Semantic Segmentation PyTorch Tutorial & ECCV 2020 VIPriors Challenge 참가 후기 정리
안녕하세요, 오늘 포스팅에서는 PyTorch로 작성한 Semantic Segmentation Tutorial 코드에 대해 설명드리고, 이 코드 베이스로 ECCV 2020 VIPriors 챌린지에 참가한 후기를 간단히 정리해볼 예정입니다.
제가 작성한 Tutorial 코드는 제 GitHub Repository 에서 확인하실 수 있습니다. 도움이 되셨다면 Star 하나씩 눌러주세요! ㅎㅎ
ECCV 2020 VIPriors Workshop & Challenge
Semantic Segmentation은 제 블로그에서는 잘 다루지 않았던 주제였습니다. 저 개인적으로는 회사 업무를 통해 다뤄본 경험이 많았습니다. 다만, 제조업 데이터의 결함을 segmentation 하는 것만 다뤄보고, 주로 사용되는 자연계 이미지인 Cityscapes, BSDS500 등은 다뤄본 경험이 없었는데, 마침 ECCV 2020에 VIPriors 워크샵에 챌린지가 열렸고 4가지 task 중 Semantic Segmentation이 있어서 공부할 겸 참가하게 되었습니다.
우선 제가 참가한 VIPriors Challenge 에 대해서 소개를 드리자면, 각 task 마다 잘 알려진 public 데이터셋을 주는데, 대신 데이터의 개수를 굉장히 적게 제공합니다. 또한 주어진 데이터 외에 외부 데이터를 사용할 수 없습니다. 즉, pretrained model 등도 사용하지 못하고 scratch로 부터 학습을 시켜야 겠죠? 이러한 조건에서 높은 성능을 달성하는 것을 목표로 합니다.
데이터가 적은 환경에서 사람이 데이터의 특징을 반영한 Inductive Prior Knowledge를 이용하는 것이 이 챌린지의 핵심이라고할 수있습니다.
저는 Image Classification, Object Detection, Semantic Segmentation, Action Recognition 중 Semantic Segmentation 과 Action Recognition에 참가를 하였는데 오늘 글에서는 Semantic Segmentation 문제 위주로 설명을 드릴 예정입니다.
VIPriors Semantic Segmentation Challenge
Segmentation Challenge는 자동차에서 취득한 주행 이미지인 Cityscapes에서 일부의 이미지만을 가져온 MiniCity 데이터셋을 학습 데이터로 제공하고 있습니다.
원래 Cityscape 데이터셋은 Training Set 2975장, Validation Set 500장, Test Set 1525장으로 총 5000장의 데이터를 제공하는 반면, MiniCity 데이터셋은 Training Set 200장, Validation Set 100장, Test Set 200장을 제공합니다. 굉장히 적은 수의 데이터를 제공하고, 저희가 주로 사용하는 ImageNet Pretrained Backbone도 사용할 수 없어 높은 성능을 달성하기 쉽지 않아보였습니다.

우선 데이터셋은 총 19가지의 class로 구성이 되어있으며 class의 종류는 위에서 확인할 수 있습니다. 위의 그림은 ACFNet 논문의 결과 그림에서 인용하였습니다.
위의 그림은 제공받은 200장의 Training Set의 19가지 Class의 Pixel Distribution을 시각화한 그림입니다. 보시면 아시겠지만 Class-Imbalance (클래스 불균형)이 굉장히 심한 데이터셋입니다.
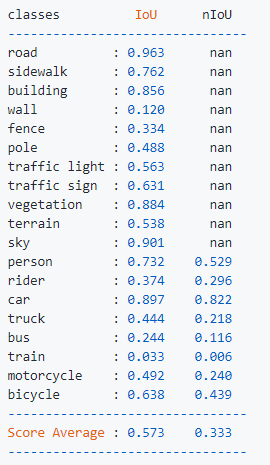
Test Metric이 mIoU 인데 이 Metric은 19가지의 class들의 IoU를 평균내어 계산을 하기 때문에, Class-Imbalance가 심한, 즉 Minor한 Class의 IoU 값이 굉장히 낮게 측정이 됩니다. 그래서 Test Metric인 mIoU에서도 손해를 보게 됩니다. 즉, 저는 이번 챌린지에서 가장 중요하게 다뤄야할 부분을 이 Class-Imbalance 라고 생각을 했습니다.
Semantic Segmentation Tutorial using PyTorch
저는 일단 주최측에서 제공해준 VIPriors Challenge Starter Code 를 바탕으로 출발을 하였으며 필요한 함수들을 가져오고 구현하여 사용하였습니다.
이제 주최측이 제공해준 코드를 바탕으로 제가 재구성한 코드에 대해 간략히 소개드리겠습니다.
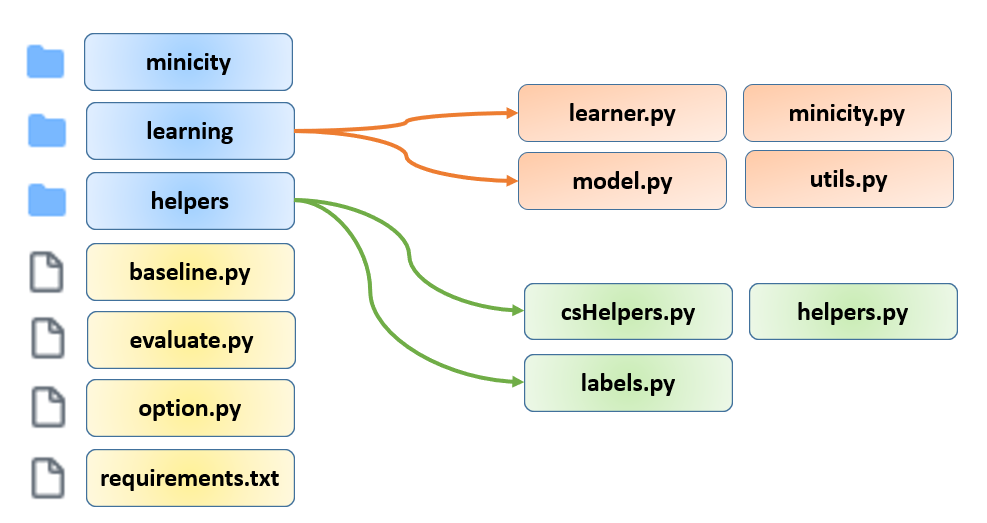
우선 제 GitHub Repository 에서 코드를 다운받으시면 다음과 같이 구성이 되어있을 것입니다.
우선 minicity 폴더에는 저희가 사용할 데이터셋이 들어갈 예정이며, 파일 용량이 커서 github repository 상에는 올려두지 않았고 제 구글 드라이브에 올려두었습니다. 혹시 MiniCity 데이터셋으로 코드를 돌려보고 싶으신 분들은 구글 드라이브 링크 를 클릭하셔서 다운 받으신 뒤 압축을 풀어서 minicity 폴더에 넣어주시면 됩니다.
learning 폴더에는 학습에 관여하는 파이썬 코드들이 존재하며, 총 4개의 파일로 구성이 되어있습니다.
- Training, Validation, Test와 관련이 있는 learner.py
- Dataset과 Dataloader와 관련이 있는 minicity.py
- Model Architecture와 관련이 있는 model.py
- 각종 utility 함수들을 구현해둔 utils.py
helpers 폴더에는 주로 evaluation과 관련이 있는 함수들이 들어가 있으며, 주최측이 제공해준 코드를 그대로 사용하였습니다. 모든 코드를 다 설명드리면 글이 너무 길어질 것 같아서 가장 중요한 main 역할을 하는 baseline.py 코드만 설명을 드리도록 하겠습니다.
baseline.py (main)
baseline.py 가 main 역할을 하며 option.py에서 argument들을 불러온 뒤 모델을 구성하고 데이터로더를 구성하고 학습 파라미터들을 설정한 뒤, training loop를 돌리는 일을 합니다. 또한 지난 “Reproducible PyTorch를 위한 randomness 올바르게 제어하기!” 포스팅에서 randomness를 제어하는 과정을 설명드렸는데, args.seed 를 통해 random seed를 부여하는 경우 reproducible하게 학습을 시킬 수 있습니다. 다만 학습이 느려질 수 있습니다.
# Resume training from checkpoint
if args.weights:
print('Resuming training from {}.'.format(args.weights))
checkpoint = torch.load(args.weights)
model.load_state_dict(checkpoint['model_state_dict'], strict=True)
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
metrics = checkpoint['metrics']
best_miou = checkpoint['best_miou']
start_epoch = checkpoint['epoch']+1
또한 학습이 중간에 중단된 경우 args.weights 옵션을 통해 저장된 checkpoint의 state dict를 불러와서 학습을 재개할 수 있습니다.
# No training, only running prediction on test set
if args.predict:
checkpoint = torch.load(args.save_path + '/best_weights.pth.tar')
model.load_state_dict(checkpoint['model_state_dict'], strict=True)
print('Loaded model weights from {}'.format(args.save_path + '/best_weights.pth.tar'))
# Create results directory
if not os.path.isdir(args.save_path + '/results_val'):
os.makedirs(args.save_path + '/results_val')
if not os.path.isdir(args.save_path + '/results_test'):
os.makedirs(args.save_path + '/results_test')
predict(dataloaders['test'], model, Dataset.mask_colors, folder=args.save_path, mode='test', args=args)
predict(dataloaders['val'], model, Dataset.mask_colors, folder=args.save_path, mode='val', args=args)
return
학습이 끝나고 저장된 모델을 불러오고 싶으신 경우, args.predict 옵션을 통해 저장된 best model의 checkpoint의 state dict를 불러와서 validation set과 test set의 결과를 뽑을 수 있습니다.
for epoch in range(start_epoch, args.epochs):
# Train
print('--- Training ---')
train_loss, train_acc = train_epoch(dataloaders['train'], model, criterion, optimizer, scheduler, epoch, void=Dataset.voidClass, args=args)
metrics['train_loss'].append(train_loss)
metrics['train_acc'].append(train_acc)
print('Epoch {} train loss: {:.4f}, acc: {:.4f}'.format(epoch,train_loss,train_acc))
# Validate
print('--- Validation ---')
val_acc, val_loss, miou = validate_epoch(dataloaders['val'], model, criterion, epoch,
Dataset.classLabels, Dataset.validClasses, void=Dataset.voidClass,
maskColors=Dataset.mask_colors, folder=args.save_path, args=args)
metrics['val_acc'].append(val_acc)
metrics['val_loss'].append(val_loss)
metrics['miou'].append(miou)
# Write logs
with open(args.save_path + '/log_epoch.csv', 'a') as epoch_log:
epoch_log.write('{}, {:.5f}, {:.5f}, {:.5f}, {:.5f}, {:.5f}\n'.format(
epoch, train_loss, val_loss, train_acc, val_acc, miou))
# Save checkpoint
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'best_miou': best_miou,
'metrics': metrics,
}, args.save_path + '/checkpoint.pth.tar')
# Save best model to file
if miou > best_miou:
print('mIoU improved from {:.4f} to {:.4f}.'.format(best_miou, miou))
best_miou = miou
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
}, args.save_path + '/best_weights.pth.tar')
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
plot_learning_curves(metrics, args)
Training Loop는 위의 코드와 같이 구현하였으며, 매 epoch 마다 training과 validation을 수행한 뒤, validation metric으로 miou를 사용하였는데, validation metric이 기존의 best 값보다 높은 값이 나온 경우 best 값을 갱신하고 그 epoch의 모델을 checkpoint로 저장하였습니다.
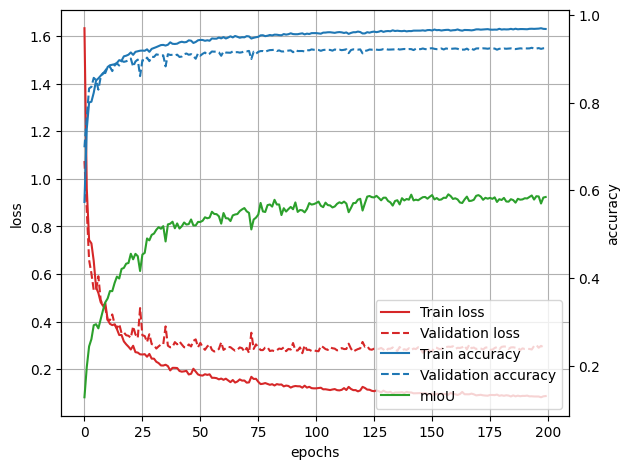
학습 전체 과정은 log_epoch.csv 파일에 저장이 되고, learning curve는 learning_curve.png 파일로 저장을 하였습니다.
Tutorial 코드 돌려보기!
코드에 대한 설명은 여기까지 하고, 이제 이 코드들을 어떻게 돌릴 수 있는지 설명드리겠습니다. 우선 제가 실험했던 것들은 다음과 같으며, 모든 실험들은 다 똑같이 돌려보실 수 있습니다.
- Model
- DeepLab V3 with ResNet-50, ResNet-101
- Loss Function
- Cross-Entropy Loss
- Class-Weighted Cross-Entropy Loss
- Focal Loss
- Normalization Layer
- Batch Normalization (BN)
- Instance Normalization (IN)
- Group Normalization (GN)
- Evolving Normalization (EvoNorm)
- Augmentation
- CutMix
- CopyBlob
- Multi-Scale Inference (Test Time Augmentation)
1. Training Baseline Model
우선 코드를 돌리기에 앞서, Segmentation Task의 특성 상 GPU Memory를 많이 잡아먹기 때문에 원활한 학습을 위해선 4개 이상의 GPU가 필요합니다. 저는 RTX 2080 Ti 4개를 사용하였는데도 Batch Size를 8까지밖에 키우지 못했습니다. ㅠㅠ. 만약 Single GPU로 돌려보고 싶으시다면 Batch Size를 아마도 1이나 2로 낮춰서 실험을 하셔야 할 것 같습니다.
우선 저는 Torchvision의 DeepLab V3을 그대로 가져와서 사용하였고, 당연히 pretrained 옵션은 False로 사용하였습니다. 또한 GPU Memory의 한계로 ResNet-50 Backbone을 사용하였을 때에는 training input size는 1024x2048을 사용하고 crop size를 576x1152로 사용하였지만, ResNet-101 Backbone을 사용하였을 때에는 training input size를 절반으로 줄인 512x1024에 crop size를 384x768로 하여 실험을 수행하였습니다.
ResNet-50 Backbone을 이용한 Baseline 모델은 다음과 같은 커맨드라인으로 돌릴 수 있습니다.
python baseline.py --save_path baseline_run_deeplabv3_resnet50 --crop_size 576 1152 --batch_size 8;
ResNet-101 Backbone을 이용한 Baseline 모델은 다음과 같은 커맨드라인으로 돌릴 수 있습니다.
python baseline.py --save_path baseline_run_deeplabv3_resnet101 --model DeepLabv3_resnet101 --train_size 512 1024 --test_size 512 1024 --crop_size 384 768 --batch_size 8;
2. Loss Functions
저는 3가지의 Loss Functions을 실험하였습니다. 결론 먼저 말씀 드리면 default로 사용한 Cross Entropy가 가장 성능이 좋았습니다. 만약 Loss Function을 바꿔서 돌려보고 싶으신 분들은 다음과 같은 커맨드라인으로 돌려보실 수 있습니다.
# Cross Entropy Loss
python baseline.py --save_path baseline_run_deeplabv3_resnet50 --crop_size 576 1152 --batch_size 8;
# Weighted Cross Entropy Loss
python baseline.py --save_path baseline_run_deeplabv3_resnet50_wce --crop_size 576 1152 --batch_size 8 --loss weighted_ce;
# Focal Loss
python baseline.py --save_path baseline_run_deeplabv3_resnet50_focal --crop_size 576 1152 --batch_size 8 --loss focal --focal_gamma 2.0;
3. Normalization Layers
4가지의 Normalization Layer를 실험하였고, 마찬가지로 default로 사용한 Batch Normalization이 가장 성능이 좋았습니다. Batch Size가 작을 때 좋은 성능을 보인다고 알려진 Group Normalization, Evolving Normalization 등이 잘 동작하지 않은 점이 특징입니다. Normalization Layer를 바꿔서 돌려보고 싶으신 분들은 다음과 같은 커맨드라인으로 돌려보실 수 있습니다.
# Batch Normalization
python baseline.py --save_path baseline_run_deeplabv3_resnet50 --crop_size 576 1152 --batch_size 8;
# Instance Normalization
python baseline.py --save_path baseline_run_deeplabv3_resnet50_instancenorm --crop_size 576 1152 --batch_size 8 --norm instance;
# Group Normalization
python baseline.py --save_path baseline_run_deeplabv3_resnet50_groupnorm --crop_size 576 1152 --batch_size 8 --norm group;
# Evolving Normalization
python baseline.py --save_path baseline_run_deeplabv3_resnet50_evonorm --crop_size 576 1152 --batch_size 8 --norm evo;
4. Additional Augmentation Tricks
또한 이번 챌린지를 위해서 2가지의 Augmentation을 제가 고안하여 적용을 해봤습니다. 우선 Classification 에서 좋은 성능을 보여주는 CutMix Augmentation을 Semantic Segmentation에 맞게 약간 변형시켜서 적용을 해보았고, 데이터셋의 특징을 반영한 Prior를 주기 위해 Copy Blob이라는 Augmentation도 적용을 해보았습니다.
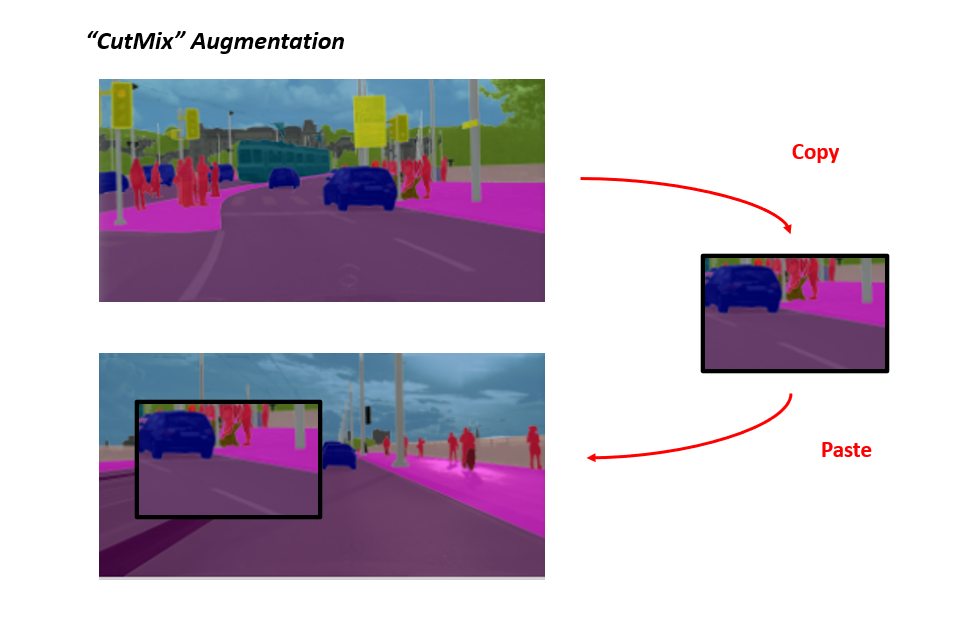
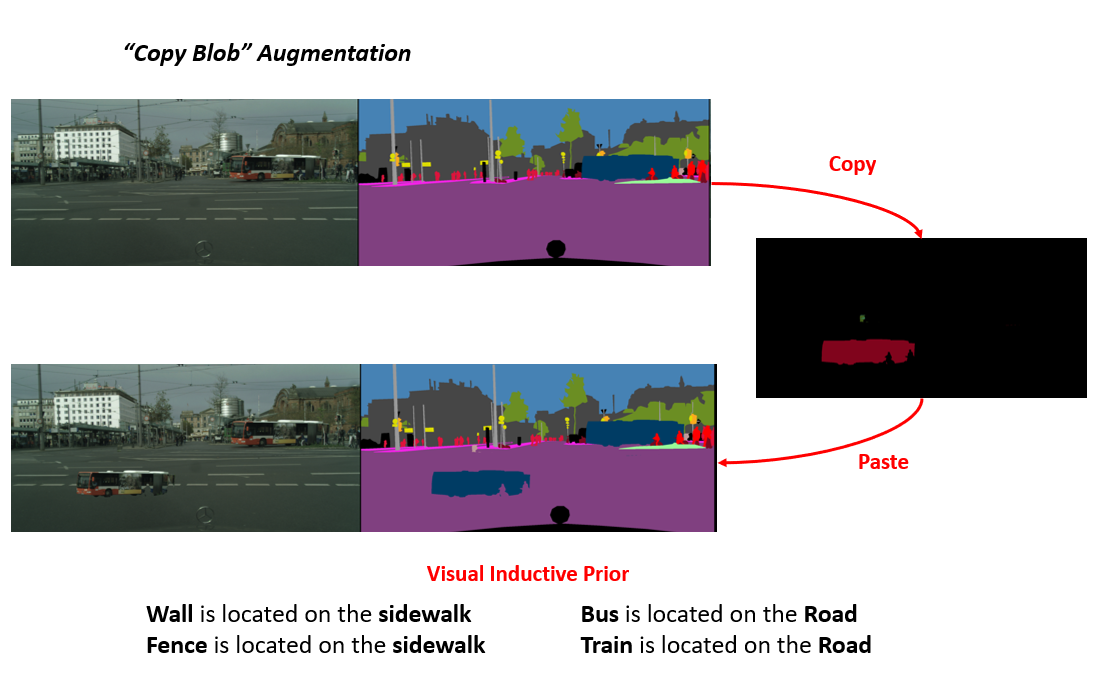
Copy Blob은 Minor한 Class의 성능을 높이기 위해 고안하였으며, Wall, Fence, Bus, Train 4개의 Class에 적용을 하였습니다. Wall과 Fence는 인도 위에 존재하고, Bus와 Train은 도로 위에 존재한다는 Prior knowledge를 이용하여 한 이미지에서 해당 class의 blob을 검출한 뒤 다른 이미지에 붙여넣는 방식을 이용하였으며 합성 예시는 위의 그림에서 확인하실 수 있습니다.
두 방법 모두 적용하였을 때 소폭의 성능 향상이 있었으며, 실험해보고 싶으신 분들은 다음과 같은 커맨드라인으로 돌려보실 수 있습니다.
# CutMix Augmentation
python baseline.py --save_path baseline_run_deeplabv3_resnet50_cutmix --crop_size 576 1152 --batch_size 8 --cutmix;
# CopyBlob Augmentation
python baseline.py --save_path baseline_run_deeplabv3_resnet50_copyblob --crop_size 576 1152 --batch_size 8 --copyblob;
5. Multi-Scale Inference
마지막으로, Inference를 할 때 Multi-Scale로 Inference를 한 뒤 결과를 평균내는 Test Time Augmentation도 적용을 해보았으며, 이 방법을 적용하였을 때도 꽤 유의미한 성능 향상이 있었습니다. Multi-Scale Inference를 적용하고 싶으신 분들은 다음과 같은 커맨드라인으로 돌려보실 수 있습니다. 이 때 유의하실 점은 Batch size를 무조건 1로 고정해야 합니다!
# Single-Scale Inference
python baseline.py --save_path baseline_run_deeplabv3_resnet50 --batch_size 4 --predict;
# Multi-Scale Inference
python baseline.py --save_path baseline_run_deeplabv3_resnet50 --batch_size 1 --predict --mst;
참석 후기 및 아쉬웠던 점
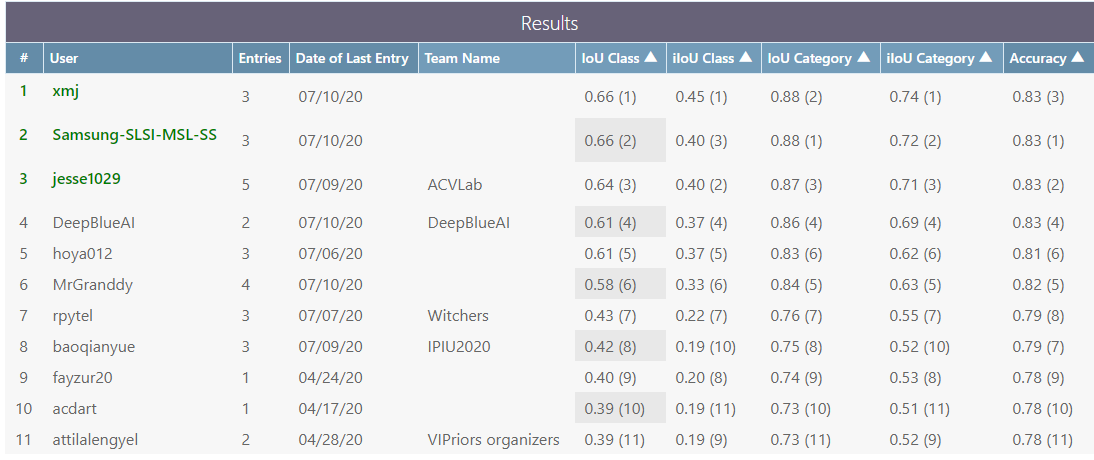
위의 그림은 VIPriors Semantic Segmentation 챌린지의 최종 리더보드이며 저는 5위의 성적을 거두었습니다. 다만, 참가자들은 모두 4페이지 분량의 tech report를 제출하여야 하는데 깜빡하여 제출 일자를 놓쳐서 제 점수가 공식 기록으로 인정 받지는 못했습니다. (ㅠㅠ) 그래도 주최측에서 제공해준 코드의 성능인 0.39 보다는 0.22 높은 값을 달성하였고 나쁘지 않은 성능을 얻은 점이 만족스러웠지만 아쉬웠던 점도 많았던 것 같습니다. 제가 생각한 아쉬웠던 점은 다음과 같습니다.
- GPU memory의 한계로 더 큰 Batch Size를 실험하지 못한 점
- GPU memory의 Input Resolution을 절반으로 줄여서 실험한 점(ResNet-101 Backbone)
- GPU memory의 한계로 더 큰 segmentation network 들을 실험하지 못한 점 (현 시점 SOTA인 HRNet, EfficientPS 등을 돌려보고 싶었지만..)
- 챌린지의 취지에 부합하는 시도를 1가지 (CopyBlob) 밖에 떠올리지 못한 점
- 모델 앙상블을 하지 않은 점
아쉬웠던 점이 많았던 만큼 다음에 비슷한 기회가 있다면 더 잘 준비해서 도전을 해봐야 겠다고 생각이 들었습니다. 또한 오늘 글에서는 대체로 잘 된 시도들만 정리를 하였고, 대부분의 실패했던 시도들은 설명을 안드렸는데, 많은 실패를 통해서 경험치를 많이 쌓은 것 같아서 만족스러웠습니다. 챌린지의 취지가 재미있고 공부하기에 적합한 것 같아서 Segmentation 뿐만 아니라 다른 task에 관심 있으신 분들은 공부용으로 사용하셔도 좋을 것 같네요! 읽어주셔서 감사합니다!