Deep Learning Image Classification Guidebook [2] PreActResNet, Inception-v2, Inception-v3, Inception-v4, Inception-ResNet, Stochastic Depth ResNet, WRN
안녕하세요, 지난 Deep Learning Image Classification Guidebook [1] 에 이어서 오늘은 2016년 공개된 주요 CNN architecture들에 대한 설명을 드릴 예정입니다. 오늘 다룰 architecture들은 다음과 같습니다.
- PreActResNet
- Inception-v2
- Inception-v3
- Inception-v4
- Inception-ResNet
- Stochastic Depth ResNet
- WRN
2016년 제안된 CNN architecture 소개
우선 시작하기 앞서, 지난 글에서 2015년까지 발표된 architecture들을 다뤘었고, 글 말미에 ResNet에 대한 설명을 드렸습니다. 오늘 다룰 2016년은 가히 ResNet 전성시대라 부를 수 있을 것 같습니다. 대다수의 논문이 ResNet을 기반으로 연구를 수행하였는데요, 어떠한 방식으로 변화를 주었는지 살펴보도록 하겠습니다.
Pre-Act ResNet, 2016
처음 소개드릴 architecture는 2016년 CVPR에 발표된 “Identity Mappings in Deep Residual Networks” 라는 논문에서 제안한 Pre-Act ResNet 입니다. Pre-Act는 Pre-Activation의 약자로, Residual Unit을 구성하고 있는 Conv-BN-ReLU 연산에서 Activation function인 ReLU를 Conv 연산 앞에 배치한다고 해서 붙여진 이름입니다. ResNet을 제안한 Microsoft Research 멤버가 그대로 유지된 채 작성한 후속 논문이며 ResNet의 성능을 개선하기 위해 여러 실험을 수행한 뒤, 이를 분석하는 식으로 설명을 하고 있습니다.
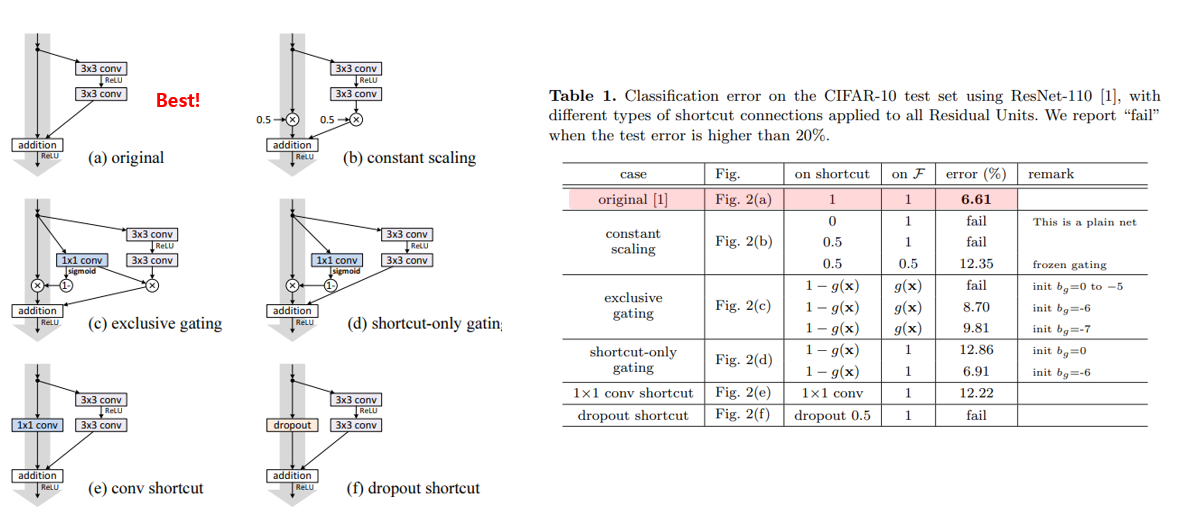
우선 기존 ResNet에서 사용되던 identity shortcut을 5가지 다양한 shortcut으로 대체하는 방법과, 각각을 적용하였을 때의 실험 결과를 위에 그림에서 확인하실 수 있습니다. 실험 결과, 아무것도 하지 않았을 때, 즉 identity shortcut일 때 가장 성능이 좋은 것을 확인할 수 있습니다. 이에 대한 짤막한 discussion이 있는데, 제안하는 gating 기법과 1x1 conv등을 추가하면 표현력(representational ability)은 증가하지만 학습 난이도를 높여서 최적화하기 어렵게 만드는 것으로 추정된다고 설명하고 있습니다.
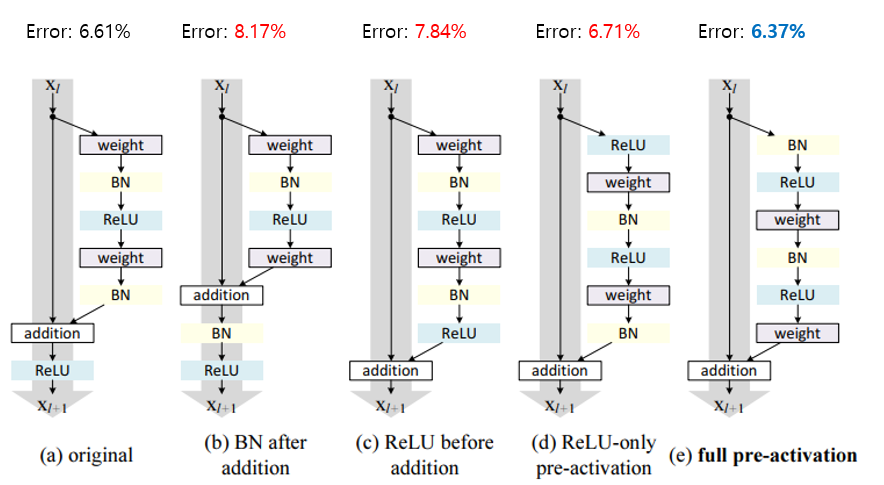
다음 그림은 activation function의 위치에 따른 test error 결과를 보여주고 있습니다. 기존엔 Conv-BN-ReLU-Conv-BN을 거친 뒤 shortcut과 더해주고 마지막으로 ReLU를 하는 방식이었는데, 총 4가지 변형된 구조를 제안하였고, 그 중 full pre-activation 구조일 때 가장 test error가 낮았고, 전반적인 학습 안정성도 좋아지는 결과를 보인다고 합니다.
Original의 경우 2번째 BN을 거쳐서 feature map이 normalize되어도 shortcut과 더해지면서 다시 unnormalized된 채로 다음 Conv 연산으로 전달되는 반면, 제안한 full pre-activation 구조는 모든 Conv 연산에 normalized input이 전달되기 때문에 좋은 성능이 관찰되는 것이라고 분석하고 있습니다.
Inception-v2, 2016
이번엔 ResNet이 아닌 GoogLeNet의 후속 연구인 Inception-v2이며 2016년 CVPR에 “Rethinking the Inception Architecture for Computer Vision” 라는 제목으로 발표가 된 논문입니다.
Inception-v2의 핵심 요소는 크게 3가지로 나눌 수 있습니다.
- Conv Filter Factorization
- Rethinking Auxiliary Classifier
- Avoid representational bottleneck
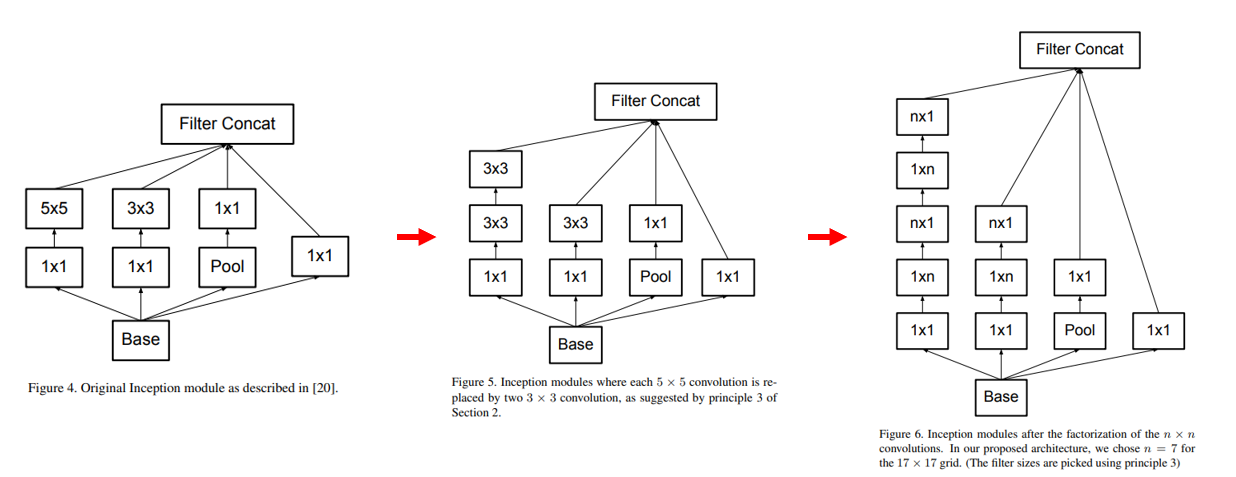
우선 Inception-v1(GoogLeNet)은 VGG, AlexNet에 비해 parameter수가 굉장히 적지만, 여전히 많은 연산량을 필요로 합니다. Inception-v2에서는 연산의 복잡도를 줄이기 위한 여러 Conv Filter Factorization 방법을 제안하고 있습니다. 우선 VGG에서 했던 것처럼 5x5 conv를 3x3 conv 2개로 대체하는 방법을 적용합니다. 여기서 나아가 연산량은 줄어들지만 receptive field는 동일한 점을 이용하여 n x n conv를 1 x n + n x 1 conv로 쪼개는 방법을 제안합니다.
그 다음은 Inception-v1(GoogLeNet)에서 적용했던 auxiliary classifier에 대한 재조명을 하는 부분입니다. 여러 실험과 분석을 통해 auxiliary classifier가 학습 초기에는 수렴성을 개선시키지 않음을 보였고, 학습 후기에 약간의 정확도 향상을 얻을 수 있음을 보였습니다. 또한 기존엔 2개의 auxiliary classifier를 사용하였으나, 실제론 초기 단계(lower)의 auxiliary classifier는 있으나 없으나 큰 차이가 없어서 제거를 하였다고 합니다.
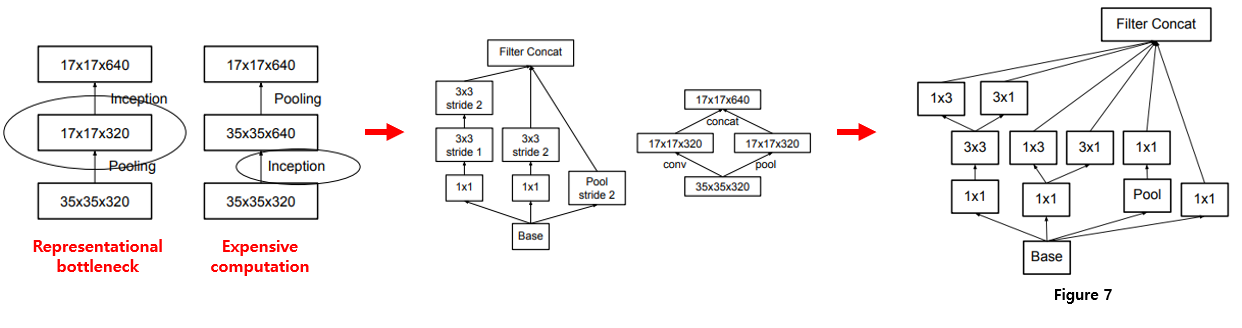
마지막으론 representational bottleneck을 피하기 위한 효과적인 Grid Size Reduction 방법을 제안하였습니다. representational bottleneck이란 CNN에서 주로 사용되는 pooling으로 인해 feature map의 size가 줄어들면서 정보량이 줄어드는 것을 의미합니다. 이해를 돕기 위해 위의 그림으로 설명을 드리면, 왼쪽 사진과 같이 pooling을 먼저 하면 Representational bottleneck이 발생하고, 오른쪽과 같이 pooling을 뒤에 하면 연산량이 많아집니다. 그래서 연산량도 줄이면서 Representational bottleneck도 피하기 위해 가운데와 같은 방식을 제안하였고, 최종적으론 맨 오른쪽과 같은 방식을 이용하였다고 합니다.
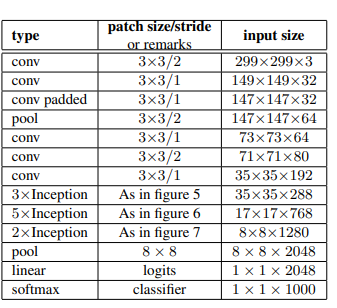
위와 같은 아이디어가 적용된 최종 Inception-v2의 architecture 구조는 위의 표와 같습니다. 기존 Inception-v1은 7x7 conv 연산이 가장 먼저 수행이 되었는데, 위의 Factorization 방법에 의거하여 3x3 conv 연산 3개로 대체가 되었고, figure5, 6, 7의 기법들이 차례대로 적용이 되어있는 것을 확인하실 수 있습니다.
Inception-v3, 2016
Inception-v3는 Inception-v2의 architecture는 그대로 가져가고, 여러 학습 방법을 적용한 버전입니다. 한 논문에서 Inception-v2와 Inception-v3를 동시에 설명하고 있습니다. Inception-v2와 중복되는 내용이 많아서 간략하게 달라진 점만 정리하고 넘어가겠습니다.
- Model Regularization via Label Smoothing
- one-hot vector label 대신 smoothed label을 생성하는 방식이며 자세한 설명은 제가 작성했던 글 의 3-B를 참고하시기 바랍니다.
- Training Methodology
- Momentum optimizer –> RMSProp optimizer / gradient clipping with threshold 2.0 / evaluation using a running average of the parameters computed over time
- BN-auxiliary
- Auxiliary classifier의 FC layer에 BN을 추가
Inception-v4, 2016
Inception 시리즈의 최종 진화형인 Inception-v4는 2017년 AAAI에 “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning” 라는 제목으로 발표가 되었으며, 이 논문에서 Inception-v4와 Inception-ResNet 구조를 제안하였습니다. 우선 Inception-v4의 architecture는 다음과 같습니다.
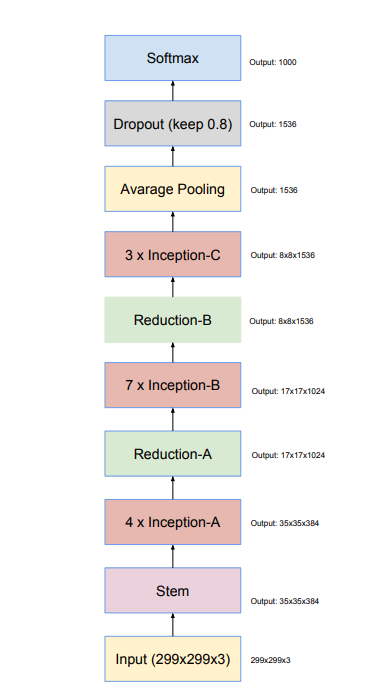
Input과 바로 연결되는 Stem block과 3개의 Inception Block(Inception-A, Inception-B, Inception-C)과, feature map의 size가 절반으로 줄어드는 2개의 Reduction Block(Reduction-A, Reduction-B)으로 구성이 되어있으며 각 Block의 자세한 구성은 아래 그림과 같습니다.
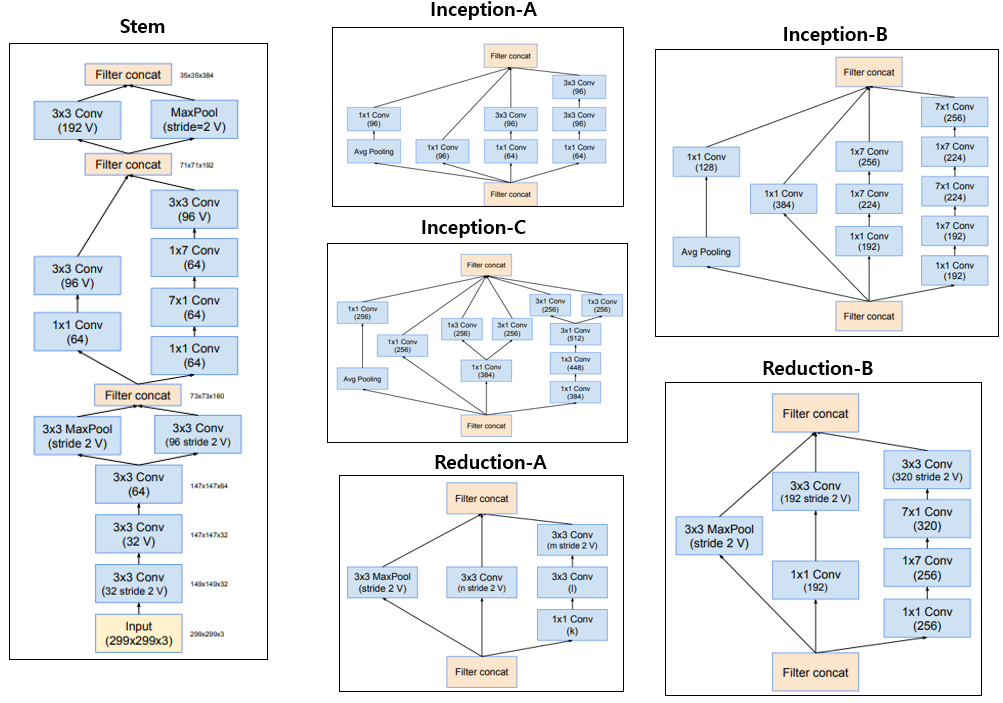
Inception-v2, Inception-v3에서 확장하여 architecture를 좀 더 균일하고 단순화한 버전이 Inception-v4라 할 수 있습니다. 구조의 단순화로 인해 backpropagation 단계에서의 memory가 최적화되는 효과를 얻을 수 있었다고 합니다.
사실 Inception-v2, Inception-v3에서 많은 시도들이 있었기 때문에 Inception-v4는 딱히 설명할 여지가 없는 것 같아서 이정도로 마치겠습니다.
Inception-ResNet, 2016
지금까지 Inception-v2, v3, v4를 설명드렸는데, Inception도 결국 ResNet의 아이디어를 가져오기 시작합니다. Inception-v4과 같은 논문에서 제안된 방법이며 Inception block에 ResNet의 Residual block을 합친 Inception-ResNet-v1 과 Inception-ResNet-v2 를 제안하였습니다. 전자는 Inception-v3과 연산량이 거의 유사한 모델이고, 후자는 Inception-v4와 연산량이 거의 유사하면서 정확도가 더 좋은 모델이라고 정리할 수 있습니다.
사실 Inception-v4와 마찬가지로 architecture를 구성하는 Inception block과 Reduction block을 바꾼 정도의 차이이기 때문에 architecture만 한 그림에 정리하여 설명하고 마치도록 하겠습니다.
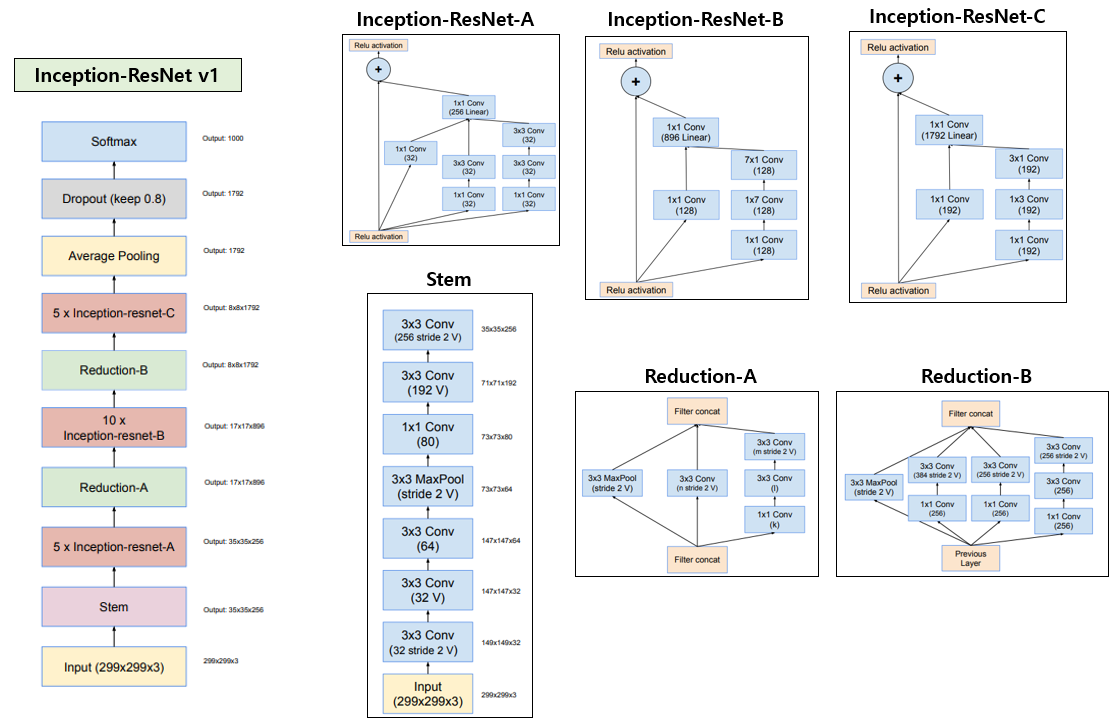
위의 그림이 Inception-ResNet-v1의 전체 architecture를 설명하고 있습니다. 혹시 그림의 글씨가 잘 보이지 않으신다면 원 논문을 참고하시기 바랍니다.
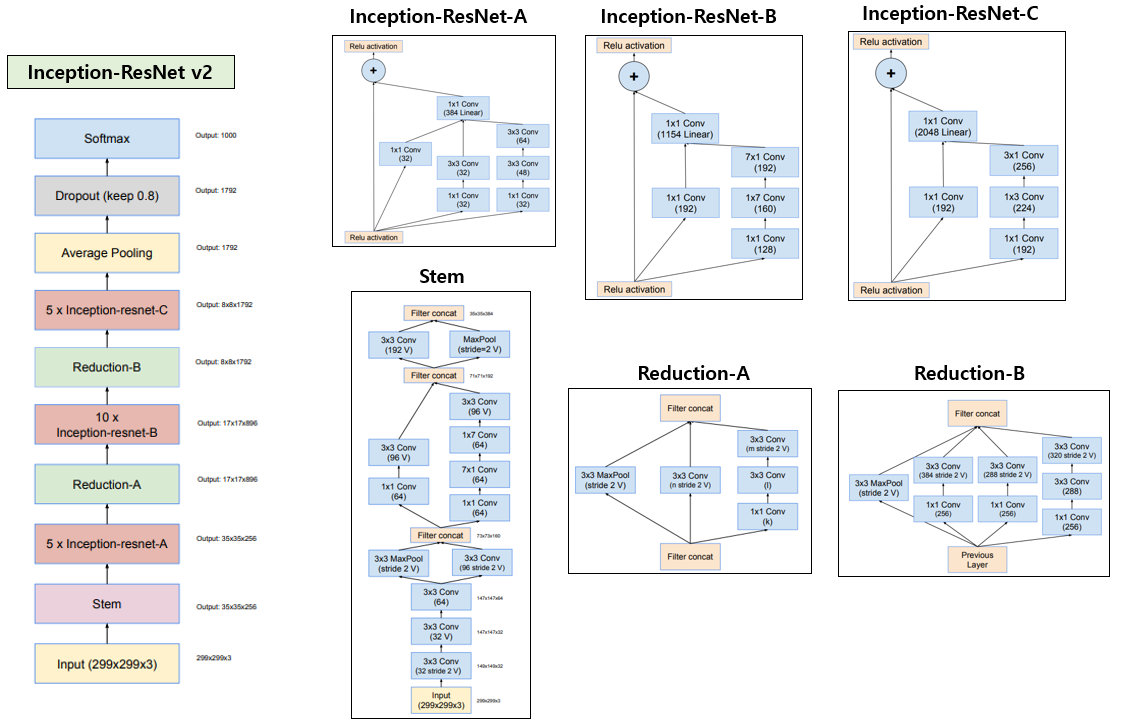
위의 그림은 Inception-ResNet-v2의 architecture이며 전반적인 틀은 Inception-ResNet-v1과 거의 유사하고 각 block의 filter 개수가 늘어나는 정도의 차이만 있습니다. 또한 Stem block은 Inception-v4에서 사용한 Stem block을 사용하였습니다. 다만 Inception-ResNet이 Inception-v3에 비해 학습이 빨리 수렴하는 효과를 얻을 수 있고, Inception-v4보다 높은 정확도를 얻을 수 있다고 합니다. ResNet과 Inception 시리즈들의 ImageNet validation set에 대한 정확도를 비교하여 표로 정리하면 다음과 같습니다.
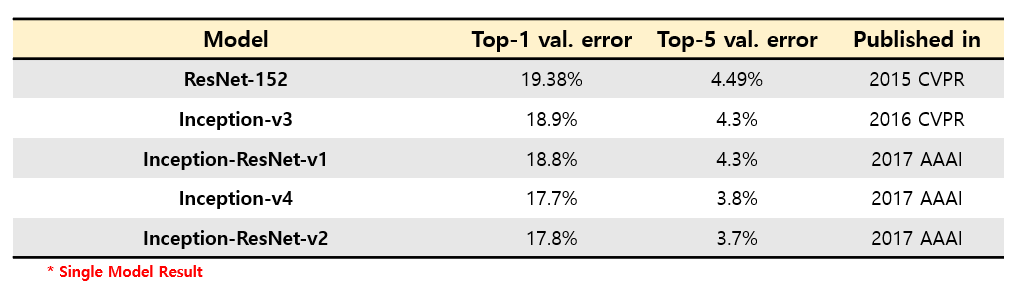
ResNet 보다 Inception v3이 정확도가 높았고, 아이디어가 추가될수록 점점 정확도가 좋아지는 것을 알 수 있습니다.
추가로 여기까지 소개 드린 architecture들의 정확도와 연산량의 Trade-off 관계를 보기 좋게 정리해 놓은 자료가 있어서 간단히 소개를 드리려 합니다.
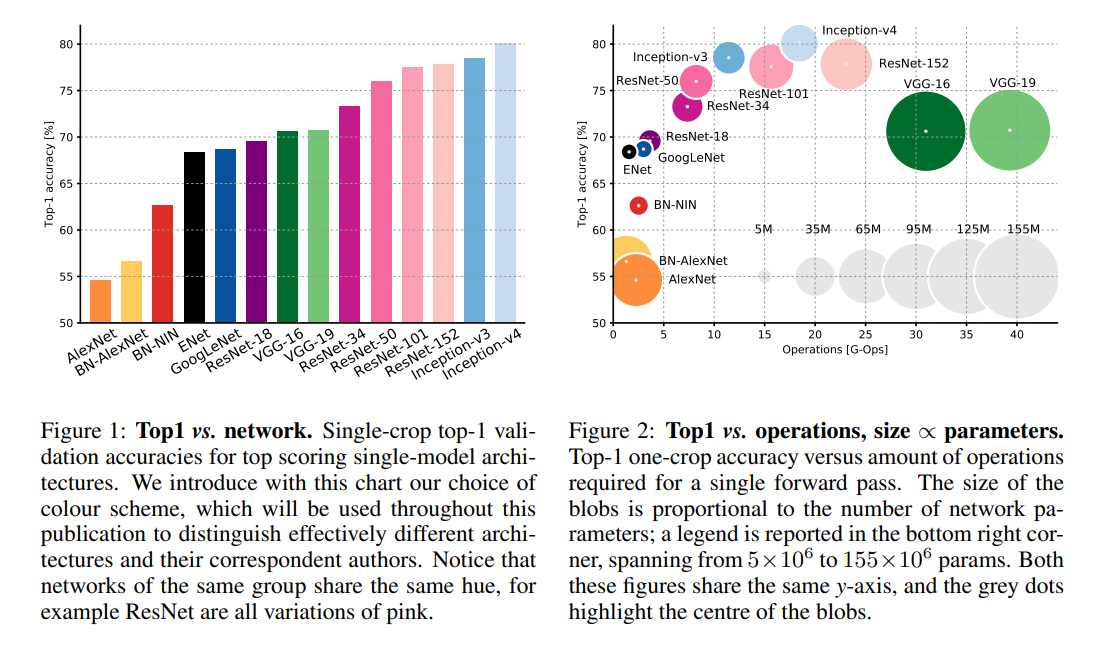
“An Analysis of Deep Neural Network Models for Practical Applications” 논문에서 여러 network들에 대해 분석을 한 결과이며, 정확도, 연산량, parameter 개수 등을 보기 좋게 그래프로 정리하여 보여주고 있습니다. ResNet과 Inception 계열이 높은 정확도에 비해 효율적으로 연산을 수행하고 있음을 알 수 있으며, VGG는 많은 연산량에 비해 정확도가 낮고 parameter 개수가 많아서 비효율적인 구조를 가지고 있음을 시사하고 있습니다.
Stochastic Depth ResNet, 2016
이번 논문은 2016년 ECCV에 발표된 “Deep Networks with Stochastic Depth”라는 논문이며, vanishing gradient로 인해 학습이 느리게 되는 문제를 완화시키고자 stochastic depth 라는 randomness에 기반한 학습 방법을 제안합니다. 이 방법은 2019년 말 ImageNet 데이터셋에 대해 State-of-the-art 성능을 달성한 “Self-training with Noisy Student improves ImageNet classification” 논문 리뷰 글에서 noise 기법으로 사용된 기법입니다. 사실 이 논문은 새로운 architecture를 제안했다고 보기는 어렵습니다. 기존 ResNet에 새로운 학습 방법을 추가했다고 보는게 맞지만, ResNet의 layer 개수를 overfitting 없이 크게 늘릴 수 있는 방법을 제안하였다는 점에서 오늘 소개를 드리고 싶습니다.
비슷한 아이디어로는 여러분들이 잘 아시는 Dropout이 있습니다. Dropout은 network의 hidden unit을 일정 확률로 0으로 만드는 regularization 기법이며, 후속 연구론 아예 connection(weight)을 끊어버리는 DropConnect(2013 ICML) 기법, MaxOut(2013 ICML), MaxDrop(2016 ACCV) 등의 후속 연구가 존재합니다. 위의 방법들은 weight나 hidden unit(feature map)에 집중했다면, Stochastic depth란 network의 depth를 학습 단계에 random하게 줄이는 것을 의미합니다.
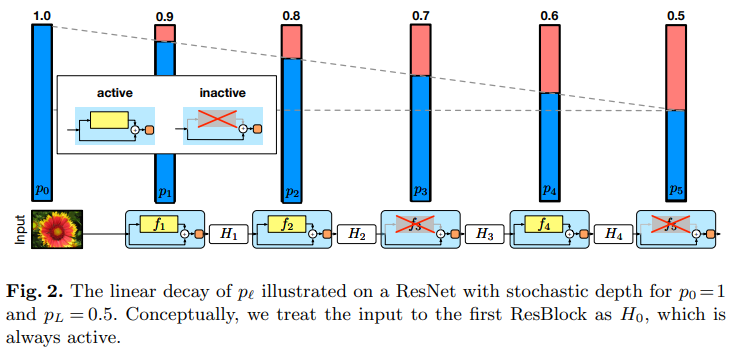
ResNet으로 치면 확률적으로 일정 block을 inactive하게 만들어서, 해당 block은 shortcut만 수행하는, 즉 input과 output이 같아져서 아무런 연산도 수행하지 않는 block으로 처리하여 network의 depth를 조절하는 것입니다. 이 방법은 학습시에만 사용하고 test 시에는 모든 block을 active하게 만든 full-length network를 사용합니다.
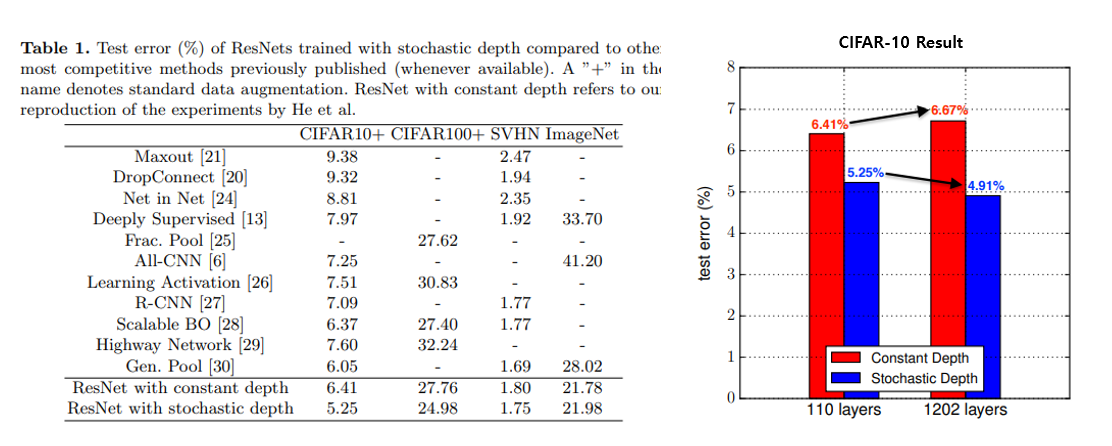
Stochastic Depth ResNet은 CIFAR-10, SVHN 등에 대해선 test error가 줄어드는 효과가 있지만, ImageNet과 같이 복잡하고 큰 데이터 셋에서는 별다른 효과를 보지 못했습니다. 다만 CIFAR-10과 같이 비교적 작은 데이터셋에서는 ResNet을 1202 layer를 쌓았을 때 기존 ResNet은 오히려 정확도가 떨어지는 반면 Stochastic Depth ResNet은 정확도가 향상되는 결과를 보여주고 있습니다.
Wide ResNet, 2016
오늘의 마지막 소개드릴 논문은 2016년 BMVC에 발표된 “Wide Residual Networks” 논문입니다. 처음 소개드렸던 Pre-Act ResNet, 방금 소개드린 Stochastic Depth ResNet과 같이 ResNet의 성능을 높이기 위한 여러 실험들을 수행한 뒤, 이를 정리한 논문입니다. 나아가 정확도를 높이기 위해 Layer(Depth)만 더 많이 쌓으려고 해왔는데, Conv filter 개수(Width)도 늘리는 시도를 하였고, 여러 실험을 통해 Wide ResNet 구조를 제안하였습니다. 마지막으로, BN의 등장 이후 잘 사용되지 않던 dropout을 ResNet의 학습 안정성을 높이기 위해 적용할 수 있음을 보였습니다.
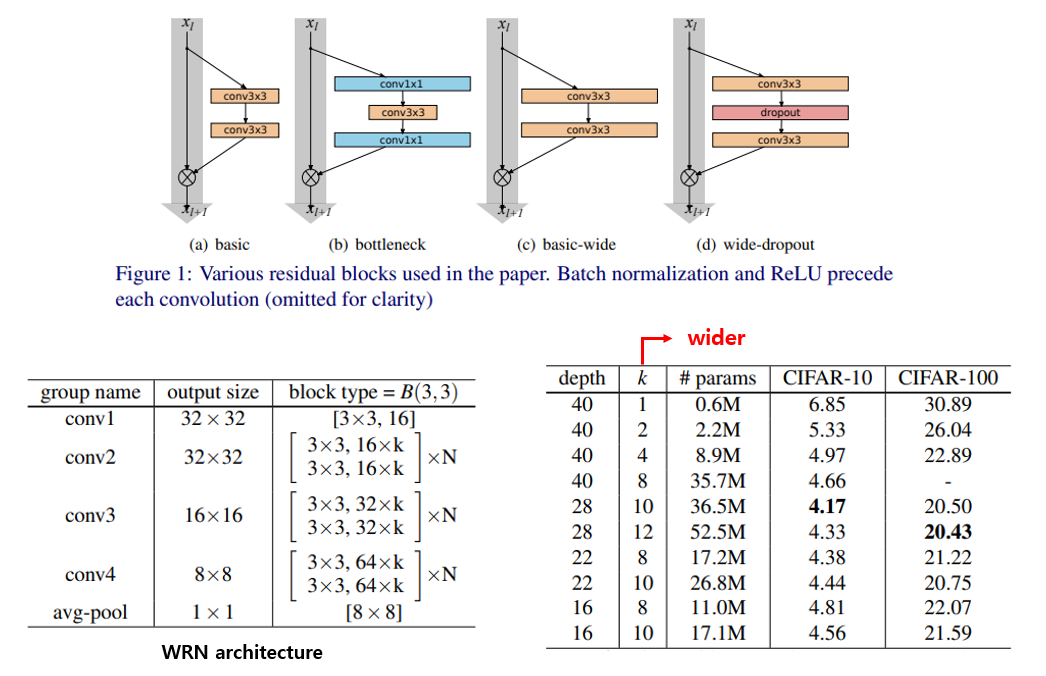
위의 그림 1과 같이 Conv layer의 filter 개수를 늘리고, dropout을 사용하는 방법이 효과적임을 실험을 통해 보여주고 있습니다. 또한 병렬처리 관점에서 봤을 때, layer의 개수(depth)를 늘리는 것보다 Conv filter 개수(width)를 늘리는 것이 더 효율적이기 때문에 본인들이 제안한 WRN-40-4 구조가 ResNet-1001과 test error는 유사하지만 forward + backward propagation에 소요되는 시간이 8배 빠름을 보여주고 있습니다.
이 논문에서는 depth 외에 width도 고려해야 한다는 점이 핵심인데, 2019년에 학계를 뜨겁게 달궜던 EfficientNet 에서는 한발 더 나아가 width와 depth 뿐만 아니라 input resolution을 동시에 고려하여서 키워주는 compound scaling 방법을 통해 굉장히 효율적으로 정확도를 높이는 방법을 제안했습니다. WRN과 같은 연구가 있었기 때문에 EfficientNet도 등장할 수 있지 않았나 생각해봅니다.
결론
오늘 포스팅에서는 2016년 제안된 7가지의 CNN architecture(PreActResNet, Inception-v2, Inception-v3, Inception-v4, Inception-ResNet, Stochastic Depth ResNet, WRN)에 대해 설명을 드렸습니다. 2016년은 ResNet으로 시작해서 ResNet으로 끝났다고 해도 과언이 아니군요. Inception 마저 v2, v3, v4를 제안했지만 결국 ResNet과 합쳐졌으니 말이죠 ㅎㅎ.
다음 포스팅에서 다룰 2017년에서는 모델의 경량화를 초점으로 한 여러 lightweight CNN 구조들, ResNet 만큼 유명한 DenseNet, 그 외 여러 다양한 시도를 한 논문들을 소개드릴 예정입니다. 다음편도 기대해주세요!
3편으로 이동
위의 버튼을 클릭하세요!
Reference
- Bag-of-Tricks-for-Image-Classification-with-Convolutional-Neural-Networks 리뷰 블로그 글
- An Analysis of Deep Neural Network Models for Practical Applications, 2016 arXiv
- “Self-training with Noisy Student improves ImageNet classification” 리뷰 블로그 글
- EfficientNet 리뷰 블로그 글