Deep Learning Image Classification Guidebook [3] SqueezeNet, Xception, MobileNet, ResNext, PolyNet, PyramidNet, Residual Attention Network, DenseNet, Dual Path Network (DPN)
안녕하세요, 지난 Deep Learning Image Classification Guidebook [2] 에 이어서 오늘은 2017년 공개된 주요 CNN architecture들에 대한 설명을 드릴 예정입니다. 2017년에 공개된 CNN architecture들은 주옥 같은 방법들이 많아서 오늘은 총 9개의 architecture를 설명할 예정입니다. 오늘 다룰 architecture들은 다음과 같습니다.
- SqueezeNet
- Xception
- MobileNet
- ResNext
- PolyNet
- PyramidNet
- Residual Attention Network
- DenseNet
- Dual Path Network (DPN)
2017년 제안된 CNN architecture 소개
지난 포스팅에서는 2016년 공개된 CNN architecture들을 소개드렸고, ResNet의 전성시대라 부를 수 있을 만큼 ResNet 관련 연구가 많았는데요, 오늘 다룰 2017년에는 여전히 ResNet 관련 연구들이 주를 이뤘지만, 경량화된 CNN 구조에 대한 연구들이 하나 둘 씩 제안이 되기 시작했고, ResNet 이후 또 한번의 큰 변화를 일으킨 DenseNet의 공개 등 굵직한 논문들이 많이 발표가 되었습니다. 자, 이제 2017년 공개된 대표적인 논문들을 알아보도록 하겠습니다!
SqueezeNet, 2016
처음 소개드릴 architecture는 2016년에 arXiv에 공개되고, 2017년 ICLR에 아쉽게 reject 되었지만, 많이 사용되는 “SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size” 라는 논문에서 제안한 SqueezeNet 입니다. 사실 지난 포스팅에서 다뤘어야 했는데 깜빡해서 오늘 소개를 드리게 되었습니다 하하..
Squeeze라는 단어는 쥐어짜내는 것을 뜻하며 제가 좋아하는 야구에서도 점수를 짜내기 위한 스퀴즈 번트라는 작전이 존재합니다. 이처럼 network를 쥐어 짜내는 것을 의미하며, 제목에서 알 수 있듯이 AlexNet의 parameter를 50배 이상 줄여서 0.5MB 이하의 model size를 가질 수 있는 architecture 구조를 제안하고 있습니다.
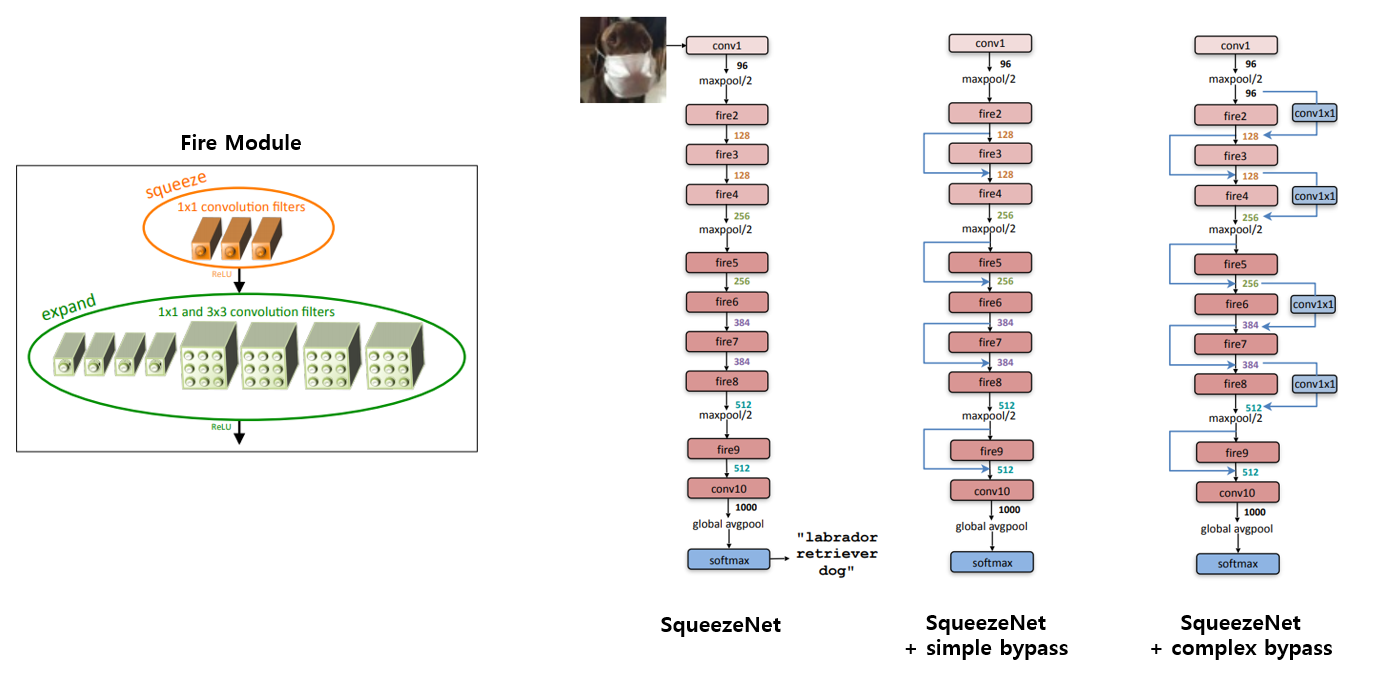
논문에서는 총 3가지 종류의 SqueezeNet architecture를 제안하고 있으며, 모든 architecture는 그림 왼쪽에 있는 Fire module 로 구성이 되어있습니다. Fire module은 1x1 convolution으로 filter 개수를 줄인 뒤(squeeze) 1x1 conv와 3x3 conv를 통해 filter 개수를 늘려주는(expand) 연산을 수행합니다. 3개의 conv layer의 filter 개수는 hyper parameter이며 자세한 구조는 다음과 같습니다.
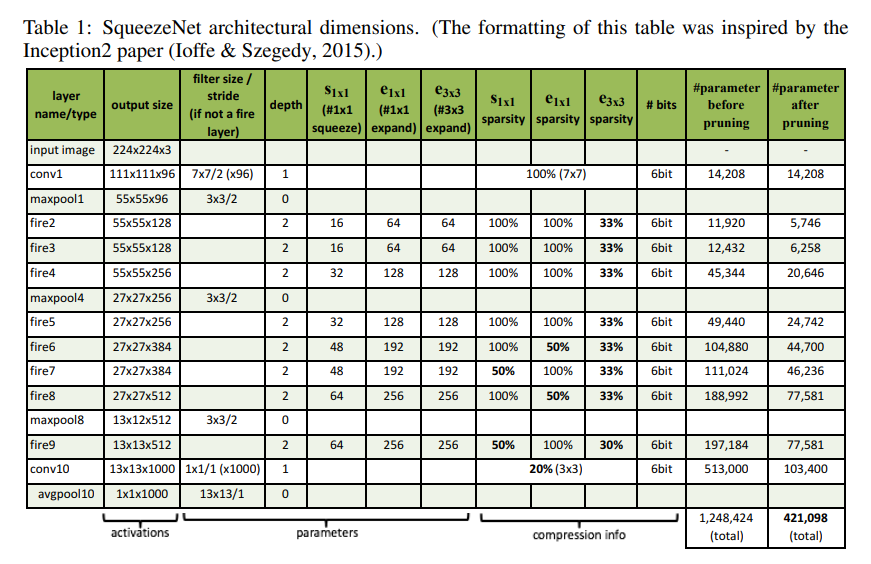
NIN, GoogLeNet 등에서 사용했던 것처럼 FC layer 대신 GAP를 이용하였고, 실험에는 architecture 구조를 제안한 것에 추가로 pruning 기법과 compression 기법(Deep Compression) 등을 같이 적용하여 최종적으로 AlexNet 대비 ImageNet Accuracy는 비슷하거나 약간 더 높은 수치를 얻으면서 Model Size는 적게는 50배에서 많게는 510배(6bit compression)까지 줄일 수 있음을 보이고 있습니다. 추가로 첫번째 그림에서 보여드렸던 3가지 구조 중 ImageNet에 대한 정확도는 Simple Bypass SqueezeNet > Complex Bypass SqueezeNet > SqueezeNet 순으로 좋았다고 합니다.
Pruning, Compression 등 모델 경량화 기법들을 많이 사용하였지만 architecture 관점에서도 연산량을 줄이기 위한 시도를 논문에서 보여주고 있습니다. 다만, fire module의 아이디어는 이미 지난 번 소개 드린 Inception v2의 Conv Filter Factorization과 비슷한 방법이고, Inception v2에 비해 정확도가 많이 낮아서 좋은 평가를 받지 못한 것으로 생각됩니다.
Xception, 2017
다음은 2017 CVPR에 “Xception: Deep Learning with Depthwise Separable Convolutions”라는 제목으로 발표된 Xception 입니다. 본 논문은 Inception 구조에 대한 고찰로 연구를 시작하였으며, 추후 많은 연구들에서 사용이 되는 연산인 depthwise-separable convolution 을 제안하고 있습니다. Inception v1, 즉 GoogLeNet에서는 여러 갈래로 연산을 쪼갠 뒤 합치는 방식을 이용함으로써 cross-channel correlation과 spatial correlation을 적절히 분리할 수 있다고 주장을 하였습니다. 쉽게 설명하자면, channel간의 상관 관계와 image의 지역적인 상관 관계를 분리해서 학습하도록 가이드를 주는 Inception module을 제안한 셈이죠.
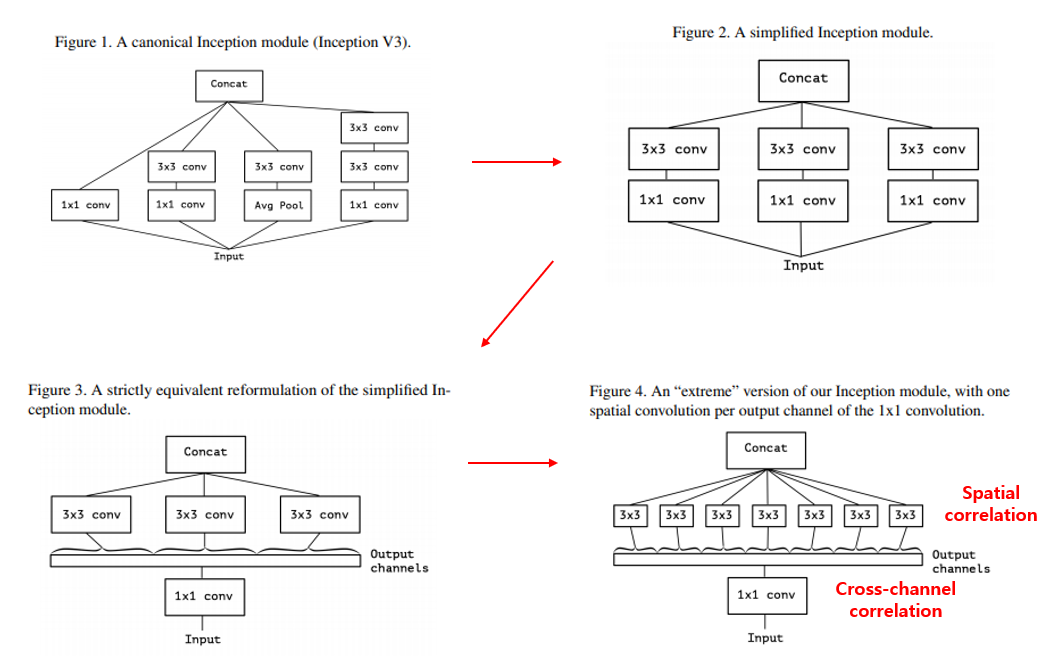
Xception은 여기서 더 나아가서 아예 channel간의 상관 관계와 image의 지역적인 상관 관계를 완벽하게 분리하는 더 높은 목표를 세우고 연구를 시작하였고, 위의 그림의 Figure 4와 같은 연산 구조를 이용하면 cross-channel correlation과 spatial correlation이 완벽하게 분리가 될 수 있음을 제안하였습니다.
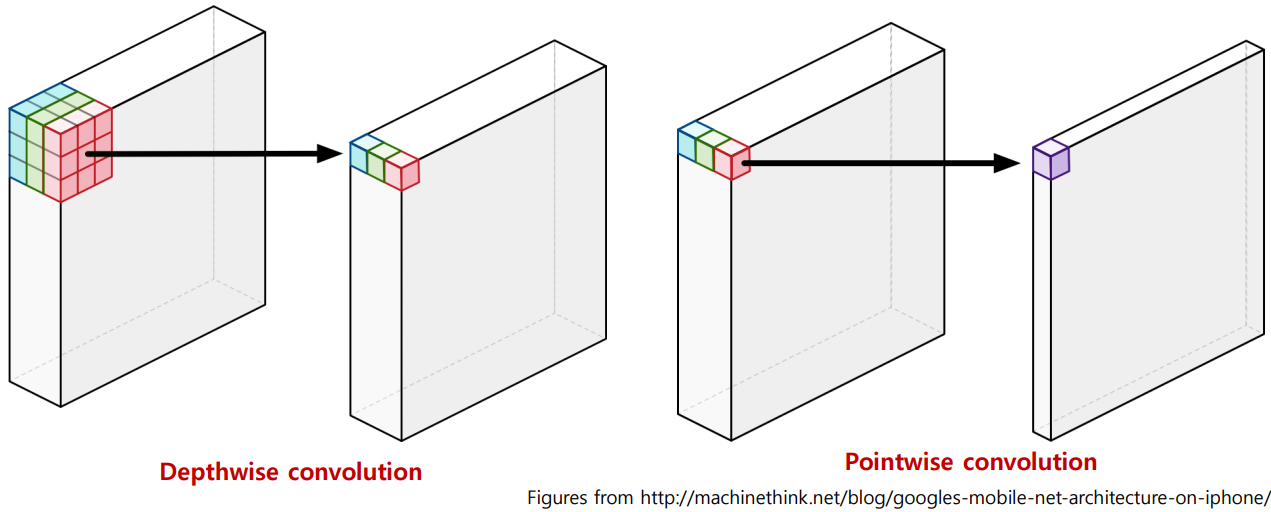
다만 실제로 Figure 4와 같은 extreme version의 Inception module을 사용하는 대신 비슷한 연산을하는 depthwise-separable convolution을 사용하였습니다. 둘의 차이는 연산의 순서와 첫 연산 직후의 non-linearity(activation function)의 유무이며 depthwise-separable convolution은 channel-wise spatial convolution(depthwise convolution)을 먼저 한 뒤, 1x1 convolution(pointwise convolution)을 수행하며, 두 연산 사이에 non-linearity는 들어가지 않습니다.
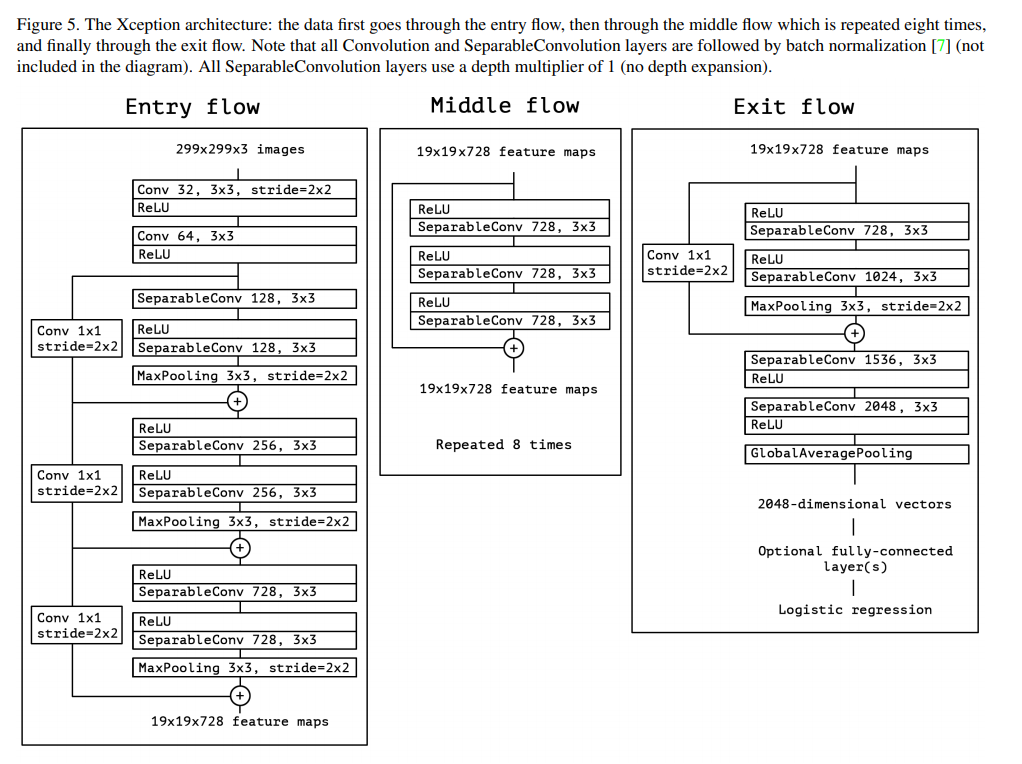
Xception의 architecture 구조는 다음과 같으며 Entry flow, Middle flow, Exit flow로 구분하여 그림을 그렸습니다. 다만 대부분의 연산들이 단순 반복되는 구조로 되어있어서 구현하기엔 어렵지 않습니다. ResNet에서 봤던 shortcut도 포함이 되어있고 Batch Normalization도 들어가 있는 등 정확도를 높이기 위한 여러 시도를 포함하고 있으며, 구현의 디테일한 정보들은 논문에 잘 정리가 되어있습니다.
MobileNet, 2017
다음은 너무나 유명한 논문이죠, 2017년 4월 arXiv에 “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications”라는 제목으로 발표된 MobileNet 입니다. 구글에서 제안한 논문이며 워낙 유명하기도 하고, 참고할 만한 자료도 굉장히 많아서 저는 자세한 설명은 생략하고 제가 공부하는데 많은 도움을 주신 이진원 선배님의 PR-12 발표 영상 과 발표 슬라이드 를 바탕으로 핵심 내용만 정리하여 소개드리겠습니다. (흔쾌히 자료 인용 허락해주셔서 감사합니다!!)
MobileNet도 핵심은 Depthwise-Separable Convolution 연산을 적절히 사용하는 것이며, 이는 직전에 소개드린 Xception 논문에서 제안한 아이디어입니다. 약간의 차이가 있다면, architecture 구조를 새롭게 제안을 하였고, Depthwise Convolution과 Point Convolution 사이에 BN과 ReLU를 넣은 점이 차이점입니다. 또한 Xception은 Inception보다 높은 정확도를 내기 위해 Depthwise-Separable Convolution을 적절히 사용하는 데 집중한 반면, MobileNet은 Depthwise-Separable Convolution을 통해 Mobile Device에서 돌아갈 수 있을 만큼 경량 architecture 구조를 제안하는데 집중을 했다는 점에서도 차이가 있습니다. 즉, 같은 연산을 사용하였지만 바라보고 있는 곳이 다른 셈이죠.
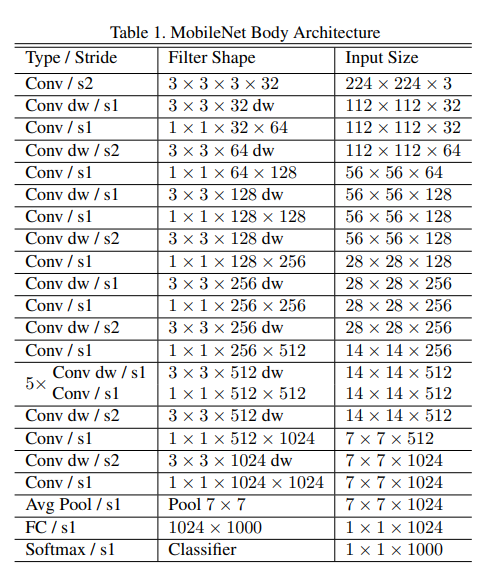
MobileNet의 architecture 구조는 다음과 같습니다. MobileNet은 추후 v2, v3까지 제안이 되는 architecture인 만큼 위의 소개 드린 자료를 바탕으로 잘 숙지해두시는 것을 권장드립니다!
ResNext, 2017
다음은 2016년 말 arXiv에 공개되고 2017년 CVPR에 “Aggregated Residual Transformations for Deep Neural Networks” 라는 이름으로 발표된 ResNext 입니다. 이름에서 유추하실 수 있듯이 ResNet을 기반으로 새로운 구조를 제안한 논문입니다. 2016년 ILSVRC 대회에서 2등을 하였으며 2015년 우승팀의 ResNet보다 높은 정확도를 달성하였습니다.
여담으로 2016년 ILSVRC 대회의 1등은 Trimps-Soushen 팀이며 이 팀은 Inception-v3, Inception-v3, Inception-v4, Inception-ResNet-v2, ResNet-200, WRN-68-3 5가지 model을 적절히 앙상블하여 1위를 달성하였다고 합니다. 그동안 ILSVRC 대회에서는 단일 모델로 참가하는 경우가 많았는데 2016년에는 잘 알려진 모델들을 앙상블한 팀이 1위를 했다는 점이 특징이며, 논문을 위한 접근이 아니라 Competition을 위한 접근을 한 방법이라고 할 수 있습니다.
무튼 다시 ResNext로 넘어와서, ResNext의 핵심 내용을 설명드리겠습니다.
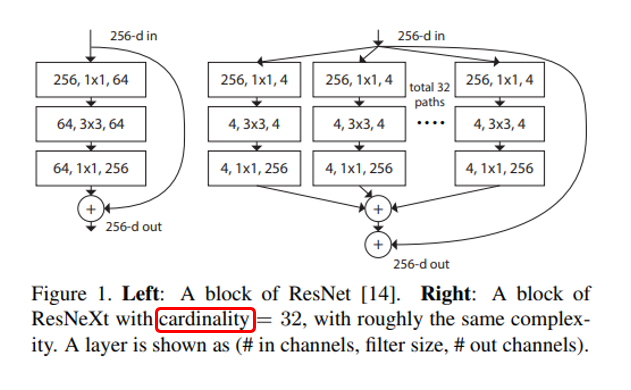
위의 그림은 ResNet과 ResNext의 가장 큰 차이점을 보여주고 있습니다. 기존 ResNet은 Res Block의 반복 구조로 이루어져 있고, 지난 2편에서 소개드렸던 여러 ResNet의 변형들도 ResNet의 width(filter 개수)와 depth(layer 개수)를 조절하는 시도를 하였는데, 본 논문에서는 width와 depth 외에 cardinality 라는 새로운 차원의 개념을 도입합니다.
Cardinality는 한글로 번역하면 집합의 크기 또는 집합의 원소 개수를 의미하는데, CNN에서는 하나의 block 안의 transformation 개수 혹은 path, branch의 개수 혹은 group의 개수 정도로 정의할 수 있습니다. 위의 그림에서는 64개의 filter 개수를 32개의 path로 쪼개서 각각 path마다 4개씩 filter를 사용하는 것을 보여주고 있으며, 이는 AlexNet에서 사용했던 Grouped Convolution 과 유사한 방식입니다. 사실 AlexNet은 GPU Memory의 부족으로 눈물을 머금고 Grouped Convolution을 이용하였는데 ResNext에서는 이러한 연산이 정확도에도 좋은 영향을 줄 수 있음을 거의 최초로 밝힌 논문입니다.
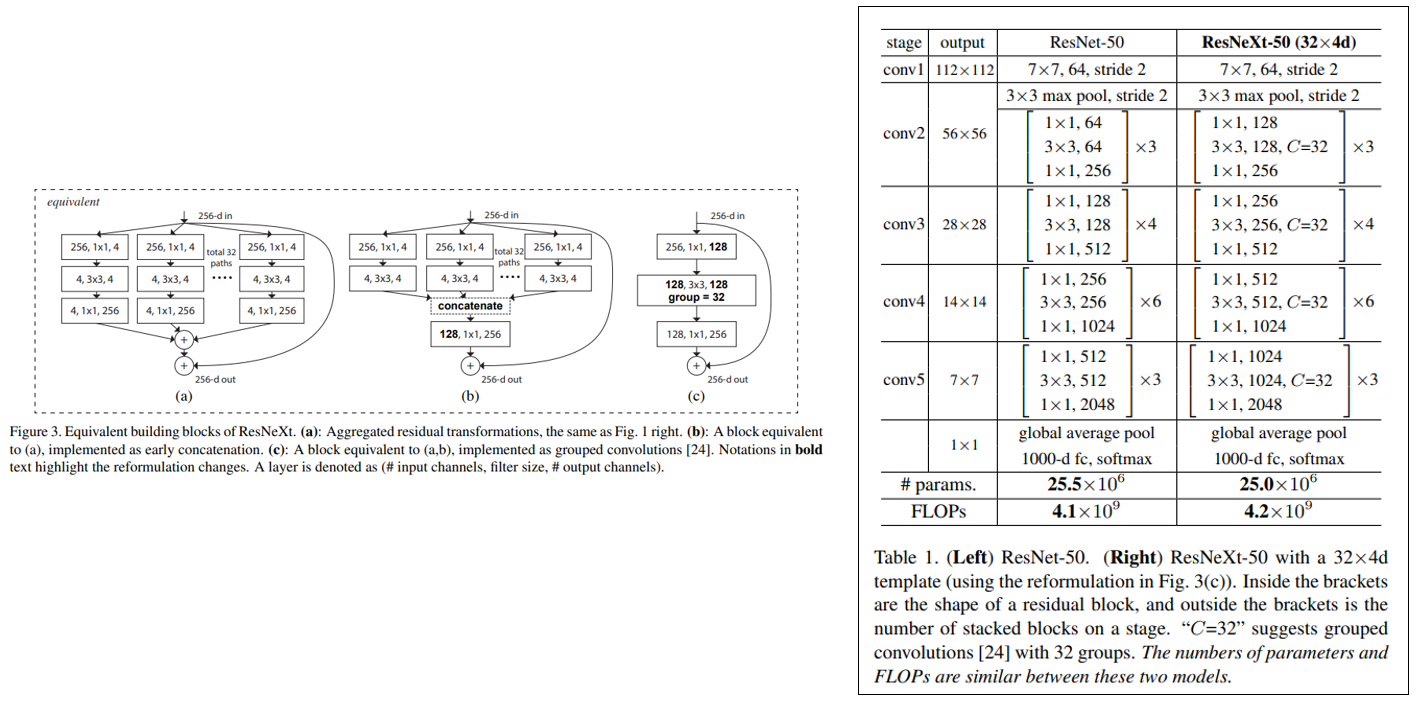
ResNext의 building block은 가장 먼저 제안한 단순한 (a) 구조에서, 3x3 conv 이후 결과를 미리 concat해주고 1x1 conv를 해주는 (b) 구조, 마지막으로 초기 1x1 conv를 하나로 합치고 중간 3x3 conv를 grouped convolution으로 대체하는 (c) 구조가 모두 동일한 과정을 수행하며, 편한 구현을 위해 실제론 (c) 구조를 사용하였습니다.
위의 그림의 오른쪽 표가 ResNet-50과 ResNext-50 (32x4d) 구조를 비교하고 있는 그림이며 parameter 수와 연산량 수(FLOPs)가 거의 비슷한 것을 확인할 수 있습니다. 하지만 정확도는 ResNet-50보다 더 높은 결과를 확인할 수 있으며, 논문에서는 ResNext 구조에 대한 여러 ablation study를 수행한 내용도 있어서 관심있으신 분들은 논문을 참고하시면 좋을 것 같습니다.
PolyNet, 2017
다음 소개드릴 논문은 2016년 arXiv에 공개되고 2017년 CVPR에 “PolyNet: A Pursuit of Structural Diversity in Very Deep Networks” 란 이름으로 발표된 논문이며, PolyNet 이라는 architecture를 제안하였습니다. 참고로 이 방법론은 2016년 ILSVRC 대회에서 0.01%라는 근소한 차이로 ResNext에게 밀려서 3위를 하였습니다. (Top-5 Error Rate: 3.031% vs 3.042%)
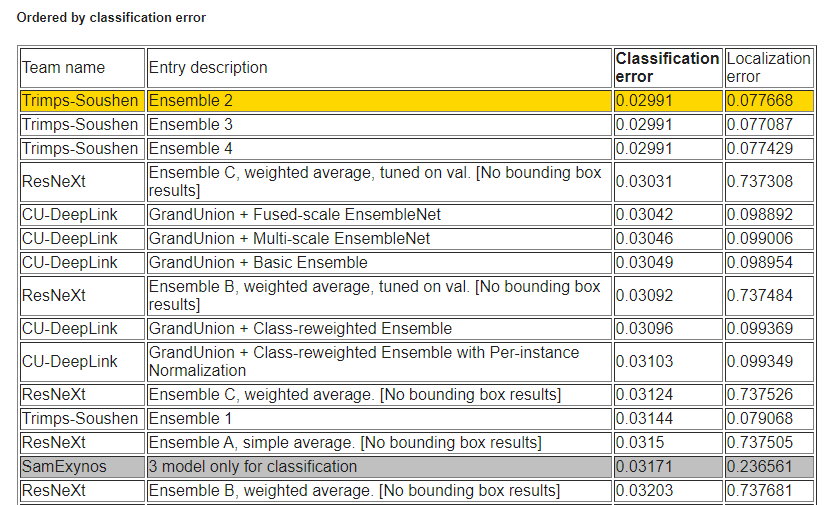
순위표를 보시면 상위 15개의 모델이 대부분 Trimps-Soushen 팀과 ResNext 팀, 그리고 이번에 소개 드리는 PolyNet을 다룬 CU-DeepLink 팀에서 다투고 있으며, 앙상블의 향연을 보실 수 있습니다.
이제 본론으로 들어가서, Inception, ResNet 등 좋은 성능을 내는 구조들이 제안이 되었는데, 한가지 문제점이 network를 굉장히 깊게 쌓으면 정확도는 미미하게 향상되거나 오히려 떨어지고, 학습 난이도만 높이는 부작용이 있습니다. 본 논문에서는 이러한 어려움을 해결하기 위한 PolyInception module 을 제안하였으며, 이러한 구조를 사용하였을 때, Inception-ResNet-v2보다 Convolution Layer를 많이 쌓을수록 더 높은 정확도를 달성하는 결과를 보였습니다. 해당 결과는 아래 그림의 왼쪽 그래프에서 확인하실 수 있습니다.
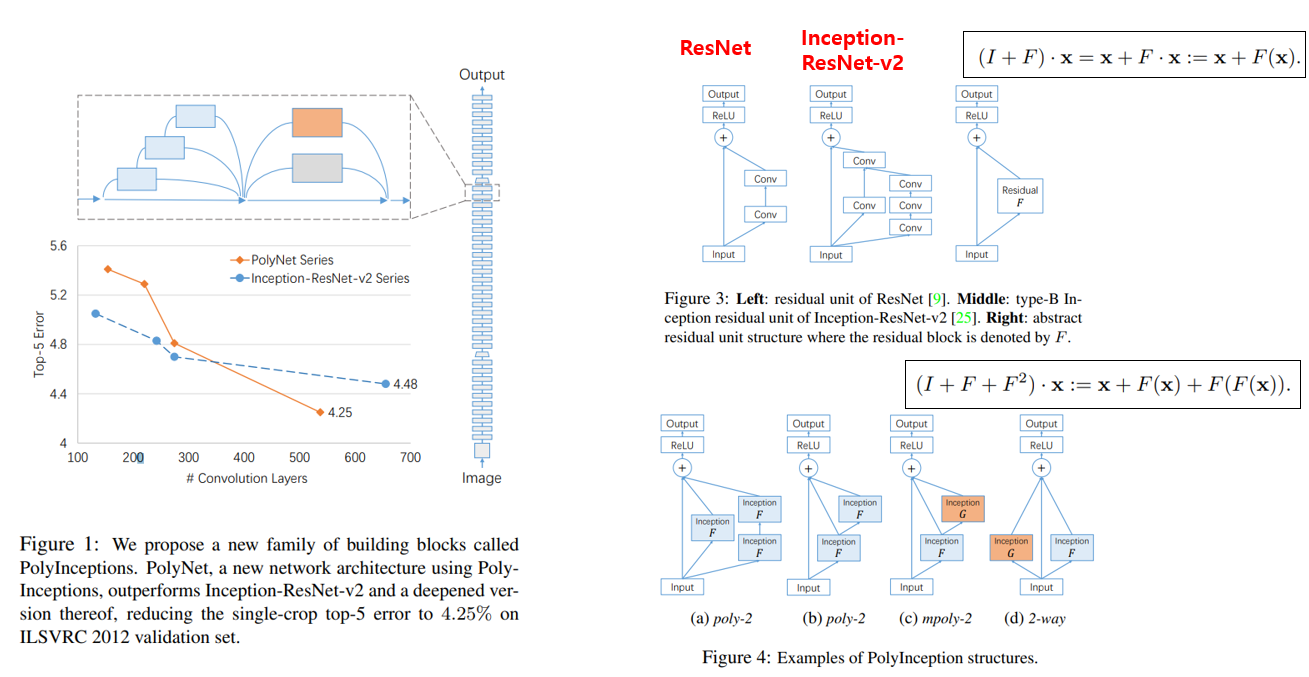
기존 Res Block과 Inception module은 x와 일종의 Residual Block을 함수로 나타낸 F에 넣어준 F(x)의 합으로 나타낼 수 있습니다. PolyInception module은 오른쪽 하단 그림과 같이 x를 F에 2번 통과시켜주는 module을 의미하며 (a)와 (b)는 단일 Inception module F를 2-order 형태로 사용하는 방식을 의미합니다. 다만 (a)는 0-odrer, 1-order, 2-order의 결과를 하나로 합쳐주는 구조라면, (b)는 1-order의 output을 이용하여 2-order로 만들어주는 차이가 있습니다. (c)는 서로 다른 Inception module F, G를 이용하여 연결하는 방식이고, 마지막 (d)는 F와 G를 1-order 형태로 단순하게 합쳐주는 구조를 의미합니다. 위의 그림은 2-order 까지만 그림을 그렸는데 3-order, 그 이상의 order도 가능하다고 합니다.
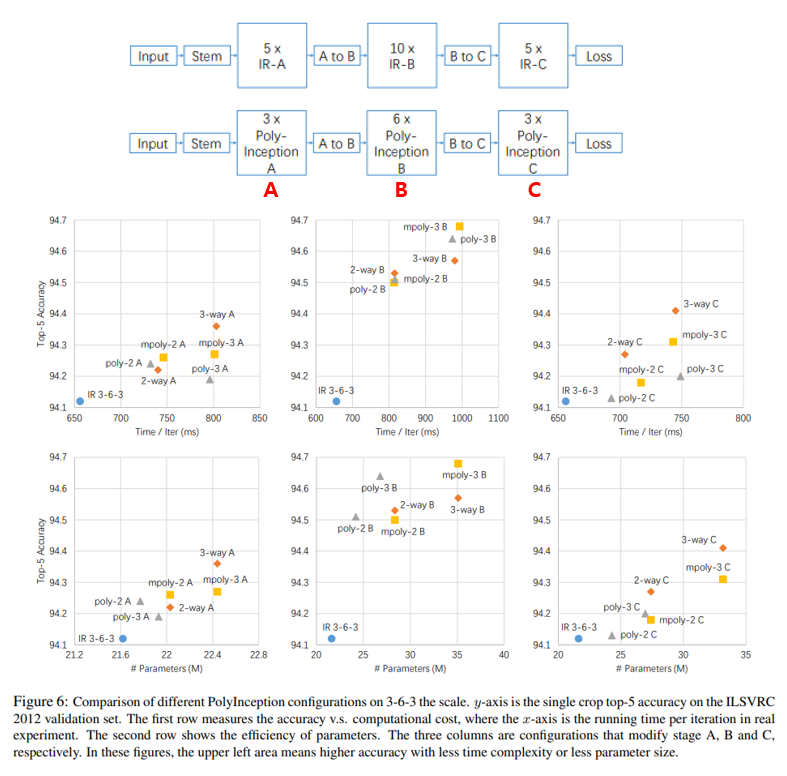
다음 그림은 Inception ResNet-v2와 PolyNet의 성능을 비교한 그림이며 모든 2-order PolyNet이 Inception ResNet-v2보다 성능이 좋은 것을 확인하실 수 있습니다. 실험 결과 그래프의 각 column은 위의 그림의 윗 부분에서 A, B, C 3가지 stage로 나뉘어져 있는데, 이 Inception ResNet의 각 Stage를 Poly-Inception A, Poly-Inception B, Poly-Inception C로 대체하였을 때의 결과를 의미합니다. 위의 그래프에서는 B stage를 PolyInception module로 대체하는 경우에 가장 효과적임을 보여주고 있습니다.
이 외에도 각 Inception block을 PolyInception module들로 대체하는 여러 경우의 수에 따른 성능 변화를 보여주고 있지만, 굉장히 복잡하고 실험적이라..(오히려 ImageNet에 Overfitting 시키는 느낌?!) 자세한 내용은 생략하도록 하겠습니다.
PyramidNet, 2017
다음 소개드릴 architecture는 2017년 CVPR에서 발표된 “Deep Pyramidal Residual Networks” 논문의 PyramidNet 입니다. ResNet을 기반으로 성능을 개선한 논문이며 제목에서 알 수 있듯이 Pyramid의 모양에서 이름을 따왔습니다. 핵심 아이디어는 다음 그림으로 설명이 가능합니다.
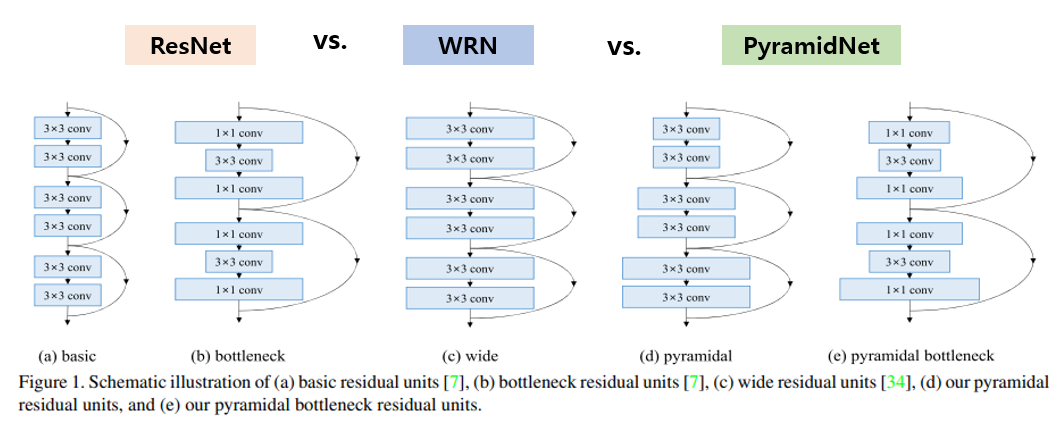
우선 ResNet은 feature map의 가로, 세로 size가 같은 layer에서는 feature map의 개수가 동일한 구조를 가지고 있고, down sampling이 되는 순간 feature map의 개수가 2배씩 증가하는 구조로 설계가 되었습니다. 이 down sampling + doubled feature map layer 가 전체 성능에 관여하는 비중이 크다는 실험 결과가 있었는데, 이에서 착안해서 down sampling layer에서만 이뤄지던 feature map의 개수를 늘리는 과정을 전체 layer에 녹여내는 구조를 제안하였습니다. 위의 그림의 (a), (b)는 기존 ResNet의 block 구조를, (c)는 WRN(Wide ResNet)의 block 구조를 나타내고, (d), (e)가 오늘 소개드릴 PyramidNet의 block 구조를 나타내고 있습니다.
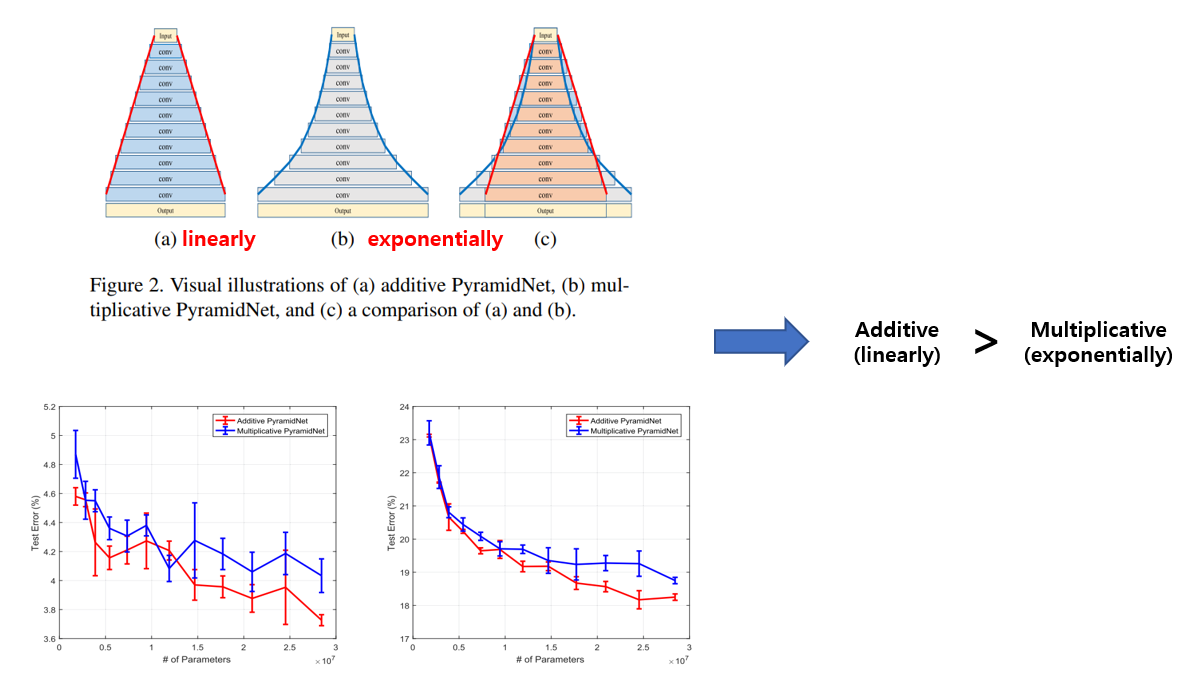
Feature map의 개수를 늘려주는 방법은 linear하게 늘려주는 방법과 exponential하게 늘려주는 방법을 생각할 수 있습니다. 위의 그림의 (a)와 같이 linear하게 늘려주는 방법을 additive라 부르고, (b)와 같이 exponential하게 늘려주는 방법을 multiplicative라 부르는데 본 논문에선 성능이 더 좋았던 additive 방법을 사용하였습니다. 위의 그림 (c)이 Additive와 multiplicative의 차이를 보여주며, additive 방식이 input과 가까운 초기의 layer의 feature map 개수가 더 많아서 성능이 더 좋다고 설명하고 있습니다.

이 외에도 여러 실험을 수행하였고, 그 중 일부를 요약해서 말씀드리면 우선 Pre-Act ResNet에서 제안한 Res Block(BN-ReLU-Conv) 대신 약간 다른 Res Block(BN-Conv-BN-ReLU-Conv-BN)을 이용하여 약간의 성능 향상을 얻었습니다. 또, Pyramidal Block을 이용하면 input과 output의 feature map의 개수가 달라지기 때문에 기존의 identity mapping을 Shortcut connection으로 이용할 수 없는데, 여러 실험을 통해 zero padding을 이용한 Identity mapping with zero-padded shortcut이 가장 효율적임을 보여주고 있습니다.
Residual Attention Network, 2017
다음 소개드릴 논문은 2017년 CVPR에 “Residual Attention Network for Image Classification” 라는 제목으로 발표된 Residual Attention Network 입니다. 제목에서 알 수 있듯이 ResNet에 Attention 아이디어를 접목시킨 논문입니다. Attention 아이디어는 자연어 처리에서 굉장히 잘 사용이 되어왔으며, 이를 Computer Vision 문제에 접목시켰습니다.

위의 그림이 핵심적인 내용을 잘 보여주고 있습니다. Attention을 적용하기 전에는 feature map이 분류하고자 하는 물체의 영역에 집중하지 못하는 경향이 있는데, attention을 적용하면 feature map을 시각화 했을 때 물체의 영역에 잘 집중을 하고 있는 것을 확인할 수 있습니다.
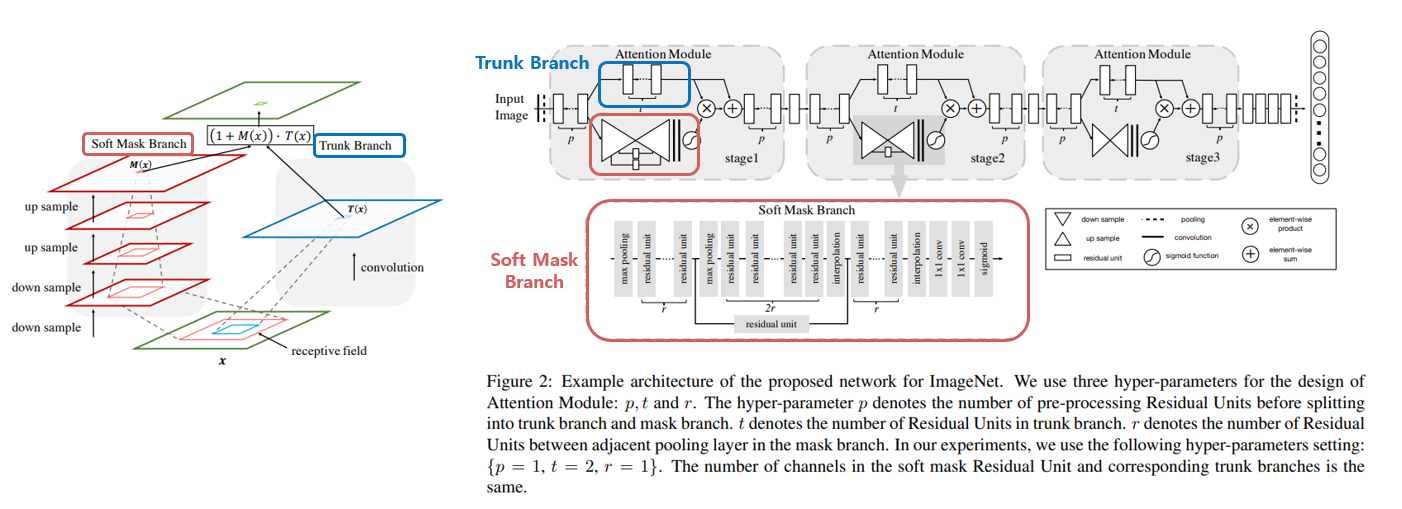
Residual Attention Network의 architecture는 위의 그림과 같이 Attention을 뽑아내는 Soft Mask Branch와 일반적인 Conv 연산이 수행되는 Trunk Branch로 구성이 되어있으며, Soft Mask Branch에서는 receptive field를 늘려 주기 위해 down sampling과 up sampling을 수행하는 식으로 구성이 되어있습니다. 또한 Attention을 주는 방식에도 Spatial Attention과 Channel Attention이 있는데, 실험 결과 두가지 방법을 섞은 Mixed Attention이 가장 성능이 좋았다고 합니다.
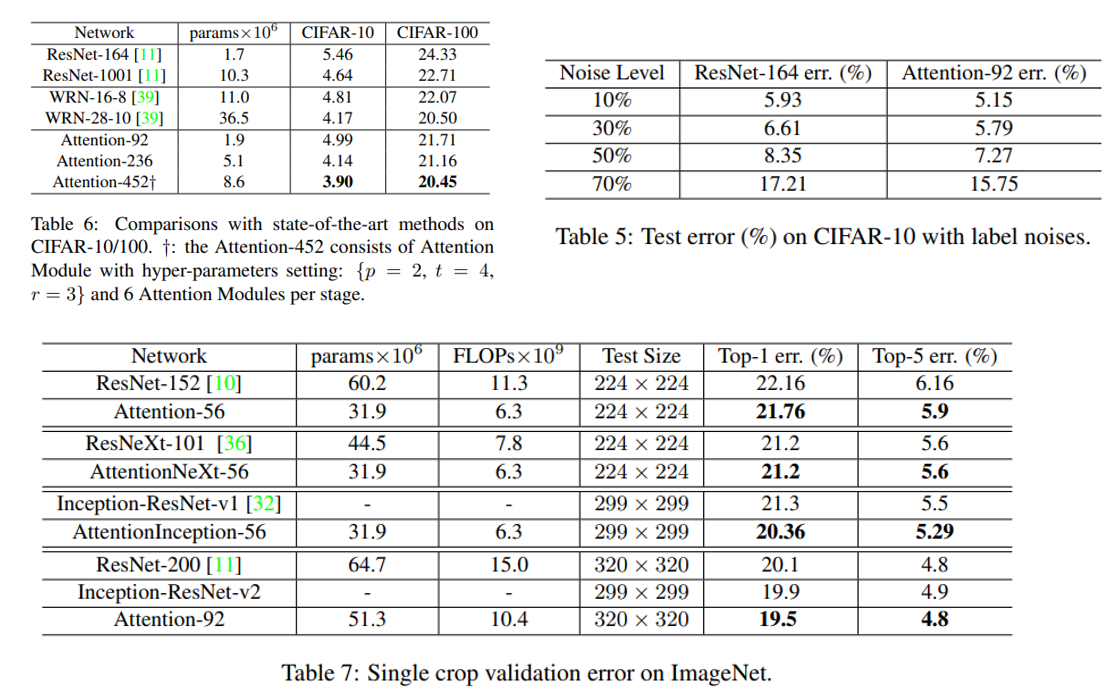
실험 결과는 CIFAR-10, CIFAR-100, ImageNet에 대해 ResNet과 WRN과 정확도를 비교하였고, 3가지 데이터셋에서 모두 비교 방법론들보다 좋은 성능을 달성하였습니다. 또한 CIFAR-10 데이터셋에 대해선 Label에 인위적으로 noise를 생성한 뒤 Noisy Label에 대한 Robustness도 실험적으로 측정하였고, ResNet보다 좋은 결과를 보였습니다. Attention을 CNN에 접목시킬 수 있는 가능성을 보여준 논문이며, 아쉽게 본 논문에서는 다른 task에 대한 실험은 수행하지 않았지만 비단 Classification 뿐만 아니라 Object Detection, Segmentation 등 다른 Computer Vision task에 대해서도 적용할 수 있는 아이디어라 생각됩니다.
DenseNet, 2017
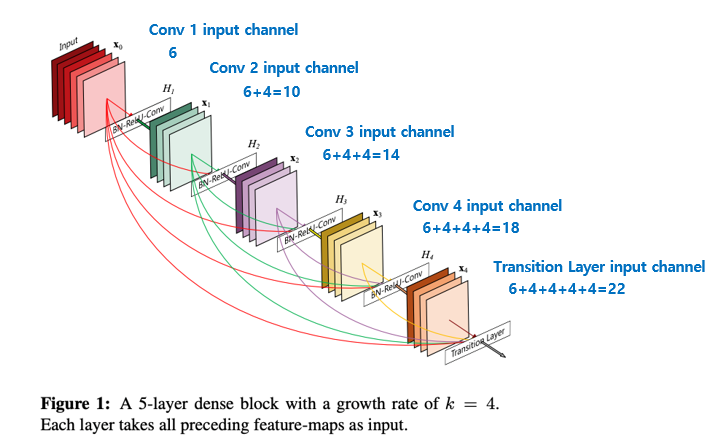
다음은 다들 한 번쯤은 들어 보셨을 2017 CVPR의 Best Paper인 “Densely Connected Convolutional Networks”의 DenseNet 입니다. ResNet의 shortcut 방식이랑 비슷한 아이디어인데, ResNet은 feature map끼리 더하기를 이용하였다면, DenseNet은 feature map끼리의 Concatenation을 이용하였다는 것이 가장 큰 차이이며 핵심 내용입니다.
DenseNet에 대한 리뷰는 제가 2019년 초에 논문 리뷰, 코드 구현(PyTorch) 2편으로 자세히 작성한 글이 있어서 그 글로 설명을 대체하겠습니다…! (같은 내용 한번 더 쓰기 귀찮아서 그러는 거 아닙니다..ㅎㅎ)
- DenseNet Tutorial [1] Paper Review & Implementation details
- DenseNet Tutorial [2] PyTorch Code Implementation
Dual Path Network(DPN), 2017
오늘의 마지막 논문은 2017년 NIPS (지금은 NeurIPS)에 “Dual Path Networks” 란 이름으로 발표된 Dual Path Networks(이하 DPN) 입니다. 2017년 ILSVRC Object Localization task에서 1위를 차지하였고, Classification task에서는 3위를 차지한 방법론입니다. 2017년 Classification task의 1위는 다음 편에서 소개드릴 Squeeze-Excitation Network(SENet)이고, 2위는 2016년에 1위를 차지한 Trimps-Soushen 팀입니다.
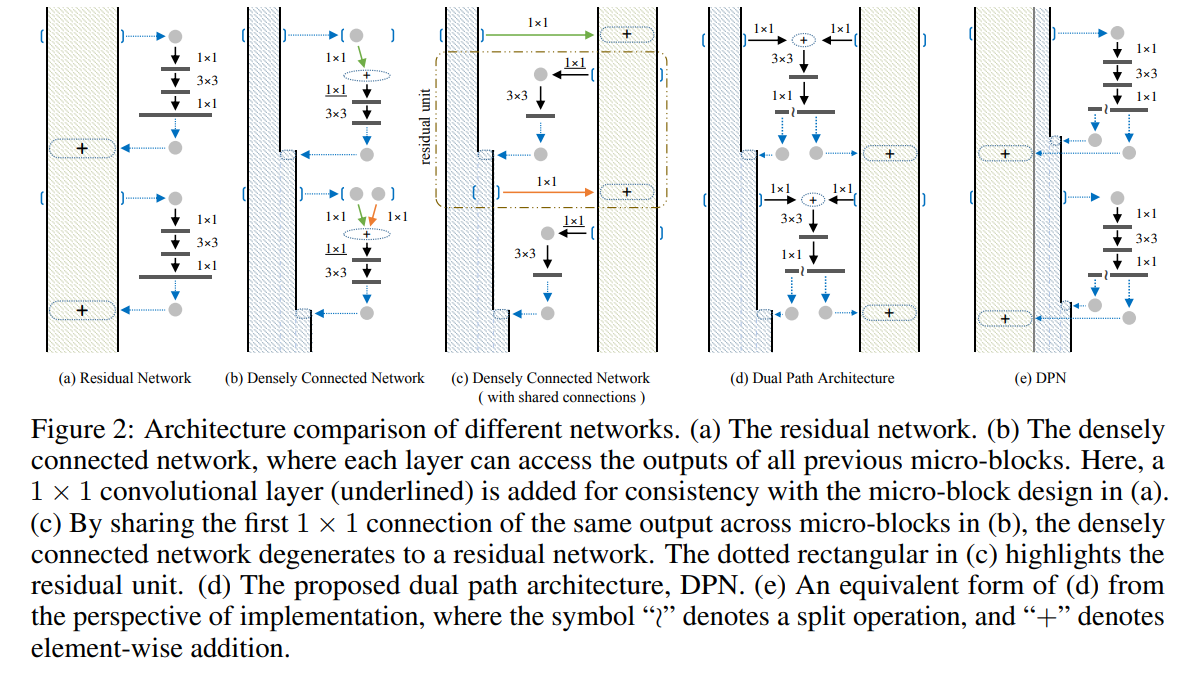
Dual Path Network는 2개의 path를 가지는 network라는 뜻으로, ResNet과 DenseNet의 각각의 아이디어에서 장점만 가져오는 데 집중하였으며, 논문에서는 ResNet과 DenseNet이 Higher Order Recurrent Neural Network(HORNN)의 형태로 표현이 가능하다는 점에서 착안해서 각각 Network의 성공 요인을 분석하고 있습니다. ResNet은 Feature refinement 혹은 Feature re-use 효과를 얻게 해주고 DenseNet은 Feature re-exploration 효과를 얻게 해준다고 합니다. 저는 HORNN을 잘 몰라서 이 부분이 잘 와 닿지 않았는데, 혹시 더 깊이 알고 싶으신 분은 2016년 발표된 “Higher Order Recurrent Neural Networks” 논문을 확인하시기 바랍니다. 중요한 건 ResNet과 DenseNet의 장점만을 가져온다는 점입니다!
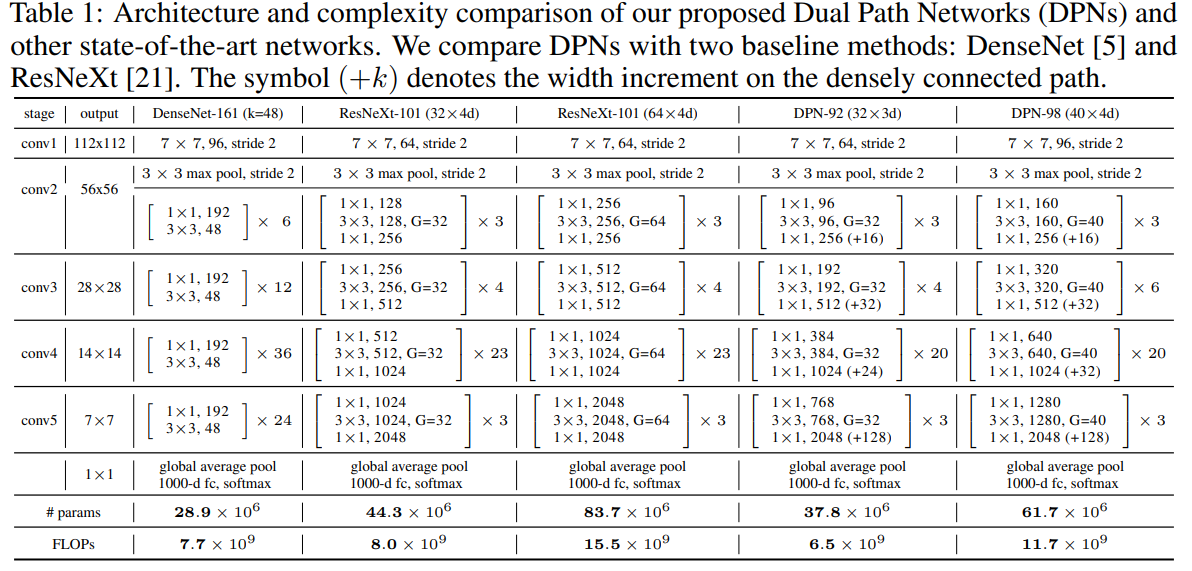
실제로 architecture도 기존 ResNet에서의 add 기반의 shortcut 방식과, DenseNet에서의 concatenate 해주는 shortcut 방식을 적절하게 섞어서 사용하고 있으며, ResNext에서의 Grouped Convolution layer 또한 사용하고 있습니다. 논문에서는 DPN-92와 DPN-98을 DenseNet-161, RexNext-101과 비교하고 있으며, 적절히 효율적인 parameter 수와 FLOPs를 보이고 있습니다.
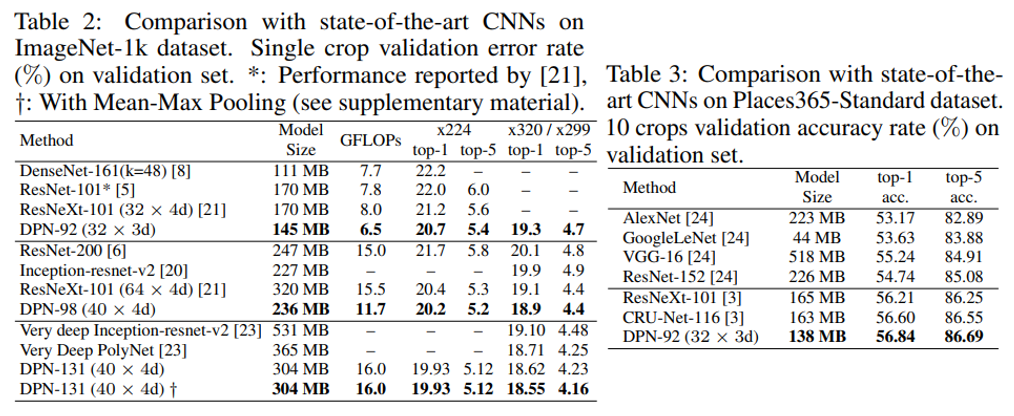
Classification task에 대한 실험 결과도 오늘 다룬 DenseNet, ResNext, PolyNet 등과 비교를 하였으며, Model size와 FLOPs를 비슷하거나 적게 조절하였을 때, 기존 방식들보다 높은 정확도를 보이는 것을 확인할 수 있습니다. 논문에서 주장하는 것처럼 DenseNet과 ResNet의 장점을 잘 가져오고 있는 모습을 확인할 수 있습니다.
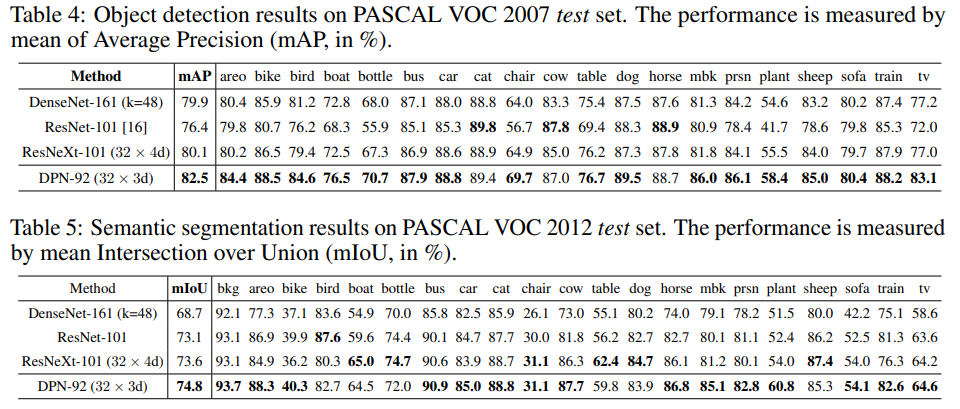
마지막으로, Classification task가 아닌 Object Detection, Semantic Segmentation task에 대해 backbone CNN을 DPN으로 대체했을 때의 실험 결과도 제시하고 있습니다. Object Detection은 Faster R-CNN을, Semantic Segmentation은 DeepLab을 이용하였고, ResNet, ResNext, DenseNet을 backbone으로 이용하였을 때보다 좋은 성능을 보이는 것을 확인할 수 있습니다.
DPN은 “ResNet과 DenseNet의 장점들을 잘 합쳐서 높은 정확도, 작은 모델 크기, 적은 계산량, 적은 GPU memory 점유량 등을 얻을 수 있으며, Object Detection, Semantic Segmentation task에서도 좋은 성능을 보인다!” 정도로 요약할 수 있을 것 같습니다.
결론
오늘 포스팅에서는 2017년 제안된 9가지의 CNN architecture(SqueezeNet, Xception, MobileNet, ResNext, PolyNet, PyramidNet, Residual Attention Network, DenseNet, Dual Path Network(DPN))에 대해 설명을 드렸습니다. 한 번에 많은 architecture를 다뤘는데, 그래도 각각의 architecture들이 가지는 특징이 명확해서, 핵심 내용들만 가져가셔도 충분할 것 같습니다.
다음 포스팅에서 다룰 2018년에서는 모델의 경량화를 다룬 논문들의 멋진 후속 작품들을 비롯해서, CNN architecture에 큰 패러다임 시프트를 가져온 AutoML을 이용한 Neural Architecture Search(NAS) 논문들을 소개드릴 예정입니다. 다음편도 기대해주세요!
4편으로 이동
위의 버튼을 클릭하세요!
Reference