Evolving Normalization-Activation Layers Review
안녕하세요, 오늘은 지난 4월 초 arXiv에 공개된 “Evolving Normalization-Activation Layers” 논문을 자세히 리뷰할 예정입니다.
Introduction
CNN을 공부하시고, 직접 다뤄 보신 분들, 제 블로그의 Deep Learning Image Classification Guidebook 시리즈를 정독하신 분들은 CNN의 안정적인 optimization과 generalization을 위해 다양한 Normalization layer와 Activation function이 사용되는 것을 잘 알고 계실 것입니다.
이 두가지 요소는 CNN의 발전에 큰 기여를 하였고, 다양한 좋은 기법들이 우수수 쏟아져 나왔습니다. Normalization layer의 경우 AlexNet의 Local-Response Normalization 부터 해서, 이제는 거의 표준으로 쓰이는 Batch Normalization, 작은 batch size에서도 잘 동작하기 위한 Group Normalization 등 굉장히 다양한 연구들이 진행되어왔습니다. 저도 Normalization에 대해 여러 번 소개를 드렸었는데, 정리하면 다음과 같습니다.
- “How does batch normalization help optimization” Paper Review
- “Norm matters: efficient and accurate normalization schemes in deep network, 2018 NeurIPS” 간단 리뷰
- “Differentiable Learning-to-Normalize via Switchable Normalization, 2019 ICLR” 간단 리뷰
- “Towards Stabilizing Batch Statistics in Backward Propagation of Batch Normalization, 2020 ICLR” 간단 리뷰
또한 Activation function의 경우 많이들 사용하시는 ReLU 부터 해서 다양한 기법들이 제안이 되었습니다. 저는 Activation function의 경우 많은 공부는 하지 않았고 찾아보니 2편의 논문을 다뤘습니다.
- “Searching for Activation Functions” Paper Review
- “How the Choice of Activation Affects Training of Overparametrized Neural Nets, 2020 ICLR” 간단 리뷰
이와 같이 대부분의 연구들 에서는 Normalization layer와 Activation function을 구분해서 생각해왔고, 둘을 순차적으로 적용을 해왔습니다. (ex, BN-ReLU or ReLU-BN)
본 논문에서는 두 연산을 동시에 고려하여 하나의 building block으로 design하는 것을 목표로 하였으며, 논문의 제목에서 유추하실 수 있듯이 evolutionary algorithm을 통해 automatic하게 이를 찾는 접근 방법을 택했습니다. 접근 방법은 얼마전 제 블로그에서 다뤘던 “AutoML-Zero:Evolving Machine Learning Algorithms From Scratch” 논문 과 유사합니다.
AutoML-Zero와 비슷하게 각 layer를 덧셈, 곱셈, 차원 방향으로의 aggregation 등 단순한 tensor-to-tensor 연산들로 나타내고, 이 연산들을 추가하고 제거하면서 자동으로 굉장히 커다란 미지의 search space 상에서 최적의 Norm+Activation 연산을 찾는 것을 목표로 합니다.
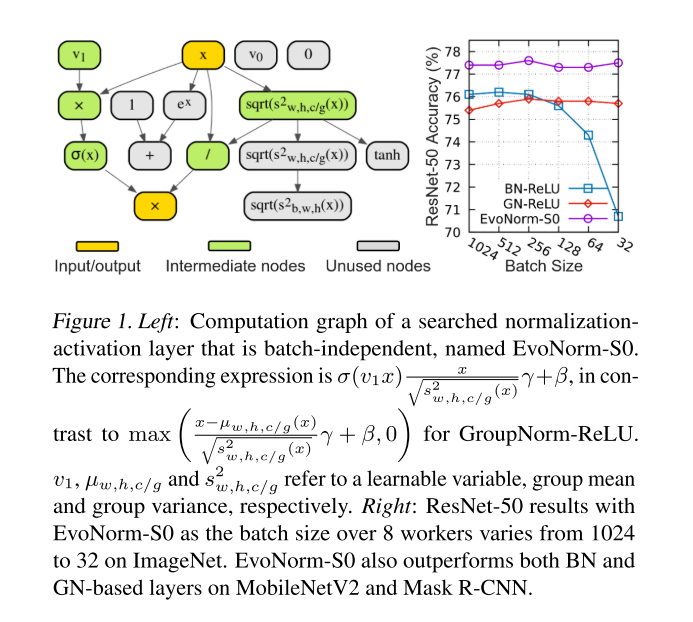
본 논문에서 제안한 방법으로 찾은 EvoNorm-S0의 구조는 위의 그림과 같으며, 기존에 많이 사용되던 BN-ReLU, GN(Group Norm)-ReLU 조합보다 모든 Batch Size 실험 환경에서 높은 성능을 보이고 있습니다. 또한 Classification task 뿐만 아니라 Instance Segmentation(Mask R-CNN), Image Synthesis(BigGAN) 등에서도 좋은 성능을 보였다고 합니다. 결과가 굉장히 인상적이죠? 본 논문의 contribution은 다음과 같으며, 이제 본 논문에서 제안한 방법들을 상세히 설명을 드리겠습니다.
- 최초로 normalization layer와 activation function을 하나의 통합된 연산으로 간주하여 co-design 하는 방법을 제안함.
- 잘 정의된 building block 들을 따라가는 대신, 굉장히 low-level한 단계에서 시작해서 사람이 design한 결과를 뛰어넘을 수 있음을 보임.
- 하나의 고정된 architecture를 찾는 Architecture Search와는 다르게 다양하게 사용될 수 있는 module을 찾는 Layer Search 라는 패러다임을 제안함.
- 다양한 Classification model들에서 제안한 layer를 사용하면 정확도 향상을 얻을 수 있음.
Search Space & Layer Search Method
Search Space
우선 자동으로 연산 구조를 찾기 위해선 Search Space를 설계해야 합니다. 위의 EvoNorm-S0 그림과 같이 input에서 output으로 가는 길에 여러 연산을 배치하는 방식이며, 이 연산들은 input tensor와 output tensor의 shape가 유지되도록 설계되어야 하며, 초기 4개의 node를 가지고 시작합니다. Initial node로는 input tensor, constant zero tensor, 각각 0과 1로 initialized된 2개의 trainable한 vector v0, v1 가 사용이 되었습니다.
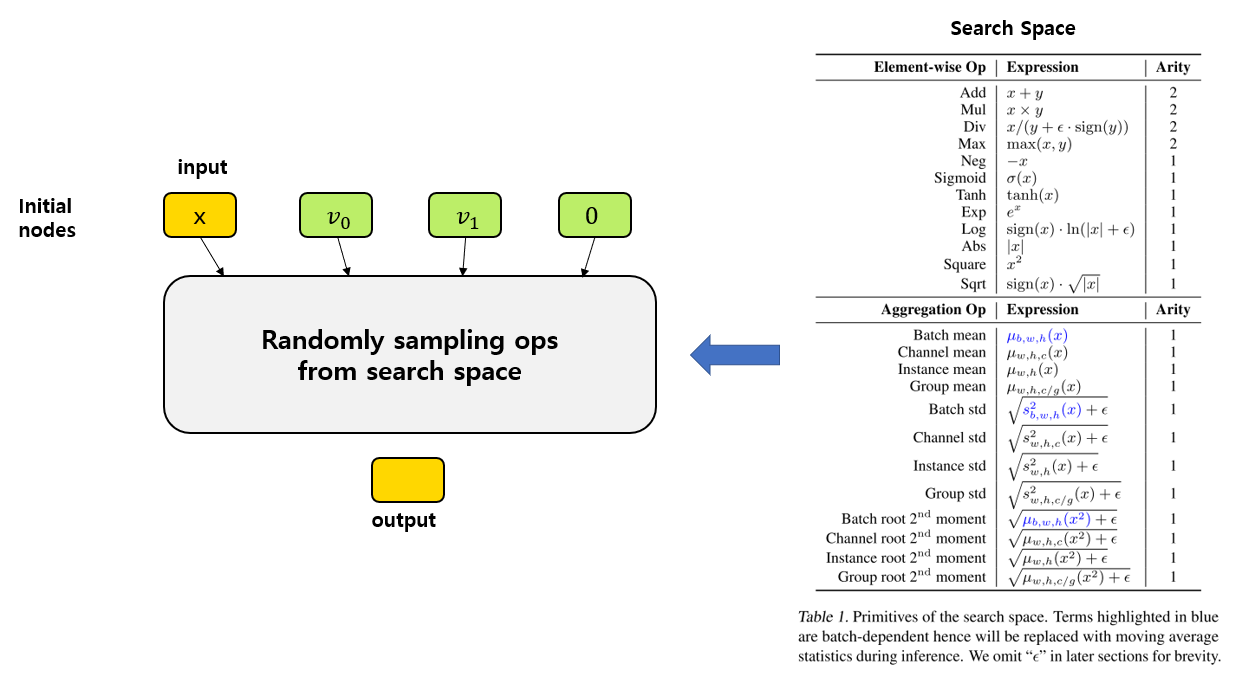
우선 오른쪽 표의 연산들이 Search Space로 사용이 되었으며, initial node 부터 시작해서 순차적으로 random하게 primitive op을 sampling해서 임의로 연결합니다. 대부분의 연산들은 input을 1개로 갖고, Add, Mul, Div, Max 연산만 input을 2개로 갖습니다. (논문에서는 input 개수를 arity라 표현하고 있습니다.) 이 arity에 맞게 input을 연결해준다고 생각하시면 될 것 같습니다. 이 과정을 반복하면 마지막 연결된 node가 output이 되며, 사용이 되지 않은 node들이 있을 수 있습니다. (처음 보여드린 그림의 회색 node)
Layer Search Method
이제, 어떻게 Layer를 탐색하는지, 어떤 layer가 좋다고 할 수 있는지를 구체적으로 설명 드리겠습니다. 우선 좋은 layer는 다양한 architecture에 대해서 잘 작동해야 함을 전제로 합니다.
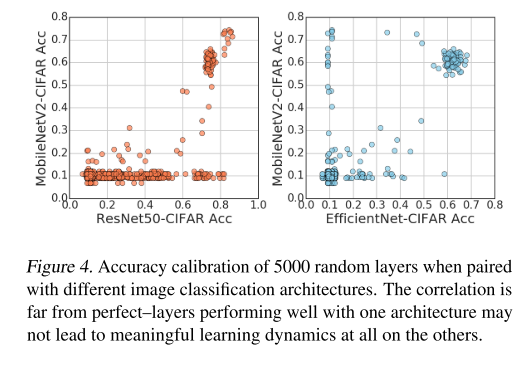
어떤 architecture에서는 잘 동작하다가 다른 architecture에 붙이면 잘 동작하지 않을 수 있습니다. 실제로 위의 그림은 random하게 5000개의 layer에 대해 다양한 architecture에 대해 accuracy를 측정한 결과인데, A architecture(X 축)에서는 높은 정확도를 냈는데 B architecture(Y 축)에서는 거의 망하는 결과를 보여주기도 했습니다. 그러므로 본 논문에서는 여러 architecture 구조에 대해서 동시에 좋은 성능을 달성하는 것을 목표로 layer를 평가합니다.
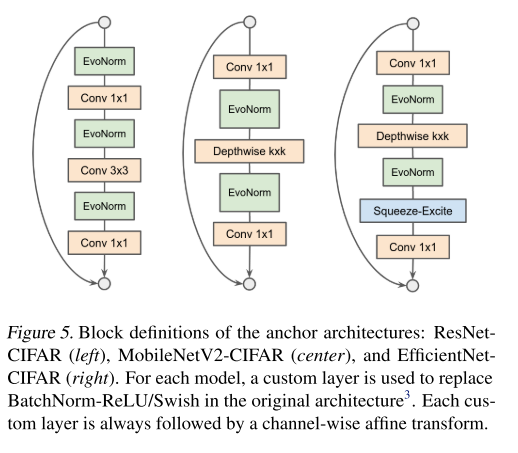
본 논문에서는 CIFAR-10에 대한 Classification task를 proxy task로 정하였고, ResNet50, MobileNetV2, EfficientNet을 architecture로 사용하였으며, 이를 논문에서는 anchor architecture라 부릅니다.
진화 알고리즘으로는 tournament selection 기반 방법을 사용하였습니다. 토너먼트는 population의 random한 subset을 기반으로 형성되며, 토너먼트의 승자는 mutated 자식을 생성하고, 평가를 거쳐 population에 추가가 되는 방식입니다.
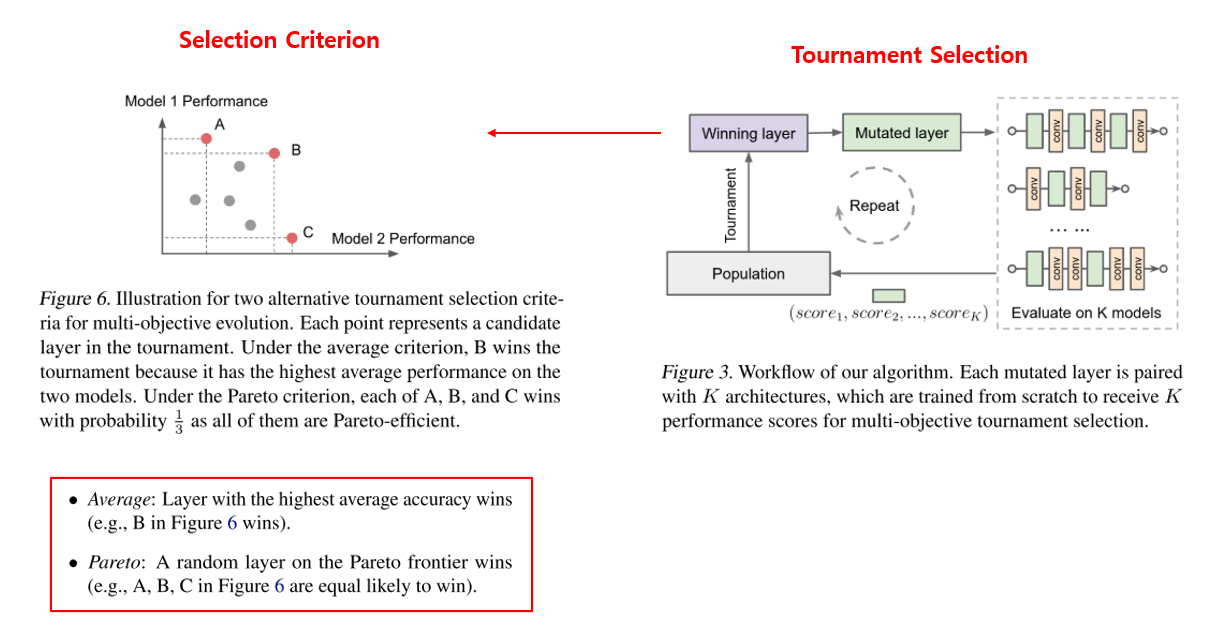
Tournament Selection을 그림으로 나타내면 위의 그림과 같으며, 승자를 선택할 때 단순히 여러 실험들의 평균을 보는 것이 아닌, Figure 6과 같이 Pareto Curve를 그린 뒤 이를 통해 승자를 정하는 방식을 채택하였습니다. 위에서 말씀드렸듯이 하나의 architecture에서 압도적으로 잘되기보다는, 여러 architecture에서 골고루 잘 되길 바라는 마음이 반영이 되었다고 보시면 될 것 같습니다. 이 경우 A, B, C 모두 높은 점수를 주고 있으므로, 이 때는 승자를 random하게 정합니다.
Mutation(돌연변이)으로는 (1) 현재 node에서 intermediate node를 uniform random하게 선택하여 연결하거나, (2) 현재 node의 operation 1개를 새로운 operation으로 uniform random하게 교체하거나, (3) 현재 node의 predecessor를 uniform random하게 선택하는 등 3가지 방법을 사용하였습니다.
마지막으로, 탐색의 효율과 안정성을 높이기 위해 2가지 Rejection Protocols 을 추가하였습니다. 우선, 100 training step 이후 validation accuracy가 20% 이하인 layer는 바로 버립니다. 가능성이 안보이는 후보들은 미리 쳐내겠다는 의도입니다.
또한, 안정성을 높이기 위해 numerically 불안정한 layer를 걸러내는 과정을 추가하였습니다. Network의 gradient norm을 최대화하는 방향으로 adversarially convolutional weight를 조절해주는 방식을 이용하였으며, 100 step동안 이 과정을 거친 뒤, worst-case gradient norm이 10의 8승보다 크면 해당 Layer를 reject 하였다고 합니다. 쉽게 생각하면 gradient가 빠르게 폭파(explode)하는 Layer는 안정성이 낮다고 판단하여 제외를 하였다고 할 수 있습니다.
실험 결과
이제 실험 결과에 대해 설명을 드리겠습니다. 실험의 디테일한 정보는 논문에 자세히 적혀 있으며, 저는 그대로 받아 적기만 하겠습니다.
We use the same training setup for all the CIFAR-10 with a batch size of 128 for training, and use the architectures.
Specifically, we use 24×24 random crops on CIFAR-10 with a batch size of 128 for training, and use the original 32x32 image with a batch size of 512 for validation.
We use SGD with learning rate 0.1, Nesterov momentum 0.9 and weight decay 10−4.
Each model is trained for 2000 steps with a constant learning rate for the EvoNorm-B experiment.
Each model is trained for 5000 steps following a cosine learning rate schedule for the EvoNorm-S experiment.
These are chosen to ensure the majority of the models can achieve reasonable convergence quickly.
With our implementation, it takes 3-10 hours to train each model on a single CPU worker with two cores.
진화 알고리즘으론 AutoML-Zero의 1저자가 2019 AAAI에 제안한 Regularized Evolution 알고리즘을 사용하였으며, 위에선 CIFAR-10에 대한 실험 셋팅을 설명드렸고, ImageNet 데이터셋에 대한 실험 셋팅은 논문에서 확인하실 수 있습니다.
또한 search 후에 Reranking 이라는 과정을 거치게 됩니다. evolution으로부터 top-10의 후보를 추린 뒤, 이들을 ResNet-50, MobileNetV2, EfficientNet-B0에 대해 성능을 측정하여 평균을 낸 뒤, top-3 layer들을 실험 결과를 측정하는데 사용하였다고 합니다. 이 과정은 계산양이 많아지지만 관심있는 downstream task을 더 대표하게 되어서 상위 후보군들을 더 잘 구분하게 해준다고 합니다. 쉽게 말해, 10번 찾은 뒤 상위 3개를 추려서 사용하겠다는 뜻이며, 논문의 Appendix B에는 search를 통해 찾은 10개의 후보 layer들이 있습니다. (이중 2개는 중복된 layer입니다.)
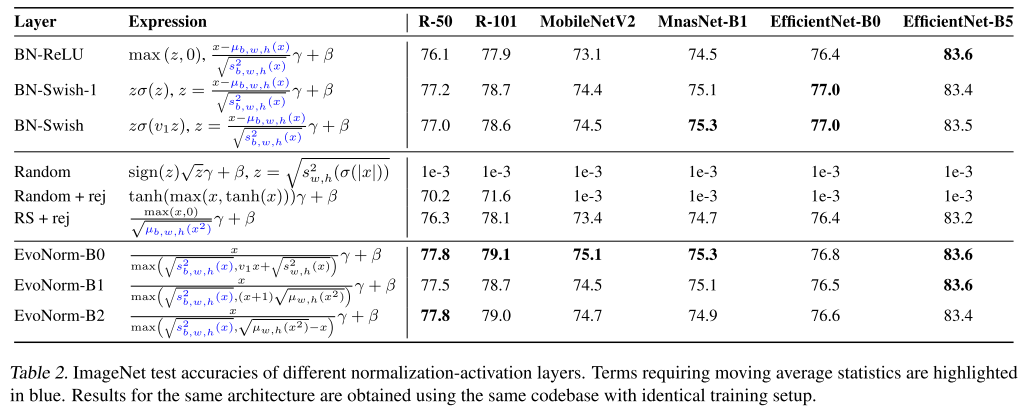
위의 표는 ImageNet test set에 대한 여러 architecture들에 대해 실험한 결과이며, 기존에 자주 사용되던 normalization-activation들, Random Search + Rejection Protocol, 그리고 EvoNorm의 실험 결과를 비교하고 있습니다. 대부분의 경우에서 EvoNorm이 우수한 성능을 보였고, AutoML로 찾은 Swish와 BN의 조합을 대부분의 경우에서 이긴 점이 인상깊은 결과입니다. 또한 완전 random하게 생성한 layer는 Rejection Protocol을 적용해도 좋지 않은 결과를 보이지만, Random Search에 Rejection Protocol을 적용하면 EvoNorm보다는 안 좋지만 BN-ReLU보다는 좋은 결과를 달성한 점도 인상깊은 결과입니다.
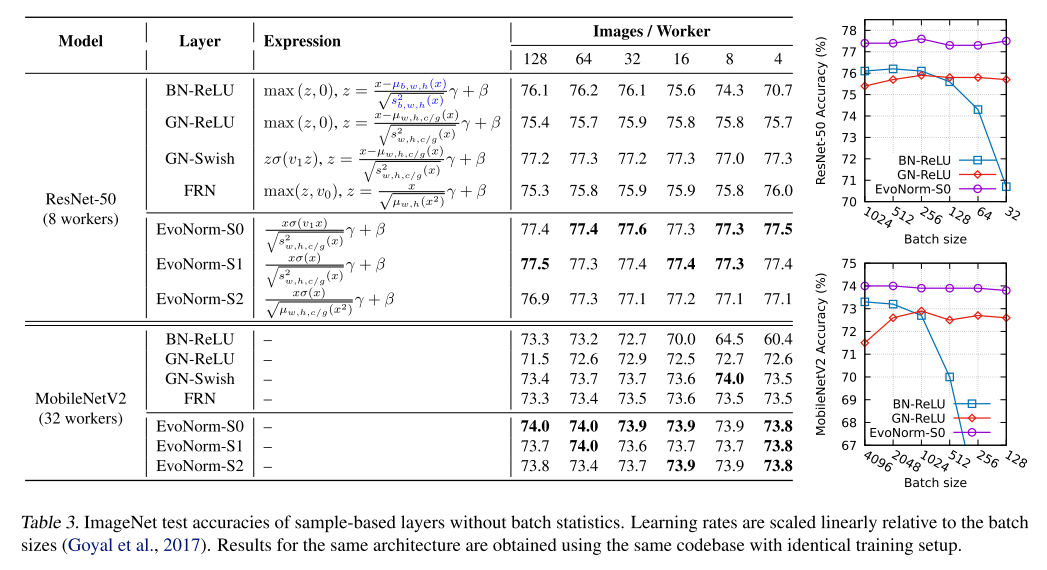
또한 위의 표와 그림은 Batch Size에 따른 실험 결과를 보여주고 있으며, 기존에 BN은 작은 Batch Size에서는 잘 동작하지 않고, 이를 해결하기 위해 나온 GN은 큰 Batch Size에서는 BN보다 좋지 않은 성능을 보였었는데, EvoNorm을 사용하면 BN, GN보다 더 높은 성능을 달성할 수 있음을 보여주고 있습니다. 자세히 보시면 EvoNorm-S 로 되어있는데, 위에서 사용된 EvoNorm-B와의 차이점은 작은 batch size에서 안정적으로 학습할 수 있도록, batch aggregation ops을 search space에서 제외하여 sample에만 집중할 수 있도록 search를 하였다고 해서, Sample-based layer 라 부르며, 줄여서 EvoNorm-S라 부르고 있습니다. 무튼, 사람이 열심히 연구해왔던 normalization 기법들보다 우수한 성능을 내는 점이 참 재밌는 결과입니다.
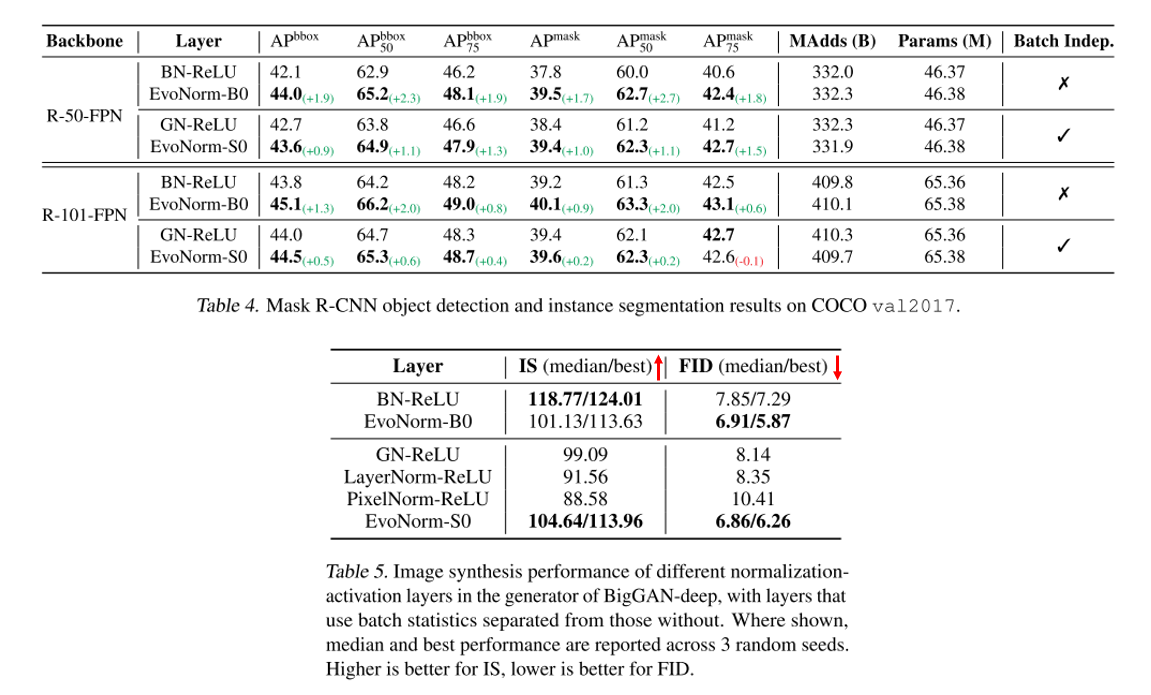
Classification task 외에도 Instance Segmentation, Image Synthesis에도 EvoNorm을 적용할 수 있으며 Instance Segmentation task에서 BN-ReLU, GN-ReLU를 EvoNorm으로 대체하면 성능이 향상되는 것을 확인할 수 있습니다. Inception Score 지표에서는 BN-ReLU가 가장 높은 성능을 보였지만, per-sample normalization-activation layer들 중에선 EvoNorm-S가 가장 좋은 성능을 보였고, FID score에서는 per-batch, per-sample 두 경우에서 모두 EvoNorm이 가장 좋은 성능을 보였습니다. Classification task를 목표로 찾은 normalization-activation layer임을 잊지 않으셔야 합니다! ㅎㅎ

마지막으로 컴퓨터(AI)가 찾은 EvoNorm 구조에 대해 사람이 분석을 하는 내용을 소개 드리겠습니다.
우선 EvoNorm-B0는 한가지 종류의 variance에 의존하는 기존 normalization 방법들과는 다르게 batch variance와 instance variance을 둘 다 고려하는 점이 특징이며, batch variance를 통해 batch 내의 image들의 global한 정보를, instance variance를 통해 single image의 local한 정보를 반영하고 있다고 설명합니다. 또한 optimization 관점에서 좋은 작용을 한다고 알려진 scale invariance property (input x를 rescaling 해도 output에 반영이 되지 않는 특성)가 반영이 되어있는 점도 흥미로운 점입니다.
Sample-based EvoNorm-S0은 분자는 Swish activation function과 거의 똑같이 생겼고 분모에는 Group Norm의 standard deviation이 선택되었습니다. 다만 GN-Swish와 같은 역할을 하지는 않으며, 여기에도 마찬가지로 scale invariance property가 반영이 되어있습니다.
결론
오늘은 최근 발표된 AutoML을 이용하여 Normalization layer와 Activation function을 동시에 설계하는 방법을 다룬 “Evolving Normalization-Activation Layers” 논문을 리뷰하였습니다. 비단 architecture 뿐만 아니라 이제는 Deep Neural Network를 구성하는 여러 요소들도 Automatically 찾을 수 있게 되었고, 심지어 사람이 몇 년에 걸쳐 찾아낸 방식들을 우습게 이겨버리는 결과를 보면 참 기술의 발전이 빠르고 무섭다는 생각이 들게 됩니다.. 다음에는 어떤 요소를 AutoML로 풀게 될지.. 기대 반 두려움 반의 마음으로 지켜보려고 합니다. 공부 하시는데 도움이 되셨으면 좋겠습니다. 감사합니다!