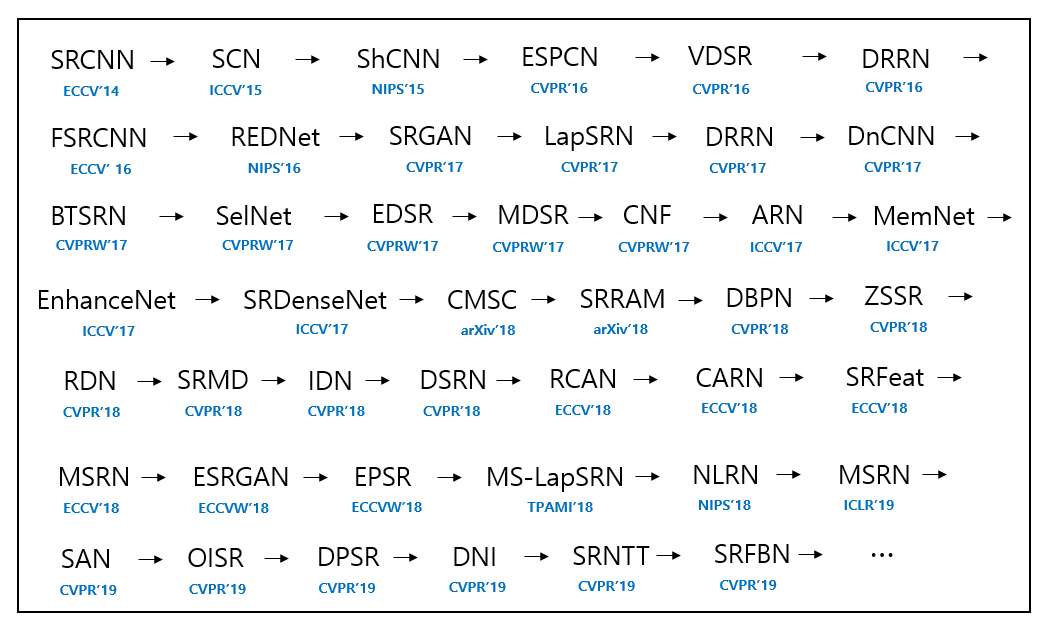
마지막으로는 위의 모델들을 시간 순서대로 한눈에 보기 편하게 정리한 그림을 소개드리고자 합니다. 불과 5년 사이에 굉장히 다양한 이름을 가진 모델들이 제안이 되었음을 확인할 수 있습니다.
Single Image Super Resolution의 주요 문제점 소개
마지막으로 다룰 내용은 현재 연구되고 있는 Single Image Super Resolution 들이 겪고 있는 주요 문제점들과 이를 태클링하고 있는 논문들을 간단히 소개드리겠습니다.
Checkerboard Artifact
우선 첫번째로 소개드릴 문제는 Checkerboard artifact 이며, 생성된, 혹은 복원된 이미지에 체커보드와 같이 생긴 열화가 발생하는 문제입니다.
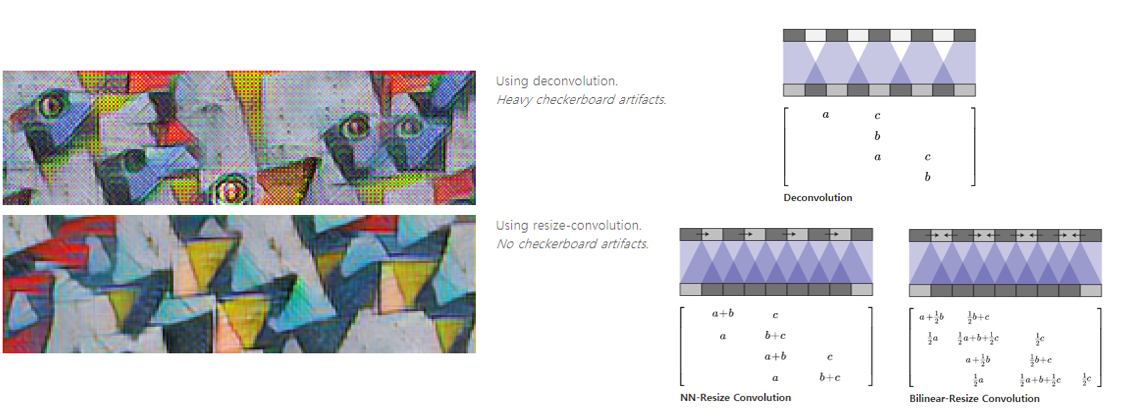
위의 그림은 distill의 블로그 에서 인용한 자료이며 deconvolution 연산을 사용할 때 filter size와 stride에 따라 uneven overlap이 발생할 수 있으며, 이로 인해 checkerboard artifact가 발생할 수 있음을 보이고 있습니다.
이를 개선하기 위해 deconvolution 연산 대신 “Interpolation 기반 resize + convolution 연산” 의 조합을 사용할 수 있고, ESPCN에서 제안한 Sub-pixel convolutional layer 도 checkerboard artifact를 줄이는데 도움이 될 수 있습니다.
Loss function
다음 다룰 문제는 loss function입니다. 초기 연구들은 다 MSE loss를 loss function으로 사용하였는데, 이러한 loss는 단순히 MSE를 최소화하는 방향으로만 학습이 되기 때문에 detail한 정보들을 잘 복원하지 못하는 것이 문제로 여겨졌습니다.
이러한 점을 지적하며 여러 loss function 들을 image restoration 문제에서 실험한 논문인 “Loss Functions for Image Restoration with Neural Networks, 2016 IEEE TCI” 에서는 l1 loss와 SSIM loss 등을 적용하는 방법을 제안하였고, 최종적으론 l1 loss와 MS-SSIM loss를 적절히 섞어서 사용할 때 성능이 가장 좋았다고 제시하고 있습니다.
위의 논문 외에도 SRGAN 등에서 perceptual loss 등을 제안하기도 하였고, 최신 논문 들에서는 MSE loss를 사용하기도 하지만 l1 loss를 더 많이 사용하고 있음을 확인할 수 있습니다.
Performance Metric
마지막으로 다룰 문제는 성능 지표입니다. 영상의 화질을 복원하는 문제이다보니, 얼만큼 잘 복원했는지를 정량화하기가 어려운 것이 문제인데요, 대부분의 논문에서는 성능 지표로 Distortion measure인 PSNR 과 SSIM 이라는 지표를 사용하고 있습니다.
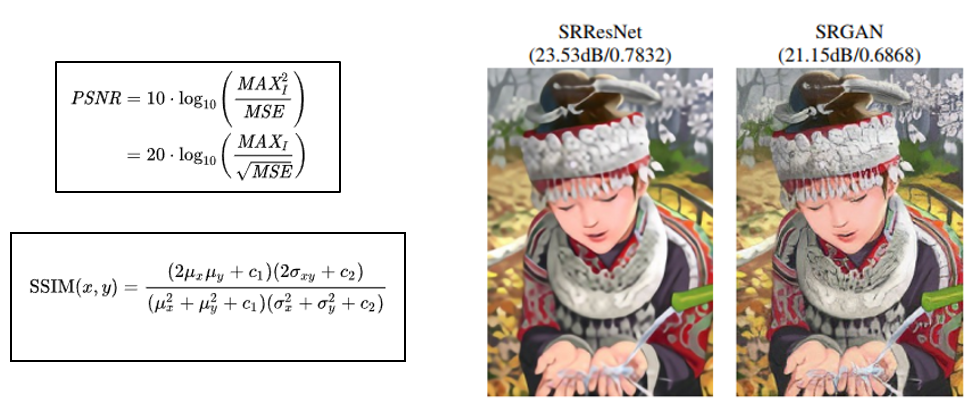
다만 PSNR, SSIM이 높다고 해서 사람 눈에 보기 좋은 것은 아닙니다. SRGAN 논문에서 제시하고 있는 결과 그림을 보면 SRGAN의 결과가 SRResNet에 비해 PSNR, SSIM 수치는 낮지만 결과 이미지 자체는 더 디테일한 영역을 잘 복원하고 있는 것을 확인할 수 있습니다.
이렇게 distortion measure 만으로 복원 결과를 판단하기엔 부족한 점이 있어서 SRGAN 논문에서는 MOS(Mean Opinion Score) 라는 지표도 사용하여 결과를 제시하고 있습니다.
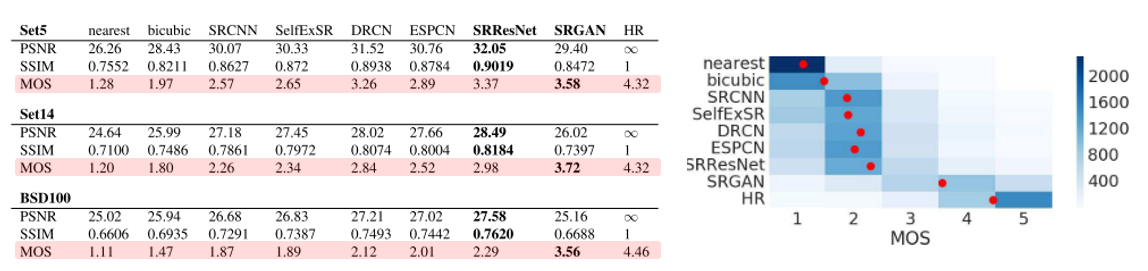
SRGAN과 같이 GAN 기반의 방법들은 distortion measure에서는 낮은 성능을 보이지만, 사람의 주관적 만족도를 반영하는 지표들에서는 기존 SR 방식들에 비해 좋은 성능을 보일 수 있음을 알 수 있습니다.
이렇게 Distortion measure와 사람이 느끼는 measure인 Perceptual measure를 분석한 논문인 “The Perception-Distortion Tradeoff, 2018 CVPR” 이 2018년 CVPR에 발표되었고, CVPR에서 개최되는 Super Resolution 챌린지에는 이 두가지 지표를 모두 반영한 지표로 성능 평가를 하고 있습니다.
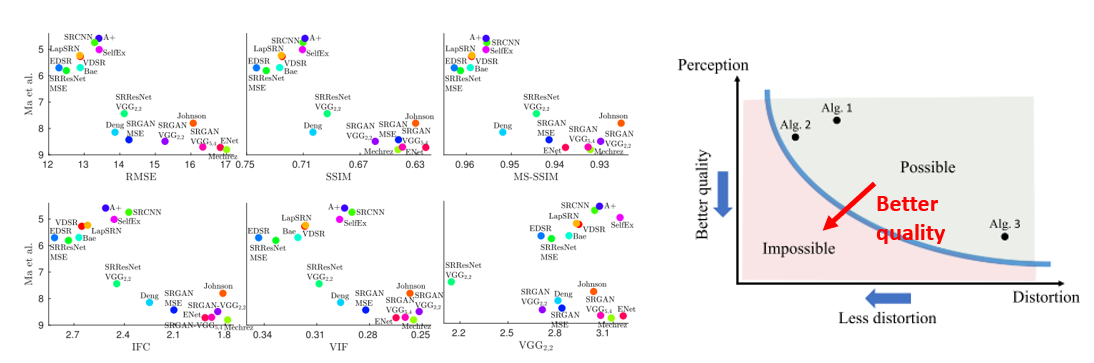
Distortion measure가 좋아지는 방향과, Perception measure가 좋아지는 방향이 서로 반대인 Trade-off 관계를 가지고 있음을 보이며, 두가지 지표를 동시에 좋아지게 하는 방향으로 연구를 수행하는 것이 좋은 성능을 내는 길임을 보여주고 있는 논문입니다. 이 논문에 대한 좋은 리뷰 자료가 존재하여 소개 드리며 글을 마무리 지으려 합니다.
결론
이번 포스팅에서는 영상 처리에서 주로 다뤄지는 문제인 Image Super Resolution 에 대해 간단히 소개를 드리고, 딥러닝을 적용하는 방법들에 대해 소개를 드렸습니다. 사실 간단하게 소개드린다고 하였는데 분량이 굉장히 길어졌습니다.. Super Resolution 자체는 오래 전부터 연구가 되어왔던 분야이지만 딥러닝이 적용된 지는 이제 막 5년이 지났음에도 불구하고 굉장히 많은 성장을 해온 분야라고 생각이 되며, 실생활에서도 유용하게 쓰일 수 있는 기술인 만큼 지금보다 더 성장하기를 기대하며 글을 마무리짓도록 하겠습니다. 공부하시는데 도움이 되셨으면 좋겠습니다. 감사합니다.
Reference
- “Image Super-Resolution Using Deep Convolutional Networks”, 2014 ECCV
- “Super Resolution Applications in Modern Digital Image Processing”, 2016 IJCA
- “Loss Functions for Image Restoration with Neural Networks”, 2016 IEEE TCI
- “Deconvolution and Checkerboard Artifacts”, distill blog(https://distill.pub/2016/deconv-checkerboard/)
- “Accurate Image Super-Resolution Using Very Deep Convolutional Networks”, 2016 CVPR
- “Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network”, 2016 CVPR
- “Accelerating the Super-Resolution Convolutional Neural Network”, 2016 ECCV
- “Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network”, 2017 CVPR
- http://www.vision.ee.ethz.ch/~timofter/publications/NTIRE2017SRchallenge_factsheets.pdf
- “The Perception-Distortion Tradeoff”, 2018 CVPR
- “Deep Learning for Single Image Super-Resolution: A Brief Review”, 2018 IEEE Transactions on Multimedia (TMM)
- “A Deep Journey into Super-resolution: A survey”, 2019 arXiv